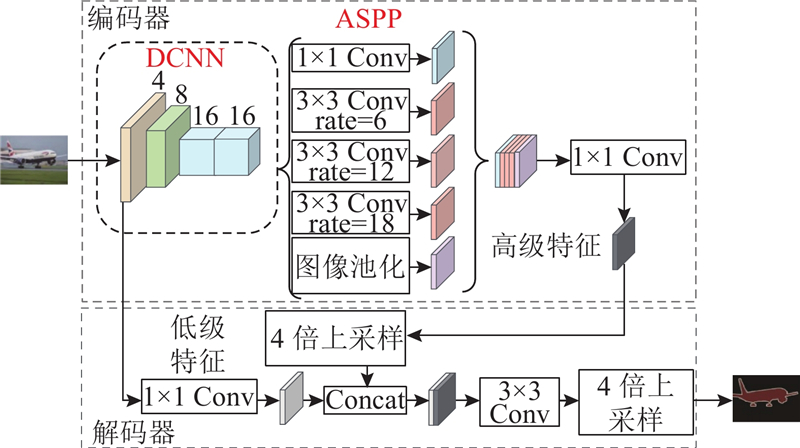
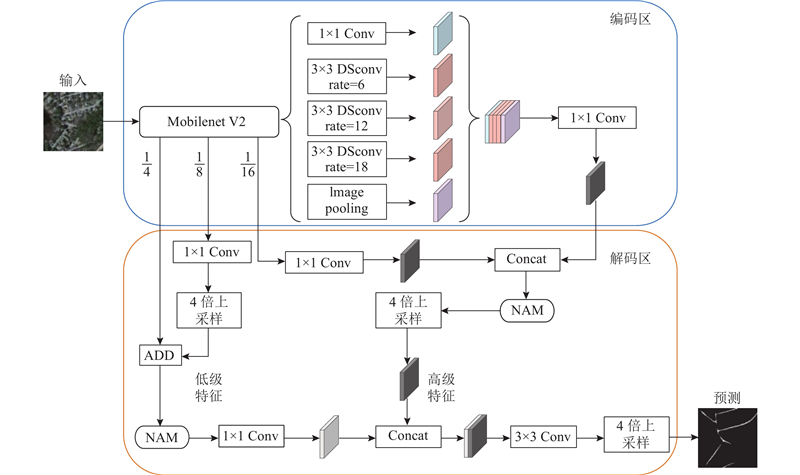
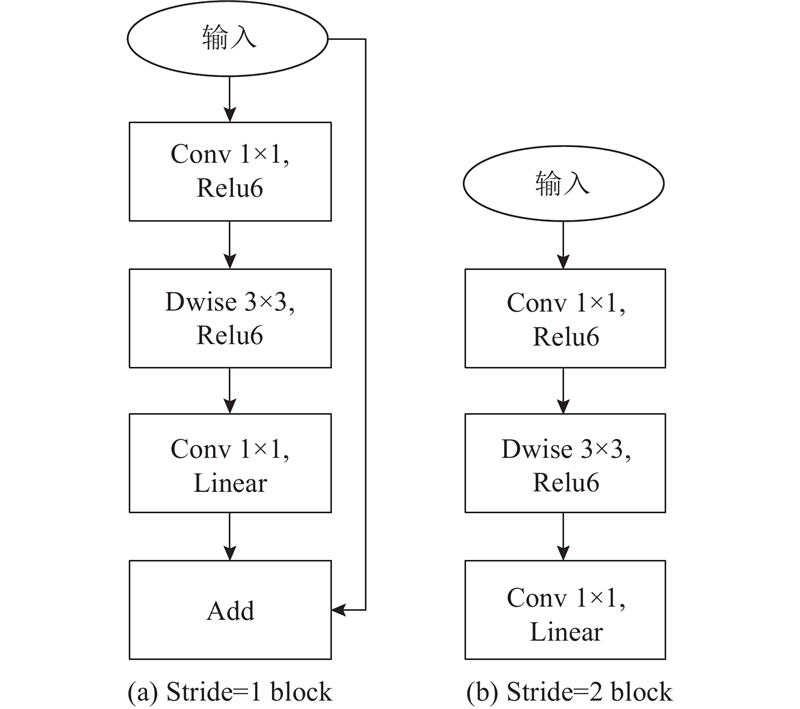
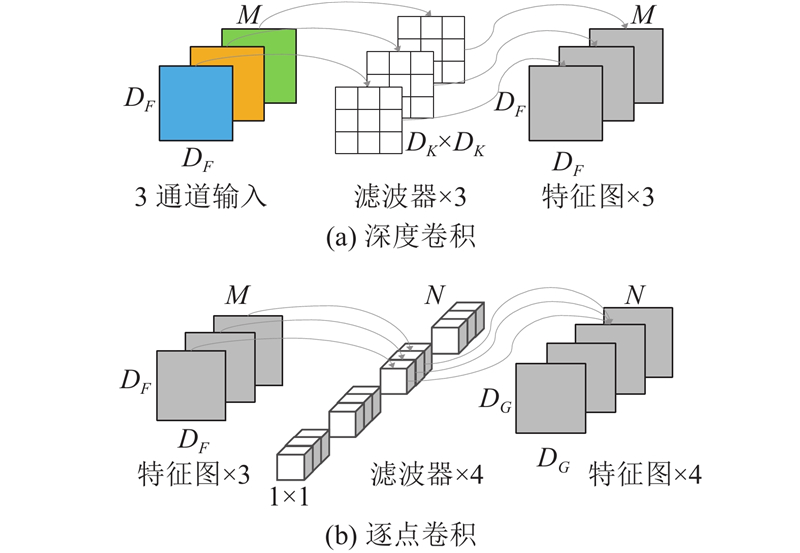
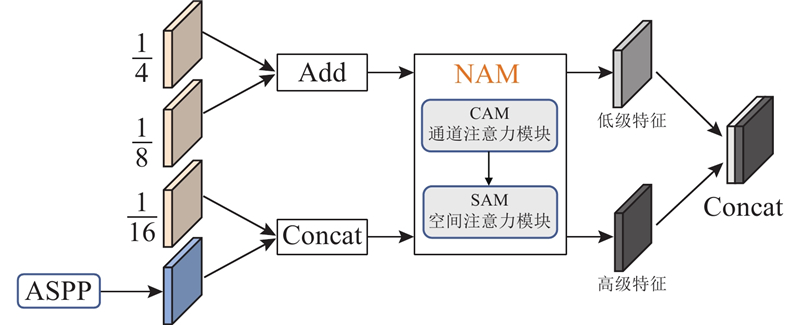
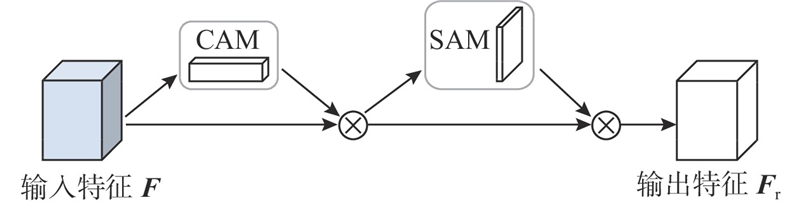
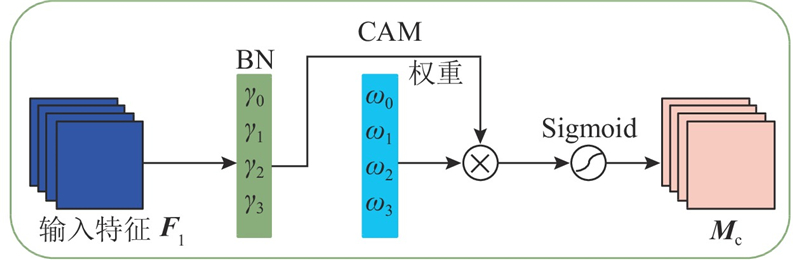
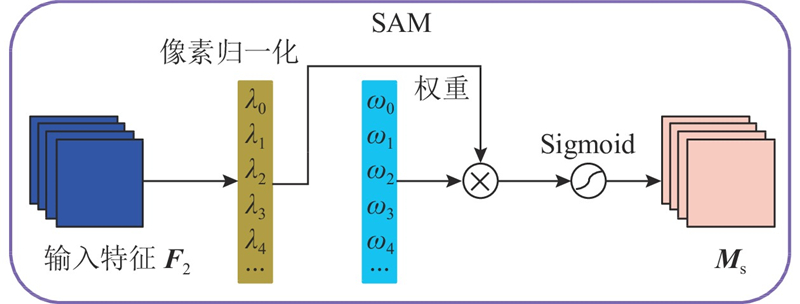
| 计算机技术、通信技术 |
|

|
|
|
| 基于多尺度特征融合的轻量化道路提取模型 |
刘毅( ),陈一丹,高琳*(),洪姣 ),陈一丹,高琳*(),洪姣 |
| 天津城建大学 计算机与信息工程学院,天津 300384 |
|
| Lightweight road extraction model based on multi-scale feature fusion |
| Yi LIU(),Yidan CHEN,Lin GAO*(),Jiao HONG |
| School of Computer and Information Engineering, Tianjin Chengjian University, Tianjin 300384, China |
引用本文:
刘毅,陈一丹,高琳,洪姣. 基于多尺度特征融合的轻量化道路提取模型[J]. 浙江大学学报(工学版), 2024, 58(5): 951-959.
Yi LIU,Yidan CHEN,Lin GAO,Jiao HONG. Lightweight road extraction model based on multi-scale feature fusion. Journal of ZheJiang University (Engineering Science), 2024, 58(5): 951-959.
链接本文:
https://www.zjujournals.com/eng/CN/10.3785/j.issn.1008-973X.2024.05.008
或
https://www.zjujournals.com/eng/CN/Y2024/V58/I5/951
|
| 1 |
HOU Y, LIU Z, ZHANG T, et al C-unet: complement unet for remote sensing road extraction[J]. Sensors, 2021, 21 (6): 2153
doi: 10.3390/s21062153
|
| 2 |
GUNAWAN A, ARIFIANY I, IRWANSYAH E Semantic segmentation of aerial imagery for road and building extraction with deep learning[J]. ICIC Express Letters, 2020, 14 (1): 43- 52
|
| 3 |
CHENG G, WANG Y, XU S, et al Automatic road detection and centerline extraction via cascaded end-to-end convolutional neural network[J]. IEEE Transactions on Geoscience and Remote Sensing, 2017, 55 (6): 3322- 3337
doi: 10.1109/TGRS.2017.2669341
|
| 4 |
杨栋杰, 高贤君, 冉树浩, 等 基于多重多尺度融合注意力网络的建筑物提取[J]. 浙江大学学报: 工学版, 2022, 56 (10): 1924- 1934
YANG Dongjie, GAO Xianjun, RAN Shuhao, et al Building extraction based on multiple multiscale-feature fusion attention network[J]. Journal of Zhejiang University: Engineering Science, 2022, 56 (10): 1924- 1934
|
| 5 |
SHI W, MIAO Z, DEBAYLE J An integrated method for urban main-road centerline extraction from optical remotely sensed imagery[J]. IEEE Transactions on Geoscience and Remote Sensing, 2014, 52 (6): 3359- 3372
doi: 10.1109/TGRS.2013.2272593
|
| 6 |
王小娟, 李云伍, 刘得雄, 等 基于机器视觉的丘陵山区田间道路虚拟中线提取方法[J]. 西南大学学报:自然科学版, 2018, 40 (4): 162- 169
WANG Xiaojuan, LI Yunwu, LIU Dexiong, et al A machine vision-based method for detecting virtual midline of field roads in the hilly areas[J]. Journal of Southwest University: Natural Science, 2018, 40 (4): 162- 169
|
| 7 |
CHANG D, WANG Q, YANG J, et al Research on road extraction method based on sustainable development goals Satellite-1 nighttime light data[J]. Remote Sensing, 2022, 14 (23): 6015
doi: 10.3390/rs14236015
|
| 8 |
王勇, 曾祥强 集成注意力机制和扩张卷积的道路提取模型[J]. 中国图象图形学报, 2022, 27 (10): 3102- 3115
WANG Yong, ZENG Xiangqiang Road extraction model derived from integrated attention mechanism and dilated convolution[J]. Journal of Image and Graphics, 2022, 27 (10): 3102- 3115
|
| 9 |
张永宏, 何静, 阚希, 等 遥感图像道路提取方法综述[J]. 计算机工程与应用, 2018, 54 (13): 1- 10
ZHANG Yonghong, HE Jing, KAN Xi, et al Summary of road extraction methods for remote sensing images[J]. Computer Engineering and Applications, 2018, 54 (13): 1- 10
|
| 10 |
MNIH V, HINTON G E. Learning to detect roads in high-resolution aerial images [C]// Proceedings of European Conference on Computer Vision . Berlin: Springer, 2010: 210-223.
|
| 11 |
ZHONG Z, LI J, CUI W, et al. Fully convolutional networks for building and road extraction: preliminary results [C]// Proceedings of Geoscience and Remote Sensing Symposium . Beijing: IEEE, 2016: 1591-1594.
|
| 12 |
WANG F, JIANG M J, QIAN C, et al. Residual attention network for image classification [C]// IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 6450-6458.
|
| 13 |
LI P, ZHANG Y, WANG C, et al. Road network extraction via deep learning and line integral convolution [C]// Proceedings of 2016 IEEE International Geoscience and Remote Sensing Symposium . Bejing: IEEE, 2016: 1599-1602.
|
| 14 |
CHEN L C, PAPANDREOU G, KOKKINOS I, et al. Semantic image segmentation with deep convolutional nets and fully connected CRFs [EB/OL]. (2014-12-22)[2023-04-13]. https://arxiv.org/abs/1412.7062.
|
| 15 |
CHEN L C, PAPANDREOU G, SCHROFF F, et al. Rethinking atrous convolution for semantic image segmentation [R/OL]. (2017-12-05)[2023-04-13]. https://arxiv.org/abs/1706.05587.
|
| 16 |
CHEN L C, PAPANDREOU G, KOKKINOS I, et al DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40 (4): 834- 848
doi: 10.1109/TPAMI.2017.2699184
|
| 17 |
CHEN L C, ZHU Y, PAPANDREOU G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation [C]// Proceedings of the European Conference on Computer Vision . Cham: Springer, 2018: 801-818.
|
| 18 |
CHOLLET F. Xception: deep learning with depth wiseseparable convolutions [C]// Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 1800-1807.
|
| 19 |
徐胜军, 邓博文, 史亚, 等 一种编解码结构的车牌图像超分辨率网络[J]. 西安交通大学学报, 2022, 56 (10): 101- 110
XU Shengjun, DENG Bowen, SHI Ya, et al An encoder-decoder based super resolution network for license plate images[J]. Journal of Xi'an Jiaotong University, 2022, 56 (10): 101- 110
|
| 20 |
赵凌虎, 袁希平, 甘淑, 等 改进Deeplabv3 +的高分辨率遥感影像道路提取模型[J]. 自然资源遥感, 2023, 35 (1): 107- 114
ZHAO Linghu, YUAN Xiping, GAN Shu, et al Road extraction in high resolution remote sensing images based on improved Deeplabv3+model[J]. Remote Sensing for Natural Resource, 2023, 35 (1): 107- 114
|
| 21 |
葛小三, 曹伟 一种改进DeepLabV3+网络的高分辨率遥感影像道路提取方法[J]. 遥感信息, 2022, 37 (1): 40- 46
GE Xiaosan, CAO Wei A road extraction method for high resolution remote sensing imagery based on improved DeepLabV3+ model[J]. Remote Sensing Information, 2022, 37 (1): 40- 46
|
| 22 |
孟庆宽, 杨晓霞, 张漫, 等 基于语义分割的非结构化田间道路场景识别[J]. 农业工程学报, 2021, 37 (22): 152- 160
MENG Qingkuan, YANG Xiaoxia, ZHANG Man, et al Recognition of unstructured field road scene based on semantic segmentation mode[J]. Transactions of the Chinese Society of Agricultural Engineering, 2021, 37 (22): 152- 160
|
| 23 |
王振, 杨珺, 邓佳莉, 等 多尺度特征自适应融合的图像语义分割算法[J]. 小型微型计算机系统, 2022, 43 (4): 834- 840
WANG Zhen, YANG Jun, DENG Jiali, et al Image semantic segmentation algorithm based on adaptive fusion of multi-scale features[J]. Journal of Chinese Computer Systems, 2022, 43 (4): 834- 840
|
| 24 |
张文博, 瞿珏, 王崴, 等 融合多尺度特征的改进Deeplab v3+图像语义分割算法[J]. 电光与控制, 2022, 29 (11): 12- 16
ZANG Wenbo, QU Jue, WANG Wei, et al An improved Deeplab v3+ image semantic segmentation algorithm incorporating multi-scale features[J]. Electronics Optics and Control, 2022, 29 (11): 12- 16
|
| 25 |
张小国, 丁立早, 刘亚飞, 等 基于双注意力模块的FDA-DeepLab语义分割网络[J]. 东南大学学报:自然科学版, 2022, 52 (6): 1145- 1151
ZHANG Xiaoguo, DING Lizao, LIU Yafei, et al FDA-DeepLab semantic segmentation network based on dual attention module[J]. Journal of Southeast University: Natural Science, 2022, 52 (6): 1145- 1151
|
| 26 |
许泽宇, 沈占锋, 李杨, 等 增强型DeepLab算法和自适应损失函数的高分辨率遥感影像分类[J]. 遥感学报, 2022, 26 (2): 406- 415
XU Zeyu, SHEN Zhanfeng, LI Yang, et al Enhanced DeepLab algorithm and adaptive loss function for high-resolution remote sensing image classification[J]. Journal of Remote Sensing, 2022, 26 (2): 406- 415
|
| 27 |
SANDLER M, HOWARD A, ZHU M, et al. MobileNetV2: inverted residuals and linear bottlenecks [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 4510-4520.
|
| 28 |
QIN Y Y, CAO J T, JI X F Fire detection method based on depthwise separable convolution and YOLOv3[J]. International Journal of Automation and Computing, 2021, 18 (2): 300- 310
doi: 10.1007/s11633-020-1269-5
|
| 29 |
LIU Y C, SHAO Z R, TENG Y Y, et al. NAM: normalization-based attention module [EB/OL]. (2021-11-24)[2023-04-23]. http://arxiv.org/abs/2111.12419.
|
| 30 |
WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module [C]// Proceedings of the European Conference on Computer Vision . Munich: [s. n. ], 2018: 3-19.
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|