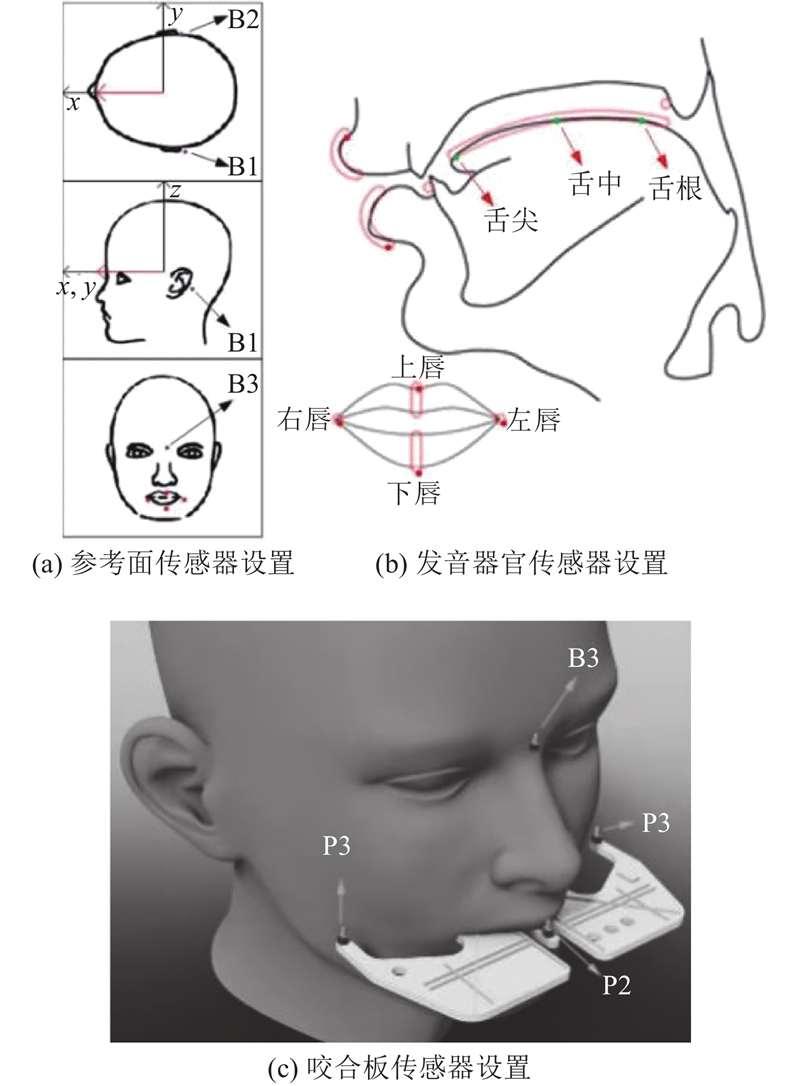
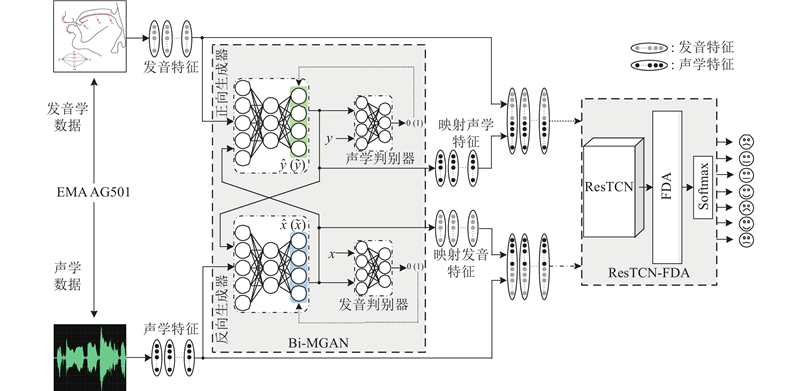
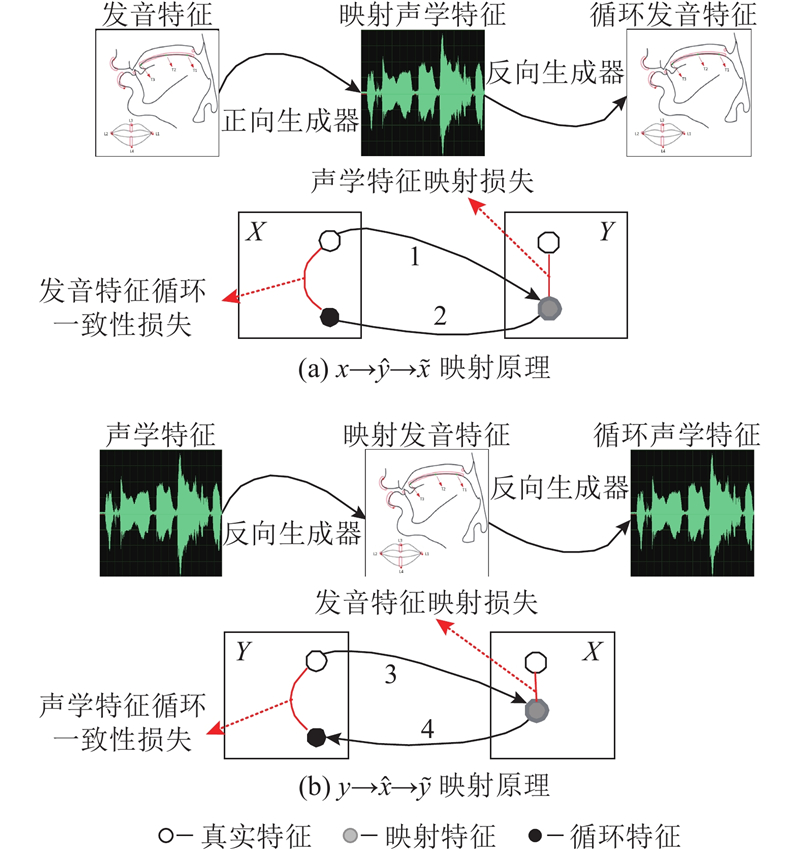
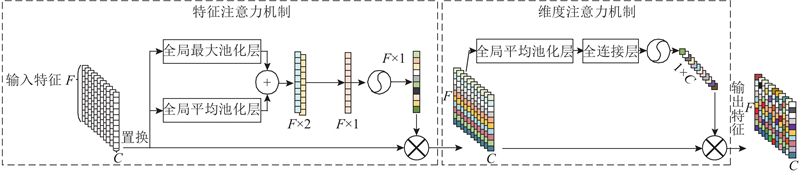
| 计算机技术 |
|

|
|
|
| 融合生成对抗网络与时间卷积网络的普通话情感识别 |
李海烽1( ),张雪英1,*(),段淑斐1,贾海蓉1,Huizhi Liang 2 ),张雪英1,*(),段淑斐1,贾海蓉1,Huizhi Liang 2 |
1. 太原理工大学 电子信息与光学工程学院,山西 太原 030024
2. 纽卡斯尔大学 计算机学院,泰恩-威尔 泰恩河畔纽卡斯尔 NE1 7RU |
|
| Fusing generative adversarial network and temporal convolutional network for Mandarin emotion recognition |
| Hai-feng LI1(),Xue-ying ZHANG1,*(),Shu-fei DUAN1,Hai-rong JIA1,Hui-zhi LIANG2 |
1. College of Electronic Information and Optical Engineering, Taiyuan University of Technology, Taiyuan 030024, China
2. School of Computing, Newcastle University, Newcastle upon Tyne NE1 7RU, United Kingdom |
引用本文:
李海烽,张雪英,段淑斐,贾海蓉,Huizhi Liang . 融合生成对抗网络与时间卷积网络的普通话情感识别[J]. 浙江大学学报(工学版), 2023, 57(9): 1865-1875.
Hai-feng LI,Xue-ying ZHANG,Shu-fei DUAN,Hai-rong JIA,Hui-zhi LIANG. Fusing generative adversarial network and temporal convolutional network for Mandarin emotion recognition. Journal of ZheJiang University (Engineering Science), 2023, 57(9): 1865-1875.
链接本文:
https://www.zjujournals.com/eng/CN/10.3785/j.issn.1008-973X.2023.09.018
或
https://www.zjujournals.com/eng/CN/Y2023/V57/I9/1865
|
| 1 |
LEI J J, ZHU X W, WANG Y BAT: block and token self-attention for speech emotion recognition[J]. Neural Networks, 2022, 156: 67- 80
doi: 10.1016/j.neunet.2022.09.022
|
| 2 |
LI Y, TAO J, CHAO L, et al CHEAVD: a Chinese natural emotional audio visual database[J]. Journal of Ambient Intelligence and Humanized Computing, 2017, 8 (6): 913- 924
doi: 10.1007/s12652-016-0406-z
|
| 3 |
CHOU H C, LIN W C, CHANG L C, et al. NNIME: the NTHU-NTUA Chinese interactive multimodal emotion corpus [C]// 2017 Seventh International Conference on Affective Computing and Intelligent Interaction. San Antonio: IEEE, 2017: 292-298.
|
| 4 |
BUSSO C, BULUT M, LEE C, et al IEMOCAP: interactive emotional dyadic motion capture database[J]. Language Resources and Evaluation, 2008, 42 (4): 335- 359
doi: 10.1007/s10579-008-9076-6
|
| 5 |
QIN C, CARREIRA M A. An empirical investigation of the nonuniqueness in the acoustic-to-articulatory mapping [C]// Eighth Annual Conference of the International Speech Communication Association. Antwerp: [s.n.], 2007: 27-31.
|
| 6 |
REN G, FU J, SHAO G, et al Articulatory to acoustic conversion of Mandarin emotional speech based on PSO-LSSVM[J]. Complexity, 2021, 29 (3): 696- 706
|
| 7 |
HOGDEN J, LOFQVIST A, GRACCO V, et al Accurate recovery of articulator positions from acoustics: new conclusions based on human data[J]. The Journal of the Acoustical Society of America, 1996, 100 (3): 1819- 1834
doi: 10.1121/1.416001
|
| 8 |
LING Z H, RICHMOND K, YAMAGISHI J, et al Integrating articulatory features into HMM based parametric speech synthesis[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2009, 17 (6): 1171- 1185
doi: 10.1109/TASL.2009.2014796
|
| 9 |
LI M, KIM J, LAMMERT A, et al Speaker verification based on the fusion of speech acoustics and inverted articulatory signals[J]. Computer Speech and Language, 2016, 36: 196- 211
doi: 10.1016/j.csl.2015.05.003
|
| 10 |
GUO L, WANG L, DANG J, et al Learning affective representations based on magnitude and dynamic relative phase information for speech emotion recognition[J]. Speech Communication, 2022, 136 (4): 118- 127
|
| 11 |
CHEN Q, HUANG G A novel dual attention based BLSTM with hybrid features in speech emotion recognition[J]. Engineering Applications of Artificial Intelligence, 2021, 102 (5): 104277
|
| 12 |
张静, 张雪英, 陈桂军, 等 结合3D-CNN和频-空注意力机制的EEG情感识别[J]. 西安电子科技大学学报, 2022, 49 (3): 191- 198
ZHANG Jing, ZHANG Xue-ying, CHEN Gui-jun, et al EEG emotion recognition based on the 3D-CNN and spatial-frequency attention mechanism[J]. Journal of Xidian University, 2022, 49 (3): 191- 198
doi: 10.19665/j.issn1001-2400.2022.03.021
|
| 13 |
KUMARAN U, RADHA R S, NAGARAJAN S M, et al Fusion of mel and gammatone frequency cepstral coefficients for speech emotion recognition using deep C-RNN[J]. International Journal of Speech Technology, 2021, 24 (2): 303- 314
doi: 10.1007/s10772-020-09792-x
|
| 14 |
LIESKOVSKA E, JAKUBEC M, JARINA R, et al A review on speech emotion recognition using deep learning and attention mechanism[J]. Electronics, 2021, 10 (10): 1163
doi: 10.3390/electronics10101163
|
| 15 |
ZHU J Y, PARK T, ISOLA P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks [C]// Proceedings of the IEEE International Conference on Computer Vision. Venice: ICCV, 2017: 2223-2232.
|
| 16 |
YUAN J, BAO C. CycleGAN based speech enhancement for the unpaired training data [C]// 2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference. Lanzhou: APSIPA, 2019: 878-883.
|
| 17 |
SU B H, LEE C Unsupervised cross-corpus speech emotion recognition using a multi-source CycleGAN[J]. IEEE Transactions on Affective Computing, 2022, 48 (8): 650- 715
|
| 18 |
LIN J, WIJNGAARDEN A J L, WANG K C, et al Speech enhancement using multi-stage self-attentive temporal convolutional networks[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2021, 29: 3440- 3450
doi: 10.1109/TASLP.2021.3125143
|
| 19 |
PANDEY A, WANG D L. TCNN: temporal convolutional neural network for real-time speech enhancement in the time domain [C]// 2019 IEEE International Conference on Acoustics, Speech and Signal Processing. Brighton: ICASSP, 2019: 6875-6879.
|
| 20 |
ZHANG L, SHI Z, HAN J, et al. Furcanext: end-to-end monaural speech separation with dynamic gated dilated temporal convolutional networks [C]// International Conference on Multimedia Modeling. Daejeon: ICMM, 2020: 653-665.
|
| 21 |
JIANG Z, ZHANG R, GUO Y, et al Noise interference reduction in vision module of intelligent plant cultivation robot using better Cycle GAN[J]. IEEE Sensors Journal, 2022, 22 (11): 11045- 11055
doi: 10.1109/JSEN.2022.3164915
|
| 22 |
GOODFELLOW I, POUGET A J, MIRZA M, et al Generative adversarial nets[J]. Advances in Neural Information Processing Systems, 2014, 27: 42- 51
|
| 23 |
LIU P, YU Q, WU Z, et al. A deep recurrent approach for acoustic-to-articulatory inversion [C]// 2015 IEEE International Conference on Acoustics, Speech and Signal Processing. Brisbane: ICASSP, 2015: 4450-4454.
|
| 24 |
CHENG Y, XU Y, ZHONG H, et al Leveraging semisupervised hierarchical stacking temporal convolutional network for anomaly detection in IoT communication[J]. IEEE Internet of Things Journal, 2020, 8 (1): 144- 155
|
| 25 |
ZHAO Z P, LI Q F, ZHANG Z X, et al Combining a parallel 2D CNN with a self-attention dilated residual network for CTC-based discrete speech emotion recognition[J]. Neural Networks, 2021, 141: 52- 60
doi: 10.1016/j.neunet.2021.03.013
|
| 26 |
CHANG, XUAN K. An exploration of self-supervised pretrained representations for end-to-end speech recognition [C]// 2021 IEEE Automatic Speech Recognition and Understanding Workshop. Cartagena: ASRU, 2021, 228-235.
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|