| 计算机技术 |
|

|
|
|
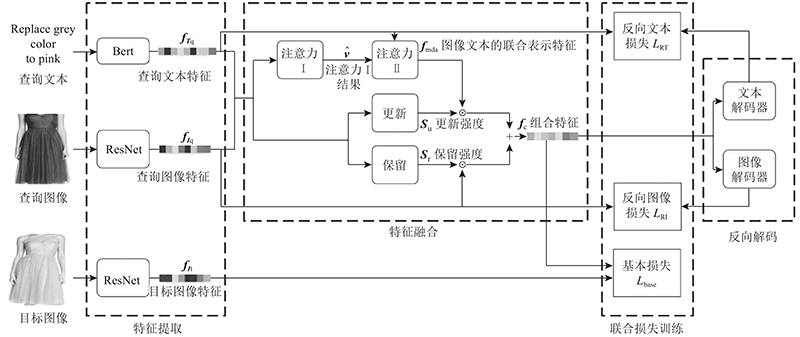
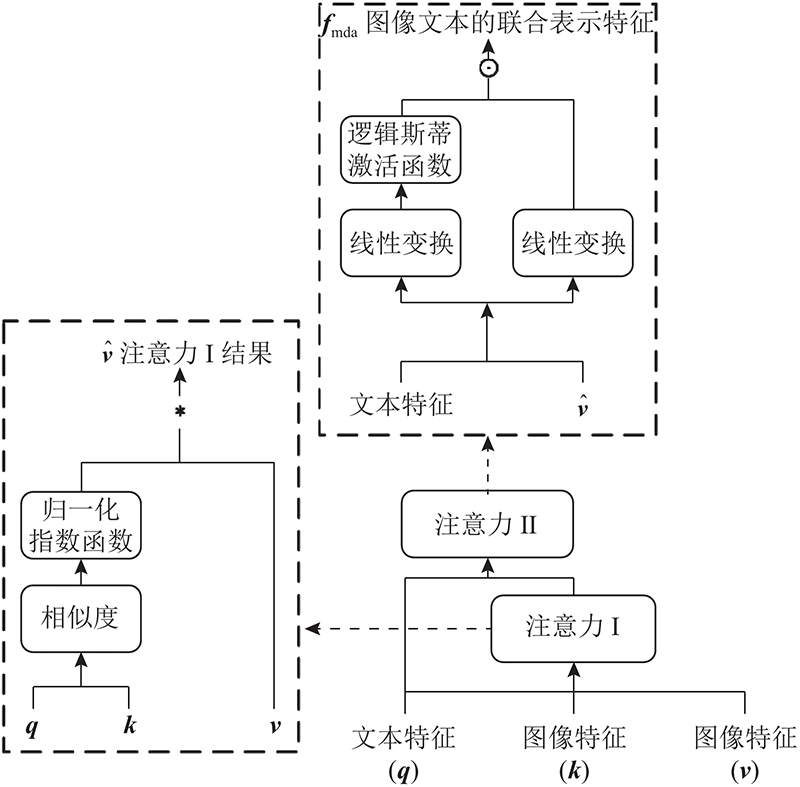
| 基于语义增强特征融合的多模态图像检索模型 |
杨帆( ),宁博*(),李怀清,周新,李冠宇 ),宁博*(),李怀清,周新,李冠宇 |
| 大连海事大学 信息科学技术学院,辽宁 大连 116026 |
|
| Multimodal image retrieval model based on semantic-enhanced feature fusion |
| Fan YANG(),Bo NING*(),Huai-qing LI,Xin ZHOU,Guan-yu LI |
| School of Information Science and Technology, Dalian Maritime University, Dalian 116026, China |
引用本文:
杨帆,宁博,李怀清,周新,李冠宇. 基于语义增强特征融合的多模态图像检索模型[J]. 浙江大学学报(工学版), 2023, 57(2): 252-258.
Fan YANG,Bo NING,Huai-qing LI,Xin ZHOU,Guan-yu LI. Multimodal image retrieval model based on semantic-enhanced feature fusion. Journal of ZheJiang University (Engineering Science), 2023, 57(2): 252-258.
链接本文:
https://www.zjujournals.com/eng/CN/10.3785/j.issn.1008-973X.2023.02.005
或
https://www.zjujournals.com/eng/CN/Y2023/V57/I2/252
|
| 1 |
DUBEY S R A decade survey of content based image retrieval using deep learning[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2022, 32 (5): 2687- 2704
doi: 10.1109/TCSVT.2021.3080920
|
| 2 |
PANG K T, LI K, YANG Y X , et al. Generalising fine-grained sketch-based image retrieval [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 677-686.
|
| 3 |
LIN T Y, CUI Y, BELONGIE S, et al. Learning deep representations for ground-to-aerial geolocalization [C]// 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 5007-5015.
|
| 4 |
ZHANG M, MAIDMENT T, DIAB A, et al. Domain-robust VQA with diverse datasets and methods but no target labels [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. [s.l.]: IEEE, 2021: 7046-7056.
|
| 5 |
CHEN L, JIANG Z, XIAO J, et al. Human-like controllable image captioning with verb-specific semantic roles [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. [s.l.]: IEEE, 2021: 16846-16856.
|
| 6 |
SANTORO A, RAPOSO D, BARRETT D G T, et al. A simple neural network module for relational reasoning [C]// Advances in Neural Information Processing Systems 30. Long Beach: Curran Associates, 2017: 4967-4976.
|
| 7 |
PEREZ E, STRUB F, VRIES H D, et al. FiLM: visual reasoning with a general conditioning layer [C]// 32nd AAAI Conference on Artificial Intelligence. New Orleans: AAAI, 2018: 3942-3951.
|
| 8 |
NAGARAJAN T, GRAUMAN K. Attributes as operators: factorizing unseen attribute-object compositions [C]// European Conference on Computer Vision. Munich: Springer, 2018: 172-190.
|
| 9 |
VO N , LU J, CHEN S, et al. Composing text and image for image retrieval: an Empirical Odyssey[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019 : 6439-6448.
|
| 10 |
ANWAAR M U, LABINTCEV E, KLEINSTEUBER M. Compositional learning of image-text query for image retrieval [C]// 2021 IEEE Winter Conference on Applications of Computer Vision. Waikoloa: IEEE, 2021: 1139-1148.
|
| 11 |
HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition [C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770-778.
|
| 12 |
DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Minneapolis: Association for Computational Linguistics, 2019: 4171–4186.
|
| 13 |
HUANG L, WANG W M, CHEN J, et al. Attention on attention for image captioning[C]// 2019 IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 4633-4642.
|
| 14 |
ISOLA P, LIM J J, ADELSON E H. Discovering states and transformations in image collections [C]// 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 1383-1391.
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|