

图像检索是数据库和计算机视觉交叉领域的一项重要任务,主要是通过一定的算法在海量图片中检索出满足条件的图片[1]. 构建图像检索系统最具挑战性的一个方面是要具备准确理解用户意图的能力. 人类的感知是多模态的,通过单一的图像或文本很难完整表达用户意图.
本研究使用多模态查询的形式进行图像检索,以便更准确地表达用户的意图,具体来说,本研究完成一个多模态图像检索任务,查询输入包括文本和图像2种形式,文本描述查询图像中须做出的修改,目标是检索出符合查询图像及文本描述的图像. 相比于单一的文本检索和图像检索,这种多模态的检索可以使用户更加灵活自然地表达他们的意图.
通常,图像特征和文本特征是从不同的神经网络中提取出来的,得到的特征分布不一致,目前多模态图像检索工作大多是直接将两者结合,忽略了两者特征片段之间复杂的相关性. 本研究旨在更好地建立图像特征与文本特征之间的相关性,通过在特征融合部分分别对文本、图像进行语义增强,建立2个模态之间的联系、优化组合特征使其更接近目标图像特征,提升检索性能.
1. 相关工作
1.1. 图像检索
图像检索的相关研究开始于20世纪70年代,最初是基于文本的图像检索技术(text-based image retrieval,TBIR),它主要通过文本标注来描述图像内容,为每个图像形成相应的关键字,在检索时可以根据用户提供的关键字找出相应图像. TBIR检索快速且精准度也较高,但存在图像文字描述匮乏且人工标注工作量大的问题. 20世纪90年代出现了基于内容的图像检索技术(content-based image retrieval,CBIR),它是以图像语义特征为线索在数据库中进行检索. 随着图像理解、图像识别技术的深入发展,图像检索任务也在逐渐复杂化、人性化,为了解决语义鸿沟问题,人们提出了带有反馈的图像检索技术,利用人机交互的形式提高检索的准确度,出现了草图检索[2]、交叉视图图像检索[3]这些新型检索方式.
1.2. 多模态深度学习
2. 模型介绍
2.1. 问题定义
给定一个输入查询Q(Iq,Tq),其中Iq表示查询图像,Tq表示查询文本. 首先通过不同的网络来提取文本特征
2.2. SEFM模型整体架构
基于语义增强特征融合的多模态图像检索模型(multimodal image retrieval model based on semantic-enhanced feature fusion,SEFM)整体架构如图1 所示. 将图像和文本输入到多模态特征提取模块即左起第1个虚线框,得到的特征向量再进入多模态特征融合模块即第2个虚线框内进行特征融合(具体包括由双重注意力机制实现的文本语义增强模块和由更新强度(update)和保留强度(retain)计算模块构成的图像语义增强模块),得到组合特征. 组合特征再通过第4个虚线框内的2个反向解码器解码为文本特征和图像特征,反向解码后的2个特征和组合特征输入到第3个虚线框内分别进行3种损失训练.
图 1
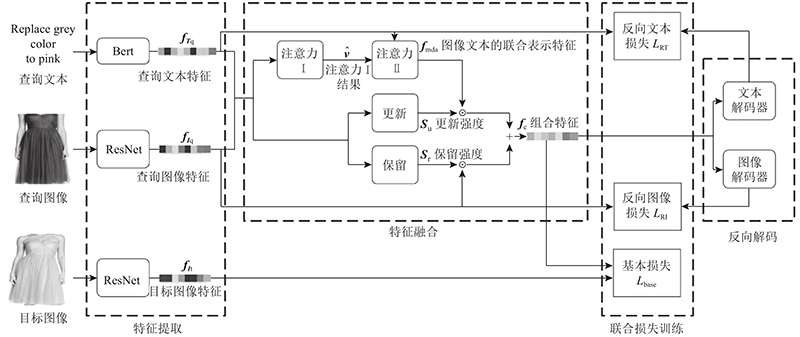
图 1 基于语义增强特征融合的多模态图像检索模型(SEFM)整体架构
Fig.1 General architecture of multimodal image retrieval model based on semantic-enhanced feature fusion (SEFM)
2.3. 多模态特征提取
SEFM图像特征fI和文本特征fT是从独立的单模态模型中提取的. 使用 ResNet-17提取位于512维空间中的图像特征向量,表达式为
式中:I为512维空间中的图像.
ResNet[11]残差网络具有深度自适应能力,它的动机是解决梯度消失问题,可以使冗余的block学习成恒等映射,性能也不会下降.
对于文本特征的提取,使用BERT[12]模型提取位于728维空间中的文本特征向量,表达式为
式中:T为728维空间中的文本.
BERT自带双向功能和多层Self-attention机制,在训练时模型在编码当前词时可以更大程度地考虑上下文,因此能够为查询文本提供更好的特征表示.
2.4. 多模态特征融合
通过文本语义增强模块和图像语义增强模块2部分进行多模态的特征融合,利用语义增强优化组合特征.
2.4.1. 文本语义增强模块
图像特征是从层次网络中提取的,文本特征是从顺序网络中提取的,由于提取2种模态特征的神经网络结构不同,得到的特征分布也不一致,图像特征与文本特征的直接结合不能建立两者特征片段之间复杂的相关性. 基于注意力机制的结构模型可以依据信息的权重去度量不同信息特征的重要性. Huang等[13]为解决图像字幕问题提出Attention on Attention模型,这启发本研究在处理文本图像2种模态之间关系时对注意力机制的应用. 因此,本研究在文本语义增强模块提出多模态双重注意力机制,可以建立文本与图像2个模态之间的联系. 其中第1重注意力用于建立查询图像和查询文本之间的相关性,第2重注意力通过第1重注意力结果和Query即文本特征计算注意力门和注意信息,以此来衡量它们之间的关联程度. 采用双重注意力可以在传统注意力的基础上确定注意力结果与查询文本之间的相关性,进一步增强文本语义.
在传统的注意力机制中,无论Query和图像特征Key是否相关,注意力模块都会生成加权平均值,这样可能得到不相关的向量甚至产生误导信息. 本研究在文本语义增强模块引入多模态双重注意力机制(multimodal dual attention,MDA),MDA专注于建立文本、图像2种模态之间的关联,结构如图2所示. 图中,q、k、v分别表示Query、Key、Value. 将文本和图像的特征输入传统注意力模型(图2的左侧部分),再将传统注意力模型求出的注意力结果和文本特征进行线性变换,生成信息向量i和注意力门g;注意力门的每个值表示信息向量中相应位置信息的相关性,通过对它们进行逐元素乘法添加另一个注意力,从而增强文本语义,过滤掉无关甚至误导的注意力结果,获得图像文本的联合表示特征fmda.
图 2
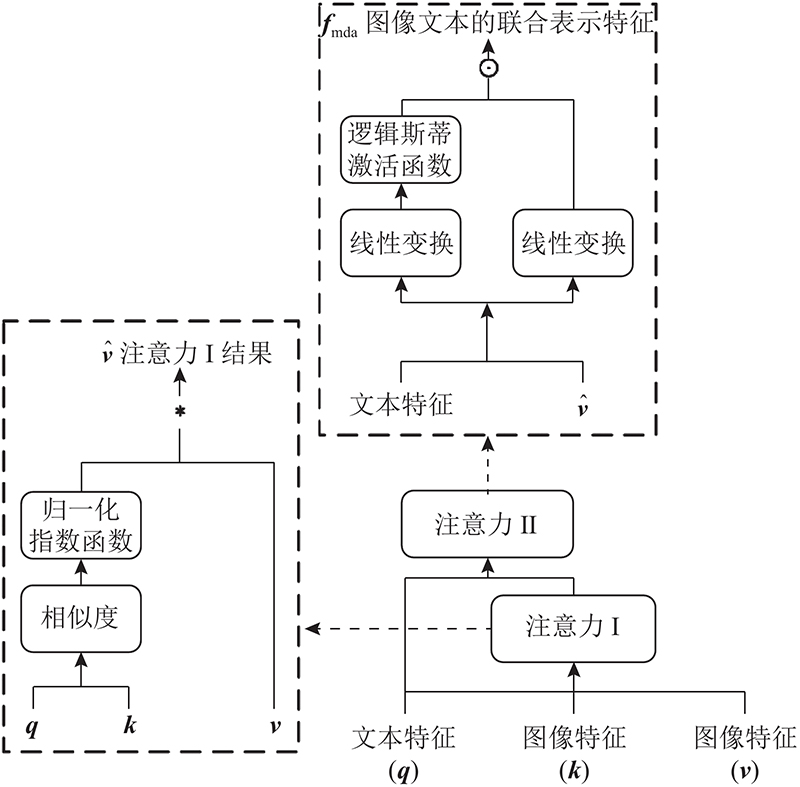
图 2 用于文本语义增强模块的多模态双重注意力MDA结构
Fig.2 Multimodal dual attention structure for text semantic enhancement module
传统注意力表达式如下:
式中:q为文本特征向量
信息向量i和注意力门g通过2个单独的线性变换生成,注意力门g比信息向量i多了一层Sigmoid激活函数. i和g的表达式分别如下:
式中:
信息向量i和注意力门g经过逐元素相乘后得到文本-图像联合表示的特征向量fmda:
式中:⊙表示逐元素乘法.
2.4.2. 图像语义增强模块
文本和图像本身特性不同,相比于文本,图像特征信息量更加丰富,而本研究最终任务是检索出符合要求的图像,因此图像信息至关重要. 本研究提出图像语义增强模块,在特征融合时保留一定的图像特征.
首先根据查询图像特征和查询文本特征计算出更新强度Su和保留强度Sr. 保留强度表示查询图像特征向量的每个特征值应该保留的比重,更新强度表示通过多模态双重注意力MDA求出的文本-图像联合表示的特征向量fmda中每个特征值应该具有的比重.
保留强度Sr和更新强度Su通过多层感知机(multilayer perceptron,MLP)实现,表达式如下:
式中:Wr、Wu为可学习的权重矩阵,用来平衡向量
2.5. 反向解码及联合损失训练
本研究采用深度度量学习 (deep metric learning, DML) 方法来训练模型,目标是使组合特征与目标图像特征之间的相似性度量 k(·,·)尽可能大,并且使组合特征与非相似图像特征的相似性尽可能减小. 对于来自大小为N的mini-batch的样本 i,
在MIT-States 数据集中,采用软三元组损失(SoftTriple Loss)作为基本损失函数,在实验中创建M个集合,每个集合包含一个正样本和一个负样本,其中M 选择与 ComposeAE 相同的值即 3. 表达式如下:
对于Fashion IQ 数据集,基本损失是具有相似性内核的softmax 损失:
受ComposeAE启发,除了基本损失,本研究通过2个反向解码器增加反向损失. 在特征融合后通过解码器反向解码组合特征,再将解码所得特征与2个模态的输入特征进行比较,作为反向损失. 这样能够约束公共空间中多模态特征的学习,使组合特征在最终表示中保留相关的文本和图像信息,减少性能的变化且有助于防止过度拟合. 通过解码器反向解码组合特征的表达式如下:
式中:
将解码所得特征与2个模态的输入特征比较作为反向损失,表达式如下:
将基本损失与2个反向解码求得的损失相加得到最终损失:
3. 实验结果及分析
3.1. 数据集
3.2. 实验设置
3.3. 定量分析
MIT-States 数据集和Fashion IQ 数据集上不同算法的召回率结果对比如表1、2所示. 表中,R@k为检索结果中排名前k的结果中包含目标图像的概率. 由表1可以看出,对于 MIT-States 数据集,SEFM相较其他模型来说效果更好. 就R@1而言,SEFM达到了15.5,相对于TIRG、TIRG-Bert、ComposeAE分别提高了 27.05%、26.02%、11.51%. 由表2可以看出SEFM在Fashion IQ数据集上相较与其他方法也有所提升. SEFM模型与ComposeAE模型进行对比,dress类别的R@10指标为11.9,性能提高了6.25%,shirt类别的R@10指标,性能提高了13.13%, top & tee类别的 R@10指标,性能提升了11.42%。SEFM模型整体效果最佳,不过在R@50指标上,TIRG-Bert的召回率更高。
表 1 MIT-States 数据集上不同算法的召回率结果对比
Tab.1
| 模型 | R@1 | R@5 | R@10 |
| % | |||
| Attributes as operators | 8.8±0.1 | 27.3±0.3 | 39.1±0.3 |
| Relationship | 12.3±0.5 | 31.9±0.7 | 42.9±0.9 |
| FiLM | 10.1±0.3 | 27.7±0.7 | 38.3±0.7 |
| TIRG | 12.2±0.4 | 31.9±0.3 | 43.1±0.3 |
| TIRG-Bert | 12.3±0.6 | 32.5±0.3 | 43.3±0.5 |
| ComposeAE | 13.9±0.5 | 35.3±0.8 | 47.9±0.7 |
| SEFM | 15.5±0.8 | 37.7±1.0 | 49.6±1.0 |
表 2 Fashion IQ 数据集上不同算法的召回率结果对比
Tab.2
| 模型 | R@10 | R@50 | |||||
| dress | shirt | top&tee | dress | shirt | top&tee | ||
| % | |||||||
| TIRG | 2.2±0.2 | 4.3±0.2 | 3.7±0.2 | 8.2±0.3 | 10.7±0.3 | 8.9±0.2 | |
| TIRG-Bert | 11.7±0.5 | 10.9±0.5 | 11.7±0.3 | 30.1±0.3 | 27.9±0.4 | 28.1±0.3 | |
| ComposeAE | 11.2±0.6 | 9.9±0.5 | 10.5±0.4 | 29.5±0.5 | 25.1±0.3 | 26.1±0.6 | |
| SEFM | 11.9±0.3 | 11.2±0.5 | 11.7±0.3 | 29.6±0.5 | 27.4±0.5 | 27.5±0.3 | |
表 3 MIT-States 数据集上不同算法的准确率结果对比
Tab.3
| 模型 | P@5 | P@10 |
| % | ||
| TIRG | 11.2±0.2 | 10.2±0.2 |
| TIRG-Bert | 11.2±0.2 | 10.1±0.2 |
| ComposeAE | 11.8±0.5 | 10.6±0.3 |
| SEFM | 12.6±0.4 | 11.2±0.2 |
由2个数据集的结果可以看出SEFM模型在多个指标上有所提升,说明通过MDA模块和保留更新机制增强文本、图像语义,可以优化组合特征提升检索性能. Fashion IQ相对于MIT-States数据集来说,整体召回率较差,这是因为Fashion IQ数据集的查询文本内容更加复杂,长度也更长.
3.4. 消融实验
为了确定本研究模型的有效性,对模型自身进行消融实验. 评估SEFM的各个关键模块对SEFM性能的影响. 进行对比的模型如下:1) SEFM(without-text semantic enhancement):去掉文本语义增强模块,即使用传统注意力代替双重注意力;2) SEFM(without-image semantic enhancement):去掉图像语义增强模块直接使用通过多模态双重注意力机制输出的文本图像联合特征作为最终组合特征;3) SEFM(Lbase):损失函数只计算基本损失;4) SEFM(Lbase+LRI):损失函数使用基本损失+反向图像损失;5) SEFM(Lbase+LRT):损失函数使用基本损失+反向文本损失.
表 4 MIT-States 数据集上消融实验召回率结果对比
Tab.4
| 模型 | R@1 | R@5 | R@10 |
| % | |||
| SEFM (without-text semantic enhancement) | 13.4±0.7 | 35.2±0.8 | 47.6±1.0 |
| SEFM (without-image semantic enhancement) | 14.6±0.8 | 34.5±0.9 | 47.7±0.8 |
| SEFM(Lbase) | 14.7±0.7 | 35.7±0.5 | 46.2±0.7 |
| SEFM(Lbase+LRI) | 14.7±0.6 | 34.9±0.5 | 46.8±0.7 |
| SEFM(Lbase+LRT) | 14.9±0.6 | 36.2±0.5 | 47.5±0.7 |
| SEFM | 15.5±0.8 | 37.7±1.0 | 49.6±1.0 |
表 5 Fashion IQ 数据集上消融实验结果召回率结果对比
Tab.5
| 模型 | R@10 | ||
| dress | shirt | top&tee | |
| % | |||
| SEFM (without-text semantic enhancement) | 10.2±0.4 | 10.2±0.2 | 11.0±0.2 |
| SEFM(without-image semantic enhancement) | 10.8±0.5 | 9.1±0.5 | 11.5±0.5 |
| SEFM(Lbase) | 11.2±0.3 | 10.7±0.3 | 11.6±0.3 |
| SEFM(Lbase+LRI) | 11.3±0.3 | 11.0±0.2 | 11.5±0.3 |
| SEFM(Lbase+LRT) | 11.6±0.4 | 11.3±0.3 | 11.7±0.4 |
| SEFM | 11.9±0.3 | 11.2±0.5 | 11.7±0.3 |
在MIT-States数据集上添加了文本语义增强模块后的SEFM模型比SEFM(without-text semantic enhancement)的R@1提升了15.67%,P@5提升了14.55%,原因在于双重注意力进一步确定了注意力结果与查询文本之间的相关性,增强了文本语义. SEFM(without-image semantic enhancement)是未使用图像语义增强模块的模型,导致R@1下降了5.81%,说明在特征融合部分使用保留更新机制加强图像语义对优化组合特征、提升检索效果有重要意义.
相比于SEFM模型,SEFM(Lbase)、SEFM(Lbase+LRI)、SEFM(Lbase+LRT) 3个模型的实验结果有所下降,体现了2个反向损失的作用,其中反向文本解码损失在提升准确性上效果更显著,在Fashion IQ数据集中shirt类别上R@10指标甚至高于SEFM完整模型. 虽然对于P@10指标,SEFM(Lbase)表现达到最优,但从整体效果来看SEFM效果更好.
表 6 MIT-States 数据集上消融实验准确率结果对比
Tab.6
| 模型 | P@5 | P@10 |
| % | ||
| SEFM (without-text semantic enhancement) | 11.0±0.3 | 10.4±0.3 |
| SEFM (without-image semantic enhancement) | 12.1±0.4 | 10.9±0.2 |
| SEFM(Lbase) | 12.0±0.5 | 11.2±0.3 |
| SEFM(Lbase+LRI) | 12.0±0.3 | 11.1±0.1 |
| SEFM(Lbase+LRT) | 11.9±0.3 | 11.0±0.2 |
| SEFM | 12.6±0.4 | 11.2±0.2 |
3.5. 定性分析
如图3所示为SEFM模型在MIT-States数据集和Fashion IQ数据集上的定性检索结果. 前2行检索来自MIT-States数据集,后2行检索来自Fashion IQ数据集. 例如第2行检索,可以看到所有图像都根据文本语义增强模块将状态调整为“古代的”,同时根据图像语义增强模块保留了查询图像中时钟的特征.
图 3

图 3 基于语义增强特征融合的多模态图像检索模型的检索示例
Fig.3 Retrieval example of multimodal image retrieval model based on semantic-enhanced feature fusion
4. 结 语
本研究为多模态图像检索问题提出一种新的方法SEFM,可以在特征融合部分增强文本特征与图像特征之间的相关性. 在文本语义增强模块引入多模态双重注意力机制为文本、图像2个模态的特征建立联系并考虑注意力结果与查询文本之间的相关性,增强文本语义特征. 同时采用图像语义增强模块计算更新强度和保留强度,达到既根据文本更新特征又保留查询图像特征的目的. 整个模型通过增强文本和图像语义使组合特征更接近于目标图像特征. 在MIT-States和Fashion IQ这2个数据集上进行实验和分析,结果表明,相比于其他方法,本研究提出的方法在多个指标上有所提升.
未来考虑将这种增强语义的方式应用到其他多模态任务中,例如视觉问答和图像字幕,可以根据不同任务的特性来增强相应模态的语义,提升特征融合的效果.
参考文献
A decade survey of content based image retrieval using deep learning
[J].DOI:10.1109/TCSVT.2021.3080920 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}