[2]
LI Y, TAO J, CHAO L, et al CHEAVD: a Chinese natural emotional audio visual database
[J]. Journal of Ambient Intelligence and Humanized Computing , 2017 , 8 (6 ): 913 - 924
DOI:10.1007/s12652-016-0406-z
[本文引用: 1]
[3]
CHOU H C, LIN W C, CHANG L C, et al. NNIME: the NTHU-NTUA Chinese interactive multimodal emotion corpus [C]// 2017 Seventh International Conference on Affective Computing and Intelligent Interaction . San Antonio: IEEE, 2017: 292-298.
[本文引用: 1]
[4]
BUSSO C, BULUT M, LEE C, et al IEMOCAP: interactive emotional dyadic motion capture database
[J]. Language Resources and Evaluation , 2008 , 42 (4 ): 335 - 359
DOI:10.1007/s10579-008-9076-6
[本文引用: 1]
[5]
QIN C, CARREIRA M A. An empirical investigation of the nonuniqueness in the acoustic-to-articulatory mapping [C]// Eighth Annual Conference of the International Speech Communication Association . Antwerp: [s.n.], 2007: 27-31.
[本文引用: 2]
[6]
REN G, FU J, SHAO G, et al Articulatory to acoustic conversion of Mandarin emotional speech based on PSO-LSSVM
[J]. Complexity , 2021 , 29 (3 ): 696 - 706
[本文引用: 3]
[7]
HOGDEN J, LOFQVIST A, GRACCO V, et al Accurate recovery of articulator positions from acoustics: new conclusions based on human data
[J]. The Journal of the Acoustical Society of America , 1996 , 100 (3 ): 1819 - 1834
DOI:10.1121/1.416001
[本文引用: 1]
[8]
LING Z H, RICHMOND K, YAMAGISHI J, et al Integrating articulatory features into HMM based parametric speech synthesis
[J]. IEEE Transactions on Audio, Speech, and Language Processing , 2009 , 17 (6 ): 1171 - 1185
DOI:10.1109/TASL.2009.2014796
[本文引用: 1]
[9]
LI M, KIM J, LAMMERT A, et al Speaker verification based on the fusion of speech acoustics and inverted articulatory signals
[J]. Computer Speech and Language , 2016 , 36 : 196 - 211
DOI:10.1016/j.csl.2015.05.003
[本文引用: 3]
[10]
GUO L, WANG L, DANG J, et al Learning affective representations based on magnitude and dynamic relative phase information for speech emotion recognition
[J]. Speech Communication , 2022 , 136 (4 ): 118 - 127
[本文引用: 1]
[11]
CHEN Q, HUANG G A novel dual attention based BLSTM with hybrid features in speech emotion recognition
[J]. Engineering Applications of Artificial Intelligence , 2021 , 102 (5 ): 104277
[本文引用: 3]
[12]
张静, 张雪英, 陈桂军, 等 结合3D-CNN和频-空注意力机制的EEG情感识别
[J]. 西安电子科技大学学报 , 2022 , 49 (3 ): 191 - 198
DOI:10.19665/j.issn1001-2400.2022.03.021
[本文引用: 6]
ZHANG Jing, ZHANG Xue-ying, CHEN Gui-jun, et al EEG emotion recognition based on the 3D-CNN and spatial-frequency attention mechanism
[J]. Journal of Xidian University , 2022 , 49 (3 ): 191 - 198
DOI:10.19665/j.issn1001-2400.2022.03.021
[本文引用: 6]
[13]
KUMARAN U, RADHA R S, NAGARAJAN S M, et al Fusion of mel and gammatone frequency cepstral coefficients for speech emotion recognition using deep C-RNN
[J]. International Journal of Speech Technology , 2021 , 24 (2 ): 303 - 314
DOI:10.1007/s10772-020-09792-x
[本文引用: 2]
[14]
LIESKOVSKA E, JAKUBEC M, JARINA R, et al A review on speech emotion recognition using deep learning and attention mechanism
[J]. Electronics , 2021 , 10 (10 ): 1163
DOI:10.3390/electronics10101163
[本文引用: 3]
[15]
ZHU J Y, PARK T, ISOLA P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks [C]// Proceedings of the IEEE International Conference on Computer Vision . Venice: ICCV, 2017: 2223-2232.
[本文引用: 1]
[16]
YUAN J, BAO C. CycleGAN based speech enhancement for the unpaired training data [C]// 2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference . Lanzhou: APSIPA, 2019: 878-883.
[本文引用: 1]
[17]
SU B H, LEE C Unsupervised cross-corpus speech emotion recognition using a multi-source CycleGAN
[J]. IEEE Transactions on Affective Computing , 2022 , 48 (8 ): 650 - 715
[本文引用: 1]
[18]
LIN J, WIJNGAARDEN A J L, WANG K C, et al Speech enhancement using multi-stage self-attentive temporal convolutional networks
[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing , 2021 , 29 : 3440 - 3450
DOI:10.1109/TASLP.2021.3125143
[本文引用: 5]
[19]
PANDEY A, WANG D L. TCNN: temporal convolutional neural network for real-time speech enhancement in the time domain [C]// 2019 IEEE International Conference on Acoustics, Speech and Signal Processing . Brighton: ICASSP, 2019: 6875-6879.
[本文引用: 1]
[20]
ZHANG L, SHI Z, HAN J, et al. Furcanext: end-to-end monaural speech separation with dynamic gated dilated temporal convolutional networks [C]// International Conference on Multimedia Modeling . Daejeon: ICMM, 2020: 653-665.
[本文引用: 5]
[21]
JIANG Z, ZHANG R, GUO Y, et al Noise interference reduction in vision module of intelligent plant cultivation robot using better Cycle GAN
[J]. IEEE Sensors Journal , 2022 , 22 (11 ): 11045 - 11055
DOI:10.1109/JSEN.2022.3164915
[本文引用: 3]
[22]
GOODFELLOW I, POUGET A J, MIRZA M, et al Generative adversarial nets
[J]. Advances in Neural Information Processing Systems , 2014 , 27 : 42 - 51
[本文引用: 2]
[23]
LIU P, YU Q, WU Z, et al. A deep recurrent approach for acoustic-to-articulatory inversion [C]// 2015 IEEE International Conference on Acoustics, Speech and Signal Processing . Brisbane: ICASSP, 2015: 4450-4454.
[本文引用: 2]
[24]
CHENG Y, XU Y, ZHONG H, et al Leveraging semisupervised hierarchical stacking temporal convolutional network for anomaly detection in IoT communication
[J]. IEEE Internet of Things Journal , 2020 , 8 (1 ): 144 - 155
[本文引用: 5]
[25]
ZHAO Z P, LI Q F, ZHANG Z X, et al Combining a parallel 2D CNN with a self-attention dilated residual network for CTC-based discrete speech emotion recognition
[J]. Neural Networks , 2021 , 141 : 52 - 60
DOI:10.1016/j.neunet.2021.03.013
[本文引用: 5]
[26]
CHANG, XUAN K. An exploration of self-supervised pretrained representations for end-to-end speech recognition [C]// 2021 IEEE Automatic Speech Recognition and Understanding Workshop . Cartagena: ASRU, 2021, 228-235.
[本文引用: 4]
[27]
ZHU, QIU S. A noise-robust self-supervised pre-training model based speech representation learning for automatic speech recognition [C]// 2022 IEEE International Conference on Acoustics, Speech and Signal Processing . Singapore: ICASSP, 2022: 3174-3178.
[本文引用: 4]
BAT: block and token self-attention for speech emotion recognition
1
2022
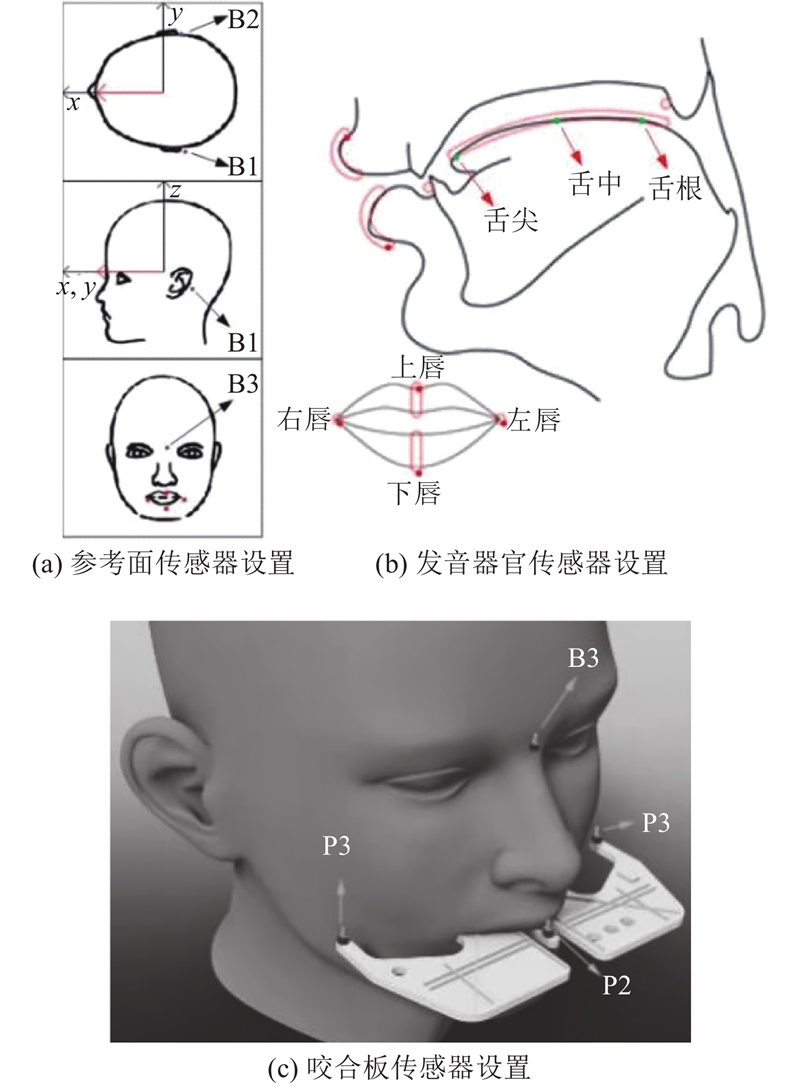
... 情感识别(emotion recognition, ER)是人机交互的重要接口[1 ] ,其目的是让计算机具备理解和识别情感的能力. 融合声学与发音特征转换的ER是情感研究领域中的重要分支,涉及情感数据库搭建、预处理、特征提取、特征转换和分类识别算法等问题. 具有丰富情感信息的多模态数据库、高精度的特征转换算法和有效的分类识别算法是提升ER系统性能的重要部分. ...
CHEAVD: a Chinese natural emotional audio visual database
1
2017
... 在情感研究领域,根据被试者表达信息的多样性构建的适合不同研究方向的数据库有CHEAVD[2 ] 、NNIME[3 ] 和IEMOCAP[4 ] 等. 每个数据库都存在局限性,只有选择与研究方向契合的数据库,研究工作才能事半功倍. 在对人体发音机制的研究中,学者们发现声音和发音器官具有很强的关联性,即人体发出的部分声学信号是由发音器官独特的运动轨迹产生的[5 ] . 正向映射[6 ] 和反向映射[7 ] 是声音与发音器官的关联性研究中较深入的2类. 正向映射指由发音器官的发音特征转换出声学特征,反向映射是指由声学特征转换出发音特征. 深度学习已经在探索正向与反向映射的研究中被应用到不同的领域:Ling等[8 ] 通过隐马尔科夫模型(hidden Markov model, HMM)探究发音特征到声学特征的联合分布关系,将正向映射应用到语音合成研究中;Li等[9 ] 提取梅尔倒谱频率系数(Mel-frequency cepstrum cofficients, MFCC),通过高斯混合模型(Gaussian mixture model, GMM)探究声学到发音特征的关联性,将反向映射应用于说话人识别. 这些方法虽然在声学与发音特征转换中取得了不错的成绩,但都存在转换结果精度偏低的问题. Guo等[10 ] 提取相位特征并探索如何将相位特征应用于语音情感识别. 双向长短期记忆网络(bi-directional long short-term memory, BiLSTM)[11 ] 、卷积神经网络(convolutional neural network, CNN)[12 ] 、深度递归神经网络(recurrent neural network, RNN)[13 ] 和深层神经网络(deep neural network, DNN)[14 ] 等算法通过建立说话人与情感间的关联模型来完成情感识别任务,但特征与维度通道中所包含的情感信息未被充分利用. ...
1
... 在情感研究领域,根据被试者表达信息的多样性构建的适合不同研究方向的数据库有CHEAVD[2 ] 、NNIME[3 ] 和IEMOCAP[4 ] 等. 每个数据库都存在局限性,只有选择与研究方向契合的数据库,研究工作才能事半功倍. 在对人体发音机制的研究中,学者们发现声音和发音器官具有很强的关联性,即人体发出的部分声学信号是由发音器官独特的运动轨迹产生的[5 ] . 正向映射[6 ] 和反向映射[7 ] 是声音与发音器官的关联性研究中较深入的2类. 正向映射指由发音器官的发音特征转换出声学特征,反向映射是指由声学特征转换出发音特征. 深度学习已经在探索正向与反向映射的研究中被应用到不同的领域:Ling等[8 ] 通过隐马尔科夫模型(hidden Markov model, HMM)探究发音特征到声学特征的联合分布关系,将正向映射应用到语音合成研究中;Li等[9 ] 提取梅尔倒谱频率系数(Mel-frequency cepstrum cofficients, MFCC),通过高斯混合模型(Gaussian mixture model, GMM)探究声学到发音特征的关联性,将反向映射应用于说话人识别. 这些方法虽然在声学与发音特征转换中取得了不错的成绩,但都存在转换结果精度偏低的问题. Guo等[10 ] 提取相位特征并探索如何将相位特征应用于语音情感识别. 双向长短期记忆网络(bi-directional long short-term memory, BiLSTM)[11 ] 、卷积神经网络(convolutional neural network, CNN)[12 ] 、深度递归神经网络(recurrent neural network, RNN)[13 ] 和深层神经网络(deep neural network, DNN)[14 ] 等算法通过建立说话人与情感间的关联模型来完成情感识别任务,但特征与维度通道中所包含的情感信息未被充分利用. ...
IEMOCAP: interactive emotional dyadic motion capture database
1
2008
... 在情感研究领域,根据被试者表达信息的多样性构建的适合不同研究方向的数据库有CHEAVD[2 ] 、NNIME[3 ] 和IEMOCAP[4 ] 等. 每个数据库都存在局限性,只有选择与研究方向契合的数据库,研究工作才能事半功倍. 在对人体发音机制的研究中,学者们发现声音和发音器官具有很强的关联性,即人体发出的部分声学信号是由发音器官独特的运动轨迹产生的[5 ] . 正向映射[6 ] 和反向映射[7 ] 是声音与发音器官的关联性研究中较深入的2类. 正向映射指由发音器官的发音特征转换出声学特征,反向映射是指由声学特征转换出发音特征. 深度学习已经在探索正向与反向映射的研究中被应用到不同的领域:Ling等[8 ] 通过隐马尔科夫模型(hidden Markov model, HMM)探究发音特征到声学特征的联合分布关系,将正向映射应用到语音合成研究中;Li等[9 ] 提取梅尔倒谱频率系数(Mel-frequency cepstrum cofficients, MFCC),通过高斯混合模型(Gaussian mixture model, GMM)探究声学到发音特征的关联性,将反向映射应用于说话人识别. 这些方法虽然在声学与发音特征转换中取得了不错的成绩,但都存在转换结果精度偏低的问题. Guo等[10 ] 提取相位特征并探索如何将相位特征应用于语音情感识别. 双向长短期记忆网络(bi-directional long short-term memory, BiLSTM)[11 ] 、卷积神经网络(convolutional neural network, CNN)[12 ] 、深度递归神经网络(recurrent neural network, RNN)[13 ] 和深层神经网络(deep neural network, DNN)[14 ] 等算法通过建立说话人与情感间的关联模型来完成情感识别任务,但特征与维度通道中所包含的情感信息未被充分利用. ...
2
... 在情感研究领域,根据被试者表达信息的多样性构建的适合不同研究方向的数据库有CHEAVD[2 ] 、NNIME[3 ] 和IEMOCAP[4 ] 等. 每个数据库都存在局限性,只有选择与研究方向契合的数据库,研究工作才能事半功倍. 在对人体发音机制的研究中,学者们发现声音和发音器官具有很强的关联性,即人体发出的部分声学信号是由发音器官独特的运动轨迹产生的[5 ] . 正向映射[6 ] 和反向映射[7 ] 是声音与发音器官的关联性研究中较深入的2类. 正向映射指由发音器官的发音特征转换出声学特征,反向映射是指由声学特征转换出发音特征. 深度学习已经在探索正向与反向映射的研究中被应用到不同的领域:Ling等[8 ] 通过隐马尔科夫模型(hidden Markov model, HMM)探究发音特征到声学特征的联合分布关系,将正向映射应用到语音合成研究中;Li等[9 ] 提取梅尔倒谱频率系数(Mel-frequency cepstrum cofficients, MFCC),通过高斯混合模型(Gaussian mixture model, GMM)探究声学到发音特征的关联性,将反向映射应用于说话人识别. 这些方法虽然在声学与发音特征转换中取得了不错的成绩,但都存在转换结果精度偏低的问题. Guo等[10 ] 提取相位特征并探索如何将相位特征应用于语音情感识别. 双向长短期记忆网络(bi-directional long short-term memory, BiLSTM)[11 ] 、卷积神经网络(convolutional neural network, CNN)[12 ] 、深度递归神经网络(recurrent neural network, RNN)[13 ] 和深层神经网络(deep neural network, DNN)[14 ] 等算法通过建立说话人与情感间的关联模型来完成情感识别任务,但特征与维度通道中所包含的情感信息未被充分利用. ...
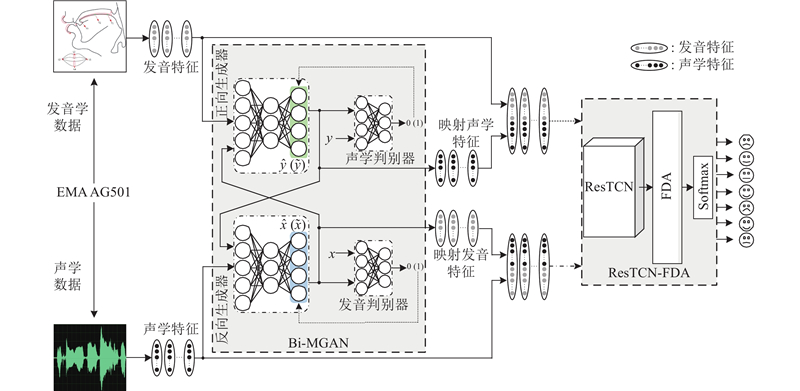
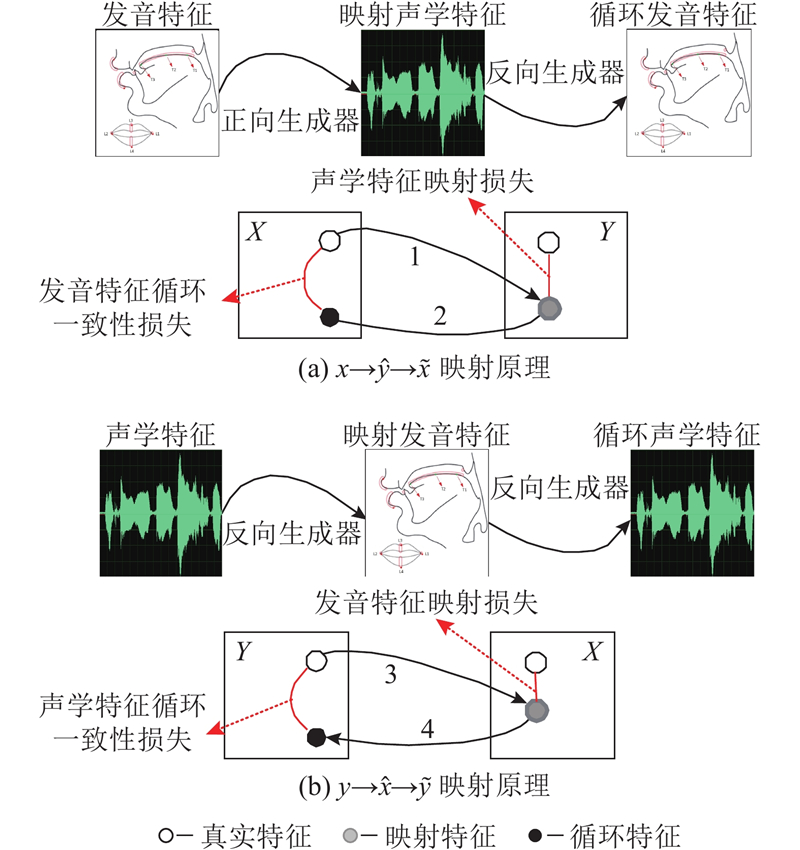
... 转换网络的目的是利用真实特征生成高精度的映射特征,进而探究映射特征对语音情感识别的影响. CycleGAN应用在图像风格转换任务时不要求成对的训练数据[21 ] ,这与声学与发音特征转换任务不同. 人体多数语音都是依靠独特的声道形状产生[5 ] ,这就要求声学与发音学数据的并行性. 为了增强转换模型的映射能力,本研究对CycleGAN的网络结构和损失函数进行优化改进,提出适用于声学与发音特征转换任务的Bi-MGAN,如图4 所示. 图4 (a)中Bi-MGAN将真实发音特征 $ x $ $ \widehat y $ $ \widehat y $ $ \widetilde x $ $ x $ $ \widehat y $ $ y $ $ \widehat y $ $ \widehat y $ $ \widetilde x $ $ x $ $ \widetilde x $ 图4 (b)中Bi-MGAN将真实声学特征 $ y $ $ \widehat x $ $ \widehat x $ $ \widetilde y $ . ...
Articulatory to acoustic conversion of Mandarin emotional speech based on PSO-LSSVM
3
2021
... 在情感研究领域,根据被试者表达信息的多样性构建的适合不同研究方向的数据库有CHEAVD[2 ] 、NNIME[3 ] 和IEMOCAP[4 ] 等. 每个数据库都存在局限性,只有选择与研究方向契合的数据库,研究工作才能事半功倍. 在对人体发音机制的研究中,学者们发现声音和发音器官具有很强的关联性,即人体发出的部分声学信号是由发音器官独特的运动轨迹产生的[5 ] . 正向映射[6 ] 和反向映射[7 ] 是声音与发音器官的关联性研究中较深入的2类. 正向映射指由发音器官的发音特征转换出声学特征,反向映射是指由声学特征转换出发音特征. 深度学习已经在探索正向与反向映射的研究中被应用到不同的领域:Ling等[8 ] 通过隐马尔科夫模型(hidden Markov model, HMM)探究发音特征到声学特征的联合分布关系,将正向映射应用到语音合成研究中;Li等[9 ] 提取梅尔倒谱频率系数(Mel-frequency cepstrum cofficients, MFCC),通过高斯混合模型(Gaussian mixture model, GMM)探究声学到发音特征的关联性,将反向映射应用于说话人识别. 这些方法虽然在声学与发音特征转换中取得了不错的成绩,但都存在转换结果精度偏低的问题. Guo等[10 ] 提取相位特征并探索如何将相位特征应用于语音情感识别. 双向长短期记忆网络(bi-directional long short-term memory, BiLSTM)[11 ] 、卷积神经网络(convolutional neural network, CNN)[12 ] 、深度递归神经网络(recurrent neural network, RNN)[13 ] 和深层神经网络(deep neural network, DNN)[14 ] 等算法通过建立说话人与情感间的关联模型来完成情感识别任务,但特征与维度通道中所包含的情感信息未被充分利用. ...
... 为了验证所提转换网络算法有效性,将Bi-MGAN与传统的DNN[14 ] 和BiLSTM[11 ] 以及深度递归混合密度网路(deep recurrent mixture density network, DRMDN)[23 ] 和粒子群优化算法的最小二乘支持向量机(particle swarm optimization algorithm of least squares support vector machines, PSO-LSSVM)[6 ] 进行对比. 如表3 所示,Bi-MGAN较传统的DNN和BiLSTM的MAE和RMSE大幅提升,较PSO-LSSVM的MAE和RMSE分别提升0.466~0.482 mm和0.344~0.453 mm,较DRMDN的MAE和RMSE分别提升0.181~0.330 mm和0.040~0.256 mm. 对比结果表明,Bi-MGAN可以大幅度提升网络的转换精度,在参加对比的网络中取得最佳的正向映射效果与反向映射效果,证明了Bi-MGAN的有效性. ...
... Comparison of mapping performance for conversion networks algorithm
mm Tab.3 算法 正向映射 反向映射 MAE RMSE MAE RMSE DNN[14 ] 1.479 1.613 1.143 1.259 BiLSTM[11 ] 1.298 1.422 1.003 1.217 PSO-LSSVM[6 ] 1.185 1.252 0.967 1.136 DRMDN[23 ] 0.884 0.948 0.831 0.939 Bi-MGAN 0.703 0.908 0.501 0.683
4.3. 情感识别网络的性能对比 为了探究FDA在情感识别中的作用,分别提取STEM-E2 VA、CASIA、RADVESS和EMO-DB数据库的60维MFCC作为识别网络的输入,进行ResTCN-FDA的消融实验. 其中CASIA为6分类数据库,STEM-E2 VA和EMO-DB为7分类数据库,RADVESS为8分类数据库. 如表4 所示,将ResTCN-FA、ResTCN-DA与ResTCN对比可以发现,特征注意力机制对准确率提升量为1.52%~5.32%,维度注意力机制对准确率提升量为1.50%~4.54%,证明给不同特征和不同通道维度分配不同的权重参数有利于提升情感识别准确率. 将ResTCN-FDA对比TCN、ResTCN、ResTCN-FA和ResTCN-DA,准确率分别提升量为7.48%~10.92%、4.14%~8.16%、2.00%~4.16%和2.48%~6.66%. 另外,ResTCN-FDA的F1和AUC也比其他算法的有一定程度的提升,这说明ResTCN-FDA可以更好的处理情感信息. ...
Accurate recovery of articulator positions from acoustics: new conclusions based on human data
1
1996
... 在情感研究领域,根据被试者表达信息的多样性构建的适合不同研究方向的数据库有CHEAVD[2 ] 、NNIME[3 ] 和IEMOCAP[4 ] 等. 每个数据库都存在局限性,只有选择与研究方向契合的数据库,研究工作才能事半功倍. 在对人体发音机制的研究中,学者们发现声音和发音器官具有很强的关联性,即人体发出的部分声学信号是由发音器官独特的运动轨迹产生的[5 ] . 正向映射[6 ] 和反向映射[7 ] 是声音与发音器官的关联性研究中较深入的2类. 正向映射指由发音器官的发音特征转换出声学特征,反向映射是指由声学特征转换出发音特征. 深度学习已经在探索正向与反向映射的研究中被应用到不同的领域:Ling等[8 ] 通过隐马尔科夫模型(hidden Markov model, HMM)探究发音特征到声学特征的联合分布关系,将正向映射应用到语音合成研究中;Li等[9 ] 提取梅尔倒谱频率系数(Mel-frequency cepstrum cofficients, MFCC),通过高斯混合模型(Gaussian mixture model, GMM)探究声学到发音特征的关联性,将反向映射应用于说话人识别. 这些方法虽然在声学与发音特征转换中取得了不错的成绩,但都存在转换结果精度偏低的问题. Guo等[10 ] 提取相位特征并探索如何将相位特征应用于语音情感识别. 双向长短期记忆网络(bi-directional long short-term memory, BiLSTM)[11 ] 、卷积神经网络(convolutional neural network, CNN)[12 ] 、深度递归神经网络(recurrent neural network, RNN)[13 ] 和深层神经网络(deep neural network, DNN)[14 ] 等算法通过建立说话人与情感间的关联模型来完成情感识别任务,但特征与维度通道中所包含的情感信息未被充分利用. ...
Integrating articulatory features into HMM based parametric speech synthesis
1
2009
... 在情感研究领域,根据被试者表达信息的多样性构建的适合不同研究方向的数据库有CHEAVD[2 ] 、NNIME[3 ] 和IEMOCAP[4 ] 等. 每个数据库都存在局限性,只有选择与研究方向契合的数据库,研究工作才能事半功倍. 在对人体发音机制的研究中,学者们发现声音和发音器官具有很强的关联性,即人体发出的部分声学信号是由发音器官独特的运动轨迹产生的[5 ] . 正向映射[6 ] 和反向映射[7 ] 是声音与发音器官的关联性研究中较深入的2类. 正向映射指由发音器官的发音特征转换出声学特征,反向映射是指由声学特征转换出发音特征. 深度学习已经在探索正向与反向映射的研究中被应用到不同的领域:Ling等[8 ] 通过隐马尔科夫模型(hidden Markov model, HMM)探究发音特征到声学特征的联合分布关系,将正向映射应用到语音合成研究中;Li等[9 ] 提取梅尔倒谱频率系数(Mel-frequency cepstrum cofficients, MFCC),通过高斯混合模型(Gaussian mixture model, GMM)探究声学到发音特征的关联性,将反向映射应用于说话人识别. 这些方法虽然在声学与发音特征转换中取得了不错的成绩,但都存在转换结果精度偏低的问题. Guo等[10 ] 提取相位特征并探索如何将相位特征应用于语音情感识别. 双向长短期记忆网络(bi-directional long short-term memory, BiLSTM)[11 ] 、卷积神经网络(convolutional neural network, CNN)[12 ] 、深度递归神经网络(recurrent neural network, RNN)[13 ] 和深层神经网络(deep neural network, DNN)[14 ] 等算法通过建立说话人与情感间的关联模型来完成情感识别任务,但特征与维度通道中所包含的情感信息未被充分利用. ...
Speaker verification based on the fusion of speech acoustics and inverted articulatory signals
3
2016
... 在情感研究领域,根据被试者表达信息的多样性构建的适合不同研究方向的数据库有CHEAVD[2 ] 、NNIME[3 ] 和IEMOCAP[4 ] 等. 每个数据库都存在局限性,只有选择与研究方向契合的数据库,研究工作才能事半功倍. 在对人体发音机制的研究中,学者们发现声音和发音器官具有很强的关联性,即人体发出的部分声学信号是由发音器官独特的运动轨迹产生的[5 ] . 正向映射[6 ] 和反向映射[7 ] 是声音与发音器官的关联性研究中较深入的2类. 正向映射指由发音器官的发音特征转换出声学特征,反向映射是指由声学特征转换出发音特征. 深度学习已经在探索正向与反向映射的研究中被应用到不同的领域:Ling等[8 ] 通过隐马尔科夫模型(hidden Markov model, HMM)探究发音特征到声学特征的联合分布关系,将正向映射应用到语音合成研究中;Li等[9 ] 提取梅尔倒谱频率系数(Mel-frequency cepstrum cofficients, MFCC),通过高斯混合模型(Gaussian mixture model, GMM)探究声学到发音特征的关联性,将反向映射应用于说话人识别. 这些方法虽然在声学与发音特征转换中取得了不错的成绩,但都存在转换结果精度偏低的问题. Guo等[10 ] 提取相位特征并探索如何将相位特征应用于语音情感识别. 双向长短期记忆网络(bi-directional long short-term memory, BiLSTM)[11 ] 、卷积神经网络(convolutional neural network, CNN)[12 ] 、深度递归神经网络(recurrent neural network, RNN)[13 ] 和深层神经网络(deep neural network, DNN)[14 ] 等算法通过建立说话人与情感间的关联模型来完成情感识别任务,但特征与维度通道中所包含的情感信息未被充分利用. ...
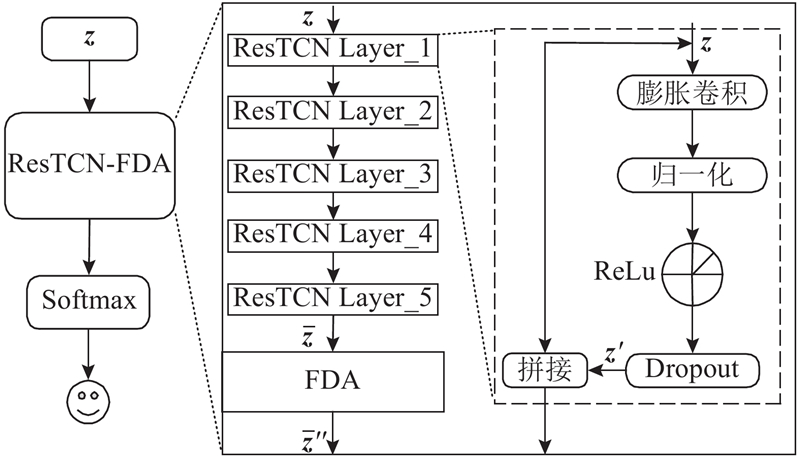
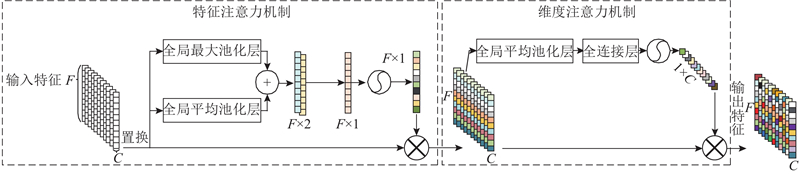
... 情感诱发下的不同特征以及不同维度通道携带的情感信息具有一定的差异性[9 ] . 在模型训练时,不同特征的不同维度通道分配的权重相同,将导致情感信息的不充分利用. 本研究将ResTCN与注意力机制相结合,提出融合FDA注意力机制的ResTCN情感识别网络,通过对ResTCN输出的特征进行加权调整,更好地利用声学与发音特征中与情感显著相关的特征和维度通道. ...
... 在情感识别中,多特征融合比单一特征的识别效果好[9 ] . 不同的特征对情感识别的反应能力不同,为了更好地提取多类特征中的情感信息,计算 $ \overline {\boldsymbol{z}} $ 图6 所示,将转置后的特征向量分别通过全局最大池化层和全局平均池化层,再将两者的输出进行拼接,并通过卷积层和Sigmoid层,最终得到特征注意力权重 $ {F_{\rm{f}}} \in {{\bf{R}}^{F \times 1}} $ . ...
Learning affective representations based on magnitude and dynamic relative phase information for speech emotion recognition
1
2022
... 在情感研究领域,根据被试者表达信息的多样性构建的适合不同研究方向的数据库有CHEAVD[2 ] 、NNIME[3 ] 和IEMOCAP[4 ] 等. 每个数据库都存在局限性,只有选择与研究方向契合的数据库,研究工作才能事半功倍. 在对人体发音机制的研究中,学者们发现声音和发音器官具有很强的关联性,即人体发出的部分声学信号是由发音器官独特的运动轨迹产生的[5 ] . 正向映射[6 ] 和反向映射[7 ] 是声音与发音器官的关联性研究中较深入的2类. 正向映射指由发音器官的发音特征转换出声学特征,反向映射是指由声学特征转换出发音特征. 深度学习已经在探索正向与反向映射的研究中被应用到不同的领域:Ling等[8 ] 通过隐马尔科夫模型(hidden Markov model, HMM)探究发音特征到声学特征的联合分布关系,将正向映射应用到语音合成研究中;Li等[9 ] 提取梅尔倒谱频率系数(Mel-frequency cepstrum cofficients, MFCC),通过高斯混合模型(Gaussian mixture model, GMM)探究声学到发音特征的关联性,将反向映射应用于说话人识别. 这些方法虽然在声学与发音特征转换中取得了不错的成绩,但都存在转换结果精度偏低的问题. Guo等[10 ] 提取相位特征并探索如何将相位特征应用于语音情感识别. 双向长短期记忆网络(bi-directional long short-term memory, BiLSTM)[11 ] 、卷积神经网络(convolutional neural network, CNN)[12 ] 、深度递归神经网络(recurrent neural network, RNN)[13 ] 和深层神经网络(deep neural network, DNN)[14 ] 等算法通过建立说话人与情感间的关联模型来完成情感识别任务,但特征与维度通道中所包含的情感信息未被充分利用. ...
A novel dual attention based BLSTM with hybrid features in speech emotion recognition
3
2021
... 在情感研究领域,根据被试者表达信息的多样性构建的适合不同研究方向的数据库有CHEAVD[2 ] 、NNIME[3 ] 和IEMOCAP[4 ] 等. 每个数据库都存在局限性,只有选择与研究方向契合的数据库,研究工作才能事半功倍. 在对人体发音机制的研究中,学者们发现声音和发音器官具有很强的关联性,即人体发出的部分声学信号是由发音器官独特的运动轨迹产生的[5 ] . 正向映射[6 ] 和反向映射[7 ] 是声音与发音器官的关联性研究中较深入的2类. 正向映射指由发音器官的发音特征转换出声学特征,反向映射是指由声学特征转换出发音特征. 深度学习已经在探索正向与反向映射的研究中被应用到不同的领域:Ling等[8 ] 通过隐马尔科夫模型(hidden Markov model, HMM)探究发音特征到声学特征的联合分布关系,将正向映射应用到语音合成研究中;Li等[9 ] 提取梅尔倒谱频率系数(Mel-frequency cepstrum cofficients, MFCC),通过高斯混合模型(Gaussian mixture model, GMM)探究声学到发音特征的关联性,将反向映射应用于说话人识别. 这些方法虽然在声学与发音特征转换中取得了不错的成绩,但都存在转换结果精度偏低的问题. Guo等[10 ] 提取相位特征并探索如何将相位特征应用于语音情感识别. 双向长短期记忆网络(bi-directional long short-term memory, BiLSTM)[11 ] 、卷积神经网络(convolutional neural network, CNN)[12 ] 、深度递归神经网络(recurrent neural network, RNN)[13 ] 和深层神经网络(deep neural network, DNN)[14 ] 等算法通过建立说话人与情感间的关联模型来完成情感识别任务,但特征与维度通道中所包含的情感信息未被充分利用. ...
... 为了验证所提转换网络算法有效性,将Bi-MGAN与传统的DNN[14 ] 和BiLSTM[11 ] 以及深度递归混合密度网路(deep recurrent mixture density network, DRMDN)[23 ] 和粒子群优化算法的最小二乘支持向量机(particle swarm optimization algorithm of least squares support vector machines, PSO-LSSVM)[6 ] 进行对比. 如表3 所示,Bi-MGAN较传统的DNN和BiLSTM的MAE和RMSE大幅提升,较PSO-LSSVM的MAE和RMSE分别提升0.466~0.482 mm和0.344~0.453 mm,较DRMDN的MAE和RMSE分别提升0.181~0.330 mm和0.040~0.256 mm. 对比结果表明,Bi-MGAN可以大幅度提升网络的转换精度,在参加对比的网络中取得最佳的正向映射效果与反向映射效果,证明了Bi-MGAN的有效性. ...
... Comparison of mapping performance for conversion networks algorithm
mm Tab.3 算法 正向映射 反向映射 MAE RMSE MAE RMSE DNN[14 ] 1.479 1.613 1.143 1.259 BiLSTM[11 ] 1.298 1.422 1.003 1.217 PSO-LSSVM[6 ] 1.185 1.252 0.967 1.136 DRMDN[23 ] 0.884 0.948 0.831 0.939 Bi-MGAN 0.703 0.908 0.501 0.683
4.3. 情感识别网络的性能对比 为了探究FDA在情感识别中的作用,分别提取STEM-E2 VA、CASIA、RADVESS和EMO-DB数据库的60维MFCC作为识别网络的输入,进行ResTCN-FDA的消融实验. 其中CASIA为6分类数据库,STEM-E2 VA和EMO-DB为7分类数据库,RADVESS为8分类数据库. 如表4 所示,将ResTCN-FA、ResTCN-DA与ResTCN对比可以发现,特征注意力机制对准确率提升量为1.52%~5.32%,维度注意力机制对准确率提升量为1.50%~4.54%,证明给不同特征和不同通道维度分配不同的权重参数有利于提升情感识别准确率. 将ResTCN-FDA对比TCN、ResTCN、ResTCN-FA和ResTCN-DA,准确率分别提升量为7.48%~10.92%、4.14%~8.16%、2.00%~4.16%和2.48%~6.66%. 另外,ResTCN-FDA的F1和AUC也比其他算法的有一定程度的提升,这说明ResTCN-FDA可以更好的处理情感信息. ...
结合3D-CNN和频-空注意力机制的EEG情感识别
6
2022
... 在情感研究领域,根据被试者表达信息的多样性构建的适合不同研究方向的数据库有CHEAVD[2 ] 、NNIME[3 ] 和IEMOCAP[4 ] 等. 每个数据库都存在局限性,只有选择与研究方向契合的数据库,研究工作才能事半功倍. 在对人体发音机制的研究中,学者们发现声音和发音器官具有很强的关联性,即人体发出的部分声学信号是由发音器官独特的运动轨迹产生的[5 ] . 正向映射[6 ] 和反向映射[7 ] 是声音与发音器官的关联性研究中较深入的2类. 正向映射指由发音器官的发音特征转换出声学特征,反向映射是指由声学特征转换出发音特征. 深度学习已经在探索正向与反向映射的研究中被应用到不同的领域:Ling等[8 ] 通过隐马尔科夫模型(hidden Markov model, HMM)探究发音特征到声学特征的联合分布关系,将正向映射应用到语音合成研究中;Li等[9 ] 提取梅尔倒谱频率系数(Mel-frequency cepstrum cofficients, MFCC),通过高斯混合模型(Gaussian mixture model, GMM)探究声学到发音特征的关联性,将反向映射应用于说话人识别. 这些方法虽然在声学与发音特征转换中取得了不错的成绩,但都存在转换结果精度偏低的问题. Guo等[10 ] 提取相位特征并探索如何将相位特征应用于语音情感识别. 双向长短期记忆网络(bi-directional long short-term memory, BiLSTM)[11 ] 、卷积神经网络(convolutional neural network, CNN)[12 ] 、深度递归神经网络(recurrent neural network, RNN)[13 ] 和深层神经网络(deep neural network, DNN)[14 ] 等算法通过建立说话人与情感间的关联模型来完成情感识别任务,但特征与维度通道中所包含的情感信息未被充分利用. ...
... 针对卷积层在处理序列特征时,维度通道分配相同权重系数导致情感信息的不充分利用问题[12 ] ,本研究提出维度通道注意力机制. 如图6 所示,对 $ {\overline {\boldsymbol{z}} '} $ $ {F_{{\text{avc}}}} $ $ {\overline {\boldsymbol{z}} '} $
... Comparison of emotion evaluation metrics for emotion recognition networks algorithm
% Tab.5 数据库 算法 ACC F1 AUC CASIA CNN[12 ] 63.00 62.43 63.19 HS-TCN[24 ] 76.25 76.64 76.91 DRN[25 ] 76.91 76.67 76.94 ResTCN-FDA 80.41 81.22 81.43 STEM-E2 VA CNN[12 ] 56.77 56.84 57.77 HS-TCN[24 ] 72.81 72.59 72.92 DRN[25 ] 68.15 68.25 68.86 ResTCN-FDA 75.63 75.44 76.82 EMO-DB CNN[12 ] 69.72 69.09 69.86 HS-TCN[24 ] 74.76 73.60 75.51 DRN[25 ] 76.64 74.72 76.96 ResTCN-FDA 80.16 80.78 81.58 RADVESS CNN[12 ] 57.29 55.67 57.85 HS-TCN[24 ] 63.29 63.56 63.58 DRN[25 ] 63.46 61.88 63.90 ResTCN-FDA 66.55 65.57 66.86
4.4. 声学与发音特征转换对情感识别的影响 为了探究声学和发音特征转换对情感识别的影响,提取STEM-E2 VA的声学特征和发音特征,利用Bi-MGAN完成映射特征的生成,以ResTCN-FDA为识别网络,通过给识别网络输入不同的特征集来探索声学与发音特征转换对情感识别的影响. 另外,提取预训练特征[26 -27 ] 来对比声学与发音特征的情感识别性能. ...
... [
12 ]
56.77 56.84 57.77 HS-TCN[24 ] 72.81 72.59 72.92 DRN[25 ] 68.15 68.25 68.86 ResTCN-FDA 75.63 75.44 76.82 EMO-DB CNN[12 ] 69.72 69.09 69.86 HS-TCN[24 ] 74.76 73.60 75.51 DRN[25 ] 76.64 74.72 76.96 ResTCN-FDA 80.16 80.78 81.58 RADVESS CNN[12 ] 57.29 55.67 57.85 HS-TCN[24 ] 63.29 63.56 63.58 DRN[25 ] 63.46 61.88 63.90 ResTCN-FDA 66.55 65.57 66.86 4.4. 声学与发音特征转换对情感识别的影响 为了探究声学和发音特征转换对情感识别的影响,提取STEM-E2 VA的声学特征和发音特征,利用Bi-MGAN完成映射特征的生成,以ResTCN-FDA为识别网络,通过给识别网络输入不同的特征集来探索声学与发音特征转换对情感识别的影响. 另外,提取预训练特征[26 -27 ] 来对比声学与发音特征的情感识别性能. ...
... [
12 ]
69.72 69.09 69.86 HS-TCN[24 ] 74.76 73.60 75.51 DRN[25 ] 76.64 74.72 76.96 ResTCN-FDA 80.16 80.78 81.58 RADVESS CNN[12 ] 57.29 55.67 57.85 HS-TCN[24 ] 63.29 63.56 63.58 DRN[25 ] 63.46 61.88 63.90 ResTCN-FDA 66.55 65.57 66.86 4.4. 声学与发音特征转换对情感识别的影响 为了探究声学和发音特征转换对情感识别的影响,提取STEM-E2 VA的声学特征和发音特征,利用Bi-MGAN完成映射特征的生成,以ResTCN-FDA为识别网络,通过给识别网络输入不同的特征集来探索声学与发音特征转换对情感识别的影响. 另外,提取预训练特征[26 -27 ] 来对比声学与发音特征的情感识别性能. ...
... [
12 ]
57.29 55.67 57.85 HS-TCN[24 ] 63.29 63.56 63.58 DRN[25 ] 63.46 61.88 63.90 ResTCN-FDA 66.55 65.57 66.86 4.4. 声学与发音特征转换对情感识别的影响 为了探究声学和发音特征转换对情感识别的影响,提取STEM-E2 VA的声学特征和发音特征,利用Bi-MGAN完成映射特征的生成,以ResTCN-FDA为识别网络,通过给识别网络输入不同的特征集来探索声学与发音特征转换对情感识别的影响. 另外,提取预训练特征[26 -27 ] 来对比声学与发音特征的情感识别性能. ...
结合3D-CNN和频-空注意力机制的EEG情感识别
6
2022
... 在情感研究领域,根据被试者表达信息的多样性构建的适合不同研究方向的数据库有CHEAVD[2 ] 、NNIME[3 ] 和IEMOCAP[4 ] 等. 每个数据库都存在局限性,只有选择与研究方向契合的数据库,研究工作才能事半功倍. 在对人体发音机制的研究中,学者们发现声音和发音器官具有很强的关联性,即人体发出的部分声学信号是由发音器官独特的运动轨迹产生的[5 ] . 正向映射[6 ] 和反向映射[7 ] 是声音与发音器官的关联性研究中较深入的2类. 正向映射指由发音器官的发音特征转换出声学特征,反向映射是指由声学特征转换出发音特征. 深度学习已经在探索正向与反向映射的研究中被应用到不同的领域:Ling等[8 ] 通过隐马尔科夫模型(hidden Markov model, HMM)探究发音特征到声学特征的联合分布关系,将正向映射应用到语音合成研究中;Li等[9 ] 提取梅尔倒谱频率系数(Mel-frequency cepstrum cofficients, MFCC),通过高斯混合模型(Gaussian mixture model, GMM)探究声学到发音特征的关联性,将反向映射应用于说话人识别. 这些方法虽然在声学与发音特征转换中取得了不错的成绩,但都存在转换结果精度偏低的问题. Guo等[10 ] 提取相位特征并探索如何将相位特征应用于语音情感识别. 双向长短期记忆网络(bi-directional long short-term memory, BiLSTM)[11 ] 、卷积神经网络(convolutional neural network, CNN)[12 ] 、深度递归神经网络(recurrent neural network, RNN)[13 ] 和深层神经网络(deep neural network, DNN)[14 ] 等算法通过建立说话人与情感间的关联模型来完成情感识别任务,但特征与维度通道中所包含的情感信息未被充分利用. ...
... 针对卷积层在处理序列特征时,维度通道分配相同权重系数导致情感信息的不充分利用问题[12 ] ,本研究提出维度通道注意力机制. 如图6 所示,对 $ {\overline {\boldsymbol{z}} '} $ $ {F_{{\text{avc}}}} $ $ {\overline {\boldsymbol{z}} '} $
... Comparison of emotion evaluation metrics for emotion recognition networks algorithm
% Tab.5 数据库 算法 ACC F1 AUC CASIA CNN[12 ] 63.00 62.43 63.19 HS-TCN[24 ] 76.25 76.64 76.91 DRN[25 ] 76.91 76.67 76.94 ResTCN-FDA 80.41 81.22 81.43 STEM-E2 VA CNN[12 ] 56.77 56.84 57.77 HS-TCN[24 ] 72.81 72.59 72.92 DRN[25 ] 68.15 68.25 68.86 ResTCN-FDA 75.63 75.44 76.82 EMO-DB CNN[12 ] 69.72 69.09 69.86 HS-TCN[24 ] 74.76 73.60 75.51 DRN[25 ] 76.64 74.72 76.96 ResTCN-FDA 80.16 80.78 81.58 RADVESS CNN[12 ] 57.29 55.67 57.85 HS-TCN[24 ] 63.29 63.56 63.58 DRN[25 ] 63.46 61.88 63.90 ResTCN-FDA 66.55 65.57 66.86
4.4. 声学与发音特征转换对情感识别的影响 为了探究声学和发音特征转换对情感识别的影响,提取STEM-E2 VA的声学特征和发音特征,利用Bi-MGAN完成映射特征的生成,以ResTCN-FDA为识别网络,通过给识别网络输入不同的特征集来探索声学与发音特征转换对情感识别的影响. 另外,提取预训练特征[26 -27 ] 来对比声学与发音特征的情感识别性能. ...
... [
12 ]
56.77 56.84 57.77 HS-TCN[24 ] 72.81 72.59 72.92 DRN[25 ] 68.15 68.25 68.86 ResTCN-FDA 75.63 75.44 76.82 EMO-DB CNN[12 ] 69.72 69.09 69.86 HS-TCN[24 ] 74.76 73.60 75.51 DRN[25 ] 76.64 74.72 76.96 ResTCN-FDA 80.16 80.78 81.58 RADVESS CNN[12 ] 57.29 55.67 57.85 HS-TCN[24 ] 63.29 63.56 63.58 DRN[25 ] 63.46 61.88 63.90 ResTCN-FDA 66.55 65.57 66.86 4.4. 声学与发音特征转换对情感识别的影响 为了探究声学和发音特征转换对情感识别的影响,提取STEM-E2 VA的声学特征和发音特征,利用Bi-MGAN完成映射特征的生成,以ResTCN-FDA为识别网络,通过给识别网络输入不同的特征集来探索声学与发音特征转换对情感识别的影响. 另外,提取预训练特征[26 -27 ] 来对比声学与发音特征的情感识别性能. ...
... [
12 ]
69.72 69.09 69.86 HS-TCN[24 ] 74.76 73.60 75.51 DRN[25 ] 76.64 74.72 76.96 ResTCN-FDA 80.16 80.78 81.58 RADVESS CNN[12 ] 57.29 55.67 57.85 HS-TCN[24 ] 63.29 63.56 63.58 DRN[25 ] 63.46 61.88 63.90 ResTCN-FDA 66.55 65.57 66.86 4.4. 声学与发音特征转换对情感识别的影响 为了探究声学和发音特征转换对情感识别的影响,提取STEM-E2 VA的声学特征和发音特征,利用Bi-MGAN完成映射特征的生成,以ResTCN-FDA为识别网络,通过给识别网络输入不同的特征集来探索声学与发音特征转换对情感识别的影响. 另外,提取预训练特征[26 -27 ] 来对比声学与发音特征的情感识别性能. ...
... [
12 ]
57.29 55.67 57.85 HS-TCN[24 ] 63.29 63.56 63.58 DRN[25 ] 63.46 61.88 63.90 ResTCN-FDA 66.55 65.57 66.86 4.4. 声学与发音特征转换对情感识别的影响 为了探究声学和发音特征转换对情感识别的影响,提取STEM-E2 VA的声学特征和发音特征,利用Bi-MGAN完成映射特征的生成,以ResTCN-FDA为识别网络,通过给识别网络输入不同的特征集来探索声学与发音特征转换对情感识别的影响. 另外,提取预训练特征[26 -27 ] 来对比声学与发音特征的情感识别性能. ...
Fusion of mel and gammatone frequency cepstral coefficients for speech emotion recognition using deep C-RNN
2
2021
... 在情感研究领域,根据被试者表达信息的多样性构建的适合不同研究方向的数据库有CHEAVD[2 ] 、NNIME[3 ] 和IEMOCAP[4 ] 等. 每个数据库都存在局限性,只有选择与研究方向契合的数据库,研究工作才能事半功倍. 在对人体发音机制的研究中,学者们发现声音和发音器官具有很强的关联性,即人体发出的部分声学信号是由发音器官独特的运动轨迹产生的[5 ] . 正向映射[6 ] 和反向映射[7 ] 是声音与发音器官的关联性研究中较深入的2类. 正向映射指由发音器官的发音特征转换出声学特征,反向映射是指由声学特征转换出发音特征. 深度学习已经在探索正向与反向映射的研究中被应用到不同的领域:Ling等[8 ] 通过隐马尔科夫模型(hidden Markov model, HMM)探究发音特征到声学特征的联合分布关系,将正向映射应用到语音合成研究中;Li等[9 ] 提取梅尔倒谱频率系数(Mel-frequency cepstrum cofficients, MFCC),通过高斯混合模型(Gaussian mixture model, GMM)探究声学到发音特征的关联性,将反向映射应用于说话人识别. 这些方法虽然在声学与发音特征转换中取得了不错的成绩,但都存在转换结果精度偏低的问题. Guo等[10 ] 提取相位特征并探索如何将相位特征应用于语音情感识别. 双向长短期记忆网络(bi-directional long short-term memory, BiLSTM)[11 ] 、卷积神经网络(convolutional neural network, CNN)[12 ] 、深度递归神经网络(recurrent neural network, RNN)[13 ] 和深层神经网络(deep neural network, DNN)[14 ] 等算法通过建立说话人与情感间的关联模型来完成情感识别任务,但特征与维度通道中所包含的情感信息未被充分利用. ...
... 从声学和发音学数据中分别提取MFCC和发音特征. MFCC特征能够模拟人耳对语音的处理, Kumaran等[13 ] 发现MFCC特征转换出的发音特征具有良好的映射性能. 本研究选用MFCC作为声学特征,定义MFCC特征集为 ...
A review on speech emotion recognition using deep learning and attention mechanism
3
2021
... 在情感研究领域,根据被试者表达信息的多样性构建的适合不同研究方向的数据库有CHEAVD[2 ] 、NNIME[3 ] 和IEMOCAP[4 ] 等. 每个数据库都存在局限性,只有选择与研究方向契合的数据库,研究工作才能事半功倍. 在对人体发音机制的研究中,学者们发现声音和发音器官具有很强的关联性,即人体发出的部分声学信号是由发音器官独特的运动轨迹产生的[5 ] . 正向映射[6 ] 和反向映射[7 ] 是声音与发音器官的关联性研究中较深入的2类. 正向映射指由发音器官的发音特征转换出声学特征,反向映射是指由声学特征转换出发音特征. 深度学习已经在探索正向与反向映射的研究中被应用到不同的领域:Ling等[8 ] 通过隐马尔科夫模型(hidden Markov model, HMM)探究发音特征到声学特征的联合分布关系,将正向映射应用到语音合成研究中;Li等[9 ] 提取梅尔倒谱频率系数(Mel-frequency cepstrum cofficients, MFCC),通过高斯混合模型(Gaussian mixture model, GMM)探究声学到发音特征的关联性,将反向映射应用于说话人识别. 这些方法虽然在声学与发音特征转换中取得了不错的成绩,但都存在转换结果精度偏低的问题. Guo等[10 ] 提取相位特征并探索如何将相位特征应用于语音情感识别. 双向长短期记忆网络(bi-directional long short-term memory, BiLSTM)[11 ] 、卷积神经网络(convolutional neural network, CNN)[12 ] 、深度递归神经网络(recurrent neural network, RNN)[13 ] 和深层神经网络(deep neural network, DNN)[14 ] 等算法通过建立说话人与情感间的关联模型来完成情感识别任务,但特征与维度通道中所包含的情感信息未被充分利用. ...
... 为了验证所提转换网络算法有效性,将Bi-MGAN与传统的DNN[14 ] 和BiLSTM[11 ] 以及深度递归混合密度网路(deep recurrent mixture density network, DRMDN)[23 ] 和粒子群优化算法的最小二乘支持向量机(particle swarm optimization algorithm of least squares support vector machines, PSO-LSSVM)[6 ] 进行对比. 如表3 所示,Bi-MGAN较传统的DNN和BiLSTM的MAE和RMSE大幅提升,较PSO-LSSVM的MAE和RMSE分别提升0.466~0.482 mm和0.344~0.453 mm,较DRMDN的MAE和RMSE分别提升0.181~0.330 mm和0.040~0.256 mm. 对比结果表明,Bi-MGAN可以大幅度提升网络的转换精度,在参加对比的网络中取得最佳的正向映射效果与反向映射效果,证明了Bi-MGAN的有效性. ...
... Comparison of mapping performance for conversion networks algorithm
mm Tab.3 算法 正向映射 反向映射 MAE RMSE MAE RMSE DNN[14 ] 1.479 1.613 1.143 1.259 BiLSTM[11 ] 1.298 1.422 1.003 1.217 PSO-LSSVM[6 ] 1.185 1.252 0.967 1.136 DRMDN[23 ] 0.884 0.948 0.831 0.939 Bi-MGAN 0.703 0.908 0.501 0.683
4.3. 情感识别网络的性能对比 为了探究FDA在情感识别中的作用,分别提取STEM-E2 VA、CASIA、RADVESS和EMO-DB数据库的60维MFCC作为识别网络的输入,进行ResTCN-FDA的消融实验. 其中CASIA为6分类数据库,STEM-E2 VA和EMO-DB为7分类数据库,RADVESS为8分类数据库. 如表4 所示,将ResTCN-FA、ResTCN-DA与ResTCN对比可以发现,特征注意力机制对准确率提升量为1.52%~5.32%,维度注意力机制对准确率提升量为1.50%~4.54%,证明给不同特征和不同通道维度分配不同的权重参数有利于提升情感识别准确率. 将ResTCN-FDA对比TCN、ResTCN、ResTCN-FA和ResTCN-DA,准确率分别提升量为7.48%~10.92%、4.14%~8.16%、2.00%~4.16%和2.48%~6.66%. 另外,ResTCN-FDA的F1和AUC也比其他算法的有一定程度的提升,这说明ResTCN-FDA可以更好的处理情感信息. ...
1
... 在设计之初,循环生成对抗网络(cycle generative adversarial network, CycleGAN)通过学习样本空间X 与Y 的转换关系来解决图像风格转换问题[15 ] . CycleGAN已被应用到不匹配数据的语音增强[16 ] 和情感识别[17 ] 领域. CycleGAN包含2个生成器( $ {G_{X \to Y}} $ $ {G_{Y \to X}} $ ) 和2个判别器( $ {D_X} $ $ {D_Y} $ ) ,生成器对 $ X $ $ Y $ $ {G_{X \to Y}} $ $ {D_Y} $
1
... 在设计之初,循环生成对抗网络(cycle generative adversarial network, CycleGAN)通过学习样本空间X 与Y 的转换关系来解决图像风格转换问题[15 ] . CycleGAN已被应用到不匹配数据的语音增强[16 ] 和情感识别[17 ] 领域. CycleGAN包含2个生成器( $ {G_{X \to Y}} $ $ {G_{Y \to X}} $ ) 和2个判别器( $ {D_X} $ $ {D_Y} $ ) ,生成器对 $ X $ $ Y $ $ {G_{X \to Y}} $ $ {D_Y} $
Unsupervised cross-corpus speech emotion recognition using a multi-source CycleGAN
1
2022
... 在设计之初,循环生成对抗网络(cycle generative adversarial network, CycleGAN)通过学习样本空间X 与Y 的转换关系来解决图像风格转换问题[15 ] . CycleGAN已被应用到不匹配数据的语音增强[16 ] 和情感识别[17 ] 领域. CycleGAN包含2个生成器( $ {G_{X \to Y}} $ $ {G_{Y \to X}} $ ) 和2个判别器( $ {D_X} $ $ {D_Y} $ ) ,生成器对 $ X $ $ Y $ $ {G_{X \to Y}} $ $ {D_Y} $
Speech enhancement using multi-stage self-attentive temporal convolutional networks
5
2021
... 时间卷积网络(TCN)可以并行处理特征序列, 为了提升TCN的建模能力, Lin等[18 ] 将自注意力机制与TCN结合,提出多级SA-TCN网络;Pandey等[19 ] 提出TCNN模型,用于探索时域中的实时语音增强;Zhang等[20 ] 改良TCN,并将改良TCN用于声道的语音分离. ResTCN利用TCN来快速并行处理特征序列,并通过残差连接使模型在训练过程中产生稳定的梯度优化路径. 其中残差连接式为 ...
... Ablation experiment of emotion recognition networks algorithm
% Tab.4 数据库 算法 ACC F1 AUC CASIA TCN[20 ] 70.69 69.18 70.79 ResTCN[18 ] 72.25 72.16 72.67 ResTCN-FA 76.25 76.56 76.96 ResTCN-DA 73.75 73.71 73.97 ResTCN-FDA 80.41 81.22 81.43 STEM-E2 VA TCN[20 ] 64.71 64.52 66.69 ResTCN[18 ] 68.31 67.68 71.14 ResTCN-FA 73.63 73.78 74.83 ResTCN-DA 72.85 72.61 73.36 ResTCN-FDA 75.63 75.44 76.82 EMO-DB TCN[20 ] 71.26 68.67 71.71 ResTCN[18 ] 73.71 74.28 74.83 ResTCN-FA 76.22 76.62 76.94 ResTCN-DA 77.29 75.81 77.91 ResTCN-FDA 80.16 80.78 81.58 RADVESS TCN[20 ] 59.07 59.02 59.66 ResTCN[18 ] 62.41 61.15 61.77 ResTCN-FA 63.93 62.40 63.98 ResTCN-DA 64.07 63.82 64.90 ResTCN-FDA 66.55 65.57 66.86
为了进一步验证所提识别网络的有效性,以MFCC为输入特征,将ResTCN-FDA分别与传统的CNN,以及HS-TCN[24 ] 和DRN[25 ] 进行比较. 如表5 所示,ResTCN-FDA在CASIA、STEM-E2 VA、EMO-DB和RADVESS数据库上准确率分别达到80.41%、75.63%、80.16%和66.55%,与CNN、HS-TCN和DRN相比性能有明显提升. 此外,ResTCN-FDA与HS-TCN和DRN相比,F1分别取得2.01%~7.85%和3.69%~7.19%的提升量,AUC分别取得3.28%~6.07%和2.96%~7.96%的提升量,证明ResTCN-FDA在情感识别中的有效性. ...
... [
18 ]
68.31 67.68 71.14 ResTCN-FA 73.63 73.78 74.83 ResTCN-DA 72.85 72.61 73.36 ResTCN-FDA 75.63 75.44 76.82 EMO-DB TCN[20 ] 71.26 68.67 71.71 ResTCN[18 ] 73.71 74.28 74.83 ResTCN-FA 76.22 76.62 76.94 ResTCN-DA 77.29 75.81 77.91 ResTCN-FDA 80.16 80.78 81.58 RADVESS TCN[20 ] 59.07 59.02 59.66 ResTCN[18 ] 62.41 61.15 61.77 ResTCN-FA 63.93 62.40 63.98 ResTCN-DA 64.07 63.82 64.90 ResTCN-FDA 66.55 65.57 66.86 为了进一步验证所提识别网络的有效性,以MFCC为输入特征,将ResTCN-FDA分别与传统的CNN,以及HS-TCN[24 ] 和DRN[25 ] 进行比较. 如表5 所示,ResTCN-FDA在CASIA、STEM-E2 VA、EMO-DB和RADVESS数据库上准确率分别达到80.41%、75.63%、80.16%和66.55%,与CNN、HS-TCN和DRN相比性能有明显提升. 此外,ResTCN-FDA与HS-TCN和DRN相比,F1分别取得2.01%~7.85%和3.69%~7.19%的提升量,AUC分别取得3.28%~6.07%和2.96%~7.96%的提升量,证明ResTCN-FDA在情感识别中的有效性. ...
... [
18 ]
73.71 74.28 74.83 ResTCN-FA 76.22 76.62 76.94 ResTCN-DA 77.29 75.81 77.91 ResTCN-FDA 80.16 80.78 81.58 RADVESS TCN[20 ] 59.07 59.02 59.66 ResTCN[18 ] 62.41 61.15 61.77 ResTCN-FA 63.93 62.40 63.98 ResTCN-DA 64.07 63.82 64.90 ResTCN-FDA 66.55 65.57 66.86 为了进一步验证所提识别网络的有效性,以MFCC为输入特征,将ResTCN-FDA分别与传统的CNN,以及HS-TCN[24 ] 和DRN[25 ] 进行比较. 如表5 所示,ResTCN-FDA在CASIA、STEM-E2 VA、EMO-DB和RADVESS数据库上准确率分别达到80.41%、75.63%、80.16%和66.55%,与CNN、HS-TCN和DRN相比性能有明显提升. 此外,ResTCN-FDA与HS-TCN和DRN相比,F1分别取得2.01%~7.85%和3.69%~7.19%的提升量,AUC分别取得3.28%~6.07%和2.96%~7.96%的提升量,证明ResTCN-FDA在情感识别中的有效性. ...
... [
18 ]
62.41 61.15 61.77 ResTCN-FA 63.93 62.40 63.98 ResTCN-DA 64.07 63.82 64.90 ResTCN-FDA 66.55 65.57 66.86 为了进一步验证所提识别网络的有效性,以MFCC为输入特征,将ResTCN-FDA分别与传统的CNN,以及HS-TCN[24 ] 和DRN[25 ] 进行比较. 如表5 所示,ResTCN-FDA在CASIA、STEM-E2 VA、EMO-DB和RADVESS数据库上准确率分别达到80.41%、75.63%、80.16%和66.55%,与CNN、HS-TCN和DRN相比性能有明显提升. 此外,ResTCN-FDA与HS-TCN和DRN相比,F1分别取得2.01%~7.85%和3.69%~7.19%的提升量,AUC分别取得3.28%~6.07%和2.96%~7.96%的提升量,证明ResTCN-FDA在情感识别中的有效性. ...
1
... 时间卷积网络(TCN)可以并行处理特征序列, 为了提升TCN的建模能力, Lin等[18 ] 将自注意力机制与TCN结合,提出多级SA-TCN网络;Pandey等[19 ] 提出TCNN模型,用于探索时域中的实时语音增强;Zhang等[20 ] 改良TCN,并将改良TCN用于声道的语音分离. ResTCN利用TCN来快速并行处理特征序列,并通过残差连接使模型在训练过程中产生稳定的梯度优化路径. 其中残差连接式为 ...
5
... 时间卷积网络(TCN)可以并行处理特征序列, 为了提升TCN的建模能力, Lin等[18 ] 将自注意力机制与TCN结合,提出多级SA-TCN网络;Pandey等[19 ] 提出TCNN模型,用于探索时域中的实时语音增强;Zhang等[20 ] 改良TCN,并将改良TCN用于声道的语音分离. ResTCN利用TCN来快速并行处理特征序列,并通过残差连接使模型在训练过程中产生稳定的梯度优化路径. 其中残差连接式为 ...
... Ablation experiment of emotion recognition networks algorithm
% Tab.4 数据库 算法 ACC F1 AUC CASIA TCN[20 ] 70.69 69.18 70.79 ResTCN[18 ] 72.25 72.16 72.67 ResTCN-FA 76.25 76.56 76.96 ResTCN-DA 73.75 73.71 73.97 ResTCN-FDA 80.41 81.22 81.43 STEM-E2 VA TCN[20 ] 64.71 64.52 66.69 ResTCN[18 ] 68.31 67.68 71.14 ResTCN-FA 73.63 73.78 74.83 ResTCN-DA 72.85 72.61 73.36 ResTCN-FDA 75.63 75.44 76.82 EMO-DB TCN[20 ] 71.26 68.67 71.71 ResTCN[18 ] 73.71 74.28 74.83 ResTCN-FA 76.22 76.62 76.94 ResTCN-DA 77.29 75.81 77.91 ResTCN-FDA 80.16 80.78 81.58 RADVESS TCN[20 ] 59.07 59.02 59.66 ResTCN[18 ] 62.41 61.15 61.77 ResTCN-FA 63.93 62.40 63.98 ResTCN-DA 64.07 63.82 64.90 ResTCN-FDA 66.55 65.57 66.86
为了进一步验证所提识别网络的有效性,以MFCC为输入特征,将ResTCN-FDA分别与传统的CNN,以及HS-TCN[24 ] 和DRN[25 ] 进行比较. 如表5 所示,ResTCN-FDA在CASIA、STEM-E2 VA、EMO-DB和RADVESS数据库上准确率分别达到80.41%、75.63%、80.16%和66.55%,与CNN、HS-TCN和DRN相比性能有明显提升. 此外,ResTCN-FDA与HS-TCN和DRN相比,F1分别取得2.01%~7.85%和3.69%~7.19%的提升量,AUC分别取得3.28%~6.07%和2.96%~7.96%的提升量,证明ResTCN-FDA在情感识别中的有效性. ...
... [
20 ]
64.71 64.52 66.69 ResTCN[18 ] 68.31 67.68 71.14 ResTCN-FA 73.63 73.78 74.83 ResTCN-DA 72.85 72.61 73.36 ResTCN-FDA 75.63 75.44 76.82 EMO-DB TCN[20 ] 71.26 68.67 71.71 ResTCN[18 ] 73.71 74.28 74.83 ResTCN-FA 76.22 76.62 76.94 ResTCN-DA 77.29 75.81 77.91 ResTCN-FDA 80.16 80.78 81.58 RADVESS TCN[20 ] 59.07 59.02 59.66 ResTCN[18 ] 62.41 61.15 61.77 ResTCN-FA 63.93 62.40 63.98 ResTCN-DA 64.07 63.82 64.90 ResTCN-FDA 66.55 65.57 66.86 为了进一步验证所提识别网络的有效性,以MFCC为输入特征,将ResTCN-FDA分别与传统的CNN,以及HS-TCN[24 ] 和DRN[25 ] 进行比较. 如表5 所示,ResTCN-FDA在CASIA、STEM-E2 VA、EMO-DB和RADVESS数据库上准确率分别达到80.41%、75.63%、80.16%和66.55%,与CNN、HS-TCN和DRN相比性能有明显提升. 此外,ResTCN-FDA与HS-TCN和DRN相比,F1分别取得2.01%~7.85%和3.69%~7.19%的提升量,AUC分别取得3.28%~6.07%和2.96%~7.96%的提升量,证明ResTCN-FDA在情感识别中的有效性. ...
... [
20 ]
71.26 68.67 71.71 ResTCN[18 ] 73.71 74.28 74.83 ResTCN-FA 76.22 76.62 76.94 ResTCN-DA 77.29 75.81 77.91 ResTCN-FDA 80.16 80.78 81.58 RADVESS TCN[20 ] 59.07 59.02 59.66 ResTCN[18 ] 62.41 61.15 61.77 ResTCN-FA 63.93 62.40 63.98 ResTCN-DA 64.07 63.82 64.90 ResTCN-FDA 66.55 65.57 66.86 为了进一步验证所提识别网络的有效性,以MFCC为输入特征,将ResTCN-FDA分别与传统的CNN,以及HS-TCN[24 ] 和DRN[25 ] 进行比较. 如表5 所示,ResTCN-FDA在CASIA、STEM-E2 VA、EMO-DB和RADVESS数据库上准确率分别达到80.41%、75.63%、80.16%和66.55%,与CNN、HS-TCN和DRN相比性能有明显提升. 此外,ResTCN-FDA与HS-TCN和DRN相比,F1分别取得2.01%~7.85%和3.69%~7.19%的提升量,AUC分别取得3.28%~6.07%和2.96%~7.96%的提升量,证明ResTCN-FDA在情感识别中的有效性. ...
... [
20 ]
59.07 59.02 59.66 ResTCN[18 ] 62.41 61.15 61.77 ResTCN-FA 63.93 62.40 63.98 ResTCN-DA 64.07 63.82 64.90 ResTCN-FDA 66.55 65.57 66.86 为了进一步验证所提识别网络的有效性,以MFCC为输入特征,将ResTCN-FDA分别与传统的CNN,以及HS-TCN[24 ] 和DRN[25 ] 进行比较. 如表5 所示,ResTCN-FDA在CASIA、STEM-E2 VA、EMO-DB和RADVESS数据库上准确率分别达到80.41%、75.63%、80.16%和66.55%,与CNN、HS-TCN和DRN相比性能有明显提升. 此外,ResTCN-FDA与HS-TCN和DRN相比,F1分别取得2.01%~7.85%和3.69%~7.19%的提升量,AUC分别取得3.28%~6.07%和2.96%~7.96%的提升量,证明ResTCN-FDA在情感识别中的有效性. ...
Noise interference reduction in vision module of intelligent plant cultivation robot using better Cycle GAN
3
2022
... 转换网络的目的是利用真实特征生成高精度的映射特征,进而探究映射特征对语音情感识别的影响. CycleGAN应用在图像风格转换任务时不要求成对的训练数据[21 ] ,这与声学与发音特征转换任务不同. 人体多数语音都是依靠独特的声道形状产生[5 ] ,这就要求声学与发音学数据的并行性. 为了增强转换模型的映射能力,本研究对CycleGAN的网络结构和损失函数进行优化改进,提出适用于声学与发音特征转换任务的Bi-MGAN,如图4 所示. 图4 (a)中Bi-MGAN将真实发音特征 $ x $ $ \widehat y $ $ \widehat y $ $ \widetilde x $ $ x $ $ \widehat y $ $ y $ $ \widehat y $ $ \widehat y $ $ \widetilde x $ $ x $ $ \widetilde x $ 图4 (b)中Bi-MGAN将真实声学特征 $ y $ $ \widehat x $ $ \widehat x $ $ \widetilde y $ . ...
... 为了验证生成器损失函数和束缚性映射损失函数的有效性,进行转换模型的消融实验,对比模型分别设置为CycleGAN[21 ] 、生成对抗网络(generative adversarial network, GAN)[22 ] 、加入生成器损失函数的Bi-MGAN(G)、加入束缚性映射性损失函数的Bi-MGAN(M)和包含以上2种损失函数的Bi-MGAN(GM). 如表2 所示,Bi-MGAN(G)较CycleGAN的MAE和RMSE分别提升0.010~0.093 mm和0.011~0.087 mm,Bi-MGAN(M)较CycleGAN的MAE和RMSE分别提升0.169~0.248 mm和0.038~0.294 mm,表明生成器损失函数与束缚性映射损失函数在正向和反向映射中皆有利于转换模型生成高精度的映射特征. 此外,Bi-MGAN(GM)较Bi-MGAN(M)的MAE和RMSE分别提升0.141~0.176 mm和0.198~0.214 mm,表明生成器损失函数与判别器损失函数的结合会增强模型映射能力,使得映射特征更加趋近于真实特征. ...
... Ablation experiment of conversion network algorithm
mm Tab.2 算法 正向映射 反向映射 MAE RMSE MAE RMSE GAN[22 ] 1.217 1.642 0.946 1.189 CycleGAN[21 ] 1.127 1.428 0.811 0.919 Bi-MGAN(G) 1.034 1.341 0.801 0.908 Bi-MGAN(M) 0.879 1.134 0.642 0.881 Bi-MGAN(GM) 0.703 0.920 0.501 0.683
为了验证所提转换网络算法有效性,将Bi-MGAN与传统的DNN[14 ] 和BiLSTM[11 ] 以及深度递归混合密度网路(deep recurrent mixture density network, DRMDN)[23 ] 和粒子群优化算法的最小二乘支持向量机(particle swarm optimization algorithm of least squares support vector machines, PSO-LSSVM)[6 ] 进行对比. 如表3 所示,Bi-MGAN较传统的DNN和BiLSTM的MAE和RMSE大幅提升,较PSO-LSSVM的MAE和RMSE分别提升0.466~0.482 mm和0.344~0.453 mm,较DRMDN的MAE和RMSE分别提升0.181~0.330 mm和0.040~0.256 mm. 对比结果表明,Bi-MGAN可以大幅度提升网络的转换精度,在参加对比的网络中取得最佳的正向映射效果与反向映射效果,证明了Bi-MGAN的有效性. ...
Generative adversarial nets
2
2014
... 为了验证生成器损失函数和束缚性映射损失函数的有效性,进行转换模型的消融实验,对比模型分别设置为CycleGAN[21 ] 、生成对抗网络(generative adversarial network, GAN)[22 ] 、加入生成器损失函数的Bi-MGAN(G)、加入束缚性映射性损失函数的Bi-MGAN(M)和包含以上2种损失函数的Bi-MGAN(GM). 如表2 所示,Bi-MGAN(G)较CycleGAN的MAE和RMSE分别提升0.010~0.093 mm和0.011~0.087 mm,Bi-MGAN(M)较CycleGAN的MAE和RMSE分别提升0.169~0.248 mm和0.038~0.294 mm,表明生成器损失函数与束缚性映射损失函数在正向和反向映射中皆有利于转换模型生成高精度的映射特征. 此外,Bi-MGAN(GM)较Bi-MGAN(M)的MAE和RMSE分别提升0.141~0.176 mm和0.198~0.214 mm,表明生成器损失函数与判别器损失函数的结合会增强模型映射能力,使得映射特征更加趋近于真实特征. ...
... Ablation experiment of conversion network algorithm
mm Tab.2 算法 正向映射 反向映射 MAE RMSE MAE RMSE GAN[22 ] 1.217 1.642 0.946 1.189 CycleGAN[21 ] 1.127 1.428 0.811 0.919 Bi-MGAN(G) 1.034 1.341 0.801 0.908 Bi-MGAN(M) 0.879 1.134 0.642 0.881 Bi-MGAN(GM) 0.703 0.920 0.501 0.683
为了验证所提转换网络算法有效性,将Bi-MGAN与传统的DNN[14 ] 和BiLSTM[11 ] 以及深度递归混合密度网路(deep recurrent mixture density network, DRMDN)[23 ] 和粒子群优化算法的最小二乘支持向量机(particle swarm optimization algorithm of least squares support vector machines, PSO-LSSVM)[6 ] 进行对比. 如表3 所示,Bi-MGAN较传统的DNN和BiLSTM的MAE和RMSE大幅提升,较PSO-LSSVM的MAE和RMSE分别提升0.466~0.482 mm和0.344~0.453 mm,较DRMDN的MAE和RMSE分别提升0.181~0.330 mm和0.040~0.256 mm. 对比结果表明,Bi-MGAN可以大幅度提升网络的转换精度,在参加对比的网络中取得最佳的正向映射效果与反向映射效果,证明了Bi-MGAN的有效性. ...
2
... 为了验证所提转换网络算法有效性,将Bi-MGAN与传统的DNN[14 ] 和BiLSTM[11 ] 以及深度递归混合密度网路(deep recurrent mixture density network, DRMDN)[23 ] 和粒子群优化算法的最小二乘支持向量机(particle swarm optimization algorithm of least squares support vector machines, PSO-LSSVM)[6 ] 进行对比. 如表3 所示,Bi-MGAN较传统的DNN和BiLSTM的MAE和RMSE大幅提升,较PSO-LSSVM的MAE和RMSE分别提升0.466~0.482 mm和0.344~0.453 mm,较DRMDN的MAE和RMSE分别提升0.181~0.330 mm和0.040~0.256 mm. 对比结果表明,Bi-MGAN可以大幅度提升网络的转换精度,在参加对比的网络中取得最佳的正向映射效果与反向映射效果,证明了Bi-MGAN的有效性. ...
... Comparison of mapping performance for conversion networks algorithm
mm Tab.3 算法 正向映射 反向映射 MAE RMSE MAE RMSE DNN[14 ] 1.479 1.613 1.143 1.259 BiLSTM[11 ] 1.298 1.422 1.003 1.217 PSO-LSSVM[6 ] 1.185 1.252 0.967 1.136 DRMDN[23 ] 0.884 0.948 0.831 0.939 Bi-MGAN 0.703 0.908 0.501 0.683
4.3. 情感识别网络的性能对比 为了探究FDA在情感识别中的作用,分别提取STEM-E2 VA、CASIA、RADVESS和EMO-DB数据库的60维MFCC作为识别网络的输入,进行ResTCN-FDA的消融实验. 其中CASIA为6分类数据库,STEM-E2 VA和EMO-DB为7分类数据库,RADVESS为8分类数据库. 如表4 所示,将ResTCN-FA、ResTCN-DA与ResTCN对比可以发现,特征注意力机制对准确率提升量为1.52%~5.32%,维度注意力机制对准确率提升量为1.50%~4.54%,证明给不同特征和不同通道维度分配不同的权重参数有利于提升情感识别准确率. 将ResTCN-FDA对比TCN、ResTCN、ResTCN-FA和ResTCN-DA,准确率分别提升量为7.48%~10.92%、4.14%~8.16%、2.00%~4.16%和2.48%~6.66%. 另外,ResTCN-FDA的F1和AUC也比其他算法的有一定程度的提升,这说明ResTCN-FDA可以更好的处理情感信息. ...
Leveraging semisupervised hierarchical stacking temporal convolutional network for anomaly detection in IoT communication
5
2020
... 为了进一步验证所提识别网络的有效性,以MFCC为输入特征,将ResTCN-FDA分别与传统的CNN,以及HS-TCN[24 ] 和DRN[25 ] 进行比较. 如表5 所示,ResTCN-FDA在CASIA、STEM-E2 VA、EMO-DB和RADVESS数据库上准确率分别达到80.41%、75.63%、80.16%和66.55%,与CNN、HS-TCN和DRN相比性能有明显提升. 此外,ResTCN-FDA与HS-TCN和DRN相比,F1分别取得2.01%~7.85%和3.69%~7.19%的提升量,AUC分别取得3.28%~6.07%和2.96%~7.96%的提升量,证明ResTCN-FDA在情感识别中的有效性. ...
... Comparison of emotion evaluation metrics for emotion recognition networks algorithm
% Tab.5 数据库 算法 ACC F1 AUC CASIA CNN[12 ] 63.00 62.43 63.19 HS-TCN[24 ] 76.25 76.64 76.91 DRN[25 ] 76.91 76.67 76.94 ResTCN-FDA 80.41 81.22 81.43 STEM-E2 VA CNN[12 ] 56.77 56.84 57.77 HS-TCN[24 ] 72.81 72.59 72.92 DRN[25 ] 68.15 68.25 68.86 ResTCN-FDA 75.63 75.44 76.82 EMO-DB CNN[12 ] 69.72 69.09 69.86 HS-TCN[24 ] 74.76 73.60 75.51 DRN[25 ] 76.64 74.72 76.96 ResTCN-FDA 80.16 80.78 81.58 RADVESS CNN[12 ] 57.29 55.67 57.85 HS-TCN[24 ] 63.29 63.56 63.58 DRN[25 ] 63.46 61.88 63.90 ResTCN-FDA 66.55 65.57 66.86
4.4. 声学与发音特征转换对情感识别的影响 为了探究声学和发音特征转换对情感识别的影响,提取STEM-E2 VA的声学特征和发音特征,利用Bi-MGAN完成映射特征的生成,以ResTCN-FDA为识别网络,通过给识别网络输入不同的特征集来探索声学与发音特征转换对情感识别的影响. 另外,提取预训练特征[26 -27 ] 来对比声学与发音特征的情感识别性能. ...
... [
24 ]
72.81 72.59 72.92 DRN[25 ] 68.15 68.25 68.86 ResTCN-FDA 75.63 75.44 76.82 EMO-DB CNN[12 ] 69.72 69.09 69.86 HS-TCN[24 ] 74.76 73.60 75.51 DRN[25 ] 76.64 74.72 76.96 ResTCN-FDA 80.16 80.78 81.58 RADVESS CNN[12 ] 57.29 55.67 57.85 HS-TCN[24 ] 63.29 63.56 63.58 DRN[25 ] 63.46 61.88 63.90 ResTCN-FDA 66.55 65.57 66.86 4.4. 声学与发音特征转换对情感识别的影响 为了探究声学和发音特征转换对情感识别的影响,提取STEM-E2 VA的声学特征和发音特征,利用Bi-MGAN完成映射特征的生成,以ResTCN-FDA为识别网络,通过给识别网络输入不同的特征集来探索声学与发音特征转换对情感识别的影响. 另外,提取预训练特征[26 -27 ] 来对比声学与发音特征的情感识别性能. ...
... [
24 ]
74.76 73.60 75.51 DRN[25 ] 76.64 74.72 76.96 ResTCN-FDA 80.16 80.78 81.58 RADVESS CNN[12 ] 57.29 55.67 57.85 HS-TCN[24 ] 63.29 63.56 63.58 DRN[25 ] 63.46 61.88 63.90 ResTCN-FDA 66.55 65.57 66.86 4.4. 声学与发音特征转换对情感识别的影响 为了探究声学和发音特征转换对情感识别的影响,提取STEM-E2 VA的声学特征和发音特征,利用Bi-MGAN完成映射特征的生成,以ResTCN-FDA为识别网络,通过给识别网络输入不同的特征集来探索声学与发音特征转换对情感识别的影响. 另外,提取预训练特征[26 -27 ] 来对比声学与发音特征的情感识别性能. ...
... [
24 ]
63.29 63.56 63.58 DRN[25 ] 63.46 61.88 63.90 ResTCN-FDA 66.55 65.57 66.86 4.4. 声学与发音特征转换对情感识别的影响 为了探究声学和发音特征转换对情感识别的影响,提取STEM-E2 VA的声学特征和发音特征,利用Bi-MGAN完成映射特征的生成,以ResTCN-FDA为识别网络,通过给识别网络输入不同的特征集来探索声学与发音特征转换对情感识别的影响. 另外,提取预训练特征[26 -27 ] 来对比声学与发音特征的情感识别性能. ...
Combining a parallel 2D CNN with a self-attention dilated residual network for CTC-based discrete speech emotion recognition
5
2021
... 为了进一步验证所提识别网络的有效性,以MFCC为输入特征,将ResTCN-FDA分别与传统的CNN,以及HS-TCN[24 ] 和DRN[25 ] 进行比较. 如表5 所示,ResTCN-FDA在CASIA、STEM-E2 VA、EMO-DB和RADVESS数据库上准确率分别达到80.41%、75.63%、80.16%和66.55%,与CNN、HS-TCN和DRN相比性能有明显提升. 此外,ResTCN-FDA与HS-TCN和DRN相比,F1分别取得2.01%~7.85%和3.69%~7.19%的提升量,AUC分别取得3.28%~6.07%和2.96%~7.96%的提升量,证明ResTCN-FDA在情感识别中的有效性. ...
... Comparison of emotion evaluation metrics for emotion recognition networks algorithm
% Tab.5 数据库 算法 ACC F1 AUC CASIA CNN[12 ] 63.00 62.43 63.19 HS-TCN[24 ] 76.25 76.64 76.91 DRN[25 ] 76.91 76.67 76.94 ResTCN-FDA 80.41 81.22 81.43 STEM-E2 VA CNN[12 ] 56.77 56.84 57.77 HS-TCN[24 ] 72.81 72.59 72.92 DRN[25 ] 68.15 68.25 68.86 ResTCN-FDA 75.63 75.44 76.82 EMO-DB CNN[12 ] 69.72 69.09 69.86 HS-TCN[24 ] 74.76 73.60 75.51 DRN[25 ] 76.64 74.72 76.96 ResTCN-FDA 80.16 80.78 81.58 RADVESS CNN[12 ] 57.29 55.67 57.85 HS-TCN[24 ] 63.29 63.56 63.58 DRN[25 ] 63.46 61.88 63.90 ResTCN-FDA 66.55 65.57 66.86
4.4. 声学与发音特征转换对情感识别的影响 为了探究声学和发音特征转换对情感识别的影响,提取STEM-E2 VA的声学特征和发音特征,利用Bi-MGAN完成映射特征的生成,以ResTCN-FDA为识别网络,通过给识别网络输入不同的特征集来探索声学与发音特征转换对情感识别的影响. 另外,提取预训练特征[26 -27 ] 来对比声学与发音特征的情感识别性能. ...
... [
25 ]
68.15 68.25 68.86 ResTCN-FDA 75.63 75.44 76.82 EMO-DB CNN[12 ] 69.72 69.09 69.86 HS-TCN[24 ] 74.76 73.60 75.51 DRN[25 ] 76.64 74.72 76.96 ResTCN-FDA 80.16 80.78 81.58 RADVESS CNN[12 ] 57.29 55.67 57.85 HS-TCN[24 ] 63.29 63.56 63.58 DRN[25 ] 63.46 61.88 63.90 ResTCN-FDA 66.55 65.57 66.86 4.4. 声学与发音特征转换对情感识别的影响 为了探究声学和发音特征转换对情感识别的影响,提取STEM-E2 VA的声学特征和发音特征,利用Bi-MGAN完成映射特征的生成,以ResTCN-FDA为识别网络,通过给识别网络输入不同的特征集来探索声学与发音特征转换对情感识别的影响. 另外,提取预训练特征[26 -27 ] 来对比声学与发音特征的情感识别性能. ...
... [
25 ]
76.64 74.72 76.96 ResTCN-FDA 80.16 80.78 81.58 RADVESS CNN[12 ] 57.29 55.67 57.85 HS-TCN[24 ] 63.29 63.56 63.58 DRN[25 ] 63.46 61.88 63.90 ResTCN-FDA 66.55 65.57 66.86 4.4. 声学与发音特征转换对情感识别的影响 为了探究声学和发音特征转换对情感识别的影响,提取STEM-E2 VA的声学特征和发音特征,利用Bi-MGAN完成映射特征的生成,以ResTCN-FDA为识别网络,通过给识别网络输入不同的特征集来探索声学与发音特征转换对情感识别的影响. 另外,提取预训练特征[26 -27 ] 来对比声学与发音特征的情感识别性能. ...
... [
25 ]
63.46 61.88 63.90 ResTCN-FDA 66.55 65.57 66.86 4.4. 声学与发音特征转换对情感识别的影响 为了探究声学和发音特征转换对情感识别的影响,提取STEM-E2 VA的声学特征和发音特征,利用Bi-MGAN完成映射特征的生成,以ResTCN-FDA为识别网络,通过给识别网络输入不同的特征集来探索声学与发音特征转换对情感识别的影响. 另外,提取预训练特征[26 -27 ] 来对比声学与发音特征的情感识别性能. ...
4
... 为了探究声学和发音特征转换对情感识别的影响,提取STEM-E2 VA的声学特征和发音特征,利用Bi-MGAN完成映射特征的生成,以ResTCN-FDA为识别网络,通过给识别网络输入不同的特征集来探索声学与发音特征转换对情感识别的影响. 另外,提取预训练特征[26 -27 ] 来对比声学与发音特征的情感识别性能. ...
... Comparison of emotion evaluation indexes for different acoustic and articulatory features
Tab.6 特征类型 特征集 输入模态 维度 ACC/% F1/% AUC/% 发音学 Articulatory(C) 映射发音特征 28 53.02 52.03 53.61 发音学 Articulatory(R) 真实发音特征 28 63.56 62.96 63.87 声学 Acoustic(C) 映射声学特征 60 59.23 58.69 59.82 声学 Acoustic(R) 真实声学特征 60 75.63 75.44 76.82 声学与发音学 Acoustic(R) + Articulatory(C) 真实声学特征+映射发音特征 88 79.51 79.69 79.97 声学与发音学 Acoustic(C)+ Articulatory(R) 真实发音特征+映射声学特征 88 72.47 72.45 72.95 声学与发音学 Acoustic(R)+Articulatory(R) 真实声学特征+真实发音特征 88 83.77 83.64 83.97 预训练 HuBERT[26 ] 48层 transformer 1 280 89.66 89.85 91.96 预训练 Wav2vec 2.0[27 ] 24层 transformer 1 024 82.57 82.25 83.93 预训练与降维 HuBERT[26 ] 48层 transformer+主成分分析 60 78.54 78.93 79.15 预训练与降维 HuBERT[26 ] 48层 transformer+主成分分析 88 80.16 80.01 80.42 预训练与降维 Wav2vec 2.0[27 ] 24层 transformer+主成分分析 60 75.90 75.45 76.88 预训练与降维 Wav2vec 2.0[27 ] 24层 transformer+主成分分析 88 76.18 76.65 76.96
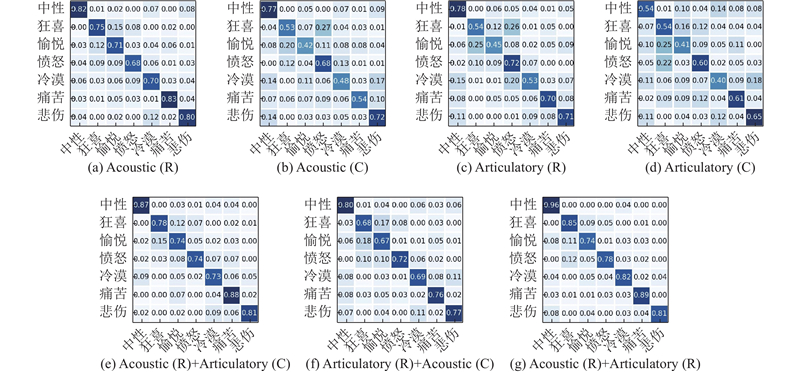
如图7 所示为不同特征的混淆矩阵. 从图7(a) ~(d)可以看出,映射特征对狂喜、愤怒、冷漠和痛苦情感的识别率远低于真实特征,对中性和伤心情感的识别率略低于真实特征,说明声学与发音特征转换受情绪的影响. 对比图7 (a)、(e)发现,当真实声学特征融合映射发音特征后,会使情感识别率有所提升,但不同的情绪提升效果有明显差异. 对比图7 (c)、(f),当真实发音特征和映射声学特征融合后,映射声学特征对真实发音特征起补充情绪作用. 对比图7 (a)、(c)、(e)、(f)和(g)可以发现,融合特征的情感识别率均低于真实的声学与发音特征的情感识别率,但映射特征对真实特征的情感补充作用会使真实特征的情感识别率有较大的提升. ...
... [
26 ]
48层 transformer+主成分分析 60 78.54 78.93 79.15 预训练与降维 HuBERT[26 ] 48层 transformer+主成分分析 88 80.16 80.01 80.42 预训练与降维 Wav2vec 2.0[27 ] 24层 transformer+主成分分析 60 75.90 75.45 76.88 预训练与降维 Wav2vec 2.0[27 ] 24层 transformer+主成分分析 88 76.18 76.65 76.96 如图7 所示为不同特征的混淆矩阵. 从图7(a) ~(d)可以看出,映射特征对狂喜、愤怒、冷漠和痛苦情感的识别率远低于真实特征,对中性和伤心情感的识别率略低于真实特征,说明声学与发音特征转换受情绪的影响. 对比图7 (a)、(e)发现,当真实声学特征融合映射发音特征后,会使情感识别率有所提升,但不同的情绪提升效果有明显差异. 对比图7 (c)、(f),当真实发音特征和映射声学特征融合后,映射声学特征对真实发音特征起补充情绪作用. 对比图7 (a)、(c)、(e)、(f)和(g)可以发现,融合特征的情感识别率均低于真实的声学与发音特征的情感识别率,但映射特征对真实特征的情感补充作用会使真实特征的情感识别率有较大的提升. ...
... [
26 ]
48层 transformer+主成分分析 88 80.16 80.01 80.42 预训练与降维 Wav2vec 2.0[27 ] 24层 transformer+主成分分析 60 75.90 75.45 76.88 预训练与降维 Wav2vec 2.0[27 ] 24层 transformer+主成分分析 88 76.18 76.65 76.96 如图7 所示为不同特征的混淆矩阵. 从图7(a) ~(d)可以看出,映射特征对狂喜、愤怒、冷漠和痛苦情感的识别率远低于真实特征,对中性和伤心情感的识别率略低于真实特征,说明声学与发音特征转换受情绪的影响. 对比图7 (a)、(e)发现,当真实声学特征融合映射发音特征后,会使情感识别率有所提升,但不同的情绪提升效果有明显差异. 对比图7 (c)、(f),当真实发音特征和映射声学特征融合后,映射声学特征对真实发音特征起补充情绪作用. 对比图7 (a)、(c)、(e)、(f)和(g)可以发现,融合特征的情感识别率均低于真实的声学与发音特征的情感识别率,但映射特征对真实特征的情感补充作用会使真实特征的情感识别率有较大的提升. ...
4
... 为了探究声学和发音特征转换对情感识别的影响,提取STEM-E2 VA的声学特征和发音特征,利用Bi-MGAN完成映射特征的生成,以ResTCN-FDA为识别网络,通过给识别网络输入不同的特征集来探索声学与发音特征转换对情感识别的影响. 另外,提取预训练特征[26 -27 ] 来对比声学与发音特征的情感识别性能. ...
... Comparison of emotion evaluation indexes for different acoustic and articulatory features
Tab.6 特征类型 特征集 输入模态 维度 ACC/% F1/% AUC/% 发音学 Articulatory(C) 映射发音特征 28 53.02 52.03 53.61 发音学 Articulatory(R) 真实发音特征 28 63.56 62.96 63.87 声学 Acoustic(C) 映射声学特征 60 59.23 58.69 59.82 声学 Acoustic(R) 真实声学特征 60 75.63 75.44 76.82 声学与发音学 Acoustic(R) + Articulatory(C) 真实声学特征+映射发音特征 88 79.51 79.69 79.97 声学与发音学 Acoustic(C)+ Articulatory(R) 真实发音特征+映射声学特征 88 72.47 72.45 72.95 声学与发音学 Acoustic(R)+Articulatory(R) 真实声学特征+真实发音特征 88 83.77 83.64 83.97 预训练 HuBERT[26 ] 48层 transformer 1 280 89.66 89.85 91.96 预训练 Wav2vec 2.0[27 ] 24层 transformer 1 024 82.57 82.25 83.93 预训练与降维 HuBERT[26 ] 48层 transformer+主成分分析 60 78.54 78.93 79.15 预训练与降维 HuBERT[26 ] 48层 transformer+主成分分析 88 80.16 80.01 80.42 预训练与降维 Wav2vec 2.0[27 ] 24层 transformer+主成分分析 60 75.90 75.45 76.88 预训练与降维 Wav2vec 2.0[27 ] 24层 transformer+主成分分析 88 76.18 76.65 76.96
如图7 所示为不同特征的混淆矩阵. 从图7(a) ~(d)可以看出,映射特征对狂喜、愤怒、冷漠和痛苦情感的识别率远低于真实特征,对中性和伤心情感的识别率略低于真实特征,说明声学与发音特征转换受情绪的影响. 对比图7 (a)、(e)发现,当真实声学特征融合映射发音特征后,会使情感识别率有所提升,但不同的情绪提升效果有明显差异. 对比图7 (c)、(f),当真实发音特征和映射声学特征融合后,映射声学特征对真实发音特征起补充情绪作用. 对比图7 (a)、(c)、(e)、(f)和(g)可以发现,融合特征的情感识别率均低于真实的声学与发音特征的情感识别率,但映射特征对真实特征的情感补充作用会使真实特征的情感识别率有较大的提升. ...
... [
27 ]
24层 transformer+主成分分析 60 75.90 75.45 76.88 预训练与降维 Wav2vec 2.0[27 ] 24层 transformer+主成分分析 88 76.18 76.65 76.96 如图7 所示为不同特征的混淆矩阵. 从图7(a) ~(d)可以看出,映射特征对狂喜、愤怒、冷漠和痛苦情感的识别率远低于真实特征,对中性和伤心情感的识别率略低于真实特征,说明声学与发音特征转换受情绪的影响. 对比图7 (a)、(e)发现,当真实声学特征融合映射发音特征后,会使情感识别率有所提升,但不同的情绪提升效果有明显差异. 对比图7 (c)、(f),当真实发音特征和映射声学特征融合后,映射声学特征对真实发音特征起补充情绪作用. 对比图7 (a)、(c)、(e)、(f)和(g)可以发现,融合特征的情感识别率均低于真实的声学与发音特征的情感识别率,但映射特征对真实特征的情感补充作用会使真实特征的情感识别率有较大的提升. ...
... [
27 ]
24层 transformer+主成分分析 88 76.18 76.65 76.96 如图7 所示为不同特征的混淆矩阵. 从图7(a) ~(d)可以看出,映射特征对狂喜、愤怒、冷漠和痛苦情感的识别率远低于真实特征,对中性和伤心情感的识别率略低于真实特征,说明声学与发音特征转换受情绪的影响. 对比图7 (a)、(e)发现,当真实声学特征融合映射发音特征后,会使情感识别率有所提升,但不同的情绪提升效果有明显差异. 对比图7 (c)、(f),当真实发音特征和映射声学特征融合后,映射声学特征对真实发音特征起补充情绪作用. 对比图7 (a)、(c)、(e)、(f)和(g)可以发现,融合特征的情感识别率均低于真实的声学与发音特征的情感识别率,但映射特征对真实特征的情感补充作用会使真实特征的情感识别率有较大的提升. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}