| 计算机技术、通信技术 |
|

|
|
|
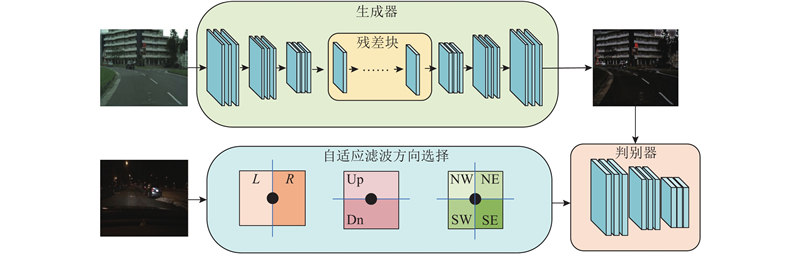
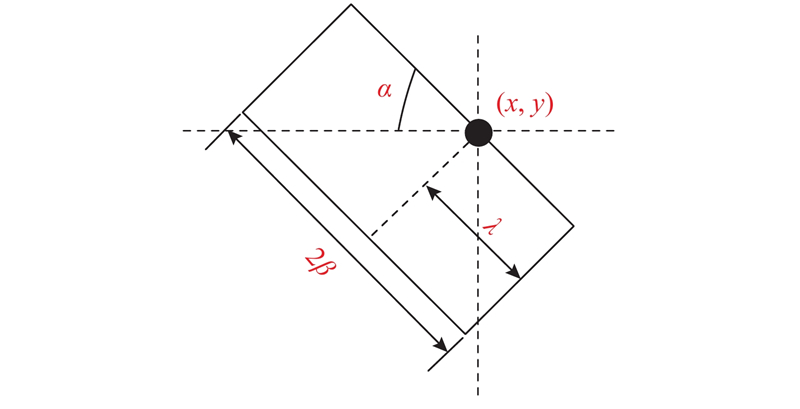
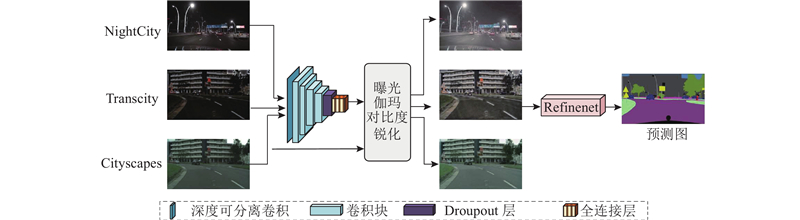
| 基于Trans-nightSeg的夜间道路场景语义分割方法 |
李灿林1( ),张文娇1,邵志文2,3,马利庄3,王新玥1 ),张文娇1,邵志文2,3,马利庄3,王新玥1 |
1. 郑州轻工业大学 计算机与通信工程学院,河南 郑州 450000
2. 中国矿业大学 计算机科学与技术学院,江苏 徐州 221116
3. 上海交通大学 计算机科学与工程系,上海 200240 |
|
| Semantic segmentation method on nighttime road scene based on Trans-nightSeg |
| Canlin LI1(),Wenjiao ZHANG1,Zhiwen SHAO2,3,Lizhuang MA3,Xinyue WANG1 |
1. School of Computer and Communication Engineering, Zhengzhou University of Light Industry, Zhengzhou 450000, China
2. School of Computer Science and Technology, China University of Mining and Technology, Xuzhou 221116, China
3. Department of Computer Science and Engineering, Shanghai Jiao Tong University, Shanghai 200240, China |
引用本文:
李灿林,张文娇,邵志文,马利庄,王新玥. 基于Trans-nightSeg的夜间道路场景语义分割方法[J]. 浙江大学学报(工学版), 2024, 58(2): 294-303.
Canlin LI,Wenjiao ZHANG,Zhiwen SHAO,Lizhuang MA,Xinyue WANG. Semantic segmentation method on nighttime road scene based on Trans-nightSeg. Journal of ZheJiang University (Engineering Science), 2024, 58(2): 294-303.
链接本文:
https://www.zjujournals.com/eng/CN/10.3785/j.issn.1008-973X.2024.02.008
或
https://www.zjujournals.com/eng/CN/Y2024/V58/I2/294
|
| 1 |
CORDTS M, OMRAN M, RAMOS S, et al. The Cityscapes dataset for semantic urban scene understanding [C]// IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 3213-3223.
|
| 2 |
SAKARIDIS C, DAI D, GOOL L V. ACDC: the adverse conditions dataset with correspondences for semantic driving scene understanding [C]// IEEE International Conference on Computer Vision. Montreal: IEEE, 2021: 10765-10775.
|
| 3 |
GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al Generative adversarial networks[J]. Communications of the ACM, 2020, 63 (11): 139- 144
doi: 10.1145/3422622
|
| 4 |
REED S, AKATA Z, YAN X, et al. Generative adversarial text to image synthesis [C]// International Conference on Machine Learning. New York: PMLR, 2016: 1060-1069.
|
| 5 |
YEH R, CHEN C, LIM T Y, et al. Semantic image inpainting with perceptual and contextual losses [EB/OL]. [2016-07-26]. https://arxiv.org/abs/1607.07539.
|
| 6 |
LEDIG C, THEIS L, HUSZAR F, et al. Photo-realistic single image super-resolution using a generative adversarial network [C]// IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 4681-4690.
|
| 7 |
ISOLA P, ZHU J Y, ZHOU T, et al. Image-to-image translation with conditional adversarial networks [C]// IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 1125-1134.
|
| 8 |
KARACAN L, AKATA Z, ERDEM A, et al. Learning to generate images of outdoor scenes from attributes and semantic layouts [EB/OL]. [2016-12-01]. https://arxiv.org/abs/1612.00215.
|
| 9 |
ZHU J Y, PARK T, ISOLA P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks [C]// IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 2223-2232.
|
| 10 |
WANG H, CHEN Y, CAI Y, et al SFNet-N: an improved SFNet algorithm for semantic segmentation of low-light autonomous driving road scenes[J]. IEEE Transactions on Intelligent Transportation Systems, 2022, 23 (11): 21405- 21417
doi: 10.1109/TITS.2022.3177615
|
| 11 |
CHEN Y, LAI Y K, LIU Y J. Cartoongan: generative adversarial networks for photo cartoonization [C]// IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 9465-9474.
|
| 12 |
YIN H, GONG Y, QIU G. Side window filtering [C]// IEEE Conference on Computer Vision and Pattern Recognition. Los Angeles: IEEE, 2019: 8758-8766.
|
| 13 |
SHELHAMER E, LONG J, DARRELL T Fully convolutional networks for semantic segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39 (4): 640- 651
doi: 10.1109/TPAMI.2016.2572683
|
| 14 |
LIN G, MILAN A, SHEN C, et al. Refinenet: multi-path refinement networks for high-resolution semantic segmentation [C]// IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 1925-1934.
|
| 15 |
BIJELIC M, GRUBER T, RITTER W. Benchmarking image sensors under adverse weather conditions for autonomous driving [C]// IEEE Intelligent Vehicles Symposium. Changshu: IEEE, 2018: 1773-1779.
|
| 16 |
WULFMEIER M, BEWLEY A, POSNER I. Addressing appearance change in outdoor robotics with adversarial domain adaptation [C] // IEEE International Conference on Intelligent Robots and Systems. Vancouver: IEEE, 2017: 1551-1558.
|
| 17 |
DAI D, GOOL L V. Dark model adaptation: semantic image segmentation from daytime to nighttime [C]// IEEE International Conference on Intelligent Transportation Systems. Hawaii: IEEE, 2018: 3819-3824.
|
| 18 |
SAKARIDIS C, DAI D, GOOL L V. Guided curriculum model adaptation and uncertainty-aware evaluation for semantic nighttime image segmentation [C]// IEEE International Conference on Computer Vision. Seoul: IEEE, 2019: 7374-7383.
|
| 19 |
SAKARIDIS C, DAI D, GOOL L V Map-guided curriculum domain adaptation and uncertainty-aware evaluation for semantic nighttime image segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44 (6): 3139- 3153
doi: 10.1109/TPAMI.2020.3045882
|
| 20 |
XU Q, MA Y, WU J, et al. CDAda: a curriculum do-main adaptation for nighttime semantic segmentation[C]// IEEE International Conference on Computer Vision. Montreal: IEEE, 2021: 2962-2971.
|
| 21 |
ROMERA E, BERGASA L M, YANG K, et al. Bridging the day and night domain gap for semantic segmentation [C]// IEEE Intelligent Vehicles Symposium. Paris: IEEE, 2019: 1312-1318.
|
| 22 |
SUN L, WANG K, YANG K, et al. See clearer at night: towards robust nighttime semantic segmentation through day-night image conversion [C]// Artificial Intelligence and Machine Learning in Defense Applications. Bellingham: SPIE, 2019, 11169: 77-89.
|
| 23 |
WU X, WU Z, GUO H, et al. Dannet: a one-stage domain adaptation network for unsupervised nighttime semantic segmentation [C]// IEEE Conference on Computer Vision and Pattern Recognition. Nashville: IEEE, 2021: 15769-15778.
|
| 24 |
WU X, WU Z, JU L, et al A one-stage domain adaptation network with image alignment for unsupervised nighttime semantic segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45 (1): 58- 72
doi: 10.1109/TPAMI.2021.3138829
|
| 25 |
HU Y, HU H, XU C, et al Exposure: a white-box photo post-processing framework[J]. ACM Transactions on Graphics, 2018, 37 (2): 26.1- 26.17
|
| 26 |
CHOLLET F. Xception: deep learning with depthwise separable convolutions [C]// IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 1251-1258.
|
| 27 |
HOWARD A G, ZHU M, CHEN B, et al. Mobilenets: efficient convolutional neural networks for mobile vis-ion applications [EB/OL]. [2017-04-17]. https://arxiv.org/abs/1704.04861.
|
| 28 |
TAN X, XU K, CAO Y, et al Nighttime scene parsing with a large real dataset[J]. IEEE Transactions on Image Processing, 2021, (30): 9085- 9098
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|