[1]
CORDTS M, OMRAN M, RAMOS S, et al. The Cityscapes dataset for semantic urban scene understanding [C]// IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 3213-3223.
[本文引用: 2]
[2]
SAKARIDIS C, DAI D, GOOL L V. ACDC: the adverse conditions dataset with correspondences for semantic driving scene understanding [C]// IEEE International Conference on Computer Vision . Montreal: IEEE, 2021: 10765-10775.
[本文引用: 1]
[3]
GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al Generative adversarial networks
[J]. Communications of the ACM , 2020 , 63 (11 ): 139 - 144
DOI:10.1145/3422622
[本文引用: 1]
[4]
REED S, AKATA Z, YAN X, et al. Generative adversarial text to image synthesis [C]// International Conference on Machine Learning . New York: PMLR, 2016: 1060-1069.
[本文引用: 1]
[5]
YEH R, CHEN C, LIM T Y, et al. Semantic image inpainting with perceptual and contextual losses [EB/OL]. [2016-07-26]. https://arxiv.org/abs/1607.07539.
[本文引用: 1]
[6]
LEDIG C, THEIS L, HUSZAR F, et al. Photo-realistic single image super-resolution using a generative adversarial network [C]// IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 4681-4690.
[本文引用: 1]
[7]
ISOLA P, ZHU J Y, ZHOU T, et al. Image-to-image translation with conditional adversarial networks [C]// IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 1125-1134.
[本文引用: 2]
[8]
KARACAN L, AKATA Z, ERDEM A, et al. Learning to generate images of outdoor scenes from attributes and semantic layouts [EB/OL]. [2016-12-01]. https://arxiv.org/abs/1612.00215.
[本文引用: 1]
[9]
ZHU J Y, PARK T, ISOLA P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks [C]// IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 2223-2232.
[本文引用: 1]
[10]
WANG H, CHEN Y, CAI Y, et al SFNet-N: an improved SFNet algorithm for semantic segmentation of low-light autonomous driving road scenes
[J]. IEEE Transactions on Intelligent Transportation Systems , 2022 , 23 (11 ): 21405 - 21417
DOI:10.1109/TITS.2022.3177615
[本文引用: 1]
[11]
CHEN Y, LAI Y K, LIU Y J. Cartoongan: generative adversarial networks for photo cartoonization [C]// IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 9465-9474.
[本文引用: 1]
[12]
YIN H, GONG Y, QIU G. Side window filtering [C]// IEEE Conference on Computer Vision and Pattern Recognition . Los Angeles: IEEE, 2019: 8758-8766.
[本文引用: 1]
[13]
SHELHAMER E, LONG J, DARRELL T Fully convolutional networks for semantic segmentation
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2017 , 39 (4 ): 640 - 651
DOI:10.1109/TPAMI.2016.2572683
[本文引用: 1]
[14]
LIN G, MILAN A, SHEN C, et al. Refinenet: multi-path refinement networks for high-resolution semantic segmentation [C]// IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 1925-1934.
[本文引用: 1]
[15]
BIJELIC M, GRUBER T, RITTER W. Benchmarking image sensors under adverse weather conditions for autonomous driving [C]// IEEE Intelligent Vehicles Symposium . Changshu: IEEE, 2018: 1773-1779.
[本文引用: 1]
[16]
WULFMEIER M, BEWLEY A, POSNER I. Addressing appearance change in outdoor robotics with adversarial domain adaptation [C] // IEEE International Conference on Intelligent Robots and Systems . Vancouver: IEEE, 2017: 1551-1558.
[本文引用: 1]
[17]
DAI D, GOOL L V. Dark model adaptation: semantic image segmentation from daytime to nighttime [C]// IEEE International Conference on Intelligent Transportation Systems . Hawaii: IEEE, 2018: 3819-3824.
[本文引用: 3]
[18]
SAKARIDIS C, DAI D, GOOL L V. Guided curriculum model adaptation and uncertainty-aware evaluation for semantic nighttime image segmentation [C]// IEEE International Conference on Computer Vision . Seoul: IEEE, 2019: 7374-7383.
[本文引用: 4]
[19]
SAKARIDIS C, DAI D, GOOL L V Map-guided curriculum domain adaptation and uncertainty-aware evaluation for semantic nighttime image segmentation
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2022 , 44 (6 ): 3139 - 3153
DOI:10.1109/TPAMI.2020.3045882
[本文引用: 2]
[20]
XU Q, MA Y, WU J, et al. CDAda: a curriculum do-main adaptation for nighttime semantic segmentation[C]// IEEE International Conference on Computer Vision . Montreal: IEEE, 2021: 2962-2971.
[本文引用: 1]
[21]
ROMERA E, BERGASA L M, YANG K, et al. Bridging the day and night domain gap for semantic segmentation [C]// IEEE Intelligent Vehicles Symposium . Paris: IEEE, 2019: 1312-1318.
[本文引用: 1]
[22]
SUN L, WANG K, YANG K, et al. See clearer at night: towards robust nighttime semantic segmentation through day-night image conversion [C]// Artificial Intelligence and Machine Learning in Defense Applications . Bellingham: SPIE, 2019, 11169: 77-89.
[本文引用: 1]
[23]
WU X, WU Z, GUO H, et al. Dannet: a one-stage domain adaptation network for unsupervised nighttime semantic segmentation [C]// IEEE Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 15769-15778.
[本文引用: 3]
[24]
WU X, WU Z, JU L, et al A one-stage domain adaptation network with image alignment for unsupervised nighttime semantic segmentation
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2023 , 45 (1 ): 58 - 72
DOI:10.1109/TPAMI.2021.3138829
[本文引用: 2]
[25]
HU Y, HU H, XU C, et al Exposure: a white-box photo post-processing framework
[J]. ACM Transactions on Graphics , 2018 , 37 (2 ): 26.1 - 26.17
[本文引用: 1]
[26]
CHOLLET F. Xception: deep learning with depthwise separable convolutions [C]// IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 1251-1258.
[本文引用: 1]
[27]
HOWARD A G, ZHU M, CHEN B, et al. Mobilenets: efficient convolutional neural networks for mobile vis-ion applications [EB/OL]. [2017-04-17]. https://arxiv.org/abs/1704.04861.
[本文引用: 1]
[28]
TAN X, XU K, CAO Y, et al Nighttime scene parsing with a large real dataset
[J]. IEEE Transactions on Image Processing , 2021 , (30 ): 9085 - 9098
[本文引用: 1]
[29]
YU F, CHEN H, WANG X, et al. Bdd100k: a diverse driving dataset for heterogeneous multitask learning [C]// IEEE Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 2636-2645.
[本文引用: 1]
2
... 夜间道路场景分割主要面临以下2个挑战. 1)由于夜间感知能力差,难以获得大规模标注的夜间道路场景数据集. 深度学习本质上是基于数据驱动的方法. 目前,实现高性能语义分割的标准策略是使用神经网络训练大量带标注的低光数据. 收集这种低光图像并对其进行标注的过程是劳动密集型的. 例如一个人需要大约90 min来标注Cityscape[1 ] 数据集的图像,该数据集只包含白天和晴朗的天气条件,对于有对应关系的恶劣条件数据集, 如ACDC[2 ] 数据集,则超过3 h. 由于夜间图片中黑暗或阴影部分的面积较大,在像素级建立高质量的标注是非常困难的. 2)夜间道路场景图像存在亮度低、噪声和运动模糊等问题,使用卷积层提取的特征与在良好光照条件下获得的特征存在明显差异. 使用日间道路数据集训练的模型,不能直接应用于夜间道路场景. ...
... 1)Cityscapes[1 ] :Cityscapes是具有白天道路场景像素级标注的语义分割数据集. 其中有2975张图像用于训练、500张图像用于验证和1525张图像用于测试,均具有19类像素级标注,分辨率均为2048×1024. 使用该数据集作为N-RefineNet的训练数据集,从中选取4000张图片作为TransCartoonGAN的源域. ...
1
... 夜间道路场景分割主要面临以下2个挑战. 1)由于夜间感知能力差,难以获得大规模标注的夜间道路场景数据集. 深度学习本质上是基于数据驱动的方法. 目前,实现高性能语义分割的标准策略是使用神经网络训练大量带标注的低光数据. 收集这种低光图像并对其进行标注的过程是劳动密集型的. 例如一个人需要大约90 min来标注Cityscape[1 ] 数据集的图像,该数据集只包含白天和晴朗的天气条件,对于有对应关系的恶劣条件数据集, 如ACDC[2 ] 数据集,则超过3 h. 由于夜间图片中黑暗或阴影部分的面积较大,在像素级建立高质量的标注是非常困难的. 2)夜间道路场景图像存在亮度低、噪声和运动模糊等问题,使用卷积层提取的特征与在良好光照条件下获得的特征存在明显差异. 使用日间道路数据集训练的模型,不能直接应用于夜间道路场景. ...
Generative adversarial networks
1
2020
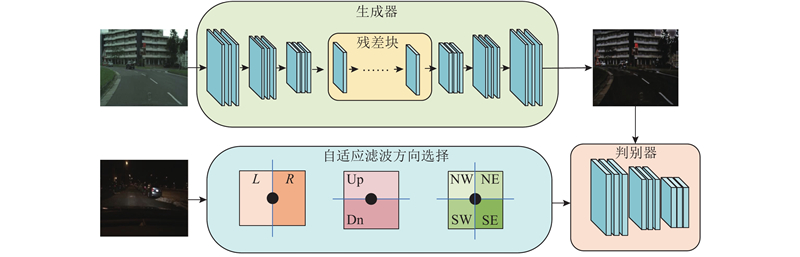
... 生成对抗性网络(generative adversarial networks,GAN)[3 ] 是常见的图像生成方法之一,它在许多应用中产生了不错的结果,如文本到图像的转换[4 ] 、图像修复[5 ] 、图像超分辨率[6 ] 等. 对于像素到像素的图像生成问题,Isola等[7 -8 ] 使用GAN提出解决方案,这些方法需要使用成对图像集,然而获得这样的对应图像集是有挑战的. 为了解决该问题,Zhu等[9 ] 提出CycleGAN,使用未配对的训练数据执行图像转换. Wang等[10 ] 将该方法应用于夜间道路场景语义分割,将日间道路场景数据集Cityscapes进行弱光条件下的风格转换,生成新的数据集Cyclecity,然而该数据集中的图片往往包含蓝色的噪点,部分效果与真实夜间道路场景图像不太相符. Chen等[11 ] 提出CartoonGAN方法,使用未配对的训练数据来实现真实图片和卡通图片之间的映射,合成高质量的卡通图像. 受上述2种方法的启发,将CartoonGAN应用到日夜道路场景的风格转换,然而仅使用CartoonGAN会导致部分生成的夜间道路场景图片含有彩色光斑. 受文献[12 ]的启发,添加侧窗盒式滤波模块,提出更适合日夜道路场景图像转换的方法TransCartoonGAN. ...
1
... 生成对抗性网络(generative adversarial networks,GAN)[3 ] 是常见的图像生成方法之一,它在许多应用中产生了不错的结果,如文本到图像的转换[4 ] 、图像修复[5 ] 、图像超分辨率[6 ] 等. 对于像素到像素的图像生成问题,Isola等[7 -8 ] 使用GAN提出解决方案,这些方法需要使用成对图像集,然而获得这样的对应图像集是有挑战的. 为了解决该问题,Zhu等[9 ] 提出CycleGAN,使用未配对的训练数据执行图像转换. Wang等[10 ] 将该方法应用于夜间道路场景语义分割,将日间道路场景数据集Cityscapes进行弱光条件下的风格转换,生成新的数据集Cyclecity,然而该数据集中的图片往往包含蓝色的噪点,部分效果与真实夜间道路场景图像不太相符. Chen等[11 ] 提出CartoonGAN方法,使用未配对的训练数据来实现真实图片和卡通图片之间的映射,合成高质量的卡通图像. 受上述2种方法的启发,将CartoonGAN应用到日夜道路场景的风格转换,然而仅使用CartoonGAN会导致部分生成的夜间道路场景图片含有彩色光斑. 受文献[12 ]的启发,添加侧窗盒式滤波模块,提出更适合日夜道路场景图像转换的方法TransCartoonGAN. ...
1
... 生成对抗性网络(generative adversarial networks,GAN)[3 ] 是常见的图像生成方法之一,它在许多应用中产生了不错的结果,如文本到图像的转换[4 ] 、图像修复[5 ] 、图像超分辨率[6 ] 等. 对于像素到像素的图像生成问题,Isola等[7 -8 ] 使用GAN提出解决方案,这些方法需要使用成对图像集,然而获得这样的对应图像集是有挑战的. 为了解决该问题,Zhu等[9 ] 提出CycleGAN,使用未配对的训练数据执行图像转换. Wang等[10 ] 将该方法应用于夜间道路场景语义分割,将日间道路场景数据集Cityscapes进行弱光条件下的风格转换,生成新的数据集Cyclecity,然而该数据集中的图片往往包含蓝色的噪点,部分效果与真实夜间道路场景图像不太相符. Chen等[11 ] 提出CartoonGAN方法,使用未配对的训练数据来实现真实图片和卡通图片之间的映射,合成高质量的卡通图像. 受上述2种方法的启发,将CartoonGAN应用到日夜道路场景的风格转换,然而仅使用CartoonGAN会导致部分生成的夜间道路场景图片含有彩色光斑. 受文献[12 ]的启发,添加侧窗盒式滤波模块,提出更适合日夜道路场景图像转换的方法TransCartoonGAN. ...
1
... 生成对抗性网络(generative adversarial networks,GAN)[3 ] 是常见的图像生成方法之一,它在许多应用中产生了不错的结果,如文本到图像的转换[4 ] 、图像修复[5 ] 、图像超分辨率[6 ] 等. 对于像素到像素的图像生成问题,Isola等[7 -8 ] 使用GAN提出解决方案,这些方法需要使用成对图像集,然而获得这样的对应图像集是有挑战的. 为了解决该问题,Zhu等[9 ] 提出CycleGAN,使用未配对的训练数据执行图像转换. Wang等[10 ] 将该方法应用于夜间道路场景语义分割,将日间道路场景数据集Cityscapes进行弱光条件下的风格转换,生成新的数据集Cyclecity,然而该数据集中的图片往往包含蓝色的噪点,部分效果与真实夜间道路场景图像不太相符. Chen等[11 ] 提出CartoonGAN方法,使用未配对的训练数据来实现真实图片和卡通图片之间的映射,合成高质量的卡通图像. 受上述2种方法的启发,将CartoonGAN应用到日夜道路场景的风格转换,然而仅使用CartoonGAN会导致部分生成的夜间道路场景图片含有彩色光斑. 受文献[12 ]的启发,添加侧窗盒式滤波模块,提出更适合日夜道路场景图像转换的方法TransCartoonGAN. ...
2
... 生成对抗性网络(generative adversarial networks,GAN)[3 ] 是常见的图像生成方法之一,它在许多应用中产生了不错的结果,如文本到图像的转换[4 ] 、图像修复[5 ] 、图像超分辨率[6 ] 等. 对于像素到像素的图像生成问题,Isola等[7 -8 ] 使用GAN提出解决方案,这些方法需要使用成对图像集,然而获得这样的对应图像集是有挑战的. 为了解决该问题,Zhu等[9 ] 提出CycleGAN,使用未配对的训练数据执行图像转换. Wang等[10 ] 将该方法应用于夜间道路场景语义分割,将日间道路场景数据集Cityscapes进行弱光条件下的风格转换,生成新的数据集Cyclecity,然而该数据集中的图片往往包含蓝色的噪点,部分效果与真实夜间道路场景图像不太相符. Chen等[11 ] 提出CartoonGAN方法,使用未配对的训练数据来实现真实图片和卡通图片之间的映射,合成高质量的卡通图像. 受上述2种方法的启发,将CartoonGAN应用到日夜道路场景的风格转换,然而仅使用CartoonGAN会导致部分生成的夜间道路场景图片含有彩色光斑. 受文献[12 ]的启发,添加侧窗盒式滤波模块,提出更适合日夜道路场景图像转换的方法TransCartoonGAN. ...
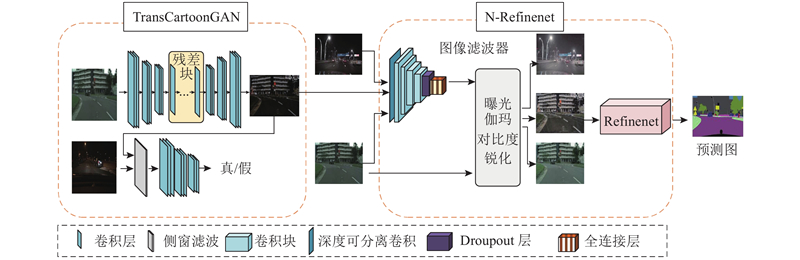
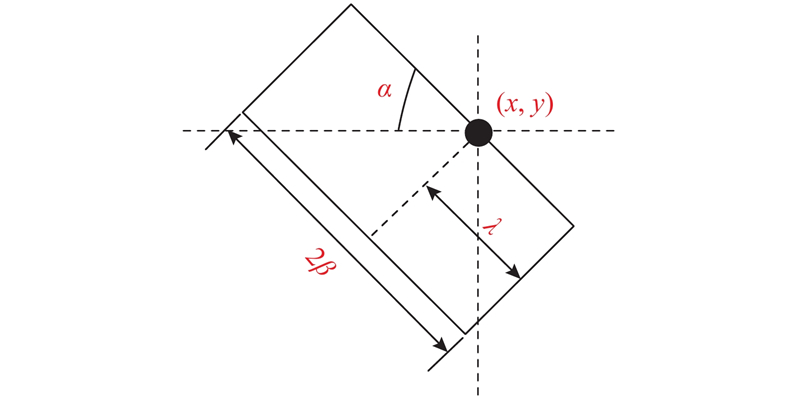
... 该网络主要完成从白天图像到夜间图像的映射转换. 如图3 所示,在生成器模块,采用7×7的卷积层、2个下采样卷积块、8个残差块、2个用于上采样的转置卷积块及1个7×7卷积层. 在判别器模块,采用PatchGAN[7 ] 将每个图像块分类为真实的或合成的. 从合成的或真实的图像中裁剪出尺寸为70×70的重叠块进行训练. 判别器由1个3×3的卷积、LReLU层及3个卷积块组成. 判别器使用较少的参数,可以处理任意大小的图像. 在滤波选择模块,考虑到传统滤波算法在进行滤波处理操作后,图片边缘信息会在一定程度上被平滑掉,采用侧窗盒式滤波,算法的原理如下. ...
1
... 生成对抗性网络(generative adversarial networks,GAN)[3 ] 是常见的图像生成方法之一,它在许多应用中产生了不错的结果,如文本到图像的转换[4 ] 、图像修复[5 ] 、图像超分辨率[6 ] 等. 对于像素到像素的图像生成问题,Isola等[7 -8 ] 使用GAN提出解决方案,这些方法需要使用成对图像集,然而获得这样的对应图像集是有挑战的. 为了解决该问题,Zhu等[9 ] 提出CycleGAN,使用未配对的训练数据执行图像转换. Wang等[10 ] 将该方法应用于夜间道路场景语义分割,将日间道路场景数据集Cityscapes进行弱光条件下的风格转换,生成新的数据集Cyclecity,然而该数据集中的图片往往包含蓝色的噪点,部分效果与真实夜间道路场景图像不太相符. Chen等[11 ] 提出CartoonGAN方法,使用未配对的训练数据来实现真实图片和卡通图片之间的映射,合成高质量的卡通图像. 受上述2种方法的启发,将CartoonGAN应用到日夜道路场景的风格转换,然而仅使用CartoonGAN会导致部分生成的夜间道路场景图片含有彩色光斑. 受文献[12 ]的启发,添加侧窗盒式滤波模块,提出更适合日夜道路场景图像转换的方法TransCartoonGAN. ...
1
... 生成对抗性网络(generative adversarial networks,GAN)[3 ] 是常见的图像生成方法之一,它在许多应用中产生了不错的结果,如文本到图像的转换[4 ] 、图像修复[5 ] 、图像超分辨率[6 ] 等. 对于像素到像素的图像生成问题,Isola等[7 -8 ] 使用GAN提出解决方案,这些方法需要使用成对图像集,然而获得这样的对应图像集是有挑战的. 为了解决该问题,Zhu等[9 ] 提出CycleGAN,使用未配对的训练数据执行图像转换. Wang等[10 ] 将该方法应用于夜间道路场景语义分割,将日间道路场景数据集Cityscapes进行弱光条件下的风格转换,生成新的数据集Cyclecity,然而该数据集中的图片往往包含蓝色的噪点,部分效果与真实夜间道路场景图像不太相符. Chen等[11 ] 提出CartoonGAN方法,使用未配对的训练数据来实现真实图片和卡通图片之间的映射,合成高质量的卡通图像. 受上述2种方法的启发,将CartoonGAN应用到日夜道路场景的风格转换,然而仅使用CartoonGAN会导致部分生成的夜间道路场景图片含有彩色光斑. 受文献[12 ]的启发,添加侧窗盒式滤波模块,提出更适合日夜道路场景图像转换的方法TransCartoonGAN. ...
SFNet-N: an improved SFNet algorithm for semantic segmentation of low-light autonomous driving road scenes
1
2022
... 生成对抗性网络(generative adversarial networks,GAN)[3 ] 是常见的图像生成方法之一,它在许多应用中产生了不错的结果,如文本到图像的转换[4 ] 、图像修复[5 ] 、图像超分辨率[6 ] 等. 对于像素到像素的图像生成问题,Isola等[7 -8 ] 使用GAN提出解决方案,这些方法需要使用成对图像集,然而获得这样的对应图像集是有挑战的. 为了解决该问题,Zhu等[9 ] 提出CycleGAN,使用未配对的训练数据执行图像转换. Wang等[10 ] 将该方法应用于夜间道路场景语义分割,将日间道路场景数据集Cityscapes进行弱光条件下的风格转换,生成新的数据集Cyclecity,然而该数据集中的图片往往包含蓝色的噪点,部分效果与真实夜间道路场景图像不太相符. Chen等[11 ] 提出CartoonGAN方法,使用未配对的训练数据来实现真实图片和卡通图片之间的映射,合成高质量的卡通图像. 受上述2种方法的启发,将CartoonGAN应用到日夜道路场景的风格转换,然而仅使用CartoonGAN会导致部分生成的夜间道路场景图片含有彩色光斑. 受文献[12 ]的启发,添加侧窗盒式滤波模块,提出更适合日夜道路场景图像转换的方法TransCartoonGAN. ...
1
... 生成对抗性网络(generative adversarial networks,GAN)[3 ] 是常见的图像生成方法之一,它在许多应用中产生了不错的结果,如文本到图像的转换[4 ] 、图像修复[5 ] 、图像超分辨率[6 ] 等. 对于像素到像素的图像生成问题,Isola等[7 -8 ] 使用GAN提出解决方案,这些方法需要使用成对图像集,然而获得这样的对应图像集是有挑战的. 为了解决该问题,Zhu等[9 ] 提出CycleGAN,使用未配对的训练数据执行图像转换. Wang等[10 ] 将该方法应用于夜间道路场景语义分割,将日间道路场景数据集Cityscapes进行弱光条件下的风格转换,生成新的数据集Cyclecity,然而该数据集中的图片往往包含蓝色的噪点,部分效果与真实夜间道路场景图像不太相符. Chen等[11 ] 提出CartoonGAN方法,使用未配对的训练数据来实现真实图片和卡通图片之间的映射,合成高质量的卡通图像. 受上述2种方法的启发,将CartoonGAN应用到日夜道路场景的风格转换,然而仅使用CartoonGAN会导致部分生成的夜间道路场景图片含有彩色光斑. 受文献[12 ]的启发,添加侧窗盒式滤波模块,提出更适合日夜道路场景图像转换的方法TransCartoonGAN. ...
1
... 生成对抗性网络(generative adversarial networks,GAN)[3 ] 是常见的图像生成方法之一,它在许多应用中产生了不错的结果,如文本到图像的转换[4 ] 、图像修复[5 ] 、图像超分辨率[6 ] 等. 对于像素到像素的图像生成问题,Isola等[7 -8 ] 使用GAN提出解决方案,这些方法需要使用成对图像集,然而获得这样的对应图像集是有挑战的. 为了解决该问题,Zhu等[9 ] 提出CycleGAN,使用未配对的训练数据执行图像转换. Wang等[10 ] 将该方法应用于夜间道路场景语义分割,将日间道路场景数据集Cityscapes进行弱光条件下的风格转换,生成新的数据集Cyclecity,然而该数据集中的图片往往包含蓝色的噪点,部分效果与真实夜间道路场景图像不太相符. Chen等[11 ] 提出CartoonGAN方法,使用未配对的训练数据来实现真实图片和卡通图片之间的映射,合成高质量的卡通图像. 受上述2种方法的启发,将CartoonGAN应用到日夜道路场景的风格转换,然而仅使用CartoonGAN会导致部分生成的夜间道路场景图片含有彩色光斑. 受文献[12 ]的启发,添加侧窗盒式滤波模块,提出更适合日夜道路场景图像转换的方法TransCartoonGAN. ...
Fully convolutional networks for semantic segmentation
1
2017
... 图像语义分割是许多计算机视觉理解系统的关键,Long等[13 ] 提出全卷积神经网络,将用于图像分类的全连接层替换为全卷积层,使得网络能够对任意大小的图像输出相应的分割结果掩码. Lin等[14 ] 提出Refinenet网络,采用多尺度分析来提取图像全局上下文,保留了低层次的细节. 这些通用的语义分割网络应用于夜间道路场景时,性能较差,因此Bijelic等[15 -16 ] 研究模型对不利条件的适应性. Dai等[17 ] 利用中间黄昏域,逐步将在白天道路场景中训练的语义模型调整为夜间道路场景. Sakaridis等[18 -19 ] 将无监督域适应扩展到指导课程自适应方法,提出从白天到夜间逐渐自适应的分割模型. 这种渐进自适应方法通常需要训练多个语义分割模型. 例如文献[18 ]的3个模型分别用于3个不同的领域,效率较低. Xu等[20 ] 提出CDAda方法,它可以根据领域的难度,分别通过熵最小化和伪标签自训练方法来调整模型. 最近的一些工作使用GAN,有效地减少域间隙. Romera等[21 -22 ] 使用GAN来学习输入图像到输出图像的映射,从2个角度提高了分割性能,包括夜间道路场景图像的直接推断和通过风格转换实时在线推断夜间道路场景图像. Wu等[23 -24 ] 提出无监督的一阶段自适应方法,其中将图像重照明网络放置在分割网络的头部,对抗性学习用于实现标记的白天数据和未标记的夜间数据之间的领域对齐. 额外的重照明网络导致了大量的参数和计算. 针对上述问题,提出低照度道路场景图像自适应增强的分割模块N-Refinenet以及分割方法Trans-nightSeg. ...
1
... 图像语义分割是许多计算机视觉理解系统的关键,Long等[13 ] 提出全卷积神经网络,将用于图像分类的全连接层替换为全卷积层,使得网络能够对任意大小的图像输出相应的分割结果掩码. Lin等[14 ] 提出Refinenet网络,采用多尺度分析来提取图像全局上下文,保留了低层次的细节. 这些通用的语义分割网络应用于夜间道路场景时,性能较差,因此Bijelic等[15 -16 ] 研究模型对不利条件的适应性. Dai等[17 ] 利用中间黄昏域,逐步将在白天道路场景中训练的语义模型调整为夜间道路场景. Sakaridis等[18 -19 ] 将无监督域适应扩展到指导课程自适应方法,提出从白天到夜间逐渐自适应的分割模型. 这种渐进自适应方法通常需要训练多个语义分割模型. 例如文献[18 ]的3个模型分别用于3个不同的领域,效率较低. Xu等[20 ] 提出CDAda方法,它可以根据领域的难度,分别通过熵最小化和伪标签自训练方法来调整模型. 最近的一些工作使用GAN,有效地减少域间隙. Romera等[21 -22 ] 使用GAN来学习输入图像到输出图像的映射,从2个角度提高了分割性能,包括夜间道路场景图像的直接推断和通过风格转换实时在线推断夜间道路场景图像. Wu等[23 -24 ] 提出无监督的一阶段自适应方法,其中将图像重照明网络放置在分割网络的头部,对抗性学习用于实现标记的白天数据和未标记的夜间数据之间的领域对齐. 额外的重照明网络导致了大量的参数和计算. 针对上述问题,提出低照度道路场景图像自适应增强的分割模块N-Refinenet以及分割方法Trans-nightSeg. ...
1
... 图像语义分割是许多计算机视觉理解系统的关键,Long等[13 ] 提出全卷积神经网络,将用于图像分类的全连接层替换为全卷积层,使得网络能够对任意大小的图像输出相应的分割结果掩码. Lin等[14 ] 提出Refinenet网络,采用多尺度分析来提取图像全局上下文,保留了低层次的细节. 这些通用的语义分割网络应用于夜间道路场景时,性能较差,因此Bijelic等[15 -16 ] 研究模型对不利条件的适应性. Dai等[17 ] 利用中间黄昏域,逐步将在白天道路场景中训练的语义模型调整为夜间道路场景. Sakaridis等[18 -19 ] 将无监督域适应扩展到指导课程自适应方法,提出从白天到夜间逐渐自适应的分割模型. 这种渐进自适应方法通常需要训练多个语义分割模型. 例如文献[18 ]的3个模型分别用于3个不同的领域,效率较低. Xu等[20 ] 提出CDAda方法,它可以根据领域的难度,分别通过熵最小化和伪标签自训练方法来调整模型. 最近的一些工作使用GAN,有效地减少域间隙. Romera等[21 -22 ] 使用GAN来学习输入图像到输出图像的映射,从2个角度提高了分割性能,包括夜间道路场景图像的直接推断和通过风格转换实时在线推断夜间道路场景图像. Wu等[23 -24 ] 提出无监督的一阶段自适应方法,其中将图像重照明网络放置在分割网络的头部,对抗性学习用于实现标记的白天数据和未标记的夜间数据之间的领域对齐. 额外的重照明网络导致了大量的参数和计算. 针对上述问题,提出低照度道路场景图像自适应增强的分割模块N-Refinenet以及分割方法Trans-nightSeg. ...
1
... 图像语义分割是许多计算机视觉理解系统的关键,Long等[13 ] 提出全卷积神经网络,将用于图像分类的全连接层替换为全卷积层,使得网络能够对任意大小的图像输出相应的分割结果掩码. Lin等[14 ] 提出Refinenet网络,采用多尺度分析来提取图像全局上下文,保留了低层次的细节. 这些通用的语义分割网络应用于夜间道路场景时,性能较差,因此Bijelic等[15 -16 ] 研究模型对不利条件的适应性. Dai等[17 ] 利用中间黄昏域,逐步将在白天道路场景中训练的语义模型调整为夜间道路场景. Sakaridis等[18 -19 ] 将无监督域适应扩展到指导课程自适应方法,提出从白天到夜间逐渐自适应的分割模型. 这种渐进自适应方法通常需要训练多个语义分割模型. 例如文献[18 ]的3个模型分别用于3个不同的领域,效率较低. Xu等[20 ] 提出CDAda方法,它可以根据领域的难度,分别通过熵最小化和伪标签自训练方法来调整模型. 最近的一些工作使用GAN,有效地减少域间隙. Romera等[21 -22 ] 使用GAN来学习输入图像到输出图像的映射,从2个角度提高了分割性能,包括夜间道路场景图像的直接推断和通过风格转换实时在线推断夜间道路场景图像. Wu等[23 -24 ] 提出无监督的一阶段自适应方法,其中将图像重照明网络放置在分割网络的头部,对抗性学习用于实现标记的白天数据和未标记的夜间数据之间的领域对齐. 额外的重照明网络导致了大量的参数和计算. 针对上述问题,提出低照度道路场景图像自适应增强的分割模块N-Refinenet以及分割方法Trans-nightSeg. ...
3
... 图像语义分割是许多计算机视觉理解系统的关键,Long等[13 ] 提出全卷积神经网络,将用于图像分类的全连接层替换为全卷积层,使得网络能够对任意大小的图像输出相应的分割结果掩码. Lin等[14 ] 提出Refinenet网络,采用多尺度分析来提取图像全局上下文,保留了低层次的细节. 这些通用的语义分割网络应用于夜间道路场景时,性能较差,因此Bijelic等[15 -16 ] 研究模型对不利条件的适应性. Dai等[17 ] 利用中间黄昏域,逐步将在白天道路场景中训练的语义模型调整为夜间道路场景. Sakaridis等[18 -19 ] 将无监督域适应扩展到指导课程自适应方法,提出从白天到夜间逐渐自适应的分割模型. 这种渐进自适应方法通常需要训练多个语义分割模型. 例如文献[18 ]的3个模型分别用于3个不同的领域,效率较低. Xu等[20 ] 提出CDAda方法,它可以根据领域的难度,分别通过熵最小化和伪标签自训练方法来调整模型. 最近的一些工作使用GAN,有效地减少域间隙. Romera等[21 -22 ] 使用GAN来学习输入图像到输出图像的映射,从2个角度提高了分割性能,包括夜间道路场景图像的直接推断和通过风格转换实时在线推断夜间道路场景图像. Wu等[23 -24 ] 提出无监督的一阶段自适应方法,其中将图像重照明网络放置在分割网络的头部,对抗性学习用于实现标记的白天数据和未标记的夜间数据之间的领域对齐. 额外的重照明网络导致了大量的参数和计算. 针对上述问题,提出低照度道路场景图像自适应增强的分割模块N-Refinenet以及分割方法Trans-nightSeg. ...
... 4)Nighttime Driving-test[17 ] :包含50张带有精细标注的夜间道路场景图像,分辨率为1920×1080. 标注的格式与Cityscapes数据集一致,共有19个类.仅使用该数据集对模型的性能进行评估. ...
... 在Dark Zurich-test的在线测试网站提交Trans-nightSeg的分割结果,将获得的IoU与现有的夜间道路分割方法进行比较,主要包括DMAda[17 ] 、GCMA[18 ] 、MGCDA[19 ] 、DANNet[23 ] 、DANIA[24 ] . 由于缺乏大规模标注的夜间道路场景语义分割数据集,以前的方法大多是基于伪标记或未标记图像的领域自适应方法. 如表2 所示为每类IoU性能的比较结果,其中最佳结果被加粗. 与现有方法(DANIA)获得的最高分数相比,Trans-nightSeg在Dark Zurich-test中实现了8.8%的改进. 本研究在一些相关论文中选择5幅常见的图像进行可视化,展示了DMAda、GCMA、MGCDA、DANNet和Trans-nightSeg的几个视觉比较示例,如图7 所示. 通过结果发现,本研究改善了大型类别的视觉质量,如图像3的人行道、图像4的植物及图像5的天空,使得小尺寸物体的边缘更加清晰和平滑,如图像1的人行道边缘及图像2的交通标志. 这表明Trans-nightSeg可以在一定程度上解决夜间道路语义分割的问题. ...
4
... 图像语义分割是许多计算机视觉理解系统的关键,Long等[13 ] 提出全卷积神经网络,将用于图像分类的全连接层替换为全卷积层,使得网络能够对任意大小的图像输出相应的分割结果掩码. Lin等[14 ] 提出Refinenet网络,采用多尺度分析来提取图像全局上下文,保留了低层次的细节. 这些通用的语义分割网络应用于夜间道路场景时,性能较差,因此Bijelic等[15 -16 ] 研究模型对不利条件的适应性. Dai等[17 ] 利用中间黄昏域,逐步将在白天道路场景中训练的语义模型调整为夜间道路场景. Sakaridis等[18 -19 ] 将无监督域适应扩展到指导课程自适应方法,提出从白天到夜间逐渐自适应的分割模型. 这种渐进自适应方法通常需要训练多个语义分割模型. 例如文献[18 ]的3个模型分别用于3个不同的领域,效率较低. Xu等[20 ] 提出CDAda方法,它可以根据领域的难度,分别通过熵最小化和伪标签自训练方法来调整模型. 最近的一些工作使用GAN,有效地减少域间隙. Romera等[21 -22 ] 使用GAN来学习输入图像到输出图像的映射,从2个角度提高了分割性能,包括夜间道路场景图像的直接推断和通过风格转换实时在线推断夜间道路场景图像. Wu等[23 -24 ] 提出无监督的一阶段自适应方法,其中将图像重照明网络放置在分割网络的头部,对抗性学习用于实现标记的白天数据和未标记的夜间数据之间的领域对齐. 额外的重照明网络导致了大量的参数和计算. 针对上述问题,提出低照度道路场景图像自适应增强的分割模块N-Refinenet以及分割方法Trans-nightSeg. ...
... 将无监督域适应扩展到指导课程自适应方法,提出从白天到夜间逐渐自适应的分割模型. 这种渐进自适应方法通常需要训练多个语义分割模型. 例如文献[18 ]的3个模型分别用于3个不同的领域,效率较低. Xu等[20 ] 提出CDAda方法,它可以根据领域的难度,分别通过熵最小化和伪标签自训练方法来调整模型. 最近的一些工作使用GAN,有效地减少域间隙. Romera等[21 -22 ] 使用GAN来学习输入图像到输出图像的映射,从2个角度提高了分割性能,包括夜间道路场景图像的直接推断和通过风格转换实时在线推断夜间道路场景图像. Wu等[23 -24 ] 提出无监督的一阶段自适应方法,其中将图像重照明网络放置在分割网络的头部,对抗性学习用于实现标记的白天数据和未标记的夜间数据之间的领域对齐. 额外的重照明网络导致了大量的参数和计算. 针对上述问题,提出低照度道路场景图像自适应增强的分割模块N-Refinenet以及分割方法Trans-nightSeg. ...
... 5)Dark Zurich[18 ] :Dark Zurich是大型数据集,可以用于无监督语义分割的道路场景. 该数据集包括2416幅夜间图像、2920幅黄昏图像和3041幅日间图像,这些图像都是未标记的,分辨率为1920×1080. Dark Zurich数据集还包括201张带有像素标注的夜间图像,其中50张用于验证,151张用于测试,可以用于定量评估算法的性能. 在在线评估网站Dark Zurich提交分割预测,获得了该算法在Dark Zurich-test上的mIoU结果. ...
... 在Dark Zurich-test的在线测试网站提交Trans-nightSeg的分割结果,将获得的IoU与现有的夜间道路分割方法进行比较,主要包括DMAda[17 ] 、GCMA[18 ] 、MGCDA[19 ] 、DANNet[23 ] 、DANIA[24 ] . 由于缺乏大规模标注的夜间道路场景语义分割数据集,以前的方法大多是基于伪标记或未标记图像的领域自适应方法. 如表2 所示为每类IoU性能的比较结果,其中最佳结果被加粗. 与现有方法(DANIA)获得的最高分数相比,Trans-nightSeg在Dark Zurich-test中实现了8.8%的改进. 本研究在一些相关论文中选择5幅常见的图像进行可视化,展示了DMAda、GCMA、MGCDA、DANNet和Trans-nightSeg的几个视觉比较示例,如图7 所示. 通过结果发现,本研究改善了大型类别的视觉质量,如图像3的人行道、图像4的植物及图像5的天空,使得小尺寸物体的边缘更加清晰和平滑,如图像1的人行道边缘及图像2的交通标志. 这表明Trans-nightSeg可以在一定程度上解决夜间道路语义分割的问题. ...
Map-guided curriculum domain adaptation and uncertainty-aware evaluation for semantic nighttime image segmentation
2
2022
... 图像语义分割是许多计算机视觉理解系统的关键,Long等[13 ] 提出全卷积神经网络,将用于图像分类的全连接层替换为全卷积层,使得网络能够对任意大小的图像输出相应的分割结果掩码. Lin等[14 ] 提出Refinenet网络,采用多尺度分析来提取图像全局上下文,保留了低层次的细节. 这些通用的语义分割网络应用于夜间道路场景时,性能较差,因此Bijelic等[15 -16 ] 研究模型对不利条件的适应性. Dai等[17 ] 利用中间黄昏域,逐步将在白天道路场景中训练的语义模型调整为夜间道路场景. Sakaridis等[18 -19 ] 将无监督域适应扩展到指导课程自适应方法,提出从白天到夜间逐渐自适应的分割模型. 这种渐进自适应方法通常需要训练多个语义分割模型. 例如文献[18 ]的3个模型分别用于3个不同的领域,效率较低. Xu等[20 ] 提出CDAda方法,它可以根据领域的难度,分别通过熵最小化和伪标签自训练方法来调整模型. 最近的一些工作使用GAN,有效地减少域间隙. Romera等[21 -22 ] 使用GAN来学习输入图像到输出图像的映射,从2个角度提高了分割性能,包括夜间道路场景图像的直接推断和通过风格转换实时在线推断夜间道路场景图像. Wu等[23 -24 ] 提出无监督的一阶段自适应方法,其中将图像重照明网络放置在分割网络的头部,对抗性学习用于实现标记的白天数据和未标记的夜间数据之间的领域对齐. 额外的重照明网络导致了大量的参数和计算. 针对上述问题,提出低照度道路场景图像自适应增强的分割模块N-Refinenet以及分割方法Trans-nightSeg. ...
... 在Dark Zurich-test的在线测试网站提交Trans-nightSeg的分割结果,将获得的IoU与现有的夜间道路分割方法进行比较,主要包括DMAda[17 ] 、GCMA[18 ] 、MGCDA[19 ] 、DANNet[23 ] 、DANIA[24 ] . 由于缺乏大规模标注的夜间道路场景语义分割数据集,以前的方法大多是基于伪标记或未标记图像的领域自适应方法. 如表2 所示为每类IoU性能的比较结果,其中最佳结果被加粗. 与现有方法(DANIA)获得的最高分数相比,Trans-nightSeg在Dark Zurich-test中实现了8.8%的改进. 本研究在一些相关论文中选择5幅常见的图像进行可视化,展示了DMAda、GCMA、MGCDA、DANNet和Trans-nightSeg的几个视觉比较示例,如图7 所示. 通过结果发现,本研究改善了大型类别的视觉质量,如图像3的人行道、图像4的植物及图像5的天空,使得小尺寸物体的边缘更加清晰和平滑,如图像1的人行道边缘及图像2的交通标志. 这表明Trans-nightSeg可以在一定程度上解决夜间道路语义分割的问题. ...
1
... 图像语义分割是许多计算机视觉理解系统的关键,Long等[13 ] 提出全卷积神经网络,将用于图像分类的全连接层替换为全卷积层,使得网络能够对任意大小的图像输出相应的分割结果掩码. Lin等[14 ] 提出Refinenet网络,采用多尺度分析来提取图像全局上下文,保留了低层次的细节. 这些通用的语义分割网络应用于夜间道路场景时,性能较差,因此Bijelic等[15 -16 ] 研究模型对不利条件的适应性. Dai等[17 ] 利用中间黄昏域,逐步将在白天道路场景中训练的语义模型调整为夜间道路场景. Sakaridis等[18 -19 ] 将无监督域适应扩展到指导课程自适应方法,提出从白天到夜间逐渐自适应的分割模型. 这种渐进自适应方法通常需要训练多个语义分割模型. 例如文献[18 ]的3个模型分别用于3个不同的领域,效率较低. Xu等[20 ] 提出CDAda方法,它可以根据领域的难度,分别通过熵最小化和伪标签自训练方法来调整模型. 最近的一些工作使用GAN,有效地减少域间隙. Romera等[21 -22 ] 使用GAN来学习输入图像到输出图像的映射,从2个角度提高了分割性能,包括夜间道路场景图像的直接推断和通过风格转换实时在线推断夜间道路场景图像. Wu等[23 -24 ] 提出无监督的一阶段自适应方法,其中将图像重照明网络放置在分割网络的头部,对抗性学习用于实现标记的白天数据和未标记的夜间数据之间的领域对齐. 额外的重照明网络导致了大量的参数和计算. 针对上述问题,提出低照度道路场景图像自适应增强的分割模块N-Refinenet以及分割方法Trans-nightSeg. ...
1
... 图像语义分割是许多计算机视觉理解系统的关键,Long等[13 ] 提出全卷积神经网络,将用于图像分类的全连接层替换为全卷积层,使得网络能够对任意大小的图像输出相应的分割结果掩码. Lin等[14 ] 提出Refinenet网络,采用多尺度分析来提取图像全局上下文,保留了低层次的细节. 这些通用的语义分割网络应用于夜间道路场景时,性能较差,因此Bijelic等[15 -16 ] 研究模型对不利条件的适应性. Dai等[17 ] 利用中间黄昏域,逐步将在白天道路场景中训练的语义模型调整为夜间道路场景. Sakaridis等[18 -19 ] 将无监督域适应扩展到指导课程自适应方法,提出从白天到夜间逐渐自适应的分割模型. 这种渐进自适应方法通常需要训练多个语义分割模型. 例如文献[18 ]的3个模型分别用于3个不同的领域,效率较低. Xu等[20 ] 提出CDAda方法,它可以根据领域的难度,分别通过熵最小化和伪标签自训练方法来调整模型. 最近的一些工作使用GAN,有效地减少域间隙. Romera等[21 -22 ] 使用GAN来学习输入图像到输出图像的映射,从2个角度提高了分割性能,包括夜间道路场景图像的直接推断和通过风格转换实时在线推断夜间道路场景图像. Wu等[23 -24 ] 提出无监督的一阶段自适应方法,其中将图像重照明网络放置在分割网络的头部,对抗性学习用于实现标记的白天数据和未标记的夜间数据之间的领域对齐. 额外的重照明网络导致了大量的参数和计算. 针对上述问题,提出低照度道路场景图像自适应增强的分割模块N-Refinenet以及分割方法Trans-nightSeg. ...
1
... 图像语义分割是许多计算机视觉理解系统的关键,Long等[13 ] 提出全卷积神经网络,将用于图像分类的全连接层替换为全卷积层,使得网络能够对任意大小的图像输出相应的分割结果掩码. Lin等[14 ] 提出Refinenet网络,采用多尺度分析来提取图像全局上下文,保留了低层次的细节. 这些通用的语义分割网络应用于夜间道路场景时,性能较差,因此Bijelic等[15 -16 ] 研究模型对不利条件的适应性. Dai等[17 ] 利用中间黄昏域,逐步将在白天道路场景中训练的语义模型调整为夜间道路场景. Sakaridis等[18 -19 ] 将无监督域适应扩展到指导课程自适应方法,提出从白天到夜间逐渐自适应的分割模型. 这种渐进自适应方法通常需要训练多个语义分割模型. 例如文献[18 ]的3个模型分别用于3个不同的领域,效率较低. Xu等[20 ] 提出CDAda方法,它可以根据领域的难度,分别通过熵最小化和伪标签自训练方法来调整模型. 最近的一些工作使用GAN,有效地减少域间隙. Romera等[21 -22 ] 使用GAN来学习输入图像到输出图像的映射,从2个角度提高了分割性能,包括夜间道路场景图像的直接推断和通过风格转换实时在线推断夜间道路场景图像. Wu等[23 -24 ] 提出无监督的一阶段自适应方法,其中将图像重照明网络放置在分割网络的头部,对抗性学习用于实现标记的白天数据和未标记的夜间数据之间的领域对齐. 额外的重照明网络导致了大量的参数和计算. 针对上述问题,提出低照度道路场景图像自适应增强的分割模块N-Refinenet以及分割方法Trans-nightSeg. ...
3
... 图像语义分割是许多计算机视觉理解系统的关键,Long等[13 ] 提出全卷积神经网络,将用于图像分类的全连接层替换为全卷积层,使得网络能够对任意大小的图像输出相应的分割结果掩码. Lin等[14 ] 提出Refinenet网络,采用多尺度分析来提取图像全局上下文,保留了低层次的细节. 这些通用的语义分割网络应用于夜间道路场景时,性能较差,因此Bijelic等[15 -16 ] 研究模型对不利条件的适应性. Dai等[17 ] 利用中间黄昏域,逐步将在白天道路场景中训练的语义模型调整为夜间道路场景. Sakaridis等[18 -19 ] 将无监督域适应扩展到指导课程自适应方法,提出从白天到夜间逐渐自适应的分割模型. 这种渐进自适应方法通常需要训练多个语义分割模型. 例如文献[18 ]的3个模型分别用于3个不同的领域,效率较低. Xu等[20 ] 提出CDAda方法,它可以根据领域的难度,分别通过熵最小化和伪标签自训练方法来调整模型. 最近的一些工作使用GAN,有效地减少域间隙. Romera等[21 -22 ] 使用GAN来学习输入图像到输出图像的映射,从2个角度提高了分割性能,包括夜间道路场景图像的直接推断和通过风格转换实时在线推断夜间道路场景图像. Wu等[23 -24 ] 提出无监督的一阶段自适应方法,其中将图像重照明网络放置在分割网络的头部,对抗性学习用于实现标记的白天数据和未标记的夜间数据之间的领域对齐. 额外的重照明网络导致了大量的参数和计算. 针对上述问题,提出低照度道路场景图像自适应增强的分割模块N-Refinenet以及分割方法Trans-nightSeg. ...
... 使用重新加权策略[23 ] ,提高网络对小物体的关注. ...
... 在Dark Zurich-test的在线测试网站提交Trans-nightSeg的分割结果,将获得的IoU与现有的夜间道路分割方法进行比较,主要包括DMAda[17 ] 、GCMA[18 ] 、MGCDA[19 ] 、DANNet[23 ] 、DANIA[24 ] . 由于缺乏大规模标注的夜间道路场景语义分割数据集,以前的方法大多是基于伪标记或未标记图像的领域自适应方法. 如表2 所示为每类IoU性能的比较结果,其中最佳结果被加粗. 与现有方法(DANIA)获得的最高分数相比,Trans-nightSeg在Dark Zurich-test中实现了8.8%的改进. 本研究在一些相关论文中选择5幅常见的图像进行可视化,展示了DMAda、GCMA、MGCDA、DANNet和Trans-nightSeg的几个视觉比较示例,如图7 所示. 通过结果发现,本研究改善了大型类别的视觉质量,如图像3的人行道、图像4的植物及图像5的天空,使得小尺寸物体的边缘更加清晰和平滑,如图像1的人行道边缘及图像2的交通标志. 这表明Trans-nightSeg可以在一定程度上解决夜间道路语义分割的问题. ...
A one-stage domain adaptation network with image alignment for unsupervised nighttime semantic segmentation
2
2023
... 图像语义分割是许多计算机视觉理解系统的关键,Long等[13 ] 提出全卷积神经网络,将用于图像分类的全连接层替换为全卷积层,使得网络能够对任意大小的图像输出相应的分割结果掩码. Lin等[14 ] 提出Refinenet网络,采用多尺度分析来提取图像全局上下文,保留了低层次的细节. 这些通用的语义分割网络应用于夜间道路场景时,性能较差,因此Bijelic等[15 -16 ] 研究模型对不利条件的适应性. Dai等[17 ] 利用中间黄昏域,逐步将在白天道路场景中训练的语义模型调整为夜间道路场景. Sakaridis等[18 -19 ] 将无监督域适应扩展到指导课程自适应方法,提出从白天到夜间逐渐自适应的分割模型. 这种渐进自适应方法通常需要训练多个语义分割模型. 例如文献[18 ]的3个模型分别用于3个不同的领域,效率较低. Xu等[20 ] 提出CDAda方法,它可以根据领域的难度,分别通过熵最小化和伪标签自训练方法来调整模型. 最近的一些工作使用GAN,有效地减少域间隙. Romera等[21 -22 ] 使用GAN来学习输入图像到输出图像的映射,从2个角度提高了分割性能,包括夜间道路场景图像的直接推断和通过风格转换实时在线推断夜间道路场景图像. Wu等[23 -24 ] 提出无监督的一阶段自适应方法,其中将图像重照明网络放置在分割网络的头部,对抗性学习用于实现标记的白天数据和未标记的夜间数据之间的领域对齐. 额外的重照明网络导致了大量的参数和计算. 针对上述问题,提出低照度道路场景图像自适应增强的分割模块N-Refinenet以及分割方法Trans-nightSeg. ...
... 在Dark Zurich-test的在线测试网站提交Trans-nightSeg的分割结果,将获得的IoU与现有的夜间道路分割方法进行比较,主要包括DMAda[17 ] 、GCMA[18 ] 、MGCDA[19 ] 、DANNet[23 ] 、DANIA[24 ] . 由于缺乏大规模标注的夜间道路场景语义分割数据集,以前的方法大多是基于伪标记或未标记图像的领域自适应方法. 如表2 所示为每类IoU性能的比较结果,其中最佳结果被加粗. 与现有方法(DANIA)获得的最高分数相比,Trans-nightSeg在Dark Zurich-test中实现了8.8%的改进. 本研究在一些相关论文中选择5幅常见的图像进行可视化,展示了DMAda、GCMA、MGCDA、DANNet和Trans-nightSeg的几个视觉比较示例,如图7 所示. 通过结果发现,本研究改善了大型类别的视觉质量,如图像3的人行道、图像4的植物及图像5的天空,使得小尺寸物体的边缘更加清晰和平滑,如图像1的人行道边缘及图像2的交通标志. 这表明Trans-nightSeg可以在一定程度上解决夜间道路语义分割的问题. ...
Exposure: a white-box photo post-processing framework
1
2018
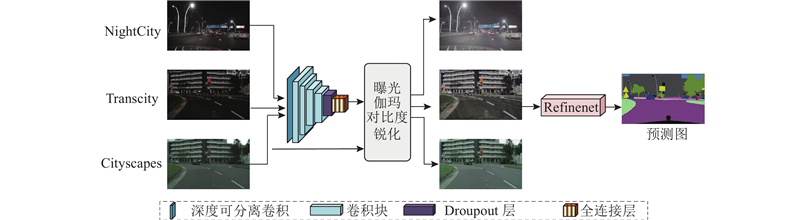
... 夜间道路场景图像亮度较低、细节模糊,导致语义分割困难,每张图像可能包含曝光过度或曝光不足的区域,因此解决夜间分割困难的关键是处理曝光差异. Hu等[25 ] 提出具有一组可微分滤波器的后处理框架,该框架使用深度强化学习来生成滤波器参数. 本研究将该方法添加到Refinenet网络结构的头部,Chollet等[26 -27 ] 提出深度可分离卷积,证明了与普通卷积相比,可以减少计算参数量和计算次数,因此本研究采用深度可分离卷积替代普通的卷积,提出低照度道路场景图像自适应增强的分割模块N-Refinenet. 深度可分离卷积由逐点卷积和空间可分离卷积组成,N-Refinenet模块通过逐点卷积来降低通道数,采用空间可分离卷积对每个通道进行卷积,得到与原始模型相当的精度,减少了计算量. 如图5 所示,该网络输入以下3个数据集进行训练:NightCity、Transcity和Cityscapes. ...
1
... 夜间道路场景图像亮度较低、细节模糊,导致语义分割困难,每张图像可能包含曝光过度或曝光不足的区域,因此解决夜间分割困难的关键是处理曝光差异. Hu等[25 ] 提出具有一组可微分滤波器的后处理框架,该框架使用深度强化学习来生成滤波器参数. 本研究将该方法添加到Refinenet网络结构的头部,Chollet等[26 -27 ] 提出深度可分离卷积,证明了与普通卷积相比,可以减少计算参数量和计算次数,因此本研究采用深度可分离卷积替代普通的卷积,提出低照度道路场景图像自适应增强的分割模块N-Refinenet. 深度可分离卷积由逐点卷积和空间可分离卷积组成,N-Refinenet模块通过逐点卷积来降低通道数,采用空间可分离卷积对每个通道进行卷积,得到与原始模型相当的精度,减少了计算量. 如图5 所示,该网络输入以下3个数据集进行训练:NightCity、Transcity和Cityscapes. ...
1
... 夜间道路场景图像亮度较低、细节模糊,导致语义分割困难,每张图像可能包含曝光过度或曝光不足的区域,因此解决夜间分割困难的关键是处理曝光差异. Hu等[25 ] 提出具有一组可微分滤波器的后处理框架,该框架使用深度强化学习来生成滤波器参数. 本研究将该方法添加到Refinenet网络结构的头部,Chollet等[26 -27 ] 提出深度可分离卷积,证明了与普通卷积相比,可以减少计算参数量和计算次数,因此本研究采用深度可分离卷积替代普通的卷积,提出低照度道路场景图像自适应增强的分割模块N-Refinenet. 深度可分离卷积由逐点卷积和空间可分离卷积组成,N-Refinenet模块通过逐点卷积来降低通道数,采用空间可分离卷积对每个通道进行卷积,得到与原始模型相当的精度,减少了计算量. 如图5 所示,该网络输入以下3个数据集进行训练:NightCity、Transcity和Cityscapes. ...
Nighttime scene parsing with a large real dataset
1
2021
... 3)NightCity[28 ] :NightCity是具有像素级标注的大型数据集,专注于夜间道路场景的语义分割任务. 该数据集有2998张图像用于训练,1299张图像用于验证或测试,均具有19类像素级标注. 标记的对象类与Cityscapes数据集相同. 使用该数据集作为训练数据集. ...
1
... 6)BDD[29 ] :BDD数据集总共有10万张驾驶图像,包含多种场景,如城市街道、住宅区和高速公路. BDD100k包含大量的夜间图像,因此从该数据集中选取4000张夜间道路场景图像作为TransCartoonGAN的目标域. ...









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}