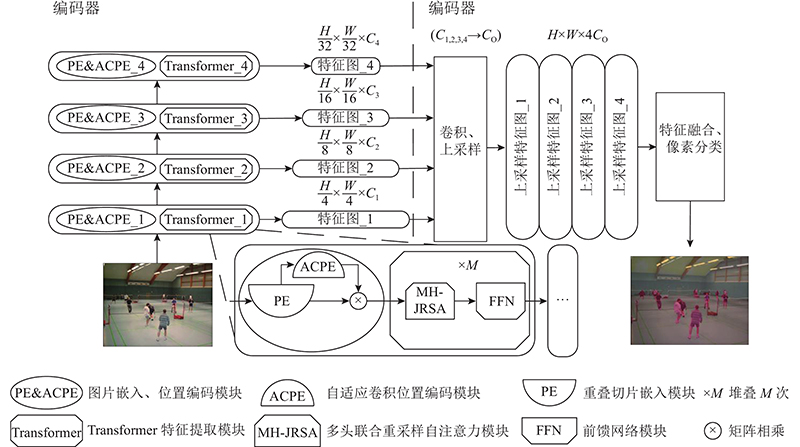
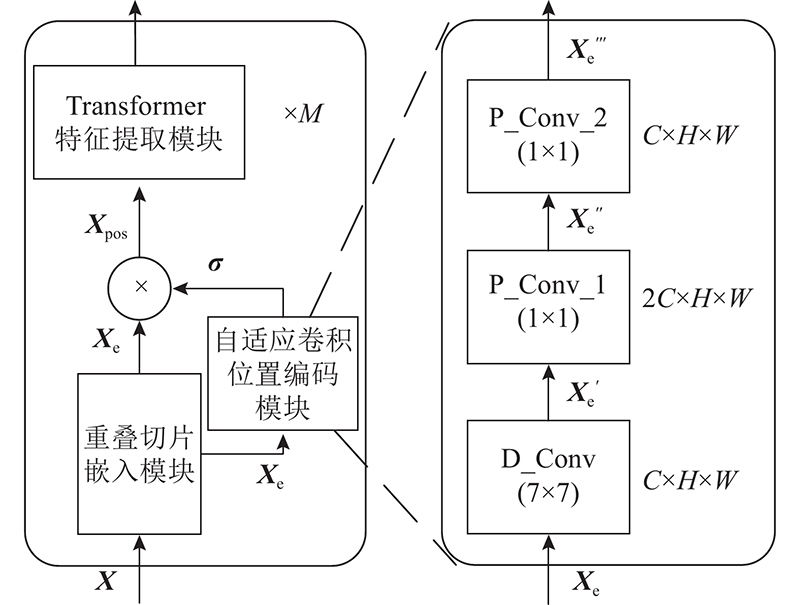
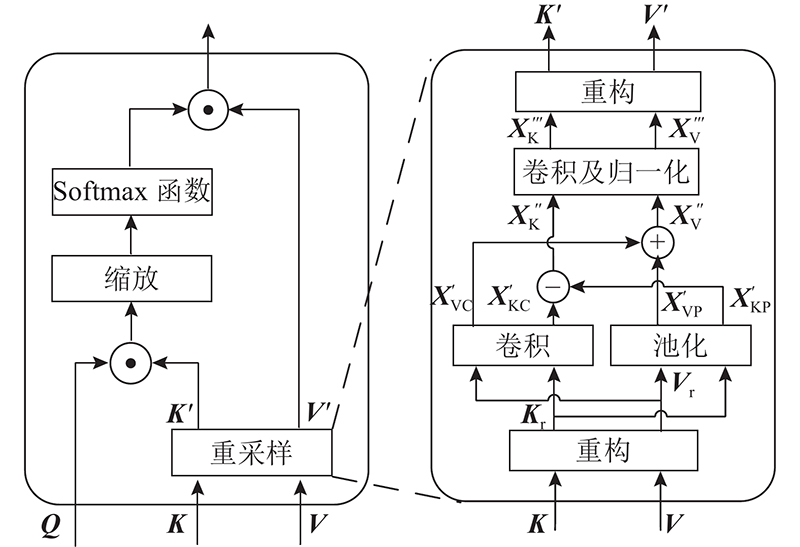
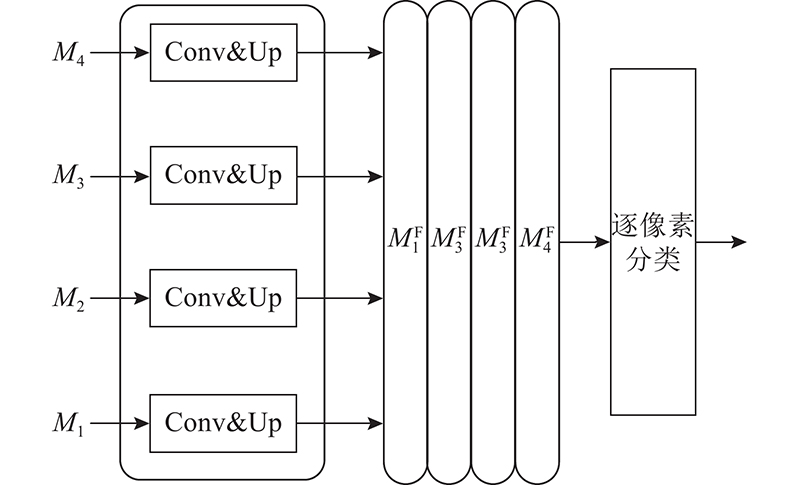
| 计算机与控制工程 |
|


|
|
|
| 基于Transformer的高效自适应语义分割网络 |
张海波1,2( ),蔡磊1,2,任俊平1,2,王汝言1,刘富3 ),蔡磊1,2,任俊平1,2,王汝言1,刘富3 |
1. 重庆邮电大学 通信与信息工程学院,重庆 400065
2. 泛在感知与互联重庆市重点实验室,重庆 400065
3. 重庆市城市照明中心,重庆 400023 |
|
| Efficient and adaptive semantic segmentation network based on Transformer |
| Hai-bo ZHANG1,2(),Lei CAI1,2,Jun-ping REN1,2,Ru-yan WANG1,Fu LIU3 |
1. School of Communications and Information Engineering, Chongqing University of Posts and Telecommunications, Chongqing 400065, China
2. Chongqing Key Laboratory of Ubiquitous Sensing and Networking, Chongqing 400065, China
3. Chongqing Urban Lighting Center, Chongqing 400023, China |
引用本文:
张海波,蔡磊,任俊平,王汝言,刘富. 基于Transformer的高效自适应语义分割网络[J]. 浙江大学学报(工学版), 2023, 57(6): 1205-1214.
Hai-bo ZHANG,Lei CAI,Jun-ping REN,Ru-yan WANG,Fu LIU. Efficient and adaptive semantic segmentation network based on Transformer. Journal of ZheJiang University (Engineering Science), 2023, 57(6): 1205-1214.
链接本文:
https://www.zjujournals.com/eng/CN/10.3785/j.issn.1008-973X.2023.06.016
或
https://www.zjujournals.com/eng/CN/Y2023/V57/I6/1205
|
| 1 |
LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 3431-3440.
|
| 2 |
EVERINGHAM M, ESLAMI S M, VAN G L, et al The Pascal visual object classes challenge: a retrospective[J]. International Journal of Computer Vision, 2015, 111: 98- 136
doi: 10.1007/s11263-014-0733-5
|
| 3 |
ZHAO H, SHI J, QI X, et al. Pyramid scene parsing network [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 2881-2890.
|
| 4 |
CHEN L C, PAPANDREOU G, KOKKINOS I, et al. Semantic image segmentation with deep convolutional nets and fully connected CRFs [EB/OL]. (2016-06-07)[2022-04-25]. https://arxiv.org/pdf/1412.7062.pdf.
|
| 5 |
CHEN L C, PAPANDREOU G, KOKKINOS I, et al Deeplab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 40 (4): 834- 848
|
| 6 |
CHEN L C, PAPANDREOU G, SCHROFF F, et al. Rethinking atrous convolution for semantic image seg-mentation [EB/OL]. (2017-06-17)[2022-04-26]. https://arxiv.org/abs/1706.05587.
|
| 7 |
CHEN L C, ZHU Y, PAPANDREOU G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation [C]// Proceedings of the European Conference on Computer Vision. Munich: Springer, 2018: 801-818.
|
| 8 |
ZHAO H, ZHANG Y, LIU S, et al. PSANet: point-wise spatial attention network for scene parsing [C]// Proceedings of the European Conference on Computer Vision. Munich: Springer, 2018: 267-283.
|
| 9 |
HUANG Z, WANG X, HUANG L, et al. CCNet: criss-cross attention for semantic segmentation [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 603-612.
|
| 10 |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Advances in Neural Information Processing Systems. Long Beach: MIT Press, 2017: 5998-6008.
|
| 11 |
ZHENG S, LU J, ZHAO H, et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers [C]// Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. Nashville: IEEE, 2021: 6881-6890.
|
| 12 |
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: transformers for image recognition at scale [EB/OL]. (2020-10-22)[2022-04-27]. https://arxiv.org/pdf/2010.11929.pdf.
|
| 13 |
ZHOU B, ZHAO H, PUIG X, et al. Scene parsing through ADE20K dataset [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 633-641.
|
| 14 |
ISLAM M A, JIA S, BRUCE N D B. How much p-osition information do convolutional neural networks encode? [EB/OL]. (2020-01-22)[2022-04-28]. https://ar-xiv.org/pdf/2001.08248.pdf.
|
| 15 |
CHU X, TIAN Z, ZHANG B, et al. Conditional posi-tional encodings for vision transformers [EB/OL]. (2021-02-22)[2022-04-29]. https://arxiv.org/pdf/2102.10882.pdf.
|
| 16 |
YUAN K, GUO S, LIU Z, et al. Incorporating conv-olution designs into visual transformers [C]// Proceed-ings of the IEEE/CVF International Conference on Computer Vision. Montreal: IEEE, 2021: 579-588.
|
| 17 |
WU H, XIAO B, CODELLA N, et al. CvT: introducing convolutions to vision transformers [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal: IEEE, 2021: 22-31.
|
| 18 |
CORDTS M, OMRAN M, RAMOS S, et al. The Cityscapes dataset for semantic urban scene understanding [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 3213-3223.
|
| 19 |
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770-778.
|
| 20 |
XIE E, WANG W, YU Z, et al. SegFormer: simple and efficient design for semantic segmentation with transformers [C]// Advances in Neural Information Processing Systems. [S.l.]: MIT Press, 2021: 12077-12090.
|
| 21 |
ZHANG H, WU C, ZHANG Z, et al. ResNeSt: split-attention networks [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. New Orleans: IEEE, 2022: 2736-2746.
|
| 22 |
XIAO T, LIU Y, ZHOU B, et al. Unified perceptual parsing for scene understanding [C]// Proceedings of the European Conference on Computer Vision. Munich: Springer, 2018: 418-434.
|
| 23 |
TOUVRON H, CORD M, DOUZE M, et al. Training data-efficient image transformers & distillation through attention [C]// Proceedings of the 38th International Conference on Machine Learning. [S.l.]: PMLR, 2021: 10347-10357.
|
| 24 |
LIU Z, LIN Y, CAO Y, et al. Swin transformer: hierarchical vision transformer using shifted windows [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal: IEEE, 2021: 10012-10022.
|
| 25 |
LIU Z, MAO H, WU C Y, et al. A convnet for the 2020s [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 11976-11986.
|
| 26 |
YANG J, LI C, ZHANG P, et al. Focal self-attention for local-global interactions in vision transformers [EB/OL]. (2021-07-01)[2022-05-06]. https://arxiv.org/pdf/21-07.00641.pdf.
|
| 27 |
CHEN Z, ZHU Y, ZHAO C, et al. DPT: deformable patch-based transformer for visual recognition [C]// Proceedings of the 29th ACM International Conference on Multimedia. [S.l.]: ACM, 2021: 2899-2907.
|
| 28 |
STRUDEL R, GARCIA R, LAPTEV I, et al. Segmenter: transformer for semantic segmentation [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal: IEEE, 2021: 7262-7272.
|
| 29 |
KIRILLOV A, GIRSHICK R, HE K, et al. Panoptic feature pyramid networks [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 6399-6408.
|
| 30 |
WANG W, XIE E, LI X, et al PVT v2: Improved baselines with pyramid vision transformer[J]. Computational Visual Media, 2022, 8: 415- 424
doi: 10.1007/s41095-022-0274-8
|
| 31 |
GUO M H, LU C Z, LIU Z N, et al. Visual attenti-on network [EB/OL]. (2022-02-20)[2022-05-16]. https://arxiv.org/pdf/2202.09741.pdf.
|
| 32 |
JAIN J, SINGH A, ORLOV N, et al. Semask: seman-tically masked transformers for semantic segmentation[EB/OL]. (2021-12-23)[2022-05-23]. https://arxiv.org/pdf/2112.12782.pdf.
|
| 33 |
YUAN Y, CHEN X, WANG J. Object-contextual representations for semantic segmentation [C]// European Conference on Computer Vision. [S.l.]: Springer, 2020: 173-190.
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|