| 计算机与控制工程 |
|

|
|
|
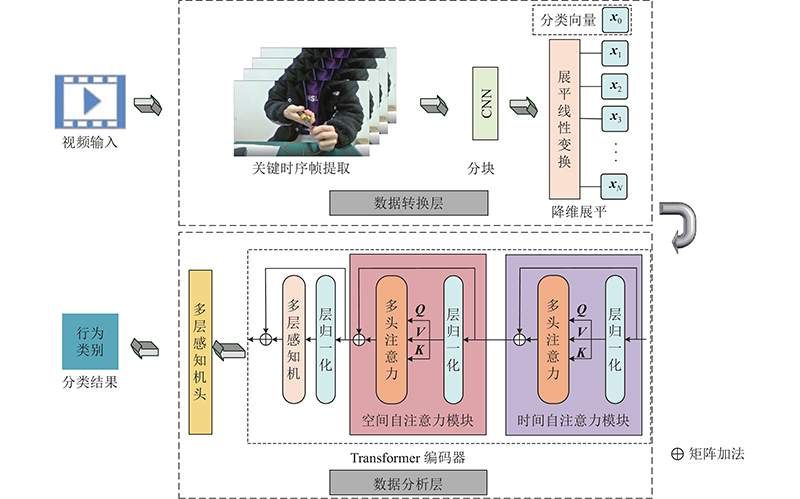
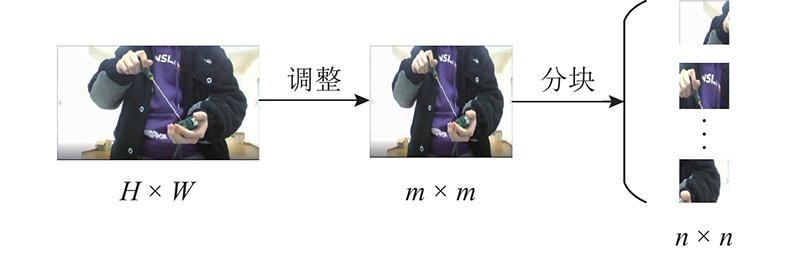
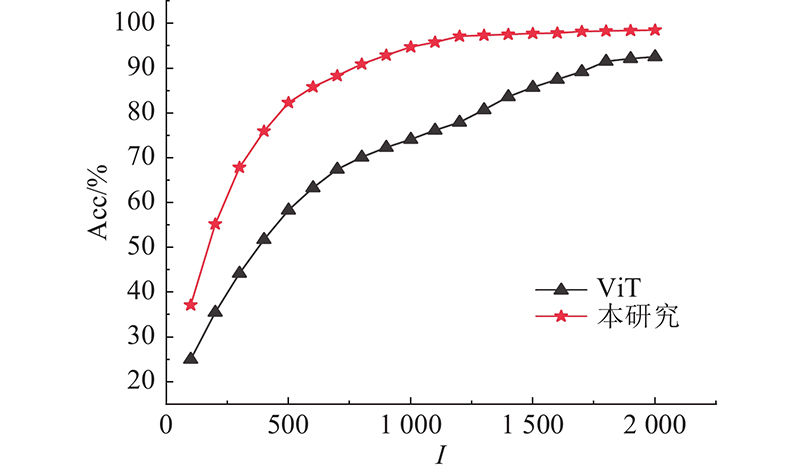
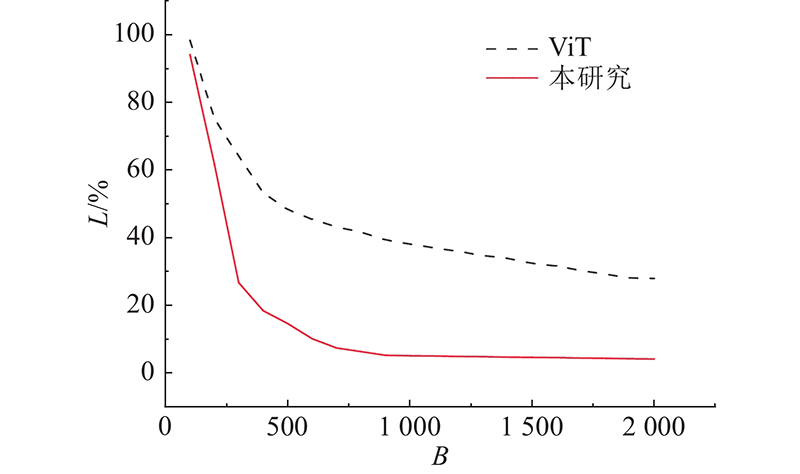
| 基于视觉Transformer时空自注意力的工人行为识别 |
陆昱翔1( ),徐冠华2,*(),唐波1,3 ),徐冠华2,*(),唐波1,3 |
1. 中国计量大学 计量测试工程学院,浙江 杭州 310018
2. 浙江大学 浙江省三维打印工艺与装备重点实验室,流体动力与机电系统国家重点实验室,浙江 杭州 310027
3. 宁波水表(集团) 股份有限公司,浙江 宁波 315033 |
|
| Worker behavior recognition based on temporal and spatial self-attention of vision Transformer |
| Yu-xiang LU1(),Guan-hua XU2,*(),Bo TANG1,3 |
1. College of Metrology and Measurement Engineering, China Jiliang University, Hangzhou 310018, China
2. Zhejiang Province’s Key Laboratory of 3D Printing Process and Equipment, State Key Laboratory of Fluid Power and Mechatronic Systems, Zhejiang University, Hangzhou 310027, China
3. Ningbo Water Meter (Group) Limited Company, Ningbo 315033, China |
| 1 |
LASOTA P A, ROSSANO G F, SHAH J A. Toward safe close-proximity human-robot interaction with standard industrial robots [C]// Proceeding of 2014 IEEE International Conference on Automation Science and Engineering. [S. l.]: IEEE, 2014: 339-344.
|
| 2 |
SCHMIDT B, WANG L Depth camera based collision avoidance via active robot control[J]. Journal of Manufacturing Systems, 2014, 33 (4): 711- 718
doi: 10.1016/j.jmsy.2014.04.004
|
| 3 |
富倩 人体行为识别研究[J]. 信息与电脑, 2017, (24): 146- 147
FU Qian Analysis of human behavior recognition[J]. China Computer and Communication, 2017, (24): 146- 147
doi: 10.3969/j.issn.1003-9767.2017.24.058
|
| 4 |
ZANCHETTIN A M, CASALINO A, PIRODDI L, et al Prediction of human activity patterns for human–robot collaborative assembly tasks[J]. IEEE Transactions on Industrial Informatics, 2019, 15 (7): 3934- 3942
doi: 10.1109/TII.2018.2882741
|
| 5 |
ZANCHETTIN A M, ROCCO P. Probabilistic inference of human arm reaching target for effective human-robot collaboration [C]// Proceeding of 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems. Vancouver: IEEE, 2017: 6595-6600.
|
| 6 |
SIMONYAN K, ZISSERMAN A. Two-stream convolutional networks for action recognition in videos [EB/OL]. [2022-05-03]. https://arxiv.org/pdf/1406.2199.pdf.
|
| 7 |
FEICHTENHOFER C, PINZ A, ZISSERMAN A. Convolutional two-stream network fusion for video action recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 1933-1941.
|
| 8 |
YE Q, LIANG Z, ZHONG H, et al Human behavior recognition based on time correlation sampling two stream heterogeneous grafting network[J]. Optik, 2022, 251: 168402
doi: 10.1016/j.ijleo.2021.168402
|
| 9 |
PENG B, YAO Z, WU Q, et al 3D convolutional neural network for human behavior analysis in intelligent sensor network[J]. Mobile Networks and Applications, 2022, 27: 1559- 1568
doi: 10.1007/s11036-021-01873-8
|
| 10 |
张传雷, 武大硕, 向启怀, 等 基于ResNet-LSTM的具有注意力机制的办公人员行为视频识别[J]. 天津科技大学学报, 2020, 35 (6): 72- 80
ZHANG Chuan-lei, WU Da-shuo, XIANG Qi-huai, et al Office staff behavior recognition based on ResNET-LSTM attention mechanism[J]. Journal of Tianjin University of Science and Technology, 2020, 35 (6): 72- 80
doi: 10.13364/j.issn.1672-6510.20190252
|
| 11 |
YU S, CHENG Y, XIE L, et al A novel recurrent hybrid network for feature fusion in action recognition[J]. Journal of Visual Communication and Image Representation, 2017, 49: 192- 203
doi: 10.1016/j.jvcir.2017.09.007
|
| 12 |
TANBERK S, KILIMCI Z H, TÜKEL D B, et al A hybrid deep model using deep learning and dense optical flow approaches for human activity recognition[J]. IEEE Access, 2020, 8: 19799- 19809
doi: 10.1109/ACCESS.2020.2968529
|
| 13 |
WU J, YANG X, XI M, et al Research on behavior recognition algorithm based on SE-I3D-GRU network[J]. High Technology Letters, 2021, 27 (2): 163- 172
|
| 14 |
VASWANI A, SHAZZER N, PARMAR N, et al. Attention is all you need [EB/OL]. [2022-05-03]. https://arxiv.org/pdf/1706.03762.pdf.
|
| 15 |
PARMAR N, VASWANI A, USZKOREIT J, et al. Image transformer [EB/OL]. [2022-05-03]. https://arxiv.org/pdf/1802.05751.pdf.
|
| 16 |
ZHU X, SU W, LU L, et al. Deformable DETR: deformable transformers for end-to-end object detection [EB/OL]. [2022-05-03]. https://arxiv.org/pdf/2010.04159.pdf.
|
| 17 |
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: transformers for image recognition at scale [EB/OL]. [2022-05-03]. https://arxiv.org/pdf/2010.11929.pdf.
|
| 18 |
ZHOU D, SHI Y, KANG B, et al. Refiner: refining self-attention for vision-transformers[EB/OL]. [2022-05-03]. https://arxiv.org/pdf/2106.03714.pdf.
|
| 19 |
CHEN C F, FAN Q F, PANDA R. CrossViT: cross-attention multi-scale vision transformer for image classification [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal: IEEE, 2021: 347-356.
|
| 20 |
LI G, LIU Z, CAI L, et al Standing-posture recognition in human–robot collaboration based on deep learning and the dempster–shafer evidence theory[J]. Sensors, 2020, 20 (4): 1158
doi: 10.3390/s20041158
|
| 21 |
JIANG J, NAN Z, CHEN H, et al Predicting short-term next-active-object through visual attention and hand position[J]. Neurocomputing, 2021, 433: 212- 222
doi: 10.1016/j.neucom.2020.12.069
|
| 22 |
汪涛, 汪泓章, 夏懿, 等 基于卷积神经网络与注意力模型的人体步态识别[J]. 传感技术学报, 2019, 32 (7): 1027- 1033
WANG Tao, WANG Hong-zhang, XIA Yi, et al Human gait recognition based on convolutional neural network and attention model[J]. Chinese Journal of Sensors and Actuators, 2019, 32 (7): 1027- 1033
doi: 10.3969/j.issn.1004-1699.2019.07.012
|
| 23 |
TRAN D, BOURDEV L, FERGUS R, et al. Learning spatiotemporal features with 3D convolutional networks [C]// Proceedings of the IEEE International Conference on Computer Vision. Santiago: IEEE, 2015: 4489-4497.
|
| 24 |
QIU Z, YAO T, MEI T. Learning spatio-temporal representation with pseudo-3D residual networks [C]// Proceedings of the IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 5533-5541.
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|