Worker behavior recognition based on temporal and spatial self-attention of vision Transformer
LU Yu-xiang,, XU Guan-hua,, TANG Bo
1. College of Metrology and Measurement Engineering, China Jiliang University, Hangzhou 310018, China
2. Zhejiang Province’s Key Laboratory of 3D Printing Process and Equipment, State Key Laboratory of Fluid Power and Mechatronic Systems, Zhejiang University, Hangzhou 310027, China
3. Ningbo Water Meter (Group) Limited Company, Ningbo 315033, China
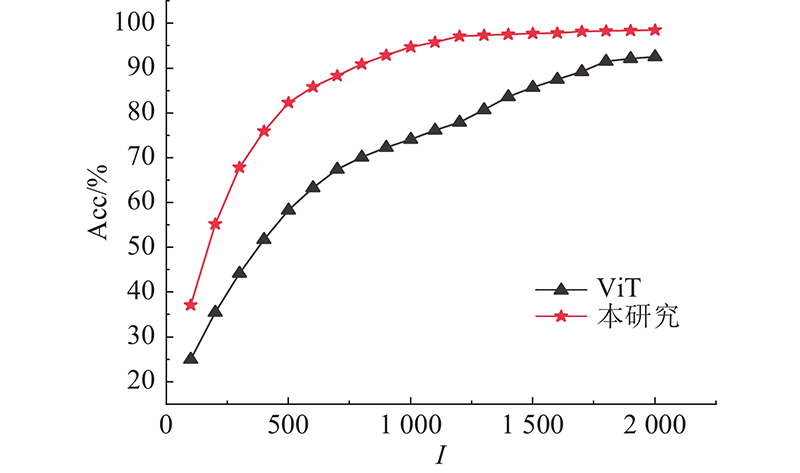
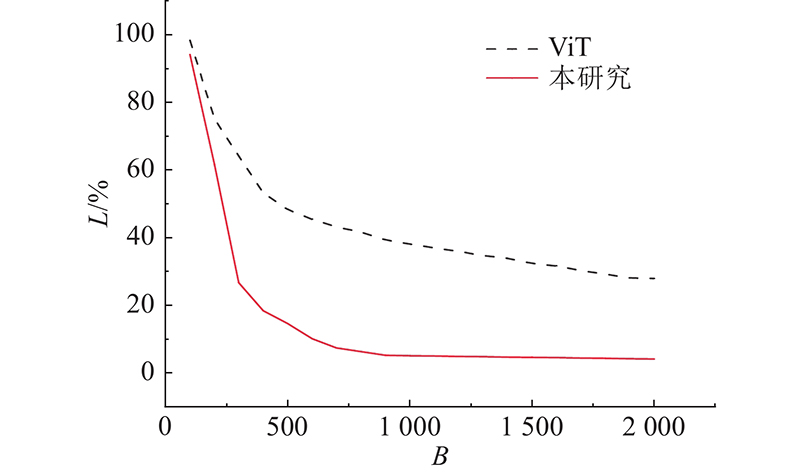
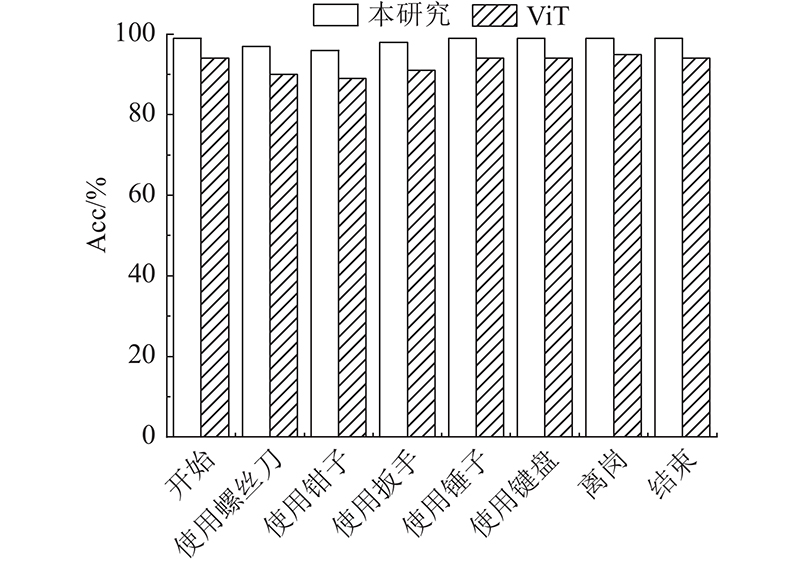
A video human behavior recognition model based on Transformer network structure was proposed, in order to solve the problem of worker behavior recognition in the special scene of human-robot collaboration. The self-attention mechanism at the core of Transformer network was used to reduce the structure complexity and boost the performance of the network. On the basis of extracting the spatial features of the image, a method of adding time features analysis was used to process the video data from two dimensions of space and time. After that, the classification vector was extracted from the processed data, and passed into the classification module to get the final recognition result. Human behavior recognition experiments were carried out on the public dataset UCF101 and the routine behavior dataset of workers collected in the laboratory (a self-built dataset) respectively, in order to verify the effectiveness of the model. Experimental results showed that the average recognition accuracy of the model on UCF101 was 93.44%, and the average recognition accuracy of the model on the self-built dataset was 98.54%.
LU Yu-xiang, XU Guan-hua, TANG Bo. Worker behavior recognition based on temporal and spatial self-attention of vision Transformer. Journal of Zhejiang University(Engineering Science)[J], 2023, 57(3): 446-454 doi:10.3785/j.issn.1008-973X.2023.03.002
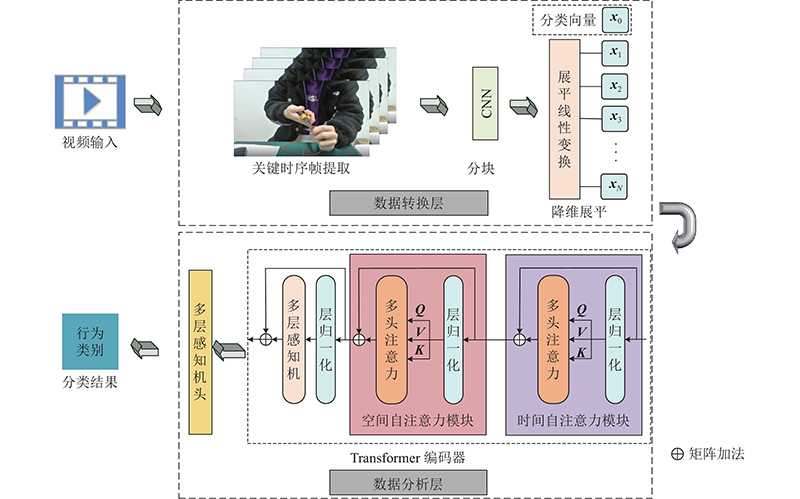
Fig.2
Flowchart of worker behavior recognition model
1.2.1. 数据转换层
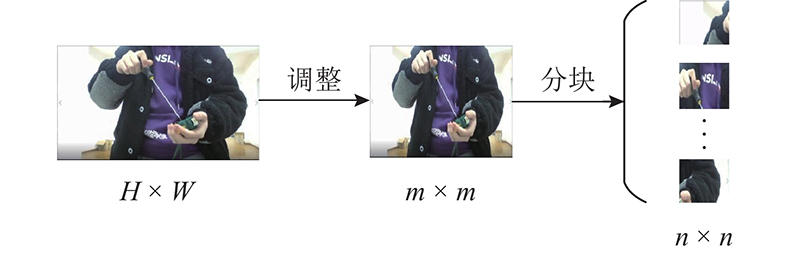
模型的输入为视频数据,每个视频片段由1组 $ F $帧的时序图像组成. 对图像进行分块的预处理,输入的图像数据为 $ H \times W \times C $的三维数据,其中 $ H $、 $ W $分别为图像高和宽, $ C $为通道数. 如图3所示,先将图像的像素大小由 $ H \times W $统一调整为 $ m \times m $,再将图像分成 $ N $个给定的像素大小为 $ n \times n $的图像块,其中 $ N=(m/n)^{2} $为产生的图像块总数. CNN分块部分使用1个卷积核大小为 $ n \times n $像素、步距为 $ n $像素、卷积核个数为 $ C \times {n^2} $的卷积来实现分块和图像维特征向量的提取. 为了减小集合变换的影响,加快模型梯度下降得到最优解,进行归一化处理,将图像像素大小介于[0,255]的图像数据转化为介于[0,1]分布的数据. 假设原始图像数据为x,采用最大最小值的归一化,计算式为
Transformer与RNN的网络结构类似,不具备直接处理图像的功能,要求输入的数据是数字序列形式,即长度为 $ \alpha $、深度为 $\; \beta $的二维矩阵[ $ \alpha $, $\; \beta $],因此须通过线性映射将每个图像块映射到二维矩阵中. 每个形式为[ $ n $, $ n $, $ C $]的块数据通过映射得到长度为 $ C \times {n^2} $像素的向量,即将[ $ m $, $ m $, $ C $]的三维图片转换为[ $ k $, $ k $, $ C \times {n^2} $]的三维数据,其中 $ k = m/n $. 再将 $ H $维度和 $ W $维度展平,即可使[ $ k $, $ k $, $ C \times {n^2} $]的三维数据转换为[ $ N $, $ C \times {n^2} $]的二维图像序列,得到的二维序列 $ {{\boldsymbol{x}}_{(p,t)}} $携带时空信息,其中 $ p $为空间位置, $ t $为时间信息. 在经过上述处理得到的图像序列中,插入专门用于分类的分类向量作为其他图像块寻找的类别信息,其数据格式与转换后的输入序列一致,为长度为 $ C \times {n^2} $的向量. 将分类向量与由输入图片数据生成的向量相互拼接,即将形式为[ $ 1 $, $ C \times {n^2} $]的分类向量序列接入形式为[ $ N $, $ C \times {n^2} $]的图像序列中,使其扩展为[ $ N+1 $, $ C \times {n^2} $]形式的序列. 为了将图像序列转化为二维数字序列,须进行将高维向量转化为低维向量的操作. 具体实现过程为
Fig.4
Screenshots of self-built dataset with eight categories of video
2.2. 数据预处理和增强
将数据集中所有视频片段进行类别标注,标注相同的视频片段分到对应的文件夹中,将视频文件路径和对应的类别信息索引存放到TXT文件中,以便后续训练和验证模型时调取数据集. 在数据集划分方面,将70%的视频行为片段作为训练集,30%的视频行为片段作为测试集. 将视频片段分段处理,依据帧间差分法的原理计算出每2帧之间的帧间差异,选取每段视频帧间差异最大的关键帧为中间帧,采集连续的16帧. 图像无需进行随机裁剪,均匀裁剪为统一大小:224像素×224像素,这里卷积核大小n=16,RGB图像通道数 $ C $=3. 对数据集进行在线增强,包括对图像的随机裁剪、均匀裁剪和随即翻转. 随机裁剪是在图像中任取一点为顶点,截取 $ H \times W $固定大小的区域;均匀裁剪是在图像长边的两端和中点截取 $ H \times W $固定大小的区域;随机翻转是对图像进行随机角度的翻转. 通过在线增强数据集的方法使训练数据扩充,避免实际训练过程中数据集内数据偏少的问题. 在使用模型训练时,对得到的数据先进行增强处理,再把增量后的数据集输入到网络中,同时使用GPU进行优化计算.
LASOTA P A, ROSSANO G F, SHAH J A. Toward safe close-proximity human-robot interaction with standard industrial robots [C]// Proceeding of 2014 IEEE International Conference on Automation Science and Engineering. [S. l.]: IEEE, 2014: 339-344.
ZANCHETTIN A M, ROCCO P. Probabilistic inference of human arm reaching target for effective human-robot collaboration [C]// Proceeding of 2017IEEE/RSJ International Conference on Intelligent Robots and Systems. Vancouver: IEEE, 2017: 6595-6600.
SIMONYAN K, ZISSERMAN A. Two-stream convolutional networks for action recognition in videos [EB/OL]. [2022-05-03]. https://arxiv.org/pdf/1406.2199.pdf.
FEICHTENHOFER C, PINZ A, ZISSERMAN A. Convolutional two-stream network fusion for video action recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 1933-1941.
ZHU X, SU W, LU L, et al. Deformable DETR: deformable transformers for end-to-end object detection [EB/OL]. [2022-05-03]. https://arxiv.org/pdf/2010.04159.pdf.
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: transformers for image recognition at scale [EB/OL]. [2022-05-03]. https://arxiv.org/pdf/2010.11929.pdf.
CHEN C F, FAN Q F, PANDA R. CrossViT: cross-attention multi-scale vision transformer for image classification [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal: IEEE, 2021: 347-356.
TRAN D, BOURDEV L, FERGUS R, et al. Learning spatiotemporal features with 3D convolutional networks [C]// Proceedings of the IEEE International Conference on Computer Vision. Santiago: IEEE, 2015: 4489-4497.
QIU Z, YAO T, MEI T. Learning spatio-temporal representation with pseudo-3D residual networks [C]// Proceedings of the IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 5533-5541.
NG J Y H, HAUSKNECHT M, VIJAYANARASIMHAN S, et al. Beyond short snippets: deep networks for video classification [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 4694-4702.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}