[1]
LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Boston: IEEE, 2015: 3431-3440.
[本文引用: 4]
[2]
EVERINGHAM M, ESLAMI S M, VAN G L, et al The Pascal visual object classes challenge: a retrospective
[J]. International Journal of Computer Vision , 2015 , 111 : 98 - 136
DOI:10.1007/s11263-014-0733-5
[本文引用: 1]
[3]
ZHAO H, SHI J, QI X, et al. Pyramid scene parsing network [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 2881-2890.
[本文引用: 4]
[4]
CHEN L C, PAPANDREOU G, KOKKINOS I, et al. Semantic image segmentation with deep convolutional nets and fully connected CRFs [EB/OL]. (2016-06-07)[2022-04-25]. https://arxiv.org/pdf/1412.7062.pdf.
[本文引用: 1]
[5]
CHEN L C, PAPANDREOU G, KOKKINOS I, et al Deeplab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2017 , 40 (4 ): 834 - 848
[6]
CHEN L C, PAPANDREOU G, SCHROFF F, et al. Rethinking atrous convolution for semantic image seg-mentation [EB/OL]. (2017-06-17)[2022-04-26]. https://arxiv.org/abs/1706.05587.
[本文引用: 2]
[7]
CHEN L C, ZHU Y, PAPANDREOU G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation [C]// Proceedings of the European Conference on Computer Vision . Munich: Springer, 2018: 801-818.
[本文引用: 4]
[8]
ZHAO H, ZHANG Y, LIU S, et al. PSANet: point-wise spatial attention network for scene parsing [C]// Proceedings of the European Conference on Computer Vision . Munich: Springer, 2018: 267-283.
[本文引用: 1]
[9]
HUANG Z, WANG X, HUANG L, et al. CCNet: criss-cross attention for semantic segmentation [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 603-612.
[本文引用: 3]
[10]
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Advances in Neural Information Processing Systems . Long Beach: MIT Press, 2017: 5998-6008.
[本文引用: 1]
[11]
ZHENG S, LU J, ZHAO H, et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers [C]// Proceedings of the IEEE/CVF conference on computer vision and pattern recognition . Nashville: IEEE, 2021: 6881-6890.
[本文引用: 6]
[12]
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: transformers for image recognition at scale [EB/OL]. (2020-10-22)[2022-04-27]. https://arxiv.org/pdf/2010.11929.pdf.
[本文引用: 5]
[13]
ZHOU B, ZHAO H, PUIG X, et al. Scene parsing through ADE20K dataset [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 633-641.
[本文引用: 1]
[14]
ISLAM M A, JIA S, BRUCE N D B. How much p-osition information do convolutional neural networks encode? [EB/OL]. (2020-01-22)[2022-04-28]. https://ar-xiv.org/pdf/2001.08248.pdf.
[本文引用: 1]
[15]
CHU X, TIAN Z, ZHANG B, et al. Conditional posi-tional encodings for vision transformers [EB/OL]. (2021-02-22)[2022-04-29]. https://arxiv.org/pdf/2102.10882.pdf.
[本文引用: 2]
[16]
YUAN K, GUO S, LIU Z, et al. Incorporating conv-olution designs into visual transformers [C]// Proceed-ings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 579-588.
[本文引用: 1]
[17]
WU H, XIAO B, CODELLA N, et al. CvT: introducing convolutions to vision transformers [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 22-31.
[本文引用: 1]
[18]
CORDTS M, OMRAN M, RAMOS S, et al. The Cityscapes dataset for semantic urban scene understanding [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 3213-3223.
[本文引用: 1]
[19]
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 770-778.
[本文引用: 4]
[20]
XIE E, WANG W, YU Z, et al. SegFormer: simple and efficient design for semantic segmentation with transformers [C]// Advances in Neural Information Processing Systems . [S.l.]: MIT Press, 2021: 12077-12090.
[本文引用: 9]
[21]
ZHANG H, WU C, ZHANG Z, et al. ResNeSt: split-attention networks [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops . New Orleans: IEEE, 2022: 2736-2746.
[本文引用: 3]
[22]
XIAO T, LIU Y, ZHOU B, et al. Unified perceptual parsing for scene understanding [C]// Proceedings of the European Conference on Computer Vision . Munich: Springer, 2018: 418-434.
[本文引用: 4]
[23]
TOUVRON H, CORD M, DOUZE M, et al. Training data-efficient image transformers & distillation through attention [C]// Proceedings of the 38 th International Conference on Machine Learning . [S.l.]: PMLR, 2021: 10347-10357.
[本文引用: 1]
[24]
LIU Z, LIN Y, CAO Y, et al. Swin transformer: hierarchical vision transformer using shifted windows [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 10012-10022.
[本文引用: 2]
[25]
LIU Z, MAO H, WU C Y, et al. A convnet for the 2020s [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 11976-11986.
[本文引用: 2]
[26]
YANG J, LI C, ZHANG P, et al. Focal self-attention for local-global interactions in vision transformers [EB/OL]. (2021-07-01)[2022-05-06]. https://arxiv.org/pdf/21-07.00641.pdf.
[本文引用: 1]
[27]
CHEN Z, ZHU Y, ZHAO C, et al. DPT: deformable patch-based transformer for visual recognition [C]// Proceedings of the 29 th ACM International Conference on Multimedia . [S.l.]: ACM, 2021: 2899-2907.
[本文引用: 2]
[28]
STRUDEL R, GARCIA R, LAPTEV I, et al. Segmenter: transformer for semantic segmentation [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 7262-7272.
[本文引用: 3]
[29]
KIRILLOV A, GIRSHICK R, HE K, et al. Panoptic feature pyramid networks [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 6399-6408.
[本文引用: 2]
[30]
WANG W, XIE E, LI X, et al PVT v2: Improved baselines with pyramid vision transformer
[J]. Computational Visual Media , 2022 , 8 : 415 - 424
DOI:10.1007/s41095-022-0274-8
[本文引用: 1]
[31]
GUO M H, LU C Z, LIU Z N, et al. Visual attenti-on network [EB/OL]. (2022-02-20)[2022-05-16]. https://arxiv.org/pdf/2202.09741.pdf.
[本文引用: 1]
[32]
JAIN J, SINGH A, ORLOV N, et al. Semask: seman-tically masked transformers for semantic segmentation[EB/OL]. (2021-12-23)[2022-05-23]. https://arxiv.org/pdf/2112.12782.pdf.
[本文引用: 1]
[33]
YUAN Y, CHEN X, WANG J. Object-contextual representations for semantic segmentation [C]// European Conference on Computer Vision . [S.l.]: Springer, 2020: 173-190.
[本文引用: 1]
[34]
SUN K, XIAO B, LIU D, et al. Deep high-resolution representation learning for human pose estimation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 5686−5696.
[本文引用: 1]
4
... 随着人工智能技术的快速发展和应用,语义分割作为场景理解的基础技术成为视觉领域的研究热点. 作为计算机视觉中的主流任务之一,语义分割被广泛用于如医疗影像分割、视频背景替换和无人驾驶等智能任务. 自Long等[1 ] 提出全卷积神经网络,卷积神经网络(convolutional neural network,CNN)在PASCAL VOC[2 ] 数据集上取得突破性进展,CNN逐渐成为语义分割领域中的主流模型. 随着对CNN研究的深入,学者发现CNN的感受域因其局部性而受限. 网络的感受域对语义分割至关重要,更大的网络感受域能够为网络提供更全面的上下文信息,帮助网络做出正确的判断,改善模型的分割性能. 为了克服CNN的固有缺陷,为网络引入更多空间上下文和多尺度信息,Zhao等[3 ] 提出空间金字塔池化;为了在不显著增加计算量的同时扩大网络感受野,Chen等[4 -7 ] 将标准卷积改为空洞卷积;为了让模型更好地捕获长距离依赖关系,Zhao等[8 -9 ] 引入注意力机制. 这些改进均未彻底解决CNN难以建模长距离依赖关系的问题. ...
... Model evaluation results of different segmentation models on ADE20K dataset
Tab.1 算法 基础网络结构 N /106 GFLOPs mIoU/ FCN[1 ] ResNet-101[19 ] 68.6 275.7 39.9 PSPNet[3 ] ResNet-101 68.1 256.4 44.3 DeepLab-V3+[7 ] ResNet-101 62.7 255.1 45.4 DeepLab-V3+ ResNeSt-101[21 ] 66.3 262.9 46.9 UperNet[22 ] DeiT[23 ] 120.5 90.1 45.3 UperNet Swin-S[24 ] 81.0 259.3 49.3 UperNet Convnext[25 ] 60.2 234.6 46.1 UperNet Focal-B[26 ] 126.0 — 49.0 SETR[11 ] ViT[12 ] 318.5 213.6 47.3 DPT[27 ] ViT 109.7 171.0 46.9 Segmenter Mask[28 ] ViT 102.5 71.1 49.6 Semantic FPN[29 ] PVTv2-B3[30 ] 49.0 62.0 47.3 Semantic FPN VAN-B3[31 ] 49.0 68.0 48.1 SeMask-B FPN[32 ] SeMask Swin 96.0 107.0 49.4 Segformer[20 ] MiT[20 ] 83.9 110.5 50.1 EA-Former MiT 136.4 61.3 49.3 Segformer* MiT 83.9 172.7 52.1 EA-Former * MiT 136.4 95.8 51.0
如表2 所示,以轻量级的MiT-B0为基础网络结构,利用ADE20K数据集训练多种实时语义分割模型,公平地比较模型之间的各项指标,进一步证明EA-Former的高效性. 表中,FPS为模型推理速度. 即使采用相同的基础网络结构MiT-B0,与之前取得最优分割精度的SETR、Segformer、Segmenter等Transformer语义分割模型相比,本研究提出的轻量级EA-Former-T在保持更低的计算量和更高推理速度的同时,mIoU更优. 虽然UperNet分割算法得到的mIoU比EA-Former-T的mIoU更优,但其计算量是EA-Former-T的4倍,且推理速度仅为EA-Former-T的57.9%. 模型对比研究结果表明,EA-Former中JRSA能够有效地降低自注意力机制的计算复杂度、维持分割精度. ...
... Model evaluation results of different segmentation models on Cityscapes dataset
Tab.3 算法 基础网络结构 N /106 GFLOPs mIoU/% FCN[1 ] ResNet-101[19 ] 68.4 619.6 75.5 PSPNet[3 ] ResNet-101 67.9 576.3 79.7 DeepLabV3+[7 ] ResNet-101 62.5 571.6 80.6 CCnet[9 ] ResNet-101 68.8 625.7 79.4 UperNet[22 ] ResNet-101 85.4 576.5 80.1 DeepLabV3[6 ] ResNeSt-101[21 ] 90.8 798.9 80.4 OCRNet[33 ] HRNet[34 ] 70.3 364.7 80.7 SETR[11 ] ViT[12 ] 318.3 818.2 79.3 Segformer[20 ] MiT[20 ] 83.9 597.6 81.8 EA-Former MiT 136.4 137.7 82.1 Segformer# MiT 83.9 735.2 84.1 EA-Former # MiT 136.4 191.8 83.9
为了直观地比较不同算法在Cityscapes数据集上的分割效果,可视化不同算法的分割结果如图6 所示. 可以看出,在方框标注的区域,其他网络的分割效果不理想,除EA-Former外,其他均存在明显的识别错误. 在左侧的分割对比中,DeepLabV3+、SETR和Upernet将公交车的部分错判为火车类,FCN则将公交车的顶部识别为建筑类;在右侧的分割对比中,SETR、UperNet均将汽车的前轮部分判断为卡车类,DeepLabV3+、FCN均将汽车的车门部分误判为墙类. 在方框标出的易错区域,EA-Former成功地分割出正确的语义类别,主要原因是Transformer结构拥有全局感受野和灵活的位置编码方式,使得EA-Former拥有更充分的全局上下文信息和更充沛的空间信息,在处理单个大尺度物体或是物体相互遮挡时,能够结合周围的语义信息做出正确的判断. 虽然SETR中也有Transformer结构,但SETR采用的是相对固定的显式位置编码,且编码器部分使用类ViT的直筒型结构,难以生成不同尺度的特征图,仅将编码器最后一层输出的特征图送入解码器进行分割,导致分割效果不佳. EA-Former使用更加灵活的自适应卷积位置编码和可生成多尺度特征图的金字塔型编码网络,因此EA-Former可以结合低层的空间特征图和高层的语义特征图输出更精准的分割结果. ...
... Evaluation results of inference speed for different segmentation models on ADE20K dataset and Cityscapes dataset
Tab.4 算法 基础网络结构 FPS/(帧 $\cdot {{\rm{s}}^{ - 1} }$ ADE20K Citysapes FCN[1 ] ResNet-101[19 ] 20.7 1.7 PSPNet[3 ] ResNet-101 20.3 1.8 DeepLabV3+[7 ] ResNet-101 18.7 1.6 DeepLabV3+ ResNeSt-101[21 ] 16.1 2.5 UperNet[22 ] Swin-S[24 ] 20.1 — UperNet Convnext[25 ] 17.1 — SETR[11 ] ViT[12 ] 8.3 — DPT[27 ] ViT 20.5 — Segmenter Mask[28 ] ViT 21.3 — Segformer[20 ] MiT[20 ] 18.6 2.5 EA-Former MiT 21.9 2.8 Segformer* MiT 15.7 — EA-Former * MiT 18.1 — UperNet ResNet-101 — 2.3 CCnet[9 ] ResNet-101 — 1.7 DeepLabV3[6 ] ResNeSt-101 — 2.4 SETR ViT — 0.4 Segformer# MiT — 2.3 EA-Former # MiT — 2.5
2.5. 消融实验 2.5.1. 自适应卷积位置编码模块(ACPE)消融实验 为了证明ACPE能灵活处理不同分辨率的图片且不会造成显著性能下降,将Cityscapes数据集中的原始图片裁剪为 $ 768 \times 768 $ $ 768 \times 768 $ $ 832 \times 832 $ $ 1\;024 \times 1\;024 $ $ 1\;024 \times 2\;048 $ 表5 所示. 均不含ACPE的SETR和EA-Former在处理不同分辨率的输入图片时,只能对之前所训练的位置编码进行插值处理,导致模型的分割性能显著下降;含ACPE的EA-Former在处理不同于训练图片分辨率的验证图片时,可以通过零值填充卷积灵活地编码位置信息,使得网络可以维持较高的分割精度,不会造成过高的性能损失. 可以看到,与不含ACPE的算法相比,在处理分辨率为 $ 1\;024 \times 2\;048 $ $ 768 \times 768 $
The Pascal visual object classes challenge: a retrospective
1
2015
... 随着人工智能技术的快速发展和应用,语义分割作为场景理解的基础技术成为视觉领域的研究热点. 作为计算机视觉中的主流任务之一,语义分割被广泛用于如医疗影像分割、视频背景替换和无人驾驶等智能任务. 自Long等[1 ] 提出全卷积神经网络,卷积神经网络(convolutional neural network,CNN)在PASCAL VOC[2 ] 数据集上取得突破性进展,CNN逐渐成为语义分割领域中的主流模型. 随着对CNN研究的深入,学者发现CNN的感受域因其局部性而受限. 网络的感受域对语义分割至关重要,更大的网络感受域能够为网络提供更全面的上下文信息,帮助网络做出正确的判断,改善模型的分割性能. 为了克服CNN的固有缺陷,为网络引入更多空间上下文和多尺度信息,Zhao等[3 ] 提出空间金字塔池化;为了在不显著增加计算量的同时扩大网络感受野,Chen等[4 -7 ] 将标准卷积改为空洞卷积;为了让模型更好地捕获长距离依赖关系,Zhao等[8 -9 ] 引入注意力机制. 这些改进均未彻底解决CNN难以建模长距离依赖关系的问题. ...
4
... 随着人工智能技术的快速发展和应用,语义分割作为场景理解的基础技术成为视觉领域的研究热点. 作为计算机视觉中的主流任务之一,语义分割被广泛用于如医疗影像分割、视频背景替换和无人驾驶等智能任务. 自Long等[1 ] 提出全卷积神经网络,卷积神经网络(convolutional neural network,CNN)在PASCAL VOC[2 ] 数据集上取得突破性进展,CNN逐渐成为语义分割领域中的主流模型. 随着对CNN研究的深入,学者发现CNN的感受域因其局部性而受限. 网络的感受域对语义分割至关重要,更大的网络感受域能够为网络提供更全面的上下文信息,帮助网络做出正确的判断,改善模型的分割性能. 为了克服CNN的固有缺陷,为网络引入更多空间上下文和多尺度信息,Zhao等[3 ] 提出空间金字塔池化;为了在不显著增加计算量的同时扩大网络感受野,Chen等[4 -7 ] 将标准卷积改为空洞卷积;为了让模型更好地捕获长距离依赖关系,Zhao等[8 -9 ] 引入注意力机制. 这些改进均未彻底解决CNN难以建模长距离依赖关系的问题. ...
... Model evaluation results of different segmentation models on ADE20K dataset
Tab.1 算法 基础网络结构 N /106 GFLOPs mIoU/ FCN[1 ] ResNet-101[19 ] 68.6 275.7 39.9 PSPNet[3 ] ResNet-101 68.1 256.4 44.3 DeepLab-V3+[7 ] ResNet-101 62.7 255.1 45.4 DeepLab-V3+ ResNeSt-101[21 ] 66.3 262.9 46.9 UperNet[22 ] DeiT[23 ] 120.5 90.1 45.3 UperNet Swin-S[24 ] 81.0 259.3 49.3 UperNet Convnext[25 ] 60.2 234.6 46.1 UperNet Focal-B[26 ] 126.0 — 49.0 SETR[11 ] ViT[12 ] 318.5 213.6 47.3 DPT[27 ] ViT 109.7 171.0 46.9 Segmenter Mask[28 ] ViT 102.5 71.1 49.6 Semantic FPN[29 ] PVTv2-B3[30 ] 49.0 62.0 47.3 Semantic FPN VAN-B3[31 ] 49.0 68.0 48.1 SeMask-B FPN[32 ] SeMask Swin 96.0 107.0 49.4 Segformer[20 ] MiT[20 ] 83.9 110.5 50.1 EA-Former MiT 136.4 61.3 49.3 Segformer* MiT 83.9 172.7 52.1 EA-Former * MiT 136.4 95.8 51.0
如表2 所示,以轻量级的MiT-B0为基础网络结构,利用ADE20K数据集训练多种实时语义分割模型,公平地比较模型之间的各项指标,进一步证明EA-Former的高效性. 表中,FPS为模型推理速度. 即使采用相同的基础网络结构MiT-B0,与之前取得最优分割精度的SETR、Segformer、Segmenter等Transformer语义分割模型相比,本研究提出的轻量级EA-Former-T在保持更低的计算量和更高推理速度的同时,mIoU更优. 虽然UperNet分割算法得到的mIoU比EA-Former-T的mIoU更优,但其计算量是EA-Former-T的4倍,且推理速度仅为EA-Former-T的57.9%. 模型对比研究结果表明,EA-Former中JRSA能够有效地降低自注意力机制的计算复杂度、维持分割精度. ...
... Model evaluation results of different segmentation models on Cityscapes dataset
Tab.3 算法 基础网络结构 N /106 GFLOPs mIoU/% FCN[1 ] ResNet-101[19 ] 68.4 619.6 75.5 PSPNet[3 ] ResNet-101 67.9 576.3 79.7 DeepLabV3+[7 ] ResNet-101 62.5 571.6 80.6 CCnet[9 ] ResNet-101 68.8 625.7 79.4 UperNet[22 ] ResNet-101 85.4 576.5 80.1 DeepLabV3[6 ] ResNeSt-101[21 ] 90.8 798.9 80.4 OCRNet[33 ] HRNet[34 ] 70.3 364.7 80.7 SETR[11 ] ViT[12 ] 318.3 818.2 79.3 Segformer[20 ] MiT[20 ] 83.9 597.6 81.8 EA-Former MiT 136.4 137.7 82.1 Segformer# MiT 83.9 735.2 84.1 EA-Former # MiT 136.4 191.8 83.9
为了直观地比较不同算法在Cityscapes数据集上的分割效果,可视化不同算法的分割结果如图6 所示. 可以看出,在方框标注的区域,其他网络的分割效果不理想,除EA-Former外,其他均存在明显的识别错误. 在左侧的分割对比中,DeepLabV3+、SETR和Upernet将公交车的部分错判为火车类,FCN则将公交车的顶部识别为建筑类;在右侧的分割对比中,SETR、UperNet均将汽车的前轮部分判断为卡车类,DeepLabV3+、FCN均将汽车的车门部分误判为墙类. 在方框标出的易错区域,EA-Former成功地分割出正确的语义类别,主要原因是Transformer结构拥有全局感受野和灵活的位置编码方式,使得EA-Former拥有更充分的全局上下文信息和更充沛的空间信息,在处理单个大尺度物体或是物体相互遮挡时,能够结合周围的语义信息做出正确的判断. 虽然SETR中也有Transformer结构,但SETR采用的是相对固定的显式位置编码,且编码器部分使用类ViT的直筒型结构,难以生成不同尺度的特征图,仅将编码器最后一层输出的特征图送入解码器进行分割,导致分割效果不佳. EA-Former使用更加灵活的自适应卷积位置编码和可生成多尺度特征图的金字塔型编码网络,因此EA-Former可以结合低层的空间特征图和高层的语义特征图输出更精准的分割结果. ...
... Evaluation results of inference speed for different segmentation models on ADE20K dataset and Cityscapes dataset
Tab.4 算法 基础网络结构 FPS/(帧 $\cdot {{\rm{s}}^{ - 1} }$ ADE20K Citysapes FCN[1 ] ResNet-101[19 ] 20.7 1.7 PSPNet[3 ] ResNet-101 20.3 1.8 DeepLabV3+[7 ] ResNet-101 18.7 1.6 DeepLabV3+ ResNeSt-101[21 ] 16.1 2.5 UperNet[22 ] Swin-S[24 ] 20.1 — UperNet Convnext[25 ] 17.1 — SETR[11 ] ViT[12 ] 8.3 — DPT[27 ] ViT 20.5 — Segmenter Mask[28 ] ViT 21.3 — Segformer[20 ] MiT[20 ] 18.6 2.5 EA-Former MiT 21.9 2.8 Segformer* MiT 15.7 — EA-Former * MiT 18.1 — UperNet ResNet-101 — 2.3 CCnet[9 ] ResNet-101 — 1.7 DeepLabV3[6 ] ResNeSt-101 — 2.4 SETR ViT — 0.4 Segformer# MiT — 2.3 EA-Former # MiT — 2.5
2.5. 消融实验 2.5.1. 自适应卷积位置编码模块(ACPE)消融实验 为了证明ACPE能灵活处理不同分辨率的图片且不会造成显著性能下降,将Cityscapes数据集中的原始图片裁剪为 $ 768 \times 768 $ $ 768 \times 768 $ $ 832 \times 832 $ $ 1\;024 \times 1\;024 $ $ 1\;024 \times 2\;048 $ 表5 所示. 均不含ACPE的SETR和EA-Former在处理不同分辨率的输入图片时,只能对之前所训练的位置编码进行插值处理,导致模型的分割性能显著下降;含ACPE的EA-Former在处理不同于训练图片分辨率的验证图片时,可以通过零值填充卷积灵活地编码位置信息,使得网络可以维持较高的分割精度,不会造成过高的性能损失. 可以看到,与不含ACPE的算法相比,在处理分辨率为 $ 1\;024 \times 2\;048 $ $ 768 \times 768 $
1
... 随着人工智能技术的快速发展和应用,语义分割作为场景理解的基础技术成为视觉领域的研究热点. 作为计算机视觉中的主流任务之一,语义分割被广泛用于如医疗影像分割、视频背景替换和无人驾驶等智能任务. 自Long等[1 ] 提出全卷积神经网络,卷积神经网络(convolutional neural network,CNN)在PASCAL VOC[2 ] 数据集上取得突破性进展,CNN逐渐成为语义分割领域中的主流模型. 随着对CNN研究的深入,学者发现CNN的感受域因其局部性而受限. 网络的感受域对语义分割至关重要,更大的网络感受域能够为网络提供更全面的上下文信息,帮助网络做出正确的判断,改善模型的分割性能. 为了克服CNN的固有缺陷,为网络引入更多空间上下文和多尺度信息,Zhao等[3 ] 提出空间金字塔池化;为了在不显著增加计算量的同时扩大网络感受野,Chen等[4 -7 ] 将标准卷积改为空洞卷积;为了让模型更好地捕获长距离依赖关系,Zhao等[8 -9 ] 引入注意力机制. 这些改进均未彻底解决CNN难以建模长距离依赖关系的问题. ...
Deeplab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs
0
2017
2
... Model evaluation results of different segmentation models on Cityscapes dataset
Tab.3 算法 基础网络结构 N /106 GFLOPs mIoU/% FCN[1 ] ResNet-101[19 ] 68.4 619.6 75.5 PSPNet[3 ] ResNet-101 67.9 576.3 79.7 DeepLabV3+[7 ] ResNet-101 62.5 571.6 80.6 CCnet[9 ] ResNet-101 68.8 625.7 79.4 UperNet[22 ] ResNet-101 85.4 576.5 80.1 DeepLabV3[6 ] ResNeSt-101[21 ] 90.8 798.9 80.4 OCRNet[33 ] HRNet[34 ] 70.3 364.7 80.7 SETR[11 ] ViT[12 ] 318.3 818.2 79.3 Segformer[20 ] MiT[20 ] 83.9 597.6 81.8 EA-Former MiT 136.4 137.7 82.1 Segformer# MiT 83.9 735.2 84.1 EA-Former # MiT 136.4 191.8 83.9
为了直观地比较不同算法在Cityscapes数据集上的分割效果,可视化不同算法的分割结果如图6 所示. 可以看出,在方框标注的区域,其他网络的分割效果不理想,除EA-Former外,其他均存在明显的识别错误. 在左侧的分割对比中,DeepLabV3+、SETR和Upernet将公交车的部分错判为火车类,FCN则将公交车的顶部识别为建筑类;在右侧的分割对比中,SETR、UperNet均将汽车的前轮部分判断为卡车类,DeepLabV3+、FCN均将汽车的车门部分误判为墙类. 在方框标出的易错区域,EA-Former成功地分割出正确的语义类别,主要原因是Transformer结构拥有全局感受野和灵活的位置编码方式,使得EA-Former拥有更充分的全局上下文信息和更充沛的空间信息,在处理单个大尺度物体或是物体相互遮挡时,能够结合周围的语义信息做出正确的判断. 虽然SETR中也有Transformer结构,但SETR采用的是相对固定的显式位置编码,且编码器部分使用类ViT的直筒型结构,难以生成不同尺度的特征图,仅将编码器最后一层输出的特征图送入解码器进行分割,导致分割效果不佳. EA-Former使用更加灵活的自适应卷积位置编码和可生成多尺度特征图的金字塔型编码网络,因此EA-Former可以结合低层的空间特征图和高层的语义特征图输出更精准的分割结果. ...
... Evaluation results of inference speed for different segmentation models on ADE20K dataset and Cityscapes dataset
Tab.4 算法 基础网络结构 FPS/(帧 $\cdot {{\rm{s}}^{ - 1} }$ ADE20K Citysapes FCN[1 ] ResNet-101[19 ] 20.7 1.7 PSPNet[3 ] ResNet-101 20.3 1.8 DeepLabV3+[7 ] ResNet-101 18.7 1.6 DeepLabV3+ ResNeSt-101[21 ] 16.1 2.5 UperNet[22 ] Swin-S[24 ] 20.1 — UperNet Convnext[25 ] 17.1 — SETR[11 ] ViT[12 ] 8.3 — DPT[27 ] ViT 20.5 — Segmenter Mask[28 ] ViT 21.3 — Segformer[20 ] MiT[20 ] 18.6 2.5 EA-Former MiT 21.9 2.8 Segformer* MiT 15.7 — EA-Former * MiT 18.1 — UperNet ResNet-101 — 2.3 CCnet[9 ] ResNet-101 — 1.7 DeepLabV3[6 ] ResNeSt-101 — 2.4 SETR ViT — 0.4 Segformer# MiT — 2.3 EA-Former # MiT — 2.5
2.5. 消融实验 2.5.1. 自适应卷积位置编码模块(ACPE)消融实验 为了证明ACPE能灵活处理不同分辨率的图片且不会造成显著性能下降,将Cityscapes数据集中的原始图片裁剪为 $ 768 \times 768 $ $ 768 \times 768 $ $ 832 \times 832 $ $ 1\;024 \times 1\;024 $ $ 1\;024 \times 2\;048 $ 表5 所示. 均不含ACPE的SETR和EA-Former在处理不同分辨率的输入图片时,只能对之前所训练的位置编码进行插值处理,导致模型的分割性能显著下降;含ACPE的EA-Former在处理不同于训练图片分辨率的验证图片时,可以通过零值填充卷积灵活地编码位置信息,使得网络可以维持较高的分割精度,不会造成过高的性能损失. 可以看到,与不含ACPE的算法相比,在处理分辨率为 $ 1\;024 \times 2\;048 $ $ 768 \times 768 $
4
... 随着人工智能技术的快速发展和应用,语义分割作为场景理解的基础技术成为视觉领域的研究热点. 作为计算机视觉中的主流任务之一,语义分割被广泛用于如医疗影像分割、视频背景替换和无人驾驶等智能任务. 自Long等[1 ] 提出全卷积神经网络,卷积神经网络(convolutional neural network,CNN)在PASCAL VOC[2 ] 数据集上取得突破性进展,CNN逐渐成为语义分割领域中的主流模型. 随着对CNN研究的深入,学者发现CNN的感受域因其局部性而受限. 网络的感受域对语义分割至关重要,更大的网络感受域能够为网络提供更全面的上下文信息,帮助网络做出正确的判断,改善模型的分割性能. 为了克服CNN的固有缺陷,为网络引入更多空间上下文和多尺度信息,Zhao等[3 ] 提出空间金字塔池化;为了在不显著增加计算量的同时扩大网络感受野,Chen等[4 -7 ] 将标准卷积改为空洞卷积;为了让模型更好地捕获长距离依赖关系,Zhao等[8 -9 ] 引入注意力机制. 这些改进均未彻底解决CNN难以建模长距离依赖关系的问题. ...
... Model evaluation results of different segmentation models on ADE20K dataset
Tab.1 算法 基础网络结构 N /106 GFLOPs mIoU/ FCN[1 ] ResNet-101[19 ] 68.6 275.7 39.9 PSPNet[3 ] ResNet-101 68.1 256.4 44.3 DeepLab-V3+[7 ] ResNet-101 62.7 255.1 45.4 DeepLab-V3+ ResNeSt-101[21 ] 66.3 262.9 46.9 UperNet[22 ] DeiT[23 ] 120.5 90.1 45.3 UperNet Swin-S[24 ] 81.0 259.3 49.3 UperNet Convnext[25 ] 60.2 234.6 46.1 UperNet Focal-B[26 ] 126.0 — 49.0 SETR[11 ] ViT[12 ] 318.5 213.6 47.3 DPT[27 ] ViT 109.7 171.0 46.9 Segmenter Mask[28 ] ViT 102.5 71.1 49.6 Semantic FPN[29 ] PVTv2-B3[30 ] 49.0 62.0 47.3 Semantic FPN VAN-B3[31 ] 49.0 68.0 48.1 SeMask-B FPN[32 ] SeMask Swin 96.0 107.0 49.4 Segformer[20 ] MiT[20 ] 83.9 110.5 50.1 EA-Former MiT 136.4 61.3 49.3 Segformer* MiT 83.9 172.7 52.1 EA-Former * MiT 136.4 95.8 51.0
如表2 所示,以轻量级的MiT-B0为基础网络结构,利用ADE20K数据集训练多种实时语义分割模型,公平地比较模型之间的各项指标,进一步证明EA-Former的高效性. 表中,FPS为模型推理速度. 即使采用相同的基础网络结构MiT-B0,与之前取得最优分割精度的SETR、Segformer、Segmenter等Transformer语义分割模型相比,本研究提出的轻量级EA-Former-T在保持更低的计算量和更高推理速度的同时,mIoU更优. 虽然UperNet分割算法得到的mIoU比EA-Former-T的mIoU更优,但其计算量是EA-Former-T的4倍,且推理速度仅为EA-Former-T的57.9%. 模型对比研究结果表明,EA-Former中JRSA能够有效地降低自注意力机制的计算复杂度、维持分割精度. ...
... Model evaluation results of different segmentation models on Cityscapes dataset
Tab.3 算法 基础网络结构 N /106 GFLOPs mIoU/% FCN[1 ] ResNet-101[19 ] 68.4 619.6 75.5 PSPNet[3 ] ResNet-101 67.9 576.3 79.7 DeepLabV3+[7 ] ResNet-101 62.5 571.6 80.6 CCnet[9 ] ResNet-101 68.8 625.7 79.4 UperNet[22 ] ResNet-101 85.4 576.5 80.1 DeepLabV3[6 ] ResNeSt-101[21 ] 90.8 798.9 80.4 OCRNet[33 ] HRNet[34 ] 70.3 364.7 80.7 SETR[11 ] ViT[12 ] 318.3 818.2 79.3 Segformer[20 ] MiT[20 ] 83.9 597.6 81.8 EA-Former MiT 136.4 137.7 82.1 Segformer# MiT 83.9 735.2 84.1 EA-Former # MiT 136.4 191.8 83.9
为了直观地比较不同算法在Cityscapes数据集上的分割效果,可视化不同算法的分割结果如图6 所示. 可以看出,在方框标注的区域,其他网络的分割效果不理想,除EA-Former外,其他均存在明显的识别错误. 在左侧的分割对比中,DeepLabV3+、SETR和Upernet将公交车的部分错判为火车类,FCN则将公交车的顶部识别为建筑类;在右侧的分割对比中,SETR、UperNet均将汽车的前轮部分判断为卡车类,DeepLabV3+、FCN均将汽车的车门部分误判为墙类. 在方框标出的易错区域,EA-Former成功地分割出正确的语义类别,主要原因是Transformer结构拥有全局感受野和灵活的位置编码方式,使得EA-Former拥有更充分的全局上下文信息和更充沛的空间信息,在处理单个大尺度物体或是物体相互遮挡时,能够结合周围的语义信息做出正确的判断. 虽然SETR中也有Transformer结构,但SETR采用的是相对固定的显式位置编码,且编码器部分使用类ViT的直筒型结构,难以生成不同尺度的特征图,仅将编码器最后一层输出的特征图送入解码器进行分割,导致分割效果不佳. EA-Former使用更加灵活的自适应卷积位置编码和可生成多尺度特征图的金字塔型编码网络,因此EA-Former可以结合低层的空间特征图和高层的语义特征图输出更精准的分割结果. ...
... Evaluation results of inference speed for different segmentation models on ADE20K dataset and Cityscapes dataset
Tab.4 算法 基础网络结构 FPS/(帧 $\cdot {{\rm{s}}^{ - 1} }$ ADE20K Citysapes FCN[1 ] ResNet-101[19 ] 20.7 1.7 PSPNet[3 ] ResNet-101 20.3 1.8 DeepLabV3+[7 ] ResNet-101 18.7 1.6 DeepLabV3+ ResNeSt-101[21 ] 16.1 2.5 UperNet[22 ] Swin-S[24 ] 20.1 — UperNet Convnext[25 ] 17.1 — SETR[11 ] ViT[12 ] 8.3 — DPT[27 ] ViT 20.5 — Segmenter Mask[28 ] ViT 21.3 — Segformer[20 ] MiT[20 ] 18.6 2.5 EA-Former MiT 21.9 2.8 Segformer* MiT 15.7 — EA-Former * MiT 18.1 — UperNet ResNet-101 — 2.3 CCnet[9 ] ResNet-101 — 1.7 DeepLabV3[6 ] ResNeSt-101 — 2.4 SETR ViT — 0.4 Segformer# MiT — 2.3 EA-Former # MiT — 2.5
2.5. 消融实验 2.5.1. 自适应卷积位置编码模块(ACPE)消融实验 为了证明ACPE能灵活处理不同分辨率的图片且不会造成显著性能下降,将Cityscapes数据集中的原始图片裁剪为 $ 768 \times 768 $ $ 768 \times 768 $ $ 832 \times 832 $ $ 1\;024 \times 1\;024 $ $ 1\;024 \times 2\;048 $ 表5 所示. 均不含ACPE的SETR和EA-Former在处理不同分辨率的输入图片时,只能对之前所训练的位置编码进行插值处理,导致模型的分割性能显著下降;含ACPE的EA-Former在处理不同于训练图片分辨率的验证图片时,可以通过零值填充卷积灵活地编码位置信息,使得网络可以维持较高的分割精度,不会造成过高的性能损失. 可以看到,与不含ACPE的算法相比,在处理分辨率为 $ 1\;024 \times 2\;048 $ $ 768 \times 768 $
1
... 随着人工智能技术的快速发展和应用,语义分割作为场景理解的基础技术成为视觉领域的研究热点. 作为计算机视觉中的主流任务之一,语义分割被广泛用于如医疗影像分割、视频背景替换和无人驾驶等智能任务. 自Long等[1 ] 提出全卷积神经网络,卷积神经网络(convolutional neural network,CNN)在PASCAL VOC[2 ] 数据集上取得突破性进展,CNN逐渐成为语义分割领域中的主流模型. 随着对CNN研究的深入,学者发现CNN的感受域因其局部性而受限. 网络的感受域对语义分割至关重要,更大的网络感受域能够为网络提供更全面的上下文信息,帮助网络做出正确的判断,改善模型的分割性能. 为了克服CNN的固有缺陷,为网络引入更多空间上下文和多尺度信息,Zhao等[3 ] 提出空间金字塔池化;为了在不显著增加计算量的同时扩大网络感受野,Chen等[4 -7 ] 将标准卷积改为空洞卷积;为了让模型更好地捕获长距离依赖关系,Zhao等[8 -9 ] 引入注意力机制. 这些改进均未彻底解决CNN难以建模长距离依赖关系的问题. ...
3
... 随着人工智能技术的快速发展和应用,语义分割作为场景理解的基础技术成为视觉领域的研究热点. 作为计算机视觉中的主流任务之一,语义分割被广泛用于如医疗影像分割、视频背景替换和无人驾驶等智能任务. 自Long等[1 ] 提出全卷积神经网络,卷积神经网络(convolutional neural network,CNN)在PASCAL VOC[2 ] 数据集上取得突破性进展,CNN逐渐成为语义分割领域中的主流模型. 随着对CNN研究的深入,学者发现CNN的感受域因其局部性而受限. 网络的感受域对语义分割至关重要,更大的网络感受域能够为网络提供更全面的上下文信息,帮助网络做出正确的判断,改善模型的分割性能. 为了克服CNN的固有缺陷,为网络引入更多空间上下文和多尺度信息,Zhao等[3 ] 提出空间金字塔池化;为了在不显著增加计算量的同时扩大网络感受野,Chen等[4 -7 ] 将标准卷积改为空洞卷积;为了让模型更好地捕获长距离依赖关系,Zhao等[8 -9 ] 引入注意力机制. 这些改进均未彻底解决CNN难以建模长距离依赖关系的问题. ...
... Model evaluation results of different segmentation models on Cityscapes dataset
Tab.3 算法 基础网络结构 N /106 GFLOPs mIoU/% FCN[1 ] ResNet-101[19 ] 68.4 619.6 75.5 PSPNet[3 ] ResNet-101 67.9 576.3 79.7 DeepLabV3+[7 ] ResNet-101 62.5 571.6 80.6 CCnet[9 ] ResNet-101 68.8 625.7 79.4 UperNet[22 ] ResNet-101 85.4 576.5 80.1 DeepLabV3[6 ] ResNeSt-101[21 ] 90.8 798.9 80.4 OCRNet[33 ] HRNet[34 ] 70.3 364.7 80.7 SETR[11 ] ViT[12 ] 318.3 818.2 79.3 Segformer[20 ] MiT[20 ] 83.9 597.6 81.8 EA-Former MiT 136.4 137.7 82.1 Segformer# MiT 83.9 735.2 84.1 EA-Former # MiT 136.4 191.8 83.9
为了直观地比较不同算法在Cityscapes数据集上的分割效果,可视化不同算法的分割结果如图6 所示. 可以看出,在方框标注的区域,其他网络的分割效果不理想,除EA-Former外,其他均存在明显的识别错误. 在左侧的分割对比中,DeepLabV3+、SETR和Upernet将公交车的部分错判为火车类,FCN则将公交车的顶部识别为建筑类;在右侧的分割对比中,SETR、UperNet均将汽车的前轮部分判断为卡车类,DeepLabV3+、FCN均将汽车的车门部分误判为墙类. 在方框标出的易错区域,EA-Former成功地分割出正确的语义类别,主要原因是Transformer结构拥有全局感受野和灵活的位置编码方式,使得EA-Former拥有更充分的全局上下文信息和更充沛的空间信息,在处理单个大尺度物体或是物体相互遮挡时,能够结合周围的语义信息做出正确的判断. 虽然SETR中也有Transformer结构,但SETR采用的是相对固定的显式位置编码,且编码器部分使用类ViT的直筒型结构,难以生成不同尺度的特征图,仅将编码器最后一层输出的特征图送入解码器进行分割,导致分割效果不佳. EA-Former使用更加灵活的自适应卷积位置编码和可生成多尺度特征图的金字塔型编码网络,因此EA-Former可以结合低层的空间特征图和高层的语义特征图输出更精准的分割结果. ...
... Evaluation results of inference speed for different segmentation models on ADE20K dataset and Cityscapes dataset
Tab.4 算法 基础网络结构 FPS/(帧 $\cdot {{\rm{s}}^{ - 1} }$ ADE20K Citysapes FCN[1 ] ResNet-101[19 ] 20.7 1.7 PSPNet[3 ] ResNet-101 20.3 1.8 DeepLabV3+[7 ] ResNet-101 18.7 1.6 DeepLabV3+ ResNeSt-101[21 ] 16.1 2.5 UperNet[22 ] Swin-S[24 ] 20.1 — UperNet Convnext[25 ] 17.1 — SETR[11 ] ViT[12 ] 8.3 — DPT[27 ] ViT 20.5 — Segmenter Mask[28 ] ViT 21.3 — Segformer[20 ] MiT[20 ] 18.6 2.5 EA-Former MiT 21.9 2.8 Segformer* MiT 15.7 — EA-Former * MiT 18.1 — UperNet ResNet-101 — 2.3 CCnet[9 ] ResNet-101 — 1.7 DeepLabV3[6 ] ResNeSt-101 — 2.4 SETR ViT — 0.4 Segformer# MiT — 2.3 EA-Former # MiT — 2.5
2.5. 消融实验 2.5.1. 自适应卷积位置编码模块(ACPE)消融实验 为了证明ACPE能灵活处理不同分辨率的图片且不会造成显著性能下降,将Cityscapes数据集中的原始图片裁剪为 $ 768 \times 768 $ $ 768 \times 768 $ $ 832 \times 832 $ $ 1\;024 \times 1\;024 $ $ 1\;024 \times 2\;048 $ 表5 所示. 均不含ACPE的SETR和EA-Former在处理不同分辨率的输入图片时,只能对之前所训练的位置编码进行插值处理,导致模型的分割性能显著下降;含ACPE的EA-Former在处理不同于训练图片分辨率的验证图片时,可以通过零值填充卷积灵活地编码位置信息,使得网络可以维持较高的分割精度,不会造成过高的性能损失. 可以看到,与不含ACPE的算法相比,在处理分辨率为 $ 1\;024 \times 2\;048 $ $ 768 \times 768 $
1
... Vaswani等[10 ] 提出单层即拥有全局感受野的Transformer结构. 之后,Transformer结构被引入计算机视觉领域,在大型图像数据集上,Transformer网络得到超越CNN最优模型的效果,如Zheng等[11 ] 提出的Transformer语义分割模型SETR,是将Transformer结构用于语义分割任务并取得显著提升的模型,SETR模型中的特征提取网络由Dosovitskiy等[12 ] 提出的Transformer编码器构成,结合所设计的分割头,在ADE20K[13 ] 数据集上超过了当时的最优水平. 将标准的Transformer结构直接用于语义分割任务存在以下不足:1)大部分Transformer视觉网络采用相对固定的位置编码方式为嵌入向量提供位置信息,当测试图片与训练图片分辨率不同时,采用该方式的模型难以自适应地生成合适的位置编码,只能对之前的位置编码向量进行插值处理,这通常会造成模型的性能显著下降. 2)在标准Transformer结构中,自注意力计算会产生与输入图像分辨率成平方倍的计算复杂度,而语义分割通常处理的都是高分辨率输入图片,因此计算复杂度过高、参数量过大的问题在语义分割任务中尤为突出. ...
6
... Vaswani等[10 ] 提出单层即拥有全局感受野的Transformer结构. 之后,Transformer结构被引入计算机视觉领域,在大型图像数据集上,Transformer网络得到超越CNN最优模型的效果,如Zheng等[11 ] 提出的Transformer语义分割模型SETR,是将Transformer结构用于语义分割任务并取得显著提升的模型,SETR模型中的特征提取网络由Dosovitskiy等[12 ] 提出的Transformer编码器构成,结合所设计的分割头,在ADE20K[13 ] 数据集上超过了当时的最优水平. 将标准的Transformer结构直接用于语义分割任务存在以下不足:1)大部分Transformer视觉网络采用相对固定的位置编码方式为嵌入向量提供位置信息,当测试图片与训练图片分辨率不同时,采用该方式的模型难以自适应地生成合适的位置编码,只能对之前的位置编码向量进行插值处理,这通常会造成模型的性能显著下降. 2)在标准Transformer结构中,自注意力计算会产生与输入图像分辨率成平方倍的计算复杂度,而语义分割通常处理的都是高分辨率输入图片,因此计算复杂度过高、参数量过大的问题在语义分割任务中尤为突出. ...
... Model evaluation results of different segmentation models on ADE20K dataset
Tab.1 算法 基础网络结构 N /106 GFLOPs mIoU/ FCN[1 ] ResNet-101[19 ] 68.6 275.7 39.9 PSPNet[3 ] ResNet-101 68.1 256.4 44.3 DeepLab-V3+[7 ] ResNet-101 62.7 255.1 45.4 DeepLab-V3+ ResNeSt-101[21 ] 66.3 262.9 46.9 UperNet[22 ] DeiT[23 ] 120.5 90.1 45.3 UperNet Swin-S[24 ] 81.0 259.3 49.3 UperNet Convnext[25 ] 60.2 234.6 46.1 UperNet Focal-B[26 ] 126.0 — 49.0 SETR[11 ] ViT[12 ] 318.5 213.6 47.3 DPT[27 ] ViT 109.7 171.0 46.9 Segmenter Mask[28 ] ViT 102.5 71.1 49.6 Semantic FPN[29 ] PVTv2-B3[30 ] 49.0 62.0 47.3 Semantic FPN VAN-B3[31 ] 49.0 68.0 48.1 SeMask-B FPN[32 ] SeMask Swin 96.0 107.0 49.4 Segformer[20 ] MiT[20 ] 83.9 110.5 50.1 EA-Former MiT 136.4 61.3 49.3 Segformer* MiT 83.9 172.7 52.1 EA-Former * MiT 136.4 95.8 51.0
如表2 所示,以轻量级的MiT-B0为基础网络结构,利用ADE20K数据集训练多种实时语义分割模型,公平地比较模型之间的各项指标,进一步证明EA-Former的高效性. 表中,FPS为模型推理速度. 即使采用相同的基础网络结构MiT-B0,与之前取得最优分割精度的SETR、Segformer、Segmenter等Transformer语义分割模型相比,本研究提出的轻量级EA-Former-T在保持更低的计算量和更高推理速度的同时,mIoU更优. 虽然UperNet分割算法得到的mIoU比EA-Former-T的mIoU更优,但其计算量是EA-Former-T的4倍,且推理速度仅为EA-Former-T的57.9%. 模型对比研究结果表明,EA-Former中JRSA能够有效地降低自注意力机制的计算复杂度、维持分割精度. ...
... Model evaluation results of lightweight segmentation models on ADE20K dataset
Tab.2 算法 基础网络结构 GFLOPs FPS/ $ \cdot {{\rm{s}}^{ - 1}} $ mIoU/ SETR[11 ] MiT-B0[20 ] 25.3 28.7 34.8 Segformer[20 ] MiT-B0 8.6 50.5 37.5 UperNet[22 ] MiT-B0 28.5 29.6 39.3 Segmenter[28 ] MiT-B0 7.9 49.2 35.9 Semantic FPN[29 ] MiT-B0 23.0 46.4 37.1 EA-Former-T MiT-B0 7.1 51.1 38.1
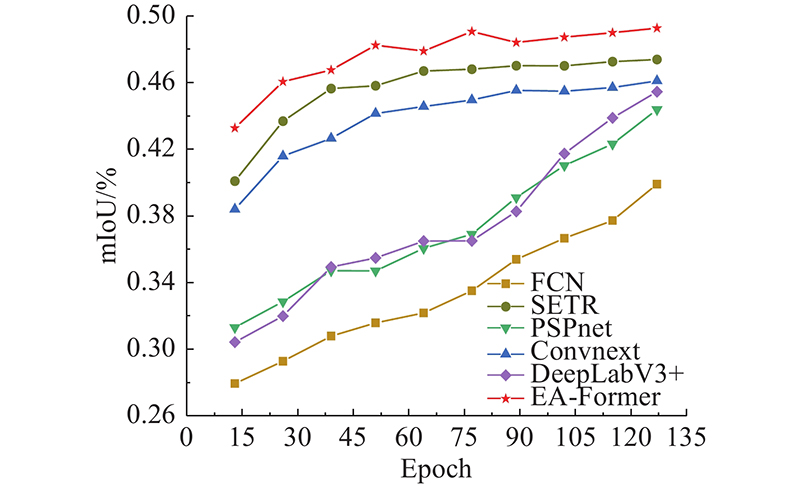
如图5 所示,为了更直观地对比不同算法的分割精度在训练过程中的变化,将典型算法在训练ADE20K数据集时的平均交并比变化可视化,其中Epoch为训练迭代轮数. 相较于如FCN、DeeplabV3+、PSPnet和Convnext等基于CNN的语义分割网络, EA-Former的语义分割精度有显著提升. 得益于单层Transformer结构拥有全局感受野的优势,在迭代轮数较小时,EA-Former能够利用所获取的丰富上下文信息迅速取得较高的mIoU,相比之下,基于CNN的语义分割网络则需要漫长的训练来逐步提高分割精度. ...
... Model evaluation results of different segmentation models on Cityscapes dataset
Tab.3 算法 基础网络结构 N /106 GFLOPs mIoU/% FCN[1 ] ResNet-101[19 ] 68.4 619.6 75.5 PSPNet[3 ] ResNet-101 67.9 576.3 79.7 DeepLabV3+[7 ] ResNet-101 62.5 571.6 80.6 CCnet[9 ] ResNet-101 68.8 625.7 79.4 UperNet[22 ] ResNet-101 85.4 576.5 80.1 DeepLabV3[6 ] ResNeSt-101[21 ] 90.8 798.9 80.4 OCRNet[33 ] HRNet[34 ] 70.3 364.7 80.7 SETR[11 ] ViT[12 ] 318.3 818.2 79.3 Segformer[20 ] MiT[20 ] 83.9 597.6 81.8 EA-Former MiT 136.4 137.7 82.1 Segformer# MiT 83.9 735.2 84.1 EA-Former # MiT 136.4 191.8 83.9
为了直观地比较不同算法在Cityscapes数据集上的分割效果,可视化不同算法的分割结果如图6 所示. 可以看出,在方框标注的区域,其他网络的分割效果不理想,除EA-Former外,其他均存在明显的识别错误. 在左侧的分割对比中,DeepLabV3+、SETR和Upernet将公交车的部分错判为火车类,FCN则将公交车的顶部识别为建筑类;在右侧的分割对比中,SETR、UperNet均将汽车的前轮部分判断为卡车类,DeepLabV3+、FCN均将汽车的车门部分误判为墙类. 在方框标出的易错区域,EA-Former成功地分割出正确的语义类别,主要原因是Transformer结构拥有全局感受野和灵活的位置编码方式,使得EA-Former拥有更充分的全局上下文信息和更充沛的空间信息,在处理单个大尺度物体或是物体相互遮挡时,能够结合周围的语义信息做出正确的判断. 虽然SETR中也有Transformer结构,但SETR采用的是相对固定的显式位置编码,且编码器部分使用类ViT的直筒型结构,难以生成不同尺度的特征图,仅将编码器最后一层输出的特征图送入解码器进行分割,导致分割效果不佳. EA-Former使用更加灵活的自适应卷积位置编码和可生成多尺度特征图的金字塔型编码网络,因此EA-Former可以结合低层的空间特征图和高层的语义特征图输出更精准的分割结果. ...
... Evaluation results of inference speed for different segmentation models on ADE20K dataset and Cityscapes dataset
Tab.4 算法 基础网络结构 FPS/(帧 $\cdot {{\rm{s}}^{ - 1} }$ ADE20K Citysapes FCN[1 ] ResNet-101[19 ] 20.7 1.7 PSPNet[3 ] ResNet-101 20.3 1.8 DeepLabV3+[7 ] ResNet-101 18.7 1.6 DeepLabV3+ ResNeSt-101[21 ] 16.1 2.5 UperNet[22 ] Swin-S[24 ] 20.1 — UperNet Convnext[25 ] 17.1 — SETR[11 ] ViT[12 ] 8.3 — DPT[27 ] ViT 20.5 — Segmenter Mask[28 ] ViT 21.3 — Segformer[20 ] MiT[20 ] 18.6 2.5 EA-Former MiT 21.9 2.8 Segformer* MiT 15.7 — EA-Former * MiT 18.1 — UperNet ResNet-101 — 2.3 CCnet[9 ] ResNet-101 — 1.7 DeepLabV3[6 ] ResNeSt-101 — 2.4 SETR ViT — 0.4 Segformer# MiT — 2.3 EA-Former # MiT — 2.5
2.5. 消融实验 2.5.1. 自适应卷积位置编码模块(ACPE)消融实验 为了证明ACPE能灵活处理不同分辨率的图片且不会造成显著性能下降,将Cityscapes数据集中的原始图片裁剪为 $ 768 \times 768 $ $ 768 \times 768 $ $ 832 \times 832 $ $ 1\;024 \times 1\;024 $ $ 1\;024 \times 2\;048 $ 表5 所示. 均不含ACPE的SETR和EA-Former在处理不同分辨率的输入图片时,只能对之前所训练的位置编码进行插值处理,导致模型的分割性能显著下降;含ACPE的EA-Former在处理不同于训练图片分辨率的验证图片时,可以通过零值填充卷积灵活地编码位置信息,使得网络可以维持较高的分割精度,不会造成过高的性能损失. 可以看到,与不含ACPE的算法相比,在处理分辨率为 $ 1\;024 \times 2\;048 $ $ 768 \times 768 $
... Influence of adaptive convolutional position encoding module on model segmentation accuracy
Tab.5 分辨率 mIoU/% SETR[11 ] [12 ] ) EA-Former EA-Former $ 768 \times 768 $ 79.3 81.9 82.1 $ 832 \times 832 $ 79.0 81.7 82.0 $1\;024 \times 1\;024$ 78.4 81.2 81.8 $1\;024 \times 2\;048$ 75.4 78.6 81.2
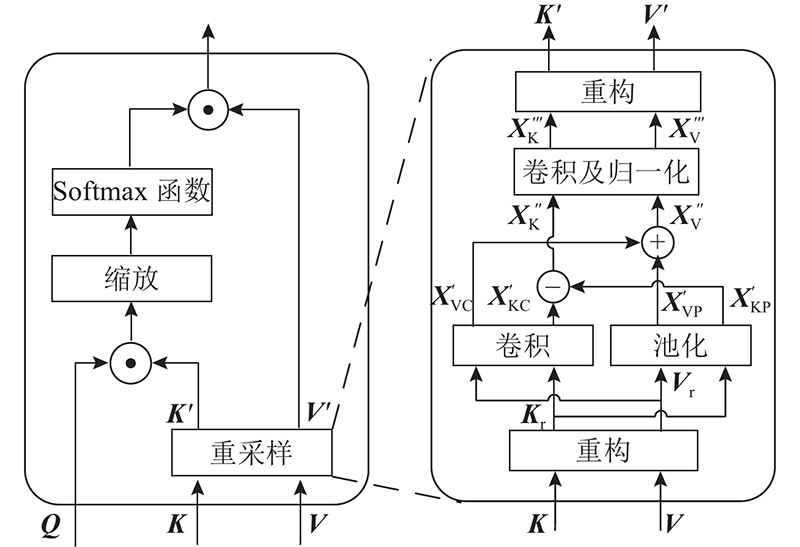
2.5.2. 联合重采样自注意力模块(JRSA)消融实验 为了证明JRSA能够高效地进行自注意力计算且不会带来更多的计算量,在ADE20K数据集上对轻量级的EA-Former-T进行JRSA的消融实验. 为了证明JRSA中降维操作带来的效率和性能优势,训练不含降维操作的EA-Former-T,即将JRSA中第一个用于降维的深度可分离卷积修改为卷积核大小为 $ 3 \times 3 $ $ 1 $ 表6 所示. 当EA-Former-T不包含JRSA时,其计算复杂度高且推理速度慢,在加入了含降维操作的JRSA后,不仅平均交并比更优,计算复杂度降低,而且推理速度极大提升. 当JRSA不包含降维操作时,其相对于标准的自注意力计算过程,更多的计算量被额外引入,与降低自注意力机制的计算复杂度的预期目标相悖. 实验结果表明,与降维后的模型效果相比,不降维模型的mIoU更低、计算复杂度更高,推理速度远低于降维模型. ...
5
... Vaswani等[10 ] 提出单层即拥有全局感受野的Transformer结构. 之后,Transformer结构被引入计算机视觉领域,在大型图像数据集上,Transformer网络得到超越CNN最优模型的效果,如Zheng等[11 ] 提出的Transformer语义分割模型SETR,是将Transformer结构用于语义分割任务并取得显著提升的模型,SETR模型中的特征提取网络由Dosovitskiy等[12 ] 提出的Transformer编码器构成,结合所设计的分割头,在ADE20K[13 ] 数据集上超过了当时的最优水平. 将标准的Transformer结构直接用于语义分割任务存在以下不足:1)大部分Transformer视觉网络采用相对固定的位置编码方式为嵌入向量提供位置信息,当测试图片与训练图片分辨率不同时,采用该方式的模型难以自适应地生成合适的位置编码,只能对之前的位置编码向量进行插值处理,这通常会造成模型的性能显著下降. 2)在标准Transformer结构中,自注意力计算会产生与输入图像分辨率成平方倍的计算复杂度,而语义分割通常处理的都是高分辨率输入图片,因此计算复杂度过高、参数量过大的问题在语义分割任务中尤为突出. ...
... Model evaluation results of different segmentation models on ADE20K dataset
Tab.1 算法 基础网络结构 N /106 GFLOPs mIoU/ FCN[1 ] ResNet-101[19 ] 68.6 275.7 39.9 PSPNet[3 ] ResNet-101 68.1 256.4 44.3 DeepLab-V3+[7 ] ResNet-101 62.7 255.1 45.4 DeepLab-V3+ ResNeSt-101[21 ] 66.3 262.9 46.9 UperNet[22 ] DeiT[23 ] 120.5 90.1 45.3 UperNet Swin-S[24 ] 81.0 259.3 49.3 UperNet Convnext[25 ] 60.2 234.6 46.1 UperNet Focal-B[26 ] 126.0 — 49.0 SETR[11 ] ViT[12 ] 318.5 213.6 47.3 DPT[27 ] ViT 109.7 171.0 46.9 Segmenter Mask[28 ] ViT 102.5 71.1 49.6 Semantic FPN[29 ] PVTv2-B3[30 ] 49.0 62.0 47.3 Semantic FPN VAN-B3[31 ] 49.0 68.0 48.1 SeMask-B FPN[32 ] SeMask Swin 96.0 107.0 49.4 Segformer[20 ] MiT[20 ] 83.9 110.5 50.1 EA-Former MiT 136.4 61.3 49.3 Segformer* MiT 83.9 172.7 52.1 EA-Former * MiT 136.4 95.8 51.0
如表2 所示,以轻量级的MiT-B0为基础网络结构,利用ADE20K数据集训练多种实时语义分割模型,公平地比较模型之间的各项指标,进一步证明EA-Former的高效性. 表中,FPS为模型推理速度. 即使采用相同的基础网络结构MiT-B0,与之前取得最优分割精度的SETR、Segformer、Segmenter等Transformer语义分割模型相比,本研究提出的轻量级EA-Former-T在保持更低的计算量和更高推理速度的同时,mIoU更优. 虽然UperNet分割算法得到的mIoU比EA-Former-T的mIoU更优,但其计算量是EA-Former-T的4倍,且推理速度仅为EA-Former-T的57.9%. 模型对比研究结果表明,EA-Former中JRSA能够有效地降低自注意力机制的计算复杂度、维持分割精度. ...
... Model evaluation results of different segmentation models on Cityscapes dataset
Tab.3 算法 基础网络结构 N /106 GFLOPs mIoU/% FCN[1 ] ResNet-101[19 ] 68.4 619.6 75.5 PSPNet[3 ] ResNet-101 67.9 576.3 79.7 DeepLabV3+[7 ] ResNet-101 62.5 571.6 80.6 CCnet[9 ] ResNet-101 68.8 625.7 79.4 UperNet[22 ] ResNet-101 85.4 576.5 80.1 DeepLabV3[6 ] ResNeSt-101[21 ] 90.8 798.9 80.4 OCRNet[33 ] HRNet[34 ] 70.3 364.7 80.7 SETR[11 ] ViT[12 ] 318.3 818.2 79.3 Segformer[20 ] MiT[20 ] 83.9 597.6 81.8 EA-Former MiT 136.4 137.7 82.1 Segformer# MiT 83.9 735.2 84.1 EA-Former # MiT 136.4 191.8 83.9
为了直观地比较不同算法在Cityscapes数据集上的分割效果,可视化不同算法的分割结果如图6 所示. 可以看出,在方框标注的区域,其他网络的分割效果不理想,除EA-Former外,其他均存在明显的识别错误. 在左侧的分割对比中,DeepLabV3+、SETR和Upernet将公交车的部分错判为火车类,FCN则将公交车的顶部识别为建筑类;在右侧的分割对比中,SETR、UperNet均将汽车的前轮部分判断为卡车类,DeepLabV3+、FCN均将汽车的车门部分误判为墙类. 在方框标出的易错区域,EA-Former成功地分割出正确的语义类别,主要原因是Transformer结构拥有全局感受野和灵活的位置编码方式,使得EA-Former拥有更充分的全局上下文信息和更充沛的空间信息,在处理单个大尺度物体或是物体相互遮挡时,能够结合周围的语义信息做出正确的判断. 虽然SETR中也有Transformer结构,但SETR采用的是相对固定的显式位置编码,且编码器部分使用类ViT的直筒型结构,难以生成不同尺度的特征图,仅将编码器最后一层输出的特征图送入解码器进行分割,导致分割效果不佳. EA-Former使用更加灵活的自适应卷积位置编码和可生成多尺度特征图的金字塔型编码网络,因此EA-Former可以结合低层的空间特征图和高层的语义特征图输出更精准的分割结果. ...
... Evaluation results of inference speed for different segmentation models on ADE20K dataset and Cityscapes dataset
Tab.4 算法 基础网络结构 FPS/(帧 $\cdot {{\rm{s}}^{ - 1} }$ ADE20K Citysapes FCN[1 ] ResNet-101[19 ] 20.7 1.7 PSPNet[3 ] ResNet-101 20.3 1.8 DeepLabV3+[7 ] ResNet-101 18.7 1.6 DeepLabV3+ ResNeSt-101[21 ] 16.1 2.5 UperNet[22 ] Swin-S[24 ] 20.1 — UperNet Convnext[25 ] 17.1 — SETR[11 ] ViT[12 ] 8.3 — DPT[27 ] ViT 20.5 — Segmenter Mask[28 ] ViT 21.3 — Segformer[20 ] MiT[20 ] 18.6 2.5 EA-Former MiT 21.9 2.8 Segformer* MiT 15.7 — EA-Former * MiT 18.1 — UperNet ResNet-101 — 2.3 CCnet[9 ] ResNet-101 — 1.7 DeepLabV3[6 ] ResNeSt-101 — 2.4 SETR ViT — 0.4 Segformer# MiT — 2.3 EA-Former # MiT — 2.5
2.5. 消融实验 2.5.1. 自适应卷积位置编码模块(ACPE)消融实验 为了证明ACPE能灵活处理不同分辨率的图片且不会造成显著性能下降,将Cityscapes数据集中的原始图片裁剪为 $ 768 \times 768 $ $ 768 \times 768 $ $ 832 \times 832 $ $ 1\;024 \times 1\;024 $ $ 1\;024 \times 2\;048 $ 表5 所示. 均不含ACPE的SETR和EA-Former在处理不同分辨率的输入图片时,只能对之前所训练的位置编码进行插值处理,导致模型的分割性能显著下降;含ACPE的EA-Former在处理不同于训练图片分辨率的验证图片时,可以通过零值填充卷积灵活地编码位置信息,使得网络可以维持较高的分割精度,不会造成过高的性能损失. 可以看到,与不含ACPE的算法相比,在处理分辨率为 $ 1\;024 \times 2\;048 $ $ 768 \times 768 $
... Influence of adaptive convolutional position encoding module on model segmentation accuracy
Tab.5 分辨率 mIoU/% SETR[11 ] [12 ] ) EA-Former EA-Former $ 768 \times 768 $ 79.3 81.9 82.1 $ 832 \times 832 $ 79.0 81.7 82.0 $1\;024 \times 1\;024$ 78.4 81.2 81.8 $1\;024 \times 2\;048$ 75.4 78.6 81.2
2.5.2. 联合重采样自注意力模块(JRSA)消融实验 为了证明JRSA能够高效地进行自注意力计算且不会带来更多的计算量,在ADE20K数据集上对轻量级的EA-Former-T进行JRSA的消融实验. 为了证明JRSA中降维操作带来的效率和性能优势,训练不含降维操作的EA-Former-T,即将JRSA中第一个用于降维的深度可分离卷积修改为卷积核大小为 $ 3 \times 3 $ $ 1 $ 表6 所示. 当EA-Former-T不包含JRSA时,其计算复杂度高且推理速度慢,在加入了含降维操作的JRSA后,不仅平均交并比更优,计算复杂度降低,而且推理速度极大提升. 当JRSA不包含降维操作时,其相对于标准的自注意力计算过程,更多的计算量被额外引入,与降低自注意力机制的计算复杂度的预期目标相悖. 实验结果表明,与降维后的模型效果相比,不降维模型的mIoU更低、计算复杂度更高,推理速度远低于降维模型. ...
1
... Vaswani等[10 ] 提出单层即拥有全局感受野的Transformer结构. 之后,Transformer结构被引入计算机视觉领域,在大型图像数据集上,Transformer网络得到超越CNN最优模型的效果,如Zheng等[11 ] 提出的Transformer语义分割模型SETR,是将Transformer结构用于语义分割任务并取得显著提升的模型,SETR模型中的特征提取网络由Dosovitskiy等[12 ] 提出的Transformer编码器构成,结合所设计的分割头,在ADE20K[13 ] 数据集上超过了当时的最优水平. 将标准的Transformer结构直接用于语义分割任务存在以下不足:1)大部分Transformer视觉网络采用相对固定的位置编码方式为嵌入向量提供位置信息,当测试图片与训练图片分辨率不同时,采用该方式的模型难以自适应地生成合适的位置编码,只能对之前的位置编码向量进行插值处理,这通常会造成模型的性能显著下降. 2)在标准Transformer结构中,自注意力计算会产生与输入图像分辨率成平方倍的计算复杂度,而语义分割通常处理的都是高分辨率输入图片,因此计算复杂度过高、参数量过大的问题在语义分割任务中尤为突出. ...
1
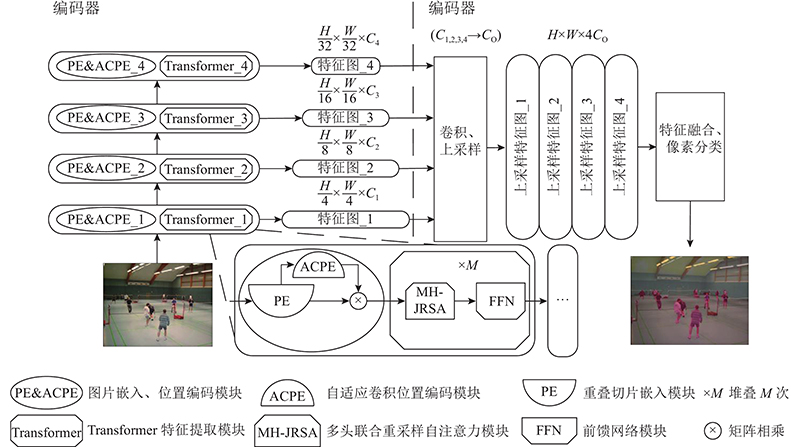
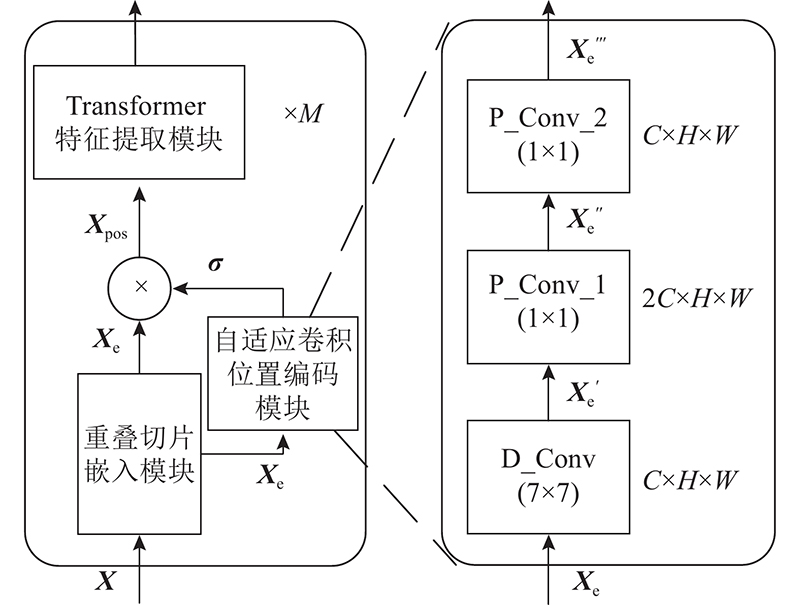
... 本研究针对上述不足,结合语义分割任务的相关特性,提出基于Transformer的高效自适应语义分割网络(efficient and adaptive for semantic segmentation based on Transformers, EA-Former). 卷积操作可以隐性编码位置信息[14 ] ,Chu等[15 -17 ] 已经证明利用卷积为Transformer网络提供位置编码的可行性,本研究利用零值填充卷积设计自适应卷积位置编码模块(adaptive convolutional positional encoding,ACPE),通过充分结合嵌入向量周围的上下文信息为网络提供准确的动态位置编码. 为了在尽量维持性能的同时,降低自注意力计算过高的计算复杂度,设计联合重采样自注意力模块(joint resampling self-attention,JRSA),通过对自注意力计算的相关矩阵进行降维,实现高效地相关性计算. 提出用于融合不同阶段特征的解码器,该解码器主要基于简单的小尺度卷积和双线性插值来融合不同分辨率的特征图,从而得到准确的分割结果. 在公开语义分割数据集ADE20K和Cityscapes[18 ] 上,本研究将进行EA-Former与主流语义分割算法的性能对比. ...
2
... 本研究针对上述不足,结合语义分割任务的相关特性,提出基于Transformer的高效自适应语义分割网络(efficient and adaptive for semantic segmentation based on Transformers, EA-Former). 卷积操作可以隐性编码位置信息[14 ] ,Chu等[15 -17 ] 已经证明利用卷积为Transformer网络提供位置编码的可行性,本研究利用零值填充卷积设计自适应卷积位置编码模块(adaptive convolutional positional encoding,ACPE),通过充分结合嵌入向量周围的上下文信息为网络提供准确的动态位置编码. 为了在尽量维持性能的同时,降低自注意力计算过高的计算复杂度,设计联合重采样自注意力模块(joint resampling self-attention,JRSA),通过对自注意力计算的相关矩阵进行降维,实现高效地相关性计算. 提出用于融合不同阶段特征的解码器,该解码器主要基于简单的小尺度卷积和双线性插值来融合不同分辨率的特征图,从而得到准确的分割结果. 在公开语义分割数据集ADE20K和Cityscapes[18 ] 上,本研究将进行EA-Former与主流语义分割算法的性能对比. ...
... 式中: ${\boldsymbol{X}} \in {{\bf{R}}^{ {H \times W} \times C}}$ $H \times W$ $ C $ ${\boldsymbol{\eta }} \in {{\bf{R}}^{ {H \times W} \times C}}$ $ {\rm{PE}}\left( \cdot \right) $ $ {{\boldsymbol{X}}_{{\text{pos}}}} $ [15 ] 提出位置编码生成器,利用单层深度可分离卷积提取对应的空间信息,生成位置编码与特征向量相加,为网络提供自适应位置信息;Yuan等[16 ] 修改标准Transformer结构,移除单独的位置编码模块,利用CNN可保留空间信息的特性, 将CNN融入Transformer的特征映射与特征提取,为Transformer视觉网络提供动态位置信息. ...
1
... 式中: ${\boldsymbol{X}} \in {{\bf{R}}^{ {H \times W} \times C}}$ $H \times W$ $ C $ ${\boldsymbol{\eta }} \in {{\bf{R}}^{ {H \times W} \times C}}$ $ {\rm{PE}}\left( \cdot \right) $ $ {{\boldsymbol{X}}_{{\text{pos}}}} $ [15 ] 提出位置编码生成器,利用单层深度可分离卷积提取对应的空间信息,生成位置编码与特征向量相加,为网络提供自适应位置信息;Yuan等[16 ] 修改标准Transformer结构,移除单独的位置编码模块,利用CNN可保留空间信息的特性, 将CNN融入Transformer的特征映射与特征提取,为Transformer视觉网络提供动态位置信息. ...
1
... 本研究针对上述不足,结合语义分割任务的相关特性,提出基于Transformer的高效自适应语义分割网络(efficient and adaptive for semantic segmentation based on Transformers, EA-Former). 卷积操作可以隐性编码位置信息[14 ] ,Chu等[15 -17 ] 已经证明利用卷积为Transformer网络提供位置编码的可行性,本研究利用零值填充卷积设计自适应卷积位置编码模块(adaptive convolutional positional encoding,ACPE),通过充分结合嵌入向量周围的上下文信息为网络提供准确的动态位置编码. 为了在尽量维持性能的同时,降低自注意力计算过高的计算复杂度,设计联合重采样自注意力模块(joint resampling self-attention,JRSA),通过对自注意力计算的相关矩阵进行降维,实现高效地相关性计算. 提出用于融合不同阶段特征的解码器,该解码器主要基于简单的小尺度卷积和双线性插值来融合不同分辨率的特征图,从而得到准确的分割结果. 在公开语义分割数据集ADE20K和Cityscapes[18 ] 上,本研究将进行EA-Former与主流语义分割算法的性能对比. ...
1
... 本研究针对上述不足,结合语义分割任务的相关特性,提出基于Transformer的高效自适应语义分割网络(efficient and adaptive for semantic segmentation based on Transformers, EA-Former). 卷积操作可以隐性编码位置信息[14 ] ,Chu等[15 -17 ] 已经证明利用卷积为Transformer网络提供位置编码的可行性,本研究利用零值填充卷积设计自适应卷积位置编码模块(adaptive convolutional positional encoding,ACPE),通过充分结合嵌入向量周围的上下文信息为网络提供准确的动态位置编码. 为了在尽量维持性能的同时,降低自注意力计算过高的计算复杂度,设计联合重采样自注意力模块(joint resampling self-attention,JRSA),通过对自注意力计算的相关矩阵进行降维,实现高效地相关性计算. 提出用于融合不同阶段特征的解码器,该解码器主要基于简单的小尺度卷积和双线性插值来融合不同分辨率的特征图,从而得到准确的分割结果. 在公开语义分割数据集ADE20K和Cityscapes[18 ] 上,本研究将进行EA-Former与主流语义分割算法的性能对比. ...
4
... 如图1 所示,EA-Former宏观上基于编码器-解码器结构,主要由以下2个部分组成:1)可以生成多尺度特征的金字塔型高效Transformer编码器. 该编码器能够根据不同的输入图像大小进行自适应卷积位置编码,输出不同阶段的特征图用于特征融合,还能够以较低的计算量得到良好的特征提取与表达能力. 2)可以有效融合不同分辨率特征图的解码器. 该解码器通过简单的卷积和上采样操作,有效融合语义信息充沛的低分辨率特征图和空间信息丰富的高分辨率特征图,得到准确的分割结果. 当分辨率为 $ H \times W \times 3 $ H 、W 分别为输入图片的高和宽),模型先将输入图像进行 $ 4 \times 4 $ [19 ] ;在特征提取完成后,将不同分辨率的特征图送入特征融合解码器,通过简单的小尺度卷积和双线性插值上采样得到4张原图大小的特征图,再将4张特征图在通道维度上进行拼接. 将拼接后的特征图送入之后的特征融合及像素分类模块进行高效的特征融合,输出按语义类别分类的逐像素分割图. ...
... Model evaluation results of different segmentation models on ADE20K dataset
Tab.1 算法 基础网络结构 N /106 GFLOPs mIoU/ FCN[1 ] ResNet-101[19 ] 68.6 275.7 39.9 PSPNet[3 ] ResNet-101 68.1 256.4 44.3 DeepLab-V3+[7 ] ResNet-101 62.7 255.1 45.4 DeepLab-V3+ ResNeSt-101[21 ] 66.3 262.9 46.9 UperNet[22 ] DeiT[23 ] 120.5 90.1 45.3 UperNet Swin-S[24 ] 81.0 259.3 49.3 UperNet Convnext[25 ] 60.2 234.6 46.1 UperNet Focal-B[26 ] 126.0 — 49.0 SETR[11 ] ViT[12 ] 318.5 213.6 47.3 DPT[27 ] ViT 109.7 171.0 46.9 Segmenter Mask[28 ] ViT 102.5 71.1 49.6 Semantic FPN[29 ] PVTv2-B3[30 ] 49.0 62.0 47.3 Semantic FPN VAN-B3[31 ] 49.0 68.0 48.1 SeMask-B FPN[32 ] SeMask Swin 96.0 107.0 49.4 Segformer[20 ] MiT[20 ] 83.9 110.5 50.1 EA-Former MiT 136.4 61.3 49.3 Segformer* MiT 83.9 172.7 52.1 EA-Former * MiT 136.4 95.8 51.0
如表2 所示,以轻量级的MiT-B0为基础网络结构,利用ADE20K数据集训练多种实时语义分割模型,公平地比较模型之间的各项指标,进一步证明EA-Former的高效性. 表中,FPS为模型推理速度. 即使采用相同的基础网络结构MiT-B0,与之前取得最优分割精度的SETR、Segformer、Segmenter等Transformer语义分割模型相比,本研究提出的轻量级EA-Former-T在保持更低的计算量和更高推理速度的同时,mIoU更优. 虽然UperNet分割算法得到的mIoU比EA-Former-T的mIoU更优,但其计算量是EA-Former-T的4倍,且推理速度仅为EA-Former-T的57.9%. 模型对比研究结果表明,EA-Former中JRSA能够有效地降低自注意力机制的计算复杂度、维持分割精度. ...
... Model evaluation results of different segmentation models on Cityscapes dataset
Tab.3 算法 基础网络结构 N /106 GFLOPs mIoU/% FCN[1 ] ResNet-101[19 ] 68.4 619.6 75.5 PSPNet[3 ] ResNet-101 67.9 576.3 79.7 DeepLabV3+[7 ] ResNet-101 62.5 571.6 80.6 CCnet[9 ] ResNet-101 68.8 625.7 79.4 UperNet[22 ] ResNet-101 85.4 576.5 80.1 DeepLabV3[6 ] ResNeSt-101[21 ] 90.8 798.9 80.4 OCRNet[33 ] HRNet[34 ] 70.3 364.7 80.7 SETR[11 ] ViT[12 ] 318.3 818.2 79.3 Segformer[20 ] MiT[20 ] 83.9 597.6 81.8 EA-Former MiT 136.4 137.7 82.1 Segformer# MiT 83.9 735.2 84.1 EA-Former # MiT 136.4 191.8 83.9
为了直观地比较不同算法在Cityscapes数据集上的分割效果,可视化不同算法的分割结果如图6 所示. 可以看出,在方框标注的区域,其他网络的分割效果不理想,除EA-Former外,其他均存在明显的识别错误. 在左侧的分割对比中,DeepLabV3+、SETR和Upernet将公交车的部分错判为火车类,FCN则将公交车的顶部识别为建筑类;在右侧的分割对比中,SETR、UperNet均将汽车的前轮部分判断为卡车类,DeepLabV3+、FCN均将汽车的车门部分误判为墙类. 在方框标出的易错区域,EA-Former成功地分割出正确的语义类别,主要原因是Transformer结构拥有全局感受野和灵活的位置编码方式,使得EA-Former拥有更充分的全局上下文信息和更充沛的空间信息,在处理单个大尺度物体或是物体相互遮挡时,能够结合周围的语义信息做出正确的判断. 虽然SETR中也有Transformer结构,但SETR采用的是相对固定的显式位置编码,且编码器部分使用类ViT的直筒型结构,难以生成不同尺度的特征图,仅将编码器最后一层输出的特征图送入解码器进行分割,导致分割效果不佳. EA-Former使用更加灵活的自适应卷积位置编码和可生成多尺度特征图的金字塔型编码网络,因此EA-Former可以结合低层的空间特征图和高层的语义特征图输出更精准的分割结果. ...
... Evaluation results of inference speed for different segmentation models on ADE20K dataset and Cityscapes dataset
Tab.4 算法 基础网络结构 FPS/(帧 $\cdot {{\rm{s}}^{ - 1} }$ ADE20K Citysapes FCN[1 ] ResNet-101[19 ] 20.7 1.7 PSPNet[3 ] ResNet-101 20.3 1.8 DeepLabV3+[7 ] ResNet-101 18.7 1.6 DeepLabV3+ ResNeSt-101[21 ] 16.1 2.5 UperNet[22 ] Swin-S[24 ] 20.1 — UperNet Convnext[25 ] 17.1 — SETR[11 ] ViT[12 ] 8.3 — DPT[27 ] ViT 20.5 — Segmenter Mask[28 ] ViT 21.3 — Segformer[20 ] MiT[20 ] 18.6 2.5 EA-Former MiT 21.9 2.8 Segformer* MiT 15.7 — EA-Former * MiT 18.1 — UperNet ResNet-101 — 2.3 CCnet[9 ] ResNet-101 — 1.7 DeepLabV3[6 ] ResNeSt-101 — 2.4 SETR ViT — 0.4 Segformer# MiT — 2.3 EA-Former # MiT — 2.5
2.5. 消融实验 2.5.1. 自适应卷积位置编码模块(ACPE)消融实验 为了证明ACPE能灵活处理不同分辨率的图片且不会造成显著性能下降,将Cityscapes数据集中的原始图片裁剪为 $ 768 \times 768 $ $ 768 \times 768 $ $ 832 \times 832 $ $ 1\;024 \times 1\;024 $ $ 1\;024 \times 2\;048 $ 表5 所示. 均不含ACPE的SETR和EA-Former在处理不同分辨率的输入图片时,只能对之前所训练的位置编码进行插值处理,导致模型的分割性能显著下降;含ACPE的EA-Former在处理不同于训练图片分辨率的验证图片时,可以通过零值填充卷积灵活地编码位置信息,使得网络可以维持较高的分割精度,不会造成过高的性能损失. 可以看到,与不含ACPE的算法相比,在处理分辨率为 $ 1\;024 \times 2\;048 $ $ 768 \times 768 $
9
... 本研究基于语义分割框架mmsegmentation实现Transformer语义分割网络,并完成对应实验. 在数据增强方面,ADE20K、Cityscapes均采用随机尺度调整、随机水平翻转以及将图像与标签随机裁剪等数据增强方式. 在模型训练方面,设置ADE20K的每批次大小为16张图片,由于Cityscapes数据集裁剪后的图片分辨率较高,在训练Cityscapes数据集时将每批次大小设定为8张图片. 实验硬件使用2个NVIDIA RTX A5000显卡训练模型,2个数据集都采用AdamW优化器,初始学习率设置为 $6.0 \times {10^{ - 5}}$ [20 ] 来初始化编码器参数,对于MiT中不包含的层,采用均值为0、方差为0.02的正态分布进行权重初始化,解码器内的网络参数则直接采用随机初始化. ...
... Model evaluation results of different segmentation models on ADE20K dataset
Tab.1 算法 基础网络结构 N /106 GFLOPs mIoU/ FCN[1 ] ResNet-101[19 ] 68.6 275.7 39.9 PSPNet[3 ] ResNet-101 68.1 256.4 44.3 DeepLab-V3+[7 ] ResNet-101 62.7 255.1 45.4 DeepLab-V3+ ResNeSt-101[21 ] 66.3 262.9 46.9 UperNet[22 ] DeiT[23 ] 120.5 90.1 45.3 UperNet Swin-S[24 ] 81.0 259.3 49.3 UperNet Convnext[25 ] 60.2 234.6 46.1 UperNet Focal-B[26 ] 126.0 — 49.0 SETR[11 ] ViT[12 ] 318.5 213.6 47.3 DPT[27 ] ViT 109.7 171.0 46.9 Segmenter Mask[28 ] ViT 102.5 71.1 49.6 Semantic FPN[29 ] PVTv2-B3[30 ] 49.0 62.0 47.3 Semantic FPN VAN-B3[31 ] 49.0 68.0 48.1 SeMask-B FPN[32 ] SeMask Swin 96.0 107.0 49.4 Segformer[20 ] MiT[20 ] 83.9 110.5 50.1 EA-Former MiT 136.4 61.3 49.3 Segformer* MiT 83.9 172.7 52.1 EA-Former * MiT 136.4 95.8 51.0
如表2 所示,以轻量级的MiT-B0为基础网络结构,利用ADE20K数据集训练多种实时语义分割模型,公平地比较模型之间的各项指标,进一步证明EA-Former的高效性. 表中,FPS为模型推理速度. 即使采用相同的基础网络结构MiT-B0,与之前取得最优分割精度的SETR、Segformer、Segmenter等Transformer语义分割模型相比,本研究提出的轻量级EA-Former-T在保持更低的计算量和更高推理速度的同时,mIoU更优. 虽然UperNet分割算法得到的mIoU比EA-Former-T的mIoU更优,但其计算量是EA-Former-T的4倍,且推理速度仅为EA-Former-T的57.9%. 模型对比研究结果表明,EA-Former中JRSA能够有效地降低自注意力机制的计算复杂度、维持分割精度. ...
... [
20 ]
83.9 110.5 50.1 EA-Former MiT 136.4 61.3 49.3 Segformer* MiT 83.9 172.7 52.1 EA-Former * MiT 136.4 95.8 51.0 如表2 所示,以轻量级的MiT-B0为基础网络结构,利用ADE20K数据集训练多种实时语义分割模型,公平地比较模型之间的各项指标,进一步证明EA-Former的高效性. 表中,FPS为模型推理速度. 即使采用相同的基础网络结构MiT-B0,与之前取得最优分割精度的SETR、Segformer、Segmenter等Transformer语义分割模型相比,本研究提出的轻量级EA-Former-T在保持更低的计算量和更高推理速度的同时,mIoU更优. 虽然UperNet分割算法得到的mIoU比EA-Former-T的mIoU更优,但其计算量是EA-Former-T的4倍,且推理速度仅为EA-Former-T的57.9%. 模型对比研究结果表明,EA-Former中JRSA能够有效地降低自注意力机制的计算复杂度、维持分割精度. ...
... Model evaluation results of lightweight segmentation models on ADE20K dataset
Tab.2 算法 基础网络结构 GFLOPs FPS/ $ \cdot {{\rm{s}}^{ - 1}} $ mIoU/ SETR[11 ] MiT-B0[20 ] 25.3 28.7 34.8 Segformer[20 ] MiT-B0 8.6 50.5 37.5 UperNet[22 ] MiT-B0 28.5 29.6 39.3 Segmenter[28 ] MiT-B0 7.9 49.2 35.9 Semantic FPN[29 ] MiT-B0 23.0 46.4 37.1 EA-Former-T MiT-B0 7.1 51.1 38.1
如图5 所示,为了更直观地对比不同算法的分割精度在训练过程中的变化,将典型算法在训练ADE20K数据集时的平均交并比变化可视化,其中Epoch为训练迭代轮数. 相较于如FCN、DeeplabV3+、PSPnet和Convnext等基于CNN的语义分割网络, EA-Former的语义分割精度有显著提升. 得益于单层Transformer结构拥有全局感受野的优势,在迭代轮数较小时,EA-Former能够利用所获取的丰富上下文信息迅速取得较高的mIoU,相比之下,基于CNN的语义分割网络则需要漫长的训练来逐步提高分割精度. ...
... [
20 ]
MiT-B0 8.6 50.5 37.5 UperNet[22 ] MiT-B0 28.5 29.6 39.3 Segmenter[28 ] MiT-B0 7.9 49.2 35.9 Semantic FPN[29 ] MiT-B0 23.0 46.4 37.1 EA-Former-T MiT-B0 7.1 51.1 38.1 如图5 所示,为了更直观地对比不同算法的分割精度在训练过程中的变化,将典型算法在训练ADE20K数据集时的平均交并比变化可视化,其中Epoch为训练迭代轮数. 相较于如FCN、DeeplabV3+、PSPnet和Convnext等基于CNN的语义分割网络, EA-Former的语义分割精度有显著提升. 得益于单层Transformer结构拥有全局感受野的优势,在迭代轮数较小时,EA-Former能够利用所获取的丰富上下文信息迅速取得较高的mIoU,相比之下,基于CNN的语义分割网络则需要漫长的训练来逐步提高分割精度. ...
... Model evaluation results of different segmentation models on Cityscapes dataset
Tab.3 算法 基础网络结构 N /106 GFLOPs mIoU/% FCN[1 ] ResNet-101[19 ] 68.4 619.6 75.5 PSPNet[3 ] ResNet-101 67.9 576.3 79.7 DeepLabV3+[7 ] ResNet-101 62.5 571.6 80.6 CCnet[9 ] ResNet-101 68.8 625.7 79.4 UperNet[22 ] ResNet-101 85.4 576.5 80.1 DeepLabV3[6 ] ResNeSt-101[21 ] 90.8 798.9 80.4 OCRNet[33 ] HRNet[34 ] 70.3 364.7 80.7 SETR[11 ] ViT[12 ] 318.3 818.2 79.3 Segformer[20 ] MiT[20 ] 83.9 597.6 81.8 EA-Former MiT 136.4 137.7 82.1 Segformer# MiT 83.9 735.2 84.1 EA-Former # MiT 136.4 191.8 83.9
为了直观地比较不同算法在Cityscapes数据集上的分割效果,可视化不同算法的分割结果如图6 所示. 可以看出,在方框标注的区域,其他网络的分割效果不理想,除EA-Former外,其他均存在明显的识别错误. 在左侧的分割对比中,DeepLabV3+、SETR和Upernet将公交车的部分错判为火车类,FCN则将公交车的顶部识别为建筑类;在右侧的分割对比中,SETR、UperNet均将汽车的前轮部分判断为卡车类,DeepLabV3+、FCN均将汽车的车门部分误判为墙类. 在方框标出的易错区域,EA-Former成功地分割出正确的语义类别,主要原因是Transformer结构拥有全局感受野和灵活的位置编码方式,使得EA-Former拥有更充分的全局上下文信息和更充沛的空间信息,在处理单个大尺度物体或是物体相互遮挡时,能够结合周围的语义信息做出正确的判断. 虽然SETR中也有Transformer结构,但SETR采用的是相对固定的显式位置编码,且编码器部分使用类ViT的直筒型结构,难以生成不同尺度的特征图,仅将编码器最后一层输出的特征图送入解码器进行分割,导致分割效果不佳. EA-Former使用更加灵活的自适应卷积位置编码和可生成多尺度特征图的金字塔型编码网络,因此EA-Former可以结合低层的空间特征图和高层的语义特征图输出更精准的分割结果. ...
... [
20 ]
83.9 597.6 81.8 EA-Former MiT 136.4 137.7 82.1 Segformer# MiT 83.9 735.2 84.1 EA-Former # MiT 136.4 191.8 83.9 为了直观地比较不同算法在Cityscapes数据集上的分割效果,可视化不同算法的分割结果如图6 所示. 可以看出,在方框标注的区域,其他网络的分割效果不理想,除EA-Former外,其他均存在明显的识别错误. 在左侧的分割对比中,DeepLabV3+、SETR和Upernet将公交车的部分错判为火车类,FCN则将公交车的顶部识别为建筑类;在右侧的分割对比中,SETR、UperNet均将汽车的前轮部分判断为卡车类,DeepLabV3+、FCN均将汽车的车门部分误判为墙类. 在方框标出的易错区域,EA-Former成功地分割出正确的语义类别,主要原因是Transformer结构拥有全局感受野和灵活的位置编码方式,使得EA-Former拥有更充分的全局上下文信息和更充沛的空间信息,在处理单个大尺度物体或是物体相互遮挡时,能够结合周围的语义信息做出正确的判断. 虽然SETR中也有Transformer结构,但SETR采用的是相对固定的显式位置编码,且编码器部分使用类ViT的直筒型结构,难以生成不同尺度的特征图,仅将编码器最后一层输出的特征图送入解码器进行分割,导致分割效果不佳. EA-Former使用更加灵活的自适应卷积位置编码和可生成多尺度特征图的金字塔型编码网络,因此EA-Former可以结合低层的空间特征图和高层的语义特征图输出更精准的分割结果. ...
... Evaluation results of inference speed for different segmentation models on ADE20K dataset and Cityscapes dataset
Tab.4 算法 基础网络结构 FPS/(帧 $\cdot {{\rm{s}}^{ - 1} }$ ADE20K Citysapes FCN[1 ] ResNet-101[19 ] 20.7 1.7 PSPNet[3 ] ResNet-101 20.3 1.8 DeepLabV3+[7 ] ResNet-101 18.7 1.6 DeepLabV3+ ResNeSt-101[21 ] 16.1 2.5 UperNet[22 ] Swin-S[24 ] 20.1 — UperNet Convnext[25 ] 17.1 — SETR[11 ] ViT[12 ] 8.3 — DPT[27 ] ViT 20.5 — Segmenter Mask[28 ] ViT 21.3 — Segformer[20 ] MiT[20 ] 18.6 2.5 EA-Former MiT 21.9 2.8 Segformer* MiT 15.7 — EA-Former * MiT 18.1 — UperNet ResNet-101 — 2.3 CCnet[9 ] ResNet-101 — 1.7 DeepLabV3[6 ] ResNeSt-101 — 2.4 SETR ViT — 0.4 Segformer# MiT — 2.3 EA-Former # MiT — 2.5
2.5. 消融实验 2.5.1. 自适应卷积位置编码模块(ACPE)消融实验 为了证明ACPE能灵活处理不同分辨率的图片且不会造成显著性能下降,将Cityscapes数据集中的原始图片裁剪为 $ 768 \times 768 $ $ 768 \times 768 $ $ 832 \times 832 $ $ 1\;024 \times 1\;024 $ $ 1\;024 \times 2\;048 $ 表5 所示. 均不含ACPE的SETR和EA-Former在处理不同分辨率的输入图片时,只能对之前所训练的位置编码进行插值处理,导致模型的分割性能显著下降;含ACPE的EA-Former在处理不同于训练图片分辨率的验证图片时,可以通过零值填充卷积灵活地编码位置信息,使得网络可以维持较高的分割精度,不会造成过高的性能损失. 可以看到,与不含ACPE的算法相比,在处理分辨率为 $ 1\;024 \times 2\;048 $ $ 768 \times 768 $
... [
20 ]
18.6 2.5 EA-Former MiT 21.9 2.8 Segformer* MiT 15.7 — EA-Former * MiT 18.1 — UperNet ResNet-101 — 2.3 CCnet[9 ] ResNet-101 — 1.7 DeepLabV3[6 ] ResNeSt-101 — 2.4 SETR ViT — 0.4 Segformer# MiT — 2.3 EA-Former # MiT — 2.5 2.5. 消融实验 2.5.1. 自适应卷积位置编码模块(ACPE)消融实验 为了证明ACPE能灵活处理不同分辨率的图片且不会造成显著性能下降,将Cityscapes数据集中的原始图片裁剪为 $ 768 \times 768 $ $ 768 \times 768 $ $ 832 \times 832 $ $ 1\;024 \times 1\;024 $ $ 1\;024 \times 2\;048 $ 表5 所示. 均不含ACPE的SETR和EA-Former在处理不同分辨率的输入图片时,只能对之前所训练的位置编码进行插值处理,导致模型的分割性能显著下降;含ACPE的EA-Former在处理不同于训练图片分辨率的验证图片时,可以通过零值填充卷积灵活地编码位置信息,使得网络可以维持较高的分割精度,不会造成过高的性能损失. 可以看到,与不含ACPE的算法相比,在处理分辨率为 $ 1\;024 \times 2\;048 $ $ 768 \times 768 $
3
... Model evaluation results of different segmentation models on ADE20K dataset
Tab.1 算法 基础网络结构 N /106 GFLOPs mIoU/ FCN[1 ] ResNet-101[19 ] 68.6 275.7 39.9 PSPNet[3 ] ResNet-101 68.1 256.4 44.3 DeepLab-V3+[7 ] ResNet-101 62.7 255.1 45.4 DeepLab-V3+ ResNeSt-101[21 ] 66.3 262.9 46.9 UperNet[22 ] DeiT[23 ] 120.5 90.1 45.3 UperNet Swin-S[24 ] 81.0 259.3 49.3 UperNet Convnext[25 ] 60.2 234.6 46.1 UperNet Focal-B[26 ] 126.0 — 49.0 SETR[11 ] ViT[12 ] 318.5 213.6 47.3 DPT[27 ] ViT 109.7 171.0 46.9 Segmenter Mask[28 ] ViT 102.5 71.1 49.6 Semantic FPN[29 ] PVTv2-B3[30 ] 49.0 62.0 47.3 Semantic FPN VAN-B3[31 ] 49.0 68.0 48.1 SeMask-B FPN[32 ] SeMask Swin 96.0 107.0 49.4 Segformer[20 ] MiT[20 ] 83.9 110.5 50.1 EA-Former MiT 136.4 61.3 49.3 Segformer* MiT 83.9 172.7 52.1 EA-Former * MiT 136.4 95.8 51.0
如表2 所示,以轻量级的MiT-B0为基础网络结构,利用ADE20K数据集训练多种实时语义分割模型,公平地比较模型之间的各项指标,进一步证明EA-Former的高效性. 表中,FPS为模型推理速度. 即使采用相同的基础网络结构MiT-B0,与之前取得最优分割精度的SETR、Segformer、Segmenter等Transformer语义分割模型相比,本研究提出的轻量级EA-Former-T在保持更低的计算量和更高推理速度的同时,mIoU更优. 虽然UperNet分割算法得到的mIoU比EA-Former-T的mIoU更优,但其计算量是EA-Former-T的4倍,且推理速度仅为EA-Former-T的57.9%. 模型对比研究结果表明,EA-Former中JRSA能够有效地降低自注意力机制的计算复杂度、维持分割精度. ...
... Model evaluation results of different segmentation models on Cityscapes dataset
Tab.3 算法 基础网络结构 N /106 GFLOPs mIoU/% FCN[1 ] ResNet-101[19 ] 68.4 619.6 75.5 PSPNet[3 ] ResNet-101 67.9 576.3 79.7 DeepLabV3+[7 ] ResNet-101 62.5 571.6 80.6 CCnet[9 ] ResNet-101 68.8 625.7 79.4 UperNet[22 ] ResNet-101 85.4 576.5 80.1 DeepLabV3[6 ] ResNeSt-101[21 ] 90.8 798.9 80.4 OCRNet[33 ] HRNet[34 ] 70.3 364.7 80.7 SETR[11 ] ViT[12 ] 318.3 818.2 79.3 Segformer[20 ] MiT[20 ] 83.9 597.6 81.8 EA-Former MiT 136.4 137.7 82.1 Segformer# MiT 83.9 735.2 84.1 EA-Former # MiT 136.4 191.8 83.9
为了直观地比较不同算法在Cityscapes数据集上的分割效果,可视化不同算法的分割结果如图6 所示. 可以看出,在方框标注的区域,其他网络的分割效果不理想,除EA-Former外,其他均存在明显的识别错误. 在左侧的分割对比中,DeepLabV3+、SETR和Upernet将公交车的部分错判为火车类,FCN则将公交车的顶部识别为建筑类;在右侧的分割对比中,SETR、UperNet均将汽车的前轮部分判断为卡车类,DeepLabV3+、FCN均将汽车的车门部分误判为墙类. 在方框标出的易错区域,EA-Former成功地分割出正确的语义类别,主要原因是Transformer结构拥有全局感受野和灵活的位置编码方式,使得EA-Former拥有更充分的全局上下文信息和更充沛的空间信息,在处理单个大尺度物体或是物体相互遮挡时,能够结合周围的语义信息做出正确的判断. 虽然SETR中也有Transformer结构,但SETR采用的是相对固定的显式位置编码,且编码器部分使用类ViT的直筒型结构,难以生成不同尺度的特征图,仅将编码器最后一层输出的特征图送入解码器进行分割,导致分割效果不佳. EA-Former使用更加灵活的自适应卷积位置编码和可生成多尺度特征图的金字塔型编码网络,因此EA-Former可以结合低层的空间特征图和高层的语义特征图输出更精准的分割结果. ...
... Evaluation results of inference speed for different segmentation models on ADE20K dataset and Cityscapes dataset
Tab.4 算法 基础网络结构 FPS/(帧 $\cdot {{\rm{s}}^{ - 1} }$ ADE20K Citysapes FCN[1 ] ResNet-101[19 ] 20.7 1.7 PSPNet[3 ] ResNet-101 20.3 1.8 DeepLabV3+[7 ] ResNet-101 18.7 1.6 DeepLabV3+ ResNeSt-101[21 ] 16.1 2.5 UperNet[22 ] Swin-S[24 ] 20.1 — UperNet Convnext[25 ] 17.1 — SETR[11 ] ViT[12 ] 8.3 — DPT[27 ] ViT 20.5 — Segmenter Mask[28 ] ViT 21.3 — Segformer[20 ] MiT[20 ] 18.6 2.5 EA-Former MiT 21.9 2.8 Segformer* MiT 15.7 — EA-Former * MiT 18.1 — UperNet ResNet-101 — 2.3 CCnet[9 ] ResNet-101 — 1.7 DeepLabV3[6 ] ResNeSt-101 — 2.4 SETR ViT — 0.4 Segformer# MiT — 2.3 EA-Former # MiT — 2.5
2.5. 消融实验 2.5.1. 自适应卷积位置编码模块(ACPE)消融实验 为了证明ACPE能灵活处理不同分辨率的图片且不会造成显著性能下降,将Cityscapes数据集中的原始图片裁剪为 $ 768 \times 768 $ $ 768 \times 768 $ $ 832 \times 832 $ $ 1\;024 \times 1\;024 $ $ 1\;024 \times 2\;048 $ 表5 所示. 均不含ACPE的SETR和EA-Former在处理不同分辨率的输入图片时,只能对之前所训练的位置编码进行插值处理,导致模型的分割性能显著下降;含ACPE的EA-Former在处理不同于训练图片分辨率的验证图片时,可以通过零值填充卷积灵活地编码位置信息,使得网络可以维持较高的分割精度,不会造成过高的性能损失. 可以看到,与不含ACPE的算法相比,在处理分辨率为 $ 1\;024 \times 2\;048 $ $ 768 \times 768 $
4
... Model evaluation results of different segmentation models on ADE20K dataset
Tab.1 算法 基础网络结构 N /106 GFLOPs mIoU/ FCN[1 ] ResNet-101[19 ] 68.6 275.7 39.9 PSPNet[3 ] ResNet-101 68.1 256.4 44.3 DeepLab-V3+[7 ] ResNet-101 62.7 255.1 45.4 DeepLab-V3+ ResNeSt-101[21 ] 66.3 262.9 46.9 UperNet[22 ] DeiT[23 ] 120.5 90.1 45.3 UperNet Swin-S[24 ] 81.0 259.3 49.3 UperNet Convnext[25 ] 60.2 234.6 46.1 UperNet Focal-B[26 ] 126.0 — 49.0 SETR[11 ] ViT[12 ] 318.5 213.6 47.3 DPT[27 ] ViT 109.7 171.0 46.9 Segmenter Mask[28 ] ViT 102.5 71.1 49.6 Semantic FPN[29 ] PVTv2-B3[30 ] 49.0 62.0 47.3 Semantic FPN VAN-B3[31 ] 49.0 68.0 48.1 SeMask-B FPN[32 ] SeMask Swin 96.0 107.0 49.4 Segformer[20 ] MiT[20 ] 83.9 110.5 50.1 EA-Former MiT 136.4 61.3 49.3 Segformer* MiT 83.9 172.7 52.1 EA-Former * MiT 136.4 95.8 51.0
如表2 所示,以轻量级的MiT-B0为基础网络结构,利用ADE20K数据集训练多种实时语义分割模型,公平地比较模型之间的各项指标,进一步证明EA-Former的高效性. 表中,FPS为模型推理速度. 即使采用相同的基础网络结构MiT-B0,与之前取得最优分割精度的SETR、Segformer、Segmenter等Transformer语义分割模型相比,本研究提出的轻量级EA-Former-T在保持更低的计算量和更高推理速度的同时,mIoU更优. 虽然UperNet分割算法得到的mIoU比EA-Former-T的mIoU更优,但其计算量是EA-Former-T的4倍,且推理速度仅为EA-Former-T的57.9%. 模型对比研究结果表明,EA-Former中JRSA能够有效地降低自注意力机制的计算复杂度、维持分割精度. ...
... Model evaluation results of lightweight segmentation models on ADE20K dataset
Tab.2 算法 基础网络结构 GFLOPs FPS/ $ \cdot {{\rm{s}}^{ - 1}} $ mIoU/ SETR[11 ] MiT-B0[20 ] 25.3 28.7 34.8 Segformer[20 ] MiT-B0 8.6 50.5 37.5 UperNet[22 ] MiT-B0 28.5 29.6 39.3 Segmenter[28 ] MiT-B0 7.9 49.2 35.9 Semantic FPN[29 ] MiT-B0 23.0 46.4 37.1 EA-Former-T MiT-B0 7.1 51.1 38.1
如图5 所示,为了更直观地对比不同算法的分割精度在训练过程中的变化,将典型算法在训练ADE20K数据集时的平均交并比变化可视化,其中Epoch为训练迭代轮数. 相较于如FCN、DeeplabV3+、PSPnet和Convnext等基于CNN的语义分割网络, EA-Former的语义分割精度有显著提升. 得益于单层Transformer结构拥有全局感受野的优势,在迭代轮数较小时,EA-Former能够利用所获取的丰富上下文信息迅速取得较高的mIoU,相比之下,基于CNN的语义分割网络则需要漫长的训练来逐步提高分割精度. ...
... Model evaluation results of different segmentation models on Cityscapes dataset
Tab.3 算法 基础网络结构 N /106 GFLOPs mIoU/% FCN[1 ] ResNet-101[19 ] 68.4 619.6 75.5 PSPNet[3 ] ResNet-101 67.9 576.3 79.7 DeepLabV3+[7 ] ResNet-101 62.5 571.6 80.6 CCnet[9 ] ResNet-101 68.8 625.7 79.4 UperNet[22 ] ResNet-101 85.4 576.5 80.1 DeepLabV3[6 ] ResNeSt-101[21 ] 90.8 798.9 80.4 OCRNet[33 ] HRNet[34 ] 70.3 364.7 80.7 SETR[11 ] ViT[12 ] 318.3 818.2 79.3 Segformer[20 ] MiT[20 ] 83.9 597.6 81.8 EA-Former MiT 136.4 137.7 82.1 Segformer# MiT 83.9 735.2 84.1 EA-Former # MiT 136.4 191.8 83.9
为了直观地比较不同算法在Cityscapes数据集上的分割效果,可视化不同算法的分割结果如图6 所示. 可以看出,在方框标注的区域,其他网络的分割效果不理想,除EA-Former外,其他均存在明显的识别错误. 在左侧的分割对比中,DeepLabV3+、SETR和Upernet将公交车的部分错判为火车类,FCN则将公交车的顶部识别为建筑类;在右侧的分割对比中,SETR、UperNet均将汽车的前轮部分判断为卡车类,DeepLabV3+、FCN均将汽车的车门部分误判为墙类. 在方框标出的易错区域,EA-Former成功地分割出正确的语义类别,主要原因是Transformer结构拥有全局感受野和灵活的位置编码方式,使得EA-Former拥有更充分的全局上下文信息和更充沛的空间信息,在处理单个大尺度物体或是物体相互遮挡时,能够结合周围的语义信息做出正确的判断. 虽然SETR中也有Transformer结构,但SETR采用的是相对固定的显式位置编码,且编码器部分使用类ViT的直筒型结构,难以生成不同尺度的特征图,仅将编码器最后一层输出的特征图送入解码器进行分割,导致分割效果不佳. EA-Former使用更加灵活的自适应卷积位置编码和可生成多尺度特征图的金字塔型编码网络,因此EA-Former可以结合低层的空间特征图和高层的语义特征图输出更精准的分割结果. ...
... Evaluation results of inference speed for different segmentation models on ADE20K dataset and Cityscapes dataset
Tab.4 算法 基础网络结构 FPS/(帧 $\cdot {{\rm{s}}^{ - 1} }$ ADE20K Citysapes FCN[1 ] ResNet-101[19 ] 20.7 1.7 PSPNet[3 ] ResNet-101 20.3 1.8 DeepLabV3+[7 ] ResNet-101 18.7 1.6 DeepLabV3+ ResNeSt-101[21 ] 16.1 2.5 UperNet[22 ] Swin-S[24 ] 20.1 — UperNet Convnext[25 ] 17.1 — SETR[11 ] ViT[12 ] 8.3 — DPT[27 ] ViT 20.5 — Segmenter Mask[28 ] ViT 21.3 — Segformer[20 ] MiT[20 ] 18.6 2.5 EA-Former MiT 21.9 2.8 Segformer* MiT 15.7 — EA-Former * MiT 18.1 — UperNet ResNet-101 — 2.3 CCnet[9 ] ResNet-101 — 1.7 DeepLabV3[6 ] ResNeSt-101 — 2.4 SETR ViT — 0.4 Segformer# MiT — 2.3 EA-Former # MiT — 2.5
2.5. 消融实验 2.5.1. 自适应卷积位置编码模块(ACPE)消融实验 为了证明ACPE能灵活处理不同分辨率的图片且不会造成显著性能下降,将Cityscapes数据集中的原始图片裁剪为 $ 768 \times 768 $ $ 768 \times 768 $ $ 832 \times 832 $ $ 1\;024 \times 1\;024 $ $ 1\;024 \times 2\;048 $ 表5 所示. 均不含ACPE的SETR和EA-Former在处理不同分辨率的输入图片时,只能对之前所训练的位置编码进行插值处理,导致模型的分割性能显著下降;含ACPE的EA-Former在处理不同于训练图片分辨率的验证图片时,可以通过零值填充卷积灵活地编码位置信息,使得网络可以维持较高的分割精度,不会造成过高的性能损失. 可以看到,与不含ACPE的算法相比,在处理分辨率为 $ 1\;024 \times 2\;048 $ $ 768 \times 768 $
1
... Model evaluation results of different segmentation models on ADE20K dataset
Tab.1 算法 基础网络结构 N /106 GFLOPs mIoU/ FCN[1 ] ResNet-101[19 ] 68.6 275.7 39.9 PSPNet[3 ] ResNet-101 68.1 256.4 44.3 DeepLab-V3+[7 ] ResNet-101 62.7 255.1 45.4 DeepLab-V3+ ResNeSt-101[21 ] 66.3 262.9 46.9 UperNet[22 ] DeiT[23 ] 120.5 90.1 45.3 UperNet Swin-S[24 ] 81.0 259.3 49.3 UperNet Convnext[25 ] 60.2 234.6 46.1 UperNet Focal-B[26 ] 126.0 — 49.0 SETR[11 ] ViT[12 ] 318.5 213.6 47.3 DPT[27 ] ViT 109.7 171.0 46.9 Segmenter Mask[28 ] ViT 102.5 71.1 49.6 Semantic FPN[29 ] PVTv2-B3[30 ] 49.0 62.0 47.3 Semantic FPN VAN-B3[31 ] 49.0 68.0 48.1 SeMask-B FPN[32 ] SeMask Swin 96.0 107.0 49.4 Segformer[20 ] MiT[20 ] 83.9 110.5 50.1 EA-Former MiT 136.4 61.3 49.3 Segformer* MiT 83.9 172.7 52.1 EA-Former * MiT 136.4 95.8 51.0
如表2 所示,以轻量级的MiT-B0为基础网络结构,利用ADE20K数据集训练多种实时语义分割模型,公平地比较模型之间的各项指标,进一步证明EA-Former的高效性. 表中,FPS为模型推理速度. 即使采用相同的基础网络结构MiT-B0,与之前取得最优分割精度的SETR、Segformer、Segmenter等Transformer语义分割模型相比,本研究提出的轻量级EA-Former-T在保持更低的计算量和更高推理速度的同时,mIoU更优. 虽然UperNet分割算法得到的mIoU比EA-Former-T的mIoU更优,但其计算量是EA-Former-T的4倍,且推理速度仅为EA-Former-T的57.9%. 模型对比研究结果表明,EA-Former中JRSA能够有效地降低自注意力机制的计算复杂度、维持分割精度. ...
2
... Model evaluation results of different segmentation models on ADE20K dataset
Tab.1 算法 基础网络结构 N /106 GFLOPs mIoU/ FCN[1 ] ResNet-101[19 ] 68.6 275.7 39.9 PSPNet[3 ] ResNet-101 68.1 256.4 44.3 DeepLab-V3+[7 ] ResNet-101 62.7 255.1 45.4 DeepLab-V3+ ResNeSt-101[21 ] 66.3 262.9 46.9 UperNet[22 ] DeiT[23 ] 120.5 90.1 45.3 UperNet Swin-S[24 ] 81.0 259.3 49.3 UperNet Convnext[25 ] 60.2 234.6 46.1 UperNet Focal-B[26 ] 126.0 — 49.0 SETR[11 ] ViT[12 ] 318.5 213.6 47.3 DPT[27 ] ViT 109.7 171.0 46.9 Segmenter Mask[28 ] ViT 102.5 71.1 49.6 Semantic FPN[29 ] PVTv2-B3[30 ] 49.0 62.0 47.3 Semantic FPN VAN-B3[31 ] 49.0 68.0 48.1 SeMask-B FPN[32 ] SeMask Swin 96.0 107.0 49.4 Segformer[20 ] MiT[20 ] 83.9 110.5 50.1 EA-Former MiT 136.4 61.3 49.3 Segformer* MiT 83.9 172.7 52.1 EA-Former * MiT 136.4 95.8 51.0
如表2 所示,以轻量级的MiT-B0为基础网络结构,利用ADE20K数据集训练多种实时语义分割模型,公平地比较模型之间的各项指标,进一步证明EA-Former的高效性. 表中,FPS为模型推理速度. 即使采用相同的基础网络结构MiT-B0,与之前取得最优分割精度的SETR、Segformer、Segmenter等Transformer语义分割模型相比,本研究提出的轻量级EA-Former-T在保持更低的计算量和更高推理速度的同时,mIoU更优. 虽然UperNet分割算法得到的mIoU比EA-Former-T的mIoU更优,但其计算量是EA-Former-T的4倍,且推理速度仅为EA-Former-T的57.9%. 模型对比研究结果表明,EA-Former中JRSA能够有效地降低自注意力机制的计算复杂度、维持分割精度. ...
... Evaluation results of inference speed for different segmentation models on ADE20K dataset and Cityscapes dataset
Tab.4 算法 基础网络结构 FPS/(帧 $\cdot {{\rm{s}}^{ - 1} }$ ADE20K Citysapes FCN[1 ] ResNet-101[19 ] 20.7 1.7 PSPNet[3 ] ResNet-101 20.3 1.8 DeepLabV3+[7 ] ResNet-101 18.7 1.6 DeepLabV3+ ResNeSt-101[21 ] 16.1 2.5 UperNet[22 ] Swin-S[24 ] 20.1 — UperNet Convnext[25 ] 17.1 — SETR[11 ] ViT[12 ] 8.3 — DPT[27 ] ViT 20.5 — Segmenter Mask[28 ] ViT 21.3 — Segformer[20 ] MiT[20 ] 18.6 2.5 EA-Former MiT 21.9 2.8 Segformer* MiT 15.7 — EA-Former * MiT 18.1 — UperNet ResNet-101 — 2.3 CCnet[9 ] ResNet-101 — 1.7 DeepLabV3[6 ] ResNeSt-101 — 2.4 SETR ViT — 0.4 Segformer# MiT — 2.3 EA-Former # MiT — 2.5
2.5. 消融实验 2.5.1. 自适应卷积位置编码模块(ACPE)消融实验 为了证明ACPE能灵活处理不同分辨率的图片且不会造成显著性能下降,将Cityscapes数据集中的原始图片裁剪为 $ 768 \times 768 $ $ 768 \times 768 $ $ 832 \times 832 $ $ 1\;024 \times 1\;024 $ $ 1\;024 \times 2\;048 $ 表5 所示. 均不含ACPE的SETR和EA-Former在处理不同分辨率的输入图片时,只能对之前所训练的位置编码进行插值处理,导致模型的分割性能显著下降;含ACPE的EA-Former在处理不同于训练图片分辨率的验证图片时,可以通过零值填充卷积灵活地编码位置信息,使得网络可以维持较高的分割精度,不会造成过高的性能损失. 可以看到,与不含ACPE的算法相比,在处理分辨率为 $ 1\;024 \times 2\;048 $ $ 768 \times 768 $
2
... Model evaluation results of different segmentation models on ADE20K dataset
Tab.1 算法 基础网络结构 N /106 GFLOPs mIoU/ FCN[1 ] ResNet-101[19 ] 68.6 275.7 39.9 PSPNet[3 ] ResNet-101 68.1 256.4 44.3 DeepLab-V3+[7 ] ResNet-101 62.7 255.1 45.4 DeepLab-V3+ ResNeSt-101[21 ] 66.3 262.9 46.9 UperNet[22 ] DeiT[23 ] 120.5 90.1 45.3 UperNet Swin-S[24 ] 81.0 259.3 49.3 UperNet Convnext[25 ] 60.2 234.6 46.1 UperNet Focal-B[26 ] 126.0 — 49.0 SETR[11 ] ViT[12 ] 318.5 213.6 47.3 DPT[27 ] ViT 109.7 171.0 46.9 Segmenter Mask[28 ] ViT 102.5 71.1 49.6 Semantic FPN[29 ] PVTv2-B3[30 ] 49.0 62.0 47.3 Semantic FPN VAN-B3[31 ] 49.0 68.0 48.1 SeMask-B FPN[32 ] SeMask Swin 96.0 107.0 49.4 Segformer[20 ] MiT[20 ] 83.9 110.5 50.1 EA-Former MiT 136.4 61.3 49.3 Segformer* MiT 83.9 172.7 52.1 EA-Former * MiT 136.4 95.8 51.0
如表2 所示,以轻量级的MiT-B0为基础网络结构,利用ADE20K数据集训练多种实时语义分割模型,公平地比较模型之间的各项指标,进一步证明EA-Former的高效性. 表中,FPS为模型推理速度. 即使采用相同的基础网络结构MiT-B0,与之前取得最优分割精度的SETR、Segformer、Segmenter等Transformer语义分割模型相比,本研究提出的轻量级EA-Former-T在保持更低的计算量和更高推理速度的同时,mIoU更优. 虽然UperNet分割算法得到的mIoU比EA-Former-T的mIoU更优,但其计算量是EA-Former-T的4倍,且推理速度仅为EA-Former-T的57.9%. 模型对比研究结果表明,EA-Former中JRSA能够有效地降低自注意力机制的计算复杂度、维持分割精度. ...
... Evaluation results of inference speed for different segmentation models on ADE20K dataset and Cityscapes dataset
Tab.4 算法 基础网络结构 FPS/(帧 $\cdot {{\rm{s}}^{ - 1} }$ ADE20K Citysapes FCN[1 ] ResNet-101[19 ] 20.7 1.7 PSPNet[3 ] ResNet-101 20.3 1.8 DeepLabV3+[7 ] ResNet-101 18.7 1.6 DeepLabV3+ ResNeSt-101[21 ] 16.1 2.5 UperNet[22 ] Swin-S[24 ] 20.1 — UperNet Convnext[25 ] 17.1 — SETR[11 ] ViT[12 ] 8.3 — DPT[27 ] ViT 20.5 — Segmenter Mask[28 ] ViT 21.3 — Segformer[20 ] MiT[20 ] 18.6 2.5 EA-Former MiT 21.9 2.8 Segformer* MiT 15.7 — EA-Former * MiT 18.1 — UperNet ResNet-101 — 2.3 CCnet[9 ] ResNet-101 — 1.7 DeepLabV3[6 ] ResNeSt-101 — 2.4 SETR ViT — 0.4 Segformer# MiT — 2.3 EA-Former # MiT — 2.5
2.5. 消融实验 2.5.1. 自适应卷积位置编码模块(ACPE)消融实验 为了证明ACPE能灵活处理不同分辨率的图片且不会造成显著性能下降,将Cityscapes数据集中的原始图片裁剪为 $ 768 \times 768 $ $ 768 \times 768 $ $ 832 \times 832 $ $ 1\;024 \times 1\;024 $ $ 1\;024 \times 2\;048 $ 表5 所示. 均不含ACPE的SETR和EA-Former在处理不同分辨率的输入图片时,只能对之前所训练的位置编码进行插值处理,导致模型的分割性能显著下降;含ACPE的EA-Former在处理不同于训练图片分辨率的验证图片时,可以通过零值填充卷积灵活地编码位置信息,使得网络可以维持较高的分割精度,不会造成过高的性能损失. 可以看到,与不含ACPE的算法相比,在处理分辨率为 $ 1\;024 \times 2\;048 $ $ 768 \times 768 $
1
... Model evaluation results of different segmentation models on ADE20K dataset
Tab.1 算法 基础网络结构 N /106 GFLOPs mIoU/ FCN[1 ] ResNet-101[19 ] 68.6 275.7 39.9 PSPNet[3 ] ResNet-101 68.1 256.4 44.3 DeepLab-V3+[7 ] ResNet-101 62.7 255.1 45.4 DeepLab-V3+ ResNeSt-101[21 ] 66.3 262.9 46.9 UperNet[22 ] DeiT[23 ] 120.5 90.1 45.3 UperNet Swin-S[24 ] 81.0 259.3 49.3 UperNet Convnext[25 ] 60.2 234.6 46.1 UperNet Focal-B[26 ] 126.0 — 49.0 SETR[11 ] ViT[12 ] 318.5 213.6 47.3 DPT[27 ] ViT 109.7 171.0 46.9 Segmenter Mask[28 ] ViT 102.5 71.1 49.6 Semantic FPN[29 ] PVTv2-B3[30 ] 49.0 62.0 47.3 Semantic FPN VAN-B3[31 ] 49.0 68.0 48.1 SeMask-B FPN[32 ] SeMask Swin 96.0 107.0 49.4 Segformer[20 ] MiT[20 ] 83.9 110.5 50.1 EA-Former MiT 136.4 61.3 49.3 Segformer* MiT 83.9 172.7 52.1 EA-Former * MiT 136.4 95.8 51.0
如表2 所示,以轻量级的MiT-B0为基础网络结构,利用ADE20K数据集训练多种实时语义分割模型,公平地比较模型之间的各项指标,进一步证明EA-Former的高效性. 表中,FPS为模型推理速度. 即使采用相同的基础网络结构MiT-B0,与之前取得最优分割精度的SETR、Segformer、Segmenter等Transformer语义分割模型相比,本研究提出的轻量级EA-Former-T在保持更低的计算量和更高推理速度的同时,mIoU更优. 虽然UperNet分割算法得到的mIoU比EA-Former-T的mIoU更优,但其计算量是EA-Former-T的4倍,且推理速度仅为EA-Former-T的57.9%. 模型对比研究结果表明,EA-Former中JRSA能够有效地降低自注意力机制的计算复杂度、维持分割精度. ...
2
... Model evaluation results of different segmentation models on ADE20K dataset
Tab.1 算法 基础网络结构 N /106 GFLOPs mIoU/ FCN[1 ] ResNet-101[19 ] 68.6 275.7 39.9 PSPNet[3 ] ResNet-101 68.1 256.4 44.3 DeepLab-V3+[7 ] ResNet-101 62.7 255.1 45.4 DeepLab-V3+ ResNeSt-101[21 ] 66.3 262.9 46.9 UperNet[22 ] DeiT[23 ] 120.5 90.1 45.3 UperNet Swin-S[24 ] 81.0 259.3 49.3 UperNet Convnext[25 ] 60.2 234.6 46.1 UperNet Focal-B[26 ] 126.0 — 49.0 SETR[11 ] ViT[12 ] 318.5 213.6 47.3 DPT[27 ] ViT 109.7 171.0 46.9 Segmenter Mask[28 ] ViT 102.5 71.1 49.6 Semantic FPN[29 ] PVTv2-B3[30 ] 49.0 62.0 47.3 Semantic FPN VAN-B3[31 ] 49.0 68.0 48.1 SeMask-B FPN[32 ] SeMask Swin 96.0 107.0 49.4 Segformer[20 ] MiT[20 ] 83.9 110.5 50.1 EA-Former MiT 136.4 61.3 49.3 Segformer* MiT 83.9 172.7 52.1 EA-Former * MiT 136.4 95.8 51.0
如表2 所示,以轻量级的MiT-B0为基础网络结构,利用ADE20K数据集训练多种实时语义分割模型,公平地比较模型之间的各项指标,进一步证明EA-Former的高效性. 表中,FPS为模型推理速度. 即使采用相同的基础网络结构MiT-B0,与之前取得最优分割精度的SETR、Segformer、Segmenter等Transformer语义分割模型相比,本研究提出的轻量级EA-Former-T在保持更低的计算量和更高推理速度的同时,mIoU更优. 虽然UperNet分割算法得到的mIoU比EA-Former-T的mIoU更优,但其计算量是EA-Former-T的4倍,且推理速度仅为EA-Former-T的57.9%. 模型对比研究结果表明,EA-Former中JRSA能够有效地降低自注意力机制的计算复杂度、维持分割精度. ...
... Evaluation results of inference speed for different segmentation models on ADE20K dataset and Cityscapes dataset
Tab.4 算法 基础网络结构 FPS/(帧 $\cdot {{\rm{s}}^{ - 1} }$ ADE20K Citysapes FCN[1 ] ResNet-101[19 ] 20.7 1.7 PSPNet[3 ] ResNet-101 20.3 1.8 DeepLabV3+[7 ] ResNet-101 18.7 1.6 DeepLabV3+ ResNeSt-101[21 ] 16.1 2.5 UperNet[22 ] Swin-S[24 ] 20.1 — UperNet Convnext[25 ] 17.1 — SETR[11 ] ViT[12 ] 8.3 — DPT[27 ] ViT 20.5 — Segmenter Mask[28 ] ViT 21.3 — Segformer[20 ] MiT[20 ] 18.6 2.5 EA-Former MiT 21.9 2.8 Segformer* MiT 15.7 — EA-Former * MiT 18.1 — UperNet ResNet-101 — 2.3 CCnet[9 ] ResNet-101 — 1.7 DeepLabV3[6 ] ResNeSt-101 — 2.4 SETR ViT — 0.4 Segformer# MiT — 2.3 EA-Former # MiT — 2.5
2.5. 消融实验 2.5.1. 自适应卷积位置编码模块(ACPE)消融实验 为了证明ACPE能灵活处理不同分辨率的图片且不会造成显著性能下降,将Cityscapes数据集中的原始图片裁剪为 $ 768 \times 768 $ $ 768 \times 768 $ $ 832 \times 832 $ $ 1\;024 \times 1\;024 $ $ 1\;024 \times 2\;048 $ 表5 所示. 均不含ACPE的SETR和EA-Former在处理不同分辨率的输入图片时,只能对之前所训练的位置编码进行插值处理,导致模型的分割性能显著下降;含ACPE的EA-Former在处理不同于训练图片分辨率的验证图片时,可以通过零值填充卷积灵活地编码位置信息,使得网络可以维持较高的分割精度,不会造成过高的性能损失. 可以看到,与不含ACPE的算法相比,在处理分辨率为 $ 1\;024 \times 2\;048 $ $ 768 \times 768 $
3
... Model evaluation results of different segmentation models on ADE20K dataset
Tab.1 算法 基础网络结构 N /106 GFLOPs mIoU/ FCN[1 ] ResNet-101[19 ] 68.6 275.7 39.9 PSPNet[3 ] ResNet-101 68.1 256.4 44.3 DeepLab-V3+[7 ] ResNet-101 62.7 255.1 45.4 DeepLab-V3+ ResNeSt-101[21 ] 66.3 262.9 46.9 UperNet[22 ] DeiT[23 ] 120.5 90.1 45.3 UperNet Swin-S[24 ] 81.0 259.3 49.3 UperNet Convnext[25 ] 60.2 234.6 46.1 UperNet Focal-B[26 ] 126.0 — 49.0 SETR[11 ] ViT[12 ] 318.5 213.6 47.3 DPT[27 ] ViT 109.7 171.0 46.9 Segmenter Mask[28 ] ViT 102.5 71.1 49.6 Semantic FPN[29 ] PVTv2-B3[30 ] 49.0 62.0 47.3 Semantic FPN VAN-B3[31 ] 49.0 68.0 48.1 SeMask-B FPN[32 ] SeMask Swin 96.0 107.0 49.4 Segformer[20 ] MiT[20 ] 83.9 110.5 50.1 EA-Former MiT 136.4 61.3 49.3 Segformer* MiT 83.9 172.7 52.1 EA-Former * MiT 136.4 95.8 51.0
如表2 所示,以轻量级的MiT-B0为基础网络结构,利用ADE20K数据集训练多种实时语义分割模型,公平地比较模型之间的各项指标,进一步证明EA-Former的高效性. 表中,FPS为模型推理速度. 即使采用相同的基础网络结构MiT-B0,与之前取得最优分割精度的SETR、Segformer、Segmenter等Transformer语义分割模型相比,本研究提出的轻量级EA-Former-T在保持更低的计算量和更高推理速度的同时,mIoU更优. 虽然UperNet分割算法得到的mIoU比EA-Former-T的mIoU更优,但其计算量是EA-Former-T的4倍,且推理速度仅为EA-Former-T的57.9%. 模型对比研究结果表明,EA-Former中JRSA能够有效地降低自注意力机制的计算复杂度、维持分割精度. ...
... Model evaluation results of lightweight segmentation models on ADE20K dataset
Tab.2 算法 基础网络结构 GFLOPs FPS/ $ \cdot {{\rm{s}}^{ - 1}} $ mIoU/ SETR[11 ] MiT-B0[20 ] 25.3 28.7 34.8 Segformer[20 ] MiT-B0 8.6 50.5 37.5 UperNet[22 ] MiT-B0 28.5 29.6 39.3 Segmenter[28 ] MiT-B0 7.9 49.2 35.9 Semantic FPN[29 ] MiT-B0 23.0 46.4 37.1 EA-Former-T MiT-B0 7.1 51.1 38.1
如图5 所示,为了更直观地对比不同算法的分割精度在训练过程中的变化,将典型算法在训练ADE20K数据集时的平均交并比变化可视化,其中Epoch为训练迭代轮数. 相较于如FCN、DeeplabV3+、PSPnet和Convnext等基于CNN的语义分割网络, EA-Former的语义分割精度有显著提升. 得益于单层Transformer结构拥有全局感受野的优势,在迭代轮数较小时,EA-Former能够利用所获取的丰富上下文信息迅速取得较高的mIoU,相比之下,基于CNN的语义分割网络则需要漫长的训练来逐步提高分割精度. ...
... Evaluation results of inference speed for different segmentation models on ADE20K dataset and Cityscapes dataset
Tab.4 算法 基础网络结构 FPS/(帧 $\cdot {{\rm{s}}^{ - 1} }$ ADE20K Citysapes FCN[1 ] ResNet-101[19 ] 20.7 1.7 PSPNet[3 ] ResNet-101 20.3 1.8 DeepLabV3+[7 ] ResNet-101 18.7 1.6 DeepLabV3+ ResNeSt-101[21 ] 16.1 2.5 UperNet[22 ] Swin-S[24 ] 20.1 — UperNet Convnext[25 ] 17.1 — SETR[11 ] ViT[12 ] 8.3 — DPT[27 ] ViT 20.5 — Segmenter Mask[28 ] ViT 21.3 — Segformer[20 ] MiT[20 ] 18.6 2.5 EA-Former MiT 21.9 2.8 Segformer* MiT 15.7 — EA-Former * MiT 18.1 — UperNet ResNet-101 — 2.3 CCnet[9 ] ResNet-101 — 1.7 DeepLabV3[6 ] ResNeSt-101 — 2.4 SETR ViT — 0.4 Segformer# MiT — 2.3 EA-Former # MiT — 2.5
2.5. 消融实验 2.5.1. 自适应卷积位置编码模块(ACPE)消融实验 为了证明ACPE能灵活处理不同分辨率的图片且不会造成显著性能下降,将Cityscapes数据集中的原始图片裁剪为 $ 768 \times 768 $ $ 768 \times 768 $ $ 832 \times 832 $ $ 1\;024 \times 1\;024 $ $ 1\;024 \times 2\;048 $ 表5 所示. 均不含ACPE的SETR和EA-Former在处理不同分辨率的输入图片时,只能对之前所训练的位置编码进行插值处理,导致模型的分割性能显著下降;含ACPE的EA-Former在处理不同于训练图片分辨率的验证图片时,可以通过零值填充卷积灵活地编码位置信息,使得网络可以维持较高的分割精度,不会造成过高的性能损失. 可以看到,与不含ACPE的算法相比,在处理分辨率为 $ 1\;024 \times 2\;048 $ $ 768 \times 768 $
2
... Model evaluation results of different segmentation models on ADE20K dataset
Tab.1 算法 基础网络结构 N /106 GFLOPs mIoU/ FCN[1 ] ResNet-101[19 ] 68.6 275.7 39.9 PSPNet[3 ] ResNet-101 68.1 256.4 44.3 DeepLab-V3+[7 ] ResNet-101 62.7 255.1 45.4 DeepLab-V3+ ResNeSt-101[21 ] 66.3 262.9 46.9 UperNet[22 ] DeiT[23 ] 120.5 90.1 45.3 UperNet Swin-S[24 ] 81.0 259.3 49.3 UperNet Convnext[25 ] 60.2 234.6 46.1 UperNet Focal-B[26 ] 126.0 — 49.0 SETR[11 ] ViT[12 ] 318.5 213.6 47.3 DPT[27 ] ViT 109.7 171.0 46.9 Segmenter Mask[28 ] ViT 102.5 71.1 49.6 Semantic FPN[29 ] PVTv2-B3[30 ] 49.0 62.0 47.3 Semantic FPN VAN-B3[31 ] 49.0 68.0 48.1 SeMask-B FPN[32 ] SeMask Swin 96.0 107.0 49.4 Segformer[20 ] MiT[20 ] 83.9 110.5 50.1 EA-Former MiT 136.4 61.3 49.3 Segformer* MiT 83.9 172.7 52.1 EA-Former * MiT 136.4 95.8 51.0
如表2 所示,以轻量级的MiT-B0为基础网络结构,利用ADE20K数据集训练多种实时语义分割模型,公平地比较模型之间的各项指标,进一步证明EA-Former的高效性. 表中,FPS为模型推理速度. 即使采用相同的基础网络结构MiT-B0,与之前取得最优分割精度的SETR、Segformer、Segmenter等Transformer语义分割模型相比,本研究提出的轻量级EA-Former-T在保持更低的计算量和更高推理速度的同时,mIoU更优. 虽然UperNet分割算法得到的mIoU比EA-Former-T的mIoU更优,但其计算量是EA-Former-T的4倍,且推理速度仅为EA-Former-T的57.9%. 模型对比研究结果表明,EA-Former中JRSA能够有效地降低自注意力机制的计算复杂度、维持分割精度. ...
... Model evaluation results of lightweight segmentation models on ADE20K dataset
Tab.2 算法 基础网络结构 GFLOPs FPS/ $ \cdot {{\rm{s}}^{ - 1}} $ mIoU/ SETR[11 ] MiT-B0[20 ] 25.3 28.7 34.8 Segformer[20 ] MiT-B0 8.6 50.5 37.5 UperNet[22 ] MiT-B0 28.5 29.6 39.3 Segmenter[28 ] MiT-B0 7.9 49.2 35.9 Semantic FPN[29 ] MiT-B0 23.0 46.4 37.1 EA-Former-T MiT-B0 7.1 51.1 38.1
如图5 所示,为了更直观地对比不同算法的分割精度在训练过程中的变化,将典型算法在训练ADE20K数据集时的平均交并比变化可视化,其中Epoch为训练迭代轮数. 相较于如FCN、DeeplabV3+、PSPnet和Convnext等基于CNN的语义分割网络, EA-Former的语义分割精度有显著提升. 得益于单层Transformer结构拥有全局感受野的优势,在迭代轮数较小时,EA-Former能够利用所获取的丰富上下文信息迅速取得较高的mIoU,相比之下,基于CNN的语义分割网络则需要漫长的训练来逐步提高分割精度. ...
PVT v2: Improved baselines with pyramid vision transformer
1
2022
... Model evaluation results of different segmentation models on ADE20K dataset
Tab.1 算法 基础网络结构 N /106 GFLOPs mIoU/ FCN[1 ] ResNet-101[19 ] 68.6 275.7 39.9 PSPNet[3 ] ResNet-101 68.1 256.4 44.3 DeepLab-V3+[7 ] ResNet-101 62.7 255.1 45.4 DeepLab-V3+ ResNeSt-101[21 ] 66.3 262.9 46.9 UperNet[22 ] DeiT[23 ] 120.5 90.1 45.3 UperNet Swin-S[24 ] 81.0 259.3 49.3 UperNet Convnext[25 ] 60.2 234.6 46.1 UperNet Focal-B[26 ] 126.0 — 49.0 SETR[11 ] ViT[12 ] 318.5 213.6 47.3 DPT[27 ] ViT 109.7 171.0 46.9 Segmenter Mask[28 ] ViT 102.5 71.1 49.6 Semantic FPN[29 ] PVTv2-B3[30 ] 49.0 62.0 47.3 Semantic FPN VAN-B3[31 ] 49.0 68.0 48.1 SeMask-B FPN[32 ] SeMask Swin 96.0 107.0 49.4 Segformer[20 ] MiT[20 ] 83.9 110.5 50.1 EA-Former MiT 136.4 61.3 49.3 Segformer* MiT 83.9 172.7 52.1 EA-Former * MiT 136.4 95.8 51.0
如表2 所示,以轻量级的MiT-B0为基础网络结构,利用ADE20K数据集训练多种实时语义分割模型,公平地比较模型之间的各项指标,进一步证明EA-Former的高效性. 表中,FPS为模型推理速度. 即使采用相同的基础网络结构MiT-B0,与之前取得最优分割精度的SETR、Segformer、Segmenter等Transformer语义分割模型相比,本研究提出的轻量级EA-Former-T在保持更低的计算量和更高推理速度的同时,mIoU更优. 虽然UperNet分割算法得到的mIoU比EA-Former-T的mIoU更优,但其计算量是EA-Former-T的4倍,且推理速度仅为EA-Former-T的57.9%. 模型对比研究结果表明,EA-Former中JRSA能够有效地降低自注意力机制的计算复杂度、维持分割精度. ...
1
... Model evaluation results of different segmentation models on ADE20K dataset
Tab.1 算法 基础网络结构 N /106 GFLOPs mIoU/ FCN[1 ] ResNet-101[19 ] 68.6 275.7 39.9 PSPNet[3 ] ResNet-101 68.1 256.4 44.3 DeepLab-V3+[7 ] ResNet-101 62.7 255.1 45.4 DeepLab-V3+ ResNeSt-101[21 ] 66.3 262.9 46.9 UperNet[22 ] DeiT[23 ] 120.5 90.1 45.3 UperNet Swin-S[24 ] 81.0 259.3 49.3 UperNet Convnext[25 ] 60.2 234.6 46.1 UperNet Focal-B[26 ] 126.0 — 49.0 SETR[11 ] ViT[12 ] 318.5 213.6 47.3 DPT[27 ] ViT 109.7 171.0 46.9 Segmenter Mask[28 ] ViT 102.5 71.1 49.6 Semantic FPN[29 ] PVTv2-B3[30 ] 49.0 62.0 47.3 Semantic FPN VAN-B3[31 ] 49.0 68.0 48.1 SeMask-B FPN[32 ] SeMask Swin 96.0 107.0 49.4 Segformer[20 ] MiT[20 ] 83.9 110.5 50.1 EA-Former MiT 136.4 61.3 49.3 Segformer* MiT 83.9 172.7 52.1 EA-Former * MiT 136.4 95.8 51.0
如表2 所示,以轻量级的MiT-B0为基础网络结构,利用ADE20K数据集训练多种实时语义分割模型,公平地比较模型之间的各项指标,进一步证明EA-Former的高效性. 表中,FPS为模型推理速度. 即使采用相同的基础网络结构MiT-B0,与之前取得最优分割精度的SETR、Segformer、Segmenter等Transformer语义分割模型相比,本研究提出的轻量级EA-Former-T在保持更低的计算量和更高推理速度的同时,mIoU更优. 虽然UperNet分割算法得到的mIoU比EA-Former-T的mIoU更优,但其计算量是EA-Former-T的4倍,且推理速度仅为EA-Former-T的57.9%. 模型对比研究结果表明,EA-Former中JRSA能够有效地降低自注意力机制的计算复杂度、维持分割精度. ...
1
... Model evaluation results of different segmentation models on ADE20K dataset
Tab.1 算法 基础网络结构 N /106 GFLOPs mIoU/ FCN[1 ] ResNet-101[19 ] 68.6 275.7 39.9 PSPNet[3 ] ResNet-101 68.1 256.4 44.3 DeepLab-V3+[7 ] ResNet-101 62.7 255.1 45.4 DeepLab-V3+ ResNeSt-101[21 ] 66.3 262.9 46.9 UperNet[22 ] DeiT[23 ] 120.5 90.1 45.3 UperNet Swin-S[24 ] 81.0 259.3 49.3 UperNet Convnext[25 ] 60.2 234.6 46.1 UperNet Focal-B[26 ] 126.0 — 49.0 SETR[11 ] ViT[12 ] 318.5 213.6 47.3 DPT[27 ] ViT 109.7 171.0 46.9 Segmenter Mask[28 ] ViT 102.5 71.1 49.6 Semantic FPN[29 ] PVTv2-B3[30 ] 49.0 62.0 47.3 Semantic FPN VAN-B3[31 ] 49.0 68.0 48.1 SeMask-B FPN[32 ] SeMask Swin 96.0 107.0 49.4 Segformer[20 ] MiT[20 ] 83.9 110.5 50.1 EA-Former MiT 136.4 61.3 49.3 Segformer* MiT 83.9 172.7 52.1 EA-Former * MiT 136.4 95.8 51.0
如表2 所示,以轻量级的MiT-B0为基础网络结构,利用ADE20K数据集训练多种实时语义分割模型,公平地比较模型之间的各项指标,进一步证明EA-Former的高效性. 表中,FPS为模型推理速度. 即使采用相同的基础网络结构MiT-B0,与之前取得最优分割精度的SETR、Segformer、Segmenter等Transformer语义分割模型相比,本研究提出的轻量级EA-Former-T在保持更低的计算量和更高推理速度的同时,mIoU更优. 虽然UperNet分割算法得到的mIoU比EA-Former-T的mIoU更优,但其计算量是EA-Former-T的4倍,且推理速度仅为EA-Former-T的57.9%. 模型对比研究结果表明,EA-Former中JRSA能够有效地降低自注意力机制的计算复杂度、维持分割精度. ...
1
... Model evaluation results of different segmentation models on Cityscapes dataset
Tab.3 算法 基础网络结构 N /106 GFLOPs mIoU/% FCN[1 ] ResNet-101[19 ] 68.4 619.6 75.5 PSPNet[3 ] ResNet-101 67.9 576.3 79.7 DeepLabV3+[7 ] ResNet-101 62.5 571.6 80.6 CCnet[9 ] ResNet-101 68.8 625.7 79.4 UperNet[22 ] ResNet-101 85.4 576.5 80.1 DeepLabV3[6 ] ResNeSt-101[21 ] 90.8 798.9 80.4 OCRNet[33 ] HRNet[34 ] 70.3 364.7 80.7 SETR[11 ] ViT[12 ] 318.3 818.2 79.3 Segformer[20 ] MiT[20 ] 83.9 597.6 81.8 EA-Former MiT 136.4 137.7 82.1 Segformer# MiT 83.9 735.2 84.1 EA-Former # MiT 136.4 191.8 83.9
为了直观地比较不同算法在Cityscapes数据集上的分割效果,可视化不同算法的分割结果如图6 所示. 可以看出,在方框标注的区域,其他网络的分割效果不理想,除EA-Former外,其他均存在明显的识别错误. 在左侧的分割对比中,DeepLabV3+、SETR和Upernet将公交车的部分错判为火车类,FCN则将公交车的顶部识别为建筑类;在右侧的分割对比中,SETR、UperNet均将汽车的前轮部分判断为卡车类,DeepLabV3+、FCN均将汽车的车门部分误判为墙类. 在方框标出的易错区域,EA-Former成功地分割出正确的语义类别,主要原因是Transformer结构拥有全局感受野和灵活的位置编码方式,使得EA-Former拥有更充分的全局上下文信息和更充沛的空间信息,在处理单个大尺度物体或是物体相互遮挡时,能够结合周围的语义信息做出正确的判断. 虽然SETR中也有Transformer结构,但SETR采用的是相对固定的显式位置编码,且编码器部分使用类ViT的直筒型结构,难以生成不同尺度的特征图,仅将编码器最后一层输出的特征图送入解码器进行分割,导致分割效果不佳. EA-Former使用更加灵活的自适应卷积位置编码和可生成多尺度特征图的金字塔型编码网络,因此EA-Former可以结合低层的空间特征图和高层的语义特征图输出更精准的分割结果. ...
1
... Model evaluation results of different segmentation models on Cityscapes dataset
Tab.3 算法 基础网络结构 N /106 GFLOPs mIoU/% FCN[1 ] ResNet-101[19 ] 68.4 619.6 75.5 PSPNet[3 ] ResNet-101 67.9 576.3 79.7 DeepLabV3+[7 ] ResNet-101 62.5 571.6 80.6 CCnet[9 ] ResNet-101 68.8 625.7 79.4 UperNet[22 ] ResNet-101 85.4 576.5 80.1 DeepLabV3[6 ] ResNeSt-101[21 ] 90.8 798.9 80.4 OCRNet[33 ] HRNet[34 ] 70.3 364.7 80.7 SETR[11 ] ViT[12 ] 318.3 818.2 79.3 Segformer[20 ] MiT[20 ] 83.9 597.6 81.8 EA-Former MiT 136.4 137.7 82.1 Segformer# MiT 83.9 735.2 84.1 EA-Former # MiT 136.4 191.8 83.9
为了直观地比较不同算法在Cityscapes数据集上的分割效果,可视化不同算法的分割结果如图6 所示. 可以看出,在方框标注的区域,其他网络的分割效果不理想,除EA-Former外,其他均存在明显的识别错误. 在左侧的分割对比中,DeepLabV3+、SETR和Upernet将公交车的部分错判为火车类,FCN则将公交车的顶部识别为建筑类;在右侧的分割对比中,SETR、UperNet均将汽车的前轮部分判断为卡车类,DeepLabV3+、FCN均将汽车的车门部分误判为墙类. 在方框标出的易错区域,EA-Former成功地分割出正确的语义类别,主要原因是Transformer结构拥有全局感受野和灵活的位置编码方式,使得EA-Former拥有更充分的全局上下文信息和更充沛的空间信息,在处理单个大尺度物体或是物体相互遮挡时,能够结合周围的语义信息做出正确的判断. 虽然SETR中也有Transformer结构,但SETR采用的是相对固定的显式位置编码,且编码器部分使用类ViT的直筒型结构,难以生成不同尺度的特征图,仅将编码器最后一层输出的特征图送入解码器进行分割,导致分割效果不佳. EA-Former使用更加灵活的自适应卷积位置编码和可生成多尺度特征图的金字塔型编码网络,因此EA-Former可以结合低层的空间特征图和高层的语义特征图输出更精准的分割结果. ...





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}