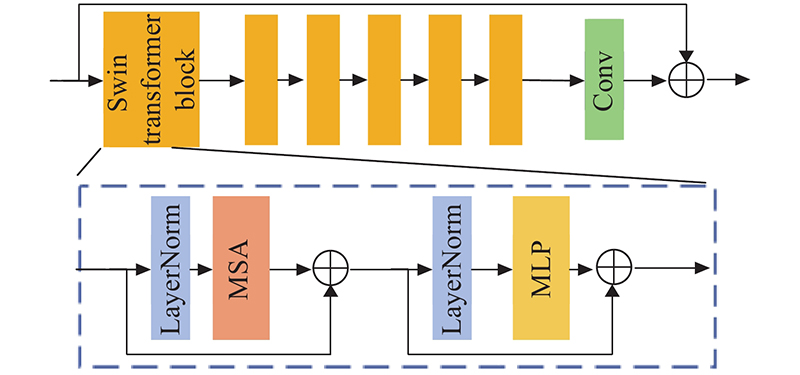
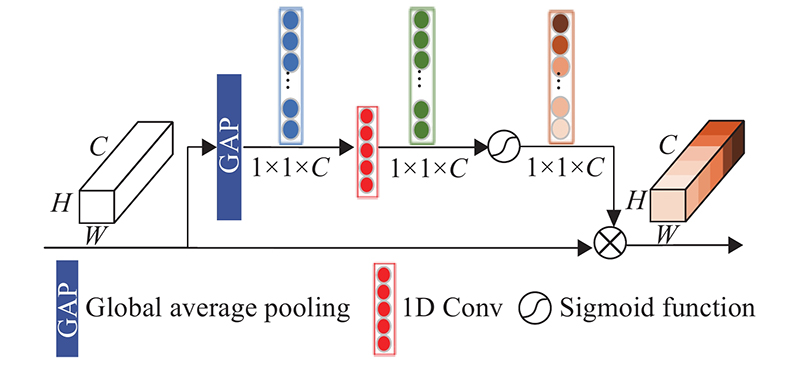
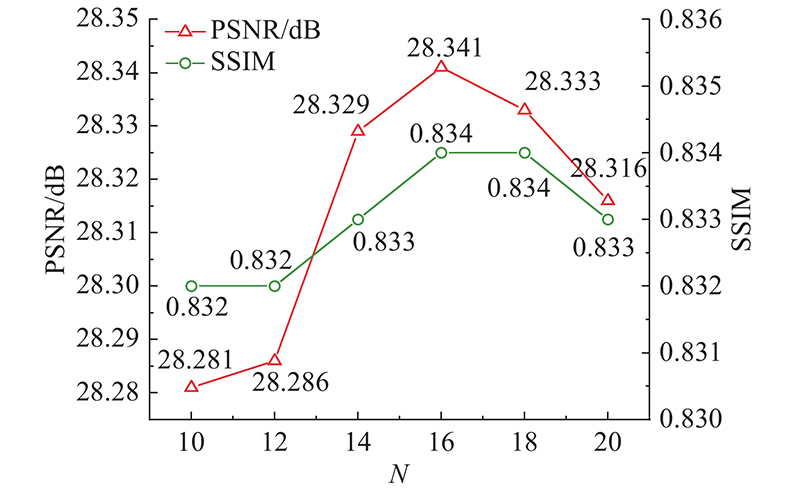
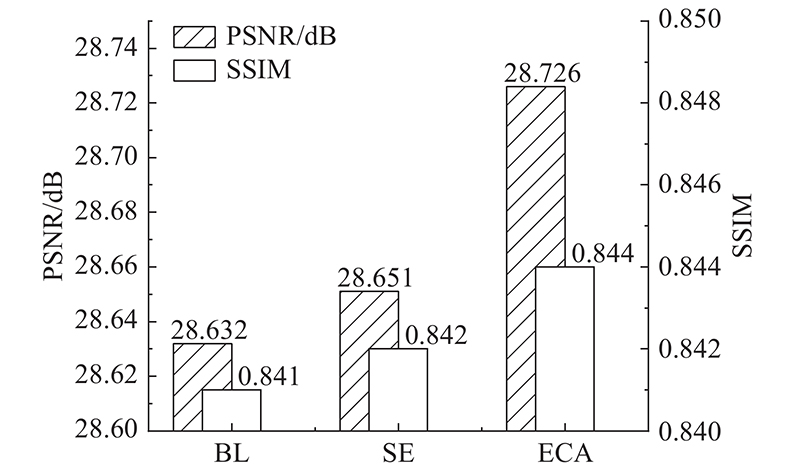
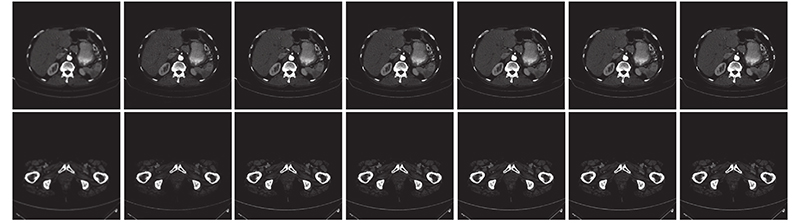
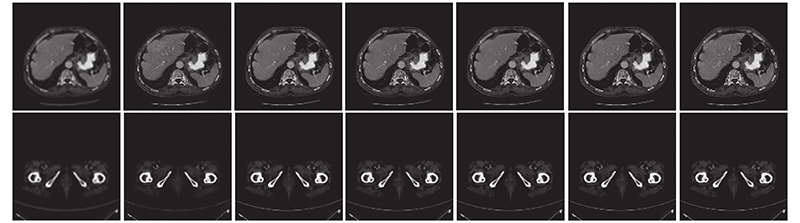
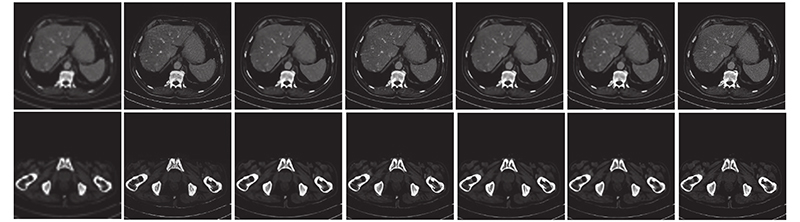
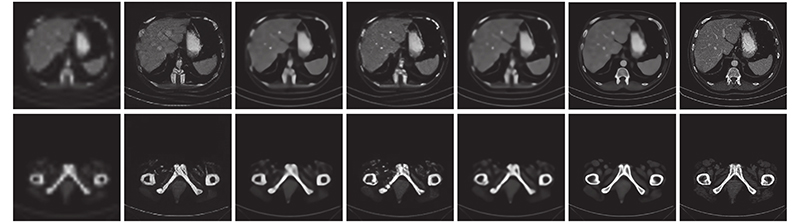
| 计算机技术与控制工程 |
|

|
|
|
| 基于改进Transformer的结构化图像超分辨网络 |
吕鑫栋( ),李娇,邓真楠,冯浩,崔欣桐,邓红霞*() ),李娇,邓真楠,冯浩,崔欣桐,邓红霞*() |
| 太原理工大学 信息与计算机学院,山西 太原 030024 |
|
| Structured image super-resolution network based on improved Transformer |
| Xin-dong LV(),Jiao LI,Zhen-nan DENG,Hao FENG,Xin-tong CUI,Hong-xia DENG*() |
| College of Information and Computer, Taiyuan University of Technology, Taiyuan 030024, China |
引用本文:
吕鑫栋,李娇,邓真楠,冯浩,崔欣桐,邓红霞. 基于改进Transformer的结构化图像超分辨网络[J]. 浙江大学学报(工学版), 2023, 57(5): 865-874.
Xin-dong LV,Jiao LI,Zhen-nan DENG,Hao FENG,Xin-tong CUI,Hong-xia DENG. Structured image super-resolution network based on improved Transformer. Journal of ZheJiang University (Engineering Science), 2023, 57(5): 865-874.
链接本文:
https://www.zjujournals.com/eng/CN/10.3785/j.issn.1008-973X.2023.05.002
或
https://www.zjujournals.com/eng/CN/Y2023/V57/I5/865
|
| 1 |
DONG C, LOY C C, HE K, et al. Learning a deep convolutional network for image super-resolution [C]// Proceedings of the European Conference on Computer Vision. Columbus: CVPR, 2014: 184-199.
|
| 2 |
LEDIG C, THEIS L, HUSZAR F, et al. Photo-realistic single image super-resolution using a generative adversarial network [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Honolulu: CVPR, 2017: 105-114.
|
| 3 |
MA C, RAO Y, CHENG Y, et al. Structure-preserving super-resolution with gradient guidance [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: CVPR, 2020: 7766-7775.
|
| 4 |
ZHANG Y, LI K, LI K, et al. Residual non-local attention networks for image restoration [EB/OL]. [2019-03-24]. https://arxiv.org/pdf/1903.10082.pdf.
|
| 5 |
徐永兵, 袁东, 余大兵, 等 多注意力机制引导的双目图像超分辨率重建算法[J]. 电子测量技术, 2021, 44 (15): 103- 108
XU Yong-bing, YUAN Dong, YU Da-bing, et al Binocular image super-resolution reconstruction algorithm guided by multi-attention mechanism[J]. Electronic Measurement Technology, 2021, 44 (15): 103- 108
doi: 10.19651/j.cnki.emt.2106993
|
| 6 |
ZHOU E, FAN H, CAO Z, et al. Learning face hallucination in the wild [C]// Proceeding of the Association or the Advancement of Artificial Intelligence. San Francisco: AAAI, 2015: 3871-3877.
|
| 7 |
LIU H, HAN Z, GUO J, et al. A noise robust face hallucination framework via cascaded model of deep convolutional networks and manifold learning [C]// Proceeding of the IEEE International Conference on Multimedia and Expo. Santiago: ICME, 2018: 1-6.
|
| 8 |
LIU S, XIONG C Y, SHI X D, et al Progressive face super-resolution with cascaded recurrent convolutional network[J]. Neurocomputing, 2021, 449 (8): 357- 367
|
| 9 |
CHEN Y, TAI Y, LIU X, et al. FSRNet: end-to-end learning face super-resolution with facial priors [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: CVPR, 2018: 2492-2501.
|
| 10 |
ZHANG Y, WU Y, CHEN L. MSFSR: a multi-stage face super-resolution with accurate facial representation via enhanced facial boundaries [C]// Proceeding of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Seattle: CVPR, 2020: 2120-2129.
|
| 11 |
YIN Y, ROBINSON J P, ZHANG Y, et al. Joint super-resolution and alignment of tiny faces [C]// Proceeding of the Association for the Advancement of Artificial Intelligence. Honolulu: AAAI, 2019: 12693–12700.
|
| 12 |
KIM J, LI G, YUN I, et al Edge and identity preserving network for face super-resolution[J]. Neurocomputing, 2021, 446 (7): 11- 22
|
| 13 |
刘朋伟, 高媛, 秦品乐, 等 基于多感受野的生成对抗网络医学MRI影像超分辨率重建[J]. 计算机应用, 2022, 42 (3): 938- 945
LIU Peng-wei, GAO Yuan, QIN Pin-le, et al Medical MRI image super-resolution reconstruction based on multi-receptive field generative adversarial network[J]. Journal of Computer Applications, 2022, 42 (3): 938- 945
|
| 14 |
NEWELL A, YANG K, DENG J. Stacked hourglass networks for human pose estimations [C]// Proceedings of the European Conference on Computer Vision. Amsterdam: ECCV, 2016: 483-499.
|
| 15 |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [EB/OL]. [2017-06-12]. https://arxiv.org/pdf/1706.03762.pdf.
|
| 16 |
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: transformers for image recognition at scale [EB/OL]. [2020-10-22]. https://arxiv.org/pdf/2010.11929.pdf.
|
| 17 |
LIU Z, LIN Y, CAO Y, et al. Swin transformer: hierarchical vision transformer using shifted windows [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal: ICCV, 2021: 9992-10002.
|
| 18 |
HU J, SHEN L, SUN G. Squeeze-and-excitation networks [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: CVPR, 2018: 7132-7141.
|
| 19 |
WANG Q, WU B, ZHU P, et al. ECA-Net: efficient channel attention for deep convolutional neural networks [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: CVPR, 2020: 11531-11539.
|
| 20 |
SHAW P, USZKOREIT J, VASWANI A. Self-attention with relative position representations [EB/OL]. [2018-03-06]. https://arxiv.org/pdf/1803.02155.pdf.
|
| 21 |
RAFFEL C, SHAZEER N, ROBERTS A, et al. Exploring the limits of transfer learning with a unified text-to-text transformer [EB/OL]. [2019-10-23]. https://arxiv.org/ pdf/1910.10683.pdf.
|
| 22 |
GATYS L A, ECKER A S, BETHGE M. Image style transfer using convolutional neural networks [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Las Vegas: CVPR, 2016: 2414-2423.
|
| 23 |
LIU Z, LUO P, WANG X, et al. Deep learning face attributes in the wild [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Santiago: ICCV, 2015: 3730-3738.
|
| 24 |
LE V, BRANDT J, LIN Z, et al. Interactive facial feature localization [C]// Proceedings of the European Conference on Computer Vision. Florence: ECCV, 2012: 679-692.
|
| 25 |
ZHANG K, ZHANG Z, LI Z, et al Joint face detection and alignment using multitask cascaded convolutional networks[J]. IEEE Signal Processing Letters, 2016, 23 (10): 1499- 1503
doi: 10.1109/LSP.2016.2603342
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|