[1]
DONG C, LOY C C, HE K, et al. Learning a deep convolutional network for image super-resolution [C]// Proceedings of the European Conference on Computer Vision . Columbus: CVPR, 2014: 184-199.
[本文引用: 1]
[2]
LEDIG C, THEIS L, HUSZAR F, et al. Photo-realistic single image super-resolution using a generative adversarial network [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Honolulu: CVPR, 2017: 105-114.
[本文引用: 2]
[3]
MA C, RAO Y, CHENG Y, et al. Structure-preserving super-resolution with gradient guidance [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: CVPR, 2020: 7766-7775.
[本文引用: 2]
[4]
ZHANG Y, LI K, LI K, et al. Residual non-local attention networks for image restoration [EB/OL]. [2019-03-24]. https://arxiv.org/pdf/1903.10082.pdf.
[本文引用: 2]
[5]
徐永兵, 袁东, 余大兵, 等 多注意力机制引导的双目图像超分辨率重建算法
[J]. 电子测量技术 , 2021 , 44 (15 ): 103 - 108
DOI:10.19651/j.cnki.emt.2106993
[本文引用: 1]
XU Yong-bing, YUAN Dong, YU Da-bing, et al Binocular image super-resolution reconstruction algorithm guided by multi-attention mechanism
[J]. Electronic Measurement Technology , 2021 , 44 (15 ): 103 - 108
DOI:10.19651/j.cnki.emt.2106993
[本文引用: 1]
[6]
ZHOU E, FAN H, CAO Z, et al. Learning face hallucination in the wild [C]// Proceeding of the Association or the Advancement of Artificial Intelligence . San Francisco: AAAI, 2015: 3871-3877.
[本文引用: 1]
[7]
LIU H, HAN Z, GUO J, et al. A noise robust face hallucination framework via cascaded model of deep convolutional networks and manifold learning [C]// Proceeding of the IEEE International Conference on Multimedia and Expo . Santiago: ICME, 2018: 1-6.
[本文引用: 1]
[8]
LIU S, XIONG C Y, SHI X D, et al Progressive face super-resolution with cascaded recurrent convolutional network
[J]. Neurocomputing , 2021 , 449 (8 ): 357 - 367
[本文引用: 1]
[9]
CHEN Y, TAI Y, LIU X, et al. FSRNet: end-to-end learning face super-resolution with facial priors [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: CVPR, 2018: 2492-2501.
[本文引用: 4]
[10]
ZHANG Y, WU Y, CHEN L. MSFSR: a multi-stage face super-resolution with accurate facial representation via enhanced facial boundaries [C]// Proceeding of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops . Seattle: CVPR, 2020: 2120-2129.
[本文引用: 1]
[11]
YIN Y, ROBINSON J P, ZHANG Y, et al. Joint super-resolution and alignment of tiny faces [C]// Proceeding of the Association for the Advancement of Artificial Intelligence . Honolulu: AAAI, 2019: 12693–12700.
[本文引用: 1]
[12]
KIM J, LI G, YUN I, et al Edge and identity preserving network for face super-resolution
[J]. Neurocomputing , 2021 , 446 (7 ): 11 - 22
[本文引用: 2]
[13]
刘朋伟, 高媛, 秦品乐, 等 基于多感受野的生成对抗网络医学MRI影像超分辨率重建
[J]. 计算机应用 , 2022 , 42 (3 ): 938 - 945
[本文引用: 1]
LIU Peng-wei, GAO Yuan, QIN Pin-le, et al Medical MRI image super-resolution reconstruction based on multi-receptive field generative adversarial network
[J]. Journal of Computer Applications , 2022 , 42 (3 ): 938 - 945
[本文引用: 1]
[14]
NEWELL A, YANG K, DENG J. Stacked hourglass networks for human pose estimations [C]// Proceedings of the European Conference on Computer Vision . Amsterdam: ECCV, 2016: 483-499.
[本文引用: 1]
[15]
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [EB/OL]. [2017-06-12]. https://arxiv.org/pdf/1706.03762.pdf.
[本文引用: 2]
[16]
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: transformers for image recognition at scale [EB/OL]. [2020-10-22]. https://arxiv.org/pdf/2010.11929.pdf.
[本文引用: 2]
[17]
LIU Z, LIN Y, CAO Y, et al. Swin transformer: hierarchical vision transformer using shifted windows [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: ICCV, 2021: 9992-10002.
[本文引用: 1]
[18]
HU J, SHEN L, SUN G. Squeeze-and-excitation networks [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: CVPR, 2018: 7132-7141.
[本文引用: 1]
[19]
WANG Q, WU B, ZHU P, et al. ECA-Net: efficient channel attention for deep convolutional neural networks [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: CVPR, 2020: 11531-11539.
[本文引用: 1]
[20]
SHAW P, USZKOREIT J, VASWANI A. Self-attention with relative position representations [EB/OL]. [2018-03-06]. https://arxiv.org/pdf/1803.02155.pdf.
[本文引用: 1]
[21]
RAFFEL C, SHAZEER N, ROBERTS A, et al. Exploring the limits of transfer learning with a unified text-to-text transformer [EB/OL]. [2019-10-23]. https://arxiv.org/ pdf/1910.10683.pdf.
[本文引用: 1]
[22]
GATYS L A, ECKER A S, BETHGE M. Image style transfer using convolutional neural networks [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Las Vegas: CVPR, 2016: 2414-2423.
[本文引用: 1]
[23]
LIU Z, LUO P, WANG X, et al. Deep learning face attributes in the wild [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Santiago: ICCV, 2015: 3730-3738.
[本文引用: 1]
[24]
LE V, BRANDT J, LIN Z, et al. Interactive facial feature localization [C]// Proceedings of the European Conference on Computer Vision . Florence: ECCV, 2012: 679-692.
[本文引用: 1]
[25]
ZHANG K, ZHANG Z, LI Z, et al Joint face detection and alignment using multitask cascaded convolutional networks
[J]. IEEE Signal Processing Letters , 2016 , 23 (10 ): 1499 - 1503
DOI:10.1109/LSP.2016.2603342
[本文引用: 1]
[26]
MEI Y, FAN Y, ZHOU Y. Image super-resolution with non-local sparse attention [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Online: CVPR, 2021: 3516-3525.
[本文引用: 1]
1
... 图像超分辨率重建(super resolution,SR)是指从低分辨率图像(low resolution,LR)中恢复高分辨率(high resolution,HR)图像的一类重要的图像处理技术,可以应用于医学成像、人脸图像恢复和视频监视等领域. 人脸图像和医学图像具有结构不变性,即固定的几何结构和丰富的先验信息. 人脸超分辨重建可以辅助提高人脸识别精准度,高质量的医学图像对病情诊断分析以及治疗都具有重要的意义. 近年来,随着深度学习技术快速发展,各种深度学习方法被用于解决SR任务,从早期的基于卷积神经网络(convolutional neural networks,CNN)[1 ] 的方法到基于生成对抗网络的SR方法(super resolution generative adversarial network,SRGAN)[2 ] ,已有不少学者提出可以利用图像的结构化特征进行图像重建. Ma等[3 ] 利用梯度分支恢复HR的梯度图,通过HR的梯度图帮助生成器网络关注图像的几何结构特征. Zhang等[4 ] 提出一种残差非局部注意力网络,利用卷积神经网络搭建局部和非局部注意力块来提取特征. 局部注意力块关注特征图的局部结构,而非局部注意力块更多考虑整个特征图中的长距离依赖关系. 徐永兵等[5 ] 提出一种视差注意力机制来充分学习双目图像的结构信息,有效提高图像质量. 上述方法利用图像的结构特征进行重建,但是这些方法都未应用在结构化图像数据集上. ...
2
... 图像超分辨率重建(super resolution,SR)是指从低分辨率图像(low resolution,LR)中恢复高分辨率(high resolution,HR)图像的一类重要的图像处理技术,可以应用于医学成像、人脸图像恢复和视频监视等领域. 人脸图像和医学图像具有结构不变性,即固定的几何结构和丰富的先验信息. 人脸超分辨重建可以辅助提高人脸识别精准度,高质量的医学图像对病情诊断分析以及治疗都具有重要的意义. 近年来,随着深度学习技术快速发展,各种深度学习方法被用于解决SR任务,从早期的基于卷积神经网络(convolutional neural networks,CNN)[1 ] 的方法到基于生成对抗网络的SR方法(super resolution generative adversarial network,SRGAN)[2 ] ,已有不少学者提出可以利用图像的结构化特征进行图像重建. Ma等[3 ] 利用梯度分支恢复HR的梯度图,通过HR的梯度图帮助生成器网络关注图像的几何结构特征. Zhang等[4 ] 提出一种残差非局部注意力网络,利用卷积神经网络搭建局部和非局部注意力块来提取特征. 局部注意力块关注特征图的局部结构,而非局部注意力块更多考虑整个特征图中的长距离依赖关系. 徐永兵等[5 ] 提出一种视差注意力机制来充分学习双目图像的结构信息,有效提高图像质量. 上述方法利用图像的结构特征进行重建,但是这些方法都未应用在结构化图像数据集上. ...
... 为了探讨TransSRNet对不同结构化图像数据集的重建性能,将所提方法与当前优秀的重建算法进行比较,包括基于生成对抗网络的SRGAN[2 ] ,利用梯度图关注图像结构特征的SPSR[3 ] ,基于先验信息约束的人脸超分辨率重建网络FSRNet[9 ] 和EIPNet[12 ] ,这些方法与本研究的实验条件相似,在TCGA-ESCA 食道癌、TCGA-COAD结肠腺癌CT图像数据集上进行对比试验. 通过实验可以验证TransSRNet能够对不同类型的结构化图像保持良好的重建效果. ...
2
... 图像超分辨率重建(super resolution,SR)是指从低分辨率图像(low resolution,LR)中恢复高分辨率(high resolution,HR)图像的一类重要的图像处理技术,可以应用于医学成像、人脸图像恢复和视频监视等领域. 人脸图像和医学图像具有结构不变性,即固定的几何结构和丰富的先验信息. 人脸超分辨重建可以辅助提高人脸识别精准度,高质量的医学图像对病情诊断分析以及治疗都具有重要的意义. 近年来,随着深度学习技术快速发展,各种深度学习方法被用于解决SR任务,从早期的基于卷积神经网络(convolutional neural networks,CNN)[1 ] 的方法到基于生成对抗网络的SR方法(super resolution generative adversarial network,SRGAN)[2 ] ,已有不少学者提出可以利用图像的结构化特征进行图像重建. Ma等[3 ] 利用梯度分支恢复HR的梯度图,通过HR的梯度图帮助生成器网络关注图像的几何结构特征. Zhang等[4 ] 提出一种残差非局部注意力网络,利用卷积神经网络搭建局部和非局部注意力块来提取特征. 局部注意力块关注特征图的局部结构,而非局部注意力块更多考虑整个特征图中的长距离依赖关系. 徐永兵等[5 ] 提出一种视差注意力机制来充分学习双目图像的结构信息,有效提高图像质量. 上述方法利用图像的结构特征进行重建,但是这些方法都未应用在结构化图像数据集上. ...
... 为了探讨TransSRNet对不同结构化图像数据集的重建性能,将所提方法与当前优秀的重建算法进行比较,包括基于生成对抗网络的SRGAN[2 ] ,利用梯度图关注图像结构特征的SPSR[3 ] ,基于先验信息约束的人脸超分辨率重建网络FSRNet[9 ] 和EIPNet[12 ] ,这些方法与本研究的实验条件相似,在TCGA-ESCA 食道癌、TCGA-COAD结肠腺癌CT图像数据集上进行对比试验. 通过实验可以验证TransSRNet能够对不同类型的结构化图像保持良好的重建效果. ...
2
... 图像超分辨率重建(super resolution,SR)是指从低分辨率图像(low resolution,LR)中恢复高分辨率(high resolution,HR)图像的一类重要的图像处理技术,可以应用于医学成像、人脸图像恢复和视频监视等领域. 人脸图像和医学图像具有结构不变性,即固定的几何结构和丰富的先验信息. 人脸超分辨重建可以辅助提高人脸识别精准度,高质量的医学图像对病情诊断分析以及治疗都具有重要的意义. 近年来,随着深度学习技术快速发展,各种深度学习方法被用于解决SR任务,从早期的基于卷积神经网络(convolutional neural networks,CNN)[1 ] 的方法到基于生成对抗网络的SR方法(super resolution generative adversarial network,SRGAN)[2 ] ,已有不少学者提出可以利用图像的结构化特征进行图像重建. Ma等[3 ] 利用梯度分支恢复HR的梯度图,通过HR的梯度图帮助生成器网络关注图像的几何结构特征. Zhang等[4 ] 提出一种残差非局部注意力网络,利用卷积神经网络搭建局部和非局部注意力块来提取特征. 局部注意力块关注特征图的局部结构,而非局部注意力块更多考虑整个特征图中的长距离依赖关系. 徐永兵等[5 ] 提出一种视差注意力机制来充分学习双目图像的结构信息,有效提高图像质量. 上述方法利用图像的结构特征进行重建,但是这些方法都未应用在结构化图像数据集上. ...
... FSRNet和EIPNet是用于人脸图像这一特定领域的超分辨重建算法,并不适用于医学图像超分辨重建. 另取RNAN算法[4 ] 和基于非局部稀疏注意力的图像超分辨率网络(NLSN)[26 ] 进行对比实验. 表5 展示不同方法在医学CT数据集上的超分辨率重建实验对比结果,表中最优指标为加粗字体. 从表5 中可以看出,TransSRNet在放大因子为3、4、8时的评价指标优于其他算法,在放大因子为2时的评价指标略低于NLSN算法,由此可以证明TransSRNet能够对不同类型的结构化图像数据集保持相同的重建效果,原因在于TransSRNet的沙漏块只需要考虑图像的结构信息,不需要考虑特定类型结构化图像的先验知识,而且该网络利用Transformer的自注意力机制,提高了对结构化图像重建效果的自然度和逼真度. ...
多注意力机制引导的双目图像超分辨率重建算法
1
2021
... 图像超分辨率重建(super resolution,SR)是指从低分辨率图像(low resolution,LR)中恢复高分辨率(high resolution,HR)图像的一类重要的图像处理技术,可以应用于医学成像、人脸图像恢复和视频监视等领域. 人脸图像和医学图像具有结构不变性,即固定的几何结构和丰富的先验信息. 人脸超分辨重建可以辅助提高人脸识别精准度,高质量的医学图像对病情诊断分析以及治疗都具有重要的意义. 近年来,随着深度学习技术快速发展,各种深度学习方法被用于解决SR任务,从早期的基于卷积神经网络(convolutional neural networks,CNN)[1 ] 的方法到基于生成对抗网络的SR方法(super resolution generative adversarial network,SRGAN)[2 ] ,已有不少学者提出可以利用图像的结构化特征进行图像重建. Ma等[3 ] 利用梯度分支恢复HR的梯度图,通过HR的梯度图帮助生成器网络关注图像的几何结构特征. Zhang等[4 ] 提出一种残差非局部注意力网络,利用卷积神经网络搭建局部和非局部注意力块来提取特征. 局部注意力块关注特征图的局部结构,而非局部注意力块更多考虑整个特征图中的长距离依赖关系. 徐永兵等[5 ] 提出一种视差注意力机制来充分学习双目图像的结构信息,有效提高图像质量. 上述方法利用图像的结构特征进行重建,但是这些方法都未应用在结构化图像数据集上. ...
多注意力机制引导的双目图像超分辨率重建算法
1
2021
... 图像超分辨率重建(super resolution,SR)是指从低分辨率图像(low resolution,LR)中恢复高分辨率(high resolution,HR)图像的一类重要的图像处理技术,可以应用于医学成像、人脸图像恢复和视频监视等领域. 人脸图像和医学图像具有结构不变性,即固定的几何结构和丰富的先验信息. 人脸超分辨重建可以辅助提高人脸识别精准度,高质量的医学图像对病情诊断分析以及治疗都具有重要的意义. 近年来,随着深度学习技术快速发展,各种深度学习方法被用于解决SR任务,从早期的基于卷积神经网络(convolutional neural networks,CNN)[1 ] 的方法到基于生成对抗网络的SR方法(super resolution generative adversarial network,SRGAN)[2 ] ,已有不少学者提出可以利用图像的结构化特征进行图像重建. Ma等[3 ] 利用梯度分支恢复HR的梯度图,通过HR的梯度图帮助生成器网络关注图像的几何结构特征. Zhang等[4 ] 提出一种残差非局部注意力网络,利用卷积神经网络搭建局部和非局部注意力块来提取特征. 局部注意力块关注特征图的局部结构,而非局部注意力块更多考虑整个特征图中的长距离依赖关系. 徐永兵等[5 ] 提出一种视差注意力机制来充分学习双目图像的结构信息,有效提高图像质量. 上述方法利用图像的结构特征进行重建,但是这些方法都未应用在结构化图像数据集上. ...
1
... 基于深度学习的结构化图像SR算法可以归纳为以下2个方面. 1)从不使用结构化图像先验信息进行重建的角度出发,Zhou等[6 ] 提出采用CNN来学习LR人脸图像到HR人脸图像的映射;Liu等[7 ] 提出的是一种先对低频信息进行去噪恢复,再利用子网络对高频信息进行补偿的级联模型;Liu等[8 ] 提出利用渐进式上采样来逐步获取高倍率的人脸图像. 这些SR方法都是采用CNN搭建网络,受CNN局部感受野的限制,重建网络对全局信息的建模能力不足,结构化图像重建效果的自然度和逼真度还有待提高. 2)由于结构化图像的特殊性,很多学者考虑利用结构化图像的先验知识辅助图像重建过程. Chen等[9 ] 提出通过人脸图像的特殊性,构建先验知识,从人脸图像中提取几何先验信息(面部解析图),辅助SR网络重建,提高超分辨率的效果. 与文献[9 ]使用先验信息类似,Zhang等[10 ] 提出MSFSR创建一种新的面部先验网络,利用对LR图像进行渐进处理. 对于8倍放大因子,使用3个2倍上采样因子的子网络构建级联网络. Yin等[11 ] 提出利用人脸关键点先验估计与人脸图像SR之间的相关性进行重建. Kim等[12 ] 利用一个轻量级的边缘块和身份信息来最小化失真程度,使用边缘块来提取感知的边缘信息,将边缘块连接到原始的多尺度特征映射,额外定义一个身份损失函数来保留SR图像的身份. 刘朋伟等[13 ] 利用多感受野特征提取块中的空间注意力模块,充分获取图像空间特征信息,减少浅层和局部特征在网络中的丢失,从而辅助生成高质量医学MRI图像. 基于先验信息引导的结构化图像SR方法,大多只适用于特定的结构化图像上,例如人脸先验信息引导的SR方法,利用面部解析图或人脸关键点作为先验知识进行重建,但是无法适用在医学图像上. ...
1
... 基于深度学习的结构化图像SR算法可以归纳为以下2个方面. 1)从不使用结构化图像先验信息进行重建的角度出发,Zhou等[6 ] 提出采用CNN来学习LR人脸图像到HR人脸图像的映射;Liu等[7 ] 提出的是一种先对低频信息进行去噪恢复,再利用子网络对高频信息进行补偿的级联模型;Liu等[8 ] 提出利用渐进式上采样来逐步获取高倍率的人脸图像. 这些SR方法都是采用CNN搭建网络,受CNN局部感受野的限制,重建网络对全局信息的建模能力不足,结构化图像重建效果的自然度和逼真度还有待提高. 2)由于结构化图像的特殊性,很多学者考虑利用结构化图像的先验知识辅助图像重建过程. Chen等[9 ] 提出通过人脸图像的特殊性,构建先验知识,从人脸图像中提取几何先验信息(面部解析图),辅助SR网络重建,提高超分辨率的效果. 与文献[9 ]使用先验信息类似,Zhang等[10 ] 提出MSFSR创建一种新的面部先验网络,利用对LR图像进行渐进处理. 对于8倍放大因子,使用3个2倍上采样因子的子网络构建级联网络. Yin等[11 ] 提出利用人脸关键点先验估计与人脸图像SR之间的相关性进行重建. Kim等[12 ] 利用一个轻量级的边缘块和身份信息来最小化失真程度,使用边缘块来提取感知的边缘信息,将边缘块连接到原始的多尺度特征映射,额外定义一个身份损失函数来保留SR图像的身份. 刘朋伟等[13 ] 利用多感受野特征提取块中的空间注意力模块,充分获取图像空间特征信息,减少浅层和局部特征在网络中的丢失,从而辅助生成高质量医学MRI图像. 基于先验信息引导的结构化图像SR方法,大多只适用于特定的结构化图像上,例如人脸先验信息引导的SR方法,利用面部解析图或人脸关键点作为先验知识进行重建,但是无法适用在医学图像上. ...
Progressive face super-resolution with cascaded recurrent convolutional network
1
2021
... 基于深度学习的结构化图像SR算法可以归纳为以下2个方面. 1)从不使用结构化图像先验信息进行重建的角度出发,Zhou等[6 ] 提出采用CNN来学习LR人脸图像到HR人脸图像的映射;Liu等[7 ] 提出的是一种先对低频信息进行去噪恢复,再利用子网络对高频信息进行补偿的级联模型;Liu等[8 ] 提出利用渐进式上采样来逐步获取高倍率的人脸图像. 这些SR方法都是采用CNN搭建网络,受CNN局部感受野的限制,重建网络对全局信息的建模能力不足,结构化图像重建效果的自然度和逼真度还有待提高. 2)由于结构化图像的特殊性,很多学者考虑利用结构化图像的先验知识辅助图像重建过程. Chen等[9 ] 提出通过人脸图像的特殊性,构建先验知识,从人脸图像中提取几何先验信息(面部解析图),辅助SR网络重建,提高超分辨率的效果. 与文献[9 ]使用先验信息类似,Zhang等[10 ] 提出MSFSR创建一种新的面部先验网络,利用对LR图像进行渐进处理. 对于8倍放大因子,使用3个2倍上采样因子的子网络构建级联网络. Yin等[11 ] 提出利用人脸关键点先验估计与人脸图像SR之间的相关性进行重建. Kim等[12 ] 利用一个轻量级的边缘块和身份信息来最小化失真程度,使用边缘块来提取感知的边缘信息,将边缘块连接到原始的多尺度特征映射,额外定义一个身份损失函数来保留SR图像的身份. 刘朋伟等[13 ] 利用多感受野特征提取块中的空间注意力模块,充分获取图像空间特征信息,减少浅层和局部特征在网络中的丢失,从而辅助生成高质量医学MRI图像. 基于先验信息引导的结构化图像SR方法,大多只适用于特定的结构化图像上,例如人脸先验信息引导的SR方法,利用面部解析图或人脸关键点作为先验知识进行重建,但是无法适用在医学图像上. ...
4
... 基于深度学习的结构化图像SR算法可以归纳为以下2个方面. 1)从不使用结构化图像先验信息进行重建的角度出发,Zhou等[6 ] 提出采用CNN来学习LR人脸图像到HR人脸图像的映射;Liu等[7 ] 提出的是一种先对低频信息进行去噪恢复,再利用子网络对高频信息进行补偿的级联模型;Liu等[8 ] 提出利用渐进式上采样来逐步获取高倍率的人脸图像. 这些SR方法都是采用CNN搭建网络,受CNN局部感受野的限制,重建网络对全局信息的建模能力不足,结构化图像重建效果的自然度和逼真度还有待提高. 2)由于结构化图像的特殊性,很多学者考虑利用结构化图像的先验知识辅助图像重建过程. Chen等[9 ] 提出通过人脸图像的特殊性,构建先验知识,从人脸图像中提取几何先验信息(面部解析图),辅助SR网络重建,提高超分辨率的效果. 与文献[9 ]使用先验信息类似,Zhang等[10 ] 提出MSFSR创建一种新的面部先验网络,利用对LR图像进行渐进处理. 对于8倍放大因子,使用3个2倍上采样因子的子网络构建级联网络. Yin等[11 ] 提出利用人脸关键点先验估计与人脸图像SR之间的相关性进行重建. Kim等[12 ] 利用一个轻量级的边缘块和身份信息来最小化失真程度,使用边缘块来提取感知的边缘信息,将边缘块连接到原始的多尺度特征映射,额外定义一个身份损失函数来保留SR图像的身份. 刘朋伟等[13 ] 利用多感受野特征提取块中的空间注意力模块,充分获取图像空间特征信息,减少浅层和局部特征在网络中的丢失,从而辅助生成高质量医学MRI图像. 基于先验信息引导的结构化图像SR方法,大多只适用于特定的结构化图像上,例如人脸先验信息引导的SR方法,利用面部解析图或人脸关键点作为先验知识进行重建,但是无法适用在医学图像上. ...
... 提出通过人脸图像的特殊性,构建先验知识,从人脸图像中提取几何先验信息(面部解析图),辅助SR网络重建,提高超分辨率的效果. 与文献[9 ]使用先验信息类似,Zhang等[10 ] 提出MSFSR创建一种新的面部先验网络,利用对LR图像进行渐进处理. 对于8倍放大因子,使用3个2倍上采样因子的子网络构建级联网络. Yin等[11 ] 提出利用人脸关键点先验估计与人脸图像SR之间的相关性进行重建. Kim等[12 ] 利用一个轻量级的边缘块和身份信息来最小化失真程度,使用边缘块来提取感知的边缘信息,将边缘块连接到原始的多尺度特征映射,额外定义一个身份损失函数来保留SR图像的身份. 刘朋伟等[13 ] 利用多感受野特征提取块中的空间注意力模块,充分获取图像空间特征信息,减少浅层和局部特征在网络中的丢失,从而辅助生成高质量医学MRI图像. 基于先验信息引导的结构化图像SR方法,大多只适用于特定的结构化图像上,例如人脸先验信息引导的SR方法,利用面部解析图或人脸关键点作为先验知识进行重建,但是无法适用在医学图像上. ...
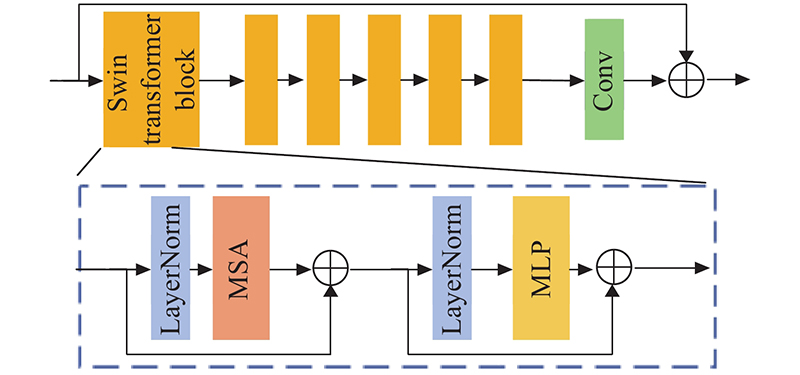
... Newell等[14 ] 提出利用沙漏块(hourglass block, HB)进行人体姿态估计. HB是对称结构,在下采样过程和上采样的过程中的网络层存在一一对应的关系. HB将多个卷积层紧密相连,有利于处理多尺度的结构化信息,能够有效地处理和整合跨尺度的特征,HB网络结构如图1 所示. 利用卷积层将特征分辨率逐步缩小;在对称层之间进行跳跃连接,在跳跃连接中对原来尺度的特征进行卷积;得到低分辨率特征后,网络开始进行上采样,并逐渐结合不同尺度的结构化特征信息,将2个不同的特征集进行逐元素相加后得到输出特征. 人脸图像超分辨重建网络FSRNet[9 ] 使用HB构建先验预测子网络,对人脸几何先验信息进行预测,从而辅助人脸图像的恢复. ...
... 为了探讨TransSRNet对不同结构化图像数据集的重建性能,将所提方法与当前优秀的重建算法进行比较,包括基于生成对抗网络的SRGAN[2 ] ,利用梯度图关注图像结构特征的SPSR[3 ] ,基于先验信息约束的人脸超分辨率重建网络FSRNet[9 ] 和EIPNet[12 ] ,这些方法与本研究的实验条件相似,在TCGA-ESCA 食道癌、TCGA-COAD结肠腺癌CT图像数据集上进行对比试验. 通过实验可以验证TransSRNet能够对不同类型的结构化图像保持良好的重建效果. ...
1
... 基于深度学习的结构化图像SR算法可以归纳为以下2个方面. 1)从不使用结构化图像先验信息进行重建的角度出发,Zhou等[6 ] 提出采用CNN来学习LR人脸图像到HR人脸图像的映射;Liu等[7 ] 提出的是一种先对低频信息进行去噪恢复,再利用子网络对高频信息进行补偿的级联模型;Liu等[8 ] 提出利用渐进式上采样来逐步获取高倍率的人脸图像. 这些SR方法都是采用CNN搭建网络,受CNN局部感受野的限制,重建网络对全局信息的建模能力不足,结构化图像重建效果的自然度和逼真度还有待提高. 2)由于结构化图像的特殊性,很多学者考虑利用结构化图像的先验知识辅助图像重建过程. Chen等[9 ] 提出通过人脸图像的特殊性,构建先验知识,从人脸图像中提取几何先验信息(面部解析图),辅助SR网络重建,提高超分辨率的效果. 与文献[9 ]使用先验信息类似,Zhang等[10 ] 提出MSFSR创建一种新的面部先验网络,利用对LR图像进行渐进处理. 对于8倍放大因子,使用3个2倍上采样因子的子网络构建级联网络. Yin等[11 ] 提出利用人脸关键点先验估计与人脸图像SR之间的相关性进行重建. Kim等[12 ] 利用一个轻量级的边缘块和身份信息来最小化失真程度,使用边缘块来提取感知的边缘信息,将边缘块连接到原始的多尺度特征映射,额外定义一个身份损失函数来保留SR图像的身份. 刘朋伟等[13 ] 利用多感受野特征提取块中的空间注意力模块,充分获取图像空间特征信息,减少浅层和局部特征在网络中的丢失,从而辅助生成高质量医学MRI图像. 基于先验信息引导的结构化图像SR方法,大多只适用于特定的结构化图像上,例如人脸先验信息引导的SR方法,利用面部解析图或人脸关键点作为先验知识进行重建,但是无法适用在医学图像上. ...
1
... 基于深度学习的结构化图像SR算法可以归纳为以下2个方面. 1)从不使用结构化图像先验信息进行重建的角度出发,Zhou等[6 ] 提出采用CNN来学习LR人脸图像到HR人脸图像的映射;Liu等[7 ] 提出的是一种先对低频信息进行去噪恢复,再利用子网络对高频信息进行补偿的级联模型;Liu等[8 ] 提出利用渐进式上采样来逐步获取高倍率的人脸图像. 这些SR方法都是采用CNN搭建网络,受CNN局部感受野的限制,重建网络对全局信息的建模能力不足,结构化图像重建效果的自然度和逼真度还有待提高. 2)由于结构化图像的特殊性,很多学者考虑利用结构化图像的先验知识辅助图像重建过程. Chen等[9 ] 提出通过人脸图像的特殊性,构建先验知识,从人脸图像中提取几何先验信息(面部解析图),辅助SR网络重建,提高超分辨率的效果. 与文献[9 ]使用先验信息类似,Zhang等[10 ] 提出MSFSR创建一种新的面部先验网络,利用对LR图像进行渐进处理. 对于8倍放大因子,使用3个2倍上采样因子的子网络构建级联网络. Yin等[11 ] 提出利用人脸关键点先验估计与人脸图像SR之间的相关性进行重建. Kim等[12 ] 利用一个轻量级的边缘块和身份信息来最小化失真程度,使用边缘块来提取感知的边缘信息,将边缘块连接到原始的多尺度特征映射,额外定义一个身份损失函数来保留SR图像的身份. 刘朋伟等[13 ] 利用多感受野特征提取块中的空间注意力模块,充分获取图像空间特征信息,减少浅层和局部特征在网络中的丢失,从而辅助生成高质量医学MRI图像. 基于先验信息引导的结构化图像SR方法,大多只适用于特定的结构化图像上,例如人脸先验信息引导的SR方法,利用面部解析图或人脸关键点作为先验知识进行重建,但是无法适用在医学图像上. ...
Edge and identity preserving network for face super-resolution
2
2021
... 基于深度学习的结构化图像SR算法可以归纳为以下2个方面. 1)从不使用结构化图像先验信息进行重建的角度出发,Zhou等[6 ] 提出采用CNN来学习LR人脸图像到HR人脸图像的映射;Liu等[7 ] 提出的是一种先对低频信息进行去噪恢复,再利用子网络对高频信息进行补偿的级联模型;Liu等[8 ] 提出利用渐进式上采样来逐步获取高倍率的人脸图像. 这些SR方法都是采用CNN搭建网络,受CNN局部感受野的限制,重建网络对全局信息的建模能力不足,结构化图像重建效果的自然度和逼真度还有待提高. 2)由于结构化图像的特殊性,很多学者考虑利用结构化图像的先验知识辅助图像重建过程. Chen等[9 ] 提出通过人脸图像的特殊性,构建先验知识,从人脸图像中提取几何先验信息(面部解析图),辅助SR网络重建,提高超分辨率的效果. 与文献[9 ]使用先验信息类似,Zhang等[10 ] 提出MSFSR创建一种新的面部先验网络,利用对LR图像进行渐进处理. 对于8倍放大因子,使用3个2倍上采样因子的子网络构建级联网络. Yin等[11 ] 提出利用人脸关键点先验估计与人脸图像SR之间的相关性进行重建. Kim等[12 ] 利用一个轻量级的边缘块和身份信息来最小化失真程度,使用边缘块来提取感知的边缘信息,将边缘块连接到原始的多尺度特征映射,额外定义一个身份损失函数来保留SR图像的身份. 刘朋伟等[13 ] 利用多感受野特征提取块中的空间注意力模块,充分获取图像空间特征信息,减少浅层和局部特征在网络中的丢失,从而辅助生成高质量医学MRI图像. 基于先验信息引导的结构化图像SR方法,大多只适用于特定的结构化图像上,例如人脸先验信息引导的SR方法,利用面部解析图或人脸关键点作为先验知识进行重建,但是无法适用在医学图像上. ...
... 为了探讨TransSRNet对不同结构化图像数据集的重建性能,将所提方法与当前优秀的重建算法进行比较,包括基于生成对抗网络的SRGAN[2 ] ,利用梯度图关注图像结构特征的SPSR[3 ] ,基于先验信息约束的人脸超分辨率重建网络FSRNet[9 ] 和EIPNet[12 ] ,这些方法与本研究的实验条件相似,在TCGA-ESCA 食道癌、TCGA-COAD结肠腺癌CT图像数据集上进行对比试验. 通过实验可以验证TransSRNet能够对不同类型的结构化图像保持良好的重建效果. ...
基于多感受野的生成对抗网络医学MRI影像超分辨率重建
1
2022
... 基于深度学习的结构化图像SR算法可以归纳为以下2个方面. 1)从不使用结构化图像先验信息进行重建的角度出发,Zhou等[6 ] 提出采用CNN来学习LR人脸图像到HR人脸图像的映射;Liu等[7 ] 提出的是一种先对低频信息进行去噪恢复,再利用子网络对高频信息进行补偿的级联模型;Liu等[8 ] 提出利用渐进式上采样来逐步获取高倍率的人脸图像. 这些SR方法都是采用CNN搭建网络,受CNN局部感受野的限制,重建网络对全局信息的建模能力不足,结构化图像重建效果的自然度和逼真度还有待提高. 2)由于结构化图像的特殊性,很多学者考虑利用结构化图像的先验知识辅助图像重建过程. Chen等[9 ] 提出通过人脸图像的特殊性,构建先验知识,从人脸图像中提取几何先验信息(面部解析图),辅助SR网络重建,提高超分辨率的效果. 与文献[9 ]使用先验信息类似,Zhang等[10 ] 提出MSFSR创建一种新的面部先验网络,利用对LR图像进行渐进处理. 对于8倍放大因子,使用3个2倍上采样因子的子网络构建级联网络. Yin等[11 ] 提出利用人脸关键点先验估计与人脸图像SR之间的相关性进行重建. Kim等[12 ] 利用一个轻量级的边缘块和身份信息来最小化失真程度,使用边缘块来提取感知的边缘信息,将边缘块连接到原始的多尺度特征映射,额外定义一个身份损失函数来保留SR图像的身份. 刘朋伟等[13 ] 利用多感受野特征提取块中的空间注意力模块,充分获取图像空间特征信息,减少浅层和局部特征在网络中的丢失,从而辅助生成高质量医学MRI图像. 基于先验信息引导的结构化图像SR方法,大多只适用于特定的结构化图像上,例如人脸先验信息引导的SR方法,利用面部解析图或人脸关键点作为先验知识进行重建,但是无法适用在医学图像上. ...
基于多感受野的生成对抗网络医学MRI影像超分辨率重建
1
2022
... 基于深度学习的结构化图像SR算法可以归纳为以下2个方面. 1)从不使用结构化图像先验信息进行重建的角度出发,Zhou等[6 ] 提出采用CNN来学习LR人脸图像到HR人脸图像的映射;Liu等[7 ] 提出的是一种先对低频信息进行去噪恢复,再利用子网络对高频信息进行补偿的级联模型;Liu等[8 ] 提出利用渐进式上采样来逐步获取高倍率的人脸图像. 这些SR方法都是采用CNN搭建网络,受CNN局部感受野的限制,重建网络对全局信息的建模能力不足,结构化图像重建效果的自然度和逼真度还有待提高. 2)由于结构化图像的特殊性,很多学者考虑利用结构化图像的先验知识辅助图像重建过程. Chen等[9 ] 提出通过人脸图像的特殊性,构建先验知识,从人脸图像中提取几何先验信息(面部解析图),辅助SR网络重建,提高超分辨率的效果. 与文献[9 ]使用先验信息类似,Zhang等[10 ] 提出MSFSR创建一种新的面部先验网络,利用对LR图像进行渐进处理. 对于8倍放大因子,使用3个2倍上采样因子的子网络构建级联网络. Yin等[11 ] 提出利用人脸关键点先验估计与人脸图像SR之间的相关性进行重建. Kim等[12 ] 利用一个轻量级的边缘块和身份信息来最小化失真程度,使用边缘块来提取感知的边缘信息,将边缘块连接到原始的多尺度特征映射,额外定义一个身份损失函数来保留SR图像的身份. 刘朋伟等[13 ] 利用多感受野特征提取块中的空间注意力模块,充分获取图像空间特征信息,减少浅层和局部特征在网络中的丢失,从而辅助生成高质量医学MRI图像. 基于先验信息引导的结构化图像SR方法,大多只适用于特定的结构化图像上,例如人脸先验信息引导的SR方法,利用面部解析图或人脸关键点作为先验知识进行重建,但是无法适用在医学图像上. ...
1
... Newell等[14 ] 提出利用沙漏块(hourglass block, HB)进行人体姿态估计. HB是对称结构,在下采样过程和上采样的过程中的网络层存在一一对应的关系. HB将多个卷积层紧密相连,有利于处理多尺度的结构化信息,能够有效地处理和整合跨尺度的特征,HB网络结构如图1 所示. 利用卷积层将特征分辨率逐步缩小;在对称层之间进行跳跃连接,在跳跃连接中对原来尺度的特征进行卷积;得到低分辨率特征后,网络开始进行上采样,并逐渐结合不同尺度的结构化特征信息,将2个不同的特征集进行逐元素相加后得到输出特征. 人脸图像超分辨重建网络FSRNet[9 ] 使用HB构建先验预测子网络,对人脸几何先验信息进行预测,从而辅助人脸图像的恢复. ...
2
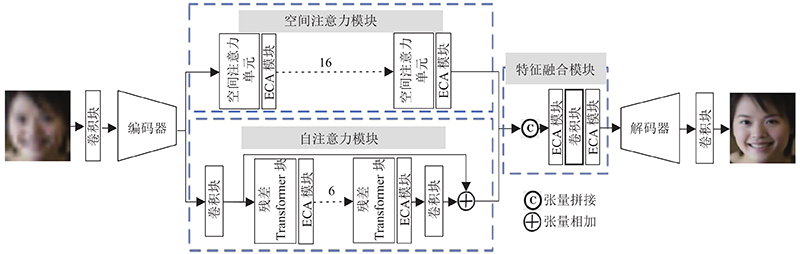
... Transformer[15 ] 的多头自注意力层和前反馈MLP层堆叠起来容易捕捉单词之间的远程相关性. 受到Transformer在自然语言处理(natural language processing,NLP)领域的激励,人们尝试着探索和利用Transformer在各种视觉任务中的优势,以强调提取全局特征的重要性. Dosovitskiy等[16 ] 提出的Vision Transformer,它将16×16图像块视为序列,并通过一个唯一的类令牌预测图像的类别. Swin Transformer[17 ] 表现出巨大的潜力,因为它整合了CNN和Transformer的优势. 一方面,由于局部注意机制,Swin Transformer具有CNN处理大尺寸图像的优势;另一方面,Swin Transformer具有Transformer的优点,可以用移位的窗口对长期依赖关系进行建模. ...
... 与绝对位置编码相比,经典的Transformer[15 -16 ] 使用确定性的位置编码或可学习的位置编码. 相对位置编码[20 ] 能够在局部内容之间学习更强的“关系”,在大规模数据集训练的情况下,带来重要的性能提升,并得到广泛的应用[21 ] . 本研究中的 Transformer添加相对位置编码,通过局部窗口内的自注意机制计算出注意力矩阵. 注意力矩阵为 ...
2
... Transformer[15 ] 的多头自注意力层和前反馈MLP层堆叠起来容易捕捉单词之间的远程相关性. 受到Transformer在自然语言处理(natural language processing,NLP)领域的激励,人们尝试着探索和利用Transformer在各种视觉任务中的优势,以强调提取全局特征的重要性. Dosovitskiy等[16 ] 提出的Vision Transformer,它将16×16图像块视为序列,并通过一个唯一的类令牌预测图像的类别. Swin Transformer[17 ] 表现出巨大的潜力,因为它整合了CNN和Transformer的优势. 一方面,由于局部注意机制,Swin Transformer具有CNN处理大尺寸图像的优势;另一方面,Swin Transformer具有Transformer的优点,可以用移位的窗口对长期依赖关系进行建模. ...
... 与绝对位置编码相比,经典的Transformer[15 -16 ] 使用确定性的位置编码或可学习的位置编码. 相对位置编码[20 ] 能够在局部内容之间学习更强的“关系”,在大规模数据集训练的情况下,带来重要的性能提升,并得到广泛的应用[21 ] . 本研究中的 Transformer添加相对位置编码,通过局部窗口内的自注意机制计算出注意力矩阵. 注意力矩阵为 ...
1
... Transformer[15 ] 的多头自注意力层和前反馈MLP层堆叠起来容易捕捉单词之间的远程相关性. 受到Transformer在自然语言处理(natural language processing,NLP)领域的激励,人们尝试着探索和利用Transformer在各种视觉任务中的优势,以强调提取全局特征的重要性. Dosovitskiy等[16 ] 提出的Vision Transformer,它将16×16图像块视为序列,并通过一个唯一的类令牌预测图像的类别. Swin Transformer[17 ] 表现出巨大的潜力,因为它整合了CNN和Transformer的优势. 一方面,由于局部注意机制,Swin Transformer具有CNN处理大尺寸图像的优势;另一方面,Swin Transformer具有Transformer的优点,可以用移位的窗口对长期依赖关系进行建模. ...
1
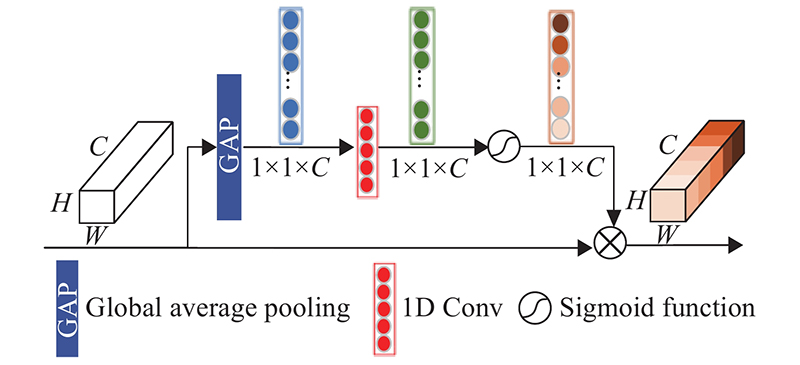
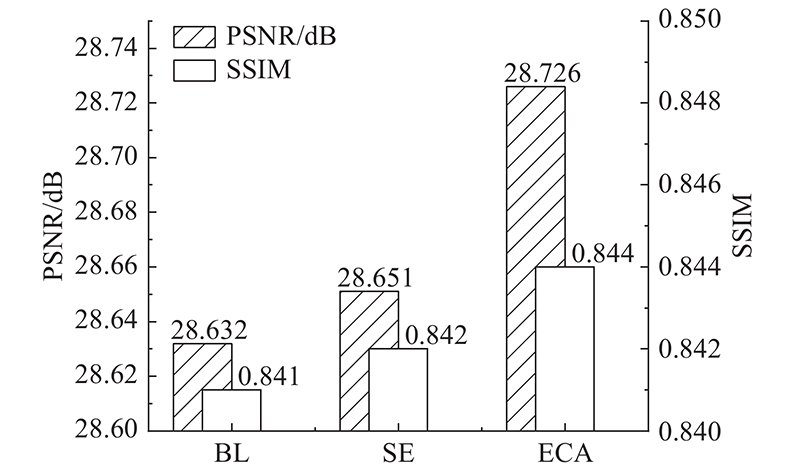
... 近年来,通道注意机制在提高深度卷积神经网络性能方面体现出巨大的潜力. Hu等[18 ] 提出SENet利用全连接层预测通道注意力权重,减少对冗余通道的关注. Wang等[19 ] 指出SENet中的降维会给通道注意力机制带来副作用,并且捕获所有通道之间的依赖关系,增加网络复杂度. 为了平衡性能与网络复杂度,Wang等还提出一种高效通道注意力(effificient channel attention,ECA)模块,该模块只涉及很少参数,却能带来明显的绩效提升. ECA模块利用一维卷积实现不降维的局部跨通道交互,同时开发了一种自适应选择一维卷积核大小的方法,以确定局部跨通道相互作用的覆盖范围. ...
1
... 近年来,通道注意机制在提高深度卷积神经网络性能方面体现出巨大的潜力. Hu等[18 ] 提出SENet利用全连接层预测通道注意力权重,减少对冗余通道的关注. Wang等[19 ] 指出SENet中的降维会给通道注意力机制带来副作用,并且捕获所有通道之间的依赖关系,增加网络复杂度. 为了平衡性能与网络复杂度,Wang等还提出一种高效通道注意力(effificient channel attention,ECA)模块,该模块只涉及很少参数,却能带来明显的绩效提升. ECA模块利用一维卷积实现不降维的局部跨通道交互,同时开发了一种自适应选择一维卷积核大小的方法,以确定局部跨通道相互作用的覆盖范围. ...
1
... 与绝对位置编码相比,经典的Transformer[15 -16 ] 使用确定性的位置编码或可学习的位置编码. 相对位置编码[20 ] 能够在局部内容之间学习更强的“关系”,在大规模数据集训练的情况下,带来重要的性能提升,并得到广泛的应用[21 ] . 本研究中的 Transformer添加相对位置编码,通过局部窗口内的自注意机制计算出注意力矩阵. 注意力矩阵为 ...
1
... 与绝对位置编码相比,经典的Transformer[15 -16 ] 使用确定性的位置编码或可学习的位置编码. 相对位置编码[20 ] 能够在局部内容之间学习更强的“关系”,在大规模数据集训练的情况下,带来重要的性能提升,并得到广泛的应用[21 ] . 本研究中的 Transformer添加相对位置编码,通过局部窗口内的自注意机制计算出注意力矩阵. 注意力矩阵为 ...
1
... 式中: $ \mathop {{\rm{SSIM}}(}\limits^{} ) $ [22 ] 提出风格损失,并用于图像样式传输. 在某种程度上,这种损失与感知损失相似,因为都是特征层面上的损失功能. 超分辨重建图像 $ {{\boldsymbol{I}}_{{\text{SR}}}} $ $ {{\boldsymbol{I}}_{{\text{HR}}}} $ $ {{\boldsymbol{F}}_{{\text{SR}}}} $ $ {{\boldsymbol{F}}_{{\text{HR}}}} $
1
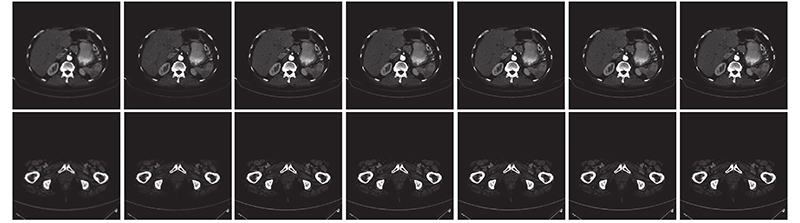
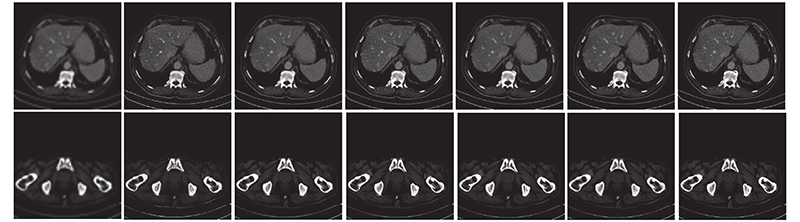
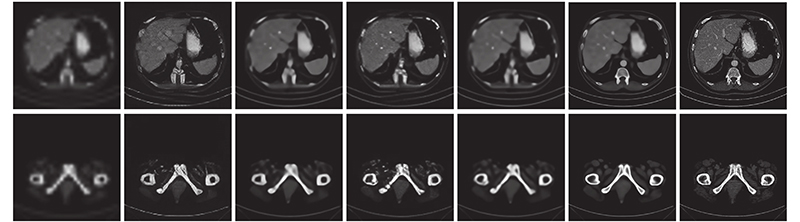
... 实验过程使用CelebA数据集[23 ] 进行训练,从Helen数据集[24 ] 中随机选取200张作为测试集进行测试. 另外使用癌症影像档案(the cancer imaging archive, TCIA)网站公开的TCGA-ESCA食道癌和TCGA-COAD结肠腺癌的CT数据集,共计26 522张图像进行放大因子分别为2、3、4、8的训练. 将1 000张图片进行测试,实验设置批处理大小为16,迭代次数设置为20,网络初始化方式设置为xavier,并确定学习速率为2×10−4 ,学习率衰减策略选择线性衰减. 实验在一台单独的 Tesla V100 GPU上进行训练和评估,所有代码都是用Pytorch和Python编写和测试的. ...
1
... 实验过程使用CelebA数据集[23 ] 进行训练,从Helen数据集[24 ] 中随机选取200张作为测试集进行测试. 另外使用癌症影像档案(the cancer imaging archive, TCIA)网站公开的TCGA-ESCA食道癌和TCGA-COAD结肠腺癌的CT数据集,共计26 522张图像进行放大因子分别为2、3、4、8的训练. 将1 000张图片进行测试,实验设置批处理大小为16,迭代次数设置为20,网络初始化方式设置为xavier,并确定学习速率为2×10−4 ,学习率衰减策略选择线性衰减. 实验在一台单独的 Tesla V100 GPU上进行训练和评估,所有代码都是用Pytorch和Python编写和测试的. ...
Joint face detection and alignment using multitask cascaded convolutional networks
1
2016
... 对人脸数据集进行预处理,使用多任务卷积网络(multi-task convolutional neural network,MTCNN)[25 ] 检测人脸并粗略地裁剪出人脸区域,通过双三次插值将大小调整为128×128,并用作HR训练集. 通过对HR图像进行下采样得到LR(16×16)训练集,产生大约202 K的图像对. 对CT图像数据集进行预处理则需要将27 522张DCM格式的CT图像转换为PNG格式,通过双三次插值调整图像大小为256×256,并将26 522张图像作为训练集. 为了避免过拟合,通过随机水平翻转、图像缩放(缩放比例在1.0~1.3)进行数据增强. ...
1
... FSRNet和EIPNet是用于人脸图像这一特定领域的超分辨重建算法,并不适用于医学图像超分辨重建. 另取RNAN算法[4 ] 和基于非局部稀疏注意力的图像超分辨率网络(NLSN)[26 ] 进行对比实验. 表5 展示不同方法在医学CT数据集上的超分辨率重建实验对比结果,表中最优指标为加粗字体. 从表5 中可以看出,TransSRNet在放大因子为3、4、8时的评价指标优于其他算法,在放大因子为2时的评价指标略低于NLSN算法,由此可以证明TransSRNet能够对不同类型的结构化图像数据集保持相同的重建效果,原因在于TransSRNet的沙漏块只需要考虑图像的结构信息,不需要考虑特定类型结构化图像的先验知识,而且该网络利用Transformer的自注意力机制,提高了对结构化图像重建效果的自然度和逼真度. ...








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}