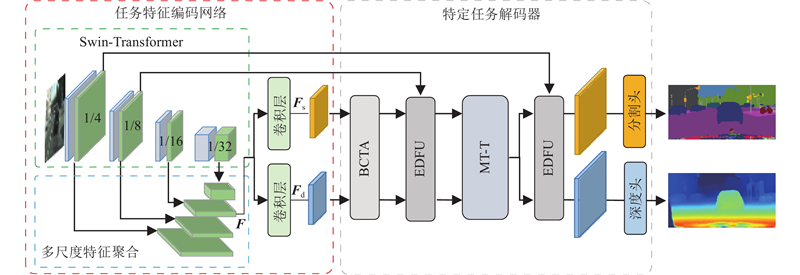
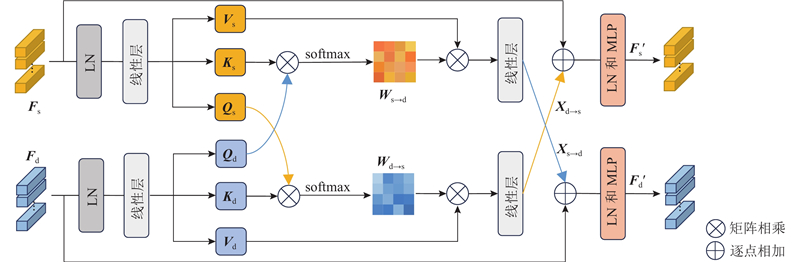
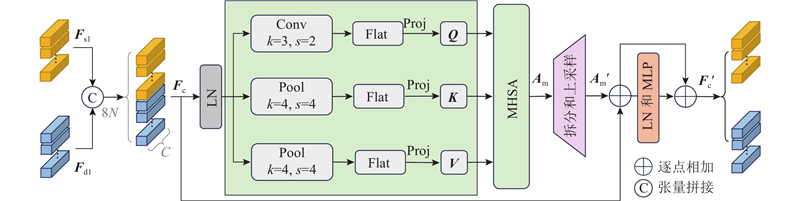
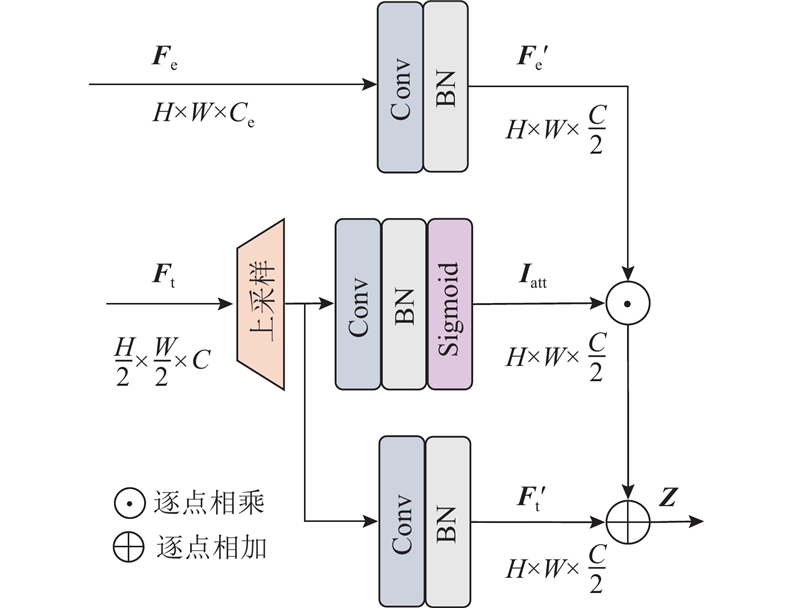
| 计算机与控制工程 |
|

|
|
|
| 联合语义分割和深度估计的交通场景感知算法 |
范康1( ),钟铭恩1,*(),谭佳威2,詹泽辉1,冯妍1 ),钟铭恩1,*(),谭佳威2,詹泽辉1,冯妍1 |
1. 厦门理工学院 福建省客车先进设计与制造重点实验室,福建 厦门 361024
2. 厦门大学 航空航天学院,福建 厦门 361102 |
|
| Traffic scene perception algorithm with joint semantic segmentation and depth estimation |
| Kang FAN1(),Ming’en ZHONG1,*(),Jiawei TAN2,Zehui ZHAN1,Yan FENG1 |
1. Fujian Key Laboratory of Bus Advanced Design and Manufacture, Xiamen University of Technology, Xiamen 361024, China
2. School of Aerospace Engineering, Xiamen University, Xiamen 361102, China |
引用本文:
范康,钟铭恩,谭佳威,詹泽辉,冯妍. 联合语义分割和深度估计的交通场景感知算法[J]. 浙江大学学报(工学版), 2024, 58(4): 684-695.
Kang FAN,Ming’en ZHONG,Jiawei TAN,Zehui ZHAN,Yan FENG. Traffic scene perception algorithm with joint semantic segmentation and depth estimation. Journal of ZheJiang University (Engineering Science), 2024, 58(4): 684-695.
链接本文:
https://www.zjujournals.com/eng/CN/10.3785/j.issn.1008-973X.2024.04.004
或
https://www.zjujournals.com/eng/CN/Y2024/V58/I4/684
|
| 1 |
李琳辉, 钱波, 连静, 等 基于卷积神经网络的交通场景语义分割方法研究[J]. 通信学报, 2018, 39 (4): 2018053
LI Linhui, QIAN Bo, LIAN Jing, et al Study on traffic scene semantic segmentation method based on convolutional neural network[J]. Journal on Communications, 2018, 39 (4): 2018053
|
| 2 |
PAN H, HONG Y, SUN W, et al Deep dual-resolution networks for real-time and accurate semantic segmentation of traffic scenes[J]. IEEE Transactions on Intelligent Transportation Systems, 2023, 24 (3): 3448- 3460
doi: 10.1109/TITS.2022.3228042
|
| 3 |
张海波, 蔡磊, 任俊平, 等 基于Transformer的高效自适应语义分割网络[J]. 浙江大学学报: 工学版, 2023, 57 (6): 1205- 1214
ZHANG Haibo, CAI Lei, REN Junping, et al Efficient and adaptive semantic segmentation network based on Transformer[J]. Journal of Zhejiang University: Engineering Science, 2023, 57 (6): 1205- 1214
|
| 4 |
EIGEN D, PUHRSCH C, FERGUS R. Depth map prediction from a single image using a multi-scale deep network [C]// Proceedings of the 27th International Conference on Neural Information Processing Systems . Cambridge: MIT Press, 2014: 2366–2374.
|
| 5 |
SONG M, LIM S, KIM W Monocular depth estimation using laplacian pyramid-based depth residuals[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2021, 31 (11): 4381- 4393
doi: 10.1109/TCSVT.2021.3049869
|
| 6 |
LI Z, CHEN Z, LIU X, et al DepthFormer: exploiting long-range correlation and local information for accurate monocular depth estimation[J]. Machine Intelligence Research, 2023, 20 (6): 837- 854
doi: 10.1007/s11633-023-1458-0
|
| 7 |
WANG P, SHEN X, LIN Z, et al. Towards unified depth and semantic prediction from a single image [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Boston: IEEE, 2015: 2800–2809.
|
| 8 |
SHOOURI S, YANG M, FAN Z, et al. Efficient computation sharing for multi-task visual scene understanding [EB/OL]. (2023-08-14)[2023-08-23]. https://arxiv.org/pdf/2303.09663.pdf.
|
| 9 |
VANDENHENDE S, GEORGOULIS S, VAN GANSBEKE W, et al Multi-task learning for dense prediction tasks: a survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44 (7): 3614- 3633
|
| 10 |
YE H, XU D. Inverted pyramid multi-task transformer for dense scene understanding [C]// European Conference on Computer Vision . [S.l.]: Springer, 2022: 514–530
|
| 11 |
XU D, OUYANG W, WANG X, et al. PAD-Net: multi-tasks guided prediction-and-distillation network for simultaneous depth estimation and scene parsing [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 675–684.
|
| 12 |
VANDENHENDE S, GEORGOULIS S, VAN GOOL L. MTI-Net: multi-scale task interaction networks for multi-task learning [C]// European Conference on Computer Vision . [S.l.]: Springer, 2020: 527–543.
|
| 13 |
ZHOU L, CUI Z, XU C, et al. Pattern-structure diffusion for multi-task learning [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 4514–4523.
|
| 14 |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Advances in Neural Information Processing Systems . Long Beach: MIT Press, 2017: 5998–6008.
|
| 15 |
ZHANG X, ZHOU L, LI Y, et al. Transfer vision patterns for multi-task pixel learning [C]// Proceedings of the 29th ACM International Conference on Multimedia . [S.l.]: ACM, 2021: 97–106.
|
| 16 |
LIU Z, LIN Y, CAO Y, et al. Swin Transformer: hierarchical vision transformer using shifted windows [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 10012–10022.
|
| 17 |
ZHANG X, CHEN Y, ZHANG H, et al When visual disparity generation meets semantic segmentation: a mutual encouragement approach[J]. IEEE Transactions on Intelligent Transportation Systems, 2021, 22 (3): 1853- 1867
doi: 10.1109/TITS.2020.3027556
|
| 18 |
LAINA I, RUPPRECHT C, BELAGIANNIS V, et al. Deeper depth prediction with fully convolutional residual networks [C]// 2016 Fourth International Conference on 3D Vision . Stanford: IEEE, 2016: 239–248.
|
| 19 |
CORDTS M, OMRAN M, RAMOS S, et al. The Cityscapes dataset for semantic urban scene understanding [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 3213–3223.
|
| 20 |
XIE E, WANG W, YU Z, et al. SegFormer: simple and efficient design for semantic segmentation with transformers [C]// Advances in Neural Information Processing Systems . [S.1.]: MIT Press, 2021: 12077–12090.
|
| 21 |
WANG W, XIE E, LI X, et al. Pyramid vision transformer: a versatile backbone for dense prediction without convolutions [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 568–578.
|
| 22 |
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 770–778.
|
| 23 |
ZHAO H, SHI J, QI X, et al. Pyramid scene parsing network [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 2881–2890.
|
| 24 |
ZHENG S, LU J, ZHAO H, et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 6881–6890.
|
| 25 |
CHENG B, MISRA I, SCHWING A G, et al. Masked-attention mask transformer for universal image segmentation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 1290–1299.
|
| 26 |
AGARWAL A, ARORA C. Attention attention everywhere: monocular depth prediction with skip attention [C]// Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision . Waikoloa: IEEE, 2023: 5861–5870.
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|