

语义分割和深度估计是交通场景感知极为重要的2个视觉任务. 前者对图像进行像素级语义分类,精确定位道路、障碍物和行人等关键区域,实现场景语义解析;后者推理图像中每个像素相对于拍摄源的距离,描述场景中物体的空间几何位置关系. 两者分别从2个不同的层次对交通场景进行理解,2种任务感知信息的结合可以为车辆自动驾驶的路径规划和行车安全性提供丰富可靠的数据支撑. 因此,研究高效、精确的交通场景语义分割和深度估计算法有着重要的现实意义和应用价值.
现有多任务网络模型主要采用编码器-解码器架构,任务解码器共享编码器,并在解码过程中设计特定模块学习特定任务特征和引导跨任务特征交互. 例如:PAD-Net[11]引入多任务信息蒸馏模块来从各任务中提取多模态信息,再将提取的信息作为残差添加到任务解码分支中,实现跨任务信息融合;MTI-Net[12]采用多尺度多模态蒸馏策略扩展PAD-Net,通过明确建模每个单独尺度上独特的任务信息交互,提升了语义分割和深度估计的性能;Zhou等[13]提出以亲和力模式为指导的多任务交互学习网络,利用全局空间注意力来增强各分支任务的特定表示,并基于注意力权重构建任务间的亲和力模式矩阵,引导跨任务交互信息提取和融合. 这些模型在网络搭建过程中大量采用卷积运算,受到卷积局部感受野的限制,基于卷积神经网络(convolutional neural network, CNN)的方法对全局信息建模能力不足,跨任务信息交互能力存在局限性, 因此模型性能难以进一步提升. 受益于Transformer[14]特有的全局和动态建模能力,越来越多的研究人员将Transformer结构引入多任务网络,弥补了CNN方法在长程依赖关系和跨任务相关性建模方面的不足. 例如:VPT[15]采用基于自注意力机制的跨任务特征交互模块,实现了更深层次的跨任务信息传播,有效增强了网络的特征抽取能力. Ye等[10]将Transformer作为主干结构引入多任务密集预测网络,实现同时建模空间和跨任务全局上下文关系,大幅提高了多任务密集预测网络的整体性能. 这些方法都在不同程度上实现了全局模式下的跨任务信息交互,但任务间的相关性建模仍不够明确. 这可能会导致任务间传递的语义信息无法达到期望,严重时甚至给任务表示本身带来不必要的噪声.
针对上述问题,本研究提出新的多任务环境感知算法SDFormer,用于实现交通环境语义分割和深度估计的联合感知. 主要工作包括:1)利用Transformer编码器提取输入图像的通用多尺度特征. 2)基于交叉注意力机制提出双向跨任务注意力模块,用来明确建模特定任务表示之间的全局相关性,引导任务间互补模式信息自适应提取和传输,达到充分利用语义信息和深度信息的模式相关性来提高网络整体性能的目的. 3)结合重采样操作构建多任务Transformer,以较低的计算成本增强网络对各任务全局语义信息的关注;隐式建模跨任务全局相关性,进一步促进任务间互补信息的交互融合. 4)设计编-解码融合上采样模块,逐步生成精细的高分辨率特定任务特征用于最终预测;在公开数据集Cityscapes上开展所提算法的性能验证实验.
1. 网络设计
1.1. 整体结构
如图1所示为SDFormer的总体框架,该网络由任务特征编码网络和2个特定的任务解码器组成,特征的传播和推理通过逐层解码以及跨任务交互式学习的方式实现. 任务特征编码网络用于提取语义分割和深度估计分支的特定任务特征,并将提取的特定任务特征传递给对应的任务分支解码器. 2个特定任务解码器结构相似,都由双向跨任务注意力模块(bidirectional cross-task attention, BCTA)、多任务Transformer模块(multi-task Transformer, MT-T)和编-解码融合上采样模块(encoder-decoder fusion upsampling, EDFU)组成. 该解码器的工作原理:1)通过BCTA挖掘特定任务特征的互补模式信息,优化特征本身的信息层次结构;2)利用MT-T增强各特定任务特征的全局上下文信息,并进行特征之间的隐式交互;3)利用EDFU对解码过程中传递的特定任务特征进行上采样,并通过跳跃连接融合编码阶段的空间细节信息,生成高分辨率的细粒度特定任务特征;4)将这些高分辨率特征传入各任务分支的解码头,进行深度估计和语义分割的任务推理.
图 1
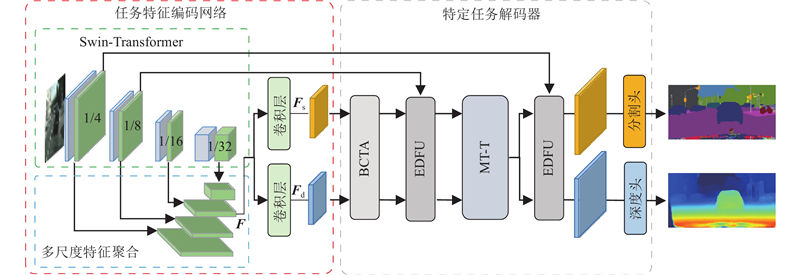
1.2. 任务特征编码网络
通过自注意力机制Transformer可以有效建模图像像素之间的长距离依赖关系,捕获输入图像的全局上下文信息,减少细节特征的丢失. Liu等[16]提出具有层级结构的通用视觉骨干Swin-Transformer,将自注意力计算限制在不重叠的局部窗口中,并进行跨窗口连接,使算法复杂度仅与图像大小线性相关并具备全局感受野. 本研究将Swin-Transformer作为编码器来提取输入图像的通用多尺度特征,以保留输入场景的粗略和精细细节. 各任务分支的卷积块由3×3卷积、批归一化层(BN)和ReLU层组成,作用是进一步解析编码器的输出特征来生成特定任务特征. 单一尺度的编码器输出特征包含的信息结构缺乏多样性,如果直接输入各任务分支卷积层将难以产生具有任务感知的特定任务特征. 为此,采用多尺度特征聚合生成信息结构丰富的融合特征,以增强特定任务特征信息丰富度,提高后续任务特征交互过程中信息传导质量. 为了尽可能承载不同尺度特征细节信息,并避免高分辨率的特征在网络解码过程中直接传递而增加网络计算复杂度,以输入图像分辨率的1/16作为多尺度特征聚合的输出分辨率. 通过特征聚合网络(path aggregation networks, PAN)结构将1/4和1/8尺度的浅层特征空间细节信息汇聚到1/16尺度特征. 与此同时,将包含高级语义信息的1/32尺度的最小分辨率特征通过双线性插值进行2倍上采样,然后与信息汇聚后的1/16尺度特征沿通道维度进行拼接,再经过卷积层生成融合空间细节信息和语义信息的特征F. 将F传入各任务分支卷积块,生成信息结构丰富的初始特定任务特征{Fs, Fd}∈RH×W×C,其中H、W分别为1/16尺度特征图的高度和宽度,C为特征的通道数.
1.3. 双向跨任务注意力模块
图 2
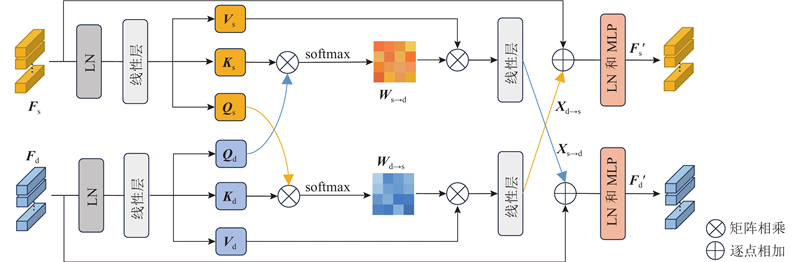
图 2 双向跨任务注意力模块的结构图
Fig.2 Overall structure of bidirectional cross-task attention module
以语义分割分支为例,进行BCTA的工作原理阐述. 语义分割分支的目标是在分割特征空间下,利用深度估计和语义分割任务之间的相关性矩阵,从分割特征中挖掘有利于深度估计任务的模态信息. 采用多头交叉注意力机制搭建任务间信息传播的桥梁,以建模跨任务全局相关性. 具体而言,对于语义分割和深度估计分支的输入特征Fs、Fd,分别沿空间维度进行展平变形为RN×C,其中N=H×W;经过LayerNorm层(LN)和线性投影层处理后,生成各任务分支交叉注意力操作所需的矩阵[Qs, Ks, Vs]和[Qd, Kd, Vd],并据此计算空间全局相关性权重矩阵Ws→d∈RN×N,表达式为
式中:
深度估计分支以对称和双向的方式实施跨任务互补特征提取步骤,同样能够从深度特征中捕获向语义分割分支传递的有利信息特征Xd→s∈RN×C,将任务之间传递的有利信息特征作为残差与原始特定任务特征进行叠加融合,并通过多层感知机进行信息整合,得到各任务分支交互融合后的输出特征Fs′和Fd′,表达式分别为
式中:MLP()为多层感知机. BCTA通过交叉注意力机制表征特定任务表示之间的关联属性,使得网络在特征交互过程中能够高效合理地提取任务之间互补模式信息,减少噪声和冗余信息的干扰,缓解任务优化目标冲突引起的性能下降情况.
1.4. 多任务Transformer模块
如图3所示,MT-T利用自注意力机制增强各特定任务特征的空间全局上下文表征能力,并隐式建模跨任务全局相关性,以促进网络学习任务之间互补模式信息. 图中,Porj为线性投影. MT-T的输入为经过模型总体框架中第1个EDFU上采样后的高分辨特定任务特征{Fs1, Fd1}∈R2H×2W×C. 将Fs1、Fd1从空间维度上展平并拼接形成多任务特征序列Fc∈R8N×C;再利用LN对Fc进行归一化,作为后续自注意力机制计算的输入.
图 3
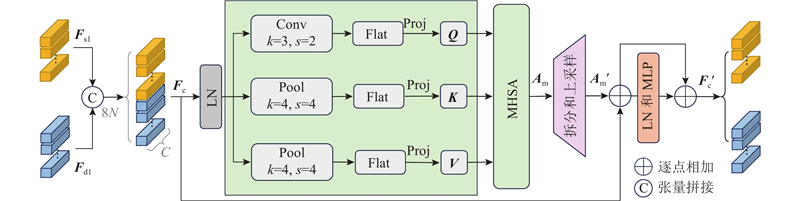
图 3 多任务Transformer模块的结构图
Fig.3 Overall structure of multi-task Transformer module
式中:Conv()为核大小为3、步距为2的下采样卷积;Pool()为核大小为4的下采样均值池化;Flat()为将下采样后的任务特征图在空间维度上展平并拼接,以重新形成多任务特征序列. 据此,可以得到注意力特征Am∈R(8N/4)×C,表达式为
Am不仅能够捕获各特定任务特征本身的全局上下文信息,还融合了特征间隐式交互所产生的互补模式信息. 为了与Fc执行残差连接,须恢复Am空间尺度与Fc对齐. 将Am拆分并重塑为对应任务空间特征图RH×W×C;再执行双线性插值,将分辨率扩大2倍;最后将对应任务空间特征图展平并连接,形成尺度恢复后的注意力特征Am′∈R8N×C. 将Am′和Fc进行逐元素相加,再通过LN和MLP层进一步处理,得到细化后的多任务特征Fc′∈R8N×C. 将Fc′拆分并重塑为对应任务空间特征图R2H×2W×C,得到MT-T各任务分支输出特征.
1.5. 编-解码融合上采样模块
为了产生精细的高分辨率特定任务特征,增强不同任务对于物体边界和小物体的信息处理能力,结合编码部分的浅层细节特征构建EDFU,其具体结构如图4所示.
图 4
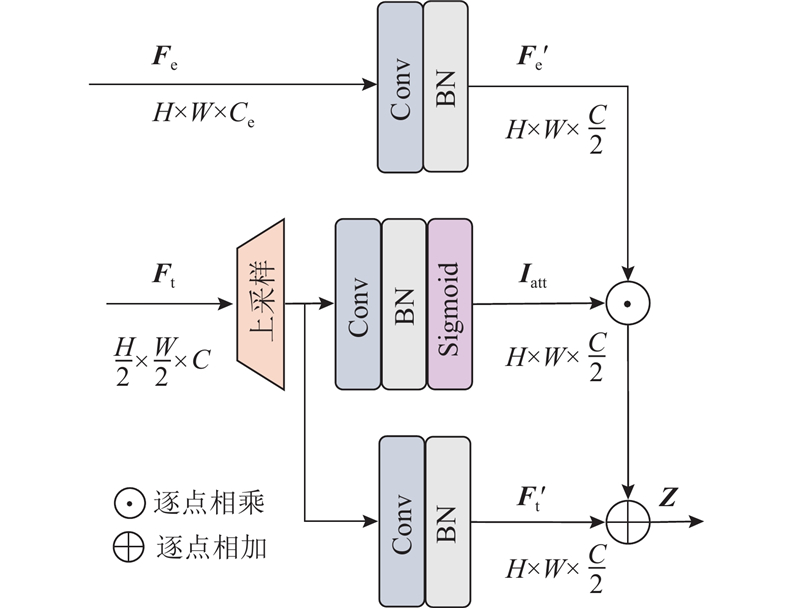
图 4 编-解码融合上采样模块的结构图
Fig.4 Overall structure of encoder-decoder fusion upsampling module
EDFU的输入由2个部分组成:1)网络模型编码器中对应尺度的空间细节特征Fe,2)待上采样的特定任务特征Ft. 将Fe经过3×3卷积和BN处理,得到空间细节信息被强化的特征Fe′. 对Ft利用双线性插值方法进行2倍上采样,再分为2个分支进行处理:1)通过1×1卷积、BN和激活函数Sigmoid产生任务感知语义权重Iatt,2)通过1×1卷积、BN生成信息重构后的特定任务特征Ft′. 以上3个分支的输出具有相同的特征维度大小,通道数被调整为输入特定任务特征Ft的一半. 最终,通过Fe′和Iatt逐像素相乘使得编码器空间细节信息注入特定任务特征当中,将乘积与Ft′进行逐像素相加,得到包含空间细节信息的特定任务特征Z,表达式为
EDFU在对特定任务特征进行上采样的同时,能够有效地融合编码部分空间细节信息,增强特定任务特征精细程度,提高网络模型语义分割和深度估计精确度.
1.6. 损失函数
针对语义分割任务,采用交叉熵作为网络训练损失函数. 针对深度估计任务,采用berHu [18]作为网络训练损失函数,计算式为
式中:
式中:
2. 实验与分析
2.1. 数据集
实验采用广泛使用于交通场景理解的大规模数据集Cityscapes[19]. 该数据集收集自50多个不同城市的街道场景,分别有2 975、500和1 525张精细标注的图像用于训练、验证和测试. Cityscapes共标注19个语义类别用于语义分割任务,提供与RGB图像相对应的视差值标签用于深度估计任务. 由于Cityscapes并未公开测试集部分的真实标签,不利于不同算法之间的性能对比,本研究涉及的消融和对比实验都在Cityscapes的验证集上完成.
2.2. 实验平台与参数设置
实验主机的操作系统为64位 Windows10,硬件采用Intel(R) Core(TM) i7-10700K CPU和NVIDIA GeForce RTX 3090显卡. 算法开发环境采用Python 3.7和 PyTorch 深度学习框架. 模型训练,使用在ImageNet-22上预训练的Swin-Transformer权重对模型编码器进行参数初始化,特定任务特征通道数初值设置为512. 采用Adam优化器,初始学习率设置为4.0×10−5,权重衰减率设置为1.0×10−6,学习率衰减策略选择指数衰减. 不同对比模型都在数据集上进行45 000次迭代训练,批处理大小设置为4. 数据加载和预处理时,将图像的像素大小从2 048×1 024调整为1 024×512,并通过随机缩放、翻转、扭曲等操作对数据集进行几何增强,以及随机调整图片的饱和度、亮度进行光照增强.
2.3. 评价指标
选择平均交并比MIoU作为分割性能的评价指标,计算式为
式中:n为类别总数,tij为将第i类真实类别预测为第j类的像素数量. 选择平均平方根误差RMSE和绝对相对误差ARE作为深度估计性能的评价指标,计算式分别为
式中:N为图像像素总数,
2.4. 所损算法消融实验
为了分析所提模块对SDFormer的性能影响,进行消融实验,实验模型编码器均使用Swin-S,结果如表1所示. 表中,STL-Seg和STL-Depth分别表示关于2个任务的单任务基线模型,由编码器和多尺度特征聚合解码器[20]组成;MTL表示任务特征编码网络和2个任务特定解码头组成的多任务基线模型;其余实验模型均表示在MTL上逐步添加对应模块. 可以看出:1)相较于基线模型MTL,添加BCTA后,语义分割的MIoU明显提升,且深度估计的RMSE和ARE均大幅下降. 这表明BCTA能够充分建模任务相关性来挖掘和利用任务间的互补模式信息,增强网络对任务特定信息的感知能力. 2)在BCTA基础上添加MT-T后,MIoU增加1.2个百分点,RMSE和ARE分别降低0.134和0.025. 这表明MT-T能够促进网络学习任务间的互补模式信息,强化各特定任务特征的全局语义信息表征能力. 3)进一步添加EDFU后,模型各任务性能指标都达到最优值. 这表明EDFU可以有效地融合空间细节信息和任务语义上下文信息,提高不同任务中对物体细节的表达能力.综上可知,相较于基线模型MTL,SDFormer的语义分割MIoU从73.2%提升到77.6%,深度估计RMSE和ARE分别从5.355和0.227下降到4.781和0.156. 这证明所提算法可以充分挖掘和利用任务之间相关信息,达到任务之间相互补充和相互约束的目的,显著提高各任务性能. 相比单任务基线模型STL-Seg和STL-Depth,SDFormer表现出明显的性能优势,参数量和计算量分别增加48%和21%. 符合多任务模型在降低内存占用和不显著增加计算复杂度的情况下,依然保持较优的整体性能的预期目标.
表 1 SDFormer消融实验结果
Tab.1
| 模型 | MIoU/% | RMSE | ARE | Np/106 | GFLOPs |
| STL-Seg | 76.3 | — | — | 50.5 | 132.5 |
| STL-Depth | — | 4.910 | 0.174 | 50.5 | 132.5 |
| MTL | 73.2 | 5.355 | 0.227 | 66.3 | 131.1 |
| +BCTA | 75.8 | 5.028 | 0.186 | 72.6 | 153.8 |
| +MT-T | 77.0 | 4.894 | 0.161 | 73.4 | 162.7 |
| +EDFU | 77.6 | 4.781 | 0.156 | 74.5 | 167.0 |
如图5所示为MTL和SDFormer关于语义分割任务的推理结果对比. 可以看出,与MTL相比,SDFormer的分割结果更平滑,对小尺度物体的分割精度更高,物体细节信息的展现能力更强. 以第3行场景中虚线框标注为例,MTL对细长类路牌杆的分割有明显缺损,而SDFormer的分割结果更精确. 如图6所示为MTL和SDFormer关于深度估计任务的推理结果对比. 与MTL相比,SDFormer预测的深度图细节更清晰,可以更好地恢复物体的轮廓边界. 以第3行场景中虚线框标注为例,MTL能够大致地估计出该区域内的深度边界,但较为模糊;SDFormer的视觉效果更好,能够较为清晰地恢复自行车的轮廓细节. 综合分析可知,通过利用任务之间的潜在关系,可以使网络模型各任务分支提取到更具判别性的特征,获得更精细的分割结果和深度估计结果.
图 5
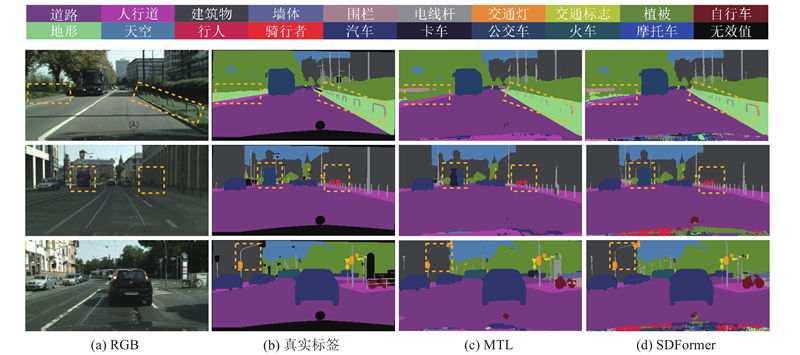
图 5 MTL与SDFormer的语义分割效果对比
Fig.5 Comparison of semantic segmentation effects between MTL and SDFormer
图 6
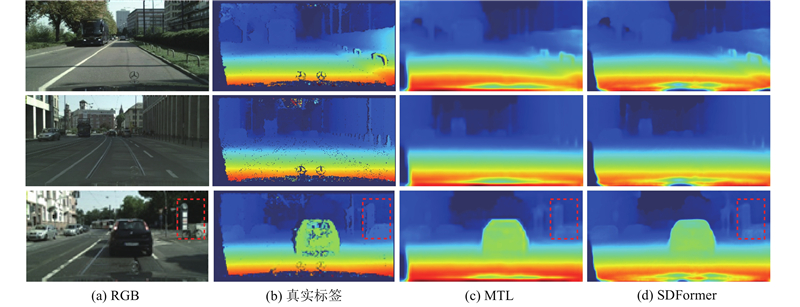
图 6 MTL与SDFormer的深度估计效果对比
Fig.6 Comparison of depth estimation effects between MTL and SDFormer
2.5. 双向跨任务注意力模块方案对比
为了进一步验证BCTA的有效性,将BCTA从SDFormer中移除,替换为Zhang等[15]提出的特征转换模块(feature pattern transformation, FPT)和结构转换模块(structure pattern transformation, SPT)作为对照组进行模块性能对比. 这2种特征交互模块在引导跨任务信息交互的相关性建模上与BCTA存在较大的差异,其中FPT利用自注意力机制挖掘任务内重要模式信息进行跨任务传播,SPT利用表征任务内重要模式信息的自注意力权重构建任务间亲和力模式矩阵,引导跨任务信息交互. 实验结果如表2所示. 可以看出,相比FPT和SPT,使用BCTA的SDFormer在2个任务上都取得了更好的性能,原因是BCTA在不同任务特征模式下都可以更明确地建模任务间的全局相关性,使得在跨任务特征交互过程中,任务之间能够传播更丰富、更有意义的信息流,减少噪声和冗余信息带来的干扰,实现更高的预测置信度.
表 2 不同双向跨任务特征交互模块的性能对比
Tab.2
| 模块 | MIoU/% | RMSE | ARE | GFLOPs |
| FPT | 76.1 | 5.058 | 0.204 | 169.2 |
| SPT | 76.7 | 4.924 | 0.180 | 173.8 |
| BCTA | 77.6 | 4.781 | 0.156 | 167.0 |
2.6. 多任务Transformer模块消融实验
为了验证MT-T的合理性和有效性,进行模块拆解和实验对比. SDFormer-noT为从SDFormer中去除MT-T的模型;SDFormer-s为采用普通Transformer替换MT-T的模型,为了尽可能与SDFormer进行公平比较,替换的Transformer层参照PVT[21]的下采样倍率设置,并利用池化层对键、值矩阵进行降维处理以减少自注意力计算复杂度;SDFormer-noD为取消了MT-T内部重采样降维处理操作的SDFormer,对比实验结果如表3所示. 由表可知:1)在各任务分支中添加Transformer层后,模型各任务性能均获得提升. 这表明Transformer层可以有效捕获全局语义信息,增强网络特定任务特征的信息表达能力. 2)使用MT-T的SDFormer能够取得更加优异的整体性能. 原因是该模块可以同时建模全局空间依赖性和跨任务相关性,在捕捉全局语义信息的同时,还能实现跨任务特征交互,融合任务之间互补模式信息,实现更好的性能提升效果. 3)当MT-T不含重采样降维处理时,对模型整体性能提升效果不明显,却大幅提高了计算复杂度,使模型推理速度变慢;相比之下,采用重采样降维处理的MT-T不仅能够有效地提升模型的推理速度,还能维持模型中各任务预测精度.
表 3 多任务Transformer模块消融实验结果
Tab.3
| 模型 | MIoU/% | RMSE | ARE | GFLOPs | f/(帧.s−1) |
| SDFormer-noT | 76.0 | 4.957 | 0.184 | 155.2 | 31.7 |
| SDFormer-s | 76.7 | 4.870 | 0.175 | 170.1 | 18.5 |
| SDFormer-noD | 77.8 | 4.815 | 0.153 | 178.3 | 9.7 |
| SDFormer | 77.6 | 4.781 | 0.156 | 167.0 | 23.6 |
2.7. 不同编码器的性能对比
表 4 不同编码器的性能对比实验结果
Tab.4
| 编码器 | MIoU/% | RMSE | ARE | Np/106 | f/(帧.s−1) |
| ResNet-50 | 74.8 | 5.287 | 0.226 | 54.1 | 65.1 |
| ResNet-101 | 76.4 | 5.053 | 0.184 | 73.1 | 34.8 |
| Swin-T | 75.3 | 5.128 | 0.206 | 58.7 | 47.6 |
| Swin-S | 77.6 | 4.781 | 0.156 | 74.5 | 23.6 |
| Swin-B | 79.2 | 4.485 | 0.132 | 116.7 | 11.2 |
2.8. 与单任务算法的性能对比
通常情况下,相比使用多个单一任务网络级联工作,使用多任务网络能够大幅降低参数规模和计算量,但多数情况下后者在各个任务上取得的性能指标不如前者. 为了探明SDFormer与现有主流单任务模型的性能差异,分别在各个任务上开展对比实验. 在语义分割任务中,主要对比对象为PSPNet[23]、SETR[24]、SegFormer[20]和Mask2Former[25],结果如表5所示. 在单目深度估计任务中,选择Lap-Depth[5]、DepthFormer[6]和pixelFormer[26]作为对比,结果如表6所示. 可以看出:1)相比于更具针对性的单任务网络模型,SDFormer同时推理语义分割和深度估计2个任务,导致任务间存在资源竞争,因此在语义分割任务和深度估计任务各性能指标上仅处于中等水平,不具备明显优势. 不过,得益于不同任务间互补模式信息的交互融合,任务之间可以进行相互指导和优化,因此综合性能仍具有较好的竞争力,尤其是在深度估计任务上的RMSE指标与当前性能最优的pixelFormer相比仅高出0.227. 2)SDFormer仅进行一次推理即可实现2个单任务网络协同工作才能完成的感知目标,耗用的总计算资源大幅减小.
表 5 SDFormer与单任务算法的语义分割性能对比
Tab.5
| 方法 | 编码器 | MIoU/% | Np/106 | GFLOPs |
| PSPNet | ResNet-101 | 78.5 | 68.5 | 546.8 |
| SETR | ViT-B | 78.0 | 97.6 | 457.2 |
| SegFormer | MiT-B3 | 80.3 | 48.2 | 224.6 |
| Mask2Former | Swin-B | 81.2 | 107.0 | 343.5 |
| SDFormer | Swin-B | 79.2 | 116.7 | 247.5 |
表 6 SDFormer与单任务算法的深度估计性能对比
Tab.6
| 方法 | 编码器 | RMSE | ARE | Np/106 | GFLOPs |
| Lap-Depth | ResNet-101 | 4.553 | 0.154 | 73.4 | 186.5 |
| DepthFormer | Swin-B | 4.326 | 0.127 | 151.3 | 282.0 |
| pixelFormer | Swin-B | 4.258 | 0.115 | 146.1 | 346.4 |
| SDFormer | Swin-B | 4.485 | 0.132 | 116.7 | 247.5 |
2.9. 与多任务算法的性能对比
为了进一步验证SDFormer的综合性能,进行多任务网络性能实验对比. 对比的经典多任务网络包括采用CNN架构的MTAN[27]、PAD-Net[11]、PSD-Net[13] 、MTI-Net[12]和采用Transformer架构的当前性能较优的InvPT,结果如表7所示. 可以看出:SDFormer在语义分割和深度估计任务的性能指标上均优于基于CNN架构网络模型,特别是对于深度估计任务,性能获得大幅提升,与CNN架构体系中较优的MTI-Net相比RMSE和ARE分别降低12.6%和32.0%. 与将Transformer架构引入多任务密集预测领域的InvPT相比,SDFormer的语义分割MIoU提高了1.4个百分点,深度估计RMSE和ARE分别降低3.7%和14.2%,且在使用相同编码器的情况下参数量和计算量分别减少了14.7%和42.7%. 结果表明,SDFormer在联合学习语义分割和深度估计2个任务上相比现有算法有更为先进的整体性能.
表 7 不同多任务算法的性能对比结果
Tab.7
| 方法 | 编码器 | MIoU/% | RMSE | ARE | Np/106 | GFLOPs |
| MTAN | ResNet-101 | 74.4 | 5.846 | 0.246 | 88.3 | 204.9 |
| PAD-Net | ResNet-101 | 76.3 | 5.275 | 0.208 | 84.5 | 194.5 |
| PSD-Net | ResNet-101 | 75.6 | 5.581 | 0.225 | 101.8 | 224.6 |
| MTI-Net | ResNet-101 | 76.8 | 5.135 | 0.194 | 112.4 | 269.4 |
| InvPT | Swin-B | 77.8 | 4.657 | 0.154 | 136.9 | 431.5 |
| SDFormer | Swin-B | 79.2 | 4.485 | 0.132 | 116.7 | 247.5 |
如图7所示为SDFormer与次优算法InvPT在语义分割任务上的推理结果差异. 在虚线框指示的易混淆类别区域中,InvPT将地形类别大面积地错判为植被类别,将自行车类别错判为摩托车类别,将人行道类别错判为植被类别. 相比而言,SDFormer关于地形类别的错判面积大幅减小,且对于自行车类别和人行道类别不存在错判. 如图8所示为SDFormer与InvPT在深度估计任务上的推理结果差异. 可以看出,SDFormer能够保留更多的细节信息,使得场景中较远处物体的轮廓更加清晰和完整. 以图中第1行虚线框指示区域内的电线杆为例,InvPT推理出的深度信息出现明显的缺损,SDFormer推理出的深度信息则更加完整和连续.
图 7
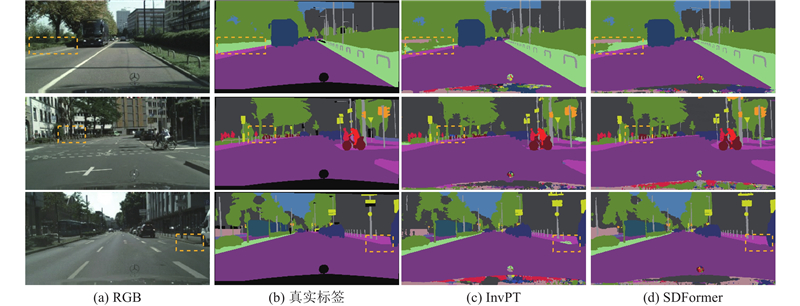
图 7 SDFormer与InvPT的语义分割效果对比
Fig.7 Comparison of semantic segmentation effects between SDFormer and InvPT
图 8
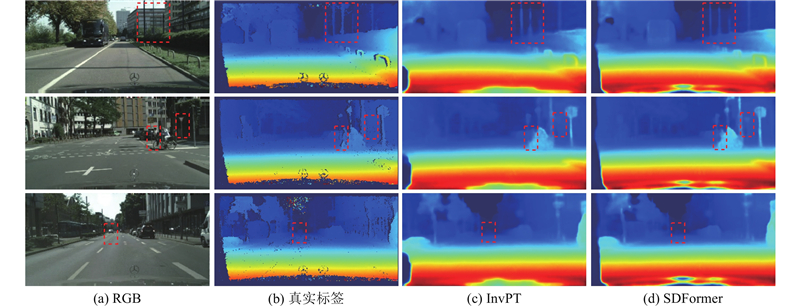
图 8 SDFormer与InvPT的深度估计效果对比
Fig.8 Comparison of depth estimation effects between SDFormer and InvPT
为了更加直观地验证所提算法对交通场景深度估计的有效性和适应能力,从验证集中随机抽样100张图像,针对图像中5类主要的交通参与者,分别计算各类别目标真实距离与预测距离之间的平均相对误差. 考虑到同一目标物体的各部分到车辆的真实距离一般存在差异,出于碰撞安全考虑,仅针对该目标物体中距离摄像机较近的20%部分的像素进行统计分析,取平均值作为该目标与摄像机的距离. 根据双目成像原理,像素所表示的距离计算式为
式中:b为双目相机的瞳距,f为相机焦距,d为视差值. 由式(14)可分别计算出第i个目标与摄像头的真实距离
式中:Nc为第c类目标的样本总数. 如表8所示为各对比模型对5种主要类别的MRE,其中mMRE为各类别MRE总和的平均值. 可以看出,SDFormer针对5个典型类别的交通参与者的综合距离估计取得了最小相对误差,为6.1%,优于现有主流多任务算法. 除car类别的MRE指标取得次小值外,其余类别均取得最小值,表明所提算法对交通场景中典型交通参与者的深度估计具备优越性和有效性.
表 8 不同多任务算法的距离估计误差对比结果
Tab.8
| 方法 | MRE/% | mMRE/% | ||||
| person | rider | car | bus | truck | ||
| MTAN | 14.5 | 15.5 | 13.0 | 16.1 | 14.7 | 14.7 |
| PAD-Net | 12.6 | 13.3 | 10.7 | 12.4 | 11.3 | 12.0 |
| PSD-Net | 11.7 | 12.6 | 11.8 | 12.7 | 12.2 | 12.2 |
| MTI-Net | 12.3 | 12.8 | 9.8 | 11.4 | 10.7 | 11.4 |
| InvPT | 7.6 | 7.2 | 6.6 | 7.8 | 8.3 | 7.5 |
| SDFormer | 6.1 | 5.4 | 7.4 | 5.2 | 6.5 | 6.1 |
如表9所示为SDFormer针对这5类典型交通参与者处在不同距离范围时的距离估计误差. 结果显示,当目标距离不同时,算法针对5类典型交通参与者距离估计误差有所不同. 当目标处于小于20 m的近距离时,mMRE取得最小值,为4.1%;当目标处于20~50 m的中距离时,mMRE=5.3%;当目标处于大于50 m的远距离时,mMRE取得最大值,为10.8%. 这说明,目标距离摄像头越近,算法的距离估计误差越小.
表 9 SDFormer在不同距离范围的距离估计误差
Tab.9
| 距离 | MRE/% | mMRE/% | ||||
| person | rider | car | bus | truck | ||
| 近 | 3.5 | 4.8 | 5.1 | 4.3 | 3.2 | 4.1 |
| 中 | 5.4 | 5.6 | 4.8 | 5.2 | 5.7 | 5.3 |
| 远 | 13.7 | 11.2 | 9.8 | 9.5 | 10.1 | 10.8 |
可视化列举展示SDFormer针对不同距离范围的5类典型交通参与者的距离预测效果如图9所示,其中上、下数据标签分别表示真实距离值和预测距离值. 由图中数据可以看出,所提算法对处在不同距离范围内的目标都具有良好的距离预测能力.
图 9

图 9 SDFormer在不同距离范围的距离预测效果展示
Fig.9 Display of distance prediction effects of SDFormer in different distance ranges
3. 结 语
本研究提出基于Transformer的多任务环境感知算法SDFormer,用于联合执行交通场景语义分割和深度估计,旨在充分利用任务之间的相关性来提高多任务模型整体性能. SDFormer利用Swin-Transformer编码器提取输入图像的多尺度特征,采用多尺度特征聚合策略增强深层特征表示,促进了初始特定任务特征的有效提取. 在任务解码过程中,提出双向跨任务注意力机制BCTA来显示建模任务间的全局相关性,引导任务之间有效地挖掘并利用互补模式信息,达到相互指导和优化的目的;构建多任务Transformer模块MT-T来增强特定任务特征的空间全局表示,隐式建模跨任务全局上下文关系,进一步促进了任务之间交互信息融合;设计编-解码融合上采样模块EDFU来实现对特定任务特征进行上采样的同时有效融合空间细节信息,获得了更精细的轮廓分割结果和深度估计结果. 在Cityscapes数据集上开展的大量实验表明:与现有多任务算法相比,所提算法在2个视觉任务:交通场景语义分割和深度估计上都取得了更先进的性能. 未来的研究内容考虑将目标检测任务融入多任务模型中,实现对交通场景更加全面的信息感知.
参考文献
基于卷积神经网络的交通场景语义分割方法研究
[J].
Study on traffic scene semantic segmentation method based on convolutional neural network
[J].
Deep dual-resolution networks for real-time and accurate semantic segmentation of traffic scenes
[J].
基于Transformer的高效自适应语义分割网络
[J].
Efficient and adaptive semantic segmentation network based on Transformer
[J].
Monocular depth estimation using laplacian pyramid-based depth residuals
[J].DOI:10.1109/TCSVT.2021.3049869 [本文引用: 1]
DepthFormer: exploiting long-range correlation and local information for accurate monocular depth estimation
[J].DOI:10.1007/s11633-023-1458-0 [本文引用: 2]
Multi-task learning for dense prediction tasks: a survey
[J].
When visual disparity generation meets semantic segmentation: a mutual encouragement approach
[J].DOI:10.1109/TITS.2020.3027556 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}