| 计算机与控制工程 |
|

|
|
|
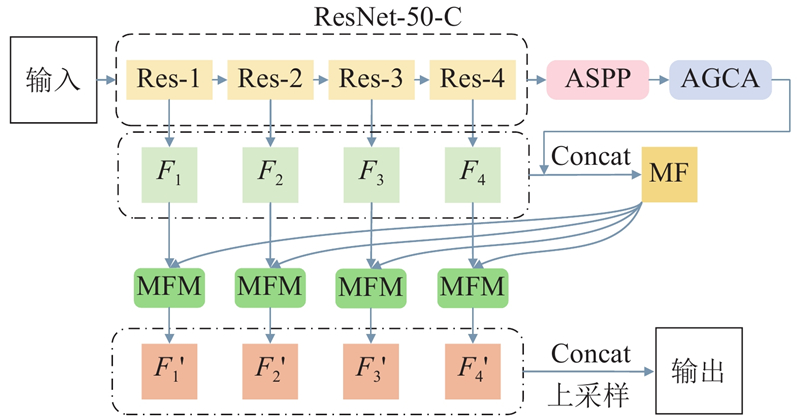
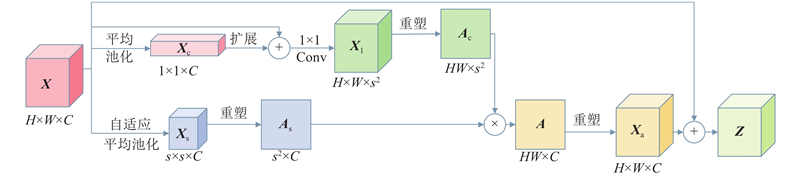
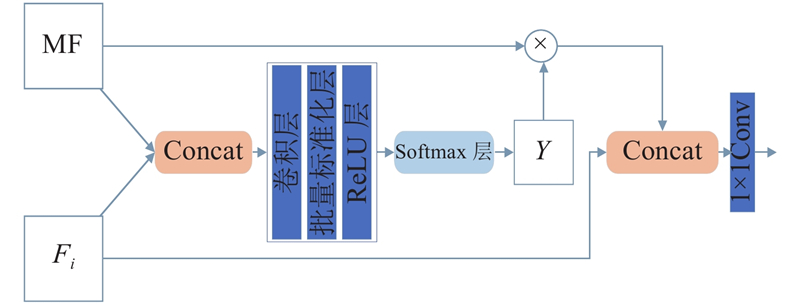
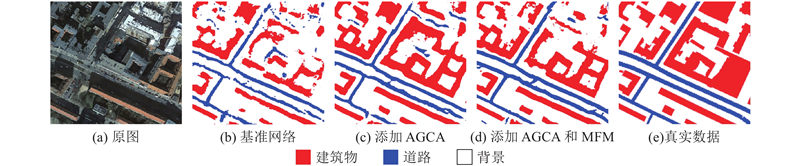
| 基于遥感图像道路提取的全局指导多特征融合网络 |
宦海1( ),盛宇2,顾晨曦1 ),盛宇2,顾晨曦1 |
1. 南京信息工程大学 人工智能学院,江苏 南京 210044
2. 南京邮电大学 集成电路科学与工程学院,江苏 南京 210003 |
|
| Global guidance multi-feature fusion network based on remote sensing image road extraction |
| Hai HUAN1(),Yu SHENG2,Chenxi GU1 |
1. School of Artificial Intelligence, Nanjing University of Information Science and Technology, Nanjing 210044, China
2. School of Integrated Circuit Science and Engineering, Nanjing University of Posts and Telecommunications, Nanjing 210003, China |
| 1 |
QUAN B, LIU B, FU D, et al. Improved DeepLabV3 for better road segmentation in remote sensing images [C]// 2021 International Conference on Computer Engineering and Artificial Intelligence . Shanghai: IEEE, 2021: 331–334.
|
| 2 |
ZHANG J, LI Y, SI Y, et al A low-grade road extraction method using SDG-DenseNet based on the fusion of optical and SAR images at decision level[J]. Remote Sensing, 2022, 14 (12): 2870
doi: 10.3390/rs14122870
|
| 3 |
胡春安, 陈玉玲 基于Gabor和改进 LDA的人耳识别[J]. 计算机工程与科学, 2015, 37 (7): 1355- 1359
HU Chun’an, CHEN Yuling An ear recognition algorithm based on gabor features and improved LDA[J]. Computer Engineering and Science, 2015, 37 (7): 1355- 1359
|
| 4 |
邢军 基于Sobel算子数字图像的边缘检测[J]. 微机发展, 2005, 15 (9): 48- 49
XING Jun Edge detection of Sobel-based digital image[J]. Microcomputer Development, 2005, 15 (9): 48- 49
|
| 5 |
SUN Q, LIU Q. The target fish’s population detection based on the improved watershed algorithm [C]// 2022 7th International Conference on Intelligent Computing and Signal Processing (ICSP) . Xi’an: IEEE, 2022: 507-510.
|
| 6 |
QIN J, HE Z S. A SVM face recognition method based on Gabor-featured key points [C]// 2005 International Conference on Machine Learning and Cybernetics . Guangzhou: IEEE, 2005: 5144–5149.
|
| 7 |
董师师, 黄哲学 随机森林理论浅析[J]. 集成技术, 2013, 2 (1): 1- 7
DONG Shishi, HUANG Zhexue A brief theoretical overview of random forests[J]. Journal of Integration Technology, 2013, 2 (1): 1- 7
|
| 8 |
GU J, WANG Z, KUEN J, et al Recent advances in convolutional neural networks[J]. Pattern Recognition, 2018, 77: 354- 377
doi: 10.1016/j.patcog.2017.10.013
|
| 9 |
ZHANG Z, LIU Q, WANG Y Road extraction by deep residual U-Net[J]. IEEE Geoscience and Remote Sensing Letters, 2018, 15 (5): 749- 753
doi: 10.1109/LGRS.2018.2802944
|
| 10 |
LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation [C]// 2015 IEEE Conference on Computer Vision and Pattern Recognition . Boston: IEEE, 2015: 3431–3440.
|
| 11 |
LIN G, MILAN A, SHEN C, et al. RefineNet: multi-path refinement networks for high-resolution semantic segmentation [C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 1925–1934.
|
| 12 |
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 770–778.
|
| 13 |
ZHAO H, SHI J, QI X, et al. Pyramid scene parsing network [C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 2881–2890.
|
| 14 |
CHEN L C, ZHU Y, PAPANDREOU G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation [C]// European Conference on Computer Vision . [S. l.]: Springer, 2018: 833–851.
|
| 15 |
HU J, SHEN L, SUN G. Squeeze-and-excitation networks [C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 7132–7141.
|
| 16 |
WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module [C]// European Conference on Computer Vision . [S. l.]: Springer, 2018: 3–19.
|
| 17 |
FU J, LIU J, TIAN H, et al. Dual attention network for scene segmentation [C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 3146–3154.
|
| 18 |
ZHANG W, HUANG Z, LUO G, et al. TopFormer: token pyramid transformer for mobile semantic segmentation [C]// 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 12083–12093.
|
| 19 |
KAISER P, WEGNER J D, LUCCHI A, et al Learning aerial image segmentation from online maps[J]. IEEE Transactions on Geoscience and Remote Sensing, 2017, 55 (11): 6054- 6068
doi: 10.1109/TGRS.2017.2719738
|
| 20 |
DEMIR I, KOPERSKI K, LINDENBAUM D, et al. Deepglobe 2018: a challenge to parse the earth through satellite images [C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops . Salt Lake City: IEEE, 2018: 172-181.
|
| 21 |
ZHU Q, ZHANG Y, WANG L, et al A global context-aware and batch-independent network for road extraction from VHR satellite imagery[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2021, 175: 353- 365
doi: 10.1016/j.isprsjprs.2021.03.016
|
| 22 |
HE T, ZHANG Z, ZHANG H, et al. Bag of tricks for image classification with convolutional neural networks [C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 558–567.
|
| 23 |
CHEN L C, PAPANDREOU G, SCHROFF F, et al. Rethinking atrous convolution for semantic image segmentation [EB/OL]. (2017-12-05)[2023-05-10]. https://arxiv.org/pdf/1706.05587.pdf.
|
| 24 |
HE J, DENG Z, ZHOU L, et al. Adaptive pyramid context network for semantic segmentation [C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 7519–7528.
|
| 25 |
HUANG Z, WANG X, HUANG L, et al. CCNet: criss-cross attention for semantic segmentation [C]// 2019 IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 603–612.
|
| 26 |
LI X, ZHONG Z, WU J, et al. Expectation-maximization attention networks for semantic segmentation [C]// 2019 IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 9167–9176.
|
| 27 |
YIN M, YAO Z, CAO Y, et al. Disentangled non-local neural networks [C]// European Conference on Computer Vision . [S. l.]: Springer, 2020: 191–207.
|
| 28 |
LI S, LIAO C, DING Y, et al Cascaded residual attention enhanced road extraction from remote sensing images[J]. ISPRS International Journal of Geo-Information, 2022, 11 (1): 9
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|