| 计算机技术 |
|

|
|
|
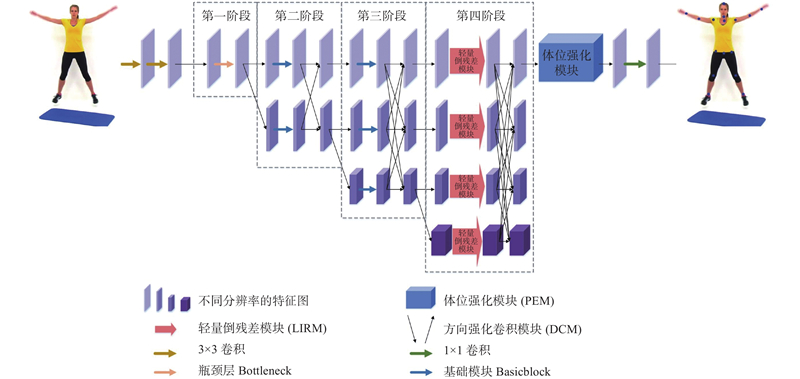
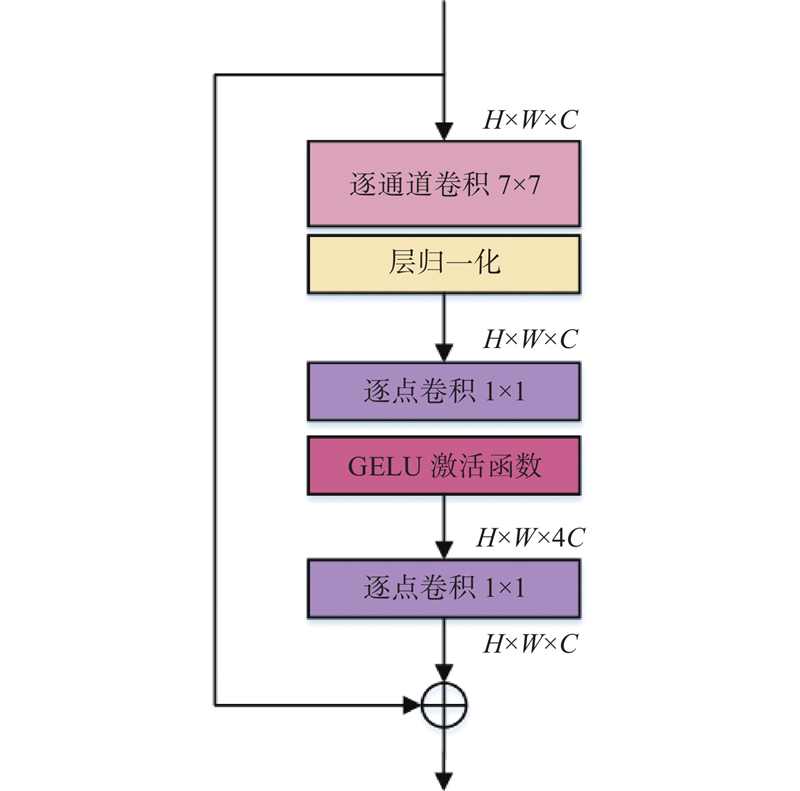
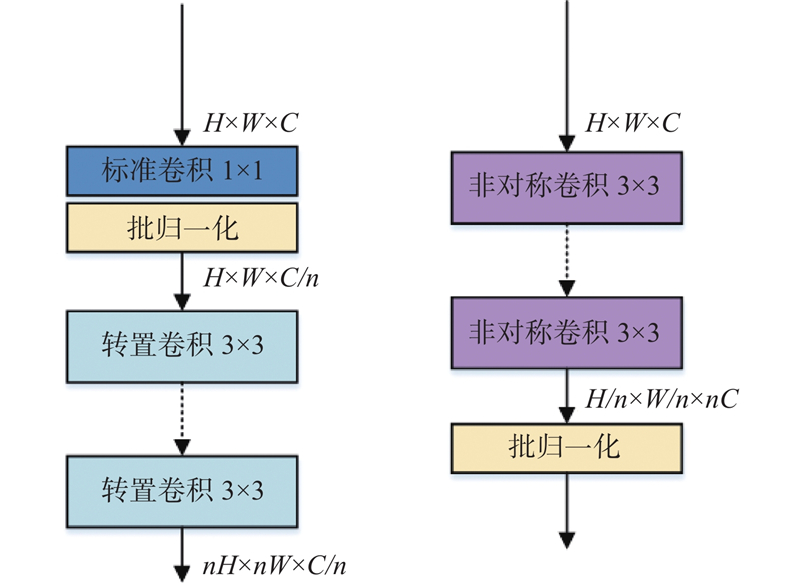
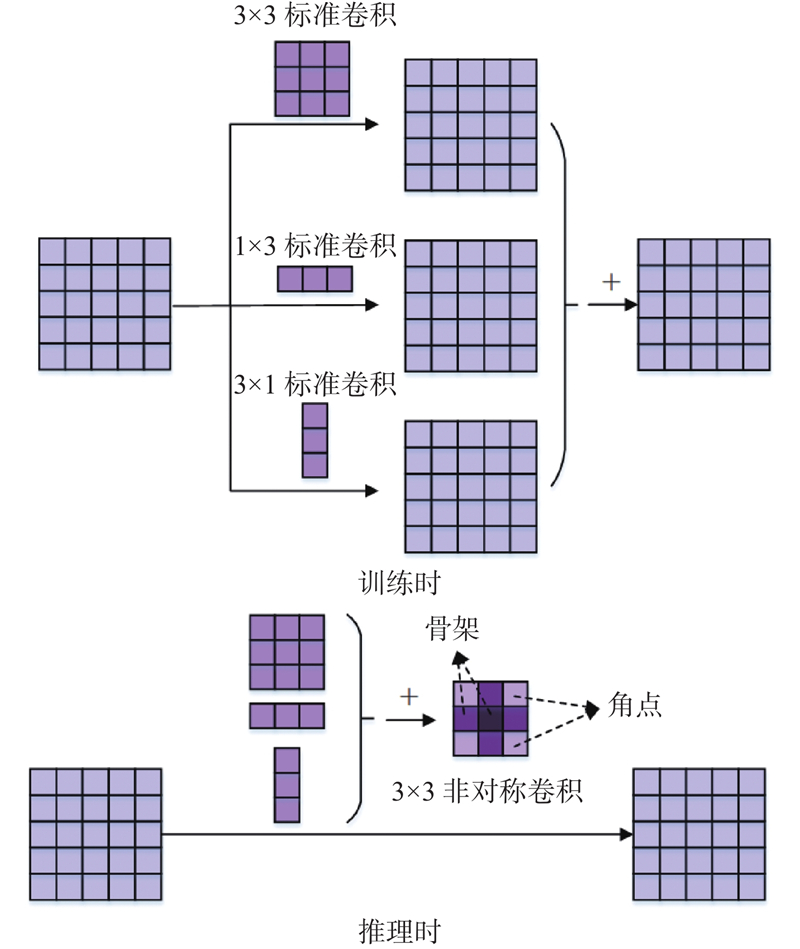
| 强化先验骨架结构的轻量型高效人体姿态估计 |
孙雪菲( ),张瑞峰,关欣,李锵*() ),张瑞峰,关欣,李锵*() |
| 天津大学 微电子学院,天津 300072 |
|
| Lightweight and efficient human pose estimation with enhanced priori skeleton structure |
| Xuefei SUN(),Ruifeng ZHANG,Xin GUAN,Qiang LI*() |
| School of Microelectronics, Tianjin University, Tianjin 300072, China |
引用本文:
孙雪菲,张瑞峰,关欣,李锵. 强化先验骨架结构的轻量型高效人体姿态估计[J]. 浙江大学学报(工学版), 2024, 58(1): 50-60.
Xuefei SUN,Ruifeng ZHANG,Xin GUAN,Qiang LI. Lightweight and efficient human pose estimation with enhanced priori skeleton structure. Journal of ZheJiang University (Engineering Science), 2024, 58(1): 50-60.
链接本文:
https://www.zjujournals.com/eng/CN/10.3785/j.issn.1008-973X.2024.01.006
或
https://www.zjujournals.com/eng/CN/Y2024/V58/I1/50
|
| 1 |
REIS E S, SEEWALD L A, ANTUNES R S, et al Monocular multi-person pose estimation: a survey[J]. Pattern Recognition, 2021, 118: 108046
|
| 2 |
NEWELL A, YANG K, DENG J. Stacked hourglass networks for human pose estimation [C]// European Conference on Computer Vision. Amsterdam: Springer, 2016: 483–499.
|
| 3 |
CHEN Y, WANG Z, PENG Y, et al. Cascaded pyramid network for multi-person pose estimation [C]// IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 7103–7112.
|
| 4 |
XIAO B, WU H, WEI Y. Simple baselines for human pose estimation and tracking [C]// European Conference on Computer Vision. Munich: Springer, 2018: 472–487.
|
| 5 |
SUN K, XIAO B, LIU D, et al. Deep high-resolution representation learning for human pose estimation [C]// IEEE Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 5686–5696.
|
| 6 |
SANDLER M, HOWARD A, ZHU M, et al. MobileNetV2: inverted residuals and linear bottlenecks [C]// IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 4510-4520.
|
| 7 |
ZHANG X, ZHOU X, LIN M, et al. ShuffleNet: an extremely efficient convolutional neural network for mobile devices [C]// IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 6848-6856.
|
| 8 |
QIAO S, CHEN L C, YUILLE A. DetectoRS: detecting objects with recursive feature pyramid and switchable atrous convolution [C]// IEEE Conference on Computer Vision and Pattern Recognition. Nashville: IEEE, 2021: 10208-10219.
|
| 9 |
LIN T Y, DOLLAR P, GIRSHICK R, et al Feature pyramid networks for object detection[J]. IEEE Computer Society, 2017, 1: 936- 944
|
| 10 |
SU H, JAMPANI V, SUN D, et al. Pixel-adaptive convolutional neural networks [C]// IEEE Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 11158-11167.
|
| 11 |
CHEN Y, DAI X, LIU M, et al. Dynamic convolution: attention over convolution kernels [C]// IEEE Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 11027-11036.
|
| 12 |
WANG Q, WU B, ZHU P, et al. ECA-Net: efficient channel attention for deep convolutional neural networks [C]// IEEE Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 11531-11539.
|
| 13 |
LI X, WANG W, HU X, et al. Selective kernel networks [C]// IEEE Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 510-519.
|
| 14 |
RAJAMANI K, GOWDA S D, TEJ V N, et al. Deformable attention (DANet) for semantic image segmentation [C]// Annual International Conference of the IEEE Engineering in Medicine and Biology Society. Glasgow: IEEE, 2022: 3781-3784.
|
| 15 |
刘勇. 基于关键点检测的目标二维姿态估计研究[D]. 成都: 中国科学院光电技术研究所, 2021.
LIU Yong. Research on two-dimensional object pose estimation based on key-point detection [D]. Chengdu: Institute of Optics and Electronics, Chinese Academy of Sciences, 2021.
|
| 16 |
LIU Z, MAO H, WU C Y, et al. A Convnet for the 2020s [C]// IEEE Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 11966-11976.
|
| 17 |
CHEN J, HE T, ZHUO W, et al. TVConv: efficient translation variant convolution for layout-aware visual processing [C]// IEEE Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 12538-12548.
|
| 18 |
CAO Y, XU J, LIN S, et al. GCNet: non-local networks meet squeeze-excitation networks and beyond [C]// IEEE International Conference on Computer Vision Workshop. Seoul: IEEE, 2019: 1971-1980.
|
| 19 |
DIND X, GUO Y, DING G, et al. ACNet: strengthening the kernel skeletons for powerful CNN via asymmetric convolution blocks [C]// IEEE International Conference on Computer Vision. Seoul: IEEE, 2019: 1911-1920.
|
| 20 |
ZEILER M D, KRISHNAN D, TAYLOR G W, et al. Deconvolutional networks [C]// IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Francisco: IEEE, 2010: 2528-2535.
|
| 21 |
ANDRILUKA M, PISHCHULIN L, GEHLER P, et al. 2D human pose estimation: new benchmark and state of the art analysis [C]// IEEE Conference on Computer Vision and Pattern Recognition. Columbus: IEEE, 2014: 3686-3693.
|
| 22 |
LIN T, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context [C]// European Conference on Computer Vision. Zurich: Springer, 2014: 740-755.
|
| 23 |
ZHANG K, HE P, YAO P, et al. Learning enhanced resolution-wise features for human pose estimation [C]// IEEE International Conference on Image Processing. Abu Dhabi: IEEE, 2020: 2256-2260.
|
| 24 |
YUAN Y, FU R, HUANG L, et al. HRFormer: high-resolution transformer for dense prediction [C]// Neural Information Processing Systems. Vancouver: MIT Press, 2021.
|
| 25 |
WANG K, LI C, REN R. High-resolution with global context network for human pose estimation [C]// Asia Pacific Conference on Communications. Jeju Island: IEEE, 2022: 621-626.
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|