[1]
REIS E S, SEEWALD L A, ANTUNES R S, et al Monocular multi-person pose estimation: a survey
[J]. Pattern Recognition , 2021 , 118 : 108046
[本文引用: 1]
[2]
NEWELL A, YANG K, DENG J. Stacked hourglass networks for human pose estimation [C]// European Conference on Computer Vision . Amsterdam: Springer, 2016: 483–499.
[本文引用: 2]
[3]
CHEN Y, WANG Z, PENG Y, et al. Cascaded pyramid network for multi-person pose estimation [C]// IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 7103–7112.
[本文引用: 5]
[4]
XIAO B, WU H, WEI Y. Simple baselines for human pose estimation and tracking [C]// European Conference on Computer Vision . Munich: Springer, 2018: 472–487.
[本文引用: 5]
[5]
SUN K, XIAO B, LIU D, et al. Deep high-resolution representation learning for human pose estimation [C]// IEEE Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 5686–5696.
[本文引用: 9]
[6]
SANDLER M, HOWARD A, ZHU M, et al. MobileNetV2: inverted residuals and linear bottlenecks [C]// IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 4510-4520.
[本文引用: 1]
[7]
ZHANG X, ZHOU X, LIN M, et al. ShuffleNet: an extremely efficient convolutional neural network for mobile devices [C]// IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 6848-6856.
[本文引用: 1]
[8]
QIAO S, CHEN L C, YUILLE A. DetectoRS: detecting objects with recursive feature pyramid and switchable atrous convolution [C]// IEEE Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 10208-10219.
[本文引用: 1]
[9]
LIN T Y, DOLLAR P, GIRSHICK R, et al Feature pyramid networks for object detection
[J]. IEEE Computer Society , 2017 , 1 : 936 - 944
[本文引用: 1]
[10]
SU H, JAMPANI V, SUN D, et al. Pixel-adaptive convolutional neural networks [C]// IEEE Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 11158-11167.
[本文引用: 1]
[11]
CHEN Y, DAI X, LIU M, et al. Dynamic convolution: attention over convolution kernels [C]// IEEE Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 11027-11036.
[本文引用: 1]
[12]
WANG Q, WU B, ZHU P, et al. ECA-Net: efficient channel attention for deep convolutional neural networks [C]// IEEE Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 11531-11539.
[本文引用: 1]
[13]
LI X, WANG W, HU X, et al. Selective kernel networks [C]// IEEE Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 510-519.
[本文引用: 1]
[14]
RAJAMANI K, GOWDA S D, TEJ V N, et al. Deformable attention (DANet) for semantic image segmentation [C]// Annual International Conference of the IEEE Engineering in Medicine and Biology Society . Glasgow: IEEE, 2022: 3781-3784.
[本文引用: 1]
[15]
刘勇. 基于关键点检测的目标二维姿态估计研究[D]. 成都: 中国科学院光电技术研究所, 2021.
[本文引用: 1]
LIU Yong. Research on two-dimensional object pose estimation based on key-point detection [D]. Chengdu: Institute of Optics and Electronics, Chinese Academy of Sciences, 2021.
[本文引用: 1]
[16]
LIU Z, MAO H, WU C Y, et al. A Convnet for the 2020s [C]// IEEE Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 11966-11976.
[本文引用: 1]
[17]
CHEN J, HE T, ZHUO W, et al. TVConv: efficient translation variant convolution for layout-aware visual processing [C]// IEEE Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 12538-12548.
[本文引用: 1]
[18]
CAO Y, XU J, LIN S, et al. GCNet: non-local networks meet squeeze-excitation networks and beyond [C]// IEEE International Conference on Computer Vision Workshop . Seoul: IEEE, 2019: 1971-1980.
[本文引用: 1]
[19]
DIND X, GUO Y, DING G, et al. ACNet: strengthening the kernel skeletons for powerful CNN via asymmetric convolution blocks [C]// IEEE International Conference on Computer Vision . Seoul: IEEE, 2019: 1911-1920.
[本文引用: 1]
[20]
ZEILER M D, KRISHNAN D, TAYLOR G W, et al. Deconvolutional networks [C]// IEEE Computer Society Conference on Computer Vision and Pattern Recognition . San Francisco: IEEE, 2010: 2528-2535.
[本文引用: 1]
[21]
ANDRILUKA M, PISHCHULIN L, GEHLER P, et al. 2D human pose estimation: new benchmark and state of the art analysis [C]// IEEE Conference on Computer Vision and Pattern Recognition . Columbus: IEEE, 2014: 3686-3693.
[本文引用: 1]
[22]
LIN T, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context [C]// European Conference on Computer Vision . Zurich: Springer, 2014: 740-755.
[本文引用: 1]
[23]
ZHANG K, HE P, YAO P, et al. Learning enhanced resolution-wise features for human pose estimation [C]// IEEE International Conference on Image Processing . Abu Dhabi: IEEE, 2020: 2256-2260.
[本文引用: 8]
[24]
YUAN Y, FU R, HUANG L, et al. HRFormer: high-resolution transformer for dense prediction [C]// Neural Information Processing Systems . Vancouver: MIT Press, 2021.
[本文引用: 5]
[25]
WANG K, LI C, REN R. High-resolution with global context network for human pose estimation [C]// Asia Pacific Conference on Communications . Jeju Island: IEEE, 2022: 621-626.
[本文引用: 8]
[26]
TRAN T D, VO X T, NGUYEN D L, et al. High-resolution network with attention module for human pose estimation [C]// Asian Control Conference . Jeju Island: IEEE, 2022: 459-464.
[本文引用: 3]
Monocular multi-person pose estimation: a survey
1
2021
... 在计算机视觉领域,二维人体姿态估计一直是重要且极具挑战性的问题,具有广泛的应用场景,例如人体动作识别、人机交互、虚拟现实、视频监控、人体轨迹跟踪等[1 ] . 由于人体关节的复杂性、高度灵活性和不同质量图像、视频中人体部分的完整性、差异性等因素,在基于视觉的运动姿势、乐器演奏姿势捕捉矫正、虚拟人动作生成、外骨骼机器人中人体运动数据获取等应用场景中,人体关键点检测仍然难以满足高精度的需求. ...
2
... 随着卷积神经网络的迅速发展,人体姿态估计取得了巨大进展. 研究人员提出了许多经典模型,旨在解决如何从图像中提取不同阶段的多尺度特征以及如何高效地融合语义、通道、空间信息等问题. Newell等[2 ] 利用多个基础沙漏模型提取多尺度特征,以关注人体图像的空间信息,但受网络深度的制约,模型精度有待提升. Chen等[3 ] 基于特征金字塔结构,提出两阶段网络,融合了多尺度特征信息,可以分别检测容易与困难2种关键点. Xiao等[4 ] 首次提出单阶段姿态估计网络,采用编解码的方式,简单、有效地识别关键点,但是网络参数量较大,计算效率不高. Sun等[5 ] 提出高分辨率网络(high-resolution network,HRNet),能够保持原始图像的空间位置信息,通过多尺寸特征融合增强对关键点的识别能力. ...
... Comparison results of average precision and average recall for different networks on COCO validation set
Tab.4 方法 预训练 输入图像尺寸 N p /106 FLOPs/109 AP/% AP0.5 /% AP0.75 /% APM /% APL /% AR/% 8-stage Hourglass[2 ] N 256×192 25.1 14.3 66.9 — — — — — CPN50[3 ] Y 256×192 27.0 6.2 68.6 — — — — — Simple Baseline152[4 ] Y 256×192 68.6 15.7 72.0 89.3 79.8 68.7 78.9 77.8 HRNet(W32)[5 ] Y 256×192 28.5 7.1 74.4 90.5 81.9 70.8 81.0 79.8 HRNet(W48)[5 ] Y 256×192 63.6 14.6 75.1 90.6 82.2 71.5 81.8 80.4 RAM-GPRNet(W32)[23 ] Y 256×192 31.4 7.7 76.0 — — — — — RAM-GPRNet(W48)[23 ] Y 256×192 70.0 15.8 76.5 — — — — — HRFormer-B[24 ] Y 256×192 43.2 12.2 75.6 90.8 82.8 71.7 82.6 80.8 HRGCNet(W32)[25 ] Y 256×192 29.6 7.11 76.6 93.6 84.6 73.9 80.7 79.3 HRGCNet(W48)[25 ] Y 256×192 64.6 14.6 77.4 93.6 84.8 74.6 81.7 80.1 AMHRNet(W32)[26 ] — 256×192 36.4 — 76.1 91.0 82.7 71.5 82.9 81.2 AMHRNet(W48)[26 ] — 256×192 71.8 — 76.4 91.1 83.1 72.2 83.3 81.4 本文方法(W32) Y 256×192 21.1 6.3 76.7 93.6 84.8 73.3 81.8 80.7 本文方法(W48) Y 256×192 46.2 12.3 77.4 93.7 85.0 74.4 82.3 81.4 CPN50[3 ] Y 384×288 — 13.9 70.6 — — — — — Simple Baseline152[4 ] Y 384×288 68.6 35.3 74.3 89.6 81.1 70.5 81.6 79.7 HRNet(W32)[5 ] Y 384×288 28.5 16.0 75.8 90.6 82.5 72.0 82.7 80.9 HRNet(W48)[5 ] Y 384×288 63.6 32.9 76.3 90.8 82.9 72.3 83.4 81.2 RAM-GPRNet(W32)[23 ] Y 384×288 31.4 17.2 77.3 — — — — — RAM-GPRNet(W48)[23 ] Y 384×288 70.0 35.6 77.7 — — — — — HRFormer-B[24 ] Y 384×288 43.2 26.8 77.2 91.0 83.6 73.2 84.2 82.0 HRGCNet(W32)[25 ] Y 384×288 29.6 16.1 78.0 93.6 84.8 75.0 82.6 80.5 HRGCNet(W48)[25 ] Y 384×288 64.6 32.9 78.4 93.6 85.8 75.3 83.5 81.3 本文方法(W32) Y 384×288 21.1 14.8 78.2 93.7 85.0 75.4 82.9 81.2 本文方法(W48) Y 384×288 46.2 28.5 78.5 93.7 85.8 75.5 83.7 81.9
表 5 在COCO测试集上不同网络的平均精度和平均召回率对比结果 ...
5
... 随着卷积神经网络的迅速发展,人体姿态估计取得了巨大进展. 研究人员提出了许多经典模型,旨在解决如何从图像中提取不同阶段的多尺度特征以及如何高效地融合语义、通道、空间信息等问题. Newell等[2 ] 利用多个基础沙漏模型提取多尺度特征,以关注人体图像的空间信息,但受网络深度的制约,模型精度有待提升. Chen等[3 ] 基于特征金字塔结构,提出两阶段网络,融合了多尺度特征信息,可以分别检测容易与困难2种关键点. Xiao等[4 ] 首次提出单阶段姿态估计网络,采用编解码的方式,简单、有效地识别关键点,但是网络参数量较大,计算效率不高. Sun等[5 ] 提出高分辨率网络(high-resolution network,HRNet),能够保持原始图像的空间位置信息,通过多尺寸特征融合增强对关键点的识别能力. ...
... Comparison results of average precision and average recall for different networks on COCO validation set
Tab.4 方法 预训练 输入图像尺寸 N p /106 FLOPs/109 AP/% AP0.5 /% AP0.75 /% APM /% APL /% AR/% 8-stage Hourglass[2 ] N 256×192 25.1 14.3 66.9 — — — — — CPN50[3 ] Y 256×192 27.0 6.2 68.6 — — — — — Simple Baseline152[4 ] Y 256×192 68.6 15.7 72.0 89.3 79.8 68.7 78.9 77.8 HRNet(W32)[5 ] Y 256×192 28.5 7.1 74.4 90.5 81.9 70.8 81.0 79.8 HRNet(W48)[5 ] Y 256×192 63.6 14.6 75.1 90.6 82.2 71.5 81.8 80.4 RAM-GPRNet(W32)[23 ] Y 256×192 31.4 7.7 76.0 — — — — — RAM-GPRNet(W48)[23 ] Y 256×192 70.0 15.8 76.5 — — — — — HRFormer-B[24 ] Y 256×192 43.2 12.2 75.6 90.8 82.8 71.7 82.6 80.8 HRGCNet(W32)[25 ] Y 256×192 29.6 7.11 76.6 93.6 84.6 73.9 80.7 79.3 HRGCNet(W48)[25 ] Y 256×192 64.6 14.6 77.4 93.6 84.8 74.6 81.7 80.1 AMHRNet(W32)[26 ] — 256×192 36.4 — 76.1 91.0 82.7 71.5 82.9 81.2 AMHRNet(W48)[26 ] — 256×192 71.8 — 76.4 91.1 83.1 72.2 83.3 81.4 本文方法(W32) Y 256×192 21.1 6.3 76.7 93.6 84.8 73.3 81.8 80.7 本文方法(W48) Y 256×192 46.2 12.3 77.4 93.7 85.0 74.4 82.3 81.4 CPN50[3 ] Y 384×288 — 13.9 70.6 — — — — — Simple Baseline152[4 ] Y 384×288 68.6 35.3 74.3 89.6 81.1 70.5 81.6 79.7 HRNet(W32)[5 ] Y 384×288 28.5 16.0 75.8 90.6 82.5 72.0 82.7 80.9 HRNet(W48)[5 ] Y 384×288 63.6 32.9 76.3 90.8 82.9 72.3 83.4 81.2 RAM-GPRNet(W32)[23 ] Y 384×288 31.4 17.2 77.3 — — — — — RAM-GPRNet(W48)[23 ] Y 384×288 70.0 35.6 77.7 — — — — — HRFormer-B[24 ] Y 384×288 43.2 26.8 77.2 91.0 83.6 73.2 84.2 82.0 HRGCNet(W32)[25 ] Y 384×288 29.6 16.1 78.0 93.6 84.8 75.0 82.6 80.5 HRGCNet(W48)[25 ] Y 384×288 64.6 32.9 78.4 93.6 85.8 75.3 83.5 81.3 本文方法(W32) Y 384×288 21.1 14.8 78.2 93.7 85.0 75.4 82.9 81.2 本文方法(W48) Y 384×288 46.2 28.5 78.5 93.7 85.8 75.5 83.7 81.9
表 5 在COCO测试集上不同网络的平均精度和平均召回率对比结果 ...
... [
3 ]
Y 384×288 — 13.9 70.6 — — — — — Simple Baseline152[4 ] Y 384×288 68.6 35.3 74.3 89.6 81.1 70.5 81.6 79.7 HRNet(W32)[5 ] Y 384×288 28.5 16.0 75.8 90.6 82.5 72.0 82.7 80.9 HRNet(W48)[5 ] Y 384×288 63.6 32.9 76.3 90.8 82.9 72.3 83.4 81.2 RAM-GPRNet(W32)[23 ] Y 384×288 31.4 17.2 77.3 — — — — — RAM-GPRNet(W48)[23 ] Y 384×288 70.0 35.6 77.7 — — — — — HRFormer-B[24 ] Y 384×288 43.2 26.8 77.2 91.0 83.6 73.2 84.2 82.0 HRGCNet(W32)[25 ] Y 384×288 29.6 16.1 78.0 93.6 84.8 75.0 82.6 80.5 HRGCNet(W48)[25 ] Y 384×288 64.6 32.9 78.4 93.6 85.8 75.3 83.5 81.3 本文方法(W32) Y 384×288 21.1 14.8 78.2 93.7 85.0 75.4 82.9 81.2 本文方法(W48) Y 384×288 46.2 28.5 78.5 93.7 85.8 75.5 83.7 81.9 表 5 在COCO测试集上不同网络的平均精度和平均召回率对比结果 ...
... Comparison results of average precision and average recall for different networks on COCO test set
Tab.5 方法 预训练 输入图像尺寸 N p /106 FLOPs/109 AP/% AP0.5 /% AP0.75 /% APM /% APL /% AR/% CPN50[3 ] — 384×288 — — 72.6 86.1 69.7 78.3 64.1 — Simple Baseline152[4 ] Y 256×192 68.6 15.7 71.6 91.2 80.1 68.7 77.2 77.3 HRNet(W32)[5 ] Y 384×288 28.5 16.0 74.9 92.5 82.8 71.3 80.9 80.1 HRNet(W48)[5 ] Y 384×288 63.6 32.9 75.5 92.5 83.3 71.9 81.5 80.5 RAM-GPRNet(W32)[23 ] Y 384×288 31.4 17.2 76.5 — — — — — RAM-GPRNet(W48)[23 ] Y 384×288 70.0 35.6 77.0 — — — — — HRFormer-B[24 ] Y 384×288 43.2 26.8 76.2 92.7 83.8 72.5 82.3 81.2 HRGCNet(W32)[25 ] Y 384×288 29.6 16.1 77.9 93.6 84.8 74.8 82.9 80.6 HRGCNet(W48)[25 ] Y 384×288 64.6 32.9 78.3 93.6 85.7 75.3 83.5 81.2 本文方法(W32) Y 384×288 21.1 14.8 78.1 93.6 85.0 75.2 83.1 81.2 本文方法(W48) Y 384×288 46.2 28.5 78.4 93.7 85.5 75.5 83.6 81.7
在COCO验证集上进行对比,当输入图像大小为256×192时,提出的网络(W32)AP值达到76.7%,优于其他具有相同输入的方法. 与HRNet[5 ] 相比,AP值大幅度提高且运算量降低;与RAM-GPRNet[23 ] 相比,AP值提高了0.7%和0.9%;与HRFormer-B[24 ] 相比,实现了0.9%的AP增益;与HRGCNet[25 ] 相比,虽然AP值相近,但参数量和运算量更低;与AMHRNet[26 ] 相比,AP值有0.6%和1.0%的提升,且参数量约为其58%和65%. 当输入图像大小为384×288时,提出的网络获得了78.2%和78.5%的AP值. 与CPN[3 ] 、SimpleBaseline[4 ] 、HRNet[5 ] 、RAM-GPRNet[23 ] 、HRFormer-B[24 ] 、HRGCNet[25 ] 相比,本网络在主要的性能指标上均得到了有效的提升,实现了初步轻量化,减少了参数量和运算量. 综合而言,本文模型在估计精度上优于多数网络,关键点的识别效果较好,且在参数量和运算量方面有所降低. ...
... 在COCO验证集上进行对比,当输入图像大小为256×192时,提出的网络(W32)AP值达到76.7%,优于其他具有相同输入的方法. 与HRNet[5 ] 相比,AP值大幅度提高且运算量降低;与RAM-GPRNet[23 ] 相比,AP值提高了0.7%和0.9%;与HRFormer-B[24 ] 相比,实现了0.9%的AP增益;与HRGCNet[25 ] 相比,虽然AP值相近,但参数量和运算量更低;与AMHRNet[26 ] 相比,AP值有0.6%和1.0%的提升,且参数量约为其58%和65%. 当输入图像大小为384×288时,提出的网络获得了78.2%和78.5%的AP值. 与CPN[3 ] 、SimpleBaseline[4 ] 、HRNet[5 ] 、RAM-GPRNet[23 ] 、HRFormer-B[24 ] 、HRGCNet[25 ] 相比,本网络在主要的性能指标上均得到了有效的提升,实现了初步轻量化,减少了参数量和运算量. 综合而言,本文模型在估计精度上优于多数网络,关键点的识别效果较好,且在参数量和运算量方面有所降低. ...
5
... 随着卷积神经网络的迅速发展,人体姿态估计取得了巨大进展. 研究人员提出了许多经典模型,旨在解决如何从图像中提取不同阶段的多尺度特征以及如何高效地融合语义、通道、空间信息等问题. Newell等[2 ] 利用多个基础沙漏模型提取多尺度特征,以关注人体图像的空间信息,但受网络深度的制约,模型精度有待提升. Chen等[3 ] 基于特征金字塔结构,提出两阶段网络,融合了多尺度特征信息,可以分别检测容易与困难2种关键点. Xiao等[4 ] 首次提出单阶段姿态估计网络,采用编解码的方式,简单、有效地识别关键点,但是网络参数量较大,计算效率不高. Sun等[5 ] 提出高分辨率网络(high-resolution network,HRNet),能够保持原始图像的空间位置信息,通过多尺寸特征融合增强对关键点的识别能力. ...
... Comparison results of average precision and average recall for different networks on COCO validation set
Tab.4 方法 预训练 输入图像尺寸 N p /106 FLOPs/109 AP/% AP0.5 /% AP0.75 /% APM /% APL /% AR/% 8-stage Hourglass[2 ] N 256×192 25.1 14.3 66.9 — — — — — CPN50[3 ] Y 256×192 27.0 6.2 68.6 — — — — — Simple Baseline152[4 ] Y 256×192 68.6 15.7 72.0 89.3 79.8 68.7 78.9 77.8 HRNet(W32)[5 ] Y 256×192 28.5 7.1 74.4 90.5 81.9 70.8 81.0 79.8 HRNet(W48)[5 ] Y 256×192 63.6 14.6 75.1 90.6 82.2 71.5 81.8 80.4 RAM-GPRNet(W32)[23 ] Y 256×192 31.4 7.7 76.0 — — — — — RAM-GPRNet(W48)[23 ] Y 256×192 70.0 15.8 76.5 — — — — — HRFormer-B[24 ] Y 256×192 43.2 12.2 75.6 90.8 82.8 71.7 82.6 80.8 HRGCNet(W32)[25 ] Y 256×192 29.6 7.11 76.6 93.6 84.6 73.9 80.7 79.3 HRGCNet(W48)[25 ] Y 256×192 64.6 14.6 77.4 93.6 84.8 74.6 81.7 80.1 AMHRNet(W32)[26 ] — 256×192 36.4 — 76.1 91.0 82.7 71.5 82.9 81.2 AMHRNet(W48)[26 ] — 256×192 71.8 — 76.4 91.1 83.1 72.2 83.3 81.4 本文方法(W32) Y 256×192 21.1 6.3 76.7 93.6 84.8 73.3 81.8 80.7 本文方法(W48) Y 256×192 46.2 12.3 77.4 93.7 85.0 74.4 82.3 81.4 CPN50[3 ] Y 384×288 — 13.9 70.6 — — — — — Simple Baseline152[4 ] Y 384×288 68.6 35.3 74.3 89.6 81.1 70.5 81.6 79.7 HRNet(W32)[5 ] Y 384×288 28.5 16.0 75.8 90.6 82.5 72.0 82.7 80.9 HRNet(W48)[5 ] Y 384×288 63.6 32.9 76.3 90.8 82.9 72.3 83.4 81.2 RAM-GPRNet(W32)[23 ] Y 384×288 31.4 17.2 77.3 — — — — — RAM-GPRNet(W48)[23 ] Y 384×288 70.0 35.6 77.7 — — — — — HRFormer-B[24 ] Y 384×288 43.2 26.8 77.2 91.0 83.6 73.2 84.2 82.0 HRGCNet(W32)[25 ] Y 384×288 29.6 16.1 78.0 93.6 84.8 75.0 82.6 80.5 HRGCNet(W48)[25 ] Y 384×288 64.6 32.9 78.4 93.6 85.8 75.3 83.5 81.3 本文方法(W32) Y 384×288 21.1 14.8 78.2 93.7 85.0 75.4 82.9 81.2 本文方法(W48) Y 384×288 46.2 28.5 78.5 93.7 85.8 75.5 83.7 81.9
表 5 在COCO测试集上不同网络的平均精度和平均召回率对比结果 ...
... [
4 ]
Y 384×288 68.6 35.3 74.3 89.6 81.1 70.5 81.6 79.7 HRNet(W32)[5 ] Y 384×288 28.5 16.0 75.8 90.6 82.5 72.0 82.7 80.9 HRNet(W48)[5 ] Y 384×288 63.6 32.9 76.3 90.8 82.9 72.3 83.4 81.2 RAM-GPRNet(W32)[23 ] Y 384×288 31.4 17.2 77.3 — — — — — RAM-GPRNet(W48)[23 ] Y 384×288 70.0 35.6 77.7 — — — — — HRFormer-B[24 ] Y 384×288 43.2 26.8 77.2 91.0 83.6 73.2 84.2 82.0 HRGCNet(W32)[25 ] Y 384×288 29.6 16.1 78.0 93.6 84.8 75.0 82.6 80.5 HRGCNet(W48)[25 ] Y 384×288 64.6 32.9 78.4 93.6 85.8 75.3 83.5 81.3 本文方法(W32) Y 384×288 21.1 14.8 78.2 93.7 85.0 75.4 82.9 81.2 本文方法(W48) Y 384×288 46.2 28.5 78.5 93.7 85.8 75.5 83.7 81.9 表 5 在COCO测试集上不同网络的平均精度和平均召回率对比结果 ...
... Comparison results of average precision and average recall for different networks on COCO test set
Tab.5 方法 预训练 输入图像尺寸 N p /106 FLOPs/109 AP/% AP0.5 /% AP0.75 /% APM /% APL /% AR/% CPN50[3 ] — 384×288 — — 72.6 86.1 69.7 78.3 64.1 — Simple Baseline152[4 ] Y 256×192 68.6 15.7 71.6 91.2 80.1 68.7 77.2 77.3 HRNet(W32)[5 ] Y 384×288 28.5 16.0 74.9 92.5 82.8 71.3 80.9 80.1 HRNet(W48)[5 ] Y 384×288 63.6 32.9 75.5 92.5 83.3 71.9 81.5 80.5 RAM-GPRNet(W32)[23 ] Y 384×288 31.4 17.2 76.5 — — — — — RAM-GPRNet(W48)[23 ] Y 384×288 70.0 35.6 77.0 — — — — — HRFormer-B[24 ] Y 384×288 43.2 26.8 76.2 92.7 83.8 72.5 82.3 81.2 HRGCNet(W32)[25 ] Y 384×288 29.6 16.1 77.9 93.6 84.8 74.8 82.9 80.6 HRGCNet(W48)[25 ] Y 384×288 64.6 32.9 78.3 93.6 85.7 75.3 83.5 81.2 本文方法(W32) Y 384×288 21.1 14.8 78.1 93.6 85.0 75.2 83.1 81.2 本文方法(W48) Y 384×288 46.2 28.5 78.4 93.7 85.5 75.5 83.6 81.7
在COCO验证集上进行对比,当输入图像大小为256×192时,提出的网络(W32)AP值达到76.7%,优于其他具有相同输入的方法. 与HRNet[5 ] 相比,AP值大幅度提高且运算量降低;与RAM-GPRNet[23 ] 相比,AP值提高了0.7%和0.9%;与HRFormer-B[24 ] 相比,实现了0.9%的AP增益;与HRGCNet[25 ] 相比,虽然AP值相近,但参数量和运算量更低;与AMHRNet[26 ] 相比,AP值有0.6%和1.0%的提升,且参数量约为其58%和65%. 当输入图像大小为384×288时,提出的网络获得了78.2%和78.5%的AP值. 与CPN[3 ] 、SimpleBaseline[4 ] 、HRNet[5 ] 、RAM-GPRNet[23 ] 、HRFormer-B[24 ] 、HRGCNet[25 ] 相比,本网络在主要的性能指标上均得到了有效的提升,实现了初步轻量化,减少了参数量和运算量. 综合而言,本文模型在估计精度上优于多数网络,关键点的识别效果较好,且在参数量和运算量方面有所降低. ...
... 在COCO验证集上进行对比,当输入图像大小为256×192时,提出的网络(W32)AP值达到76.7%,优于其他具有相同输入的方法. 与HRNet[5 ] 相比,AP值大幅度提高且运算量降低;与RAM-GPRNet[23 ] 相比,AP值提高了0.7%和0.9%;与HRFormer-B[24 ] 相比,实现了0.9%的AP增益;与HRGCNet[25 ] 相比,虽然AP值相近,但参数量和运算量更低;与AMHRNet[26 ] 相比,AP值有0.6%和1.0%的提升,且参数量约为其58%和65%. 当输入图像大小为384×288时,提出的网络获得了78.2%和78.5%的AP值. 与CPN[3 ] 、SimpleBaseline[4 ] 、HRNet[5 ] 、RAM-GPRNet[23 ] 、HRFormer-B[24 ] 、HRGCNet[25 ] 相比,本网络在主要的性能指标上均得到了有效的提升,实现了初步轻量化,减少了参数量和运算量. 综合而言,本文模型在估计精度上优于多数网络,关键点的识别效果较好,且在参数量和运算量方面有所降低. ...
9
... 随着卷积神经网络的迅速发展,人体姿态估计取得了巨大进展. 研究人员提出了许多经典模型,旨在解决如何从图像中提取不同阶段的多尺度特征以及如何高效地融合语义、通道、空间信息等问题. Newell等[2 ] 利用多个基础沙漏模型提取多尺度特征,以关注人体图像的空间信息,但受网络深度的制约,模型精度有待提升. Chen等[3 ] 基于特征金字塔结构,提出两阶段网络,融合了多尺度特征信息,可以分别检测容易与困难2种关键点. Xiao等[4 ] 首次提出单阶段姿态估计网络,采用编解码的方式,简单、有效地识别关键点,但是网络参数量较大,计算效率不高. Sun等[5 ] 提出高分辨率网络(high-resolution network,HRNet),能够保持原始图像的空间位置信息,通过多尺寸特征融合增强对关键点的识别能力. ...
... Comparison results of average precision and average recall for different networks on COCO validation set
Tab.4 方法 预训练 输入图像尺寸 N p /106 FLOPs/109 AP/% AP0.5 /% AP0.75 /% APM /% APL /% AR/% 8-stage Hourglass[2 ] N 256×192 25.1 14.3 66.9 — — — — — CPN50[3 ] Y 256×192 27.0 6.2 68.6 — — — — — Simple Baseline152[4 ] Y 256×192 68.6 15.7 72.0 89.3 79.8 68.7 78.9 77.8 HRNet(W32)[5 ] Y 256×192 28.5 7.1 74.4 90.5 81.9 70.8 81.0 79.8 HRNet(W48)[5 ] Y 256×192 63.6 14.6 75.1 90.6 82.2 71.5 81.8 80.4 RAM-GPRNet(W32)[23 ] Y 256×192 31.4 7.7 76.0 — — — — — RAM-GPRNet(W48)[23 ] Y 256×192 70.0 15.8 76.5 — — — — — HRFormer-B[24 ] Y 256×192 43.2 12.2 75.6 90.8 82.8 71.7 82.6 80.8 HRGCNet(W32)[25 ] Y 256×192 29.6 7.11 76.6 93.6 84.6 73.9 80.7 79.3 HRGCNet(W48)[25 ] Y 256×192 64.6 14.6 77.4 93.6 84.8 74.6 81.7 80.1 AMHRNet(W32)[26 ] — 256×192 36.4 — 76.1 91.0 82.7 71.5 82.9 81.2 AMHRNet(W48)[26 ] — 256×192 71.8 — 76.4 91.1 83.1 72.2 83.3 81.4 本文方法(W32) Y 256×192 21.1 6.3 76.7 93.6 84.8 73.3 81.8 80.7 本文方法(W48) Y 256×192 46.2 12.3 77.4 93.7 85.0 74.4 82.3 81.4 CPN50[3 ] Y 384×288 — 13.9 70.6 — — — — — Simple Baseline152[4 ] Y 384×288 68.6 35.3 74.3 89.6 81.1 70.5 81.6 79.7 HRNet(W32)[5 ] Y 384×288 28.5 16.0 75.8 90.6 82.5 72.0 82.7 80.9 HRNet(W48)[5 ] Y 384×288 63.6 32.9 76.3 90.8 82.9 72.3 83.4 81.2 RAM-GPRNet(W32)[23 ] Y 384×288 31.4 17.2 77.3 — — — — — RAM-GPRNet(W48)[23 ] Y 384×288 70.0 35.6 77.7 — — — — — HRFormer-B[24 ] Y 384×288 43.2 26.8 77.2 91.0 83.6 73.2 84.2 82.0 HRGCNet(W32)[25 ] Y 384×288 29.6 16.1 78.0 93.6 84.8 75.0 82.6 80.5 HRGCNet(W48)[25 ] Y 384×288 64.6 32.9 78.4 93.6 85.8 75.3 83.5 81.3 本文方法(W32) Y 384×288 21.1 14.8 78.2 93.7 85.0 75.4 82.9 81.2 本文方法(W48) Y 384×288 46.2 28.5 78.5 93.7 85.8 75.5 83.7 81.9
表 5 在COCO测试集上不同网络的平均精度和平均召回率对比结果 ...
... [
5 ]
Y 256×192 63.6 14.6 75.1 90.6 82.2 71.5 81.8 80.4 RAM-GPRNet(W32)[23 ] Y 256×192 31.4 7.7 76.0 — — — — — RAM-GPRNet(W48)[23 ] Y 256×192 70.0 15.8 76.5 — — — — — HRFormer-B[24 ] Y 256×192 43.2 12.2 75.6 90.8 82.8 71.7 82.6 80.8 HRGCNet(W32)[25 ] Y 256×192 29.6 7.11 76.6 93.6 84.6 73.9 80.7 79.3 HRGCNet(W48)[25 ] Y 256×192 64.6 14.6 77.4 93.6 84.8 74.6 81.7 80.1 AMHRNet(W32)[26 ] — 256×192 36.4 — 76.1 91.0 82.7 71.5 82.9 81.2 AMHRNet(W48)[26 ] — 256×192 71.8 — 76.4 91.1 83.1 72.2 83.3 81.4 本文方法(W32) Y 256×192 21.1 6.3 76.7 93.6 84.8 73.3 81.8 80.7 本文方法(W48) Y 256×192 46.2 12.3 77.4 93.7 85.0 74.4 82.3 81.4 CPN50[3 ] Y 384×288 — 13.9 70.6 — — — — — Simple Baseline152[4 ] Y 384×288 68.6 35.3 74.3 89.6 81.1 70.5 81.6 79.7 HRNet(W32)[5 ] Y 384×288 28.5 16.0 75.8 90.6 82.5 72.0 82.7 80.9 HRNet(W48)[5 ] Y 384×288 63.6 32.9 76.3 90.8 82.9 72.3 83.4 81.2 RAM-GPRNet(W32)[23 ] Y 384×288 31.4 17.2 77.3 — — — — — RAM-GPRNet(W48)[23 ] Y 384×288 70.0 35.6 77.7 — — — — — HRFormer-B[24 ] Y 384×288 43.2 26.8 77.2 91.0 83.6 73.2 84.2 82.0 HRGCNet(W32)[25 ] Y 384×288 29.6 16.1 78.0 93.6 84.8 75.0 82.6 80.5 HRGCNet(W48)[25 ] Y 384×288 64.6 32.9 78.4 93.6 85.8 75.3 83.5 81.3 本文方法(W32) Y 384×288 21.1 14.8 78.2 93.7 85.0 75.4 82.9 81.2 本文方法(W48) Y 384×288 46.2 28.5 78.5 93.7 85.8 75.5 83.7 81.9 表 5 在COCO测试集上不同网络的平均精度和平均召回率对比结果 ...
... [
5 ]
Y 384×288 28.5 16.0 75.8 90.6 82.5 72.0 82.7 80.9 HRNet(W48)[5 ] Y 384×288 63.6 32.9 76.3 90.8 82.9 72.3 83.4 81.2 RAM-GPRNet(W32)[23 ] Y 384×288 31.4 17.2 77.3 — — — — — RAM-GPRNet(W48)[23 ] Y 384×288 70.0 35.6 77.7 — — — — — HRFormer-B[24 ] Y 384×288 43.2 26.8 77.2 91.0 83.6 73.2 84.2 82.0 HRGCNet(W32)[25 ] Y 384×288 29.6 16.1 78.0 93.6 84.8 75.0 82.6 80.5 HRGCNet(W48)[25 ] Y 384×288 64.6 32.9 78.4 93.6 85.8 75.3 83.5 81.3 本文方法(W32) Y 384×288 21.1 14.8 78.2 93.7 85.0 75.4 82.9 81.2 本文方法(W48) Y 384×288 46.2 28.5 78.5 93.7 85.8 75.5 83.7 81.9 表 5 在COCO测试集上不同网络的平均精度和平均召回率对比结果 ...
... [
5 ]
Y 384×288 63.6 32.9 76.3 90.8 82.9 72.3 83.4 81.2 RAM-GPRNet(W32)[23 ] Y 384×288 31.4 17.2 77.3 — — — — — RAM-GPRNet(W48)[23 ] Y 384×288 70.0 35.6 77.7 — — — — — HRFormer-B[24 ] Y 384×288 43.2 26.8 77.2 91.0 83.6 73.2 84.2 82.0 HRGCNet(W32)[25 ] Y 384×288 29.6 16.1 78.0 93.6 84.8 75.0 82.6 80.5 HRGCNet(W48)[25 ] Y 384×288 64.6 32.9 78.4 93.6 85.8 75.3 83.5 81.3 本文方法(W32) Y 384×288 21.1 14.8 78.2 93.7 85.0 75.4 82.9 81.2 本文方法(W48) Y 384×288 46.2 28.5 78.5 93.7 85.8 75.5 83.7 81.9 表 5 在COCO测试集上不同网络的平均精度和平均召回率对比结果 ...
... Comparison results of average precision and average recall for different networks on COCO test set
Tab.5 方法 预训练 输入图像尺寸 N p /106 FLOPs/109 AP/% AP0.5 /% AP0.75 /% APM /% APL /% AR/% CPN50[3 ] — 384×288 — — 72.6 86.1 69.7 78.3 64.1 — Simple Baseline152[4 ] Y 256×192 68.6 15.7 71.6 91.2 80.1 68.7 77.2 77.3 HRNet(W32)[5 ] Y 384×288 28.5 16.0 74.9 92.5 82.8 71.3 80.9 80.1 HRNet(W48)[5 ] Y 384×288 63.6 32.9 75.5 92.5 83.3 71.9 81.5 80.5 RAM-GPRNet(W32)[23 ] Y 384×288 31.4 17.2 76.5 — — — — — RAM-GPRNet(W48)[23 ] Y 384×288 70.0 35.6 77.0 — — — — — HRFormer-B[24 ] Y 384×288 43.2 26.8 76.2 92.7 83.8 72.5 82.3 81.2 HRGCNet(W32)[25 ] Y 384×288 29.6 16.1 77.9 93.6 84.8 74.8 82.9 80.6 HRGCNet(W48)[25 ] Y 384×288 64.6 32.9 78.3 93.6 85.7 75.3 83.5 81.2 本文方法(W32) Y 384×288 21.1 14.8 78.1 93.6 85.0 75.2 83.1 81.2 本文方法(W48) Y 384×288 46.2 28.5 78.4 93.7 85.5 75.5 83.6 81.7
在COCO验证集上进行对比,当输入图像大小为256×192时,提出的网络(W32)AP值达到76.7%,优于其他具有相同输入的方法. 与HRNet[5 ] 相比,AP值大幅度提高且运算量降低;与RAM-GPRNet[23 ] 相比,AP值提高了0.7%和0.9%;与HRFormer-B[24 ] 相比,实现了0.9%的AP增益;与HRGCNet[25 ] 相比,虽然AP值相近,但参数量和运算量更低;与AMHRNet[26 ] 相比,AP值有0.6%和1.0%的提升,且参数量约为其58%和65%. 当输入图像大小为384×288时,提出的网络获得了78.2%和78.5%的AP值. 与CPN[3 ] 、SimpleBaseline[4 ] 、HRNet[5 ] 、RAM-GPRNet[23 ] 、HRFormer-B[24 ] 、HRGCNet[25 ] 相比,本网络在主要的性能指标上均得到了有效的提升,实现了初步轻量化,减少了参数量和运算量. 综合而言,本文模型在估计精度上优于多数网络,关键点的识别效果较好,且在参数量和运算量方面有所降低. ...
... [
5 ]
Y 384×288 63.6 32.9 75.5 92.5 83.3 71.9 81.5 80.5 RAM-GPRNet(W32)[23 ] Y 384×288 31.4 17.2 76.5 — — — — — RAM-GPRNet(W48)[23 ] Y 384×288 70.0 35.6 77.0 — — — — — HRFormer-B[24 ] Y 384×288 43.2 26.8 76.2 92.7 83.8 72.5 82.3 81.2 HRGCNet(W32)[25 ] Y 384×288 29.6 16.1 77.9 93.6 84.8 74.8 82.9 80.6 HRGCNet(W48)[25 ] Y 384×288 64.6 32.9 78.3 93.6 85.7 75.3 83.5 81.2 本文方法(W32) Y 384×288 21.1 14.8 78.1 93.6 85.0 75.2 83.1 81.2 本文方法(W48) Y 384×288 46.2 28.5 78.4 93.7 85.5 75.5 83.6 81.7 在COCO验证集上进行对比,当输入图像大小为256×192时,提出的网络(W32)AP值达到76.7%,优于其他具有相同输入的方法. 与HRNet[5 ] 相比,AP值大幅度提高且运算量降低;与RAM-GPRNet[23 ] 相比,AP值提高了0.7%和0.9%;与HRFormer-B[24 ] 相比,实现了0.9%的AP增益;与HRGCNet[25 ] 相比,虽然AP值相近,但参数量和运算量更低;与AMHRNet[26 ] 相比,AP值有0.6%和1.0%的提升,且参数量约为其58%和65%. 当输入图像大小为384×288时,提出的网络获得了78.2%和78.5%的AP值. 与CPN[3 ] 、SimpleBaseline[4 ] 、HRNet[5 ] 、RAM-GPRNet[23 ] 、HRFormer-B[24 ] 、HRGCNet[25 ] 相比,本网络在主要的性能指标上均得到了有效的提升,实现了初步轻量化,减少了参数量和运算量. 综合而言,本文模型在估计精度上优于多数网络,关键点的识别效果较好,且在参数量和运算量方面有所降低. ...
... 在COCO验证集上进行对比,当输入图像大小为256×192时,提出的网络(W32)AP值达到76.7%,优于其他具有相同输入的方法. 与HRNet[5 ] 相比,AP值大幅度提高且运算量降低;与RAM-GPRNet[23 ] 相比,AP值提高了0.7%和0.9%;与HRFormer-B[24 ] 相比,实现了0.9%的AP增益;与HRGCNet[25 ] 相比,虽然AP值相近,但参数量和运算量更低;与AMHRNet[26 ] 相比,AP值有0.6%和1.0%的提升,且参数量约为其58%和65%. 当输入图像大小为384×288时,提出的网络获得了78.2%和78.5%的AP值. 与CPN[3 ] 、SimpleBaseline[4 ] 、HRNet[5 ] 、RAM-GPRNet[23 ] 、HRFormer-B[24 ] 、HRGCNet[25 ] 相比,本网络在主要的性能指标上均得到了有效的提升,实现了初步轻量化,减少了参数量和运算量. 综合而言,本文模型在估计精度上优于多数网络,关键点的识别效果较好,且在参数量和运算量方面有所降低. ...
... [5 ]、RAM-GPRNet[23 ] 、HRFormer-B[24 ] 、HRGCNet[25 ] 相比,本网络在主要的性能指标上均得到了有效的提升,实现了初步轻量化,减少了参数量和运算量. 综合而言,本文模型在估计精度上优于多数网络,关键点的识别效果较好,且在参数量和运算量方面有所降低. ...
1
... 在计算机视觉领域中,不同的特征提取方式可以实现不同的效果. MobileNet[6 ] 使用中间大、两头小的逆瓶颈层架构,可以有效地避免特征信息流失,提取更多的特征信息. ShuffleNet[7 ] 提取图像语义特征,采用多种轻量级卷积,大幅度减少模型参数量,便于在移动设备上使用. Transformer利用自注意力机制,有效地获取全局信息,使得模型表达能力增强,结构上在编解码中融合逆瓶颈层,减少归一化和激活函数,减少训练压力. 递归金字塔[8 ] 和特征金字塔[9 ] 模块的提出,能够充分利用局部和全局信息,整合多尺度特征图像内所包含的不同信息,增强模型特征的表达能力. 自适应卷积[10 ] 和动态卷积[11 ] 可以根据输入自适应调整每个卷积核的权重. 这种动态调整参数的方式以小幅度增加计算量为代价,换取了模型表达能力的显著提升. 对于人体姿态估计任务,可以根据不同目的,针对性地采用合适的特征提取方式,有利于提升关键点的识别精度. 除此之外,注意力机制可以根据网络中每层不同的特征信息的重要程度调整相应的权重系数,更加突出重要的关键信息. 通道注意力[12 ] 可以自适应地校准每个通道的权重,使得网络加强对关键通道特征的利用. 空间注意力[13 ] 可以视为空间区域选择机制,有助于更好地划分关键点所在的区域,有效提升了关键点定位精度. 混合注意力[14 ] 结合通道注意力和空间注意力,共同提升人体关键点的估计效果. ...
1
... 在计算机视觉领域中,不同的特征提取方式可以实现不同的效果. MobileNet[6 ] 使用中间大、两头小的逆瓶颈层架构,可以有效地避免特征信息流失,提取更多的特征信息. ShuffleNet[7 ] 提取图像语义特征,采用多种轻量级卷积,大幅度减少模型参数量,便于在移动设备上使用. Transformer利用自注意力机制,有效地获取全局信息,使得模型表达能力增强,结构上在编解码中融合逆瓶颈层,减少归一化和激活函数,减少训练压力. 递归金字塔[8 ] 和特征金字塔[9 ] 模块的提出,能够充分利用局部和全局信息,整合多尺度特征图像内所包含的不同信息,增强模型特征的表达能力. 自适应卷积[10 ] 和动态卷积[11 ] 可以根据输入自适应调整每个卷积核的权重. 这种动态调整参数的方式以小幅度增加计算量为代价,换取了模型表达能力的显著提升. 对于人体姿态估计任务,可以根据不同目的,针对性地采用合适的特征提取方式,有利于提升关键点的识别精度. 除此之外,注意力机制可以根据网络中每层不同的特征信息的重要程度调整相应的权重系数,更加突出重要的关键信息. 通道注意力[12 ] 可以自适应地校准每个通道的权重,使得网络加强对关键通道特征的利用. 空间注意力[13 ] 可以视为空间区域选择机制,有助于更好地划分关键点所在的区域,有效提升了关键点定位精度. 混合注意力[14 ] 结合通道注意力和空间注意力,共同提升人体关键点的估计效果. ...
1
... 在计算机视觉领域中,不同的特征提取方式可以实现不同的效果. MobileNet[6 ] 使用中间大、两头小的逆瓶颈层架构,可以有效地避免特征信息流失,提取更多的特征信息. ShuffleNet[7 ] 提取图像语义特征,采用多种轻量级卷积,大幅度减少模型参数量,便于在移动设备上使用. Transformer利用自注意力机制,有效地获取全局信息,使得模型表达能力增强,结构上在编解码中融合逆瓶颈层,减少归一化和激活函数,减少训练压力. 递归金字塔[8 ] 和特征金字塔[9 ] 模块的提出,能够充分利用局部和全局信息,整合多尺度特征图像内所包含的不同信息,增强模型特征的表达能力. 自适应卷积[10 ] 和动态卷积[11 ] 可以根据输入自适应调整每个卷积核的权重. 这种动态调整参数的方式以小幅度增加计算量为代价,换取了模型表达能力的显著提升. 对于人体姿态估计任务,可以根据不同目的,针对性地采用合适的特征提取方式,有利于提升关键点的识别精度. 除此之外,注意力机制可以根据网络中每层不同的特征信息的重要程度调整相应的权重系数,更加突出重要的关键信息. 通道注意力[12 ] 可以自适应地校准每个通道的权重,使得网络加强对关键通道特征的利用. 空间注意力[13 ] 可以视为空间区域选择机制,有助于更好地划分关键点所在的区域,有效提升了关键点定位精度. 混合注意力[14 ] 结合通道注意力和空间注意力,共同提升人体关键点的估计效果. ...
Feature pyramid networks for object detection
1
2017
... 在计算机视觉领域中,不同的特征提取方式可以实现不同的效果. MobileNet[6 ] 使用中间大、两头小的逆瓶颈层架构,可以有效地避免特征信息流失,提取更多的特征信息. ShuffleNet[7 ] 提取图像语义特征,采用多种轻量级卷积,大幅度减少模型参数量,便于在移动设备上使用. Transformer利用自注意力机制,有效地获取全局信息,使得模型表达能力增强,结构上在编解码中融合逆瓶颈层,减少归一化和激活函数,减少训练压力. 递归金字塔[8 ] 和特征金字塔[9 ] 模块的提出,能够充分利用局部和全局信息,整合多尺度特征图像内所包含的不同信息,增强模型特征的表达能力. 自适应卷积[10 ] 和动态卷积[11 ] 可以根据输入自适应调整每个卷积核的权重. 这种动态调整参数的方式以小幅度增加计算量为代价,换取了模型表达能力的显著提升. 对于人体姿态估计任务,可以根据不同目的,针对性地采用合适的特征提取方式,有利于提升关键点的识别精度. 除此之外,注意力机制可以根据网络中每层不同的特征信息的重要程度调整相应的权重系数,更加突出重要的关键信息. 通道注意力[12 ] 可以自适应地校准每个通道的权重,使得网络加强对关键通道特征的利用. 空间注意力[13 ] 可以视为空间区域选择机制,有助于更好地划分关键点所在的区域,有效提升了关键点定位精度. 混合注意力[14 ] 结合通道注意力和空间注意力,共同提升人体关键点的估计效果. ...
1
... 在计算机视觉领域中,不同的特征提取方式可以实现不同的效果. MobileNet[6 ] 使用中间大、两头小的逆瓶颈层架构,可以有效地避免特征信息流失,提取更多的特征信息. ShuffleNet[7 ] 提取图像语义特征,采用多种轻量级卷积,大幅度减少模型参数量,便于在移动设备上使用. Transformer利用自注意力机制,有效地获取全局信息,使得模型表达能力增强,结构上在编解码中融合逆瓶颈层,减少归一化和激活函数,减少训练压力. 递归金字塔[8 ] 和特征金字塔[9 ] 模块的提出,能够充分利用局部和全局信息,整合多尺度特征图像内所包含的不同信息,增强模型特征的表达能力. 自适应卷积[10 ] 和动态卷积[11 ] 可以根据输入自适应调整每个卷积核的权重. 这种动态调整参数的方式以小幅度增加计算量为代价,换取了模型表达能力的显著提升. 对于人体姿态估计任务,可以根据不同目的,针对性地采用合适的特征提取方式,有利于提升关键点的识别精度. 除此之外,注意力机制可以根据网络中每层不同的特征信息的重要程度调整相应的权重系数,更加突出重要的关键信息. 通道注意力[12 ] 可以自适应地校准每个通道的权重,使得网络加强对关键通道特征的利用. 空间注意力[13 ] 可以视为空间区域选择机制,有助于更好地划分关键点所在的区域,有效提升了关键点定位精度. 混合注意力[14 ] 结合通道注意力和空间注意力,共同提升人体关键点的估计效果. ...
1
... 在计算机视觉领域中,不同的特征提取方式可以实现不同的效果. MobileNet[6 ] 使用中间大、两头小的逆瓶颈层架构,可以有效地避免特征信息流失,提取更多的特征信息. ShuffleNet[7 ] 提取图像语义特征,采用多种轻量级卷积,大幅度减少模型参数量,便于在移动设备上使用. Transformer利用自注意力机制,有效地获取全局信息,使得模型表达能力增强,结构上在编解码中融合逆瓶颈层,减少归一化和激活函数,减少训练压力. 递归金字塔[8 ] 和特征金字塔[9 ] 模块的提出,能够充分利用局部和全局信息,整合多尺度特征图像内所包含的不同信息,增强模型特征的表达能力. 自适应卷积[10 ] 和动态卷积[11 ] 可以根据输入自适应调整每个卷积核的权重. 这种动态调整参数的方式以小幅度增加计算量为代价,换取了模型表达能力的显著提升. 对于人体姿态估计任务,可以根据不同目的,针对性地采用合适的特征提取方式,有利于提升关键点的识别精度. 除此之外,注意力机制可以根据网络中每层不同的特征信息的重要程度调整相应的权重系数,更加突出重要的关键信息. 通道注意力[12 ] 可以自适应地校准每个通道的权重,使得网络加强对关键通道特征的利用. 空间注意力[13 ] 可以视为空间区域选择机制,有助于更好地划分关键点所在的区域,有效提升了关键点定位精度. 混合注意力[14 ] 结合通道注意力和空间注意力,共同提升人体关键点的估计效果. ...
1
... 在计算机视觉领域中,不同的特征提取方式可以实现不同的效果. MobileNet[6 ] 使用中间大、两头小的逆瓶颈层架构,可以有效地避免特征信息流失,提取更多的特征信息. ShuffleNet[7 ] 提取图像语义特征,采用多种轻量级卷积,大幅度减少模型参数量,便于在移动设备上使用. Transformer利用自注意力机制,有效地获取全局信息,使得模型表达能力增强,结构上在编解码中融合逆瓶颈层,减少归一化和激活函数,减少训练压力. 递归金字塔[8 ] 和特征金字塔[9 ] 模块的提出,能够充分利用局部和全局信息,整合多尺度特征图像内所包含的不同信息,增强模型特征的表达能力. 自适应卷积[10 ] 和动态卷积[11 ] 可以根据输入自适应调整每个卷积核的权重. 这种动态调整参数的方式以小幅度增加计算量为代价,换取了模型表达能力的显著提升. 对于人体姿态估计任务,可以根据不同目的,针对性地采用合适的特征提取方式,有利于提升关键点的识别精度. 除此之外,注意力机制可以根据网络中每层不同的特征信息的重要程度调整相应的权重系数,更加突出重要的关键信息. 通道注意力[12 ] 可以自适应地校准每个通道的权重,使得网络加强对关键通道特征的利用. 空间注意力[13 ] 可以视为空间区域选择机制,有助于更好地划分关键点所在的区域,有效提升了关键点定位精度. 混合注意力[14 ] 结合通道注意力和空间注意力,共同提升人体关键点的估计效果. ...
1
... 在计算机视觉领域中,不同的特征提取方式可以实现不同的效果. MobileNet[6 ] 使用中间大、两头小的逆瓶颈层架构,可以有效地避免特征信息流失,提取更多的特征信息. ShuffleNet[7 ] 提取图像语义特征,采用多种轻量级卷积,大幅度减少模型参数量,便于在移动设备上使用. Transformer利用自注意力机制,有效地获取全局信息,使得模型表达能力增强,结构上在编解码中融合逆瓶颈层,减少归一化和激活函数,减少训练压力. 递归金字塔[8 ] 和特征金字塔[9 ] 模块的提出,能够充分利用局部和全局信息,整合多尺度特征图像内所包含的不同信息,增强模型特征的表达能力. 自适应卷积[10 ] 和动态卷积[11 ] 可以根据输入自适应调整每个卷积核的权重. 这种动态调整参数的方式以小幅度增加计算量为代价,换取了模型表达能力的显著提升. 对于人体姿态估计任务,可以根据不同目的,针对性地采用合适的特征提取方式,有利于提升关键点的识别精度. 除此之外,注意力机制可以根据网络中每层不同的特征信息的重要程度调整相应的权重系数,更加突出重要的关键信息. 通道注意力[12 ] 可以自适应地校准每个通道的权重,使得网络加强对关键通道特征的利用. 空间注意力[13 ] 可以视为空间区域选择机制,有助于更好地划分关键点所在的区域,有效提升了关键点定位精度. 混合注意力[14 ] 结合通道注意力和空间注意力,共同提升人体关键点的估计效果. ...
1
... 在计算机视觉领域中,不同的特征提取方式可以实现不同的效果. MobileNet[6 ] 使用中间大、两头小的逆瓶颈层架构,可以有效地避免特征信息流失,提取更多的特征信息. ShuffleNet[7 ] 提取图像语义特征,采用多种轻量级卷积,大幅度减少模型参数量,便于在移动设备上使用. Transformer利用自注意力机制,有效地获取全局信息,使得模型表达能力增强,结构上在编解码中融合逆瓶颈层,减少归一化和激活函数,减少训练压力. 递归金字塔[8 ] 和特征金字塔[9 ] 模块的提出,能够充分利用局部和全局信息,整合多尺度特征图像内所包含的不同信息,增强模型特征的表达能力. 自适应卷积[10 ] 和动态卷积[11 ] 可以根据输入自适应调整每个卷积核的权重. 这种动态调整参数的方式以小幅度增加计算量为代价,换取了模型表达能力的显著提升. 对于人体姿态估计任务,可以根据不同目的,针对性地采用合适的特征提取方式,有利于提升关键点的识别精度. 除此之外,注意力机制可以根据网络中每层不同的特征信息的重要程度调整相应的权重系数,更加突出重要的关键信息. 通道注意力[12 ] 可以自适应地校准每个通道的权重,使得网络加强对关键通道特征的利用. 空间注意力[13 ] 可以视为空间区域选择机制,有助于更好地划分关键点所在的区域,有效提升了关键点定位精度. 混合注意力[14 ] 结合通道注意力和空间注意力,共同提升人体关键点的估计效果. ...
1
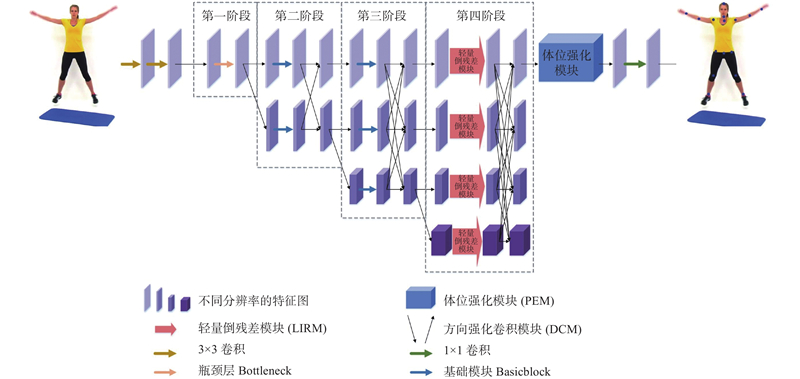
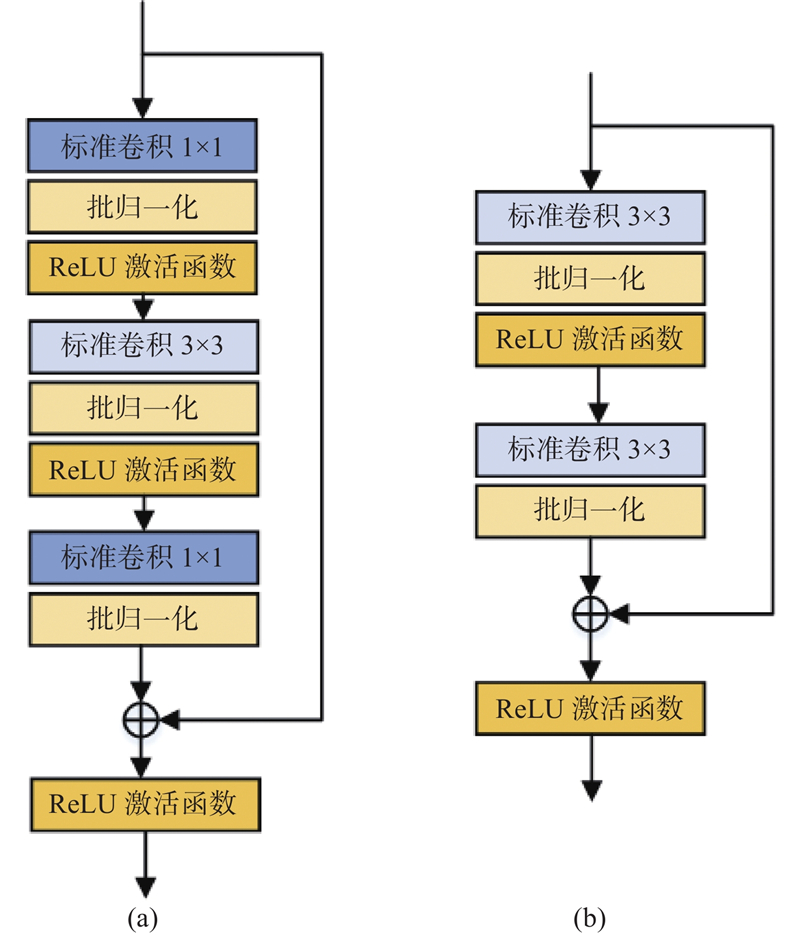
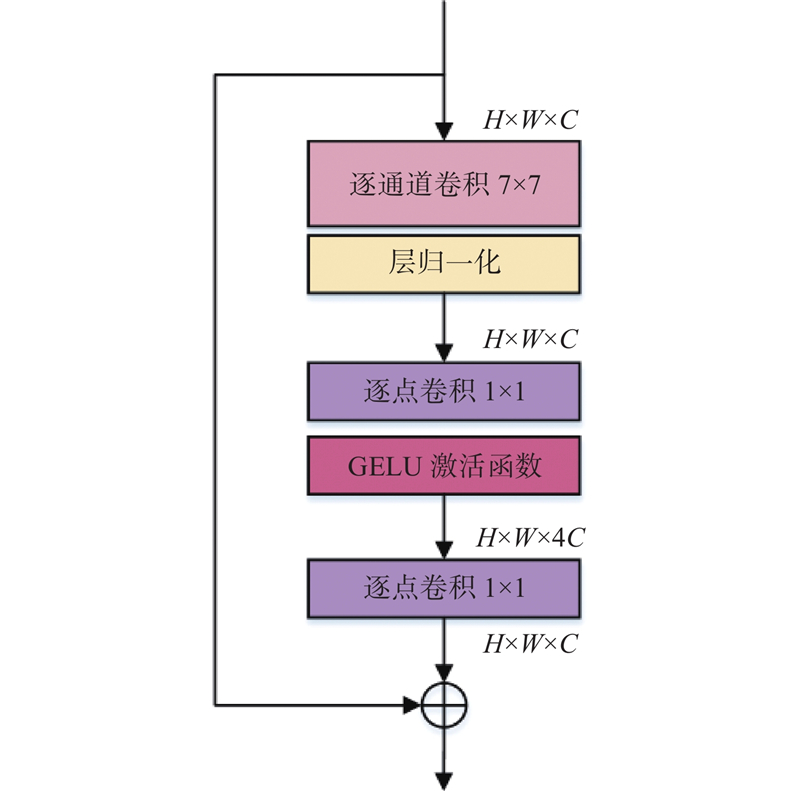
... HRNet可以缓解特征提取过程中尺度变换导致空间特征信息丢失的问题,在特征提取和融合时一直保持高分辨率,保障对输入图像的特征提取能力,因此产生了运算复杂度高、参数量大的问题. HRNet的后3个阶段均使用Basicblock作为基础特征提取模块,由于第4阶段有4条不同分辨率的支路,导致第4阶段所产生的参数量最多,但实际上对关键点的估计效果没有明显的提升[15 ] . 受到ConvNet[16 ] 的启发,提出LIRM替换网络中第4阶段的基本模块,以实现模型精度与效率之间的平衡. ...
1
... HRNet可以缓解特征提取过程中尺度变换导致空间特征信息丢失的问题,在特征提取和融合时一直保持高分辨率,保障对输入图像的特征提取能力,因此产生了运算复杂度高、参数量大的问题. HRNet的后3个阶段均使用Basicblock作为基础特征提取模块,由于第4阶段有4条不同分辨率的支路,导致第4阶段所产生的参数量最多,但实际上对关键点的估计效果没有明显的提升[15 ] . 受到ConvNet[16 ] 的启发,提出LIRM替换网络中第4阶段的基本模块,以实现模型精度与效率之间的平衡. ...
1
... HRNet可以缓解特征提取过程中尺度变换导致空间特征信息丢失的问题,在特征提取和融合时一直保持高分辨率,保障对输入图像的特征提取能力,因此产生了运算复杂度高、参数量大的问题. HRNet的后3个阶段均使用Basicblock作为基础特征提取模块,由于第4阶段有4条不同分辨率的支路,导致第4阶段所产生的参数量最多,但实际上对关键点的估计效果没有明显的提升[15 ] . 受到ConvNet[16 ] 的启发,提出LIRM替换网络中第4阶段的基本模块,以实现模型精度与效率之间的平衡. ...
1
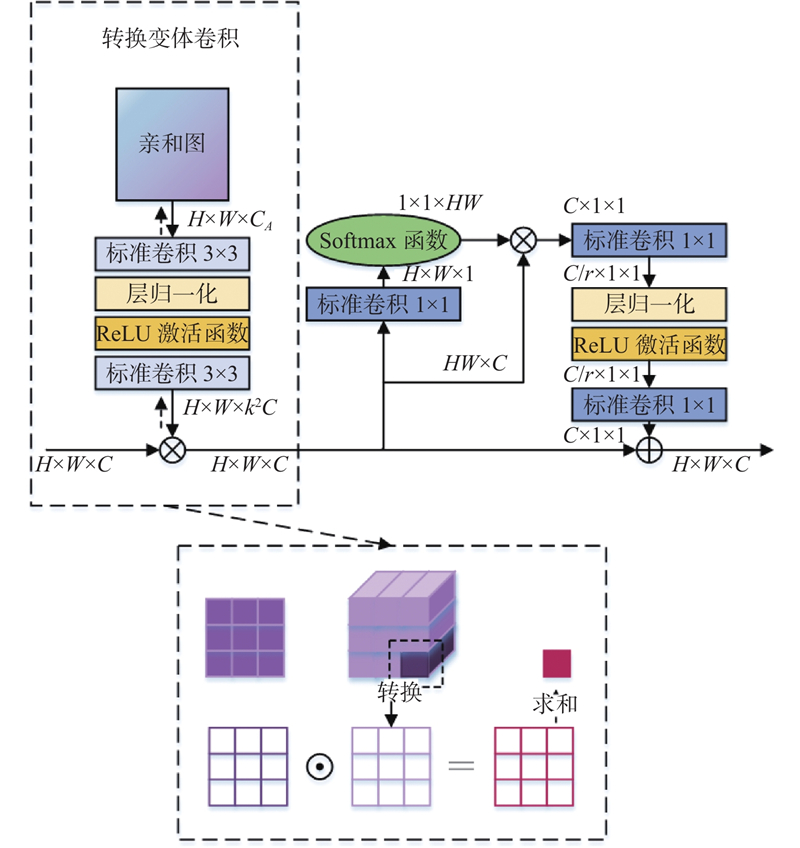
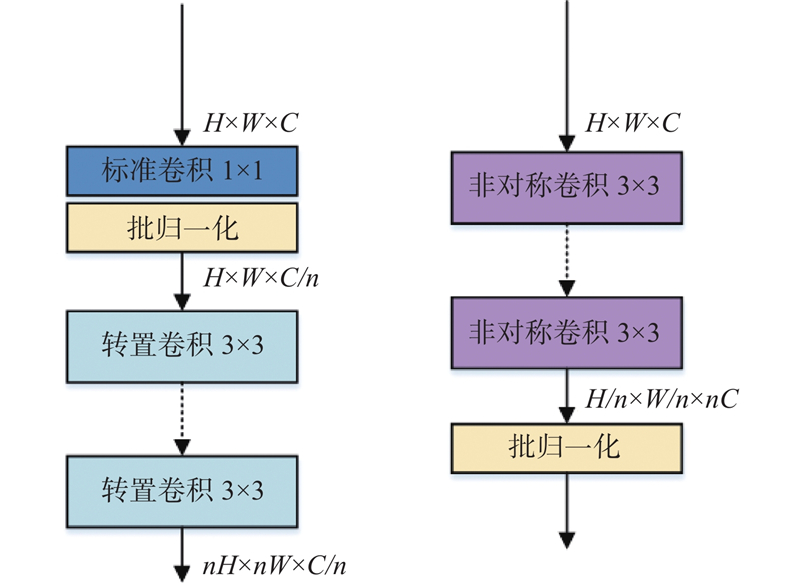
... PEM可以提升网络对人体结构信息的感知能力,将该模块放在网络第4阶段输出特征后,可以在最终输出特征图前进一步强化全局关键点的上下文联系. 除此之外,网络第1条分支的图像分辨率始终保持目标特征图尺寸不变,能够很好地保留空间位置信息. PEM在通道和空间2个方向均有效增强关键点特征表达能力,结构如图4 所示,主要包括2个部分:转换变体卷积[17 ] 与全局上下文注意模块[18 ] . ...
1
... PEM可以提升网络对人体结构信息的感知能力,将该模块放在网络第4阶段输出特征后,可以在最终输出特征图前进一步强化全局关键点的上下文联系. 除此之外,网络第1条分支的图像分辨率始终保持目标特征图尺寸不变,能够很好地保留空间位置信息. PEM在通道和空间2个方向均有效增强关键点特征表达能力,结构如图4 所示,主要包括2个部分:转换变体卷积[17 ] 与全局上下文注意模块[18 ] . ...
1
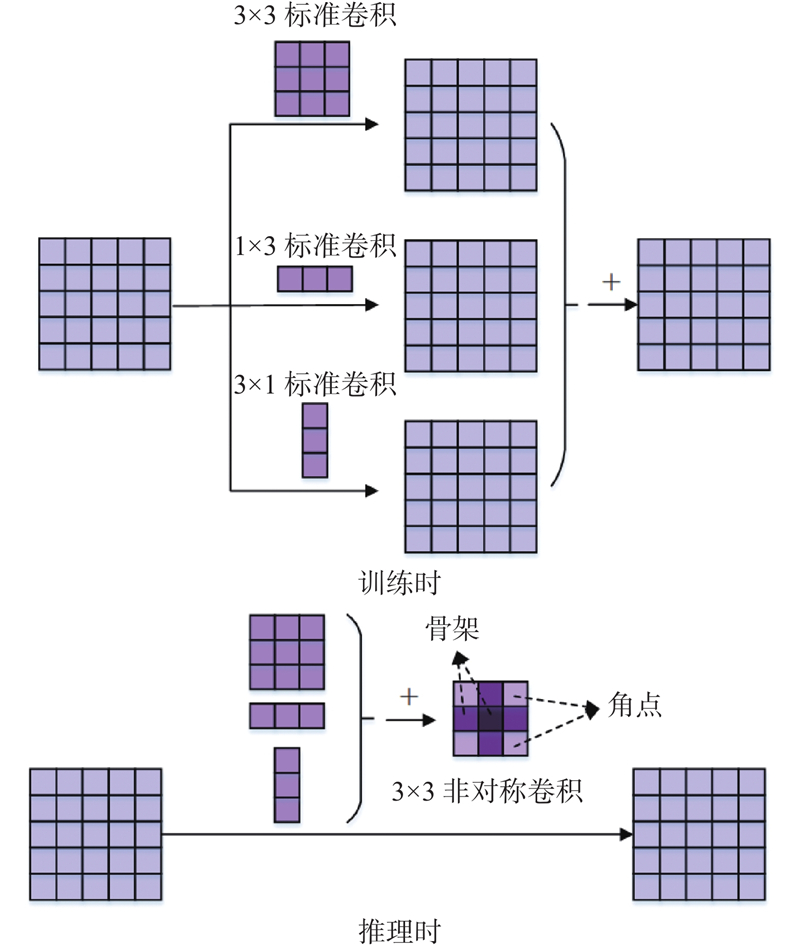
... 研究表明,卷积核上参数的重要程度不同,处在中央交叉位置即卷积核骨架上的参数更加重要,更需要被网络重视,处于边角的参数影响较小[19 ] . 当降低图像分辨率时,普通的3×3卷积对卷积核参数不进行区分处理. 在初始化时参数是随机的,因此随着后续训练过程的进行,可能导致网络向着非强化骨架参数的方向优化,最终削弱了中央交叉位置上参数对于网络的作用,导致特征提取能力降低. 人体关键点分布有水平和垂直的方向特性,当关键点位于卷积核骨架位置时,需要被重点强化,增强卷积核的方向性可以在下采样过程中不遗失关键信息. 采用非对称卷积模块降低分辨率,将额外的水平卷积和垂直卷积叠加到普通方形卷积核骨架上,起到强化骨架上参数的作用. 非对称卷积的操作原理如图6 所示. 训练时对输入特征图像并行开展3×3、1×3和3×1卷积操作,将3组输出特征图像叠加作为整体输出. 在推理时,相当于将上述3个卷积核叠加起来转换为1个新的卷积核即非对称卷积进行卷积操作,得到输出特征图. 采用2种卷积操作方式得到的输出特征图是等价的. 非对称卷积会在下采样过程中强化位于卷积核骨架位置的关键点,避免关键点特征信息的遗失. ...
1
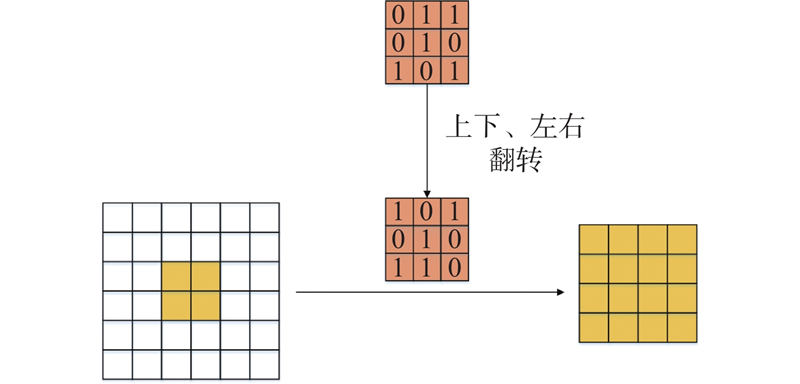
... 最近邻上采样仅使用距离待测采样点最近的像素的灰度作为该采样点的灰度,而没有考虑其他相邻像素点的影响. 在人体姿态估计中,这种上采样方式会导致关键点所在的像素位置模糊,不利于关键点的精确定位. 为了解决该问题,提出采用转置卷积[20 ] 来提高图像分辨率的方法. 使用1×1卷积来转换通道数量,采用多个转置卷积将输入特征图恢复至目标尺寸. 如图7 所示,转置卷积在卷积前增加了参数转置的过程,能够在上采样过程中持续提取特征信息. 转置卷积中的权重是可以被学习的,通过学习获取最适合当前数据集的上采样方式. 具体来说,转置卷积需要对输入进行填充,在输入特征图元素间填充s −1行(其中s 为转置卷积的步距),在输入特征图四周填充k −p −1行(其中k 为转置卷积的卷积核大小,p 为转置卷积的填充数量). 将卷积核参数上下、左右翻转,最后进行标准卷积运算. 利用该方式不会模糊关键点所在的像素位置,能够在上采样过程中进一步提取图像特征,有利于不同分辨率特征图像的融合. ...
1
... 在MPII人体姿势数据集[21 ] 和COCO2017数据集[22 ] 上进行验证测试. ...
1
... 在MPII人体姿势数据集[21 ] 和COCO2017数据集[22 ] 上进行验证测试. ...
8
... Comparison results of average precision and average recall for different networks on COCO validation set
Tab.4 方法 预训练 输入图像尺寸 N p /106 FLOPs/109 AP/% AP0.5 /% AP0.75 /% APM /% APL /% AR/% 8-stage Hourglass[2 ] N 256×192 25.1 14.3 66.9 — — — — — CPN50[3 ] Y 256×192 27.0 6.2 68.6 — — — — — Simple Baseline152[4 ] Y 256×192 68.6 15.7 72.0 89.3 79.8 68.7 78.9 77.8 HRNet(W32)[5 ] Y 256×192 28.5 7.1 74.4 90.5 81.9 70.8 81.0 79.8 HRNet(W48)[5 ] Y 256×192 63.6 14.6 75.1 90.6 82.2 71.5 81.8 80.4 RAM-GPRNet(W32)[23 ] Y 256×192 31.4 7.7 76.0 — — — — — RAM-GPRNet(W48)[23 ] Y 256×192 70.0 15.8 76.5 — — — — — HRFormer-B[24 ] Y 256×192 43.2 12.2 75.6 90.8 82.8 71.7 82.6 80.8 HRGCNet(W32)[25 ] Y 256×192 29.6 7.11 76.6 93.6 84.6 73.9 80.7 79.3 HRGCNet(W48)[25 ] Y 256×192 64.6 14.6 77.4 93.6 84.8 74.6 81.7 80.1 AMHRNet(W32)[26 ] — 256×192 36.4 — 76.1 91.0 82.7 71.5 82.9 81.2 AMHRNet(W48)[26 ] — 256×192 71.8 — 76.4 91.1 83.1 72.2 83.3 81.4 本文方法(W32) Y 256×192 21.1 6.3 76.7 93.6 84.8 73.3 81.8 80.7 本文方法(W48) Y 256×192 46.2 12.3 77.4 93.7 85.0 74.4 82.3 81.4 CPN50[3 ] Y 384×288 — 13.9 70.6 — — — — — Simple Baseline152[4 ] Y 384×288 68.6 35.3 74.3 89.6 81.1 70.5 81.6 79.7 HRNet(W32)[5 ] Y 384×288 28.5 16.0 75.8 90.6 82.5 72.0 82.7 80.9 HRNet(W48)[5 ] Y 384×288 63.6 32.9 76.3 90.8 82.9 72.3 83.4 81.2 RAM-GPRNet(W32)[23 ] Y 384×288 31.4 17.2 77.3 — — — — — RAM-GPRNet(W48)[23 ] Y 384×288 70.0 35.6 77.7 — — — — — HRFormer-B[24 ] Y 384×288 43.2 26.8 77.2 91.0 83.6 73.2 84.2 82.0 HRGCNet(W32)[25 ] Y 384×288 29.6 16.1 78.0 93.6 84.8 75.0 82.6 80.5 HRGCNet(W48)[25 ] Y 384×288 64.6 32.9 78.4 93.6 85.8 75.3 83.5 81.3 本文方法(W32) Y 384×288 21.1 14.8 78.2 93.7 85.0 75.4 82.9 81.2 本文方法(W48) Y 384×288 46.2 28.5 78.5 93.7 85.8 75.5 83.7 81.9
表 5 在COCO测试集上不同网络的平均精度和平均召回率对比结果 ...
... [
23 ]
Y 256×192 70.0 15.8 76.5 — — — — — HRFormer-B[24 ] Y 256×192 43.2 12.2 75.6 90.8 82.8 71.7 82.6 80.8 HRGCNet(W32)[25 ] Y 256×192 29.6 7.11 76.6 93.6 84.6 73.9 80.7 79.3 HRGCNet(W48)[25 ] Y 256×192 64.6 14.6 77.4 93.6 84.8 74.6 81.7 80.1 AMHRNet(W32)[26 ] — 256×192 36.4 — 76.1 91.0 82.7 71.5 82.9 81.2 AMHRNet(W48)[26 ] — 256×192 71.8 — 76.4 91.1 83.1 72.2 83.3 81.4 本文方法(W32) Y 256×192 21.1 6.3 76.7 93.6 84.8 73.3 81.8 80.7 本文方法(W48) Y 256×192 46.2 12.3 77.4 93.7 85.0 74.4 82.3 81.4 CPN50[3 ] Y 384×288 — 13.9 70.6 — — — — — Simple Baseline152[4 ] Y 384×288 68.6 35.3 74.3 89.6 81.1 70.5 81.6 79.7 HRNet(W32)[5 ] Y 384×288 28.5 16.0 75.8 90.6 82.5 72.0 82.7 80.9 HRNet(W48)[5 ] Y 384×288 63.6 32.9 76.3 90.8 82.9 72.3 83.4 81.2 RAM-GPRNet(W32)[23 ] Y 384×288 31.4 17.2 77.3 — — — — — RAM-GPRNet(W48)[23 ] Y 384×288 70.0 35.6 77.7 — — — — — HRFormer-B[24 ] Y 384×288 43.2 26.8 77.2 91.0 83.6 73.2 84.2 82.0 HRGCNet(W32)[25 ] Y 384×288 29.6 16.1 78.0 93.6 84.8 75.0 82.6 80.5 HRGCNet(W48)[25 ] Y 384×288 64.6 32.9 78.4 93.6 85.8 75.3 83.5 81.3 本文方法(W32) Y 384×288 21.1 14.8 78.2 93.7 85.0 75.4 82.9 81.2 本文方法(W48) Y 384×288 46.2 28.5 78.5 93.7 85.8 75.5 83.7 81.9 表 5 在COCO测试集上不同网络的平均精度和平均召回率对比结果 ...
... [
23 ]
Y 384×288 31.4 17.2 77.3 — — — — — RAM-GPRNet(W48)[23 ] Y 384×288 70.0 35.6 77.7 — — — — — HRFormer-B[24 ] Y 384×288 43.2 26.8 77.2 91.0 83.6 73.2 84.2 82.0 HRGCNet(W32)[25 ] Y 384×288 29.6 16.1 78.0 93.6 84.8 75.0 82.6 80.5 HRGCNet(W48)[25 ] Y 384×288 64.6 32.9 78.4 93.6 85.8 75.3 83.5 81.3 本文方法(W32) Y 384×288 21.1 14.8 78.2 93.7 85.0 75.4 82.9 81.2 本文方法(W48) Y 384×288 46.2 28.5 78.5 93.7 85.8 75.5 83.7 81.9 表 5 在COCO测试集上不同网络的平均精度和平均召回率对比结果 ...
... [
23 ]
Y 384×288 70.0 35.6 77.7 — — — — — HRFormer-B[24 ] Y 384×288 43.2 26.8 77.2 91.0 83.6 73.2 84.2 82.0 HRGCNet(W32)[25 ] Y 384×288 29.6 16.1 78.0 93.6 84.8 75.0 82.6 80.5 HRGCNet(W48)[25 ] Y 384×288 64.6 32.9 78.4 93.6 85.8 75.3 83.5 81.3 本文方法(W32) Y 384×288 21.1 14.8 78.2 93.7 85.0 75.4 82.9 81.2 本文方法(W48) Y 384×288 46.2 28.5 78.5 93.7 85.8 75.5 83.7 81.9 表 5 在COCO测试集上不同网络的平均精度和平均召回率对比结果 ...
... Comparison results of average precision and average recall for different networks on COCO test set
Tab.5 方法 预训练 输入图像尺寸 N p /106 FLOPs/109 AP/% AP0.5 /% AP0.75 /% APM /% APL /% AR/% CPN50[3 ] — 384×288 — — 72.6 86.1 69.7 78.3 64.1 — Simple Baseline152[4 ] Y 256×192 68.6 15.7 71.6 91.2 80.1 68.7 77.2 77.3 HRNet(W32)[5 ] Y 384×288 28.5 16.0 74.9 92.5 82.8 71.3 80.9 80.1 HRNet(W48)[5 ] Y 384×288 63.6 32.9 75.5 92.5 83.3 71.9 81.5 80.5 RAM-GPRNet(W32)[23 ] Y 384×288 31.4 17.2 76.5 — — — — — RAM-GPRNet(W48)[23 ] Y 384×288 70.0 35.6 77.0 — — — — — HRFormer-B[24 ] Y 384×288 43.2 26.8 76.2 92.7 83.8 72.5 82.3 81.2 HRGCNet(W32)[25 ] Y 384×288 29.6 16.1 77.9 93.6 84.8 74.8 82.9 80.6 HRGCNet(W48)[25 ] Y 384×288 64.6 32.9 78.3 93.6 85.7 75.3 83.5 81.2 本文方法(W32) Y 384×288 21.1 14.8 78.1 93.6 85.0 75.2 83.1 81.2 本文方法(W48) Y 384×288 46.2 28.5 78.4 93.7 85.5 75.5 83.6 81.7
在COCO验证集上进行对比,当输入图像大小为256×192时,提出的网络(W32)AP值达到76.7%,优于其他具有相同输入的方法. 与HRNet[5 ] 相比,AP值大幅度提高且运算量降低;与RAM-GPRNet[23 ] 相比,AP值提高了0.7%和0.9%;与HRFormer-B[24 ] 相比,实现了0.9%的AP增益;与HRGCNet[25 ] 相比,虽然AP值相近,但参数量和运算量更低;与AMHRNet[26 ] 相比,AP值有0.6%和1.0%的提升,且参数量约为其58%和65%. 当输入图像大小为384×288时,提出的网络获得了78.2%和78.5%的AP值. 与CPN[3 ] 、SimpleBaseline[4 ] 、HRNet[5 ] 、RAM-GPRNet[23 ] 、HRFormer-B[24 ] 、HRGCNet[25 ] 相比,本网络在主要的性能指标上均得到了有效的提升,实现了初步轻量化,减少了参数量和运算量. 综合而言,本文模型在估计精度上优于多数网络,关键点的识别效果较好,且在参数量和运算量方面有所降低. ...
... [
23 ]
Y 384×288 70.0 35.6 77.0 — — — — — HRFormer-B[24 ] Y 384×288 43.2 26.8 76.2 92.7 83.8 72.5 82.3 81.2 HRGCNet(W32)[25 ] Y 384×288 29.6 16.1 77.9 93.6 84.8 74.8 82.9 80.6 HRGCNet(W48)[25 ] Y 384×288 64.6 32.9 78.3 93.6 85.7 75.3 83.5 81.2 本文方法(W32) Y 384×288 21.1 14.8 78.1 93.6 85.0 75.2 83.1 81.2 本文方法(W48) Y 384×288 46.2 28.5 78.4 93.7 85.5 75.5 83.6 81.7 在COCO验证集上进行对比,当输入图像大小为256×192时,提出的网络(W32)AP值达到76.7%,优于其他具有相同输入的方法. 与HRNet[5 ] 相比,AP值大幅度提高且运算量降低;与RAM-GPRNet[23 ] 相比,AP值提高了0.7%和0.9%;与HRFormer-B[24 ] 相比,实现了0.9%的AP增益;与HRGCNet[25 ] 相比,虽然AP值相近,但参数量和运算量更低;与AMHRNet[26 ] 相比,AP值有0.6%和1.0%的提升,且参数量约为其58%和65%. 当输入图像大小为384×288时,提出的网络获得了78.2%和78.5%的AP值. 与CPN[3 ] 、SimpleBaseline[4 ] 、HRNet[5 ] 、RAM-GPRNet[23 ] 、HRFormer-B[24 ] 、HRGCNet[25 ] 相比,本网络在主要的性能指标上均得到了有效的提升,实现了初步轻量化,减少了参数量和运算量. 综合而言,本文模型在估计精度上优于多数网络,关键点的识别效果较好,且在参数量和运算量方面有所降低. ...
... 在COCO验证集上进行对比,当输入图像大小为256×192时,提出的网络(W32)AP值达到76.7%,优于其他具有相同输入的方法. 与HRNet[5 ] 相比,AP值大幅度提高且运算量降低;与RAM-GPRNet[23 ] 相比,AP值提高了0.7%和0.9%;与HRFormer-B[24 ] 相比,实现了0.9%的AP增益;与HRGCNet[25 ] 相比,虽然AP值相近,但参数量和运算量更低;与AMHRNet[26 ] 相比,AP值有0.6%和1.0%的提升,且参数量约为其58%和65%. 当输入图像大小为384×288时,提出的网络获得了78.2%和78.5%的AP值. 与CPN[3 ] 、SimpleBaseline[4 ] 、HRNet[5 ] 、RAM-GPRNet[23 ] 、HRFormer-B[24 ] 、HRGCNet[25 ] 相比,本网络在主要的性能指标上均得到了有效的提升,实现了初步轻量化,减少了参数量和运算量. 综合而言,本文模型在估计精度上优于多数网络,关键点的识别效果较好,且在参数量和运算量方面有所降低. ...
... [23 ]、HRFormer-B[24 ] 、HRGCNet[25 ] 相比,本网络在主要的性能指标上均得到了有效的提升,实现了初步轻量化,减少了参数量和运算量. 综合而言,本文模型在估计精度上优于多数网络,关键点的识别效果较好,且在参数量和运算量方面有所降低. ...
5
... Comparison results of average precision and average recall for different networks on COCO validation set
Tab.4 方法 预训练 输入图像尺寸 N p /106 FLOPs/109 AP/% AP0.5 /% AP0.75 /% APM /% APL /% AR/% 8-stage Hourglass[2 ] N 256×192 25.1 14.3 66.9 — — — — — CPN50[3 ] Y 256×192 27.0 6.2 68.6 — — — — — Simple Baseline152[4 ] Y 256×192 68.6 15.7 72.0 89.3 79.8 68.7 78.9 77.8 HRNet(W32)[5 ] Y 256×192 28.5 7.1 74.4 90.5 81.9 70.8 81.0 79.8 HRNet(W48)[5 ] Y 256×192 63.6 14.6 75.1 90.6 82.2 71.5 81.8 80.4 RAM-GPRNet(W32)[23 ] Y 256×192 31.4 7.7 76.0 — — — — — RAM-GPRNet(W48)[23 ] Y 256×192 70.0 15.8 76.5 — — — — — HRFormer-B[24 ] Y 256×192 43.2 12.2 75.6 90.8 82.8 71.7 82.6 80.8 HRGCNet(W32)[25 ] Y 256×192 29.6 7.11 76.6 93.6 84.6 73.9 80.7 79.3 HRGCNet(W48)[25 ] Y 256×192 64.6 14.6 77.4 93.6 84.8 74.6 81.7 80.1 AMHRNet(W32)[26 ] — 256×192 36.4 — 76.1 91.0 82.7 71.5 82.9 81.2 AMHRNet(W48)[26 ] — 256×192 71.8 — 76.4 91.1 83.1 72.2 83.3 81.4 本文方法(W32) Y 256×192 21.1 6.3 76.7 93.6 84.8 73.3 81.8 80.7 本文方法(W48) Y 256×192 46.2 12.3 77.4 93.7 85.0 74.4 82.3 81.4 CPN50[3 ] Y 384×288 — 13.9 70.6 — — — — — Simple Baseline152[4 ] Y 384×288 68.6 35.3 74.3 89.6 81.1 70.5 81.6 79.7 HRNet(W32)[5 ] Y 384×288 28.5 16.0 75.8 90.6 82.5 72.0 82.7 80.9 HRNet(W48)[5 ] Y 384×288 63.6 32.9 76.3 90.8 82.9 72.3 83.4 81.2 RAM-GPRNet(W32)[23 ] Y 384×288 31.4 17.2 77.3 — — — — — RAM-GPRNet(W48)[23 ] Y 384×288 70.0 35.6 77.7 — — — — — HRFormer-B[24 ] Y 384×288 43.2 26.8 77.2 91.0 83.6 73.2 84.2 82.0 HRGCNet(W32)[25 ] Y 384×288 29.6 16.1 78.0 93.6 84.8 75.0 82.6 80.5 HRGCNet(W48)[25 ] Y 384×288 64.6 32.9 78.4 93.6 85.8 75.3 83.5 81.3 本文方法(W32) Y 384×288 21.1 14.8 78.2 93.7 85.0 75.4 82.9 81.2 本文方法(W48) Y 384×288 46.2 28.5 78.5 93.7 85.8 75.5 83.7 81.9
表 5 在COCO测试集上不同网络的平均精度和平均召回率对比结果 ...
... [
24 ]
Y 384×288 43.2 26.8 77.2 91.0 83.6 73.2 84.2 82.0 HRGCNet(W32)[25 ] Y 384×288 29.6 16.1 78.0 93.6 84.8 75.0 82.6 80.5 HRGCNet(W48)[25 ] Y 384×288 64.6 32.9 78.4 93.6 85.8 75.3 83.5 81.3 本文方法(W32) Y 384×288 21.1 14.8 78.2 93.7 85.0 75.4 82.9 81.2 本文方法(W48) Y 384×288 46.2 28.5 78.5 93.7 85.8 75.5 83.7 81.9 表 5 在COCO测试集上不同网络的平均精度和平均召回率对比结果 ...
... Comparison results of average precision and average recall for different networks on COCO test set
Tab.5 方法 预训练 输入图像尺寸 N p /106 FLOPs/109 AP/% AP0.5 /% AP0.75 /% APM /% APL /% AR/% CPN50[3 ] — 384×288 — — 72.6 86.1 69.7 78.3 64.1 — Simple Baseline152[4 ] Y 256×192 68.6 15.7 71.6 91.2 80.1 68.7 77.2 77.3 HRNet(W32)[5 ] Y 384×288 28.5 16.0 74.9 92.5 82.8 71.3 80.9 80.1 HRNet(W48)[5 ] Y 384×288 63.6 32.9 75.5 92.5 83.3 71.9 81.5 80.5 RAM-GPRNet(W32)[23 ] Y 384×288 31.4 17.2 76.5 — — — — — RAM-GPRNet(W48)[23 ] Y 384×288 70.0 35.6 77.0 — — — — — HRFormer-B[24 ] Y 384×288 43.2 26.8 76.2 92.7 83.8 72.5 82.3 81.2 HRGCNet(W32)[25 ] Y 384×288 29.6 16.1 77.9 93.6 84.8 74.8 82.9 80.6 HRGCNet(W48)[25 ] Y 384×288 64.6 32.9 78.3 93.6 85.7 75.3 83.5 81.2 本文方法(W32) Y 384×288 21.1 14.8 78.1 93.6 85.0 75.2 83.1 81.2 本文方法(W48) Y 384×288 46.2 28.5 78.4 93.7 85.5 75.5 83.6 81.7
在COCO验证集上进行对比,当输入图像大小为256×192时,提出的网络(W32)AP值达到76.7%,优于其他具有相同输入的方法. 与HRNet[5 ] 相比,AP值大幅度提高且运算量降低;与RAM-GPRNet[23 ] 相比,AP值提高了0.7%和0.9%;与HRFormer-B[24 ] 相比,实现了0.9%的AP增益;与HRGCNet[25 ] 相比,虽然AP值相近,但参数量和运算量更低;与AMHRNet[26 ] 相比,AP值有0.6%和1.0%的提升,且参数量约为其58%和65%. 当输入图像大小为384×288时,提出的网络获得了78.2%和78.5%的AP值. 与CPN[3 ] 、SimpleBaseline[4 ] 、HRNet[5 ] 、RAM-GPRNet[23 ] 、HRFormer-B[24 ] 、HRGCNet[25 ] 相比,本网络在主要的性能指标上均得到了有效的提升,实现了初步轻量化,减少了参数量和运算量. 综合而言,本文模型在估计精度上优于多数网络,关键点的识别效果较好,且在参数量和运算量方面有所降低. ...
... 在COCO验证集上进行对比,当输入图像大小为256×192时,提出的网络(W32)AP值达到76.7%,优于其他具有相同输入的方法. 与HRNet[5 ] 相比,AP值大幅度提高且运算量降低;与RAM-GPRNet[23 ] 相比,AP值提高了0.7%和0.9%;与HRFormer-B[24 ] 相比,实现了0.9%的AP增益;与HRGCNet[25 ] 相比,虽然AP值相近,但参数量和运算量更低;与AMHRNet[26 ] 相比,AP值有0.6%和1.0%的提升,且参数量约为其58%和65%. 当输入图像大小为384×288时,提出的网络获得了78.2%和78.5%的AP值. 与CPN[3 ] 、SimpleBaseline[4 ] 、HRNet[5 ] 、RAM-GPRNet[23 ] 、HRFormer-B[24 ] 、HRGCNet[25 ] 相比,本网络在主要的性能指标上均得到了有效的提升,实现了初步轻量化,减少了参数量和运算量. 综合而言,本文模型在估计精度上优于多数网络,关键点的识别效果较好,且在参数量和运算量方面有所降低. ...
... [24 ]、HRGCNet[25 ] 相比,本网络在主要的性能指标上均得到了有效的提升,实现了初步轻量化,减少了参数量和运算量. 综合而言,本文模型在估计精度上优于多数网络,关键点的识别效果较好,且在参数量和运算量方面有所降低. ...
8
... Comparison results of average precision and average recall for different networks on COCO validation set
Tab.4 方法 预训练 输入图像尺寸 N p /106 FLOPs/109 AP/% AP0.5 /% AP0.75 /% APM /% APL /% AR/% 8-stage Hourglass[2 ] N 256×192 25.1 14.3 66.9 — — — — — CPN50[3 ] Y 256×192 27.0 6.2 68.6 — — — — — Simple Baseline152[4 ] Y 256×192 68.6 15.7 72.0 89.3 79.8 68.7 78.9 77.8 HRNet(W32)[5 ] Y 256×192 28.5 7.1 74.4 90.5 81.9 70.8 81.0 79.8 HRNet(W48)[5 ] Y 256×192 63.6 14.6 75.1 90.6 82.2 71.5 81.8 80.4 RAM-GPRNet(W32)[23 ] Y 256×192 31.4 7.7 76.0 — — — — — RAM-GPRNet(W48)[23 ] Y 256×192 70.0 15.8 76.5 — — — — — HRFormer-B[24 ] Y 256×192 43.2 12.2 75.6 90.8 82.8 71.7 82.6 80.8 HRGCNet(W32)[25 ] Y 256×192 29.6 7.11 76.6 93.6 84.6 73.9 80.7 79.3 HRGCNet(W48)[25 ] Y 256×192 64.6 14.6 77.4 93.6 84.8 74.6 81.7 80.1 AMHRNet(W32)[26 ] — 256×192 36.4 — 76.1 91.0 82.7 71.5 82.9 81.2 AMHRNet(W48)[26 ] — 256×192 71.8 — 76.4 91.1 83.1 72.2 83.3 81.4 本文方法(W32) Y 256×192 21.1 6.3 76.7 93.6 84.8 73.3 81.8 80.7 本文方法(W48) Y 256×192 46.2 12.3 77.4 93.7 85.0 74.4 82.3 81.4 CPN50[3 ] Y 384×288 — 13.9 70.6 — — — — — Simple Baseline152[4 ] Y 384×288 68.6 35.3 74.3 89.6 81.1 70.5 81.6 79.7 HRNet(W32)[5 ] Y 384×288 28.5 16.0 75.8 90.6 82.5 72.0 82.7 80.9 HRNet(W48)[5 ] Y 384×288 63.6 32.9 76.3 90.8 82.9 72.3 83.4 81.2 RAM-GPRNet(W32)[23 ] Y 384×288 31.4 17.2 77.3 — — — — — RAM-GPRNet(W48)[23 ] Y 384×288 70.0 35.6 77.7 — — — — — HRFormer-B[24 ] Y 384×288 43.2 26.8 77.2 91.0 83.6 73.2 84.2 82.0 HRGCNet(W32)[25 ] Y 384×288 29.6 16.1 78.0 93.6 84.8 75.0 82.6 80.5 HRGCNet(W48)[25 ] Y 384×288 64.6 32.9 78.4 93.6 85.8 75.3 83.5 81.3 本文方法(W32) Y 384×288 21.1 14.8 78.2 93.7 85.0 75.4 82.9 81.2 本文方法(W48) Y 384×288 46.2 28.5 78.5 93.7 85.8 75.5 83.7 81.9
表 5 在COCO测试集上不同网络的平均精度和平均召回率对比结果 ...
... [
25 ]
Y 256×192 64.6 14.6 77.4 93.6 84.8 74.6 81.7 80.1 AMHRNet(W32)[26 ] — 256×192 36.4 — 76.1 91.0 82.7 71.5 82.9 81.2 AMHRNet(W48)[26 ] — 256×192 71.8 — 76.4 91.1 83.1 72.2 83.3 81.4 本文方法(W32) Y 256×192 21.1 6.3 76.7 93.6 84.8 73.3 81.8 80.7 本文方法(W48) Y 256×192 46.2 12.3 77.4 93.7 85.0 74.4 82.3 81.4 CPN50[3 ] Y 384×288 — 13.9 70.6 — — — — — Simple Baseline152[4 ] Y 384×288 68.6 35.3 74.3 89.6 81.1 70.5 81.6 79.7 HRNet(W32)[5 ] Y 384×288 28.5 16.0 75.8 90.6 82.5 72.0 82.7 80.9 HRNet(W48)[5 ] Y 384×288 63.6 32.9 76.3 90.8 82.9 72.3 83.4 81.2 RAM-GPRNet(W32)[23 ] Y 384×288 31.4 17.2 77.3 — — — — — RAM-GPRNet(W48)[23 ] Y 384×288 70.0 35.6 77.7 — — — — — HRFormer-B[24 ] Y 384×288 43.2 26.8 77.2 91.0 83.6 73.2 84.2 82.0 HRGCNet(W32)[25 ] Y 384×288 29.6 16.1 78.0 93.6 84.8 75.0 82.6 80.5 HRGCNet(W48)[25 ] Y 384×288 64.6 32.9 78.4 93.6 85.8 75.3 83.5 81.3 本文方法(W32) Y 384×288 21.1 14.8 78.2 93.7 85.0 75.4 82.9 81.2 本文方法(W48) Y 384×288 46.2 28.5 78.5 93.7 85.8 75.5 83.7 81.9 表 5 在COCO测试集上不同网络的平均精度和平均召回率对比结果 ...
... [
25 ]
Y 384×288 29.6 16.1 78.0 93.6 84.8 75.0 82.6 80.5 HRGCNet(W48)[25 ] Y 384×288 64.6 32.9 78.4 93.6 85.8 75.3 83.5 81.3 本文方法(W32) Y 384×288 21.1 14.8 78.2 93.7 85.0 75.4 82.9 81.2 本文方法(W48) Y 384×288 46.2 28.5 78.5 93.7 85.8 75.5 83.7 81.9 表 5 在COCO测试集上不同网络的平均精度和平均召回率对比结果 ...
... [
25 ]
Y 384×288 64.6 32.9 78.4 93.6 85.8 75.3 83.5 81.3 本文方法(W32) Y 384×288 21.1 14.8 78.2 93.7 85.0 75.4 82.9 81.2 本文方法(W48) Y 384×288 46.2 28.5 78.5 93.7 85.8 75.5 83.7 81.9 表 5 在COCO测试集上不同网络的平均精度和平均召回率对比结果 ...
... Comparison results of average precision and average recall for different networks on COCO test set
Tab.5 方法 预训练 输入图像尺寸 N p /106 FLOPs/109 AP/% AP0.5 /% AP0.75 /% APM /% APL /% AR/% CPN50[3 ] — 384×288 — — 72.6 86.1 69.7 78.3 64.1 — Simple Baseline152[4 ] Y 256×192 68.6 15.7 71.6 91.2 80.1 68.7 77.2 77.3 HRNet(W32)[5 ] Y 384×288 28.5 16.0 74.9 92.5 82.8 71.3 80.9 80.1 HRNet(W48)[5 ] Y 384×288 63.6 32.9 75.5 92.5 83.3 71.9 81.5 80.5 RAM-GPRNet(W32)[23 ] Y 384×288 31.4 17.2 76.5 — — — — — RAM-GPRNet(W48)[23 ] Y 384×288 70.0 35.6 77.0 — — — — — HRFormer-B[24 ] Y 384×288 43.2 26.8 76.2 92.7 83.8 72.5 82.3 81.2 HRGCNet(W32)[25 ] Y 384×288 29.6 16.1 77.9 93.6 84.8 74.8 82.9 80.6 HRGCNet(W48)[25 ] Y 384×288 64.6 32.9 78.3 93.6 85.7 75.3 83.5 81.2 本文方法(W32) Y 384×288 21.1 14.8 78.1 93.6 85.0 75.2 83.1 81.2 本文方法(W48) Y 384×288 46.2 28.5 78.4 93.7 85.5 75.5 83.6 81.7
在COCO验证集上进行对比,当输入图像大小为256×192时,提出的网络(W32)AP值达到76.7%,优于其他具有相同输入的方法. 与HRNet[5 ] 相比,AP值大幅度提高且运算量降低;与RAM-GPRNet[23 ] 相比,AP值提高了0.7%和0.9%;与HRFormer-B[24 ] 相比,实现了0.9%的AP增益;与HRGCNet[25 ] 相比,虽然AP值相近,但参数量和运算量更低;与AMHRNet[26 ] 相比,AP值有0.6%和1.0%的提升,且参数量约为其58%和65%. 当输入图像大小为384×288时,提出的网络获得了78.2%和78.5%的AP值. 与CPN[3 ] 、SimpleBaseline[4 ] 、HRNet[5 ] 、RAM-GPRNet[23 ] 、HRFormer-B[24 ] 、HRGCNet[25 ] 相比,本网络在主要的性能指标上均得到了有效的提升,实现了初步轻量化,减少了参数量和运算量. 综合而言,本文模型在估计精度上优于多数网络,关键点的识别效果较好,且在参数量和运算量方面有所降低. ...
... [
25 ]
Y 384×288 64.6 32.9 78.3 93.6 85.7 75.3 83.5 81.2 本文方法(W32) Y 384×288 21.1 14.8 78.1 93.6 85.0 75.2 83.1 81.2 本文方法(W48) Y 384×288 46.2 28.5 78.4 93.7 85.5 75.5 83.6 81.7 在COCO验证集上进行对比,当输入图像大小为256×192时,提出的网络(W32)AP值达到76.7%,优于其他具有相同输入的方法. 与HRNet[5 ] 相比,AP值大幅度提高且运算量降低;与RAM-GPRNet[23 ] 相比,AP值提高了0.7%和0.9%;与HRFormer-B[24 ] 相比,实现了0.9%的AP增益;与HRGCNet[25 ] 相比,虽然AP值相近,但参数量和运算量更低;与AMHRNet[26 ] 相比,AP值有0.6%和1.0%的提升,且参数量约为其58%和65%. 当输入图像大小为384×288时,提出的网络获得了78.2%和78.5%的AP值. 与CPN[3 ] 、SimpleBaseline[4 ] 、HRNet[5 ] 、RAM-GPRNet[23 ] 、HRFormer-B[24 ] 、HRGCNet[25 ] 相比,本网络在主要的性能指标上均得到了有效的提升,实现了初步轻量化,减少了参数量和运算量. 综合而言,本文模型在估计精度上优于多数网络,关键点的识别效果较好,且在参数量和运算量方面有所降低. ...
... 在COCO验证集上进行对比,当输入图像大小为256×192时,提出的网络(W32)AP值达到76.7%,优于其他具有相同输入的方法. 与HRNet[5 ] 相比,AP值大幅度提高且运算量降低;与RAM-GPRNet[23 ] 相比,AP值提高了0.7%和0.9%;与HRFormer-B[24 ] 相比,实现了0.9%的AP增益;与HRGCNet[25 ] 相比,虽然AP值相近,但参数量和运算量更低;与AMHRNet[26 ] 相比,AP值有0.6%和1.0%的提升,且参数量约为其58%和65%. 当输入图像大小为384×288时,提出的网络获得了78.2%和78.5%的AP值. 与CPN[3 ] 、SimpleBaseline[4 ] 、HRNet[5 ] 、RAM-GPRNet[23 ] 、HRFormer-B[24 ] 、HRGCNet[25 ] 相比,本网络在主要的性能指标上均得到了有效的提升,实现了初步轻量化,减少了参数量和运算量. 综合而言,本文模型在估计精度上优于多数网络,关键点的识别效果较好,且在参数量和运算量方面有所降低. ...
... [25 ]相比,本网络在主要的性能指标上均得到了有效的提升,实现了初步轻量化,减少了参数量和运算量. 综合而言,本文模型在估计精度上优于多数网络,关键点的识别效果较好,且在参数量和运算量方面有所降低. ...
3
... Comparison results of average precision and average recall for different networks on COCO validation set
Tab.4 方法 预训练 输入图像尺寸 N p /106 FLOPs/109 AP/% AP0.5 /% AP0.75 /% APM /% APL /% AR/% 8-stage Hourglass[2 ] N 256×192 25.1 14.3 66.9 — — — — — CPN50[3 ] Y 256×192 27.0 6.2 68.6 — — — — — Simple Baseline152[4 ] Y 256×192 68.6 15.7 72.0 89.3 79.8 68.7 78.9 77.8 HRNet(W32)[5 ] Y 256×192 28.5 7.1 74.4 90.5 81.9 70.8 81.0 79.8 HRNet(W48)[5 ] Y 256×192 63.6 14.6 75.1 90.6 82.2 71.5 81.8 80.4 RAM-GPRNet(W32)[23 ] Y 256×192 31.4 7.7 76.0 — — — — — RAM-GPRNet(W48)[23 ] Y 256×192 70.0 15.8 76.5 — — — — — HRFormer-B[24 ] Y 256×192 43.2 12.2 75.6 90.8 82.8 71.7 82.6 80.8 HRGCNet(W32)[25 ] Y 256×192 29.6 7.11 76.6 93.6 84.6 73.9 80.7 79.3 HRGCNet(W48)[25 ] Y 256×192 64.6 14.6 77.4 93.6 84.8 74.6 81.7 80.1 AMHRNet(W32)[26 ] — 256×192 36.4 — 76.1 91.0 82.7 71.5 82.9 81.2 AMHRNet(W48)[26 ] — 256×192 71.8 — 76.4 91.1 83.1 72.2 83.3 81.4 本文方法(W32) Y 256×192 21.1 6.3 76.7 93.6 84.8 73.3 81.8 80.7 本文方法(W48) Y 256×192 46.2 12.3 77.4 93.7 85.0 74.4 82.3 81.4 CPN50[3 ] Y 384×288 — 13.9 70.6 — — — — — Simple Baseline152[4 ] Y 384×288 68.6 35.3 74.3 89.6 81.1 70.5 81.6 79.7 HRNet(W32)[5 ] Y 384×288 28.5 16.0 75.8 90.6 82.5 72.0 82.7 80.9 HRNet(W48)[5 ] Y 384×288 63.6 32.9 76.3 90.8 82.9 72.3 83.4 81.2 RAM-GPRNet(W32)[23 ] Y 384×288 31.4 17.2 77.3 — — — — — RAM-GPRNet(W48)[23 ] Y 384×288 70.0 35.6 77.7 — — — — — HRFormer-B[24 ] Y 384×288 43.2 26.8 77.2 91.0 83.6 73.2 84.2 82.0 HRGCNet(W32)[25 ] Y 384×288 29.6 16.1 78.0 93.6 84.8 75.0 82.6 80.5 HRGCNet(W48)[25 ] Y 384×288 64.6 32.9 78.4 93.6 85.8 75.3 83.5 81.3 本文方法(W32) Y 384×288 21.1 14.8 78.2 93.7 85.0 75.4 82.9 81.2 本文方法(W48) Y 384×288 46.2 28.5 78.5 93.7 85.8 75.5 83.7 81.9
表 5 在COCO测试集上不同网络的平均精度和平均召回率对比结果 ...
... [
26 ]
— 256×192 71.8 — 76.4 91.1 83.1 72.2 83.3 81.4 本文方法(W32) Y 256×192 21.1 6.3 76.7 93.6 84.8 73.3 81.8 80.7 本文方法(W48) Y 256×192 46.2 12.3 77.4 93.7 85.0 74.4 82.3 81.4 CPN50[3 ] Y 384×288 — 13.9 70.6 — — — — — Simple Baseline152[4 ] Y 384×288 68.6 35.3 74.3 89.6 81.1 70.5 81.6 79.7 HRNet(W32)[5 ] Y 384×288 28.5 16.0 75.8 90.6 82.5 72.0 82.7 80.9 HRNet(W48)[5 ] Y 384×288 63.6 32.9 76.3 90.8 82.9 72.3 83.4 81.2 RAM-GPRNet(W32)[23 ] Y 384×288 31.4 17.2 77.3 — — — — — RAM-GPRNet(W48)[23 ] Y 384×288 70.0 35.6 77.7 — — — — — HRFormer-B[24 ] Y 384×288 43.2 26.8 77.2 91.0 83.6 73.2 84.2 82.0 HRGCNet(W32)[25 ] Y 384×288 29.6 16.1 78.0 93.6 84.8 75.0 82.6 80.5 HRGCNet(W48)[25 ] Y 384×288 64.6 32.9 78.4 93.6 85.8 75.3 83.5 81.3 本文方法(W32) Y 384×288 21.1 14.8 78.2 93.7 85.0 75.4 82.9 81.2 本文方法(W48) Y 384×288 46.2 28.5 78.5 93.7 85.8 75.5 83.7 81.9 表 5 在COCO测试集上不同网络的平均精度和平均召回率对比结果 ...
... 在COCO验证集上进行对比,当输入图像大小为256×192时,提出的网络(W32)AP值达到76.7%,优于其他具有相同输入的方法. 与HRNet[5 ] 相比,AP值大幅度提高且运算量降低;与RAM-GPRNet[23 ] 相比,AP值提高了0.7%和0.9%;与HRFormer-B[24 ] 相比,实现了0.9%的AP增益;与HRGCNet[25 ] 相比,虽然AP值相近,但参数量和运算量更低;与AMHRNet[26 ] 相比,AP值有0.6%和1.0%的提升,且参数量约为其58%和65%. 当输入图像大小为384×288时,提出的网络获得了78.2%和78.5%的AP值. 与CPN[3 ] 、SimpleBaseline[4 ] 、HRNet[5 ] 、RAM-GPRNet[23 ] 、HRFormer-B[24 ] 、HRGCNet[25 ] 相比,本网络在主要的性能指标上均得到了有效的提升,实现了初步轻量化,减少了参数量和运算量. 综合而言,本文模型在估计精度上优于多数网络,关键点的识别效果较好,且在参数量和运算量方面有所降低. ...





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}