[1]
QUAN B, LIU B, FU D, et al. Improved DeepLabV3 for better road segmentation in remote sensing images [C]// 2021 International Conference on Computer Engineering and Artificial Intelligence . Shanghai: IEEE, 2021: 331–334.
[本文引用: 1]
[2]
ZHANG J, LI Y, SI Y, et al A low-grade road extraction method using SDG-DenseNet based on the fusion of optical and SAR images at decision level
[J]. Remote Sensing , 2022 , 14 (12 ): 2870
DOI:10.3390/rs14122870
[本文引用: 1]
[3]
胡春安, 陈玉玲 基于Gabor和改进 LDA的人耳识别
[J]. 计算机工程与科学 , 2015 , 37 (7 ): 1355 - 1359
[本文引用: 1]
HU Chun’an, CHEN Yuling An ear recognition algorithm based on gabor features and improved LDA
[J]. Computer Engineering and Science , 2015 , 37 (7 ): 1355 - 1359
[本文引用: 1]
[4]
邢军 基于Sobel算子数字图像的边缘检测
[J]. 微机发展 , 2005 , 15 (9 ): 48 - 49
[本文引用: 1]
XING Jun Edge detection of Sobel-based digital image
[J]. Microcomputer Development , 2005 , 15 (9 ): 48 - 49
[本文引用: 1]
[5]
SUN Q, LIU Q. The target fish’s population detection based on the improved watershed algorithm [C]// 2022 7th International Conference on Intelligent Computing and Signal Processing (ICSP) . Xi’an: IEEE, 2022: 507-510.
[本文引用: 1]
[6]
QIN J, HE Z S. A SVM face recognition method based on Gabor-featured key points [C]// 2005 International Conference on Machine Learning and Cybernetics . Guangzhou: IEEE, 2005: 5144–5149.
[本文引用: 1]
[7]
董师师, 黄哲学 随机森林理论浅析
[J]. 集成技术 , 2013 , 2 (1 ): 1 - 7
[本文引用: 1]
DONG Shishi, HUANG Zhexue A brief theoretical overview of random forests
[J]. Journal of Integration Technology , 2013 , 2 (1 ): 1 - 7
[本文引用: 1]
[9]
ZHANG Z, LIU Q, WANG Y Road extraction by deep residual U-Net
[J]. IEEE Geoscience and Remote Sensing Letters , 2018 , 15 (5 ): 749 - 753
DOI:10.1109/LGRS.2018.2802944
[本文引用: 1]
[10]
LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation [C]// 2015 IEEE Conference on Computer Vision and Pattern Recognition . Boston: IEEE, 2015: 3431–3440.
[本文引用: 1]
[11]
LIN G, MILAN A, SHEN C, et al. RefineNet: multi-path refinement networks for high-resolution semantic segmentation [C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 1925–1934.
[本文引用: 1]
[12]
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 770–778.
[本文引用: 1]
[13]
ZHAO H, SHI J, QI X, et al. Pyramid scene parsing network [C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 2881–2890.
[本文引用: 1]
[14]
CHEN L C, ZHU Y, PAPANDREOU G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation [C]// European Conference on Computer Vision . [S. l.]: Springer, 2018: 833–851.
[本文引用: 1]
[15]
HU J, SHEN L, SUN G. Squeeze-and-excitation networks [C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 7132–7141.
[本文引用: 1]
[16]
WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module [C]// European Conference on Computer Vision . [S. l.]: Springer, 2018: 3–19.
[本文引用: 1]
[17]
FU J, LIU J, TIAN H, et al. Dual attention network for scene segmentation [C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 3146–3154.
[本文引用: 1]
[18]
ZHANG W, HUANG Z, LUO G, et al. TopFormer: token pyramid transformer for mobile semantic segmentation [C]// 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 12083–12093.
[本文引用: 1]
[19]
KAISER P, WEGNER J D, LUCCHI A, et al Learning aerial image segmentation from online maps
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2017 , 55 (11 ): 6054 - 6068
DOI:10.1109/TGRS.2017.2719738
[本文引用: 1]
[20]
DEMIR I, KOPERSKI K, LINDENBAUM D, et al. Deepglobe 2018: a challenge to parse the earth through satellite images [C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops . Salt Lake City: IEEE, 2018: 172-181.
[本文引用: 1]
[21]
ZHU Q, ZHANG Y, WANG L, et al A global context-aware and batch-independent network for road extraction from VHR satellite imagery
[J]. ISPRS Journal of Photogrammetry and Remote Sensing , 2021 , 175 : 353 - 365
DOI:10.1016/j.isprsjprs.2021.03.016
[本文引用: 1]
[22]
HE T, ZHANG Z, ZHANG H, et al. Bag of tricks for image classification with convolutional neural networks [C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 558–567.
[本文引用: 1]
[23]
CHEN L C, PAPANDREOU G, SCHROFF F, et al. Rethinking atrous convolution for semantic image segmentation [EB/OL]. (2017-12-05)[2023-05-10]. https://arxiv.org/pdf/1706.05587.pdf.
[本文引用: 1]
[24]
HE J, DENG Z, ZHOU L, et al. Adaptive pyramid context network for semantic segmentation [C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 7519–7528.
[本文引用: 1]
[25]
HUANG Z, WANG X, HUANG L, et al. CCNet: criss-cross attention for semantic segmentation [C]// 2019 IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 603–612.
[本文引用: 1]
[26]
LI X, ZHONG Z, WU J, et al. Expectation-maximization attention networks for semantic segmentation [C]// 2019 IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 9167–9176.
[本文引用: 1]
[27]
YIN M, YAO Z, CAO Y, et al. Disentangled non-local neural networks [C]// European Conference on Computer Vision . [S. l.]: Springer, 2020: 191–207.
[本文引用: 1]
[28]
LI S, LIAO C, DING Y, et al Cascaded residual attention enhanced road extraction from remote sensing images
[J]. ISPRS International Journal of Geo-Information , 2022 , 11 (1 ): 9
[本文引用: 1]
[29]
HUAN H, SHENG Y, ZHANG Y, et al Strip attention networks for road extraction
[J]. Remote Sensing , 2022 , 14 (18 ): 4516
DOI:10.3390/rs14184516
[本文引用: 1]
1
... 遥感图像道路分割可以应用于地图生成、汽车自动驾驶与导航等多个场景[1 ] . 相较于一般的分割任务,遥感图像道路分割有其独特性和困难性:1)在遥感图像中,目标道路占据的画幅比例普遍偏小;2)如河流、铁路的分类对象与道路过于相似,人眼难以判别;3)道路分岔连通情况较复杂,对道路提取的识别精度有较高要求[2 ] . ...
A low-grade road extraction method using SDG-DenseNet based on the fusion of optical and SAR images at decision level
1
2022
... 遥感图像道路分割可以应用于地图生成、汽车自动驾驶与导航等多个场景[1 ] . 相较于一般的分割任务,遥感图像道路分割有其独特性和困难性:1)在遥感图像中,目标道路占据的画幅比例普遍偏小;2)如河流、铁路的分类对象与道路过于相似,人眼难以判别;3)道路分岔连通情况较复杂,对道路提取的识别精度有较高要求[2 ] . ...
基于Gabor和改进 LDA的人耳识别
1
2015
... 运用分割算法提取道路由计算机视觉(computer vision, CV)的图像分割技术发展而来. 图像分割方法大致可以分为传统算法和深度学习算法. 传统算法主要有Gabor滤波器[3 ] 、Sobel算子[4 ] 、分水岭算法[5 ] 等,还有较先进的机器学习方法,如支持向量机[6 ] (support vector machine, SVM)和随机森林[7 ] (random forests, RF). 这些方法通过提取遥感图像中的特征,如纹理、边缘、形状等,进行图像分割从而实现目标提取. 在遥感图像中,道路表现为具有连通性的狭窄线条,有些线条覆盖整幅图像且多条道路可能存在交叉连通,待提取的特征复杂且丰富,干扰也较多,因此传统的图像分割方法很难用于道路提取. 深度学习技术在计算机视觉研究领域发展迅速,该方法自动获取图像的非线性和层次特征,可以更好地解决其他道路提取方法存在的问题. 语义分割是深度学习在图像分割领域中的主要研究方向,它能较全面地利用卷积神经网络(convolutional neural networks, CNNs)[8 ] 从输入图像中提取图像的浅层和深层特征,实现端到端的像素级图像分割,具有较高的分割精度和效率. ...
基于Gabor和改进 LDA的人耳识别
1
2015
... 运用分割算法提取道路由计算机视觉(computer vision, CV)的图像分割技术发展而来. 图像分割方法大致可以分为传统算法和深度学习算法. 传统算法主要有Gabor滤波器[3 ] 、Sobel算子[4 ] 、分水岭算法[5 ] 等,还有较先进的机器学习方法,如支持向量机[6 ] (support vector machine, SVM)和随机森林[7 ] (random forests, RF). 这些方法通过提取遥感图像中的特征,如纹理、边缘、形状等,进行图像分割从而实现目标提取. 在遥感图像中,道路表现为具有连通性的狭窄线条,有些线条覆盖整幅图像且多条道路可能存在交叉连通,待提取的特征复杂且丰富,干扰也较多,因此传统的图像分割方法很难用于道路提取. 深度学习技术在计算机视觉研究领域发展迅速,该方法自动获取图像的非线性和层次特征,可以更好地解决其他道路提取方法存在的问题. 语义分割是深度学习在图像分割领域中的主要研究方向,它能较全面地利用卷积神经网络(convolutional neural networks, CNNs)[8 ] 从输入图像中提取图像的浅层和深层特征,实现端到端的像素级图像分割,具有较高的分割精度和效率. ...
基于Sobel算子数字图像的边缘检测
1
2005
... 运用分割算法提取道路由计算机视觉(computer vision, CV)的图像分割技术发展而来. 图像分割方法大致可以分为传统算法和深度学习算法. 传统算法主要有Gabor滤波器[3 ] 、Sobel算子[4 ] 、分水岭算法[5 ] 等,还有较先进的机器学习方法,如支持向量机[6 ] (support vector machine, SVM)和随机森林[7 ] (random forests, RF). 这些方法通过提取遥感图像中的特征,如纹理、边缘、形状等,进行图像分割从而实现目标提取. 在遥感图像中,道路表现为具有连通性的狭窄线条,有些线条覆盖整幅图像且多条道路可能存在交叉连通,待提取的特征复杂且丰富,干扰也较多,因此传统的图像分割方法很难用于道路提取. 深度学习技术在计算机视觉研究领域发展迅速,该方法自动获取图像的非线性和层次特征,可以更好地解决其他道路提取方法存在的问题. 语义分割是深度学习在图像分割领域中的主要研究方向,它能较全面地利用卷积神经网络(convolutional neural networks, CNNs)[8 ] 从输入图像中提取图像的浅层和深层特征,实现端到端的像素级图像分割,具有较高的分割精度和效率. ...
基于Sobel算子数字图像的边缘检测
1
2005
... 运用分割算法提取道路由计算机视觉(computer vision, CV)的图像分割技术发展而来. 图像分割方法大致可以分为传统算法和深度学习算法. 传统算法主要有Gabor滤波器[3 ] 、Sobel算子[4 ] 、分水岭算法[5 ] 等,还有较先进的机器学习方法,如支持向量机[6 ] (support vector machine, SVM)和随机森林[7 ] (random forests, RF). 这些方法通过提取遥感图像中的特征,如纹理、边缘、形状等,进行图像分割从而实现目标提取. 在遥感图像中,道路表现为具有连通性的狭窄线条,有些线条覆盖整幅图像且多条道路可能存在交叉连通,待提取的特征复杂且丰富,干扰也较多,因此传统的图像分割方法很难用于道路提取. 深度学习技术在计算机视觉研究领域发展迅速,该方法自动获取图像的非线性和层次特征,可以更好地解决其他道路提取方法存在的问题. 语义分割是深度学习在图像分割领域中的主要研究方向,它能较全面地利用卷积神经网络(convolutional neural networks, CNNs)[8 ] 从输入图像中提取图像的浅层和深层特征,实现端到端的像素级图像分割,具有较高的分割精度和效率. ...
1
... 运用分割算法提取道路由计算机视觉(computer vision, CV)的图像分割技术发展而来. 图像分割方法大致可以分为传统算法和深度学习算法. 传统算法主要有Gabor滤波器[3 ] 、Sobel算子[4 ] 、分水岭算法[5 ] 等,还有较先进的机器学习方法,如支持向量机[6 ] (support vector machine, SVM)和随机森林[7 ] (random forests, RF). 这些方法通过提取遥感图像中的特征,如纹理、边缘、形状等,进行图像分割从而实现目标提取. 在遥感图像中,道路表现为具有连通性的狭窄线条,有些线条覆盖整幅图像且多条道路可能存在交叉连通,待提取的特征复杂且丰富,干扰也较多,因此传统的图像分割方法很难用于道路提取. 深度学习技术在计算机视觉研究领域发展迅速,该方法自动获取图像的非线性和层次特征,可以更好地解决其他道路提取方法存在的问题. 语义分割是深度学习在图像分割领域中的主要研究方向,它能较全面地利用卷积神经网络(convolutional neural networks, CNNs)[8 ] 从输入图像中提取图像的浅层和深层特征,实现端到端的像素级图像分割,具有较高的分割精度和效率. ...
1
... 运用分割算法提取道路由计算机视觉(computer vision, CV)的图像分割技术发展而来. 图像分割方法大致可以分为传统算法和深度学习算法. 传统算法主要有Gabor滤波器[3 ] 、Sobel算子[4 ] 、分水岭算法[5 ] 等,还有较先进的机器学习方法,如支持向量机[6 ] (support vector machine, SVM)和随机森林[7 ] (random forests, RF). 这些方法通过提取遥感图像中的特征,如纹理、边缘、形状等,进行图像分割从而实现目标提取. 在遥感图像中,道路表现为具有连通性的狭窄线条,有些线条覆盖整幅图像且多条道路可能存在交叉连通,待提取的特征复杂且丰富,干扰也较多,因此传统的图像分割方法很难用于道路提取. 深度学习技术在计算机视觉研究领域发展迅速,该方法自动获取图像的非线性和层次特征,可以更好地解决其他道路提取方法存在的问题. 语义分割是深度学习在图像分割领域中的主要研究方向,它能较全面地利用卷积神经网络(convolutional neural networks, CNNs)[8 ] 从输入图像中提取图像的浅层和深层特征,实现端到端的像素级图像分割,具有较高的分割精度和效率. ...
随机森林理论浅析
1
2013
... 运用分割算法提取道路由计算机视觉(computer vision, CV)的图像分割技术发展而来. 图像分割方法大致可以分为传统算法和深度学习算法. 传统算法主要有Gabor滤波器[3 ] 、Sobel算子[4 ] 、分水岭算法[5 ] 等,还有较先进的机器学习方法,如支持向量机[6 ] (support vector machine, SVM)和随机森林[7 ] (random forests, RF). 这些方法通过提取遥感图像中的特征,如纹理、边缘、形状等,进行图像分割从而实现目标提取. 在遥感图像中,道路表现为具有连通性的狭窄线条,有些线条覆盖整幅图像且多条道路可能存在交叉连通,待提取的特征复杂且丰富,干扰也较多,因此传统的图像分割方法很难用于道路提取. 深度学习技术在计算机视觉研究领域发展迅速,该方法自动获取图像的非线性和层次特征,可以更好地解决其他道路提取方法存在的问题. 语义分割是深度学习在图像分割领域中的主要研究方向,它能较全面地利用卷积神经网络(convolutional neural networks, CNNs)[8 ] 从输入图像中提取图像的浅层和深层特征,实现端到端的像素级图像分割,具有较高的分割精度和效率. ...
随机森林理论浅析
1
2013
... 运用分割算法提取道路由计算机视觉(computer vision, CV)的图像分割技术发展而来. 图像分割方法大致可以分为传统算法和深度学习算法. 传统算法主要有Gabor滤波器[3 ] 、Sobel算子[4 ] 、分水岭算法[5 ] 等,还有较先进的机器学习方法,如支持向量机[6 ] (support vector machine, SVM)和随机森林[7 ] (random forests, RF). 这些方法通过提取遥感图像中的特征,如纹理、边缘、形状等,进行图像分割从而实现目标提取. 在遥感图像中,道路表现为具有连通性的狭窄线条,有些线条覆盖整幅图像且多条道路可能存在交叉连通,待提取的特征复杂且丰富,干扰也较多,因此传统的图像分割方法很难用于道路提取. 深度学习技术在计算机视觉研究领域发展迅速,该方法自动获取图像的非线性和层次特征,可以更好地解决其他道路提取方法存在的问题. 语义分割是深度学习在图像分割领域中的主要研究方向,它能较全面地利用卷积神经网络(convolutional neural networks, CNNs)[8 ] 从输入图像中提取图像的浅层和深层特征,实现端到端的像素级图像分割,具有较高的分割精度和效率. ...
Recent advances in convolutional neural networks
1
2018
... 运用分割算法提取道路由计算机视觉(computer vision, CV)的图像分割技术发展而来. 图像分割方法大致可以分为传统算法和深度学习算法. 传统算法主要有Gabor滤波器[3 ] 、Sobel算子[4 ] 、分水岭算法[5 ] 等,还有较先进的机器学习方法,如支持向量机[6 ] (support vector machine, SVM)和随机森林[7 ] (random forests, RF). 这些方法通过提取遥感图像中的特征,如纹理、边缘、形状等,进行图像分割从而实现目标提取. 在遥感图像中,道路表现为具有连通性的狭窄线条,有些线条覆盖整幅图像且多条道路可能存在交叉连通,待提取的特征复杂且丰富,干扰也较多,因此传统的图像分割方法很难用于道路提取. 深度学习技术在计算机视觉研究领域发展迅速,该方法自动获取图像的非线性和层次特征,可以更好地解决其他道路提取方法存在的问题. 语义分割是深度学习在图像分割领域中的主要研究方向,它能较全面地利用卷积神经网络(convolutional neural networks, CNNs)[8 ] 从输入图像中提取图像的浅层和深层特征,实现端到端的像素级图像分割,具有较高的分割精度和效率. ...
Road extraction by deep residual U-Net
1
2018
... 学者针对高分辨率的道路图像提取提出的深度学习研究方法不少,但类间相似度高、噪声干扰多、狭窄道路难提取等难点仍有待克服[9 ] . Long等[10 ] 提出不包含全连接层的全卷积网络(fully convolutional networks, FCN). FCN将CNN最后的全连接层替换为卷积层,称为反卷积,利用反卷积对最后一个卷积层的特征图进行上采样,使最后一个卷积层恢复到输入图像相同的尺寸,在预测每个像素的同时保留空间信息. FCN可以适应任意尺寸输入图像,并且通过不同层之间的跳跃连接同时确保了网络的鲁棒性和精确性,但是FCN不能充分提取上下文信息,语义分割精度较差. 基于FCN改进的U-Net[11 ] 采用编解码的网络结构,它可以充分利用像素的位置信息,在训练集样本较少时仍可保持一定的分割精度. 残差神经网络(deep residual networks, ResNet)[12 ] 避免了因增加网络深度造成的模型过拟合、梯度消失和梯度爆炸问题,被广泛应用于特征提取网络中. Zhao等[13 ] 提出的金字塔场景解析网络(pyramid scene parsing network, PSPNet)使用金字塔池化模块,Chen等[14 ] 提出的DeepLabV3+网络使用空洞空间金字塔池化(atrous spatial pyramid pooling, ASPP)获取并引入解码模块恢复便捷信息,这2个网络均提取多尺度的语义信息进行融合,提高了分割精度,但它们只关注宏观的空间位置信息,对细节方面的信息关注不足. ...
1
... 学者针对高分辨率的道路图像提取提出的深度学习研究方法不少,但类间相似度高、噪声干扰多、狭窄道路难提取等难点仍有待克服[9 ] . Long等[10 ] 提出不包含全连接层的全卷积网络(fully convolutional networks, FCN). FCN将CNN最后的全连接层替换为卷积层,称为反卷积,利用反卷积对最后一个卷积层的特征图进行上采样,使最后一个卷积层恢复到输入图像相同的尺寸,在预测每个像素的同时保留空间信息. FCN可以适应任意尺寸输入图像,并且通过不同层之间的跳跃连接同时确保了网络的鲁棒性和精确性,但是FCN不能充分提取上下文信息,语义分割精度较差. 基于FCN改进的U-Net[11 ] 采用编解码的网络结构,它可以充分利用像素的位置信息,在训练集样本较少时仍可保持一定的分割精度. 残差神经网络(deep residual networks, ResNet)[12 ] 避免了因增加网络深度造成的模型过拟合、梯度消失和梯度爆炸问题,被广泛应用于特征提取网络中. Zhao等[13 ] 提出的金字塔场景解析网络(pyramid scene parsing network, PSPNet)使用金字塔池化模块,Chen等[14 ] 提出的DeepLabV3+网络使用空洞空间金字塔池化(atrous spatial pyramid pooling, ASPP)获取并引入解码模块恢复便捷信息,这2个网络均提取多尺度的语义信息进行融合,提高了分割精度,但它们只关注宏观的空间位置信息,对细节方面的信息关注不足. ...
1
... 学者针对高分辨率的道路图像提取提出的深度学习研究方法不少,但类间相似度高、噪声干扰多、狭窄道路难提取等难点仍有待克服[9 ] . Long等[10 ] 提出不包含全连接层的全卷积网络(fully convolutional networks, FCN). FCN将CNN最后的全连接层替换为卷积层,称为反卷积,利用反卷积对最后一个卷积层的特征图进行上采样,使最后一个卷积层恢复到输入图像相同的尺寸,在预测每个像素的同时保留空间信息. FCN可以适应任意尺寸输入图像,并且通过不同层之间的跳跃连接同时确保了网络的鲁棒性和精确性,但是FCN不能充分提取上下文信息,语义分割精度较差. 基于FCN改进的U-Net[11 ] 采用编解码的网络结构,它可以充分利用像素的位置信息,在训练集样本较少时仍可保持一定的分割精度. 残差神经网络(deep residual networks, ResNet)[12 ] 避免了因增加网络深度造成的模型过拟合、梯度消失和梯度爆炸问题,被广泛应用于特征提取网络中. Zhao等[13 ] 提出的金字塔场景解析网络(pyramid scene parsing network, PSPNet)使用金字塔池化模块,Chen等[14 ] 提出的DeepLabV3+网络使用空洞空间金字塔池化(atrous spatial pyramid pooling, ASPP)获取并引入解码模块恢复便捷信息,这2个网络均提取多尺度的语义信息进行融合,提高了分割精度,但它们只关注宏观的空间位置信息,对细节方面的信息关注不足. ...
1
... 学者针对高分辨率的道路图像提取提出的深度学习研究方法不少,但类间相似度高、噪声干扰多、狭窄道路难提取等难点仍有待克服[9 ] . Long等[10 ] 提出不包含全连接层的全卷积网络(fully convolutional networks, FCN). FCN将CNN最后的全连接层替换为卷积层,称为反卷积,利用反卷积对最后一个卷积层的特征图进行上采样,使最后一个卷积层恢复到输入图像相同的尺寸,在预测每个像素的同时保留空间信息. FCN可以适应任意尺寸输入图像,并且通过不同层之间的跳跃连接同时确保了网络的鲁棒性和精确性,但是FCN不能充分提取上下文信息,语义分割精度较差. 基于FCN改进的U-Net[11 ] 采用编解码的网络结构,它可以充分利用像素的位置信息,在训练集样本较少时仍可保持一定的分割精度. 残差神经网络(deep residual networks, ResNet)[12 ] 避免了因增加网络深度造成的模型过拟合、梯度消失和梯度爆炸问题,被广泛应用于特征提取网络中. Zhao等[13 ] 提出的金字塔场景解析网络(pyramid scene parsing network, PSPNet)使用金字塔池化模块,Chen等[14 ] 提出的DeepLabV3+网络使用空洞空间金字塔池化(atrous spatial pyramid pooling, ASPP)获取并引入解码模块恢复便捷信息,这2个网络均提取多尺度的语义信息进行融合,提高了分割精度,但它们只关注宏观的空间位置信息,对细节方面的信息关注不足. ...
1
... 学者针对高分辨率的道路图像提取提出的深度学习研究方法不少,但类间相似度高、噪声干扰多、狭窄道路难提取等难点仍有待克服[9 ] . Long等[10 ] 提出不包含全连接层的全卷积网络(fully convolutional networks, FCN). FCN将CNN最后的全连接层替换为卷积层,称为反卷积,利用反卷积对最后一个卷积层的特征图进行上采样,使最后一个卷积层恢复到输入图像相同的尺寸,在预测每个像素的同时保留空间信息. FCN可以适应任意尺寸输入图像,并且通过不同层之间的跳跃连接同时确保了网络的鲁棒性和精确性,但是FCN不能充分提取上下文信息,语义分割精度较差. 基于FCN改进的U-Net[11 ] 采用编解码的网络结构,它可以充分利用像素的位置信息,在训练集样本较少时仍可保持一定的分割精度. 残差神经网络(deep residual networks, ResNet)[12 ] 避免了因增加网络深度造成的模型过拟合、梯度消失和梯度爆炸问题,被广泛应用于特征提取网络中. Zhao等[13 ] 提出的金字塔场景解析网络(pyramid scene parsing network, PSPNet)使用金字塔池化模块,Chen等[14 ] 提出的DeepLabV3+网络使用空洞空间金字塔池化(atrous spatial pyramid pooling, ASPP)获取并引入解码模块恢复便捷信息,这2个网络均提取多尺度的语义信息进行融合,提高了分割精度,但它们只关注宏观的空间位置信息,对细节方面的信息关注不足. ...
1
... 学者针对高分辨率的道路图像提取提出的深度学习研究方法不少,但类间相似度高、噪声干扰多、狭窄道路难提取等难点仍有待克服[9 ] . Long等[10 ] 提出不包含全连接层的全卷积网络(fully convolutional networks, FCN). FCN将CNN最后的全连接层替换为卷积层,称为反卷积,利用反卷积对最后一个卷积层的特征图进行上采样,使最后一个卷积层恢复到输入图像相同的尺寸,在预测每个像素的同时保留空间信息. FCN可以适应任意尺寸输入图像,并且通过不同层之间的跳跃连接同时确保了网络的鲁棒性和精确性,但是FCN不能充分提取上下文信息,语义分割精度较差. 基于FCN改进的U-Net[11 ] 采用编解码的网络结构,它可以充分利用像素的位置信息,在训练集样本较少时仍可保持一定的分割精度. 残差神经网络(deep residual networks, ResNet)[12 ] 避免了因增加网络深度造成的模型过拟合、梯度消失和梯度爆炸问题,被广泛应用于特征提取网络中. Zhao等[13 ] 提出的金字塔场景解析网络(pyramid scene parsing network, PSPNet)使用金字塔池化模块,Chen等[14 ] 提出的DeepLabV3+网络使用空洞空间金字塔池化(atrous spatial pyramid pooling, ASPP)获取并引入解码模块恢复便捷信息,这2个网络均提取多尺度的语义信息进行融合,提高了分割精度,但它们只关注宏观的空间位置信息,对细节方面的信息关注不足. ...
1
... 注意力机制使神经网络具备专注于输入图像的某些重点部分的能力. Hu等[15 ] 提出挤压激励网络(squeeze-and-excitation networks, SE-Net),将通道注意力机制加入主干网,提升了特征提取的效率. Woo等[16 ] 提出卷积块注意模块(convolutional block attention module, CBAM),此模块将全局最大池化加入SE模块,同时引入空间注意力机制,有效地提取了特征图内的位置相关信息. Fu等[17 ] 提出的双重注意网络(dual attention network, DANet)使用2种类型的注意力模块,分别模拟空间维度和通道维度中的语义相互依赖性,通过对局部特征的上下文依赖关系进行建模,显著改善了分割结果. Zhang等[18 ] 提出上下文先验网络移动语义分割的令牌金字塔转换器,设计金字塔形式的视觉转换器,平衡了分割精度与速度,减少了数据量,完成了困难样本的较快速分割. ...
1
... 注意力机制使神经网络具备专注于输入图像的某些重点部分的能力. Hu等[15 ] 提出挤压激励网络(squeeze-and-excitation networks, SE-Net),将通道注意力机制加入主干网,提升了特征提取的效率. Woo等[16 ] 提出卷积块注意模块(convolutional block attention module, CBAM),此模块将全局最大池化加入SE模块,同时引入空间注意力机制,有效地提取了特征图内的位置相关信息. Fu等[17 ] 提出的双重注意网络(dual attention network, DANet)使用2种类型的注意力模块,分别模拟空间维度和通道维度中的语义相互依赖性,通过对局部特征的上下文依赖关系进行建模,显著改善了分割结果. Zhang等[18 ] 提出上下文先验网络移动语义分割的令牌金字塔转换器,设计金字塔形式的视觉转换器,平衡了分割精度与速度,减少了数据量,完成了困难样本的较快速分割. ...
1
... 注意力机制使神经网络具备专注于输入图像的某些重点部分的能力. Hu等[15 ] 提出挤压激励网络(squeeze-and-excitation networks, SE-Net),将通道注意力机制加入主干网,提升了特征提取的效率. Woo等[16 ] 提出卷积块注意模块(convolutional block attention module, CBAM),此模块将全局最大池化加入SE模块,同时引入空间注意力机制,有效地提取了特征图内的位置相关信息. Fu等[17 ] 提出的双重注意网络(dual attention network, DANet)使用2种类型的注意力模块,分别模拟空间维度和通道维度中的语义相互依赖性,通过对局部特征的上下文依赖关系进行建模,显著改善了分割结果. Zhang等[18 ] 提出上下文先验网络移动语义分割的令牌金字塔转换器,设计金字塔形式的视觉转换器,平衡了分割精度与速度,减少了数据量,完成了困难样本的较快速分割. ...
1
... 注意力机制使神经网络具备专注于输入图像的某些重点部分的能力. Hu等[15 ] 提出挤压激励网络(squeeze-and-excitation networks, SE-Net),将通道注意力机制加入主干网,提升了特征提取的效率. Woo等[16 ] 提出卷积块注意模块(convolutional block attention module, CBAM),此模块将全局最大池化加入SE模块,同时引入空间注意力机制,有效地提取了特征图内的位置相关信息. Fu等[17 ] 提出的双重注意网络(dual attention network, DANet)使用2种类型的注意力模块,分别模拟空间维度和通道维度中的语义相互依赖性,通过对局部特征的上下文依赖关系进行建模,显著改善了分割结果. Zhang等[18 ] 提出上下文先验网络移动语义分割的令牌金字塔转换器,设计金字塔形式的视觉转换器,平衡了分割精度与速度,减少了数据量,完成了困难样本的较快速分割. ...
Learning aerial image segmentation from online maps
1
2017
... 采用3个数据集进行训练与测试,分别为CITY-OSM数据集[19 ] 、DeepGlobe道路提取遥感地图数据集[20 ] 和CHN6-CUG数据集[21 ] . CITY-OSM数据集使用柏林和巴黎的谷歌地图高分辨率RGB正射影像,共有825幅图像,每幅图像为2 611×2 453像素. 按照4∶1的比例随机抽取,其中660幅图像作为训练集,剩余165幅图像作为测试集. CITY-OSM数据集有背景、建筑物和道路3个类别. DeepGlobe道路提取遥感地图数据集共有6 226幅遥感图像,每幅图像为1 500$ \times $ 1 500像素,按照4∶1的比例随机抽取,其中4 981幅图像作为训练集,剩余1 245幅图像作为测试集. 该数据集的图像拍摄于泰国、印度、印度尼西亚等地,图像场景包括城市、乡村、荒郊、海滨、热带雨林等,数据集有道路和背景2个类别. CHN6-CUG数据集是中国代表性城市大尺度卫星影像数据集,遥感影像底图来自谷歌地球. 在该数据集中,根据道路覆盖的程度,标记道路由覆盖道路和未覆盖道路组成;根据地理因素的物理角度,标示道路包括铁路、公路、城市道路和农村道路等. CHN6-CUG数据集共有4 511幅遥感图像,每幅图像为512×512像素,按照4∶1的比例随机抽取,其中3608幅图像作为训练集,剩余903幅图像作为测试集. ...
1
... 采用3个数据集进行训练与测试,分别为CITY-OSM数据集[19 ] 、DeepGlobe道路提取遥感地图数据集[20 ] 和CHN6-CUG数据集[21 ] . CITY-OSM数据集使用柏林和巴黎的谷歌地图高分辨率RGB正射影像,共有825幅图像,每幅图像为2 611×2 453像素. 按照4∶1的比例随机抽取,其中660幅图像作为训练集,剩余165幅图像作为测试集. CITY-OSM数据集有背景、建筑物和道路3个类别. DeepGlobe道路提取遥感地图数据集共有6 226幅遥感图像,每幅图像为1 500$ \times $ 1 500像素,按照4∶1的比例随机抽取,其中4 981幅图像作为训练集,剩余1 245幅图像作为测试集. 该数据集的图像拍摄于泰国、印度、印度尼西亚等地,图像场景包括城市、乡村、荒郊、海滨、热带雨林等,数据集有道路和背景2个类别. CHN6-CUG数据集是中国代表性城市大尺度卫星影像数据集,遥感影像底图来自谷歌地球. 在该数据集中,根据道路覆盖的程度,标记道路由覆盖道路和未覆盖道路组成;根据地理因素的物理角度,标示道路包括铁路、公路、城市道路和农村道路等. CHN6-CUG数据集共有4 511幅遥感图像,每幅图像为512×512像素,按照4∶1的比例随机抽取,其中3608幅图像作为训练集,剩余903幅图像作为测试集. ...
A global context-aware and batch-independent network for road extraction from VHR satellite imagery
1
2021
... 采用3个数据集进行训练与测试,分别为CITY-OSM数据集[19 ] 、DeepGlobe道路提取遥感地图数据集[20 ] 和CHN6-CUG数据集[21 ] . CITY-OSM数据集使用柏林和巴黎的谷歌地图高分辨率RGB正射影像,共有825幅图像,每幅图像为2 611×2 453像素. 按照4∶1的比例随机抽取,其中660幅图像作为训练集,剩余165幅图像作为测试集. CITY-OSM数据集有背景、建筑物和道路3个类别. DeepGlobe道路提取遥感地图数据集共有6 226幅遥感图像,每幅图像为1 500$ \times $ 1 500像素,按照4∶1的比例随机抽取,其中4 981幅图像作为训练集,剩余1 245幅图像作为测试集. 该数据集的图像拍摄于泰国、印度、印度尼西亚等地,图像场景包括城市、乡村、荒郊、海滨、热带雨林等,数据集有道路和背景2个类别. CHN6-CUG数据集是中国代表性城市大尺度卫星影像数据集,遥感影像底图来自谷歌地球. 在该数据集中,根据道路覆盖的程度,标记道路由覆盖道路和未覆盖道路组成;根据地理因素的物理角度,标示道路包括铁路、公路、城市道路和农村道路等. CHN6-CUG数据集共有4 511幅遥感图像,每幅图像为512×512像素,按照4∶1的比例随机抽取,其中3608幅图像作为训练集,剩余903幅图像作为测试集. ...
1
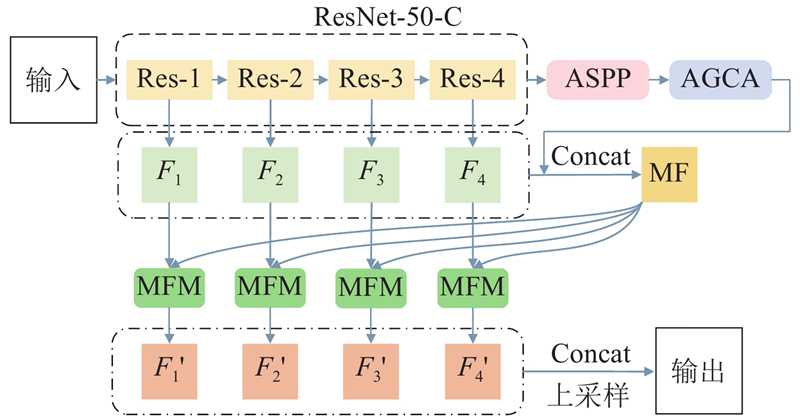
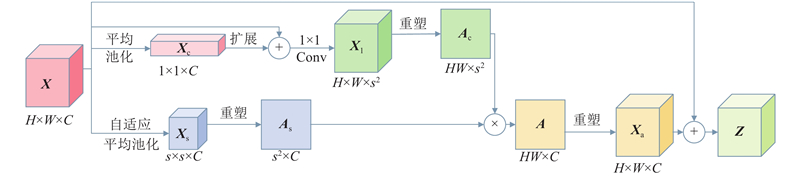
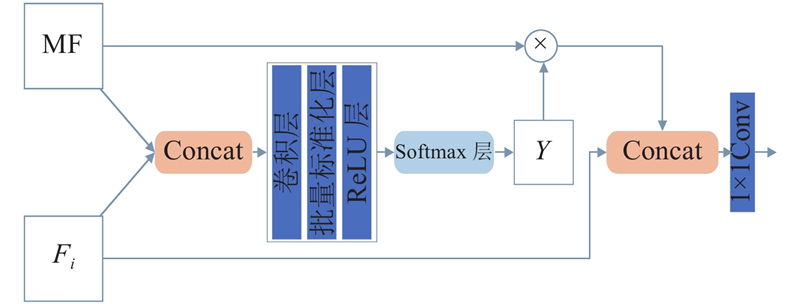
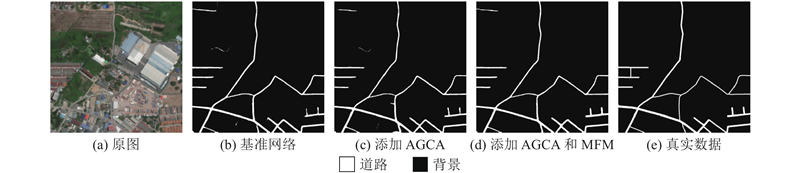
... GGMNet的整体结构如图1 所示. 网络的主干部分采用ResNet-50-C[22 ] 来提取输入图像的特征. 网络保留阶段Res-1~Res-4的4个结果,并对Res-2~Res-4的结果进行上采样,获得3个与Res-1结果的尺度相同的结果,分别为$ {F}_{1}、{F}_{2}、{F}_{3}、{F}_{4} $ . 将Res-4的结果输入ASPP,以提取深层特征图中的全局信息和多尺度信息. 再将ASPP的输出作为AGCA的输入,利用AGCA提取特征图的类别信息. 对AGCA的结果进行上采样并与之前的4个结果进行融合,得到多层特征(multi-layer features, MF). 分别将$ {F}_{1}、{F}_{2}、{F}_{3}、{F}_{4} $ $ \mathrm{M}\mathrm{F} $ $ {F}_{1}'、{F}_{2}'、{F}_{3}'、{F}_{4}' $ . 融合这4个结果并进行上采样,得到最终的分割结果. ...
1
... 对比不同网络在道路提取中的性能,使用DeepLabV3[23 ] 、APCNet[24 ] 、CCNet[25 ] 、DANet、EMANet[26 ] 、DNLNet[27 ] 、CRANet[28 ] 、SANet[29 ] 与所提网络进行对比. APCNet融合多尺度、自适应和全局指导局部亲和力3个要素设计网络,道路分割性能较好;DANet通过建模通道注意力和空间注意力来提取特征;EMANet设计期望最大化注意力机制(EMA),摒弃在全图上计算注意力图的流程,转而通过期望最大化(EM)算法迭代出一组紧凑的基,在这组基上运行注意力机制,大大降低了复杂度;DNLNet设计解耦non-local模块,增加通道间的位置信息的交互,增加了道路分割的精确度和效率;CRANet通过使用级联的残差注意力模块来提取遥感图像中边界细化的道路,该结构利用多尺度特征上的空间注意残块来捕获长距离关系,并引入通道注意里模块来优化多尺度特征融合,并且设计轻量级编码器-解码器网络,以自适应优化提取的道路边界. ...
1
... 对比不同网络在道路提取中的性能,使用DeepLabV3[23 ] 、APCNet[24 ] 、CCNet[25 ] 、DANet、EMANet[26 ] 、DNLNet[27 ] 、CRANet[28 ] 、SANet[29 ] 与所提网络进行对比. APCNet融合多尺度、自适应和全局指导局部亲和力3个要素设计网络,道路分割性能较好;DANet通过建模通道注意力和空间注意力来提取特征;EMANet设计期望最大化注意力机制(EMA),摒弃在全图上计算注意力图的流程,转而通过期望最大化(EM)算法迭代出一组紧凑的基,在这组基上运行注意力机制,大大降低了复杂度;DNLNet设计解耦non-local模块,增加通道间的位置信息的交互,增加了道路分割的精确度和效率;CRANet通过使用级联的残差注意力模块来提取遥感图像中边界细化的道路,该结构利用多尺度特征上的空间注意残块来捕获长距离关系,并引入通道注意里模块来优化多尺度特征融合,并且设计轻量级编码器-解码器网络,以自适应优化提取的道路边界. ...
1
... 对比不同网络在道路提取中的性能,使用DeepLabV3[23 ] 、APCNet[24 ] 、CCNet[25 ] 、DANet、EMANet[26 ] 、DNLNet[27 ] 、CRANet[28 ] 、SANet[29 ] 与所提网络进行对比. APCNet融合多尺度、自适应和全局指导局部亲和力3个要素设计网络,道路分割性能较好;DANet通过建模通道注意力和空间注意力来提取特征;EMANet设计期望最大化注意力机制(EMA),摒弃在全图上计算注意力图的流程,转而通过期望最大化(EM)算法迭代出一组紧凑的基,在这组基上运行注意力机制,大大降低了复杂度;DNLNet设计解耦non-local模块,增加通道间的位置信息的交互,增加了道路分割的精确度和效率;CRANet通过使用级联的残差注意力模块来提取遥感图像中边界细化的道路,该结构利用多尺度特征上的空间注意残块来捕获长距离关系,并引入通道注意里模块来优化多尺度特征融合,并且设计轻量级编码器-解码器网络,以自适应优化提取的道路边界. ...
1
... 对比不同网络在道路提取中的性能,使用DeepLabV3[23 ] 、APCNet[24 ] 、CCNet[25 ] 、DANet、EMANet[26 ] 、DNLNet[27 ] 、CRANet[28 ] 、SANet[29 ] 与所提网络进行对比. APCNet融合多尺度、自适应和全局指导局部亲和力3个要素设计网络,道路分割性能较好;DANet通过建模通道注意力和空间注意力来提取特征;EMANet设计期望最大化注意力机制(EMA),摒弃在全图上计算注意力图的流程,转而通过期望最大化(EM)算法迭代出一组紧凑的基,在这组基上运行注意力机制,大大降低了复杂度;DNLNet设计解耦non-local模块,增加通道间的位置信息的交互,增加了道路分割的精确度和效率;CRANet通过使用级联的残差注意力模块来提取遥感图像中边界细化的道路,该结构利用多尺度特征上的空间注意残块来捕获长距离关系,并引入通道注意里模块来优化多尺度特征融合,并且设计轻量级编码器-解码器网络,以自适应优化提取的道路边界. ...
1
... 对比不同网络在道路提取中的性能,使用DeepLabV3[23 ] 、APCNet[24 ] 、CCNet[25 ] 、DANet、EMANet[26 ] 、DNLNet[27 ] 、CRANet[28 ] 、SANet[29 ] 与所提网络进行对比. APCNet融合多尺度、自适应和全局指导局部亲和力3个要素设计网络,道路分割性能较好;DANet通过建模通道注意力和空间注意力来提取特征;EMANet设计期望最大化注意力机制(EMA),摒弃在全图上计算注意力图的流程,转而通过期望最大化(EM)算法迭代出一组紧凑的基,在这组基上运行注意力机制,大大降低了复杂度;DNLNet设计解耦non-local模块,增加通道间的位置信息的交互,增加了道路分割的精确度和效率;CRANet通过使用级联的残差注意力模块来提取遥感图像中边界细化的道路,该结构利用多尺度特征上的空间注意残块来捕获长距离关系,并引入通道注意里模块来优化多尺度特征融合,并且设计轻量级编码器-解码器网络,以自适应优化提取的道路边界. ...
Cascaded residual attention enhanced road extraction from remote sensing images
1
2022
... 对比不同网络在道路提取中的性能,使用DeepLabV3[23 ] 、APCNet[24 ] 、CCNet[25 ] 、DANet、EMANet[26 ] 、DNLNet[27 ] 、CRANet[28 ] 、SANet[29 ] 与所提网络进行对比. APCNet融合多尺度、自适应和全局指导局部亲和力3个要素设计网络,道路分割性能较好;DANet通过建模通道注意力和空间注意力来提取特征;EMANet设计期望最大化注意力机制(EMA),摒弃在全图上计算注意力图的流程,转而通过期望最大化(EM)算法迭代出一组紧凑的基,在这组基上运行注意力机制,大大降低了复杂度;DNLNet设计解耦non-local模块,增加通道间的位置信息的交互,增加了道路分割的精确度和效率;CRANet通过使用级联的残差注意力模块来提取遥感图像中边界细化的道路,该结构利用多尺度特征上的空间注意残块来捕获长距离关系,并引入通道注意里模块来优化多尺度特征融合,并且设计轻量级编码器-解码器网络,以自适应优化提取的道路边界. ...
Strip attention networks for road extraction
1
2022
... 对比不同网络在道路提取中的性能,使用DeepLabV3[23 ] 、APCNet[24 ] 、CCNet[25 ] 、DANet、EMANet[26 ] 、DNLNet[27 ] 、CRANet[28 ] 、SANet[29 ] 与所提网络进行对比. APCNet融合多尺度、自适应和全局指导局部亲和力3个要素设计网络,道路分割性能较好;DANet通过建模通道注意力和空间注意力来提取特征;EMANet设计期望最大化注意力机制(EMA),摒弃在全图上计算注意力图的流程,转而通过期望最大化(EM)算法迭代出一组紧凑的基,在这组基上运行注意力机制,大大降低了复杂度;DNLNet设计解耦non-local模块,增加通道间的位置信息的交互,增加了道路分割的精确度和效率;CRANet通过使用级联的残差注意力模块来提取遥感图像中边界细化的道路,该结构利用多尺度特征上的空间注意残块来捕获长距离关系,并引入通道注意里模块来优化多尺度特征融合,并且设计轻量级编码器-解码器网络,以自适应优化提取的道路边界. ...










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}