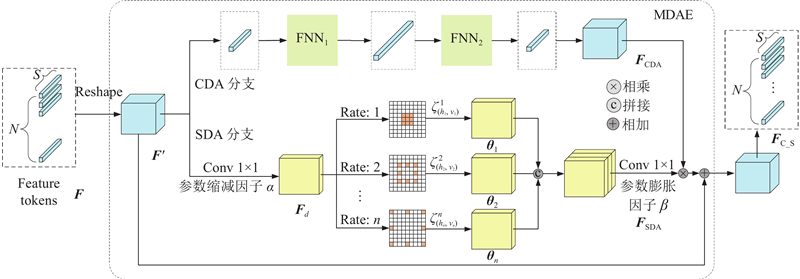
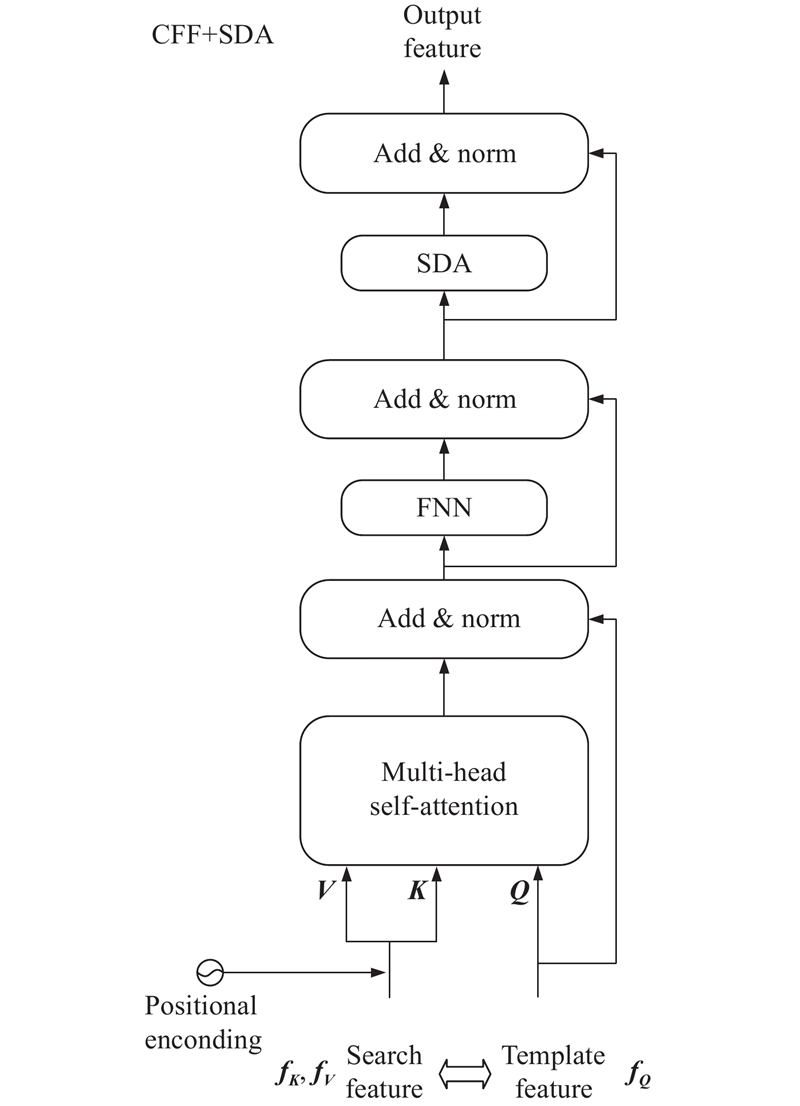
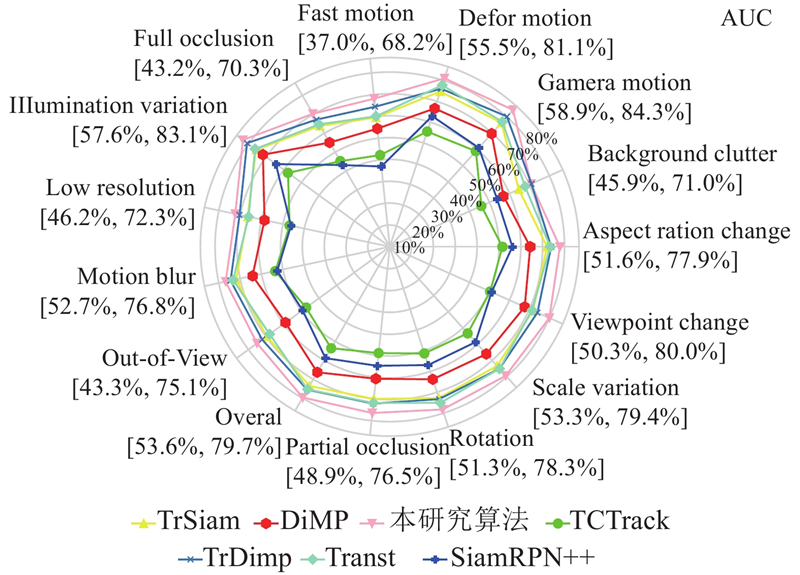
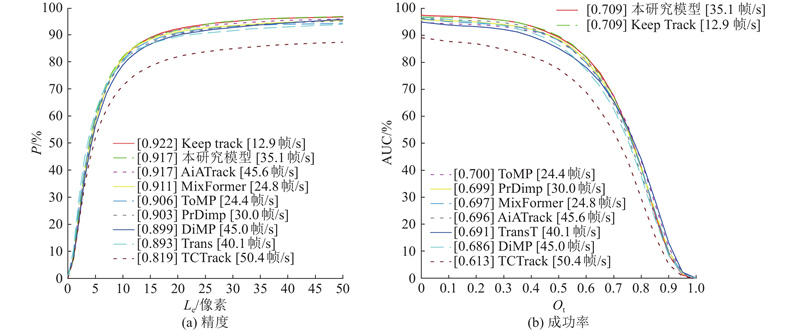
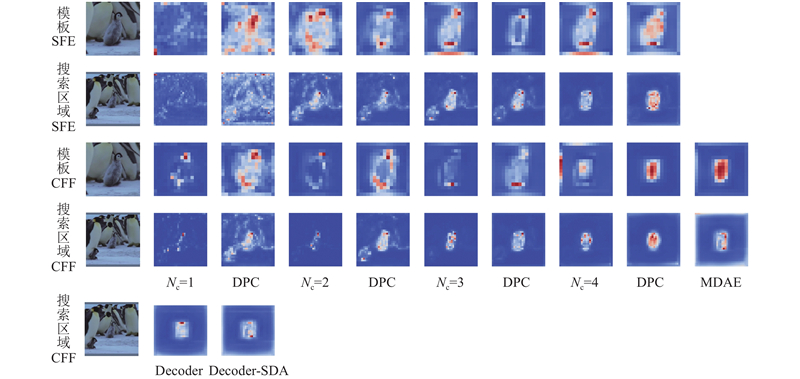
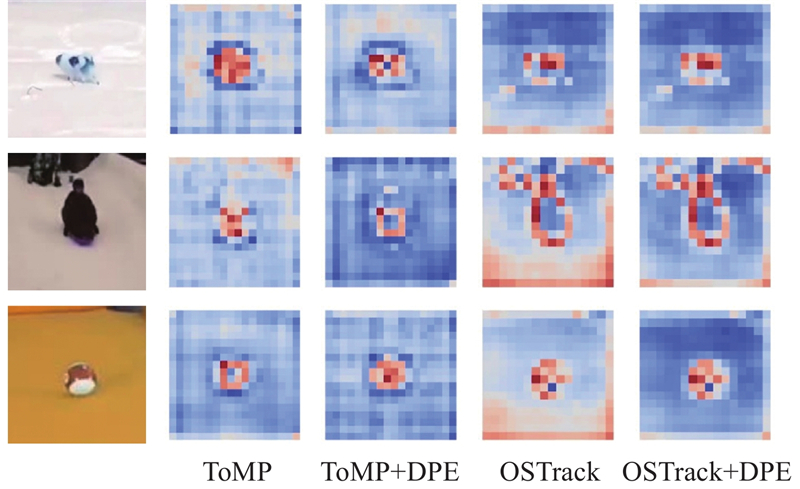
| 计算机技术 |
|

|
|
|
| 基于动态位置编码和注意力增强的目标跟踪算法 |
熊昌镇( ),郭传玺,王聪 ),郭传玺,王聪 |
| 北方工业大学 城市道路交通智能控制技术北京市重点实验室,北京 100144 |
|
| Target tracking algorithm based on dynamic position encoding and attention enhancement |
| Changzhen XIONG(),Chuanxi GUO,Cong WANG |
| Beijing Key Laboratory of Urban Road Transportation Intelligent Control Technology, North China University of Technology, Beijing 100144, China |
| 1 |
韩瑞泽, 冯伟, 郭青, 等 视频单目标跟踪研究进展综述[J]. 计算机学报, 2022, 45 (9): 1877- 1907
HAN Ruize, FENG Wei, GUO Qing, et al Single object tracking research: a survey[J]. Chinese Journal of Computers, 2022, 45 (9): 1877- 1907
doi: 10.11897/SP.J.1016.2022.01877
|
| 2 |
卢湖川, 李佩霞, 王栋 目标跟踪算法综述[J]. 模式识别与人工智能, 2018, 31 (1): 61- 76
LU Huchuan, LI Peixia, WANG Dong Visual object tracking: a survey[J]. Pattern Recognition and Artificial Intelligence, 2018, 31 (1): 61- 76
|
| 3 |
BERTINETTO L, VALMADRE J, HENRIQUES J F, et al. Fully-convolutional siamese networks for object tracking [C]// 14th European Conference on Computer Vision . Amsterdam: Springer, 2016: 850–865.
|
| 4 |
陈志旺, 张忠新, 宋娟, 等 基于目标感知特征筛选的孪生网络跟踪算法[J]. 光学学报, 2020, 40 (9): 110- 126
CHEN Zhiwang, ZHANG Zhongxin, SONG Juan, et al Tracking algorithm for siamese network based on target-aware feature selection[J]. Acta Optica Sinica, 2020, 40 (9): 110- 126
|
| 5 |
陈法领, 丁庆海, 罗海波, 等 基于自适应多层卷积特征决策融合的目标跟踪[J]. 光学学报, 2020, 40 (23): 175- 187
CHEN Faling, DING Qinghai, LUO Haibo, et al Target tracking based on adaptive multilayer convolutional feature decision fusion[J]. Acta Optica Sinica, 2020, 40 (23): 175- 187
|
| 6 |
LI B, YAN J, WU W, et al. High performance visual tracking with Siamese region proposal network [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . New York: IEEE, 2018: 8971–8980.
|
| 7 |
ZHANG Z, PENG H, FU J, et al. ocean: object-aware anchor-free tracking [C]// 16th European Conference on Computer Vision . Glasgow : Springer, 2020: 771–787.
|
| 8 |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// 31st Annual Conference on Neural Information Processing Systems . Long Beach: IEEE, 2017: 5998–6010.
|
| 9 |
WANG N, ZHOU W, WANG J, et al. Transformer meets tracker: exploiting temporal context for robust visual tracking [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . [s.l.]: IEEE, 2021: 1571–1580.
|
| 10 |
CHEN X, YAN B, ZHU J, et al. Transformer tracking [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . [s.l.]: IEEE, 2021: 8126–8135.
|
| 11 |
GAO S, ZHOU C, MA C, et al. Aiatrack: attention in attention for transformer visual tracking [C]// 17th European Conference on Computer Vision . Tel Aviv: Springer, 2022: 146–164.
|
| 12 |
CAO Z, HUANG Z, PAN L, et al. TCTrack: temporal contexts for aerial tracking [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 14798–14808.
|
| 13 |
MAYER C, DANELLJAN M, PAUDEL D P, et al. Learning target candidate association to keep track of what not to track [C]// 18th IEEE/CVF International Conference on Computer Vision . [s.l.]: IEEE, 2021: 13444–1345.
|
| 14 |
MAYER C, DANELLJAN M, BHAT G, et al. Transforming model prediction for tracking [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 8731–8740.
|
| 15 |
CUI Y, JIANG C, WANG L, et al. Mixformer: end-to-end tracking with iterative mixed attention [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 13608–13618.
|
| 16 |
WU Q, YANG T, LIU Z, et al. Dropmae: masked autoencoders with spatial-attention dropout for tracking tasks [C]// 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition . New York: IEEE, 2023: 14561–14571.
|
| 17 |
CHEN X, PENG H, WANG D, et al. Seqtrack: sequence to sequence learning for visual object tracking [C]// 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition . New York: IEEE, 2023: 14572–14581.
|
| 18 |
CHU X, TIAN Z, ZHANG B, et al. Conditional positional encodings for vision transformers. (2021-02-22)[2023-10-10]. https://www.arxiv.org/abs/2102.10882v2.
|
| 19 |
WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module [C]// 15th European Conference on Computer Vision . Munich: Springer, 2018: 3–19.
|
| 20 |
WANG C, XU H, ZHANG X, et al. Convolutional embedding makes hierarchical vision transformer stronger [C]// 17th European Conference on Computer Vision . Tel Aviv: Springer, 2022: 739–756.
|
| 21 |
LI B, WU W, WANG Q, et al. Siamrpn++: evolution of siamese visual tracking with very deep networks [C]// 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 15–20.
|
| 22 |
DANELLJAN M, BHAT G, KHAN F S, et al. ATOM: accurate tracking by overlap maximization [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 4660–4669.
|
| 23 |
BHAT G, DANELLJAN M, GOOL L V, et al. Learning discriminative model prediction for tracking [C]// IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 6182–6191.
|
| 24 |
BHAT G, DANELLJAN M, VAN G L, et al. Know your surroundings: exploiting scene information for object tracking [C]// 16th European Conference on Computer Vision . Glasgow: Springer, 2020: 205–221.
|
| 25 |
YU B, TANG M, ZHENG L, et al. High-performance discriminative tracking with transformers [C]// 18th IEEE/CVF International Conference on Computer Vision . [s.l.]: IEEE, 2021: 9856–9865.
|
| 26 |
DANELLJAN M, GOOL L V, TIMOFTE R. Probabilistic regression for visual tracking [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . [s.l.]: IEEE, 2020: 7183–7192.
|
| 27 |
YAN B, PENG H, FU J, et al. Learning spatio-temporal transformer for visual tracking [C]// 18th IEEE/CVF International Conference on Computer Vision . [s.l.]: IEEE, 2021: 10448–10457.
|
| 28 |
ZHONG M, CHEN F, XU J, et al. Correlation-based transformer tracking [C]// 31st International Conference on Artificial Neural Networks . Bristol: European Neural Networks Soc, 2022: 85–96.
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|