[1]
韩瑞泽, 冯伟, 郭青, 等 视频单目标跟踪研究进展综述
[J]. 计算机学报 , 2022 , 45 (9 ): 1877 - 1907
DOI:10.11897/SP.J.1016.2022.01877
[本文引用: 1]
HAN Ruize, FENG Wei, GUO Qing, et al Single object tracking research: a survey
[J]. Chinese Journal of Computers , 2022 , 45 (9 ): 1877 - 1907
DOI:10.11897/SP.J.1016.2022.01877
[本文引用: 1]
[2]
卢湖川, 李佩霞, 王栋 目标跟踪算法综述
[J]. 模式识别与人工智能 , 2018 , 31 (1 ): 61 - 76
[本文引用: 1]
LU Huchuan, LI Peixia, WANG Dong Visual object tracking: a survey
[J]. Pattern Recognition and Artificial Intelligence , 2018 , 31 (1 ): 61 - 76
[本文引用: 1]
[3]
BERTINETTO L, VALMADRE J, HENRIQUES J F, et al. Fully-convolutional siamese networks for object tracking [C]// 14th European Conference on Computer Vision . Amsterdam: Springer, 2016: 850–865.
[本文引用: 3]
[4]
陈志旺, 张忠新, 宋娟, 等 基于目标感知特征筛选的孪生网络跟踪算法
[J]. 光学学报 , 2020 , 40 (9 ): 110 - 126
[本文引用: 1]
CHEN Zhiwang, ZHANG Zhongxin, SONG Juan, et al Tracking algorithm for siamese network based on target-aware feature selection
[J]. Acta Optica Sinica , 2020 , 40 (9 ): 110 - 126
[本文引用: 1]
[5]
陈法领, 丁庆海, 罗海波, 等 基于自适应多层卷积特征决策融合的目标跟踪
[J]. 光学学报 , 2020 , 40 (23 ): 175 - 187
[本文引用: 1]
CHEN Faling, DING Qinghai, LUO Haibo, et al Target tracking based on adaptive multilayer convolutional feature decision fusion
[J]. Acta Optica Sinica , 2020 , 40 (23 ): 175 - 187
[本文引用: 1]
[6]
LI B, YAN J, WU W, et al. High performance visual tracking with Siamese region proposal network [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . New York: IEEE, 2018: 8971–8980.
[本文引用: 1]
[7]
ZHANG Z, PENG H, FU J, et al. ocean: object-aware anchor-free tracking [C]// 16th European Conference on Computer Vision . Glasgow : Springer, 2020: 771–787.
[本文引用: 2]
[8]
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// 31st Annual Conference on Neural Information Processing Systems . Long Beach: IEEE, 2017: 5998–6010.
[本文引用: 1]
[9]
WANG N, ZHOU W, WANG J, et al. Transformer meets tracker: exploiting temporal context for robust visual tracking [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . [s.l.]: IEEE, 2021: 1571–1580.
[本文引用: 4]
[10]
CHEN X, YAN B, ZHU J, et al. Transformer tracking [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . [s.l.]: IEEE, 2021: 8126–8135.
[本文引用: 19]
[11]
GAO S, ZHOU C, MA C, et al. Aiatrack: attention in attention for transformer visual tracking [C]// 17th European Conference on Computer Vision . Tel Aviv: Springer, 2022: 146–164.
[本文引用: 2]
[12]
CAO Z, HUANG Z, PAN L, et al. TCTrack: temporal contexts for aerial tracking [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 14798–14808.
[本文引用: 5]
[13]
MAYER C, DANELLJAN M, PAUDEL D P, et al. Learning target candidate association to keep track of what not to track [C]// 18th IEEE/CVF International Conference on Computer Vision . [s.l.]: IEEE, 2021: 13444–1345.
[本文引用: 4]
[14]
MAYER C, DANELLJAN M, BHAT G, et al. Transforming model prediction for tracking [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 8731–8740.
[本文引用: 10]
[15]
CUI Y, JIANG C, WANG L, et al. Mixformer: end-to-end tracking with iterative mixed attention [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 13608–13618.
[本文引用: 6]
[16]
WU Q, YANG T, LIU Z, et al. Dropmae: masked autoencoders with spatial-attention dropout for tracking tasks [C]// 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition . New York: IEEE, 2023: 14561–14571.
[本文引用: 1]
[17]
CHEN X, PENG H, WANG D, et al. Seqtrack: sequence to sequence learning for visual object tracking [C]// 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition . New York: IEEE, 2023: 14572–14581.
[本文引用: 1]
[18]
CHU X, TIAN Z, ZHANG B, et al. Conditional positional encodings for vision transformers. (2021-02-22)[2023-10-10]. https://www.arxiv.org/abs/2102.10882v2.
[本文引用: 2]
[19]
WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module [C]// 15th European Conference on Computer Vision . Munich: Springer, 2018: 3–19.
[本文引用: 1]
[20]
WANG C, XU H, ZHANG X, et al. Convolutional embedding makes hierarchical vision transformer stronger [C]// 17th European Conference on Computer Vision . Tel Aviv: Springer, 2022: 739–756.
[本文引用: 1]
[21]
LI B, WU W, WANG Q, et al. Siamrpn++: evolution of siamese visual tracking with very deep networks [C]// 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 15–20.
[本文引用: 1]
[22]
DANELLJAN M, BHAT G, KHAN F S, et al. ATOM: accurate tracking by overlap maximization [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 4660–4669.
[本文引用: 1]
[23]
BHAT G, DANELLJAN M, GOOL L V, et al. Learning discriminative model prediction for tracking [C]// IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 6182–6191.
[本文引用: 2]
[24]
BHAT G, DANELLJAN M, VAN G L, et al. Know your surroundings: exploiting scene information for object tracking [C]// 16th European Conference on Computer Vision . Glasgow: Springer, 2020: 205–221.
[本文引用: 1]
[25]
YU B, TANG M, ZHENG L, et al. High-performance discriminative tracking with transformers [C]// 18th IEEE/CVF International Conference on Computer Vision . [s.l.]: IEEE, 2021: 9856–9865.
[本文引用: 1]
[26]
DANELLJAN M, GOOL L V, TIMOFTE R. Probabilistic regression for visual tracking [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . [s.l.]: IEEE, 2020: 7183–7192.
[本文引用: 2]
[27]
YAN B, PENG H, FU J, et al. Learning spatio-temporal transformer for visual tracking [C]// 18th IEEE/CVF International Conference on Computer Vision . [s.l.]: IEEE, 2021: 10448–10457.
[本文引用: 1]
[28]
ZHONG M, CHEN F, XU J, et al. Correlation-based transformer tracking [C]// 31st International Conference on Artificial Neural Networks . Bristol: European Neural Networks Soc, 2022: 85–96.
[本文引用: 1]
[29]
YE B, CHANG H, MA B, et al. Joint feature learning and relation modeling for tracking: a one-stream framework [C]// 17th European Conference on Computer Vision . Tel Aviv: Springer, 2022: 341–357.
[本文引用: 6]
视频单目标跟踪研究进展综述
1
2022
... 视觉跟踪是指在视频序列第1帧指定目标后,在后续帧持续跟踪目标,实现目标的定位与尺度估计[1 -2 ] ,广泛应用于体育赛事、安防、无人车和机器人等领域. 其受目标形变、遮挡、相似物体干扰和跟踪速度等因素的影响,面临着很多挑战. 自从SiamFC[3 ] 将目标跟踪问题转化为模板和搜索区域间的特征匹配问题后,孪生网络跟踪算法因其较高的精度和超高的运行速度备受研究者青睐[4 -5 ] . SiameseRPN[6 ] 在SiamFC[3 ] 基础上增加了区域候选模块,能进行更有效的目标状态估计,提高了跟踪精度,但受限于锚框先验知识. Ocean[7 ] 受目标检测框架影响,提出基于目标感知的无锚框实时跟踪算法,引入特征对齐模块,能够在预测的边界框中感知特征. ...
视频单目标跟踪研究进展综述
1
2022
... 视觉跟踪是指在视频序列第1帧指定目标后,在后续帧持续跟踪目标,实现目标的定位与尺度估计[1 -2 ] ,广泛应用于体育赛事、安防、无人车和机器人等领域. 其受目标形变、遮挡、相似物体干扰和跟踪速度等因素的影响,面临着很多挑战. 自从SiamFC[3 ] 将目标跟踪问题转化为模板和搜索区域间的特征匹配问题后,孪生网络跟踪算法因其较高的精度和超高的运行速度备受研究者青睐[4 -5 ] . SiameseRPN[6 ] 在SiamFC[3 ] 基础上增加了区域候选模块,能进行更有效的目标状态估计,提高了跟踪精度,但受限于锚框先验知识. Ocean[7 ] 受目标检测框架影响,提出基于目标感知的无锚框实时跟踪算法,引入特征对齐模块,能够在预测的边界框中感知特征. ...
目标跟踪算法综述
1
2018
... 视觉跟踪是指在视频序列第1帧指定目标后,在后续帧持续跟踪目标,实现目标的定位与尺度估计[1 -2 ] ,广泛应用于体育赛事、安防、无人车和机器人等领域. 其受目标形变、遮挡、相似物体干扰和跟踪速度等因素的影响,面临着很多挑战. 自从SiamFC[3 ] 将目标跟踪问题转化为模板和搜索区域间的特征匹配问题后,孪生网络跟踪算法因其较高的精度和超高的运行速度备受研究者青睐[4 -5 ] . SiameseRPN[6 ] 在SiamFC[3 ] 基础上增加了区域候选模块,能进行更有效的目标状态估计,提高了跟踪精度,但受限于锚框先验知识. Ocean[7 ] 受目标检测框架影响,提出基于目标感知的无锚框实时跟踪算法,引入特征对齐模块,能够在预测的边界框中感知特征. ...
目标跟踪算法综述
1
2018
... 视觉跟踪是指在视频序列第1帧指定目标后,在后续帧持续跟踪目标,实现目标的定位与尺度估计[1 -2 ] ,广泛应用于体育赛事、安防、无人车和机器人等领域. 其受目标形变、遮挡、相似物体干扰和跟踪速度等因素的影响,面临着很多挑战. 自从SiamFC[3 ] 将目标跟踪问题转化为模板和搜索区域间的特征匹配问题后,孪生网络跟踪算法因其较高的精度和超高的运行速度备受研究者青睐[4 -5 ] . SiameseRPN[6 ] 在SiamFC[3 ] 基础上增加了区域候选模块,能进行更有效的目标状态估计,提高了跟踪精度,但受限于锚框先验知识. Ocean[7 ] 受目标检测框架影响,提出基于目标感知的无锚框实时跟踪算法,引入特征对齐模块,能够在预测的边界框中感知特征. ...
3
... 视觉跟踪是指在视频序列第1帧指定目标后,在后续帧持续跟踪目标,实现目标的定位与尺度估计[1 -2 ] ,广泛应用于体育赛事、安防、无人车和机器人等领域. 其受目标形变、遮挡、相似物体干扰和跟踪速度等因素的影响,面临着很多挑战. 自从SiamFC[3 ] 将目标跟踪问题转化为模板和搜索区域间的特征匹配问题后,孪生网络跟踪算法因其较高的精度和超高的运行速度备受研究者青睐[4 -5 ] . SiameseRPN[6 ] 在SiamFC[3 ] 基础上增加了区域候选模块,能进行更有效的目标状态估计,提高了跟踪精度,但受限于锚框先验知识. Ocean[7 ] 受目标检测框架影响,提出基于目标感知的无锚框实时跟踪算法,引入特征对齐模块,能够在预测的边界框中感知特征. ...
... [3 ]基础上增加了区域候选模块,能进行更有效的目标状态估计,提高了跟踪精度,但受限于锚框先验知识. Ocean[7 ] 受目标检测框架影响,提出基于目标感知的无锚框实时跟踪算法,引入特征对齐模块,能够在预测的边界框中感知特征. ...
... Comparison of different algorithms on GOT-10K, TrackingNet and UAV123
Tab.1 Trackers GOT-10K TrackingNet UAV123 AO/% SR0.50 /% SR0.75 /% AUC/% P Norm /%P /%AUC/% P /%SiamFC[3 ] 34.8 35.3 9.8 57.1 66.3 53.3 48.5 69.3 SiamPRN++[21 ] 51.7 61.6 32.5 73.3 80.0 69.4 64.2 84.0 ATOM[22 ] 55.6 63.4 40.2 70.3 77.1 64.8 64.3 — Ocean[7 ] 61.1 72.1 47.3 — — — 62.1 82.3 DiMP[23 ] 61.1 71.7 49.2 74.0 80.1 68.7 65.4 85.8 KYS[24 ] 63.6 75.1 51.5 74.0 80.0 68.8 — — DTT[25 ] 63.4 74.9 51.4 79.6 85.0 78.9 — — PrDiMP[26 ] 63.4 73.8 54.3 75.8 81.6 70.4 66.9 87.8 TrSiam[9 ] 66.0 76.6 57.1 78.1 82.9 72.7 — — TrDimp[9 ] 67.1 77.7 58.3 78.4 83.3 73.1 67.5 — KeepTrack[13 ] 68.3 79.3 61.0 78.1 83.5 73.8 69.7 — STARK[27 ] 68.8 78.1 64.1 82.0 86.9 — — — TransT[10 ] 72.3 82.4 68.2 81.4 86.7 80.3 69.1 — CTT[28 ] — — — 81.4 86.4 — — — TCTrack[12 ] — — — — — — 60.4 80.0 AiATrack[11 ] 69.6 77.7 63.2 82.7 87.8 80.4 69.3 90.7 ToMP[14 ] 73.5 85.6 66.5 81.5 86.4 78.9 65.9 85.2 MixFormer[15 ] 73.2 83.2 70.2 82.6 87.7 81.2 68.7 89.5 本研究算法 73.9 83.3 68.6 82.7 87.7 80.8 69.3 90.5
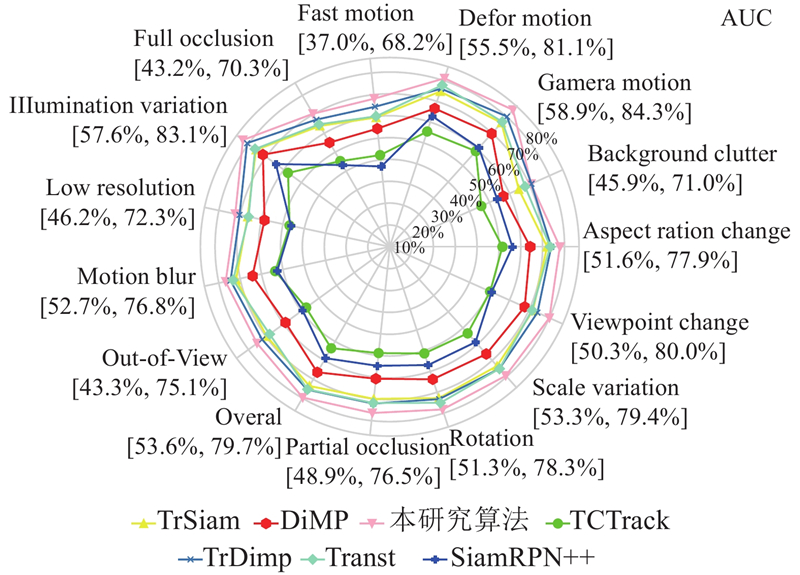
为了测试本研究算法在不同干扰场景下的跟踪能力,选择在LaSOT(large-scale single object tracking)数据集上进行测试. LaSOT数据集由1400 个序列组成,测试集包含280个视频序列,分为快速运动(fast motion)、遮挡(occlusion)、明暗变化(illumination)、运动模糊(motion blur)、形变(deformation)、尺度变化(scale variation)、超出视线之外(out-of-view)等14个属性. 如图6 所示展示了不同算法在14个属性下的结果对比. 图中,[x , y ]中x 、y 分别表示在该属性下,测试算法AUC得分的最低值和最高值. 本研究算法结果在背景杂质(background clutter)属性下较TrDiMP[9 ] 的略低,其他属性均优于其他算法的,尤其是在视点变化(viewpoint change) 、明暗变化(illumination)和尺度变化(scale variation)属性上均有较大提升. 此外,14个属性下的AUC得分均高于本研究的基线算法TransT[10 ] 的,反映了所提出的带有动态位置编码和多域注意力增强的模型针对多种场景都有强大的特征提取和融合能力,具备良好的鲁棒性. ...
基于目标感知特征筛选的孪生网络跟踪算法
1
2020
... 视觉跟踪是指在视频序列第1帧指定目标后,在后续帧持续跟踪目标,实现目标的定位与尺度估计[1 -2 ] ,广泛应用于体育赛事、安防、无人车和机器人等领域. 其受目标形变、遮挡、相似物体干扰和跟踪速度等因素的影响,面临着很多挑战. 自从SiamFC[3 ] 将目标跟踪问题转化为模板和搜索区域间的特征匹配问题后,孪生网络跟踪算法因其较高的精度和超高的运行速度备受研究者青睐[4 -5 ] . SiameseRPN[6 ] 在SiamFC[3 ] 基础上增加了区域候选模块,能进行更有效的目标状态估计,提高了跟踪精度,但受限于锚框先验知识. Ocean[7 ] 受目标检测框架影响,提出基于目标感知的无锚框实时跟踪算法,引入特征对齐模块,能够在预测的边界框中感知特征. ...
基于目标感知特征筛选的孪生网络跟踪算法
1
2020
... 视觉跟踪是指在视频序列第1帧指定目标后,在后续帧持续跟踪目标,实现目标的定位与尺度估计[1 -2 ] ,广泛应用于体育赛事、安防、无人车和机器人等领域. 其受目标形变、遮挡、相似物体干扰和跟踪速度等因素的影响,面临着很多挑战. 自从SiamFC[3 ] 将目标跟踪问题转化为模板和搜索区域间的特征匹配问题后,孪生网络跟踪算法因其较高的精度和超高的运行速度备受研究者青睐[4 -5 ] . SiameseRPN[6 ] 在SiamFC[3 ] 基础上增加了区域候选模块,能进行更有效的目标状态估计,提高了跟踪精度,但受限于锚框先验知识. Ocean[7 ] 受目标检测框架影响,提出基于目标感知的无锚框实时跟踪算法,引入特征对齐模块,能够在预测的边界框中感知特征. ...
基于自适应多层卷积特征决策融合的目标跟踪
1
2020
... 视觉跟踪是指在视频序列第1帧指定目标后,在后续帧持续跟踪目标,实现目标的定位与尺度估计[1 -2 ] ,广泛应用于体育赛事、安防、无人车和机器人等领域. 其受目标形变、遮挡、相似物体干扰和跟踪速度等因素的影响,面临着很多挑战. 自从SiamFC[3 ] 将目标跟踪问题转化为模板和搜索区域间的特征匹配问题后,孪生网络跟踪算法因其较高的精度和超高的运行速度备受研究者青睐[4 -5 ] . SiameseRPN[6 ] 在SiamFC[3 ] 基础上增加了区域候选模块,能进行更有效的目标状态估计,提高了跟踪精度,但受限于锚框先验知识. Ocean[7 ] 受目标检测框架影响,提出基于目标感知的无锚框实时跟踪算法,引入特征对齐模块,能够在预测的边界框中感知特征. ...
基于自适应多层卷积特征决策融合的目标跟踪
1
2020
... 视觉跟踪是指在视频序列第1帧指定目标后,在后续帧持续跟踪目标,实现目标的定位与尺度估计[1 -2 ] ,广泛应用于体育赛事、安防、无人车和机器人等领域. 其受目标形变、遮挡、相似物体干扰和跟踪速度等因素的影响,面临着很多挑战. 自从SiamFC[3 ] 将目标跟踪问题转化为模板和搜索区域间的特征匹配问题后,孪生网络跟踪算法因其较高的精度和超高的运行速度备受研究者青睐[4 -5 ] . SiameseRPN[6 ] 在SiamFC[3 ] 基础上增加了区域候选模块,能进行更有效的目标状态估计,提高了跟踪精度,但受限于锚框先验知识. Ocean[7 ] 受目标检测框架影响,提出基于目标感知的无锚框实时跟踪算法,引入特征对齐模块,能够在预测的边界框中感知特征. ...
1
... 视觉跟踪是指在视频序列第1帧指定目标后,在后续帧持续跟踪目标,实现目标的定位与尺度估计[1 -2 ] ,广泛应用于体育赛事、安防、无人车和机器人等领域. 其受目标形变、遮挡、相似物体干扰和跟踪速度等因素的影响,面临着很多挑战. 自从SiamFC[3 ] 将目标跟踪问题转化为模板和搜索区域间的特征匹配问题后,孪生网络跟踪算法因其较高的精度和超高的运行速度备受研究者青睐[4 -5 ] . SiameseRPN[6 ] 在SiamFC[3 ] 基础上增加了区域候选模块,能进行更有效的目标状态估计,提高了跟踪精度,但受限于锚框先验知识. Ocean[7 ] 受目标检测框架影响,提出基于目标感知的无锚框实时跟踪算法,引入特征对齐模块,能够在预测的边界框中感知特征. ...
2
... 视觉跟踪是指在视频序列第1帧指定目标后,在后续帧持续跟踪目标,实现目标的定位与尺度估计[1 -2 ] ,广泛应用于体育赛事、安防、无人车和机器人等领域. 其受目标形变、遮挡、相似物体干扰和跟踪速度等因素的影响,面临着很多挑战. 自从SiamFC[3 ] 将目标跟踪问题转化为模板和搜索区域间的特征匹配问题后,孪生网络跟踪算法因其较高的精度和超高的运行速度备受研究者青睐[4 -5 ] . SiameseRPN[6 ] 在SiamFC[3 ] 基础上增加了区域候选模块,能进行更有效的目标状态估计,提高了跟踪精度,但受限于锚框先验知识. Ocean[7 ] 受目标检测框架影响,提出基于目标感知的无锚框实时跟踪算法,引入特征对齐模块,能够在预测的边界框中感知特征. ...
... Comparison of different algorithms on GOT-10K, TrackingNet and UAV123
Tab.1 Trackers GOT-10K TrackingNet UAV123 AO/% SR0.50 /% SR0.75 /% AUC/% P Norm /%P /%AUC/% P /%SiamFC[3 ] 34.8 35.3 9.8 57.1 66.3 53.3 48.5 69.3 SiamPRN++[21 ] 51.7 61.6 32.5 73.3 80.0 69.4 64.2 84.0 ATOM[22 ] 55.6 63.4 40.2 70.3 77.1 64.8 64.3 — Ocean[7 ] 61.1 72.1 47.3 — — — 62.1 82.3 DiMP[23 ] 61.1 71.7 49.2 74.0 80.1 68.7 65.4 85.8 KYS[24 ] 63.6 75.1 51.5 74.0 80.0 68.8 — — DTT[25 ] 63.4 74.9 51.4 79.6 85.0 78.9 — — PrDiMP[26 ] 63.4 73.8 54.3 75.8 81.6 70.4 66.9 87.8 TrSiam[9 ] 66.0 76.6 57.1 78.1 82.9 72.7 — — TrDimp[9 ] 67.1 77.7 58.3 78.4 83.3 73.1 67.5 — KeepTrack[13 ] 68.3 79.3 61.0 78.1 83.5 73.8 69.7 — STARK[27 ] 68.8 78.1 64.1 82.0 86.9 — — — TransT[10 ] 72.3 82.4 68.2 81.4 86.7 80.3 69.1 — CTT[28 ] — — — 81.4 86.4 — — — TCTrack[12 ] — — — — — — 60.4 80.0 AiATrack[11 ] 69.6 77.7 63.2 82.7 87.8 80.4 69.3 90.7 ToMP[14 ] 73.5 85.6 66.5 81.5 86.4 78.9 65.9 85.2 MixFormer[15 ] 73.2 83.2 70.2 82.6 87.7 81.2 68.7 89.5 本研究算法 73.9 83.3 68.6 82.7 87.7 80.8 69.3 90.5
为了测试本研究算法在不同干扰场景下的跟踪能力,选择在LaSOT(large-scale single object tracking)数据集上进行测试. LaSOT数据集由1400 个序列组成,测试集包含280个视频序列,分为快速运动(fast motion)、遮挡(occlusion)、明暗变化(illumination)、运动模糊(motion blur)、形变(deformation)、尺度变化(scale variation)、超出视线之外(out-of-view)等14个属性. 如图6 所示展示了不同算法在14个属性下的结果对比. 图中,[x , y ]中x 、y 分别表示在该属性下,测试算法AUC得分的最低值和最高值. 本研究算法结果在背景杂质(background clutter)属性下较TrDiMP[9 ] 的略低,其他属性均优于其他算法的,尤其是在视点变化(viewpoint change) 、明暗变化(illumination)和尺度变化(scale variation)属性上均有较大提升. 此外,14个属性下的AUC得分均高于本研究的基线算法TransT[10 ] 的,反映了所提出的带有动态位置编码和多域注意力增强的模型针对多种场景都有强大的特征提取和融合能力,具备良好的鲁棒性. ...
1
... 随着Transformer[8 ] 在目标检测领域展现出强大的能力,Wang等[9 ] 将其集成到基于孪生网络的视觉跟踪算法中. TransT[10 ] 利用注意力机制捕获全局信息,融合模板和搜索区域信息,大大提升了跟踪精度. AiATrack[11 ] 通过计算2次注意力矩阵来增强向量之间的相关性并抑制错误的相关性. TCTrack[12 ] 提出新的结合历史帧信息的框架,可以有效利用整个视频序列. KeepTrack[13 ] 提出可学习的目标候选关联网络,通过逐帧传播的形式对所有目标候选者进行优化,研究如何解决相似物干扰挑战. ToMP[14 ] 使用类相关滤波的目标模型用于定位目标,其权重通过Transformer预测器获得. MixFormer[15 ] 使用Transformer结构进行特征提取和特征融合,能够有效建立全局特征关系,达到了较高的跟踪精度. DropMAE[16 ] 提出自适应的空间-注意力剔除技术,对于给定的query序列,自适应地放弃一部分帧内线索以促进模型学习更可靠的时空对应关系. SeqTrack[17 ] 提出用于视觉跟踪的序列到序列学习框架, 将视觉跟踪问题转换为序列生成问题,以自回归的方式预测目标边界框,采用预训练的Vit进行特征融合计算. 但以上模型在注意力计算时均采用固定的位置编码,未能充分利用模板和搜索区域的位置信息;在特征融合计算时主要使用交叉注意力和自注意力进行,空间和通道维度的特征受到限制. ...
4
... 随着Transformer[8 ] 在目标检测领域展现出强大的能力,Wang等[9 ] 将其集成到基于孪生网络的视觉跟踪算法中. TransT[10 ] 利用注意力机制捕获全局信息,融合模板和搜索区域信息,大大提升了跟踪精度. AiATrack[11 ] 通过计算2次注意力矩阵来增强向量之间的相关性并抑制错误的相关性. TCTrack[12 ] 提出新的结合历史帧信息的框架,可以有效利用整个视频序列. KeepTrack[13 ] 提出可学习的目标候选关联网络,通过逐帧传播的形式对所有目标候选者进行优化,研究如何解决相似物干扰挑战. ToMP[14 ] 使用类相关滤波的目标模型用于定位目标,其权重通过Transformer预测器获得. MixFormer[15 ] 使用Transformer结构进行特征提取和特征融合,能够有效建立全局特征关系,达到了较高的跟踪精度. DropMAE[16 ] 提出自适应的空间-注意力剔除技术,对于给定的query序列,自适应地放弃一部分帧内线索以促进模型学习更可靠的时空对应关系. SeqTrack[17 ] 提出用于视觉跟踪的序列到序列学习框架, 将视觉跟踪问题转换为序列生成问题,以自回归的方式预测目标边界框,采用预训练的Vit进行特征融合计算. 但以上模型在注意力计算时均采用固定的位置编码,未能充分利用模板和搜索区域的位置信息;在特征融合计算时主要使用交叉注意力和自注意力进行,空间和通道维度的特征受到限制. ...
... Comparison of different algorithms on GOT-10K, TrackingNet and UAV123
Tab.1 Trackers GOT-10K TrackingNet UAV123 AO/% SR0.50 /% SR0.75 /% AUC/% P Norm /%P /%AUC/% P /%SiamFC[3 ] 34.8 35.3 9.8 57.1 66.3 53.3 48.5 69.3 SiamPRN++[21 ] 51.7 61.6 32.5 73.3 80.0 69.4 64.2 84.0 ATOM[22 ] 55.6 63.4 40.2 70.3 77.1 64.8 64.3 — Ocean[7 ] 61.1 72.1 47.3 — — — 62.1 82.3 DiMP[23 ] 61.1 71.7 49.2 74.0 80.1 68.7 65.4 85.8 KYS[24 ] 63.6 75.1 51.5 74.0 80.0 68.8 — — DTT[25 ] 63.4 74.9 51.4 79.6 85.0 78.9 — — PrDiMP[26 ] 63.4 73.8 54.3 75.8 81.6 70.4 66.9 87.8 TrSiam[9 ] 66.0 76.6 57.1 78.1 82.9 72.7 — — TrDimp[9 ] 67.1 77.7 58.3 78.4 83.3 73.1 67.5 — KeepTrack[13 ] 68.3 79.3 61.0 78.1 83.5 73.8 69.7 — STARK[27 ] 68.8 78.1 64.1 82.0 86.9 — — — TransT[10 ] 72.3 82.4 68.2 81.4 86.7 80.3 69.1 — CTT[28 ] — — — 81.4 86.4 — — — TCTrack[12 ] — — — — — — 60.4 80.0 AiATrack[11 ] 69.6 77.7 63.2 82.7 87.8 80.4 69.3 90.7 ToMP[14 ] 73.5 85.6 66.5 81.5 86.4 78.9 65.9 85.2 MixFormer[15 ] 73.2 83.2 70.2 82.6 87.7 81.2 68.7 89.5 本研究算法 73.9 83.3 68.6 82.7 87.7 80.8 69.3 90.5
为了测试本研究算法在不同干扰场景下的跟踪能力,选择在LaSOT(large-scale single object tracking)数据集上进行测试. LaSOT数据集由1400 个序列组成,测试集包含280个视频序列,分为快速运动(fast motion)、遮挡(occlusion)、明暗变化(illumination)、运动模糊(motion blur)、形变(deformation)、尺度变化(scale variation)、超出视线之外(out-of-view)等14个属性. 如图6 所示展示了不同算法在14个属性下的结果对比. 图中,[x , y ]中x 、y 分别表示在该属性下,测试算法AUC得分的最低值和最高值. 本研究算法结果在背景杂质(background clutter)属性下较TrDiMP[9 ] 的略低,其他属性均优于其他算法的,尤其是在视点变化(viewpoint change) 、明暗变化(illumination)和尺度变化(scale variation)属性上均有较大提升. 此外,14个属性下的AUC得分均高于本研究的基线算法TransT[10 ] 的,反映了所提出的带有动态位置编码和多域注意力增强的模型针对多种场景都有强大的特征提取和融合能力,具备良好的鲁棒性. ...
... [
9 ]
67.1 77.7 58.3 78.4 83.3 73.1 67.5 — KeepTrack[13 ] 68.3 79.3 61.0 78.1 83.5 73.8 69.7 — STARK[27 ] 68.8 78.1 64.1 82.0 86.9 — — — TransT[10 ] 72.3 82.4 68.2 81.4 86.7 80.3 69.1 — CTT[28 ] — — — 81.4 86.4 — — — TCTrack[12 ] — — — — — — 60.4 80.0 AiATrack[11 ] 69.6 77.7 63.2 82.7 87.8 80.4 69.3 90.7 ToMP[14 ] 73.5 85.6 66.5 81.5 86.4 78.9 65.9 85.2 MixFormer[15 ] 73.2 83.2 70.2 82.6 87.7 81.2 68.7 89.5 本研究算法 73.9 83.3 68.6 82.7 87.7 80.8 69.3 90.5 为了测试本研究算法在不同干扰场景下的跟踪能力,选择在LaSOT(large-scale single object tracking)数据集上进行测试. LaSOT数据集由1400 个序列组成,测试集包含280个视频序列,分为快速运动(fast motion)、遮挡(occlusion)、明暗变化(illumination)、运动模糊(motion blur)、形变(deformation)、尺度变化(scale variation)、超出视线之外(out-of-view)等14个属性. 如图6 所示展示了不同算法在14个属性下的结果对比. 图中,[x , y ]中x 、y 分别表示在该属性下,测试算法AUC得分的最低值和最高值. 本研究算法结果在背景杂质(background clutter)属性下较TrDiMP[9 ] 的略低,其他属性均优于其他算法的,尤其是在视点变化(viewpoint change) 、明暗变化(illumination)和尺度变化(scale variation)属性上均有较大提升. 此外,14个属性下的AUC得分均高于本研究的基线算法TransT[10 ] 的,反映了所提出的带有动态位置编码和多域注意力增强的模型针对多种场景都有强大的特征提取和融合能力,具备良好的鲁棒性. ...
... 为了测试本研究算法在不同干扰场景下的跟踪能力,选择在LaSOT(large-scale single object tracking)数据集上进行测试. LaSOT数据集由1400 个序列组成,测试集包含280个视频序列,分为快速运动(fast motion)、遮挡(occlusion)、明暗变化(illumination)、运动模糊(motion blur)、形变(deformation)、尺度变化(scale variation)、超出视线之外(out-of-view)等14个属性. 如图6 所示展示了不同算法在14个属性下的结果对比. 图中,[x , y ]中x 、y 分别表示在该属性下,测试算法AUC得分的最低值和最高值. 本研究算法结果在背景杂质(background clutter)属性下较TrDiMP[9 ] 的略低,其他属性均优于其他算法的,尤其是在视点变化(viewpoint change) 、明暗变化(illumination)和尺度变化(scale variation)属性上均有较大提升. 此外,14个属性下的AUC得分均高于本研究的基线算法TransT[10 ] 的,反映了所提出的带有动态位置编码和多域注意力增强的模型针对多种场景都有强大的特征提取和融合能力,具备良好的鲁棒性. ...
19
... 随着Transformer[8 ] 在目标检测领域展现出强大的能力,Wang等[9 ] 将其集成到基于孪生网络的视觉跟踪算法中. TransT[10 ] 利用注意力机制捕获全局信息,融合模板和搜索区域信息,大大提升了跟踪精度. AiATrack[11 ] 通过计算2次注意力矩阵来增强向量之间的相关性并抑制错误的相关性. TCTrack[12 ] 提出新的结合历史帧信息的框架,可以有效利用整个视频序列. KeepTrack[13 ] 提出可学习的目标候选关联网络,通过逐帧传播的形式对所有目标候选者进行优化,研究如何解决相似物干扰挑战. ToMP[14 ] 使用类相关滤波的目标模型用于定位目标,其权重通过Transformer预测器获得. MixFormer[15 ] 使用Transformer结构进行特征提取和特征融合,能够有效建立全局特征关系,达到了较高的跟踪精度. DropMAE[16 ] 提出自适应的空间-注意力剔除技术,对于给定的query序列,自适应地放弃一部分帧内线索以促进模型学习更可靠的时空对应关系. SeqTrack[17 ] 提出用于视觉跟踪的序列到序列学习框架, 将视觉跟踪问题转换为序列生成问题,以自回归的方式预测目标边界框,采用预训练的Vit进行特征融合计算. 但以上模型在注意力计算时均采用固定的位置编码,未能充分利用模板和搜索区域的位置信息;在特征融合计算时主要使用交叉注意力和自注意力进行,空间和通道维度的特征受到限制. ...
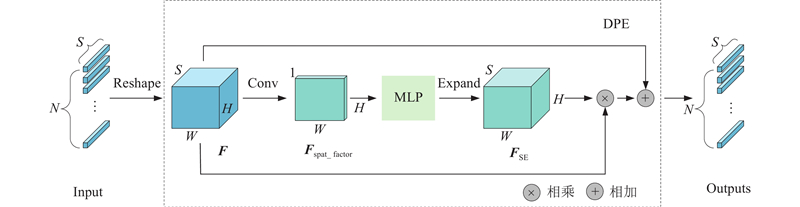
... Chu等[18 ] 提出带有卷积计算的位置编码生成器,Woo等[19 ] 利用空间注意力和通道注意力对特征增强,Wang等[20 ] 利用卷积嵌入的方式改进Vision Transformer架构,这些改进方法有效提升了包括跟踪算法在内的多种视觉任务的算法性能. 受以上方法启发,本研究基于TransT[10 ] 框架,设计动态位置编码方法,提高位置信息利用率. 通过多域注意力增强方法,增强混合了模板和搜索区域的特征. 在特征融合解码计算时使用多个不同空洞率的平行卷积融合信息,提高特征表达能力. ...
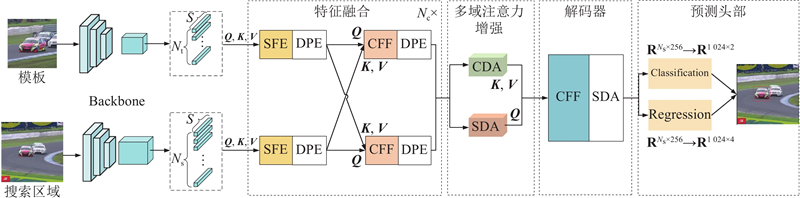
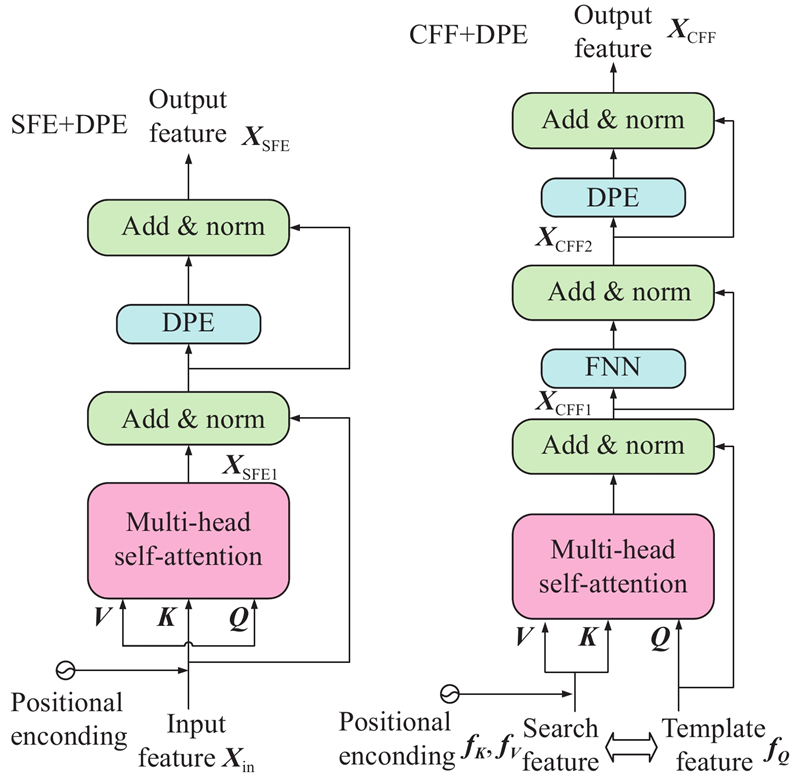
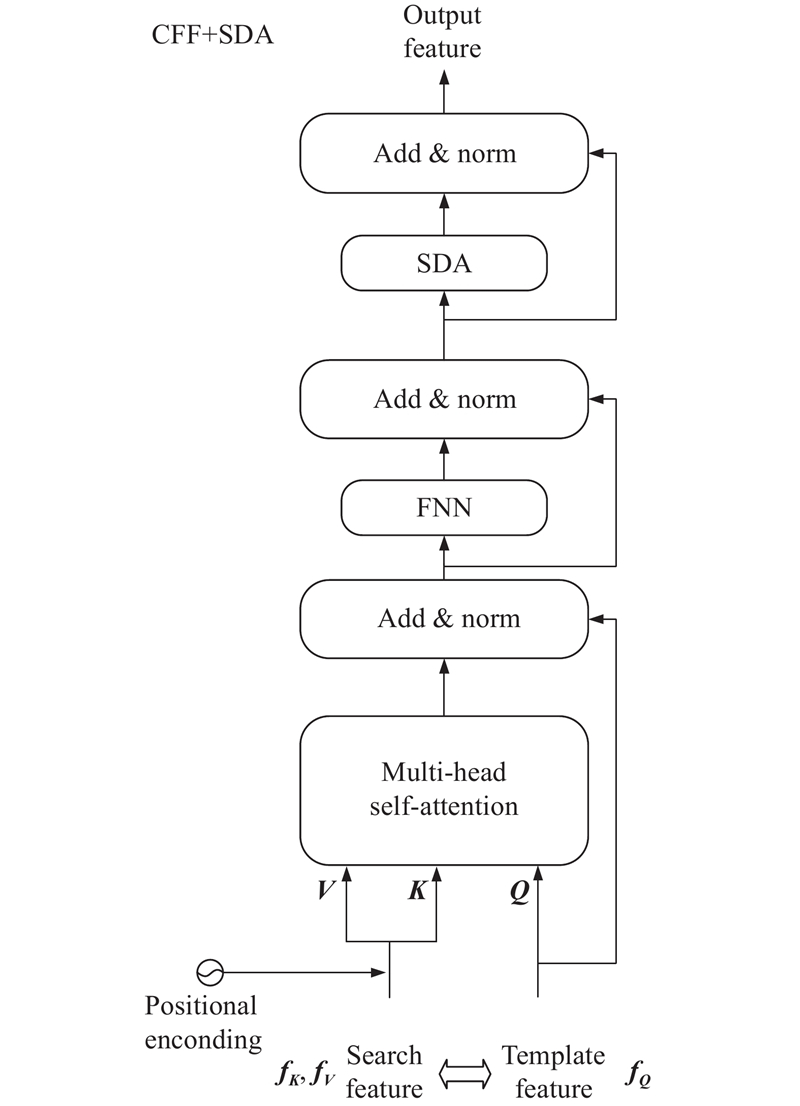
... 本研究算法整体框架如图1 所示,算法整体结构由5部分组成:基于Resnet50的特征提取主干网络、基于注意力机制的特征融合模块、多域注意力增强模块、特征解码器模块和预测头. 本研究算法提出的动态位置编码模块和多域注意力增强模块分别应用于特征融合层、多域注意力增强层和解码器. 首先,使用修改的 Resnet50主干网络提取模板帧与搜索区域帧的特征,将得到的特征图按通道重新组合为二维向量后引入自注意力特征增强(self-attention feature enhancement, SFE)模块. 其次,分别使用动态位置编码(dynamic position encoding, DPE)模块为其添加位置信息. 将编码后的模板、搜索区域特征传入交叉注意力特征融合 (cross-attention feature fusion, CFF)模块,再进行 DPE 提高位置信息的利用率. 然后,通过多域注意力增强(multi-domain attention enhancement, MDAE)模块,从空间和通道2个维度建模,增强特征表征能力. 随后,将混合了模板和搜索区域的特征序列通过由CFF和空间域注意力增强(spatial-domain attention, SDA)模块组成的解码器(decoder)模块进一步融合,得到更完备的特征. 最后,将增强后的信息传入分类回归预测头,得到目标边界框. 本研究分类和回归预测头与TransT[10 ] 的相同. ...
... 本研究基线算法TransT[10 ] 中使用语境增强(ego-context augment, ECA)模块和交叉特征增强(cross-feature augment, CFA)模块来对模板和搜索区域的特征进行融合,结合残差结构的多头注意力机制和前馈网络来增强特征表征. 但在训练时,ECA和CFA模块需要进行多次计算,且每次计算时须添加同样的位置编码信息. 为此,本研究设计了自注意力特征增强 SFE 和交叉注意力特征融合CFF 模块,由于添加了动态位置编码模块,仅在第1次计算时须添加固定的位置信息. ...
... 本研究算法与主流跟踪器在GOT-10K、TrackingNet和UAV123数据集上的对比实验结果如表1 所示. 表中,最优结果加粗显示,次优结果下划线显示. 可以看出,与当前最先进的跟踪器相比,本研究算法在3个数据集下的测试指标均处于最优或次优的位置,较本研究的基线算法TransT[10 ] 有大幅提升. 其中,在GOT-10K数据集上,平均重合度(AO)比TransT[10 ] 和MixFormer[15 ] 的分别提升了1.6个百分点和0.7个百分点;在TrackingNet数据集上,相比于TransT[10 ] 和ToMP[14 ] ,AUC分别提高1.3个百分点和4.3个百分点;在UAV123数据集上,相比于TransT[10 ] 和MixFormer[15 ] ,AUC分别提高0.2个百分点和0.6个百分点. ...
... [10 ]和MixFormer[15 ] 的分别提升了1.6个百分点和0.7个百分点;在TrackingNet数据集上,相比于TransT[10 ] 和ToMP[14 ] ,AUC分别提高1.3个百分点和4.3个百分点;在UAV123数据集上,相比于TransT[10 ] 和MixFormer[15 ] ,AUC分别提高0.2个百分点和0.6个百分点. ...
... [10 ]和ToMP[14 ] ,AUC分别提高1.3个百分点和4.3个百分点;在UAV123数据集上,相比于TransT[10 ] 和MixFormer[15 ] ,AUC分别提高0.2个百分点和0.6个百分点. ...
... [10 ]和MixFormer[15 ] ,AUC分别提高0.2个百分点和0.6个百分点. ...
... Comparison of different algorithms on GOT-10K, TrackingNet and UAV123
Tab.1 Trackers GOT-10K TrackingNet UAV123 AO/% SR0.50 /% SR0.75 /% AUC/% P Norm /%P /%AUC/% P /%SiamFC[3 ] 34.8 35.3 9.8 57.1 66.3 53.3 48.5 69.3 SiamPRN++[21 ] 51.7 61.6 32.5 73.3 80.0 69.4 64.2 84.0 ATOM[22 ] 55.6 63.4 40.2 70.3 77.1 64.8 64.3 — Ocean[7 ] 61.1 72.1 47.3 — — — 62.1 82.3 DiMP[23 ] 61.1 71.7 49.2 74.0 80.1 68.7 65.4 85.8 KYS[24 ] 63.6 75.1 51.5 74.0 80.0 68.8 — — DTT[25 ] 63.4 74.9 51.4 79.6 85.0 78.9 — — PrDiMP[26 ] 63.4 73.8 54.3 75.8 81.6 70.4 66.9 87.8 TrSiam[9 ] 66.0 76.6 57.1 78.1 82.9 72.7 — — TrDimp[9 ] 67.1 77.7 58.3 78.4 83.3 73.1 67.5 — KeepTrack[13 ] 68.3 79.3 61.0 78.1 83.5 73.8 69.7 — STARK[27 ] 68.8 78.1 64.1 82.0 86.9 — — — TransT[10 ] 72.3 82.4 68.2 81.4 86.7 80.3 69.1 — CTT[28 ] — — — 81.4 86.4 — — — TCTrack[12 ] — — — — — — 60.4 80.0 AiATrack[11 ] 69.6 77.7 63.2 82.7 87.8 80.4 69.3 90.7 ToMP[14 ] 73.5 85.6 66.5 81.5 86.4 78.9 65.9 85.2 MixFormer[15 ] 73.2 83.2 70.2 82.6 87.7 81.2 68.7 89.5 本研究算法 73.9 83.3 68.6 82.7 87.7 80.8 69.3 90.5
为了测试本研究算法在不同干扰场景下的跟踪能力,选择在LaSOT(large-scale single object tracking)数据集上进行测试. LaSOT数据集由1400 个序列组成,测试集包含280个视频序列,分为快速运动(fast motion)、遮挡(occlusion)、明暗变化(illumination)、运动模糊(motion blur)、形变(deformation)、尺度变化(scale variation)、超出视线之外(out-of-view)等14个属性. 如图6 所示展示了不同算法在14个属性下的结果对比. 图中,[x , y ]中x 、y 分别表示在该属性下,测试算法AUC得分的最低值和最高值. 本研究算法结果在背景杂质(background clutter)属性下较TrDiMP[9 ] 的略低,其他属性均优于其他算法的,尤其是在视点变化(viewpoint change) 、明暗变化(illumination)和尺度变化(scale variation)属性上均有较大提升. 此外,14个属性下的AUC得分均高于本研究的基线算法TransT[10 ] 的,反映了所提出的带有动态位置编码和多域注意力增强的模型针对多种场景都有强大的特征提取和融合能力,具备良好的鲁棒性. ...
... 为了测试本研究算法在不同干扰场景下的跟踪能力,选择在LaSOT(large-scale single object tracking)数据集上进行测试. LaSOT数据集由1400 个序列组成,测试集包含280个视频序列,分为快速运动(fast motion)、遮挡(occlusion)、明暗变化(illumination)、运动模糊(motion blur)、形变(deformation)、尺度变化(scale variation)、超出视线之外(out-of-view)等14个属性. 如图6 所示展示了不同算法在14个属性下的结果对比. 图中,[x , y ]中x 、y 分别表示在该属性下,测试算法AUC得分的最低值和最高值. 本研究算法结果在背景杂质(background clutter)属性下较TrDiMP[9 ] 的略低,其他属性均优于其他算法的,尤其是在视点变化(viewpoint change) 、明暗变化(illumination)和尺度变化(scale variation)属性上均有较大提升. 此外,14个属性下的AUC得分均高于本研究的基线算法TransT[10 ] 的,反映了所提出的带有动态位置编码和多域注意力增强的模型针对多种场景都有强大的特征提取和融合能力,具备良好的鲁棒性. ...
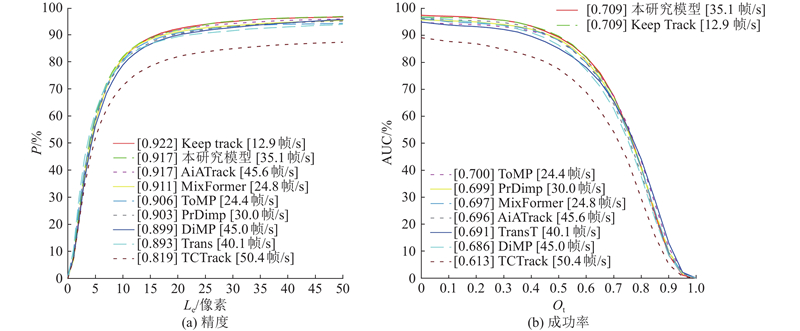
... 为了测试本研究模型的跟踪实时性, 将本研究算法与目前主流的跟踪算法在OTB100数据集上进行跟踪精度与速度的对比实验. OTB100由100个视频序列组成,包括25%的灰度序列,评价指标为AUC和P . 如图7 所示列出了本研究算法和其他几种算法的AUC、精度和运行速度(使用2.1节中的测试环境)的对比结果. 图中,L e 表示定位误差阈值,O t 表示预测值与真值之间框的重叠阈值,方框中的数值为定位误差阈值取20时对应的纵坐标的值. 可以看出,本研究算法的速度达到35.1帧/s,而MixFormer[15 ] 的速度仅为24.8帧/s;AUC达到最优;P 为次优,仅比具有相似物干扰分析模块的KeepTrack[13 ] 算法略低,但KeepTrack[13 ] 运行速度较低. 本研究算法的P 比基线算法TransT[10 ] 的提升2.4个百分点,比其他同样使用Transformer结构的ToMP[14 ] 和TCTrack[12 ] 分别高1.1个百分点和9.6个百分点,略高于MixFormer[15 ] 算法的. 结果表明,本研究算法在OTB数据集上有较好的跟踪效果和跟踪速度. ...
... 1)在篮球的视频序列中,在目标发生形变的同时出现相似物体,TransT[10 ] 在此类场景下的跟踪能力不足,出现了跟踪失败的情况. 在第346帧时,其他算法均将目标识别到了其他相似球衣的运动员上. 本研究算法则正确跟踪了目标,展现出更强的特征表征能力. ...
... 2)在打斗场景中,跟踪物体较小且存在背景干扰. 在第36、37和51帧目标物较小时,本研究模型较其他算法得到了更加准确的目标框,TransT[10 ] 和TCTrack[12 ] 的表现不佳. TransT[10 ] 在第92帧将背景中的雨滴误认为跟踪对象,本研究模型仍然可以得到较好的跟踪结果. ...
... [10 ]在第92帧将背景中的雨滴误认为跟踪对象,本研究模型仍然可以得到较好的跟踪结果. ...
... 3)在钞票视频序列中,出现与目标物相同的物体,对跟踪器造成了干扰. 在第126帧将目标钞票折叠时,5个跟踪器都能够定位目标. 当第306、322、326帧出现相同钞票时,TransT[10 ] 、TCTrack[12 ] 和PrDiMP[26 ] 将另外钞票误认为目标,DiMP[23 ] 则是将2个钞票均识别成目标,本研究模型在此场景下体现出了较强的跟踪能力. ...
... 4)在第4个视频序列目标被大部分遮挡时,TransT[10 ] 仅能跟踪目标露出的部分,本研究算法可以有效预测被遮挡的目标物. ...
... 为了测试动态位置编码(DPE)模块、空间域注意力(SDA)模块和多域注意力(MDAE)模块对跟踪结果的影响,在GOT-10K上进行消融实验. 具体测试结果如表3 所示. 表中,fps为速度. 第1行为本地复现TransT[10 ] 结果,由于实验设备、数据量、运行环境等原因,本研究测试的Base算法TransT效果与原文[10 ] 有所不同(原文中GOT-10K数据集测试AO为72.3%,速度为50.0帧/s). ...
... [10 ]有所不同(原文中GOT-10K数据集测试AO为72.3%,速度为50.0帧/s). ...
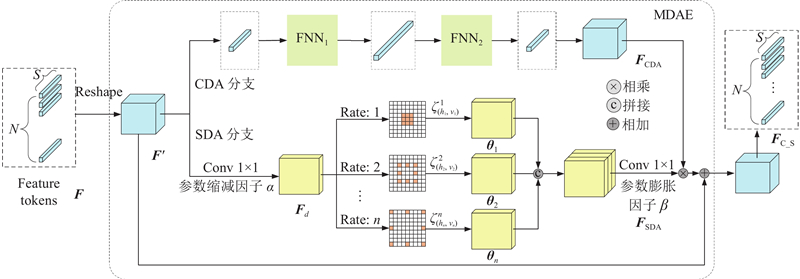
... 由表3 中第1行可以看出,添加DPE模块后,AO相比较基线算法TransT[10 ] 增长了1.1个百分点,验证了在注意力计算后附加的动态位置编码DPE模块可以随注意力计算逐层添加特征图的位置信息,从而有效提升注意力精确度. 加入DPE模块后,速度为36.7帧/s,降低幅度不大. 在算法设计中,MDAE和Decoder-SDA相较DPE模块参数量更少. 如表中第3行数据所示,在加入MDAE后,相比于第2行数据,AO增长0.6个百分点,速度仅降低1.0帧/s,说明融合了通道和空间注意力的特征可以有效提升模型的跟踪精度. 而在仅添加MDAE和Decoder-SDA模块时,运行速度降低并不明显,AO提升0.9个百分点,表明MDAE模块中的参数缩减策略可以在保证精度提高的同时降低算法复杂度. 从第6行可以看出,在解码器中添加SDA模块后,相较于第3行,AO提升0.5个百分点,表明SDA中3个平行卷积的设计可以为分类回归预测头提供更加精确的信息. 此外,第5行的实验结果显示,将CDA模块应用到解码器中对模型准确率并没有有效提升.为了使模型更为简洁高效,在Decoder设计中仅保留SDA模块. ...
2
... 随着Transformer[8 ] 在目标检测领域展现出强大的能力,Wang等[9 ] 将其集成到基于孪生网络的视觉跟踪算法中. TransT[10 ] 利用注意力机制捕获全局信息,融合模板和搜索区域信息,大大提升了跟踪精度. AiATrack[11 ] 通过计算2次注意力矩阵来增强向量之间的相关性并抑制错误的相关性. TCTrack[12 ] 提出新的结合历史帧信息的框架,可以有效利用整个视频序列. KeepTrack[13 ] 提出可学习的目标候选关联网络,通过逐帧传播的形式对所有目标候选者进行优化,研究如何解决相似物干扰挑战. ToMP[14 ] 使用类相关滤波的目标模型用于定位目标,其权重通过Transformer预测器获得. MixFormer[15 ] 使用Transformer结构进行特征提取和特征融合,能够有效建立全局特征关系,达到了较高的跟踪精度. DropMAE[16 ] 提出自适应的空间-注意力剔除技术,对于给定的query序列,自适应地放弃一部分帧内线索以促进模型学习更可靠的时空对应关系. SeqTrack[17 ] 提出用于视觉跟踪的序列到序列学习框架, 将视觉跟踪问题转换为序列生成问题,以自回归的方式预测目标边界框,采用预训练的Vit进行特征融合计算. 但以上模型在注意力计算时均采用固定的位置编码,未能充分利用模板和搜索区域的位置信息;在特征融合计算时主要使用交叉注意力和自注意力进行,空间和通道维度的特征受到限制. ...
... Comparison of different algorithms on GOT-10K, TrackingNet and UAV123
Tab.1 Trackers GOT-10K TrackingNet UAV123 AO/% SR0.50 /% SR0.75 /% AUC/% P Norm /%P /%AUC/% P /%SiamFC[3 ] 34.8 35.3 9.8 57.1 66.3 53.3 48.5 69.3 SiamPRN++[21 ] 51.7 61.6 32.5 73.3 80.0 69.4 64.2 84.0 ATOM[22 ] 55.6 63.4 40.2 70.3 77.1 64.8 64.3 — Ocean[7 ] 61.1 72.1 47.3 — — — 62.1 82.3 DiMP[23 ] 61.1 71.7 49.2 74.0 80.1 68.7 65.4 85.8 KYS[24 ] 63.6 75.1 51.5 74.0 80.0 68.8 — — DTT[25 ] 63.4 74.9 51.4 79.6 85.0 78.9 — — PrDiMP[26 ] 63.4 73.8 54.3 75.8 81.6 70.4 66.9 87.8 TrSiam[9 ] 66.0 76.6 57.1 78.1 82.9 72.7 — — TrDimp[9 ] 67.1 77.7 58.3 78.4 83.3 73.1 67.5 — KeepTrack[13 ] 68.3 79.3 61.0 78.1 83.5 73.8 69.7 — STARK[27 ] 68.8 78.1 64.1 82.0 86.9 — — — TransT[10 ] 72.3 82.4 68.2 81.4 86.7 80.3 69.1 — CTT[28 ] — — — 81.4 86.4 — — — TCTrack[12 ] — — — — — — 60.4 80.0 AiATrack[11 ] 69.6 77.7 63.2 82.7 87.8 80.4 69.3 90.7 ToMP[14 ] 73.5 85.6 66.5 81.5 86.4 78.9 65.9 85.2 MixFormer[15 ] 73.2 83.2 70.2 82.6 87.7 81.2 68.7 89.5 本研究算法 73.9 83.3 68.6 82.7 87.7 80.8 69.3 90.5
为了测试本研究算法在不同干扰场景下的跟踪能力,选择在LaSOT(large-scale single object tracking)数据集上进行测试. LaSOT数据集由1400 个序列组成,测试集包含280个视频序列,分为快速运动(fast motion)、遮挡(occlusion)、明暗变化(illumination)、运动模糊(motion blur)、形变(deformation)、尺度变化(scale variation)、超出视线之外(out-of-view)等14个属性. 如图6 所示展示了不同算法在14个属性下的结果对比. 图中,[x , y ]中x 、y 分别表示在该属性下,测试算法AUC得分的最低值和最高值. 本研究算法结果在背景杂质(background clutter)属性下较TrDiMP[9 ] 的略低,其他属性均优于其他算法的,尤其是在视点变化(viewpoint change) 、明暗变化(illumination)和尺度变化(scale variation)属性上均有较大提升. 此外,14个属性下的AUC得分均高于本研究的基线算法TransT[10 ] 的,反映了所提出的带有动态位置编码和多域注意力增强的模型针对多种场景都有强大的特征提取和融合能力,具备良好的鲁棒性. ...
5
... 随着Transformer[8 ] 在目标检测领域展现出强大的能力,Wang等[9 ] 将其集成到基于孪生网络的视觉跟踪算法中. TransT[10 ] 利用注意力机制捕获全局信息,融合模板和搜索区域信息,大大提升了跟踪精度. AiATrack[11 ] 通过计算2次注意力矩阵来增强向量之间的相关性并抑制错误的相关性. TCTrack[12 ] 提出新的结合历史帧信息的框架,可以有效利用整个视频序列. KeepTrack[13 ] 提出可学习的目标候选关联网络,通过逐帧传播的形式对所有目标候选者进行优化,研究如何解决相似物干扰挑战. ToMP[14 ] 使用类相关滤波的目标模型用于定位目标,其权重通过Transformer预测器获得. MixFormer[15 ] 使用Transformer结构进行特征提取和特征融合,能够有效建立全局特征关系,达到了较高的跟踪精度. DropMAE[16 ] 提出自适应的空间-注意力剔除技术,对于给定的query序列,自适应地放弃一部分帧内线索以促进模型学习更可靠的时空对应关系. SeqTrack[17 ] 提出用于视觉跟踪的序列到序列学习框架, 将视觉跟踪问题转换为序列生成问题,以自回归的方式预测目标边界框,采用预训练的Vit进行特征融合计算. 但以上模型在注意力计算时均采用固定的位置编码,未能充分利用模板和搜索区域的位置信息;在特征融合计算时主要使用交叉注意力和自注意力进行,空间和通道维度的特征受到限制. ...
... Comparison of different algorithms on GOT-10K, TrackingNet and UAV123
Tab.1 Trackers GOT-10K TrackingNet UAV123 AO/% SR0.50 /% SR0.75 /% AUC/% P Norm /%P /%AUC/% P /%SiamFC[3 ] 34.8 35.3 9.8 57.1 66.3 53.3 48.5 69.3 SiamPRN++[21 ] 51.7 61.6 32.5 73.3 80.0 69.4 64.2 84.0 ATOM[22 ] 55.6 63.4 40.2 70.3 77.1 64.8 64.3 — Ocean[7 ] 61.1 72.1 47.3 — — — 62.1 82.3 DiMP[23 ] 61.1 71.7 49.2 74.0 80.1 68.7 65.4 85.8 KYS[24 ] 63.6 75.1 51.5 74.0 80.0 68.8 — — DTT[25 ] 63.4 74.9 51.4 79.6 85.0 78.9 — — PrDiMP[26 ] 63.4 73.8 54.3 75.8 81.6 70.4 66.9 87.8 TrSiam[9 ] 66.0 76.6 57.1 78.1 82.9 72.7 — — TrDimp[9 ] 67.1 77.7 58.3 78.4 83.3 73.1 67.5 — KeepTrack[13 ] 68.3 79.3 61.0 78.1 83.5 73.8 69.7 — STARK[27 ] 68.8 78.1 64.1 82.0 86.9 — — — TransT[10 ] 72.3 82.4 68.2 81.4 86.7 80.3 69.1 — CTT[28 ] — — — 81.4 86.4 — — — TCTrack[12 ] — — — — — — 60.4 80.0 AiATrack[11 ] 69.6 77.7 63.2 82.7 87.8 80.4 69.3 90.7 ToMP[14 ] 73.5 85.6 66.5 81.5 86.4 78.9 65.9 85.2 MixFormer[15 ] 73.2 83.2 70.2 82.6 87.7 81.2 68.7 89.5 本研究算法 73.9 83.3 68.6 82.7 87.7 80.8 69.3 90.5
为了测试本研究算法在不同干扰场景下的跟踪能力,选择在LaSOT(large-scale single object tracking)数据集上进行测试. LaSOT数据集由1400 个序列组成,测试集包含280个视频序列,分为快速运动(fast motion)、遮挡(occlusion)、明暗变化(illumination)、运动模糊(motion blur)、形变(deformation)、尺度变化(scale variation)、超出视线之外(out-of-view)等14个属性. 如图6 所示展示了不同算法在14个属性下的结果对比. 图中,[x , y ]中x 、y 分别表示在该属性下,测试算法AUC得分的最低值和最高值. 本研究算法结果在背景杂质(background clutter)属性下较TrDiMP[9 ] 的略低,其他属性均优于其他算法的,尤其是在视点变化(viewpoint change) 、明暗变化(illumination)和尺度变化(scale variation)属性上均有较大提升. 此外,14个属性下的AUC得分均高于本研究的基线算法TransT[10 ] 的,反映了所提出的带有动态位置编码和多域注意力增强的模型针对多种场景都有强大的特征提取和融合能力,具备良好的鲁棒性. ...
... 为了测试本研究模型的跟踪实时性, 将本研究算法与目前主流的跟踪算法在OTB100数据集上进行跟踪精度与速度的对比实验. OTB100由100个视频序列组成,包括25%的灰度序列,评价指标为AUC和P . 如图7 所示列出了本研究算法和其他几种算法的AUC、精度和运行速度(使用2.1节中的测试环境)的对比结果. 图中,L e 表示定位误差阈值,O t 表示预测值与真值之间框的重叠阈值,方框中的数值为定位误差阈值取20时对应的纵坐标的值. 可以看出,本研究算法的速度达到35.1帧/s,而MixFormer[15 ] 的速度仅为24.8帧/s;AUC达到最优;P 为次优,仅比具有相似物干扰分析模块的KeepTrack[13 ] 算法略低,但KeepTrack[13 ] 运行速度较低. 本研究算法的P 比基线算法TransT[10 ] 的提升2.4个百分点,比其他同样使用Transformer结构的ToMP[14 ] 和TCTrack[12 ] 分别高1.1个百分点和9.6个百分点,略高于MixFormer[15 ] 算法的. 结果表明,本研究算法在OTB数据集上有较好的跟踪效果和跟踪速度. ...
... 2)在打斗场景中,跟踪物体较小且存在背景干扰. 在第36、37和51帧目标物较小时,本研究模型较其他算法得到了更加准确的目标框,TransT[10 ] 和TCTrack[12 ] 的表现不佳. TransT[10 ] 在第92帧将背景中的雨滴误认为跟踪对象,本研究模型仍然可以得到较好的跟踪结果. ...
... 3)在钞票视频序列中,出现与目标物相同的物体,对跟踪器造成了干扰. 在第126帧将目标钞票折叠时,5个跟踪器都能够定位目标. 当第306、322、326帧出现相同钞票时,TransT[10 ] 、TCTrack[12 ] 和PrDiMP[26 ] 将另外钞票误认为目标,DiMP[23 ] 则是将2个钞票均识别成目标,本研究模型在此场景下体现出了较强的跟踪能力. ...
4
... 随着Transformer[8 ] 在目标检测领域展现出强大的能力,Wang等[9 ] 将其集成到基于孪生网络的视觉跟踪算法中. TransT[10 ] 利用注意力机制捕获全局信息,融合模板和搜索区域信息,大大提升了跟踪精度. AiATrack[11 ] 通过计算2次注意力矩阵来增强向量之间的相关性并抑制错误的相关性. TCTrack[12 ] 提出新的结合历史帧信息的框架,可以有效利用整个视频序列. KeepTrack[13 ] 提出可学习的目标候选关联网络,通过逐帧传播的形式对所有目标候选者进行优化,研究如何解决相似物干扰挑战. ToMP[14 ] 使用类相关滤波的目标模型用于定位目标,其权重通过Transformer预测器获得. MixFormer[15 ] 使用Transformer结构进行特征提取和特征融合,能够有效建立全局特征关系,达到了较高的跟踪精度. DropMAE[16 ] 提出自适应的空间-注意力剔除技术,对于给定的query序列,自适应地放弃一部分帧内线索以促进模型学习更可靠的时空对应关系. SeqTrack[17 ] 提出用于视觉跟踪的序列到序列学习框架, 将视觉跟踪问题转换为序列生成问题,以自回归的方式预测目标边界框,采用预训练的Vit进行特征融合计算. 但以上模型在注意力计算时均采用固定的位置编码,未能充分利用模板和搜索区域的位置信息;在特征融合计算时主要使用交叉注意力和自注意力进行,空间和通道维度的特征受到限制. ...
... Comparison of different algorithms on GOT-10K, TrackingNet and UAV123
Tab.1 Trackers GOT-10K TrackingNet UAV123 AO/% SR0.50 /% SR0.75 /% AUC/% P Norm /%P /%AUC/% P /%SiamFC[3 ] 34.8 35.3 9.8 57.1 66.3 53.3 48.5 69.3 SiamPRN++[21 ] 51.7 61.6 32.5 73.3 80.0 69.4 64.2 84.0 ATOM[22 ] 55.6 63.4 40.2 70.3 77.1 64.8 64.3 — Ocean[7 ] 61.1 72.1 47.3 — — — 62.1 82.3 DiMP[23 ] 61.1 71.7 49.2 74.0 80.1 68.7 65.4 85.8 KYS[24 ] 63.6 75.1 51.5 74.0 80.0 68.8 — — DTT[25 ] 63.4 74.9 51.4 79.6 85.0 78.9 — — PrDiMP[26 ] 63.4 73.8 54.3 75.8 81.6 70.4 66.9 87.8 TrSiam[9 ] 66.0 76.6 57.1 78.1 82.9 72.7 — — TrDimp[9 ] 67.1 77.7 58.3 78.4 83.3 73.1 67.5 — KeepTrack[13 ] 68.3 79.3 61.0 78.1 83.5 73.8 69.7 — STARK[27 ] 68.8 78.1 64.1 82.0 86.9 — — — TransT[10 ] 72.3 82.4 68.2 81.4 86.7 80.3 69.1 — CTT[28 ] — — — 81.4 86.4 — — — TCTrack[12 ] — — — — — — 60.4 80.0 AiATrack[11 ] 69.6 77.7 63.2 82.7 87.8 80.4 69.3 90.7 ToMP[14 ] 73.5 85.6 66.5 81.5 86.4 78.9 65.9 85.2 MixFormer[15 ] 73.2 83.2 70.2 82.6 87.7 81.2 68.7 89.5 本研究算法 73.9 83.3 68.6 82.7 87.7 80.8 69.3 90.5
为了测试本研究算法在不同干扰场景下的跟踪能力,选择在LaSOT(large-scale single object tracking)数据集上进行测试. LaSOT数据集由1400 个序列组成,测试集包含280个视频序列,分为快速运动(fast motion)、遮挡(occlusion)、明暗变化(illumination)、运动模糊(motion blur)、形变(deformation)、尺度变化(scale variation)、超出视线之外(out-of-view)等14个属性. 如图6 所示展示了不同算法在14个属性下的结果对比. 图中,[x , y ]中x 、y 分别表示在该属性下,测试算法AUC得分的最低值和最高值. 本研究算法结果在背景杂质(background clutter)属性下较TrDiMP[9 ] 的略低,其他属性均优于其他算法的,尤其是在视点变化(viewpoint change) 、明暗变化(illumination)和尺度变化(scale variation)属性上均有较大提升. 此外,14个属性下的AUC得分均高于本研究的基线算法TransT[10 ] 的,反映了所提出的带有动态位置编码和多域注意力增强的模型针对多种场景都有强大的特征提取和融合能力,具备良好的鲁棒性. ...
... 为了测试本研究模型的跟踪实时性, 将本研究算法与目前主流的跟踪算法在OTB100数据集上进行跟踪精度与速度的对比实验. OTB100由100个视频序列组成,包括25%的灰度序列,评价指标为AUC和P . 如图7 所示列出了本研究算法和其他几种算法的AUC、精度和运行速度(使用2.1节中的测试环境)的对比结果. 图中,L e 表示定位误差阈值,O t 表示预测值与真值之间框的重叠阈值,方框中的数值为定位误差阈值取20时对应的纵坐标的值. 可以看出,本研究算法的速度达到35.1帧/s,而MixFormer[15 ] 的速度仅为24.8帧/s;AUC达到最优;P 为次优,仅比具有相似物干扰分析模块的KeepTrack[13 ] 算法略低,但KeepTrack[13 ] 运行速度较低. 本研究算法的P 比基线算法TransT[10 ] 的提升2.4个百分点,比其他同样使用Transformer结构的ToMP[14 ] 和TCTrack[12 ] 分别高1.1个百分点和9.6个百分点,略高于MixFormer[15 ] 算法的. 结果表明,本研究算法在OTB数据集上有较好的跟踪效果和跟踪速度. ...
... [13 ]运行速度较低. 本研究算法的P 比基线算法TransT[10 ] 的提升2.4个百分点,比其他同样使用Transformer结构的ToMP[14 ] 和TCTrack[12 ] 分别高1.1个百分点和9.6个百分点,略高于MixFormer[15 ] 算法的. 结果表明,本研究算法在OTB数据集上有较好的跟踪效果和跟踪速度. ...
10
... 随着Transformer[8 ] 在目标检测领域展现出强大的能力,Wang等[9 ] 将其集成到基于孪生网络的视觉跟踪算法中. TransT[10 ] 利用注意力机制捕获全局信息,融合模板和搜索区域信息,大大提升了跟踪精度. AiATrack[11 ] 通过计算2次注意力矩阵来增强向量之间的相关性并抑制错误的相关性. TCTrack[12 ] 提出新的结合历史帧信息的框架,可以有效利用整个视频序列. KeepTrack[13 ] 提出可学习的目标候选关联网络,通过逐帧传播的形式对所有目标候选者进行优化,研究如何解决相似物干扰挑战. ToMP[14 ] 使用类相关滤波的目标模型用于定位目标,其权重通过Transformer预测器获得. MixFormer[15 ] 使用Transformer结构进行特征提取和特征融合,能够有效建立全局特征关系,达到了较高的跟踪精度. DropMAE[16 ] 提出自适应的空间-注意力剔除技术,对于给定的query序列,自适应地放弃一部分帧内线索以促进模型学习更可靠的时空对应关系. SeqTrack[17 ] 提出用于视觉跟踪的序列到序列学习框架, 将视觉跟踪问题转换为序列生成问题,以自回归的方式预测目标边界框,采用预训练的Vit进行特征融合计算. 但以上模型在注意力计算时均采用固定的位置编码,未能充分利用模板和搜索区域的位置信息;在特征融合计算时主要使用交叉注意力和自注意力进行,空间和通道维度的特征受到限制. ...
... 本研究算法与主流跟踪器在GOT-10K、TrackingNet和UAV123数据集上的对比实验结果如表1 所示. 表中,最优结果加粗显示,次优结果下划线显示. 可以看出,与当前最先进的跟踪器相比,本研究算法在3个数据集下的测试指标均处于最优或次优的位置,较本研究的基线算法TransT[10 ] 有大幅提升. 其中,在GOT-10K数据集上,平均重合度(AO)比TransT[10 ] 和MixFormer[15 ] 的分别提升了1.6个百分点和0.7个百分点;在TrackingNet数据集上,相比于TransT[10 ] 和ToMP[14 ] ,AUC分别提高1.3个百分点和4.3个百分点;在UAV123数据集上,相比于TransT[10 ] 和MixFormer[15 ] ,AUC分别提高0.2个百分点和0.6个百分点. ...
... Comparison of different algorithms on GOT-10K, TrackingNet and UAV123
Tab.1 Trackers GOT-10K TrackingNet UAV123 AO/% SR0.50 /% SR0.75 /% AUC/% P Norm /%P /%AUC/% P /%SiamFC[3 ] 34.8 35.3 9.8 57.1 66.3 53.3 48.5 69.3 SiamPRN++[21 ] 51.7 61.6 32.5 73.3 80.0 69.4 64.2 84.0 ATOM[22 ] 55.6 63.4 40.2 70.3 77.1 64.8 64.3 — Ocean[7 ] 61.1 72.1 47.3 — — — 62.1 82.3 DiMP[23 ] 61.1 71.7 49.2 74.0 80.1 68.7 65.4 85.8 KYS[24 ] 63.6 75.1 51.5 74.0 80.0 68.8 — — DTT[25 ] 63.4 74.9 51.4 79.6 85.0 78.9 — — PrDiMP[26 ] 63.4 73.8 54.3 75.8 81.6 70.4 66.9 87.8 TrSiam[9 ] 66.0 76.6 57.1 78.1 82.9 72.7 — — TrDimp[9 ] 67.1 77.7 58.3 78.4 83.3 73.1 67.5 — KeepTrack[13 ] 68.3 79.3 61.0 78.1 83.5 73.8 69.7 — STARK[27 ] 68.8 78.1 64.1 82.0 86.9 — — — TransT[10 ] 72.3 82.4 68.2 81.4 86.7 80.3 69.1 — CTT[28 ] — — — 81.4 86.4 — — — TCTrack[12 ] — — — — — — 60.4 80.0 AiATrack[11 ] 69.6 77.7 63.2 82.7 87.8 80.4 69.3 90.7 ToMP[14 ] 73.5 85.6 66.5 81.5 86.4 78.9 65.9 85.2 MixFormer[15 ] 73.2 83.2 70.2 82.6 87.7 81.2 68.7 89.5 本研究算法 73.9 83.3 68.6 82.7 87.7 80.8 69.3 90.5
为了测试本研究算法在不同干扰场景下的跟踪能力,选择在LaSOT(large-scale single object tracking)数据集上进行测试. LaSOT数据集由1400 个序列组成,测试集包含280个视频序列,分为快速运动(fast motion)、遮挡(occlusion)、明暗变化(illumination)、运动模糊(motion blur)、形变(deformation)、尺度变化(scale variation)、超出视线之外(out-of-view)等14个属性. 如图6 所示展示了不同算法在14个属性下的结果对比. 图中,[x , y ]中x 、y 分别表示在该属性下,测试算法AUC得分的最低值和最高值. 本研究算法结果在背景杂质(background clutter)属性下较TrDiMP[9 ] 的略低,其他属性均优于其他算法的,尤其是在视点变化(viewpoint change) 、明暗变化(illumination)和尺度变化(scale variation)属性上均有较大提升. 此外,14个属性下的AUC得分均高于本研究的基线算法TransT[10 ] 的,反映了所提出的带有动态位置编码和多域注意力增强的模型针对多种场景都有强大的特征提取和融合能力,具备良好的鲁棒性. ...
... 为了测试本研究模型的跟踪实时性, 将本研究算法与目前主流的跟踪算法在OTB100数据集上进行跟踪精度与速度的对比实验. OTB100由100个视频序列组成,包括25%的灰度序列,评价指标为AUC和P . 如图7 所示列出了本研究算法和其他几种算法的AUC、精度和运行速度(使用2.1节中的测试环境)的对比结果. 图中,L e 表示定位误差阈值,O t 表示预测值与真值之间框的重叠阈值,方框中的数值为定位误差阈值取20时对应的纵坐标的值. 可以看出,本研究算法的速度达到35.1帧/s,而MixFormer[15 ] 的速度仅为24.8帧/s;AUC达到最优;P 为次优,仅比具有相似物干扰分析模块的KeepTrack[13 ] 算法略低,但KeepTrack[13 ] 运行速度较低. 本研究算法的P 比基线算法TransT[10 ] 的提升2.4个百分点,比其他同样使用Transformer结构的ToMP[14 ] 和TCTrack[12 ] 分别高1.1个百分点和9.6个百分点,略高于MixFormer[15 ] 算法的. 结果表明,本研究算法在OTB数据集上有较好的跟踪效果和跟踪速度. ...
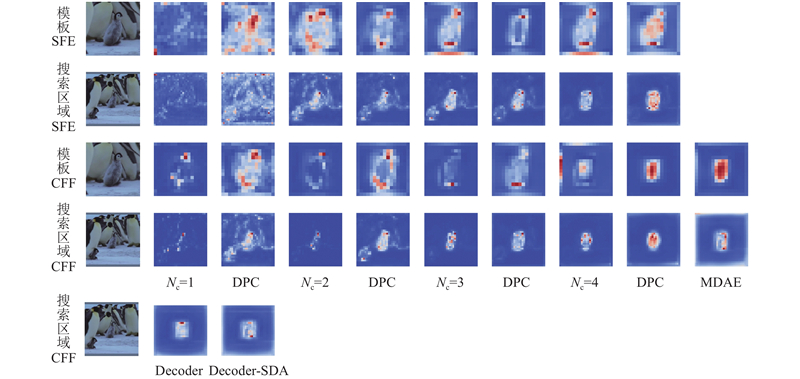
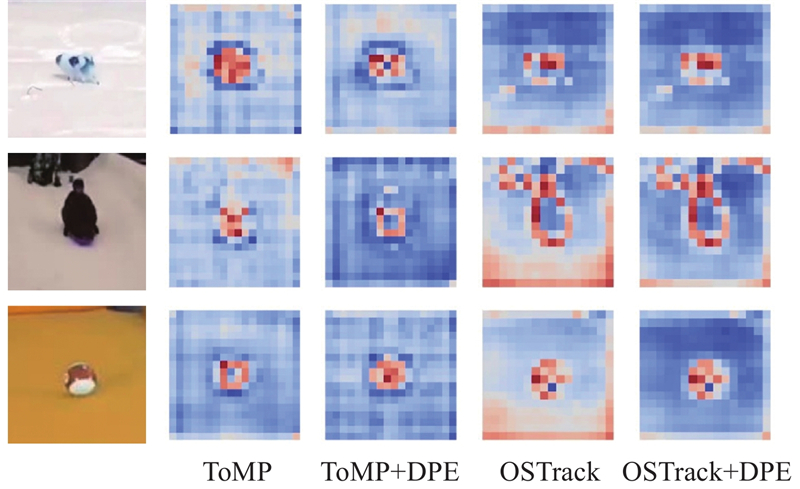
... 整体来看,在自注意力特征增强(SFE)计算时,要分别提取模板和搜索区域的关键信息,模型此时更关注目标的中心位置. 而在交叉注意力特征融合(CFF)计算时,要依靠SFE提取的特征进行特征融合,实现对搜索区域的目标定位,模型此时更关注目标的边缘位置.在网络较浅即N c =1、2时,仅依靠注意力计算不能有效提取模板的中心位置信息,动态位置编码(DPE)模块显著增强了模型提取模板图片和搜索区域中心区域的能力. 在N c =3、4时,DPE模块有效解决了模型对模板特征注意力错位的问题,同时加强了模型对搜索区域边缘信息的注意力. 这表明,融合了动态位置编码的特征融合模块可以通过提高对位置信息的利用来修正错误的注意力,提高模型表达能力. 为了充分验证上述结论,将DPE模块嵌入到ToMP[14 ] 和OSTrack[29 ] 模型中,得到结果如表2 所示. 可以看出,对ToMP[14 ] 和OSTrack[29 ] 增加DPE后,AO分别提升0.6个百分点和0.5个百分点. 此外,将ToMP[14 ] 和OSTrack[29 ] 计算时的特征图进行可视化,如图10 所示. 可以看出,加入DPE模块,在3种场景下均对原本模型计算产生的错误的注意力有一定的修正效果,当第1行场景存在背景干扰时,DPE模块在ToMP[14 ] 和OSTrack[29 ] 上均使得注意力更集中到物体本身. 从第3行可以看出,DPE明显修正了原本模型错误的注意力. ...
... [14 ]和OSTrack[29 ] 增加DPE后,AO分别提升0.6个百分点和0.5个百分点. 此外,将ToMP[14 ] 和OSTrack[29 ] 计算时的特征图进行可视化,如图10 所示. 可以看出,加入DPE模块,在3种场景下均对原本模型计算产生的错误的注意力有一定的修正效果,当第1行场景存在背景干扰时,DPE模块在ToMP[14 ] 和OSTrack[29 ] 上均使得注意力更集中到物体本身. 从第3行可以看出,DPE明显修正了原本模型错误的注意力. ...
... [14 ]和OSTrack[29 ] 计算时的特征图进行可视化,如图10 所示. 可以看出,加入DPE模块,在3种场景下均对原本模型计算产生的错误的注意力有一定的修正效果,当第1行场景存在背景干扰时,DPE模块在ToMP[14 ] 和OSTrack[29 ] 上均使得注意力更集中到物体本身. 从第3行可以看出,DPE明显修正了原本模型错误的注意力. ...
... [14 ]和OSTrack[29 ] 上均使得注意力更集中到物体本身. 从第3行可以看出,DPE明显修正了原本模型错误的注意力. ...
... Performance of ToMP and OSTrack with DPE embedded on GOT-10K
Tab.2 模块 AO/% SR0.50 /% SR0.75 /% ToMP[14 ] 71.9 83.1 66.7 ToMP[14 ] +DPE 72.5 83.4 66.8 OSTrack[29 ] 73.1 82.5 70.9 OSTrack[29 ] +DPE 73.6 82.8 70.8
引入多域注意力增强(MDAE)模块后,模型更加关注模板的中心位置和搜索区域的边缘位置. 同样,解码器在添加空间域增强(SDA)模块后,对目标边缘信息的捕捉更加明显. 这是因为预测头由分类+回归组成,边缘信息更有助于区分前景和背景,从而实现目标定位. ...
... [
14 ]+DPE
72.5 83.4 66.8 OSTrack[29 ] 73.1 82.5 70.9 OSTrack[29 ] +DPE 73.6 82.8 70.8 引入多域注意力增强(MDAE)模块后,模型更加关注模板的中心位置和搜索区域的边缘位置. 同样,解码器在添加空间域增强(SDA)模块后,对目标边缘信息的捕捉更加明显. 这是因为预测头由分类+回归组成,边缘信息更有助于区分前景和背景,从而实现目标定位. ...
6
... 随着Transformer[8 ] 在目标检测领域展现出强大的能力,Wang等[9 ] 将其集成到基于孪生网络的视觉跟踪算法中. TransT[10 ] 利用注意力机制捕获全局信息,融合模板和搜索区域信息,大大提升了跟踪精度. AiATrack[11 ] 通过计算2次注意力矩阵来增强向量之间的相关性并抑制错误的相关性. TCTrack[12 ] 提出新的结合历史帧信息的框架,可以有效利用整个视频序列. KeepTrack[13 ] 提出可学习的目标候选关联网络,通过逐帧传播的形式对所有目标候选者进行优化,研究如何解决相似物干扰挑战. ToMP[14 ] 使用类相关滤波的目标模型用于定位目标,其权重通过Transformer预测器获得. MixFormer[15 ] 使用Transformer结构进行特征提取和特征融合,能够有效建立全局特征关系,达到了较高的跟踪精度. DropMAE[16 ] 提出自适应的空间-注意力剔除技术,对于给定的query序列,自适应地放弃一部分帧内线索以促进模型学习更可靠的时空对应关系. SeqTrack[17 ] 提出用于视觉跟踪的序列到序列学习框架, 将视觉跟踪问题转换为序列生成问题,以自回归的方式预测目标边界框,采用预训练的Vit进行特征融合计算. 但以上模型在注意力计算时均采用固定的位置编码,未能充分利用模板和搜索区域的位置信息;在特征融合计算时主要使用交叉注意力和自注意力进行,空间和通道维度的特征受到限制. ...
... 本研究算法与主流跟踪器在GOT-10K、TrackingNet和UAV123数据集上的对比实验结果如表1 所示. 表中,最优结果加粗显示,次优结果下划线显示. 可以看出,与当前最先进的跟踪器相比,本研究算法在3个数据集下的测试指标均处于最优或次优的位置,较本研究的基线算法TransT[10 ] 有大幅提升. 其中,在GOT-10K数据集上,平均重合度(AO)比TransT[10 ] 和MixFormer[15 ] 的分别提升了1.6个百分点和0.7个百分点;在TrackingNet数据集上,相比于TransT[10 ] 和ToMP[14 ] ,AUC分别提高1.3个百分点和4.3个百分点;在UAV123数据集上,相比于TransT[10 ] 和MixFormer[15 ] ,AUC分别提高0.2个百分点和0.6个百分点. ...
... [15 ],AUC分别提高0.2个百分点和0.6个百分点. ...
... Comparison of different algorithms on GOT-10K, TrackingNet and UAV123
Tab.1 Trackers GOT-10K TrackingNet UAV123 AO/% SR0.50 /% SR0.75 /% AUC/% P Norm /%P /%AUC/% P /%SiamFC[3 ] 34.8 35.3 9.8 57.1 66.3 53.3 48.5 69.3 SiamPRN++[21 ] 51.7 61.6 32.5 73.3 80.0 69.4 64.2 84.0 ATOM[22 ] 55.6 63.4 40.2 70.3 77.1 64.8 64.3 — Ocean[7 ] 61.1 72.1 47.3 — — — 62.1 82.3 DiMP[23 ] 61.1 71.7 49.2 74.0 80.1 68.7 65.4 85.8 KYS[24 ] 63.6 75.1 51.5 74.0 80.0 68.8 — — DTT[25 ] 63.4 74.9 51.4 79.6 85.0 78.9 — — PrDiMP[26 ] 63.4 73.8 54.3 75.8 81.6 70.4 66.9 87.8 TrSiam[9 ] 66.0 76.6 57.1 78.1 82.9 72.7 — — TrDimp[9 ] 67.1 77.7 58.3 78.4 83.3 73.1 67.5 — KeepTrack[13 ] 68.3 79.3 61.0 78.1 83.5 73.8 69.7 — STARK[27 ] 68.8 78.1 64.1 82.0 86.9 — — — TransT[10 ] 72.3 82.4 68.2 81.4 86.7 80.3 69.1 — CTT[28 ] — — — 81.4 86.4 — — — TCTrack[12 ] — — — — — — 60.4 80.0 AiATrack[11 ] 69.6 77.7 63.2 82.7 87.8 80.4 69.3 90.7 ToMP[14 ] 73.5 85.6 66.5 81.5 86.4 78.9 65.9 85.2 MixFormer[15 ] 73.2 83.2 70.2 82.6 87.7 81.2 68.7 89.5 本研究算法 73.9 83.3 68.6 82.7 87.7 80.8 69.3 90.5
为了测试本研究算法在不同干扰场景下的跟踪能力,选择在LaSOT(large-scale single object tracking)数据集上进行测试. LaSOT数据集由1400 个序列组成,测试集包含280个视频序列,分为快速运动(fast motion)、遮挡(occlusion)、明暗变化(illumination)、运动模糊(motion blur)、形变(deformation)、尺度变化(scale variation)、超出视线之外(out-of-view)等14个属性. 如图6 所示展示了不同算法在14个属性下的结果对比. 图中,[x , y ]中x 、y 分别表示在该属性下,测试算法AUC得分的最低值和最高值. 本研究算法结果在背景杂质(background clutter)属性下较TrDiMP[9 ] 的略低,其他属性均优于其他算法的,尤其是在视点变化(viewpoint change) 、明暗变化(illumination)和尺度变化(scale variation)属性上均有较大提升. 此外,14个属性下的AUC得分均高于本研究的基线算法TransT[10 ] 的,反映了所提出的带有动态位置编码和多域注意力增强的模型针对多种场景都有强大的特征提取和融合能力,具备良好的鲁棒性. ...
... 为了测试本研究模型的跟踪实时性, 将本研究算法与目前主流的跟踪算法在OTB100数据集上进行跟踪精度与速度的对比实验. OTB100由100个视频序列组成,包括25%的灰度序列,评价指标为AUC和P . 如图7 所示列出了本研究算法和其他几种算法的AUC、精度和运行速度(使用2.1节中的测试环境)的对比结果. 图中,L e 表示定位误差阈值,O t 表示预测值与真值之间框的重叠阈值,方框中的数值为定位误差阈值取20时对应的纵坐标的值. 可以看出,本研究算法的速度达到35.1帧/s,而MixFormer[15 ] 的速度仅为24.8帧/s;AUC达到最优;P 为次优,仅比具有相似物干扰分析模块的KeepTrack[13 ] 算法略低,但KeepTrack[13 ] 运行速度较低. 本研究算法的P 比基线算法TransT[10 ] 的提升2.4个百分点,比其他同样使用Transformer结构的ToMP[14 ] 和TCTrack[12 ] 分别高1.1个百分点和9.6个百分点,略高于MixFormer[15 ] 算法的. 结果表明,本研究算法在OTB数据集上有较好的跟踪效果和跟踪速度. ...
... [15 ]算法的. 结果表明,本研究算法在OTB数据集上有较好的跟踪效果和跟踪速度. ...
1
... 随着Transformer[8 ] 在目标检测领域展现出强大的能力,Wang等[9 ] 将其集成到基于孪生网络的视觉跟踪算法中. TransT[10 ] 利用注意力机制捕获全局信息,融合模板和搜索区域信息,大大提升了跟踪精度. AiATrack[11 ] 通过计算2次注意力矩阵来增强向量之间的相关性并抑制错误的相关性. TCTrack[12 ] 提出新的结合历史帧信息的框架,可以有效利用整个视频序列. KeepTrack[13 ] 提出可学习的目标候选关联网络,通过逐帧传播的形式对所有目标候选者进行优化,研究如何解决相似物干扰挑战. ToMP[14 ] 使用类相关滤波的目标模型用于定位目标,其权重通过Transformer预测器获得. MixFormer[15 ] 使用Transformer结构进行特征提取和特征融合,能够有效建立全局特征关系,达到了较高的跟踪精度. DropMAE[16 ] 提出自适应的空间-注意力剔除技术,对于给定的query序列,自适应地放弃一部分帧内线索以促进模型学习更可靠的时空对应关系. SeqTrack[17 ] 提出用于视觉跟踪的序列到序列学习框架, 将视觉跟踪问题转换为序列生成问题,以自回归的方式预测目标边界框,采用预训练的Vit进行特征融合计算. 但以上模型在注意力计算时均采用固定的位置编码,未能充分利用模板和搜索区域的位置信息;在特征融合计算时主要使用交叉注意力和自注意力进行,空间和通道维度的特征受到限制. ...
1
... 随着Transformer[8 ] 在目标检测领域展现出强大的能力,Wang等[9 ] 将其集成到基于孪生网络的视觉跟踪算法中. TransT[10 ] 利用注意力机制捕获全局信息,融合模板和搜索区域信息,大大提升了跟踪精度. AiATrack[11 ] 通过计算2次注意力矩阵来增强向量之间的相关性并抑制错误的相关性. TCTrack[12 ] 提出新的结合历史帧信息的框架,可以有效利用整个视频序列. KeepTrack[13 ] 提出可学习的目标候选关联网络,通过逐帧传播的形式对所有目标候选者进行优化,研究如何解决相似物干扰挑战. ToMP[14 ] 使用类相关滤波的目标模型用于定位目标,其权重通过Transformer预测器获得. MixFormer[15 ] 使用Transformer结构进行特征提取和特征融合,能够有效建立全局特征关系,达到了较高的跟踪精度. DropMAE[16 ] 提出自适应的空间-注意力剔除技术,对于给定的query序列,自适应地放弃一部分帧内线索以促进模型学习更可靠的时空对应关系. SeqTrack[17 ] 提出用于视觉跟踪的序列到序列学习框架, 将视觉跟踪问题转换为序列生成问题,以自回归的方式预测目标边界框,采用预训练的Vit进行特征融合计算. 但以上模型在注意力计算时均采用固定的位置编码,未能充分利用模板和搜索区域的位置信息;在特征融合计算时主要使用交叉注意力和自注意力进行,空间和通道维度的特征受到限制. ...
2
... Chu等[18 ] 提出带有卷积计算的位置编码生成器,Woo等[19 ] 利用空间注意力和通道注意力对特征增强,Wang等[20 ] 利用卷积嵌入的方式改进Vision Transformer架构,这些改进方法有效提升了包括跟踪算法在内的多种视觉任务的算法性能. 受以上方法启发,本研究基于TransT[10 ] 框架,设计动态位置编码方法,提高位置信息利用率. 通过多域注意力增强方法,增强混合了模板和搜索区域的特征. 在特征融合解码计算时使用多个不同空洞率的平行卷积融合信息,提高特征表达能力. ...
... 为了保证Transformer在计算过程中可以兼顾到不同位置的信息,通常使用绝对位置编码来确定单个token中各元素的位置关系. 实验已经证明,这种方法可以有效地提升注意力计算的精度. 但这种编码方式忽略了输入的特征图中蕴含的丰富的空间信息,即token之间的相对位置关系,尤其在2次相邻的注意力计算之间,缺失的空间信息会对下一次计算造成干扰. 受文献[18 ]启发,利用二维卷积计算的方法对上述场景进行动态位置编码,其结构如图2 所示. ...
1
... Chu等[18 ] 提出带有卷积计算的位置编码生成器,Woo等[19 ] 利用空间注意力和通道注意力对特征增强,Wang等[20 ] 利用卷积嵌入的方式改进Vision Transformer架构,这些改进方法有效提升了包括跟踪算法在内的多种视觉任务的算法性能. 受以上方法启发,本研究基于TransT[10 ] 框架,设计动态位置编码方法,提高位置信息利用率. 通过多域注意力增强方法,增强混合了模板和搜索区域的特征. 在特征融合解码计算时使用多个不同空洞率的平行卷积融合信息,提高特征表达能力. ...
1
... Chu等[18 ] 提出带有卷积计算的位置编码生成器,Woo等[19 ] 利用空间注意力和通道注意力对特征增强,Wang等[20 ] 利用卷积嵌入的方式改进Vision Transformer架构,这些改进方法有效提升了包括跟踪算法在内的多种视觉任务的算法性能. 受以上方法启发,本研究基于TransT[10 ] 框架,设计动态位置编码方法,提高位置信息利用率. 通过多域注意力增强方法,增强混合了模板和搜索区域的特征. 在特征融合解码计算时使用多个不同空洞率的平行卷积融合信息,提高特征表达能力. ...
1
... Comparison of different algorithms on GOT-10K, TrackingNet and UAV123
Tab.1 Trackers GOT-10K TrackingNet UAV123 AO/% SR0.50 /% SR0.75 /% AUC/% P Norm /%P /%AUC/% P /%SiamFC[3 ] 34.8 35.3 9.8 57.1 66.3 53.3 48.5 69.3 SiamPRN++[21 ] 51.7 61.6 32.5 73.3 80.0 69.4 64.2 84.0 ATOM[22 ] 55.6 63.4 40.2 70.3 77.1 64.8 64.3 — Ocean[7 ] 61.1 72.1 47.3 — — — 62.1 82.3 DiMP[23 ] 61.1 71.7 49.2 74.0 80.1 68.7 65.4 85.8 KYS[24 ] 63.6 75.1 51.5 74.0 80.0 68.8 — — DTT[25 ] 63.4 74.9 51.4 79.6 85.0 78.9 — — PrDiMP[26 ] 63.4 73.8 54.3 75.8 81.6 70.4 66.9 87.8 TrSiam[9 ] 66.0 76.6 57.1 78.1 82.9 72.7 — — TrDimp[9 ] 67.1 77.7 58.3 78.4 83.3 73.1 67.5 — KeepTrack[13 ] 68.3 79.3 61.0 78.1 83.5 73.8 69.7 — STARK[27 ] 68.8 78.1 64.1 82.0 86.9 — — — TransT[10 ] 72.3 82.4 68.2 81.4 86.7 80.3 69.1 — CTT[28 ] — — — 81.4 86.4 — — — TCTrack[12 ] — — — — — — 60.4 80.0 AiATrack[11 ] 69.6 77.7 63.2 82.7 87.8 80.4 69.3 90.7 ToMP[14 ] 73.5 85.6 66.5 81.5 86.4 78.9 65.9 85.2 MixFormer[15 ] 73.2 83.2 70.2 82.6 87.7 81.2 68.7 89.5 本研究算法 73.9 83.3 68.6 82.7 87.7 80.8 69.3 90.5
为了测试本研究算法在不同干扰场景下的跟踪能力,选择在LaSOT(large-scale single object tracking)数据集上进行测试. LaSOT数据集由1400 个序列组成,测试集包含280个视频序列,分为快速运动(fast motion)、遮挡(occlusion)、明暗变化(illumination)、运动模糊(motion blur)、形变(deformation)、尺度变化(scale variation)、超出视线之外(out-of-view)等14个属性. 如图6 所示展示了不同算法在14个属性下的结果对比. 图中,[x , y ]中x 、y 分别表示在该属性下,测试算法AUC得分的最低值和最高值. 本研究算法结果在背景杂质(background clutter)属性下较TrDiMP[9 ] 的略低,其他属性均优于其他算法的,尤其是在视点变化(viewpoint change) 、明暗变化(illumination)和尺度变化(scale variation)属性上均有较大提升. 此外,14个属性下的AUC得分均高于本研究的基线算法TransT[10 ] 的,反映了所提出的带有动态位置编码和多域注意力增强的模型针对多种场景都有强大的特征提取和融合能力,具备良好的鲁棒性. ...
1
... Comparison of different algorithms on GOT-10K, TrackingNet and UAV123
Tab.1 Trackers GOT-10K TrackingNet UAV123 AO/% SR0.50 /% SR0.75 /% AUC/% P Norm /%P /%AUC/% P /%SiamFC[3 ] 34.8 35.3 9.8 57.1 66.3 53.3 48.5 69.3 SiamPRN++[21 ] 51.7 61.6 32.5 73.3 80.0 69.4 64.2 84.0 ATOM[22 ] 55.6 63.4 40.2 70.3 77.1 64.8 64.3 — Ocean[7 ] 61.1 72.1 47.3 — — — 62.1 82.3 DiMP[23 ] 61.1 71.7 49.2 74.0 80.1 68.7 65.4 85.8 KYS[24 ] 63.6 75.1 51.5 74.0 80.0 68.8 — — DTT[25 ] 63.4 74.9 51.4 79.6 85.0 78.9 — — PrDiMP[26 ] 63.4 73.8 54.3 75.8 81.6 70.4 66.9 87.8 TrSiam[9 ] 66.0 76.6 57.1 78.1 82.9 72.7 — — TrDimp[9 ] 67.1 77.7 58.3 78.4 83.3 73.1 67.5 — KeepTrack[13 ] 68.3 79.3 61.0 78.1 83.5 73.8 69.7 — STARK[27 ] 68.8 78.1 64.1 82.0 86.9 — — — TransT[10 ] 72.3 82.4 68.2 81.4 86.7 80.3 69.1 — CTT[28 ] — — — 81.4 86.4 — — — TCTrack[12 ] — — — — — — 60.4 80.0 AiATrack[11 ] 69.6 77.7 63.2 82.7 87.8 80.4 69.3 90.7 ToMP[14 ] 73.5 85.6 66.5 81.5 86.4 78.9 65.9 85.2 MixFormer[15 ] 73.2 83.2 70.2 82.6 87.7 81.2 68.7 89.5 本研究算法 73.9 83.3 68.6 82.7 87.7 80.8 69.3 90.5
为了测试本研究算法在不同干扰场景下的跟踪能力,选择在LaSOT(large-scale single object tracking)数据集上进行测试. LaSOT数据集由1400 个序列组成,测试集包含280个视频序列,分为快速运动(fast motion)、遮挡(occlusion)、明暗变化(illumination)、运动模糊(motion blur)、形变(deformation)、尺度变化(scale variation)、超出视线之外(out-of-view)等14个属性. 如图6 所示展示了不同算法在14个属性下的结果对比. 图中,[x , y ]中x 、y 分别表示在该属性下,测试算法AUC得分的最低值和最高值. 本研究算法结果在背景杂质(background clutter)属性下较TrDiMP[9 ] 的略低,其他属性均优于其他算法的,尤其是在视点变化(viewpoint change) 、明暗变化(illumination)和尺度变化(scale variation)属性上均有较大提升. 此外,14个属性下的AUC得分均高于本研究的基线算法TransT[10 ] 的,反映了所提出的带有动态位置编码和多域注意力增强的模型针对多种场景都有强大的特征提取和融合能力,具备良好的鲁棒性. ...
2
... Comparison of different algorithms on GOT-10K, TrackingNet and UAV123
Tab.1 Trackers GOT-10K TrackingNet UAV123 AO/% SR0.50 /% SR0.75 /% AUC/% P Norm /%P /%AUC/% P /%SiamFC[3 ] 34.8 35.3 9.8 57.1 66.3 53.3 48.5 69.3 SiamPRN++[21 ] 51.7 61.6 32.5 73.3 80.0 69.4 64.2 84.0 ATOM[22 ] 55.6 63.4 40.2 70.3 77.1 64.8 64.3 — Ocean[7 ] 61.1 72.1 47.3 — — — 62.1 82.3 DiMP[23 ] 61.1 71.7 49.2 74.0 80.1 68.7 65.4 85.8 KYS[24 ] 63.6 75.1 51.5 74.0 80.0 68.8 — — DTT[25 ] 63.4 74.9 51.4 79.6 85.0 78.9 — — PrDiMP[26 ] 63.4 73.8 54.3 75.8 81.6 70.4 66.9 87.8 TrSiam[9 ] 66.0 76.6 57.1 78.1 82.9 72.7 — — TrDimp[9 ] 67.1 77.7 58.3 78.4 83.3 73.1 67.5 — KeepTrack[13 ] 68.3 79.3 61.0 78.1 83.5 73.8 69.7 — STARK[27 ] 68.8 78.1 64.1 82.0 86.9 — — — TransT[10 ] 72.3 82.4 68.2 81.4 86.7 80.3 69.1 — CTT[28 ] — — — 81.4 86.4 — — — TCTrack[12 ] — — — — — — 60.4 80.0 AiATrack[11 ] 69.6 77.7 63.2 82.7 87.8 80.4 69.3 90.7 ToMP[14 ] 73.5 85.6 66.5 81.5 86.4 78.9 65.9 85.2 MixFormer[15 ] 73.2 83.2 70.2 82.6 87.7 81.2 68.7 89.5 本研究算法 73.9 83.3 68.6 82.7 87.7 80.8 69.3 90.5
为了测试本研究算法在不同干扰场景下的跟踪能力,选择在LaSOT(large-scale single object tracking)数据集上进行测试. LaSOT数据集由1400 个序列组成,测试集包含280个视频序列,分为快速运动(fast motion)、遮挡(occlusion)、明暗变化(illumination)、运动模糊(motion blur)、形变(deformation)、尺度变化(scale variation)、超出视线之外(out-of-view)等14个属性. 如图6 所示展示了不同算法在14个属性下的结果对比. 图中,[x , y ]中x 、y 分别表示在该属性下,测试算法AUC得分的最低值和最高值. 本研究算法结果在背景杂质(background clutter)属性下较TrDiMP[9 ] 的略低,其他属性均优于其他算法的,尤其是在视点变化(viewpoint change) 、明暗变化(illumination)和尺度变化(scale variation)属性上均有较大提升. 此外,14个属性下的AUC得分均高于本研究的基线算法TransT[10 ] 的,反映了所提出的带有动态位置编码和多域注意力增强的模型针对多种场景都有强大的特征提取和融合能力,具备良好的鲁棒性. ...
... 3)在钞票视频序列中,出现与目标物相同的物体,对跟踪器造成了干扰. 在第126帧将目标钞票折叠时,5个跟踪器都能够定位目标. 当第306、322、326帧出现相同钞票时,TransT[10 ] 、TCTrack[12 ] 和PrDiMP[26 ] 将另外钞票误认为目标,DiMP[23 ] 则是将2个钞票均识别成目标,本研究模型在此场景下体现出了较强的跟踪能力. ...
1
... Comparison of different algorithms on GOT-10K, TrackingNet and UAV123
Tab.1 Trackers GOT-10K TrackingNet UAV123 AO/% SR0.50 /% SR0.75 /% AUC/% P Norm /%P /%AUC/% P /%SiamFC[3 ] 34.8 35.3 9.8 57.1 66.3 53.3 48.5 69.3 SiamPRN++[21 ] 51.7 61.6 32.5 73.3 80.0 69.4 64.2 84.0 ATOM[22 ] 55.6 63.4 40.2 70.3 77.1 64.8 64.3 — Ocean[7 ] 61.1 72.1 47.3 — — — 62.1 82.3 DiMP[23 ] 61.1 71.7 49.2 74.0 80.1 68.7 65.4 85.8 KYS[24 ] 63.6 75.1 51.5 74.0 80.0 68.8 — — DTT[25 ] 63.4 74.9 51.4 79.6 85.0 78.9 — — PrDiMP[26 ] 63.4 73.8 54.3 75.8 81.6 70.4 66.9 87.8 TrSiam[9 ] 66.0 76.6 57.1 78.1 82.9 72.7 — — TrDimp[9 ] 67.1 77.7 58.3 78.4 83.3 73.1 67.5 — KeepTrack[13 ] 68.3 79.3 61.0 78.1 83.5 73.8 69.7 — STARK[27 ] 68.8 78.1 64.1 82.0 86.9 — — — TransT[10 ] 72.3 82.4 68.2 81.4 86.7 80.3 69.1 — CTT[28 ] — — — 81.4 86.4 — — — TCTrack[12 ] — — — — — — 60.4 80.0 AiATrack[11 ] 69.6 77.7 63.2 82.7 87.8 80.4 69.3 90.7 ToMP[14 ] 73.5 85.6 66.5 81.5 86.4 78.9 65.9 85.2 MixFormer[15 ] 73.2 83.2 70.2 82.6 87.7 81.2 68.7 89.5 本研究算法 73.9 83.3 68.6 82.7 87.7 80.8 69.3 90.5
为了测试本研究算法在不同干扰场景下的跟踪能力,选择在LaSOT(large-scale single object tracking)数据集上进行测试. LaSOT数据集由1400 个序列组成,测试集包含280个视频序列,分为快速运动(fast motion)、遮挡(occlusion)、明暗变化(illumination)、运动模糊(motion blur)、形变(deformation)、尺度变化(scale variation)、超出视线之外(out-of-view)等14个属性. 如图6 所示展示了不同算法在14个属性下的结果对比. 图中,[x , y ]中x 、y 分别表示在该属性下,测试算法AUC得分的最低值和最高值. 本研究算法结果在背景杂质(background clutter)属性下较TrDiMP[9 ] 的略低,其他属性均优于其他算法的,尤其是在视点变化(viewpoint change) 、明暗变化(illumination)和尺度变化(scale variation)属性上均有较大提升. 此外,14个属性下的AUC得分均高于本研究的基线算法TransT[10 ] 的,反映了所提出的带有动态位置编码和多域注意力增强的模型针对多种场景都有强大的特征提取和融合能力,具备良好的鲁棒性. ...
1
... Comparison of different algorithms on GOT-10K, TrackingNet and UAV123
Tab.1 Trackers GOT-10K TrackingNet UAV123 AO/% SR0.50 /% SR0.75 /% AUC/% P Norm /%P /%AUC/% P /%SiamFC[3 ] 34.8 35.3 9.8 57.1 66.3 53.3 48.5 69.3 SiamPRN++[21 ] 51.7 61.6 32.5 73.3 80.0 69.4 64.2 84.0 ATOM[22 ] 55.6 63.4 40.2 70.3 77.1 64.8 64.3 — Ocean[7 ] 61.1 72.1 47.3 — — — 62.1 82.3 DiMP[23 ] 61.1 71.7 49.2 74.0 80.1 68.7 65.4 85.8 KYS[24 ] 63.6 75.1 51.5 74.0 80.0 68.8 — — DTT[25 ] 63.4 74.9 51.4 79.6 85.0 78.9 — — PrDiMP[26 ] 63.4 73.8 54.3 75.8 81.6 70.4 66.9 87.8 TrSiam[9 ] 66.0 76.6 57.1 78.1 82.9 72.7 — — TrDimp[9 ] 67.1 77.7 58.3 78.4 83.3 73.1 67.5 — KeepTrack[13 ] 68.3 79.3 61.0 78.1 83.5 73.8 69.7 — STARK[27 ] 68.8 78.1 64.1 82.0 86.9 — — — TransT[10 ] 72.3 82.4 68.2 81.4 86.7 80.3 69.1 — CTT[28 ] — — — 81.4 86.4 — — — TCTrack[12 ] — — — — — — 60.4 80.0 AiATrack[11 ] 69.6 77.7 63.2 82.7 87.8 80.4 69.3 90.7 ToMP[14 ] 73.5 85.6 66.5 81.5 86.4 78.9 65.9 85.2 MixFormer[15 ] 73.2 83.2 70.2 82.6 87.7 81.2 68.7 89.5 本研究算法 73.9 83.3 68.6 82.7 87.7 80.8 69.3 90.5
为了测试本研究算法在不同干扰场景下的跟踪能力,选择在LaSOT(large-scale single object tracking)数据集上进行测试. LaSOT数据集由1400 个序列组成,测试集包含280个视频序列,分为快速运动(fast motion)、遮挡(occlusion)、明暗变化(illumination)、运动模糊(motion blur)、形变(deformation)、尺度变化(scale variation)、超出视线之外(out-of-view)等14个属性. 如图6 所示展示了不同算法在14个属性下的结果对比. 图中,[x , y ]中x 、y 分别表示在该属性下,测试算法AUC得分的最低值和最高值. 本研究算法结果在背景杂质(background clutter)属性下较TrDiMP[9 ] 的略低,其他属性均优于其他算法的,尤其是在视点变化(viewpoint change) 、明暗变化(illumination)和尺度变化(scale variation)属性上均有较大提升. 此外,14个属性下的AUC得分均高于本研究的基线算法TransT[10 ] 的,反映了所提出的带有动态位置编码和多域注意力增强的模型针对多种场景都有强大的特征提取和融合能力,具备良好的鲁棒性. ...
2
... Comparison of different algorithms on GOT-10K, TrackingNet and UAV123
Tab.1 Trackers GOT-10K TrackingNet UAV123 AO/% SR0.50 /% SR0.75 /% AUC/% P Norm /%P /%AUC/% P /%SiamFC[3 ] 34.8 35.3 9.8 57.1 66.3 53.3 48.5 69.3 SiamPRN++[21 ] 51.7 61.6 32.5 73.3 80.0 69.4 64.2 84.0 ATOM[22 ] 55.6 63.4 40.2 70.3 77.1 64.8 64.3 — Ocean[7 ] 61.1 72.1 47.3 — — — 62.1 82.3 DiMP[23 ] 61.1 71.7 49.2 74.0 80.1 68.7 65.4 85.8 KYS[24 ] 63.6 75.1 51.5 74.0 80.0 68.8 — — DTT[25 ] 63.4 74.9 51.4 79.6 85.0 78.9 — — PrDiMP[26 ] 63.4 73.8 54.3 75.8 81.6 70.4 66.9 87.8 TrSiam[9 ] 66.0 76.6 57.1 78.1 82.9 72.7 — — TrDimp[9 ] 67.1 77.7 58.3 78.4 83.3 73.1 67.5 — KeepTrack[13 ] 68.3 79.3 61.0 78.1 83.5 73.8 69.7 — STARK[27 ] 68.8 78.1 64.1 82.0 86.9 — — — TransT[10 ] 72.3 82.4 68.2 81.4 86.7 80.3 69.1 — CTT[28 ] — — — 81.4 86.4 — — — TCTrack[12 ] — — — — — — 60.4 80.0 AiATrack[11 ] 69.6 77.7 63.2 82.7 87.8 80.4 69.3 90.7 ToMP[14 ] 73.5 85.6 66.5 81.5 86.4 78.9 65.9 85.2 MixFormer[15 ] 73.2 83.2 70.2 82.6 87.7 81.2 68.7 89.5 本研究算法 73.9 83.3 68.6 82.7 87.7 80.8 69.3 90.5
为了测试本研究算法在不同干扰场景下的跟踪能力,选择在LaSOT(large-scale single object tracking)数据集上进行测试. LaSOT数据集由1400 个序列组成,测试集包含280个视频序列,分为快速运动(fast motion)、遮挡(occlusion)、明暗变化(illumination)、运动模糊(motion blur)、形变(deformation)、尺度变化(scale variation)、超出视线之外(out-of-view)等14个属性. 如图6 所示展示了不同算法在14个属性下的结果对比. 图中,[x , y ]中x 、y 分别表示在该属性下,测试算法AUC得分的最低值和最高值. 本研究算法结果在背景杂质(background clutter)属性下较TrDiMP[9 ] 的略低,其他属性均优于其他算法的,尤其是在视点变化(viewpoint change) 、明暗变化(illumination)和尺度变化(scale variation)属性上均有较大提升. 此外,14个属性下的AUC得分均高于本研究的基线算法TransT[10 ] 的,反映了所提出的带有动态位置编码和多域注意力增强的模型针对多种场景都有强大的特征提取和融合能力,具备良好的鲁棒性. ...
... 3)在钞票视频序列中,出现与目标物相同的物体,对跟踪器造成了干扰. 在第126帧将目标钞票折叠时,5个跟踪器都能够定位目标. 当第306、322、326帧出现相同钞票时,TransT[10 ] 、TCTrack[12 ] 和PrDiMP[26 ] 将另外钞票误认为目标,DiMP[23 ] 则是将2个钞票均识别成目标,本研究模型在此场景下体现出了较强的跟踪能力. ...
1
... Comparison of different algorithms on GOT-10K, TrackingNet and UAV123
Tab.1 Trackers GOT-10K TrackingNet UAV123 AO/% SR0.50 /% SR0.75 /% AUC/% P Norm /%P /%AUC/% P /%SiamFC[3 ] 34.8 35.3 9.8 57.1 66.3 53.3 48.5 69.3 SiamPRN++[21 ] 51.7 61.6 32.5 73.3 80.0 69.4 64.2 84.0 ATOM[22 ] 55.6 63.4 40.2 70.3 77.1 64.8 64.3 — Ocean[7 ] 61.1 72.1 47.3 — — — 62.1 82.3 DiMP[23 ] 61.1 71.7 49.2 74.0 80.1 68.7 65.4 85.8 KYS[24 ] 63.6 75.1 51.5 74.0 80.0 68.8 — — DTT[25 ] 63.4 74.9 51.4 79.6 85.0 78.9 — — PrDiMP[26 ] 63.4 73.8 54.3 75.8 81.6 70.4 66.9 87.8 TrSiam[9 ] 66.0 76.6 57.1 78.1 82.9 72.7 — — TrDimp[9 ] 67.1 77.7 58.3 78.4 83.3 73.1 67.5 — KeepTrack[13 ] 68.3 79.3 61.0 78.1 83.5 73.8 69.7 — STARK[27 ] 68.8 78.1 64.1 82.0 86.9 — — — TransT[10 ] 72.3 82.4 68.2 81.4 86.7 80.3 69.1 — CTT[28 ] — — — 81.4 86.4 — — — TCTrack[12 ] — — — — — — 60.4 80.0 AiATrack[11 ] 69.6 77.7 63.2 82.7 87.8 80.4 69.3 90.7 ToMP[14 ] 73.5 85.6 66.5 81.5 86.4 78.9 65.9 85.2 MixFormer[15 ] 73.2 83.2 70.2 82.6 87.7 81.2 68.7 89.5 本研究算法 73.9 83.3 68.6 82.7 87.7 80.8 69.3 90.5
为了测试本研究算法在不同干扰场景下的跟踪能力,选择在LaSOT(large-scale single object tracking)数据集上进行测试. LaSOT数据集由1400 个序列组成,测试集包含280个视频序列,分为快速运动(fast motion)、遮挡(occlusion)、明暗变化(illumination)、运动模糊(motion blur)、形变(deformation)、尺度变化(scale variation)、超出视线之外(out-of-view)等14个属性. 如图6 所示展示了不同算法在14个属性下的结果对比. 图中,[x , y ]中x 、y 分别表示在该属性下,测试算法AUC得分的最低值和最高值. 本研究算法结果在背景杂质(background clutter)属性下较TrDiMP[9 ] 的略低,其他属性均优于其他算法的,尤其是在视点变化(viewpoint change) 、明暗变化(illumination)和尺度变化(scale variation)属性上均有较大提升. 此外,14个属性下的AUC得分均高于本研究的基线算法TransT[10 ] 的,反映了所提出的带有动态位置编码和多域注意力增强的模型针对多种场景都有强大的特征提取和融合能力,具备良好的鲁棒性. ...
1
... Comparison of different algorithms on GOT-10K, TrackingNet and UAV123
Tab.1 Trackers GOT-10K TrackingNet UAV123 AO/% SR0.50 /% SR0.75 /% AUC/% P Norm /%P /%AUC/% P /%SiamFC[3 ] 34.8 35.3 9.8 57.1 66.3 53.3 48.5 69.3 SiamPRN++[21 ] 51.7 61.6 32.5 73.3 80.0 69.4 64.2 84.0 ATOM[22 ] 55.6 63.4 40.2 70.3 77.1 64.8 64.3 — Ocean[7 ] 61.1 72.1 47.3 — — — 62.1 82.3 DiMP[23 ] 61.1 71.7 49.2 74.0 80.1 68.7 65.4 85.8 KYS[24 ] 63.6 75.1 51.5 74.0 80.0 68.8 — — DTT[25 ] 63.4 74.9 51.4 79.6 85.0 78.9 — — PrDiMP[26 ] 63.4 73.8 54.3 75.8 81.6 70.4 66.9 87.8 TrSiam[9 ] 66.0 76.6 57.1 78.1 82.9 72.7 — — TrDimp[9 ] 67.1 77.7 58.3 78.4 83.3 73.1 67.5 — KeepTrack[13 ] 68.3 79.3 61.0 78.1 83.5 73.8 69.7 — STARK[27 ] 68.8 78.1 64.1 82.0 86.9 — — — TransT[10 ] 72.3 82.4 68.2 81.4 86.7 80.3 69.1 — CTT[28 ] — — — 81.4 86.4 — — — TCTrack[12 ] — — — — — — 60.4 80.0 AiATrack[11 ] 69.6 77.7 63.2 82.7 87.8 80.4 69.3 90.7 ToMP[14 ] 73.5 85.6 66.5 81.5 86.4 78.9 65.9 85.2 MixFormer[15 ] 73.2 83.2 70.2 82.6 87.7 81.2 68.7 89.5 本研究算法 73.9 83.3 68.6 82.7 87.7 80.8 69.3 90.5
为了测试本研究算法在不同干扰场景下的跟踪能力,选择在LaSOT(large-scale single object tracking)数据集上进行测试. LaSOT数据集由1400 个序列组成,测试集包含280个视频序列,分为快速运动(fast motion)、遮挡(occlusion)、明暗变化(illumination)、运动模糊(motion blur)、形变(deformation)、尺度变化(scale variation)、超出视线之外(out-of-view)等14个属性. 如图6 所示展示了不同算法在14个属性下的结果对比. 图中,[x , y ]中x 、y 分别表示在该属性下,测试算法AUC得分的最低值和最高值. 本研究算法结果在背景杂质(background clutter)属性下较TrDiMP[9 ] 的略低,其他属性均优于其他算法的,尤其是在视点变化(viewpoint change) 、明暗变化(illumination)和尺度变化(scale variation)属性上均有较大提升. 此外,14个属性下的AUC得分均高于本研究的基线算法TransT[10 ] 的,反映了所提出的带有动态位置编码和多域注意力增强的模型针对多种场景都有强大的特征提取和融合能力,具备良好的鲁棒性. ...
6
... 整体来看,在自注意力特征增强(SFE)计算时,要分别提取模板和搜索区域的关键信息,模型此时更关注目标的中心位置. 而在交叉注意力特征融合(CFF)计算时,要依靠SFE提取的特征进行特征融合,实现对搜索区域的目标定位,模型此时更关注目标的边缘位置.在网络较浅即N c =1、2时,仅依靠注意力计算不能有效提取模板的中心位置信息,动态位置编码(DPE)模块显著增强了模型提取模板图片和搜索区域中心区域的能力. 在N c =3、4时,DPE模块有效解决了模型对模板特征注意力错位的问题,同时加强了模型对搜索区域边缘信息的注意力. 这表明,融合了动态位置编码的特征融合模块可以通过提高对位置信息的利用来修正错误的注意力,提高模型表达能力. 为了充分验证上述结论,将DPE模块嵌入到ToMP[14 ] 和OSTrack[29 ] 模型中,得到结果如表2 所示. 可以看出,对ToMP[14 ] 和OSTrack[29 ] 增加DPE后,AO分别提升0.6个百分点和0.5个百分点. 此外,将ToMP[14 ] 和OSTrack[29 ] 计算时的特征图进行可视化,如图10 所示. 可以看出,加入DPE模块,在3种场景下均对原本模型计算产生的错误的注意力有一定的修正效果,当第1行场景存在背景干扰时,DPE模块在ToMP[14 ] 和OSTrack[29 ] 上均使得注意力更集中到物体本身. 从第3行可以看出,DPE明显修正了原本模型错误的注意力. ...
... [29 ]增加DPE后,AO分别提升0.6个百分点和0.5个百分点. 此外,将ToMP[14 ] 和OSTrack[29 ] 计算时的特征图进行可视化,如图10 所示. 可以看出,加入DPE模块,在3种场景下均对原本模型计算产生的错误的注意力有一定的修正效果,当第1行场景存在背景干扰时,DPE模块在ToMP[14 ] 和OSTrack[29 ] 上均使得注意力更集中到物体本身. 从第3行可以看出,DPE明显修正了原本模型错误的注意力. ...
... [29 ]计算时的特征图进行可视化,如图10 所示. 可以看出,加入DPE模块,在3种场景下均对原本模型计算产生的错误的注意力有一定的修正效果,当第1行场景存在背景干扰时,DPE模块在ToMP[14 ] 和OSTrack[29 ] 上均使得注意力更集中到物体本身. 从第3行可以看出,DPE明显修正了原本模型错误的注意力. ...
... [29 ]上均使得注意力更集中到物体本身. 从第3行可以看出,DPE明显修正了原本模型错误的注意力. ...
... Performance of ToMP and OSTrack with DPE embedded on GOT-10K
Tab.2 模块 AO/% SR0.50 /% SR0.75 /% ToMP[14 ] 71.9 83.1 66.7 ToMP[14 ] +DPE 72.5 83.4 66.8 OSTrack[29 ] 73.1 82.5 70.9 OSTrack[29 ] +DPE 73.6 82.8 70.8
引入多域注意力增强(MDAE)模块后,模型更加关注模板的中心位置和搜索区域的边缘位置. 同样,解码器在添加空间域增强(SDA)模块后,对目标边缘信息的捕捉更加明显. 这是因为预测头由分类+回归组成,边缘信息更有助于区分前景和背景,从而实现目标定位. ...
... [
29 ]+DPE
73.6 82.8 70.8 引入多域注意力增强(MDAE)模块后,模型更加关注模板的中心位置和搜索区域的边缘位置. 同样,解码器在添加空间域增强(SDA)模块后,对目标边缘信息的捕捉更加明显. 这是因为预测头由分类+回归组成,边缘信息更有助于区分前景和背景,从而实现目标定位. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}