| 计算机技术、控制工程 |
|

|
|
|
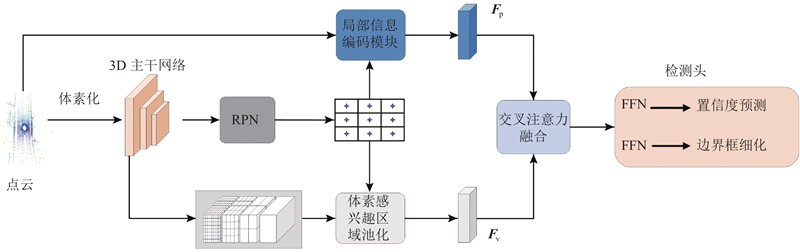
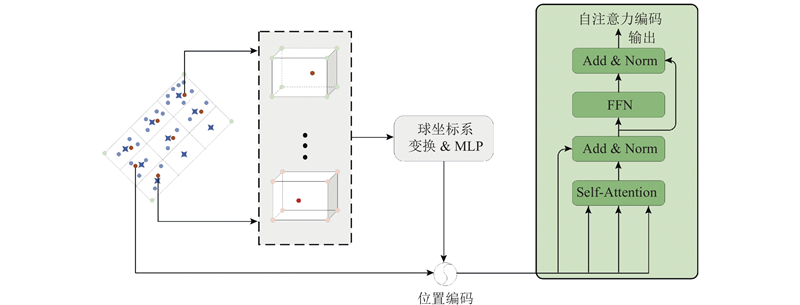
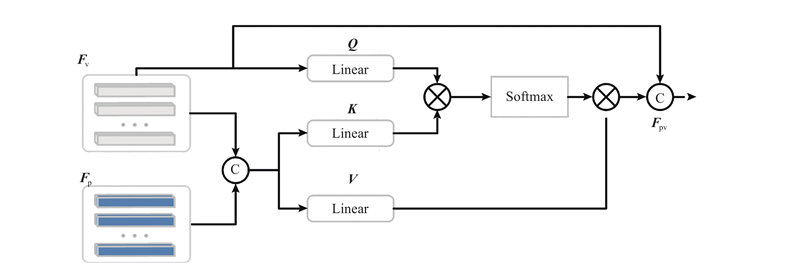
| 基于局部信息融合的点云3D目标检测算法 |
张林杰1( ),柴志雷1,2,*(),王宁1 ),柴志雷1,2,*(),王宁1 |
1. 江南大学 人工智能与计算机学院,江苏 无锡 214122
2. 江苏省模式识别与计算智能工程实验室,江苏 无锡 214122 |
|
| Point cloud 3D object detection algorithm based on local information fusion |
| Linjie ZHANG1(),Zhilei CHAI1,2,*(),Ning WANG1 |
1. School of Artificial Intelligence and Computer Science, Jiangnan University, Wuxi 214122, China
2. Jiangsu Provincial Engineering Laboratory of Pattern Recognition and Computational Intelligence, Wuxi 214122, China |
| 1 |
MAO J, SHI S, WANG X, et al 3D object detection for autonomous driving: a comprehensive survey[J]. International Journal of Computer Vision, 2023, 131: 1909- 1963
doi: 10.1007/s11263-023-01790-1
|
| 2 |
MUHAMMAD K, HUSSAIN T, ULLAH H, et al Vision-based semantic segmentation in scene understanding for autonomous driving: recent achievements, challenges, and outlooks[J]. IEEE Transactions on Intelligent Transportation Systems, 2022, 23 (12): 22694- 22715
doi: 10.1109/TITS.2022.3207665
|
| 3 |
BEHLEY J, GARBADE M, MILIOTO A, et al. Semantickitti: a dataset for semantic scene understanding of lidar sequences [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 9297-9307.
|
| 4 |
LIU Z, WU S, JIN S, et al Investigating pose representations and motion contexts modeling for 3D motion prediction[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 45 (1): 681- 697
|
| 5 |
AKSAN E, KAUFMANN M, CAO P, et al. A spatio-temporal transformer for 3d human motion prediction [C]// International Conference on 3D Vision . [S. l. ]: IEEE, 2021: 567-574.
|
| 6 |
CUI A, CASAS S, SADAT A, et al. Lookout: diverse multi-future prediction and planning for self-driving [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 16107-16116.
|
| 7 |
DERUYTTERE T, VANDENHENDE S, GRUJICIC D, et al. Talk2car: taking control of your self-driving car [C]//. Processing and the 9th International Joint Conference on Natural Language Processing , Hong Kong: ACL, 2019: 2088-2098.
|
| 8 |
SHENG H, CAI S, LIU Y, et al. Improving 3d object detection with channel-wise transformer [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 2743-2752.
|
| 9 |
DENG J, SHI S, LI P, et al. Voxel R-CNN: towards high performance voxel-based 3d object detection [C]// Proceedings of the AAAI Conference on Artificial Intelligence . Vancouver: AAAI, 2021: 1201-1209.
|
| 10 |
GEIGER A, LENZ P, URTASUN R. Are we ready for autonomous driving? the kitti vision benchmark suite [C]// IEEE Conference on Computer Vision and Pattern Recognition . Providence: IEEE, 2012: 3354-3361.
|
| 11 |
SUN P, KRETZSCHMAR H, DOTIWALLA X, et al. Scalability in perception for autonomous driving: Waymo open dataset [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 2446-2454.
|
| 12 |
HUO Weile, JING Tao, REN Shuang Review of 3D object detection for autonomous driving[J]. Computer Science, 2023, 50 (7): 107- 118
|
| 13 |
QI C R, SU H, MO K, et al. Pointnet: deep learning on point sets for 3D classification and segmentation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 652-660.
|
| 14 |
SHI S, WANG X, LI H. Pointrcnn: 3d object proposal generation and detection from point cloud [C]// Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 770-779.
|
| 15 |
QI C R, LITANY O, HE K, et al. Deep hough voting for 3d object detection in point clouds [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 9277-9286.
|
| 16 |
SHI W, RAJKUMAR R. Point-gnn: graph neural network for 3d object detection in a point cloud [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 1711-1719.
|
| 17 |
YANG Z, SUN Y, LIU S, et al. Std: sparse-to-dense 3d object detector for point cloud [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 1951-1960.
|
| 18 |
YANG Z, SUN Y, LIU S, et al. 3dssd: point-based 3d single stage object detector [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 11040-11048.
|
| 19 |
ZHOU Y, TUZEL O. Voxelnet: end-to-end learning for point cloud based 3d object detection [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 4490-4499.
|
| 20 |
YAN Y, MAO Y, LI B Second: sparsely embedded convolutional detection[J]. Sensors, 2018, 18 (10): 3337- 3353
doi: 10.3390/s18103337
|
| 21 |
MAO J, XUE Y, NIU M, et al. Voxel transformer for 3d object detection [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 3164-3173.
|
| 22 |
XU Q, ZHOU Y, WANG W, et al. Spg: unsupervised domain adaptation for 3d object detection via semantic point generation [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 15446-15456.
|
| 23 |
KOO I, LEE I, KIM S H, et al. PG-RCNN: semantic surface point generation for 3D object detection [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Vancouver: IEEE, 2023: 18142-18151.
|
| 24 |
YANG H, WANG W, CHEN M, et al. PVT-SSD: single-stage 3D object detector with point-voxel Transformer [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver: IEEE, 2023: 13476-13487.
|
| 25 |
MAHMOUD A, HU J S, WASLANDER S L. Dense voxel fusion for 3D object detection [C]// Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision . Waikoloa: IEEE, 2023: 663-672.
|
| 26 |
VASWANI A, SHAZEER N, PARMAR N, et al Attention is all you need[J]. Advances in Neural Information Processing Systems, 2017, 30 (2): 6000- 6010
|
| 27 |
HE C, LI R, LI S, et al. Voxel set transformer: a set-to-set approach to 3d object detection from point clouds [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 8417-8427.
|
| 28 |
MAO J, NIU M, BAI H, et al. Pyramid R-CNN: towards better performance and adaptability for 3d object detection [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . [S. l. ]: IEEE, 2021: 2723-2732.
|
| 29 |
PAN X, XIA Z, SONG S, et al. 3d object detection with pointformer [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . [S. l. ]: IEEE, 2021: 7463-7472.
|
| 30 |
SHI S, GUO C, JIANG L, et al. Pv-rcnn: point-voxel feature set abstraction for 3d object detection [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . [S. l. ]: IEEE, 2020: 10529-10538.
|
| 31 |
HU J S, KUAI T, WASLANDER S L. Point density-aware voxels for lidar 3d object detection [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 8469-8478.
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|