[1]
MAO J, SHI S, WANG X, et al 3D object detection for autonomous driving: a comprehensive survey
[J]. International Journal of Computer Vision , 2023 , 131 : 1909 - 1963
DOI:10.1007/s11263-023-01790-1
[本文引用: 1]
[2]
MUHAMMAD K, HUSSAIN T, ULLAH H, et al Vision-based semantic segmentation in scene understanding for autonomous driving: recent achievements, challenges, and outlooks
[J]. IEEE Transactions on Intelligent Transportation Systems , 2022 , 23 (12 ): 22694 - 22715
DOI:10.1109/TITS.2022.3207665
[本文引用: 1]
[3]
BEHLEY J, GARBADE M, MILIOTO A, et al. Semantickitti: a dataset for semantic scene understanding of lidar sequences [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 9297-9307.
[本文引用: 1]
[4]
LIU Z, WU S, JIN S, et al Investigating pose representations and motion contexts modeling for 3D motion prediction
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2022 , 45 (1 ): 681 - 697
[本文引用: 1]
[5]
AKSAN E, KAUFMANN M, CAO P, et al. A spatio-temporal transformer for 3d human motion prediction [C]// International Conference on 3D Vision . [S. l. ]: IEEE, 2021: 567-574.
[本文引用: 1]
[6]
CUI A, CASAS S, SADAT A, et al. Lookout: diverse multi-future prediction and planning for self-driving [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 16107-16116.
[本文引用: 1]
[7]
DERUYTTERE T, VANDENHENDE S, GRUJICIC D, et al. Talk2car: taking control of your self-driving car [C]//. Processing and the 9th International Joint Conference on Natural Language Processing , Hong Kong: ACL, 2019: 2088-2098.
[本文引用: 1]
[8]
SHENG H, CAI S, LIU Y, et al. Improving 3d object detection with channel-wise transformer [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 2743-2752.
[本文引用: 5]
[9]
DENG J, SHI S, LI P, et al. Voxel R-CNN: towards high performance voxel-based 3d object detection [C]// Proceedings of the AAAI Conference on Artificial Intelligence . Vancouver: AAAI, 2021: 1201-1209.
[本文引用: 13]
[10]
GEIGER A, LENZ P, URTASUN R. Are we ready for autonomous driving? the kitti vision benchmark suite [C]// IEEE Conference on Computer Vision and Pattern Recognition . Providence: IEEE, 2012: 3354-3361.
[本文引用: 2]
[11]
SUN P, KRETZSCHMAR H, DOTIWALLA X, et al. Scalability in perception for autonomous driving: Waymo open dataset [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 2446-2454.
[本文引用: 2]
[12]
HUO Weile, JING Tao, REN Shuang Review of 3D object detection for autonomous driving
[J]. Computer Science , 2023 , 50 (7 ): 107 - 118
[本文引用: 1]
[13]
QI C R, SU H, MO K, et al. Pointnet: deep learning on point sets for 3D classification and segmentation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 652-660.
[本文引用: 1]
[14]
SHI S, WANG X, LI H. Pointrcnn: 3d object proposal generation and detection from point cloud [C]// Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 770-779.
[本文引用: 3]
[15]
QI C R, LITANY O, HE K, et al. Deep hough voting for 3d object detection in point clouds [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 9277-9286.
[本文引用: 1]
[16]
SHI W, RAJKUMAR R. Point-gnn: graph neural network for 3d object detection in a point cloud [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 1711-1719.
[本文引用: 2]
[17]
YANG Z, SUN Y, LIU S, et al. Std: sparse-to-dense 3d object detector for point cloud [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 1951-1960.
[本文引用: 1]
[18]
YANG Z, SUN Y, LIU S, et al. 3dssd: point-based 3d single stage object detector [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 11040-11048.
[本文引用: 3]
[19]
ZHOU Y, TUZEL O. Voxelnet: end-to-end learning for point cloud based 3d object detection [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 4490-4499.
[本文引用: 1]
[20]
YAN Y, MAO Y, LI B Second: sparsely embedded convolutional detection
[J]. Sensors , 2018 , 18 (10 ): 3337 - 3353
DOI:10.3390/s18103337
[本文引用: 3]
[21]
MAO J, XUE Y, NIU M, et al. Voxel transformer for 3d object detection [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 3164-3173.
[本文引用: 2]
[22]
XU Q, ZHOU Y, WANG W, et al. Spg: unsupervised domain adaptation for 3d object detection via semantic point generation [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 15446-15456.
[本文引用: 2]
[23]
KOO I, LEE I, KIM S H, et al. PG-RCNN: semantic surface point generation for 3D object detection [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Vancouver: IEEE, 2023: 18142-18151.
[本文引用: 2]
[24]
YANG H, WANG W, CHEN M, et al. PVT-SSD: single-stage 3D object detector with point-voxel Transformer [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver: IEEE, 2023: 13476-13487.
[本文引用: 2]
[25]
MAHMOUD A, HU J S, WASLANDER S L. Dense voxel fusion for 3D object detection [C]// Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision . Waikoloa: IEEE, 2023: 663-672.
[本文引用: 2]
[26]
VASWANI A, SHAZEER N, PARMAR N, et al Attention is all you need
[J]. Advances in Neural Information Processing Systems , 2017 , 30 (2 ): 6000 - 6010
[本文引用: 4]
[27]
HE C, LI R, LI S, et al. Voxel set transformer: a set-to-set approach to 3d object detection from point clouds [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 8417-8427.
[本文引用: 2]
[28]
MAO J, NIU M, BAI H, et al. Pyramid R-CNN: towards better performance and adaptability for 3d object detection [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . [S. l. ]: IEEE, 2021: 2723-2732.
[本文引用: 2]
[29]
PAN X, XIA Z, SONG S, et al. 3d object detection with pointformer [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . [S. l. ]: IEEE, 2021: 7463-7472.
[本文引用: 1]
[30]
SHI S, GUO C, JIANG L, et al. Pv-rcnn: point-voxel feature set abstraction for 3d object detection [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . [S. l. ]: IEEE, 2020: 10529-10538.
[本文引用: 6]
[31]
HU J S, KUAI T, WASLANDER S L. Point density-aware voxels for lidar 3d object detection [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 8469-8478.
[本文引用: 2]
[32]
LI Y, QI X, CHEN Y, et al. Voxel field fusion for 3d object detection [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 1120-1129.
[本文引用: 2]
3D object detection for autonomous driving: a comprehensive survey
1
2023
... 三维目标检测旨在对空间中的目标实例进行精确定位和分类,是实现环境感知的一项重要任务,在自动驾驶、工业制造和智能机器人[1 ] 等智能应用中起到关键作用. 模型的性能与智能系统的安全性有着最直接的关联,精准的目标检测为后续的场景理解[2 -3 ] 、运动预测[4 -5 ] 、规划与控制[6 -7 ] 等任务提供了可靠的环境观察. 点云和图像是在三维目标检测领域中广泛采用的数据结构. 相较于图像,点云受光照环境的影响较小,能够提供更精确的深度和几何信息. 基于点云的方法受到了工业界和学术界的广泛关注. ...
Vision-based semantic segmentation in scene understanding for autonomous driving: recent achievements, challenges, and outlooks
1
2022
... 三维目标检测旨在对空间中的目标实例进行精确定位和分类,是实现环境感知的一项重要任务,在自动驾驶、工业制造和智能机器人[1 ] 等智能应用中起到关键作用. 模型的性能与智能系统的安全性有着最直接的关联,精准的目标检测为后续的场景理解[2 -3 ] 、运动预测[4 -5 ] 、规划与控制[6 -7 ] 等任务提供了可靠的环境观察. 点云和图像是在三维目标检测领域中广泛采用的数据结构. 相较于图像,点云受光照环境的影响较小,能够提供更精确的深度和几何信息. 基于点云的方法受到了工业界和学术界的广泛关注. ...
1
... 三维目标检测旨在对空间中的目标实例进行精确定位和分类,是实现环境感知的一项重要任务,在自动驾驶、工业制造和智能机器人[1 ] 等智能应用中起到关键作用. 模型的性能与智能系统的安全性有着最直接的关联,精准的目标检测为后续的场景理解[2 -3 ] 、运动预测[4 -5 ] 、规划与控制[6 -7 ] 等任务提供了可靠的环境观察. 点云和图像是在三维目标检测领域中广泛采用的数据结构. 相较于图像,点云受光照环境的影响较小,能够提供更精确的深度和几何信息. 基于点云的方法受到了工业界和学术界的广泛关注. ...
Investigating pose representations and motion contexts modeling for 3D motion prediction
1
2022
... 三维目标检测旨在对空间中的目标实例进行精确定位和分类,是实现环境感知的一项重要任务,在自动驾驶、工业制造和智能机器人[1 ] 等智能应用中起到关键作用. 模型的性能与智能系统的安全性有着最直接的关联,精准的目标检测为后续的场景理解[2 -3 ] 、运动预测[4 -5 ] 、规划与控制[6 -7 ] 等任务提供了可靠的环境观察. 点云和图像是在三维目标检测领域中广泛采用的数据结构. 相较于图像,点云受光照环境的影响较小,能够提供更精确的深度和几何信息. 基于点云的方法受到了工业界和学术界的广泛关注. ...
1
... 三维目标检测旨在对空间中的目标实例进行精确定位和分类,是实现环境感知的一项重要任务,在自动驾驶、工业制造和智能机器人[1 ] 等智能应用中起到关键作用. 模型的性能与智能系统的安全性有着最直接的关联,精准的目标检测为后续的场景理解[2 -3 ] 、运动预测[4 -5 ] 、规划与控制[6 -7 ] 等任务提供了可靠的环境观察. 点云和图像是在三维目标检测领域中广泛采用的数据结构. 相较于图像,点云受光照环境的影响较小,能够提供更精确的深度和几何信息. 基于点云的方法受到了工业界和学术界的广泛关注. ...
1
... 三维目标检测旨在对空间中的目标实例进行精确定位和分类,是实现环境感知的一项重要任务,在自动驾驶、工业制造和智能机器人[1 ] 等智能应用中起到关键作用. 模型的性能与智能系统的安全性有着最直接的关联,精准的目标检测为后续的场景理解[2 -3 ] 、运动预测[4 -5 ] 、规划与控制[6 -7 ] 等任务提供了可靠的环境观察. 点云和图像是在三维目标检测领域中广泛采用的数据结构. 相较于图像,点云受光照环境的影响较小,能够提供更精确的深度和几何信息. 基于点云的方法受到了工业界和学术界的广泛关注. ...
1
... 三维目标检测旨在对空间中的目标实例进行精确定位和分类,是实现环境感知的一项重要任务,在自动驾驶、工业制造和智能机器人[1 ] 等智能应用中起到关键作用. 模型的性能与智能系统的安全性有着最直接的关联,精准的目标检测为后续的场景理解[2 -3 ] 、运动预测[4 -5 ] 、规划与控制[6 -7 ] 等任务提供了可靠的环境观察. 点云和图像是在三维目标检测领域中广泛采用的数据结构. 相较于图像,点云受光照环境的影响较小,能够提供更精确的深度和几何信息. 基于点云的方法受到了工业界和学术界的广泛关注. ...
5
... 当前基于点云的模型存在以下3个问题. 1)基于点的方法直接处理无序的点云,导致计算资源占用高,且难以提取有效特征. 这类方法通过迭代采样和分组来抽象一组点,利用堆叠的多层感知器和最大池化层学习特征表示. 基于点的方法依赖于抽象的上下文点的数量和半径范围,难以建模上下文点之间的关联特征. 2)基于体素的方法将点云转换为规则的体素表示,可以利用稀疏卷积神经网络来学习点云的深度体素特征. 这种量化的表示方式损失了点云数据中的目标细节信息,降低了最终的检测性能. 3)目前最先进的模型在利用区域提议网络(region proposal network, RPN)进行检测时可以取得很高的召回率,但是在平均精度上表现一般[8 ] . 这主要是因为难以从三维提议中有效编码目标信息和提取鲁棒特征. ...
... Transformer[26 ] 模型在二维图像识别和检测任务中展现出强大的特征表示能力. 这启发了一些研究尝试将注意力机制应用到点云理解任务中,利用其建模全局上下文依赖关系的优势来增强点云的特征表达能力. Yang等[18 ] 使用基于注意力机制的编码器-解码器结构对点云进行多尺度学习,捕获全局上下文信息,实现端到端的目标检测. Sheng等[8 ] 提出通道注意力模块,可以有效增强特征在通道层面的相关性,在候选框细化中使用该模块,提升特征表达能力. He等[27 ] 提出基于体素集合的自注意力骨干网络,该方法侧重于利用集合到集合的学习方式,捕捉局部点集与对应的体素集之间的关系,实现更准确的目标检测. Mao等[28 ] 基于金字塔结构的特征表示方法,通过在不同尺度上对输入点云进行特征提取,捕捉不同尺度的目标信息. 这种结构使得网络能够对目标的多个尺度进行建模,提高特征提取的鲁棒性. ...
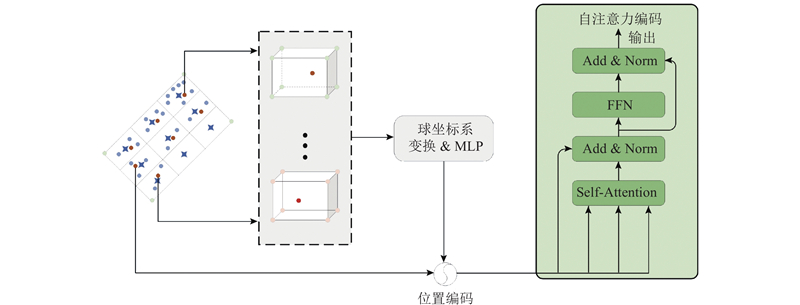
... 候选框内的子体素点集共同表现目标的细节特征,包括纹理、形状和结构等信息. 为了更好地突显这些细节特征,提出一种策略,用以凸显候选框内部点与周围环境之间的差异性,保留目标独特的细节信息. 受CT3D[8 ] 的启发,计算每个子体素点与提议的8个顶点之间的相对坐标关系. 相对坐标表示为 ...
... Comparison of detection result from different algorithm on KITTI test dataset
Tab.1 方法 模态 AP3D /% APBEV /% 简单 中等 困难 mAP 简单 中等 困难 mAP Point-GNN[16 ] L 88.33 79.47 72.29 80.03 93.11 89.17 83.90 88.73 3DSSD[18 ] L 88.36 79.57 74.55 80.83 92.66 89.02 85.86 89.18 PV-RCNN[30 ] L 90.25 81.43 76.82 82.83 94.98 90.65 86.14 90.60 Voxel-RCNN[9 ] L 90.90 81.62 77.06 83.19 94.85 88.83 86.13 89.94 CT3D[8 ] L 87.83 81.77 77.16 82.25 92.36 88.83 84.07 88.42 Pyramid-PV[28 ] L 88.39 82.08 77.49 82.65 92.19 88.84 86.21 89.08 VoTr[21 ] L 89.90 82.09 79.14 83.71 94.03 90.34 86.14 90.17 SPG[22 ] L 90.50 82.13 78.90 83.84 94.33 88.70 85.98 89.67 VoxSet[27 ] L 88.53 82.06 77.46 82.68 — — — — PDV[31 ] L 90.43 81.86 77.36 83.22 94.56 90.48 86.23 90.42 VFF[32 ] L+I 89.50 82.09 79.29 83.62 — — — — PG-RCNN[23 ] I 89.38 82.13 77.33 82.88 93.39 89.46 86.54 89.80 PVT-SSD[24 ] I 90.65 82.29 76.85 83.26 95.23 91.63 86.43 91.10 DVF-PV[25 ] L+I 90.99 82.40 77.37 83.58 — — — — 本文方法 L 91.60 82.53 77.83 83.99 95.59 91.37 86.72 91.23
在实验过程中,采用共同的划分方法将训练样本划分成训练集和验证集. 如表2 所示为本文方法在KITTI验证集上的结果,采用40个召回位置记录平均准确率. 利用本文方法取得了最先进的结果,相比于基线模型Voxel-RCNN[9 ] ,在简单、中等、困难的难度级别上分别将三维AP提高了0.89%、0.71%、0.71%,俯视图AP提高了1.14%、0.86%、0.76%. ...
... Comparison of detection result from different algorithm on KITTI validation dataset
Tab.2 方法 AP3D /% APBEV /% 简单 中等 困难 简单 中等 困难 PV-RCNN[30 ] 92.57 84.43 82.69 95.76 91.11 88.93 Voxel-RCNN[9 ] 92.38 85.29 82.86 95.52 91.25 88.99 PDV[31 ] 92.56 85.29 83.05 — — — VFF[32 ] 92.47 85.65 83.38 95.62 91.75 91.39 CT3D[8 ] 92.85 85.82 83.46 96.14 91.88 89.63 本文方法 93.27 86.00 83.57 96.66 92.11 89.75
4.3. Waymo数据集上不同算法的检测结果对比 如表3 所示为本文方法与先进方法的性能比较. 参与对比的模型有SECOND[20 ] 、PV-RCNN[30 ] 和Voxel-RCNN[9 ] ,所有模型都基于PyTorch实现,本文使用训练集的1/10进行训练,使用验证集的1/10进行测试. 与基线模型Voxel-RCNN[9 ] 相比,本文模型在等级1上的AP提升了1.02%,在等级2上提升了1.09%. 本文方法在所有期望的距离范围上都获得了良好的结果,其中在50 m以上的长距离范围内获得了最大的性能提升,在等级1和等级2上的AP分别提升了2.03%和1.72%. 从表3 可以看出,本文方法在2个难度级别上取得了较高的APH性能,验证了本文在捕获目标细节和空间关系方面具有优势,能够有效地处理各种目标难度. ...
13
... 为了解决上述问题,本文在文献[9 ]的研究基础上,提出基于局部信息融合的三维目标检测模型. 模型利用体素表示和点表示的优点实现高精度的检测效果,其核心组件为局部信息编码(local information encoding, LIE)模块和交叉注意力融合(cross-attention fusion, CAF)模块. 对点云进行体素化表示,通过稀疏卷积编码多尺度体素特征和生成3D候选框. LIE模块通过建立候选框内部点云与候选框的相对位置关系来编码得到更细粒度的点特征信息. CAF模块将多尺度体素特征与点特征自适应地融合,以弥补体素化过程中目标位置信息的损失. 由于LIE模块和CAF模块既保留了体素表示的空间整体性,又包含了关键局部细节信息,在KITTI数据集[10 ] 和Waymo数据集[11 ] 上的大量实验结果表明,所提出的算法在检测精度性能上具有明显的优势. ...
... 基于体素的方法将点云进行规则化处理,这种规则的表示方便应用卷积神经网络对其进行特征提取. Zhou等[19 ] 提出点云到体素的编码层,设计稠密的三维卷积网络,在体素上直接学习特征,验证了利用体素的方法可以有效地解析点云并实现目标检测. 由于点云数据本身分布稀疏,在转换到体素表示后,会出现大量空的体素没有点信息. 三维稠密卷积操作会对所有的体素均进行卷积计算,包括未包含点云的体素,导致大量的无效计算和计算资源浪费. 之后的研究中,Yan等[20 ] 使用稀疏卷积代替密集卷积,可以跳过空体素的计算,有针对性和高效地提取和学习体素数据的特征. Deng等[9 ] 提出体素查询方法,在目标候选框内聚合相邻体素的特征到中心体素上,扩大了体素的感受野,取得了较好的效果. Mao等[21 ] 提出新的体素特征增强模块,通过残差学习来增强体素特征,将体素的坐标信息整合到主干网络,增强对局部结构的建模能力. Xu等[22 ] 提出语义点集生成模块,用于生成前景体素的语义点集,填补前景物体缺失的部分. Koo等[23 ] 引入感兴趣区域点生成模块,用于估计前景对象的完整形状和位移,为每个候选框创建语义曲面点云. Yang等[24 ] 通过从虚拟距离图像中获取参考点,引入点体素变换模块,自适应地将参考点周围的上下文信息和局部集合信息融合到内容查询中. Mahmoud等[25 ] 提出密集体素融合的方法,用于生成多尺度的密集体素特征,以提升对稀疏区域的特征表达能力. ...
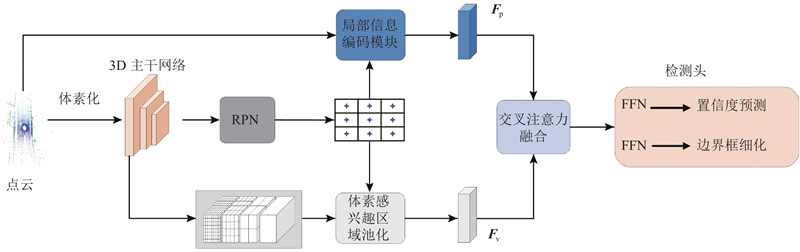
... 提出的局部信息融合方法为两阶段目标检测器,整体框架如图1 所示. 整个网络的第一阶段由主干网络和区域提议网络组成,分别用于特征学习和初始化提议框. 在细化阶段,采用当前的先进方法[9 ] 中提出的体素感兴趣区域池化操作来聚合多尺度体素特征,以用于编码候选框的全局特征${{\boldsymbol{F}}_{\text{v}}}$ . 本文提出2个新模块:局部信息编码(LIE)模块和交叉注意力融合(CAF)模块,以改善体素化过程中可能丢失目标细节信息的问题. LIE模块通过编码局部信息,有助于保留目标的细微特征. CAF模块引入交叉注意力机制,将全局体素特征${{\boldsymbol{F}}_{\text{v}}}$
... 式中:${L_{{\text{rpn}}}}$ [9 ] ;${L_{{\text{head}}}}$
... 在测试集上与最先进的模型对比时,采用一致的训练策略,用全部的训练样本作为训练集. 如表1 所示为本文方法与最新方法在KITTI官方测试服务器上的性能比较,采用40个召回位置记录车辆类别的检测结果. 图中,AP3D 为三维AP,APBEV 为鸟瞰(BEV)视角下的平均精度. 记录方法遵循官方协议,分别记录了三维场景和俯视图(bird-eye-view, BEV)场景下简单、中等和困难任务的平均准确度. 结果表明,本文方法在激光雷达(LiDAR, L)和多模态(LiDAR+ Image, L+I)2种数据模式下,在车辆检测的简单和中等难度级别上都获得了最佳性能. 与基线模型Voxel-RCNN[9 ] 相比,在最重要的中等难度级别上将三维AP提高了0.91%. 在3种任务的三维和俯视图平均准确率方面,均展现出了模型的卓越性能,显示了提出方法的高度鲁棒性. ...
... Comparison of detection result from different algorithm on KITTI test dataset
Tab.1 方法 模态 AP3D /% APBEV /% 简单 中等 困难 mAP 简单 中等 困难 mAP Point-GNN[16 ] L 88.33 79.47 72.29 80.03 93.11 89.17 83.90 88.73 3DSSD[18 ] L 88.36 79.57 74.55 80.83 92.66 89.02 85.86 89.18 PV-RCNN[30 ] L 90.25 81.43 76.82 82.83 94.98 90.65 86.14 90.60 Voxel-RCNN[9 ] L 90.90 81.62 77.06 83.19 94.85 88.83 86.13 89.94 CT3D[8 ] L 87.83 81.77 77.16 82.25 92.36 88.83 84.07 88.42 Pyramid-PV[28 ] L 88.39 82.08 77.49 82.65 92.19 88.84 86.21 89.08 VoTr[21 ] L 89.90 82.09 79.14 83.71 94.03 90.34 86.14 90.17 SPG[22 ] L 90.50 82.13 78.90 83.84 94.33 88.70 85.98 89.67 VoxSet[27 ] L 88.53 82.06 77.46 82.68 — — — — PDV[31 ] L 90.43 81.86 77.36 83.22 94.56 90.48 86.23 90.42 VFF[32 ] L+I 89.50 82.09 79.29 83.62 — — — — PG-RCNN[23 ] I 89.38 82.13 77.33 82.88 93.39 89.46 86.54 89.80 PVT-SSD[24 ] I 90.65 82.29 76.85 83.26 95.23 91.63 86.43 91.10 DVF-PV[25 ] L+I 90.99 82.40 77.37 83.58 — — — — 本文方法 L 91.60 82.53 77.83 83.99 95.59 91.37 86.72 91.23
在实验过程中,采用共同的划分方法将训练样本划分成训练集和验证集. 如表2 所示为本文方法在KITTI验证集上的结果,采用40个召回位置记录平均准确率. 利用本文方法取得了最先进的结果,相比于基线模型Voxel-RCNN[9 ] ,在简单、中等、困难的难度级别上分别将三维AP提高了0.89%、0.71%、0.71%,俯视图AP提高了1.14%、0.86%、0.76%. ...
... 在实验过程中,采用共同的划分方法将训练样本划分成训练集和验证集. 如表2 所示为本文方法在KITTI验证集上的结果,采用40个召回位置记录平均准确率. 利用本文方法取得了最先进的结果,相比于基线模型Voxel-RCNN[9 ] ,在简单、中等、困难的难度级别上分别将三维AP提高了0.89%、0.71%、0.71%,俯视图AP提高了1.14%、0.86%、0.76%. ...
... Comparison of detection result from different algorithm on KITTI validation dataset
Tab.2 方法 AP3D /% APBEV /% 简单 中等 困难 简单 中等 困难 PV-RCNN[30 ] 92.57 84.43 82.69 95.76 91.11 88.93 Voxel-RCNN[9 ] 92.38 85.29 82.86 95.52 91.25 88.99 PDV[31 ] 92.56 85.29 83.05 — — — VFF[32 ] 92.47 85.65 83.38 95.62 91.75 91.39 CT3D[8 ] 92.85 85.82 83.46 96.14 91.88 89.63 本文方法 93.27 86.00 83.57 96.66 92.11 89.75
4.3. Waymo数据集上不同算法的检测结果对比 如表3 所示为本文方法与先进方法的性能比较. 参与对比的模型有SECOND[20 ] 、PV-RCNN[30 ] 和Voxel-RCNN[9 ] ,所有模型都基于PyTorch实现,本文使用训练集的1/10进行训练,使用验证集的1/10进行测试. 与基线模型Voxel-RCNN[9 ] 相比,本文模型在等级1上的AP提升了1.02%,在等级2上提升了1.09%. 本文方法在所有期望的距离范围上都获得了良好的结果,其中在50 m以上的长距离范围内获得了最大的性能提升,在等级1和等级2上的AP分别提升了2.03%和1.72%. 从表3 可以看出,本文方法在2个难度级别上取得了较高的APH性能,验证了本文在捕获目标细节和空间关系方面具有优势,能够有效地处理各种目标难度. ...
... 如表3 所示为本文方法与先进方法的性能比较. 参与对比的模型有SECOND[20 ] 、PV-RCNN[30 ] 和Voxel-RCNN[9 ] ,所有模型都基于PyTorch实现,本文使用训练集的1/10进行训练,使用验证集的1/10进行测试. 与基线模型Voxel-RCNN[9 ] 相比,本文模型在等级1上的AP提升了1.02%,在等级2上提升了1.09%. 本文方法在所有期望的距离范围上都获得了良好的结果,其中在50 m以上的长距离范围内获得了最大的性能提升,在等级1和等级2上的AP分别提升了2.03%和1.72%. 从表3 可以看出,本文方法在2个难度级别上取得了较高的APH性能,验证了本文在捕获目标细节和空间关系方面具有优势,能够有效地处理各种目标难度. ...
... [9 ]相比,本文模型在等级1上的AP提升了1.02%,在等级2上提升了1.09%. 本文方法在所有期望的距离范围上都获得了良好的结果,其中在50 m以上的长距离范围内获得了最大的性能提升,在等级1和等级2上的AP分别提升了2.03%和1.72%. 从表3 可以看出,本文方法在2个难度级别上取得了较高的APH性能,验证了本文在捕获目标细节和空间关系方面具有优势,能够有效地处理各种目标难度. ...
... Comparison of detection results from different algorithms on Waymo validation dataset
Tab.3 方法 AP/APH (LEVEL_1) AP/APH (LEVEL_2) d = 0~30 md = 30~50 md > 50 m均值 d = 0~30 md = 30~50 md > 50 m均值 SECOND[20 ] 88.66/88.18 67.35/66.70 42.89/42.09 70.07/69.52 87.33/86.86 60.92/60.23 32.39/31.77 61.63/61.14 PV-RCNN[30 ] 91.30/90.56 73.00/72.31 51.35/50.34 74.70/74.09 89.75/89.29 66.32/65.68 39.27/38.46 66.05/65.50 Voxel-RCNN[9 ] 90.81/90.36 72.43/71.78 50.37/49.47 73.90/73.32 89.50/89.05 65.68/65.08 38.32/37.61 65.10/64.58 本文方法 91.20 /90.77 73.28 /72.68 52.40 /51.45 74.92 /74.38 89.91 /89.48 66.58 /66.02 40.04 /39.29 66.19 /65.69
4.4. KITTI数据集上的消融实验结果展示与分析 为了分析本文所提出LIE模块和CAF模块的有效性,对2个模块进行消融实验. 可知,LIE模块可以分为2个部分:局部空间位置编码(local position encoding, LPE)和自注意力信息捕获(self-attention information capture, SIC). 如表4 所示,对整体架构进行全面的消融实验,验证每个组件的有效性. ...
... 表6 中,v 为推理速度,C 为计算量. 如表6 所示,相对于基线模型Voxel-RCNN[9 ] ,本文方法在提升检测性能0.79%的同时,增大了推理时间和计算量. 与基于点方法Point-RCNN[14 ] 相比,本文方法不仅使推理时间减少近56.21%,而且检测效果显著提升. 与点体素方法PV-RCNN[30 ] 相比,本文方法在推理时间和计算量方面均具有显著优势. 这得益于本文在体素方法的基础上,高效率编码多尺度体素特征和快速生成候选框,在细化阶段利用原始点云编码局部特征,避免了对全场景信息进行点特征提取,降低了时间和计算上的成本. ...
... Comparison of performance and efficiency of proposed method and other model
Tab.6 模型 v /(帧·s−1 )C /GBAP3D /% Voxel-RCNN[9 ] 0.041 22.78 85.29 PV-RCNN[30 ] 0.128 89.27 84.43 Point-RCNN[14 ] 0.153 27.71 78.63 本文方法 0.067 26.64 86.00
本文方法通过局部信息的重编码,在性能和效率方面取得了具有竞争力的效果. 局部信息的获取取决于RPN阶段生成的候选框质量. 由于RPN阶段采用普通卷积,相较于稀疏卷积,耗时较大. 普通卷积会对细化阶段的信息融合效果及整体的模型性能产生影响. 在接下来的工作中,将改进生成候选框的方式,利用稀疏卷积的高性能来提高候选框生成的速度. ...
2
... 为了解决上述问题,本文在文献[9 ]的研究基础上,提出基于局部信息融合的三维目标检测模型. 模型利用体素表示和点表示的优点实现高精度的检测效果,其核心组件为局部信息编码(local information encoding, LIE)模块和交叉注意力融合(cross-attention fusion, CAF)模块. 对点云进行体素化表示,通过稀疏卷积编码多尺度体素特征和生成3D候选框. LIE模块通过建立候选框内部点云与候选框的相对位置关系来编码得到更细粒度的点特征信息. CAF模块将多尺度体素特征与点特征自适应地融合,以弥补体素化过程中目标位置信息的损失. 由于LIE模块和CAF模块既保留了体素表示的空间整体性,又包含了关键局部细节信息,在KITTI数据集[10 ] 和Waymo数据集[11 ] 上的大量实验结果表明,所提出的算法在检测精度性能上具有明显的优势. ...
... KITTI数据集[10 ] 目前是评估计算机视觉任务最流行的城市街景数据集,也是三维目标检测最常用的数据集之一. 该数据集包含了7 481个训练样本和7 518个测试样本,适用于自动驾驶场景. 由于测试集不提供真值,遵循传统的样本划分方式,将训练集划分为3 712个用于训练和3769 个用于验证. 在验证集上记录结果,与在线测试排行榜进行比较. ...
2
... 为了解决上述问题,本文在文献[9 ]的研究基础上,提出基于局部信息融合的三维目标检测模型. 模型利用体素表示和点表示的优点实现高精度的检测效果,其核心组件为局部信息编码(local information encoding, LIE)模块和交叉注意力融合(cross-attention fusion, CAF)模块. 对点云进行体素化表示,通过稀疏卷积编码多尺度体素特征和生成3D候选框. LIE模块通过建立候选框内部点云与候选框的相对位置关系来编码得到更细粒度的点特征信息. CAF模块将多尺度体素特征与点特征自适应地融合,以弥补体素化过程中目标位置信息的损失. 由于LIE模块和CAF模块既保留了体素表示的空间整体性,又包含了关键局部细节信息,在KITTI数据集[10 ] 和Waymo数据集[11 ] 上的大量实验结果表明,所提出的算法在检测精度性能上具有明显的优势. ...
... Waymo数据集[11 ] 目前是自动驾驶领域最大、最多样化的三维目标检测数据集之一,包含798个训练序列(约158 000个点云样本)和202个验证序列(约40 000个点云样本). 鉴于Waymo数据集的巨大规模,需要大量的计算资源. 本文选择使用训练集的1/10进行训练,将验证集的1/10用于测试. ...
Review of 3D object detection for autonomous driving
1
2023
... 点云是一组无序点的集合,具有排列不变性和旋转不变性,这些特性使得研究者难以用处理规则序列的方式去处理点云[12 ] . Qi等[13 ] 提出PointNet系列,利用排列不变性操作,如多层感知器和最大池化层,进行点云特征学习. PointNet系列在点云上的成功应用促使研究者提出各种架构从原始点云中检测目标. Shi等[14 ] 提出基于点的两阶段检测网络:第一阶段使用特征学习网络直接学习点云信息并生成3D候选框;第二阶段将候选框进行坐标变换以细化候选框的细节,实现高精度的目标检测结果. Qi等[15 ] 提出投票策略,利用学习得到的深度特征,将投票空间量化为具体的检测框候选. Shi等[16 ] 使用固定半径的最近邻图对原始点云进行编码,学习点云的局部和全局特征,通过在图上迭代传播,增强点云特征的表达能力. Yang等[17 ] 提出将稀疏点特征转换为稠密体素特征,提升特征的区分能力,从而提升检测精度. Yang等[18 ] 基于特征的距离提出最远点采样策略,用于点云采样和分组,直接在原始点云上进行检测. ...
1
... 点云是一组无序点的集合,具有排列不变性和旋转不变性,这些特性使得研究者难以用处理规则序列的方式去处理点云[12 ] . Qi等[13 ] 提出PointNet系列,利用排列不变性操作,如多层感知器和最大池化层,进行点云特征学习. PointNet系列在点云上的成功应用促使研究者提出各种架构从原始点云中检测目标. Shi等[14 ] 提出基于点的两阶段检测网络:第一阶段使用特征学习网络直接学习点云信息并生成3D候选框;第二阶段将候选框进行坐标变换以细化候选框的细节,实现高精度的目标检测结果. Qi等[15 ] 提出投票策略,利用学习得到的深度特征,将投票空间量化为具体的检测框候选. Shi等[16 ] 使用固定半径的最近邻图对原始点云进行编码,学习点云的局部和全局特征,通过在图上迭代传播,增强点云特征的表达能力. Yang等[17 ] 提出将稀疏点特征转换为稠密体素特征,提升特征的区分能力,从而提升检测精度. Yang等[18 ] 基于特征的距离提出最远点采样策略,用于点云采样和分组,直接在原始点云上进行检测. ...
3
... 点云是一组无序点的集合,具有排列不变性和旋转不变性,这些特性使得研究者难以用处理规则序列的方式去处理点云[12 ] . Qi等[13 ] 提出PointNet系列,利用排列不变性操作,如多层感知器和最大池化层,进行点云特征学习. PointNet系列在点云上的成功应用促使研究者提出各种架构从原始点云中检测目标. Shi等[14 ] 提出基于点的两阶段检测网络:第一阶段使用特征学习网络直接学习点云信息并生成3D候选框;第二阶段将候选框进行坐标变换以细化候选框的细节,实现高精度的目标检测结果. Qi等[15 ] 提出投票策略,利用学习得到的深度特征,将投票空间量化为具体的检测框候选. Shi等[16 ] 使用固定半径的最近邻图对原始点云进行编码,学习点云的局部和全局特征,通过在图上迭代传播,增强点云特征的表达能力. Yang等[17 ] 提出将稀疏点特征转换为稠密体素特征,提升特征的区分能力,从而提升检测精度. Yang等[18 ] 基于特征的距离提出最远点采样策略,用于点云采样和分组,直接在原始点云上进行检测. ...
... 表6 中,v 为推理速度,C 为计算量. 如表6 所示,相对于基线模型Voxel-RCNN[9 ] ,本文方法在提升检测性能0.79%的同时,增大了推理时间和计算量. 与基于点方法Point-RCNN[14 ] 相比,本文方法不仅使推理时间减少近56.21%,而且检测效果显著提升. 与点体素方法PV-RCNN[30 ] 相比,本文方法在推理时间和计算量方面均具有显著优势. 这得益于本文在体素方法的基础上,高效率编码多尺度体素特征和快速生成候选框,在细化阶段利用原始点云编码局部特征,避免了对全场景信息进行点特征提取,降低了时间和计算上的成本. ...
... Comparison of performance and efficiency of proposed method and other model
Tab.6 模型 v /(帧·s−1 )C /GBAP3D /% Voxel-RCNN[9 ] 0.041 22.78 85.29 PV-RCNN[30 ] 0.128 89.27 84.43 Point-RCNN[14 ] 0.153 27.71 78.63 本文方法 0.067 26.64 86.00
本文方法通过局部信息的重编码,在性能和效率方面取得了具有竞争力的效果. 局部信息的获取取决于RPN阶段生成的候选框质量. 由于RPN阶段采用普通卷积,相较于稀疏卷积,耗时较大. 普通卷积会对细化阶段的信息融合效果及整体的模型性能产生影响. 在接下来的工作中,将改进生成候选框的方式,利用稀疏卷积的高性能来提高候选框生成的速度. ...
1
... 点云是一组无序点的集合,具有排列不变性和旋转不变性,这些特性使得研究者难以用处理规则序列的方式去处理点云[12 ] . Qi等[13 ] 提出PointNet系列,利用排列不变性操作,如多层感知器和最大池化层,进行点云特征学习. PointNet系列在点云上的成功应用促使研究者提出各种架构从原始点云中检测目标. Shi等[14 ] 提出基于点的两阶段检测网络:第一阶段使用特征学习网络直接学习点云信息并生成3D候选框;第二阶段将候选框进行坐标变换以细化候选框的细节,实现高精度的目标检测结果. Qi等[15 ] 提出投票策略,利用学习得到的深度特征,将投票空间量化为具体的检测框候选. Shi等[16 ] 使用固定半径的最近邻图对原始点云进行编码,学习点云的局部和全局特征,通过在图上迭代传播,增强点云特征的表达能力. Yang等[17 ] 提出将稀疏点特征转换为稠密体素特征,提升特征的区分能力,从而提升检测精度. Yang等[18 ] 基于特征的距离提出最远点采样策略,用于点云采样和分组,直接在原始点云上进行检测. ...
2
... 点云是一组无序点的集合,具有排列不变性和旋转不变性,这些特性使得研究者难以用处理规则序列的方式去处理点云[12 ] . Qi等[13 ] 提出PointNet系列,利用排列不变性操作,如多层感知器和最大池化层,进行点云特征学习. PointNet系列在点云上的成功应用促使研究者提出各种架构从原始点云中检测目标. Shi等[14 ] 提出基于点的两阶段检测网络:第一阶段使用特征学习网络直接学习点云信息并生成3D候选框;第二阶段将候选框进行坐标变换以细化候选框的细节,实现高精度的目标检测结果. Qi等[15 ] 提出投票策略,利用学习得到的深度特征,将投票空间量化为具体的检测框候选. Shi等[16 ] 使用固定半径的最近邻图对原始点云进行编码,学习点云的局部和全局特征,通过在图上迭代传播,增强点云特征的表达能力. Yang等[17 ] 提出将稀疏点特征转换为稠密体素特征,提升特征的区分能力,从而提升检测精度. Yang等[18 ] 基于特征的距离提出最远点采样策略,用于点云采样和分组,直接在原始点云上进行检测. ...
... Comparison of detection result from different algorithm on KITTI test dataset
Tab.1 方法 模态 AP3D /% APBEV /% 简单 中等 困难 mAP 简单 中等 困难 mAP Point-GNN[16 ] L 88.33 79.47 72.29 80.03 93.11 89.17 83.90 88.73 3DSSD[18 ] L 88.36 79.57 74.55 80.83 92.66 89.02 85.86 89.18 PV-RCNN[30 ] L 90.25 81.43 76.82 82.83 94.98 90.65 86.14 90.60 Voxel-RCNN[9 ] L 90.90 81.62 77.06 83.19 94.85 88.83 86.13 89.94 CT3D[8 ] L 87.83 81.77 77.16 82.25 92.36 88.83 84.07 88.42 Pyramid-PV[28 ] L 88.39 82.08 77.49 82.65 92.19 88.84 86.21 89.08 VoTr[21 ] L 89.90 82.09 79.14 83.71 94.03 90.34 86.14 90.17 SPG[22 ] L 90.50 82.13 78.90 83.84 94.33 88.70 85.98 89.67 VoxSet[27 ] L 88.53 82.06 77.46 82.68 — — — — PDV[31 ] L 90.43 81.86 77.36 83.22 94.56 90.48 86.23 90.42 VFF[32 ] L+I 89.50 82.09 79.29 83.62 — — — — PG-RCNN[23 ] I 89.38 82.13 77.33 82.88 93.39 89.46 86.54 89.80 PVT-SSD[24 ] I 90.65 82.29 76.85 83.26 95.23 91.63 86.43 91.10 DVF-PV[25 ] L+I 90.99 82.40 77.37 83.58 — — — — 本文方法 L 91.60 82.53 77.83 83.99 95.59 91.37 86.72 91.23
在实验过程中,采用共同的划分方法将训练样本划分成训练集和验证集. 如表2 所示为本文方法在KITTI验证集上的结果,采用40个召回位置记录平均准确率. 利用本文方法取得了最先进的结果,相比于基线模型Voxel-RCNN[9 ] ,在简单、中等、困难的难度级别上分别将三维AP提高了0.89%、0.71%、0.71%,俯视图AP提高了1.14%、0.86%、0.76%. ...
1
... 点云是一组无序点的集合,具有排列不变性和旋转不变性,这些特性使得研究者难以用处理规则序列的方式去处理点云[12 ] . Qi等[13 ] 提出PointNet系列,利用排列不变性操作,如多层感知器和最大池化层,进行点云特征学习. PointNet系列在点云上的成功应用促使研究者提出各种架构从原始点云中检测目标. Shi等[14 ] 提出基于点的两阶段检测网络:第一阶段使用特征学习网络直接学习点云信息并生成3D候选框;第二阶段将候选框进行坐标变换以细化候选框的细节,实现高精度的目标检测结果. Qi等[15 ] 提出投票策略,利用学习得到的深度特征,将投票空间量化为具体的检测框候选. Shi等[16 ] 使用固定半径的最近邻图对原始点云进行编码,学习点云的局部和全局特征,通过在图上迭代传播,增强点云特征的表达能力. Yang等[17 ] 提出将稀疏点特征转换为稠密体素特征,提升特征的区分能力,从而提升检测精度. Yang等[18 ] 基于特征的距离提出最远点采样策略,用于点云采样和分组,直接在原始点云上进行检测. ...
3
... 点云是一组无序点的集合,具有排列不变性和旋转不变性,这些特性使得研究者难以用处理规则序列的方式去处理点云[12 ] . Qi等[13 ] 提出PointNet系列,利用排列不变性操作,如多层感知器和最大池化层,进行点云特征学习. PointNet系列在点云上的成功应用促使研究者提出各种架构从原始点云中检测目标. Shi等[14 ] 提出基于点的两阶段检测网络:第一阶段使用特征学习网络直接学习点云信息并生成3D候选框;第二阶段将候选框进行坐标变换以细化候选框的细节,实现高精度的目标检测结果. Qi等[15 ] 提出投票策略,利用学习得到的深度特征,将投票空间量化为具体的检测框候选. Shi等[16 ] 使用固定半径的最近邻图对原始点云进行编码,学习点云的局部和全局特征,通过在图上迭代传播,增强点云特征的表达能力. Yang等[17 ] 提出将稀疏点特征转换为稠密体素特征,提升特征的区分能力,从而提升检测精度. Yang等[18 ] 基于特征的距离提出最远点采样策略,用于点云采样和分组,直接在原始点云上进行检测. ...
... Transformer[26 ] 模型在二维图像识别和检测任务中展现出强大的特征表示能力. 这启发了一些研究尝试将注意力机制应用到点云理解任务中,利用其建模全局上下文依赖关系的优势来增强点云的特征表达能力. Yang等[18 ] 使用基于注意力机制的编码器-解码器结构对点云进行多尺度学习,捕获全局上下文信息,实现端到端的目标检测. Sheng等[8 ] 提出通道注意力模块,可以有效增强特征在通道层面的相关性,在候选框细化中使用该模块,提升特征表达能力. He等[27 ] 提出基于体素集合的自注意力骨干网络,该方法侧重于利用集合到集合的学习方式,捕捉局部点集与对应的体素集之间的关系,实现更准确的目标检测. Mao等[28 ] 基于金字塔结构的特征表示方法,通过在不同尺度上对输入点云进行特征提取,捕捉不同尺度的目标信息. 这种结构使得网络能够对目标的多个尺度进行建模,提高特征提取的鲁棒性. ...
... Comparison of detection result from different algorithm on KITTI test dataset
Tab.1 方法 模态 AP3D /% APBEV /% 简单 中等 困难 mAP 简单 中等 困难 mAP Point-GNN[16 ] L 88.33 79.47 72.29 80.03 93.11 89.17 83.90 88.73 3DSSD[18 ] L 88.36 79.57 74.55 80.83 92.66 89.02 85.86 89.18 PV-RCNN[30 ] L 90.25 81.43 76.82 82.83 94.98 90.65 86.14 90.60 Voxel-RCNN[9 ] L 90.90 81.62 77.06 83.19 94.85 88.83 86.13 89.94 CT3D[8 ] L 87.83 81.77 77.16 82.25 92.36 88.83 84.07 88.42 Pyramid-PV[28 ] L 88.39 82.08 77.49 82.65 92.19 88.84 86.21 89.08 VoTr[21 ] L 89.90 82.09 79.14 83.71 94.03 90.34 86.14 90.17 SPG[22 ] L 90.50 82.13 78.90 83.84 94.33 88.70 85.98 89.67 VoxSet[27 ] L 88.53 82.06 77.46 82.68 — — — — PDV[31 ] L 90.43 81.86 77.36 83.22 94.56 90.48 86.23 90.42 VFF[32 ] L+I 89.50 82.09 79.29 83.62 — — — — PG-RCNN[23 ] I 89.38 82.13 77.33 82.88 93.39 89.46 86.54 89.80 PVT-SSD[24 ] I 90.65 82.29 76.85 83.26 95.23 91.63 86.43 91.10 DVF-PV[25 ] L+I 90.99 82.40 77.37 83.58 — — — — 本文方法 L 91.60 82.53 77.83 83.99 95.59 91.37 86.72 91.23
在实验过程中,采用共同的划分方法将训练样本划分成训练集和验证集. 如表2 所示为本文方法在KITTI验证集上的结果,采用40个召回位置记录平均准确率. 利用本文方法取得了最先进的结果,相比于基线模型Voxel-RCNN[9 ] ,在简单、中等、困难的难度级别上分别将三维AP提高了0.89%、0.71%、0.71%,俯视图AP提高了1.14%、0.86%、0.76%. ...
1
... 基于体素的方法将点云进行规则化处理,这种规则的表示方便应用卷积神经网络对其进行特征提取. Zhou等[19 ] 提出点云到体素的编码层,设计稠密的三维卷积网络,在体素上直接学习特征,验证了利用体素的方法可以有效地解析点云并实现目标检测. 由于点云数据本身分布稀疏,在转换到体素表示后,会出现大量空的体素没有点信息. 三维稠密卷积操作会对所有的体素均进行卷积计算,包括未包含点云的体素,导致大量的无效计算和计算资源浪费. 之后的研究中,Yan等[20 ] 使用稀疏卷积代替密集卷积,可以跳过空体素的计算,有针对性和高效地提取和学习体素数据的特征. Deng等[9 ] 提出体素查询方法,在目标候选框内聚合相邻体素的特征到中心体素上,扩大了体素的感受野,取得了较好的效果. Mao等[21 ] 提出新的体素特征增强模块,通过残差学习来增强体素特征,将体素的坐标信息整合到主干网络,增强对局部结构的建模能力. Xu等[22 ] 提出语义点集生成模块,用于生成前景体素的语义点集,填补前景物体缺失的部分. Koo等[23 ] 引入感兴趣区域点生成模块,用于估计前景对象的完整形状和位移,为每个候选框创建语义曲面点云. Yang等[24 ] 通过从虚拟距离图像中获取参考点,引入点体素变换模块,自适应地将参考点周围的上下文信息和局部集合信息融合到内容查询中. Mahmoud等[25 ] 提出密集体素融合的方法,用于生成多尺度的密集体素特征,以提升对稀疏区域的特征表达能力. ...
Second: sparsely embedded convolutional detection
3
2018
... 基于体素的方法将点云进行规则化处理,这种规则的表示方便应用卷积神经网络对其进行特征提取. Zhou等[19 ] 提出点云到体素的编码层,设计稠密的三维卷积网络,在体素上直接学习特征,验证了利用体素的方法可以有效地解析点云并实现目标检测. 由于点云数据本身分布稀疏,在转换到体素表示后,会出现大量空的体素没有点信息. 三维稠密卷积操作会对所有的体素均进行卷积计算,包括未包含点云的体素,导致大量的无效计算和计算资源浪费. 之后的研究中,Yan等[20 ] 使用稀疏卷积代替密集卷积,可以跳过空体素的计算,有针对性和高效地提取和学习体素数据的特征. Deng等[9 ] 提出体素查询方法,在目标候选框内聚合相邻体素的特征到中心体素上,扩大了体素的感受野,取得了较好的效果. Mao等[21 ] 提出新的体素特征增强模块,通过残差学习来增强体素特征,将体素的坐标信息整合到主干网络,增强对局部结构的建模能力. Xu等[22 ] 提出语义点集生成模块,用于生成前景体素的语义点集,填补前景物体缺失的部分. Koo等[23 ] 引入感兴趣区域点生成模块,用于估计前景对象的完整形状和位移,为每个候选框创建语义曲面点云. Yang等[24 ] 通过从虚拟距离图像中获取参考点,引入点体素变换模块,自适应地将参考点周围的上下文信息和局部集合信息融合到内容查询中. Mahmoud等[25 ] 提出密集体素融合的方法,用于生成多尺度的密集体素特征,以提升对稀疏区域的特征表达能力. ...
... 如表3 所示为本文方法与先进方法的性能比较. 参与对比的模型有SECOND[20 ] 、PV-RCNN[30 ] 和Voxel-RCNN[9 ] ,所有模型都基于PyTorch实现,本文使用训练集的1/10进行训练,使用验证集的1/10进行测试. 与基线模型Voxel-RCNN[9 ] 相比,本文模型在等级1上的AP提升了1.02%,在等级2上提升了1.09%. 本文方法在所有期望的距离范围上都获得了良好的结果,其中在50 m以上的长距离范围内获得了最大的性能提升,在等级1和等级2上的AP分别提升了2.03%和1.72%. 从表3 可以看出,本文方法在2个难度级别上取得了较高的APH性能,验证了本文在捕获目标细节和空间关系方面具有优势,能够有效地处理各种目标难度. ...
... Comparison of detection results from different algorithms on Waymo validation dataset
Tab.3 方法 AP/APH (LEVEL_1) AP/APH (LEVEL_2) d = 0~30 md = 30~50 md > 50 m均值 d = 0~30 md = 30~50 md > 50 m均值 SECOND[20 ] 88.66/88.18 67.35/66.70 42.89/42.09 70.07/69.52 87.33/86.86 60.92/60.23 32.39/31.77 61.63/61.14 PV-RCNN[30 ] 91.30/90.56 73.00/72.31 51.35/50.34 74.70/74.09 89.75/89.29 66.32/65.68 39.27/38.46 66.05/65.50 Voxel-RCNN[9 ] 90.81/90.36 72.43/71.78 50.37/49.47 73.90/73.32 89.50/89.05 65.68/65.08 38.32/37.61 65.10/64.58 本文方法 91.20 /90.77 73.28 /72.68 52.40 /51.45 74.92 /74.38 89.91 /89.48 66.58 /66.02 40.04 /39.29 66.19 /65.69
4.4. KITTI数据集上的消融实验结果展示与分析 为了分析本文所提出LIE模块和CAF模块的有效性,对2个模块进行消融实验. 可知,LIE模块可以分为2个部分:局部空间位置编码(local position encoding, LPE)和自注意力信息捕获(self-attention information capture, SIC). 如表4 所示,对整体架构进行全面的消融实验,验证每个组件的有效性. ...
2
... 基于体素的方法将点云进行规则化处理,这种规则的表示方便应用卷积神经网络对其进行特征提取. Zhou等[19 ] 提出点云到体素的编码层,设计稠密的三维卷积网络,在体素上直接学习特征,验证了利用体素的方法可以有效地解析点云并实现目标检测. 由于点云数据本身分布稀疏,在转换到体素表示后,会出现大量空的体素没有点信息. 三维稠密卷积操作会对所有的体素均进行卷积计算,包括未包含点云的体素,导致大量的无效计算和计算资源浪费. 之后的研究中,Yan等[20 ] 使用稀疏卷积代替密集卷积,可以跳过空体素的计算,有针对性和高效地提取和学习体素数据的特征. Deng等[9 ] 提出体素查询方法,在目标候选框内聚合相邻体素的特征到中心体素上,扩大了体素的感受野,取得了较好的效果. Mao等[21 ] 提出新的体素特征增强模块,通过残差学习来增强体素特征,将体素的坐标信息整合到主干网络,增强对局部结构的建模能力. Xu等[22 ] 提出语义点集生成模块,用于生成前景体素的语义点集,填补前景物体缺失的部分. Koo等[23 ] 引入感兴趣区域点生成模块,用于估计前景对象的完整形状和位移,为每个候选框创建语义曲面点云. Yang等[24 ] 通过从虚拟距离图像中获取参考点,引入点体素变换模块,自适应地将参考点周围的上下文信息和局部集合信息融合到内容查询中. Mahmoud等[25 ] 提出密集体素融合的方法,用于生成多尺度的密集体素特征,以提升对稀疏区域的特征表达能力. ...
... Comparison of detection result from different algorithm on KITTI test dataset
Tab.1 方法 模态 AP3D /% APBEV /% 简单 中等 困难 mAP 简单 中等 困难 mAP Point-GNN[16 ] L 88.33 79.47 72.29 80.03 93.11 89.17 83.90 88.73 3DSSD[18 ] L 88.36 79.57 74.55 80.83 92.66 89.02 85.86 89.18 PV-RCNN[30 ] L 90.25 81.43 76.82 82.83 94.98 90.65 86.14 90.60 Voxel-RCNN[9 ] L 90.90 81.62 77.06 83.19 94.85 88.83 86.13 89.94 CT3D[8 ] L 87.83 81.77 77.16 82.25 92.36 88.83 84.07 88.42 Pyramid-PV[28 ] L 88.39 82.08 77.49 82.65 92.19 88.84 86.21 89.08 VoTr[21 ] L 89.90 82.09 79.14 83.71 94.03 90.34 86.14 90.17 SPG[22 ] L 90.50 82.13 78.90 83.84 94.33 88.70 85.98 89.67 VoxSet[27 ] L 88.53 82.06 77.46 82.68 — — — — PDV[31 ] L 90.43 81.86 77.36 83.22 94.56 90.48 86.23 90.42 VFF[32 ] L+I 89.50 82.09 79.29 83.62 — — — — PG-RCNN[23 ] I 89.38 82.13 77.33 82.88 93.39 89.46 86.54 89.80 PVT-SSD[24 ] I 90.65 82.29 76.85 83.26 95.23 91.63 86.43 91.10 DVF-PV[25 ] L+I 90.99 82.40 77.37 83.58 — — — — 本文方法 L 91.60 82.53 77.83 83.99 95.59 91.37 86.72 91.23
在实验过程中,采用共同的划分方法将训练样本划分成训练集和验证集. 如表2 所示为本文方法在KITTI验证集上的结果,采用40个召回位置记录平均准确率. 利用本文方法取得了最先进的结果,相比于基线模型Voxel-RCNN[9 ] ,在简单、中等、困难的难度级别上分别将三维AP提高了0.89%、0.71%、0.71%,俯视图AP提高了1.14%、0.86%、0.76%. ...
2
... 基于体素的方法将点云进行规则化处理,这种规则的表示方便应用卷积神经网络对其进行特征提取. Zhou等[19 ] 提出点云到体素的编码层,设计稠密的三维卷积网络,在体素上直接学习特征,验证了利用体素的方法可以有效地解析点云并实现目标检测. 由于点云数据本身分布稀疏,在转换到体素表示后,会出现大量空的体素没有点信息. 三维稠密卷积操作会对所有的体素均进行卷积计算,包括未包含点云的体素,导致大量的无效计算和计算资源浪费. 之后的研究中,Yan等[20 ] 使用稀疏卷积代替密集卷积,可以跳过空体素的计算,有针对性和高效地提取和学习体素数据的特征. Deng等[9 ] 提出体素查询方法,在目标候选框内聚合相邻体素的特征到中心体素上,扩大了体素的感受野,取得了较好的效果. Mao等[21 ] 提出新的体素特征增强模块,通过残差学习来增强体素特征,将体素的坐标信息整合到主干网络,增强对局部结构的建模能力. Xu等[22 ] 提出语义点集生成模块,用于生成前景体素的语义点集,填补前景物体缺失的部分. Koo等[23 ] 引入感兴趣区域点生成模块,用于估计前景对象的完整形状和位移,为每个候选框创建语义曲面点云. Yang等[24 ] 通过从虚拟距离图像中获取参考点,引入点体素变换模块,自适应地将参考点周围的上下文信息和局部集合信息融合到内容查询中. Mahmoud等[25 ] 提出密集体素融合的方法,用于生成多尺度的密集体素特征,以提升对稀疏区域的特征表达能力. ...
... Comparison of detection result from different algorithm on KITTI test dataset
Tab.1 方法 模态 AP3D /% APBEV /% 简单 中等 困难 mAP 简单 中等 困难 mAP Point-GNN[16 ] L 88.33 79.47 72.29 80.03 93.11 89.17 83.90 88.73 3DSSD[18 ] L 88.36 79.57 74.55 80.83 92.66 89.02 85.86 89.18 PV-RCNN[30 ] L 90.25 81.43 76.82 82.83 94.98 90.65 86.14 90.60 Voxel-RCNN[9 ] L 90.90 81.62 77.06 83.19 94.85 88.83 86.13 89.94 CT3D[8 ] L 87.83 81.77 77.16 82.25 92.36 88.83 84.07 88.42 Pyramid-PV[28 ] L 88.39 82.08 77.49 82.65 92.19 88.84 86.21 89.08 VoTr[21 ] L 89.90 82.09 79.14 83.71 94.03 90.34 86.14 90.17 SPG[22 ] L 90.50 82.13 78.90 83.84 94.33 88.70 85.98 89.67 VoxSet[27 ] L 88.53 82.06 77.46 82.68 — — — — PDV[31 ] L 90.43 81.86 77.36 83.22 94.56 90.48 86.23 90.42 VFF[32 ] L+I 89.50 82.09 79.29 83.62 — — — — PG-RCNN[23 ] I 89.38 82.13 77.33 82.88 93.39 89.46 86.54 89.80 PVT-SSD[24 ] I 90.65 82.29 76.85 83.26 95.23 91.63 86.43 91.10 DVF-PV[25 ] L+I 90.99 82.40 77.37 83.58 — — — — 本文方法 L 91.60 82.53 77.83 83.99 95.59 91.37 86.72 91.23
在实验过程中,采用共同的划分方法将训练样本划分成训练集和验证集. 如表2 所示为本文方法在KITTI验证集上的结果,采用40个召回位置记录平均准确率. 利用本文方法取得了最先进的结果,相比于基线模型Voxel-RCNN[9 ] ,在简单、中等、困难的难度级别上分别将三维AP提高了0.89%、0.71%、0.71%,俯视图AP提高了1.14%、0.86%、0.76%. ...
2
... 基于体素的方法将点云进行规则化处理,这种规则的表示方便应用卷积神经网络对其进行特征提取. Zhou等[19 ] 提出点云到体素的编码层,设计稠密的三维卷积网络,在体素上直接学习特征,验证了利用体素的方法可以有效地解析点云并实现目标检测. 由于点云数据本身分布稀疏,在转换到体素表示后,会出现大量空的体素没有点信息. 三维稠密卷积操作会对所有的体素均进行卷积计算,包括未包含点云的体素,导致大量的无效计算和计算资源浪费. 之后的研究中,Yan等[20 ] 使用稀疏卷积代替密集卷积,可以跳过空体素的计算,有针对性和高效地提取和学习体素数据的特征. Deng等[9 ] 提出体素查询方法,在目标候选框内聚合相邻体素的特征到中心体素上,扩大了体素的感受野,取得了较好的效果. Mao等[21 ] 提出新的体素特征增强模块,通过残差学习来增强体素特征,将体素的坐标信息整合到主干网络,增强对局部结构的建模能力. Xu等[22 ] 提出语义点集生成模块,用于生成前景体素的语义点集,填补前景物体缺失的部分. Koo等[23 ] 引入感兴趣区域点生成模块,用于估计前景对象的完整形状和位移,为每个候选框创建语义曲面点云. Yang等[24 ] 通过从虚拟距离图像中获取参考点,引入点体素变换模块,自适应地将参考点周围的上下文信息和局部集合信息融合到内容查询中. Mahmoud等[25 ] 提出密集体素融合的方法,用于生成多尺度的密集体素特征,以提升对稀疏区域的特征表达能力. ...
... Comparison of detection result from different algorithm on KITTI test dataset
Tab.1 方法 模态 AP3D /% APBEV /% 简单 中等 困难 mAP 简单 中等 困难 mAP Point-GNN[16 ] L 88.33 79.47 72.29 80.03 93.11 89.17 83.90 88.73 3DSSD[18 ] L 88.36 79.57 74.55 80.83 92.66 89.02 85.86 89.18 PV-RCNN[30 ] L 90.25 81.43 76.82 82.83 94.98 90.65 86.14 90.60 Voxel-RCNN[9 ] L 90.90 81.62 77.06 83.19 94.85 88.83 86.13 89.94 CT3D[8 ] L 87.83 81.77 77.16 82.25 92.36 88.83 84.07 88.42 Pyramid-PV[28 ] L 88.39 82.08 77.49 82.65 92.19 88.84 86.21 89.08 VoTr[21 ] L 89.90 82.09 79.14 83.71 94.03 90.34 86.14 90.17 SPG[22 ] L 90.50 82.13 78.90 83.84 94.33 88.70 85.98 89.67 VoxSet[27 ] L 88.53 82.06 77.46 82.68 — — — — PDV[31 ] L 90.43 81.86 77.36 83.22 94.56 90.48 86.23 90.42 VFF[32 ] L+I 89.50 82.09 79.29 83.62 — — — — PG-RCNN[23 ] I 89.38 82.13 77.33 82.88 93.39 89.46 86.54 89.80 PVT-SSD[24 ] I 90.65 82.29 76.85 83.26 95.23 91.63 86.43 91.10 DVF-PV[25 ] L+I 90.99 82.40 77.37 83.58 — — — — 本文方法 L 91.60 82.53 77.83 83.99 95.59 91.37 86.72 91.23
在实验过程中,采用共同的划分方法将训练样本划分成训练集和验证集. 如表2 所示为本文方法在KITTI验证集上的结果,采用40个召回位置记录平均准确率. 利用本文方法取得了最先进的结果,相比于基线模型Voxel-RCNN[9 ] ,在简单、中等、困难的难度级别上分别将三维AP提高了0.89%、0.71%、0.71%,俯视图AP提高了1.14%、0.86%、0.76%. ...
2
... 基于体素的方法将点云进行规则化处理,这种规则的表示方便应用卷积神经网络对其进行特征提取. Zhou等[19 ] 提出点云到体素的编码层,设计稠密的三维卷积网络,在体素上直接学习特征,验证了利用体素的方法可以有效地解析点云并实现目标检测. 由于点云数据本身分布稀疏,在转换到体素表示后,会出现大量空的体素没有点信息. 三维稠密卷积操作会对所有的体素均进行卷积计算,包括未包含点云的体素,导致大量的无效计算和计算资源浪费. 之后的研究中,Yan等[20 ] 使用稀疏卷积代替密集卷积,可以跳过空体素的计算,有针对性和高效地提取和学习体素数据的特征. Deng等[9 ] 提出体素查询方法,在目标候选框内聚合相邻体素的特征到中心体素上,扩大了体素的感受野,取得了较好的效果. Mao等[21 ] 提出新的体素特征增强模块,通过残差学习来增强体素特征,将体素的坐标信息整合到主干网络,增强对局部结构的建模能力. Xu等[22 ] 提出语义点集生成模块,用于生成前景体素的语义点集,填补前景物体缺失的部分. Koo等[23 ] 引入感兴趣区域点生成模块,用于估计前景对象的完整形状和位移,为每个候选框创建语义曲面点云. Yang等[24 ] 通过从虚拟距离图像中获取参考点,引入点体素变换模块,自适应地将参考点周围的上下文信息和局部集合信息融合到内容查询中. Mahmoud等[25 ] 提出密集体素融合的方法,用于生成多尺度的密集体素特征,以提升对稀疏区域的特征表达能力. ...
... Comparison of detection result from different algorithm on KITTI test dataset
Tab.1 方法 模态 AP3D /% APBEV /% 简单 中等 困难 mAP 简单 中等 困难 mAP Point-GNN[16 ] L 88.33 79.47 72.29 80.03 93.11 89.17 83.90 88.73 3DSSD[18 ] L 88.36 79.57 74.55 80.83 92.66 89.02 85.86 89.18 PV-RCNN[30 ] L 90.25 81.43 76.82 82.83 94.98 90.65 86.14 90.60 Voxel-RCNN[9 ] L 90.90 81.62 77.06 83.19 94.85 88.83 86.13 89.94 CT3D[8 ] L 87.83 81.77 77.16 82.25 92.36 88.83 84.07 88.42 Pyramid-PV[28 ] L 88.39 82.08 77.49 82.65 92.19 88.84 86.21 89.08 VoTr[21 ] L 89.90 82.09 79.14 83.71 94.03 90.34 86.14 90.17 SPG[22 ] L 90.50 82.13 78.90 83.84 94.33 88.70 85.98 89.67 VoxSet[27 ] L 88.53 82.06 77.46 82.68 — — — — PDV[31 ] L 90.43 81.86 77.36 83.22 94.56 90.48 86.23 90.42 VFF[32 ] L+I 89.50 82.09 79.29 83.62 — — — — PG-RCNN[23 ] I 89.38 82.13 77.33 82.88 93.39 89.46 86.54 89.80 PVT-SSD[24 ] I 90.65 82.29 76.85 83.26 95.23 91.63 86.43 91.10 DVF-PV[25 ] L+I 90.99 82.40 77.37 83.58 — — — — 本文方法 L 91.60 82.53 77.83 83.99 95.59 91.37 86.72 91.23
在实验过程中,采用共同的划分方法将训练样本划分成训练集和验证集. 如表2 所示为本文方法在KITTI验证集上的结果,采用40个召回位置记录平均准确率. 利用本文方法取得了最先进的结果,相比于基线模型Voxel-RCNN[9 ] ,在简单、中等、困难的难度级别上分别将三维AP提高了0.89%、0.71%、0.71%,俯视图AP提高了1.14%、0.86%、0.76%. ...
2
... 基于体素的方法将点云进行规则化处理,这种规则的表示方便应用卷积神经网络对其进行特征提取. Zhou等[19 ] 提出点云到体素的编码层,设计稠密的三维卷积网络,在体素上直接学习特征,验证了利用体素的方法可以有效地解析点云并实现目标检测. 由于点云数据本身分布稀疏,在转换到体素表示后,会出现大量空的体素没有点信息. 三维稠密卷积操作会对所有的体素均进行卷积计算,包括未包含点云的体素,导致大量的无效计算和计算资源浪费. 之后的研究中,Yan等[20 ] 使用稀疏卷积代替密集卷积,可以跳过空体素的计算,有针对性和高效地提取和学习体素数据的特征. Deng等[9 ] 提出体素查询方法,在目标候选框内聚合相邻体素的特征到中心体素上,扩大了体素的感受野,取得了较好的效果. Mao等[21 ] 提出新的体素特征增强模块,通过残差学习来增强体素特征,将体素的坐标信息整合到主干网络,增强对局部结构的建模能力. Xu等[22 ] 提出语义点集生成模块,用于生成前景体素的语义点集,填补前景物体缺失的部分. Koo等[23 ] 引入感兴趣区域点生成模块,用于估计前景对象的完整形状和位移,为每个候选框创建语义曲面点云. Yang等[24 ] 通过从虚拟距离图像中获取参考点,引入点体素变换模块,自适应地将参考点周围的上下文信息和局部集合信息融合到内容查询中. Mahmoud等[25 ] 提出密集体素融合的方法,用于生成多尺度的密集体素特征,以提升对稀疏区域的特征表达能力. ...
... Comparison of detection result from different algorithm on KITTI test dataset
Tab.1 方法 模态 AP3D /% APBEV /% 简单 中等 困难 mAP 简单 中等 困难 mAP Point-GNN[16 ] L 88.33 79.47 72.29 80.03 93.11 89.17 83.90 88.73 3DSSD[18 ] L 88.36 79.57 74.55 80.83 92.66 89.02 85.86 89.18 PV-RCNN[30 ] L 90.25 81.43 76.82 82.83 94.98 90.65 86.14 90.60 Voxel-RCNN[9 ] L 90.90 81.62 77.06 83.19 94.85 88.83 86.13 89.94 CT3D[8 ] L 87.83 81.77 77.16 82.25 92.36 88.83 84.07 88.42 Pyramid-PV[28 ] L 88.39 82.08 77.49 82.65 92.19 88.84 86.21 89.08 VoTr[21 ] L 89.90 82.09 79.14 83.71 94.03 90.34 86.14 90.17 SPG[22 ] L 90.50 82.13 78.90 83.84 94.33 88.70 85.98 89.67 VoxSet[27 ] L 88.53 82.06 77.46 82.68 — — — — PDV[31 ] L 90.43 81.86 77.36 83.22 94.56 90.48 86.23 90.42 VFF[32 ] L+I 89.50 82.09 79.29 83.62 — — — — PG-RCNN[23 ] I 89.38 82.13 77.33 82.88 93.39 89.46 86.54 89.80 PVT-SSD[24 ] I 90.65 82.29 76.85 83.26 95.23 91.63 86.43 91.10 DVF-PV[25 ] L+I 90.99 82.40 77.37 83.58 — — — — 本文方法 L 91.60 82.53 77.83 83.99 95.59 91.37 86.72 91.23
在实验过程中,采用共同的划分方法将训练样本划分成训练集和验证集. 如表2 所示为本文方法在KITTI验证集上的结果,采用40个召回位置记录平均准确率. 利用本文方法取得了最先进的结果,相比于基线模型Voxel-RCNN[9 ] ,在简单、中等、困难的难度级别上分别将三维AP提高了0.89%、0.71%、0.71%,俯视图AP提高了1.14%、0.86%、0.76%. ...
Attention is all you need
4
2017
... Transformer[26 ] 模型在二维图像识别和检测任务中展现出强大的特征表示能力. 这启发了一些研究尝试将注意力机制应用到点云理解任务中,利用其建模全局上下文依赖关系的优势来增强点云的特征表达能力. Yang等[18 ] 使用基于注意力机制的编码器-解码器结构对点云进行多尺度学习,捕获全局上下文信息,实现端到端的目标检测. Sheng等[8 ] 提出通道注意力模块,可以有效增强特征在通道层面的相关性,在候选框细化中使用该模块,提升特征表达能力. He等[27 ] 提出基于体素集合的自注意力骨干网络,该方法侧重于利用集合到集合的学习方式,捕捉局部点集与对应的体素集之间的关系,实现更准确的目标检测. Mao等[28 ] 基于金字塔结构的特征表示方法,通过在不同尺度上对输入点云进行特征提取,捕捉不同尺度的目标信息. 这种结构使得网络能够对目标的多个尺度进行建模,提高特征提取的鲁棒性. ...
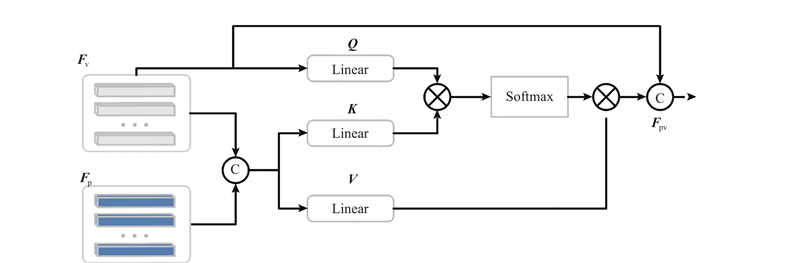
... 这些方法应用注意力机制来自适应地学习稀疏点特征,但忽略了原始点所携带的目标精确细节信息. 本文提出使用基于多头注意力机制[26 ] 提出CAF模块,旨在有效地将原始点云中丰富的细节信息融合到全局体素特征中. 该融合模块的设计使得网络能够同时关注局部细节和整体特征的不同方面,从而更全面地捕捉目标的特征信息. ...
... 关注${{\boldsymbol{F}}_{\mathrm{p}}}$ ${{\boldsymbol{F}}_{\mathrm{v}}}$ [26 ] ,实现特征之间的有效交互学习. 如图3 所示,将${{\boldsymbol{F}}_{\mathrm{p}}}$ ${{\boldsymbol{F}}_{\mathrm{v}}}$ ${{\boldsymbol{F}}_{\mathrm{B}}} = [{{\boldsymbol{F}}_{\mathrm{p}}},{{\boldsymbol{F}}_{\mathrm{v}}}]$
... $ {{\boldsymbol{F}}_{\mathrm{v}}} $ ${{\boldsymbol{F}}_{\mathrm{B}}}$ $ {{\boldsymbol{F}}_{\mathrm{v}}} $ [26 ] 获得有效的融合特征: ...
2
... Transformer[26 ] 模型在二维图像识别和检测任务中展现出强大的特征表示能力. 这启发了一些研究尝试将注意力机制应用到点云理解任务中,利用其建模全局上下文依赖关系的优势来增强点云的特征表达能力. Yang等[18 ] 使用基于注意力机制的编码器-解码器结构对点云进行多尺度学习,捕获全局上下文信息,实现端到端的目标检测. Sheng等[8 ] 提出通道注意力模块,可以有效增强特征在通道层面的相关性,在候选框细化中使用该模块,提升特征表达能力. He等[27 ] 提出基于体素集合的自注意力骨干网络,该方法侧重于利用集合到集合的学习方式,捕捉局部点集与对应的体素集之间的关系,实现更准确的目标检测. Mao等[28 ] 基于金字塔结构的特征表示方法,通过在不同尺度上对输入点云进行特征提取,捕捉不同尺度的目标信息. 这种结构使得网络能够对目标的多个尺度进行建模,提高特征提取的鲁棒性. ...
... Comparison of detection result from different algorithm on KITTI test dataset
Tab.1 方法 模态 AP3D /% APBEV /% 简单 中等 困难 mAP 简单 中等 困难 mAP Point-GNN[16 ] L 88.33 79.47 72.29 80.03 93.11 89.17 83.90 88.73 3DSSD[18 ] L 88.36 79.57 74.55 80.83 92.66 89.02 85.86 89.18 PV-RCNN[30 ] L 90.25 81.43 76.82 82.83 94.98 90.65 86.14 90.60 Voxel-RCNN[9 ] L 90.90 81.62 77.06 83.19 94.85 88.83 86.13 89.94 CT3D[8 ] L 87.83 81.77 77.16 82.25 92.36 88.83 84.07 88.42 Pyramid-PV[28 ] L 88.39 82.08 77.49 82.65 92.19 88.84 86.21 89.08 VoTr[21 ] L 89.90 82.09 79.14 83.71 94.03 90.34 86.14 90.17 SPG[22 ] L 90.50 82.13 78.90 83.84 94.33 88.70 85.98 89.67 VoxSet[27 ] L 88.53 82.06 77.46 82.68 — — — — PDV[31 ] L 90.43 81.86 77.36 83.22 94.56 90.48 86.23 90.42 VFF[32 ] L+I 89.50 82.09 79.29 83.62 — — — — PG-RCNN[23 ] I 89.38 82.13 77.33 82.88 93.39 89.46 86.54 89.80 PVT-SSD[24 ] I 90.65 82.29 76.85 83.26 95.23 91.63 86.43 91.10 DVF-PV[25 ] L+I 90.99 82.40 77.37 83.58 — — — — 本文方法 L 91.60 82.53 77.83 83.99 95.59 91.37 86.72 91.23
在实验过程中,采用共同的划分方法将训练样本划分成训练集和验证集. 如表2 所示为本文方法在KITTI验证集上的结果,采用40个召回位置记录平均准确率. 利用本文方法取得了最先进的结果,相比于基线模型Voxel-RCNN[9 ] ,在简单、中等、困难的难度级别上分别将三维AP提高了0.89%、0.71%、0.71%,俯视图AP提高了1.14%、0.86%、0.76%. ...
2
... Transformer[26 ] 模型在二维图像识别和检测任务中展现出强大的特征表示能力. 这启发了一些研究尝试将注意力机制应用到点云理解任务中,利用其建模全局上下文依赖关系的优势来增强点云的特征表达能力. Yang等[18 ] 使用基于注意力机制的编码器-解码器结构对点云进行多尺度学习,捕获全局上下文信息,实现端到端的目标检测. Sheng等[8 ] 提出通道注意力模块,可以有效增强特征在通道层面的相关性,在候选框细化中使用该模块,提升特征表达能力. He等[27 ] 提出基于体素集合的自注意力骨干网络,该方法侧重于利用集合到集合的学习方式,捕捉局部点集与对应的体素集之间的关系,实现更准确的目标检测. Mao等[28 ] 基于金字塔结构的特征表示方法,通过在不同尺度上对输入点云进行特征提取,捕捉不同尺度的目标信息. 这种结构使得网络能够对目标的多个尺度进行建模,提高特征提取的鲁棒性. ...
... Comparison of detection result from different algorithm on KITTI test dataset
Tab.1 方法 模态 AP3D /% APBEV /% 简单 中等 困难 mAP 简单 中等 困难 mAP Point-GNN[16 ] L 88.33 79.47 72.29 80.03 93.11 89.17 83.90 88.73 3DSSD[18 ] L 88.36 79.57 74.55 80.83 92.66 89.02 85.86 89.18 PV-RCNN[30 ] L 90.25 81.43 76.82 82.83 94.98 90.65 86.14 90.60 Voxel-RCNN[9 ] L 90.90 81.62 77.06 83.19 94.85 88.83 86.13 89.94 CT3D[8 ] L 87.83 81.77 77.16 82.25 92.36 88.83 84.07 88.42 Pyramid-PV[28 ] L 88.39 82.08 77.49 82.65 92.19 88.84 86.21 89.08 VoTr[21 ] L 89.90 82.09 79.14 83.71 94.03 90.34 86.14 90.17 SPG[22 ] L 90.50 82.13 78.90 83.84 94.33 88.70 85.98 89.67 VoxSet[27 ] L 88.53 82.06 77.46 82.68 — — — — PDV[31 ] L 90.43 81.86 77.36 83.22 94.56 90.48 86.23 90.42 VFF[32 ] L+I 89.50 82.09 79.29 83.62 — — — — PG-RCNN[23 ] I 89.38 82.13 77.33 82.88 93.39 89.46 86.54 89.80 PVT-SSD[24 ] I 90.65 82.29 76.85 83.26 95.23 91.63 86.43 91.10 DVF-PV[25 ] L+I 90.99 82.40 77.37 83.58 — — — — 本文方法 L 91.60 82.53 77.83 83.99 95.59 91.37 86.72 91.23
在实验过程中,采用共同的划分方法将训练样本划分成训练集和验证集. 如表2 所示为本文方法在KITTI验证集上的结果,采用40个召回位置记录平均准确率. 利用本文方法取得了最先进的结果,相比于基线模型Voxel-RCNN[9 ] ,在简单、中等、困难的难度级别上分别将三维AP提高了0.89%、0.71%、0.71%,俯视图AP提高了1.14%、0.86%、0.76%. ...
1
... 在作为输入之前,原始点云被划分成规则的体素. 对于KITTI数据集,将点云的范围裁剪为X 轴[0, 70.4] m,Y 轴[−40, 40] m,Z 轴[−3, 1] m. 输入体素大小设置为(0.05, 0.05, 0.01) m. 对于Waymo公开数据集,点云的范围被裁剪为X 轴和Y 轴[−75.2, 75.2] m,Z 轴[−2, 4] m. 输入体素大小设置为(0.1, 0.1, 0.15) m. 提出方法的检测头模块遵循Pointformer[29 ] 中前馈神经网络的大小,进行最终的目标框回归和置信度预测. ...
6
... Comparison of detection result from different algorithm on KITTI test dataset
Tab.1 方法 模态 AP3D /% APBEV /% 简单 中等 困难 mAP 简单 中等 困难 mAP Point-GNN[16 ] L 88.33 79.47 72.29 80.03 93.11 89.17 83.90 88.73 3DSSD[18 ] L 88.36 79.57 74.55 80.83 92.66 89.02 85.86 89.18 PV-RCNN[30 ] L 90.25 81.43 76.82 82.83 94.98 90.65 86.14 90.60 Voxel-RCNN[9 ] L 90.90 81.62 77.06 83.19 94.85 88.83 86.13 89.94 CT3D[8 ] L 87.83 81.77 77.16 82.25 92.36 88.83 84.07 88.42 Pyramid-PV[28 ] L 88.39 82.08 77.49 82.65 92.19 88.84 86.21 89.08 VoTr[21 ] L 89.90 82.09 79.14 83.71 94.03 90.34 86.14 90.17 SPG[22 ] L 90.50 82.13 78.90 83.84 94.33 88.70 85.98 89.67 VoxSet[27 ] L 88.53 82.06 77.46 82.68 — — — — PDV[31 ] L 90.43 81.86 77.36 83.22 94.56 90.48 86.23 90.42 VFF[32 ] L+I 89.50 82.09 79.29 83.62 — — — — PG-RCNN[23 ] I 89.38 82.13 77.33 82.88 93.39 89.46 86.54 89.80 PVT-SSD[24 ] I 90.65 82.29 76.85 83.26 95.23 91.63 86.43 91.10 DVF-PV[25 ] L+I 90.99 82.40 77.37 83.58 — — — — 本文方法 L 91.60 82.53 77.83 83.99 95.59 91.37 86.72 91.23
在实验过程中,采用共同的划分方法将训练样本划分成训练集和验证集. 如表2 所示为本文方法在KITTI验证集上的结果,采用40个召回位置记录平均准确率. 利用本文方法取得了最先进的结果,相比于基线模型Voxel-RCNN[9 ] ,在简单、中等、困难的难度级别上分别将三维AP提高了0.89%、0.71%、0.71%,俯视图AP提高了1.14%、0.86%、0.76%. ...
... Comparison of detection result from different algorithm on KITTI validation dataset
Tab.2 方法 AP3D /% APBEV /% 简单 中等 困难 简单 中等 困难 PV-RCNN[30 ] 92.57 84.43 82.69 95.76 91.11 88.93 Voxel-RCNN[9 ] 92.38 85.29 82.86 95.52 91.25 88.99 PDV[31 ] 92.56 85.29 83.05 — — — VFF[32 ] 92.47 85.65 83.38 95.62 91.75 91.39 CT3D[8 ] 92.85 85.82 83.46 96.14 91.88 89.63 本文方法 93.27 86.00 83.57 96.66 92.11 89.75
4.3. Waymo数据集上不同算法的检测结果对比 如表3 所示为本文方法与先进方法的性能比较. 参与对比的模型有SECOND[20 ] 、PV-RCNN[30 ] 和Voxel-RCNN[9 ] ,所有模型都基于PyTorch实现,本文使用训练集的1/10进行训练,使用验证集的1/10进行测试. 与基线模型Voxel-RCNN[9 ] 相比,本文模型在等级1上的AP提升了1.02%,在等级2上提升了1.09%. 本文方法在所有期望的距离范围上都获得了良好的结果,其中在50 m以上的长距离范围内获得了最大的性能提升,在等级1和等级2上的AP分别提升了2.03%和1.72%. 从表3 可以看出,本文方法在2个难度级别上取得了较高的APH性能,验证了本文在捕获目标细节和空间关系方面具有优势,能够有效地处理各种目标难度. ...
... 如表3 所示为本文方法与先进方法的性能比较. 参与对比的模型有SECOND[20 ] 、PV-RCNN[30 ] 和Voxel-RCNN[9 ] ,所有模型都基于PyTorch实现,本文使用训练集的1/10进行训练,使用验证集的1/10进行测试. 与基线模型Voxel-RCNN[9 ] 相比,本文模型在等级1上的AP提升了1.02%,在等级2上提升了1.09%. 本文方法在所有期望的距离范围上都获得了良好的结果,其中在50 m以上的长距离范围内获得了最大的性能提升,在等级1和等级2上的AP分别提升了2.03%和1.72%. 从表3 可以看出,本文方法在2个难度级别上取得了较高的APH性能,验证了本文在捕获目标细节和空间关系方面具有优势,能够有效地处理各种目标难度. ...
... Comparison of detection results from different algorithms on Waymo validation dataset
Tab.3 方法 AP/APH (LEVEL_1) AP/APH (LEVEL_2) d = 0~30 md = 30~50 md > 50 m均值 d = 0~30 md = 30~50 md > 50 m均值 SECOND[20 ] 88.66/88.18 67.35/66.70 42.89/42.09 70.07/69.52 87.33/86.86 60.92/60.23 32.39/31.77 61.63/61.14 PV-RCNN[30 ] 91.30/90.56 73.00/72.31 51.35/50.34 74.70/74.09 89.75/89.29 66.32/65.68 39.27/38.46 66.05/65.50 Voxel-RCNN[9 ] 90.81/90.36 72.43/71.78 50.37/49.47 73.90/73.32 89.50/89.05 65.68/65.08 38.32/37.61 65.10/64.58 本文方法 91.20 /90.77 73.28 /72.68 52.40 /51.45 74.92 /74.38 89.91 /89.48 66.58 /66.02 40.04 /39.29 66.19 /65.69
4.4. KITTI数据集上的消融实验结果展示与分析 为了分析本文所提出LIE模块和CAF模块的有效性,对2个模块进行消融实验. 可知,LIE模块可以分为2个部分:局部空间位置编码(local position encoding, LPE)和自注意力信息捕获(self-attention information capture, SIC). 如表4 所示,对整体架构进行全面的消融实验,验证每个组件的有效性. ...
... 表6 中,v 为推理速度,C 为计算量. 如表6 所示,相对于基线模型Voxel-RCNN[9 ] ,本文方法在提升检测性能0.79%的同时,增大了推理时间和计算量. 与基于点方法Point-RCNN[14 ] 相比,本文方法不仅使推理时间减少近56.21%,而且检测效果显著提升. 与点体素方法PV-RCNN[30 ] 相比,本文方法在推理时间和计算量方面均具有显著优势. 这得益于本文在体素方法的基础上,高效率编码多尺度体素特征和快速生成候选框,在细化阶段利用原始点云编码局部特征,避免了对全场景信息进行点特征提取,降低了时间和计算上的成本. ...
... Comparison of performance and efficiency of proposed method and other model
Tab.6 模型 v /(帧·s−1 )C /GBAP3D /% Voxel-RCNN[9 ] 0.041 22.78 85.29 PV-RCNN[30 ] 0.128 89.27 84.43 Point-RCNN[14 ] 0.153 27.71 78.63 本文方法 0.067 26.64 86.00
本文方法通过局部信息的重编码,在性能和效率方面取得了具有竞争力的效果. 局部信息的获取取决于RPN阶段生成的候选框质量. 由于RPN阶段采用普通卷积,相较于稀疏卷积,耗时较大. 普通卷积会对细化阶段的信息融合效果及整体的模型性能产生影响. 在接下来的工作中,将改进生成候选框的方式,利用稀疏卷积的高性能来提高候选框生成的速度. ...
2
... Comparison of detection result from different algorithm on KITTI test dataset
Tab.1 方法 模态 AP3D /% APBEV /% 简单 中等 困难 mAP 简单 中等 困难 mAP Point-GNN[16 ] L 88.33 79.47 72.29 80.03 93.11 89.17 83.90 88.73 3DSSD[18 ] L 88.36 79.57 74.55 80.83 92.66 89.02 85.86 89.18 PV-RCNN[30 ] L 90.25 81.43 76.82 82.83 94.98 90.65 86.14 90.60 Voxel-RCNN[9 ] L 90.90 81.62 77.06 83.19 94.85 88.83 86.13 89.94 CT3D[8 ] L 87.83 81.77 77.16 82.25 92.36 88.83 84.07 88.42 Pyramid-PV[28 ] L 88.39 82.08 77.49 82.65 92.19 88.84 86.21 89.08 VoTr[21 ] L 89.90 82.09 79.14 83.71 94.03 90.34 86.14 90.17 SPG[22 ] L 90.50 82.13 78.90 83.84 94.33 88.70 85.98 89.67 VoxSet[27 ] L 88.53 82.06 77.46 82.68 — — — — PDV[31 ] L 90.43 81.86 77.36 83.22 94.56 90.48 86.23 90.42 VFF[32 ] L+I 89.50 82.09 79.29 83.62 — — — — PG-RCNN[23 ] I 89.38 82.13 77.33 82.88 93.39 89.46 86.54 89.80 PVT-SSD[24 ] I 90.65 82.29 76.85 83.26 95.23 91.63 86.43 91.10 DVF-PV[25 ] L+I 90.99 82.40 77.37 83.58 — — — — 本文方法 L 91.60 82.53 77.83 83.99 95.59 91.37 86.72 91.23
在实验过程中,采用共同的划分方法将训练样本划分成训练集和验证集. 如表2 所示为本文方法在KITTI验证集上的结果,采用40个召回位置记录平均准确率. 利用本文方法取得了最先进的结果,相比于基线模型Voxel-RCNN[9 ] ,在简单、中等、困难的难度级别上分别将三维AP提高了0.89%、0.71%、0.71%,俯视图AP提高了1.14%、0.86%、0.76%. ...
... Comparison of detection result from different algorithm on KITTI validation dataset
Tab.2 方法 AP3D /% APBEV /% 简单 中等 困难 简单 中等 困难 PV-RCNN[30 ] 92.57 84.43 82.69 95.76 91.11 88.93 Voxel-RCNN[9 ] 92.38 85.29 82.86 95.52 91.25 88.99 PDV[31 ] 92.56 85.29 83.05 — — — VFF[32 ] 92.47 85.65 83.38 95.62 91.75 91.39 CT3D[8 ] 92.85 85.82 83.46 96.14 91.88 89.63 本文方法 93.27 86.00 83.57 96.66 92.11 89.75
4.3. Waymo数据集上不同算法的检测结果对比 如表3 所示为本文方法与先进方法的性能比较. 参与对比的模型有SECOND[20 ] 、PV-RCNN[30 ] 和Voxel-RCNN[9 ] ,所有模型都基于PyTorch实现,本文使用训练集的1/10进行训练,使用验证集的1/10进行测试. 与基线模型Voxel-RCNN[9 ] 相比,本文模型在等级1上的AP提升了1.02%,在等级2上提升了1.09%. 本文方法在所有期望的距离范围上都获得了良好的结果,其中在50 m以上的长距离范围内获得了最大的性能提升,在等级1和等级2上的AP分别提升了2.03%和1.72%. 从表3 可以看出,本文方法在2个难度级别上取得了较高的APH性能,验证了本文在捕获目标细节和空间关系方面具有优势,能够有效地处理各种目标难度. ...
2
... Comparison of detection result from different algorithm on KITTI test dataset
Tab.1 方法 模态 AP3D /% APBEV /% 简单 中等 困难 mAP 简单 中等 困难 mAP Point-GNN[16 ] L 88.33 79.47 72.29 80.03 93.11 89.17 83.90 88.73 3DSSD[18 ] L 88.36 79.57 74.55 80.83 92.66 89.02 85.86 89.18 PV-RCNN[30 ] L 90.25 81.43 76.82 82.83 94.98 90.65 86.14 90.60 Voxel-RCNN[9 ] L 90.90 81.62 77.06 83.19 94.85 88.83 86.13 89.94 CT3D[8 ] L 87.83 81.77 77.16 82.25 92.36 88.83 84.07 88.42 Pyramid-PV[28 ] L 88.39 82.08 77.49 82.65 92.19 88.84 86.21 89.08 VoTr[21 ] L 89.90 82.09 79.14 83.71 94.03 90.34 86.14 90.17 SPG[22 ] L 90.50 82.13 78.90 83.84 94.33 88.70 85.98 89.67 VoxSet[27 ] L 88.53 82.06 77.46 82.68 — — — — PDV[31 ] L 90.43 81.86 77.36 83.22 94.56 90.48 86.23 90.42 VFF[32 ] L+I 89.50 82.09 79.29 83.62 — — — — PG-RCNN[23 ] I 89.38 82.13 77.33 82.88 93.39 89.46 86.54 89.80 PVT-SSD[24 ] I 90.65 82.29 76.85 83.26 95.23 91.63 86.43 91.10 DVF-PV[25 ] L+I 90.99 82.40 77.37 83.58 — — — — 本文方法 L 91.60 82.53 77.83 83.99 95.59 91.37 86.72 91.23
在实验过程中,采用共同的划分方法将训练样本划分成训练集和验证集. 如表2 所示为本文方法在KITTI验证集上的结果,采用40个召回位置记录平均准确率. 利用本文方法取得了最先进的结果,相比于基线模型Voxel-RCNN[9 ] ,在简单、中等、困难的难度级别上分别将三维AP提高了0.89%、0.71%、0.71%,俯视图AP提高了1.14%、0.86%、0.76%. ...
... Comparison of detection result from different algorithm on KITTI validation dataset
Tab.2 方法 AP3D /% APBEV /% 简单 中等 困难 简单 中等 困难 PV-RCNN[30 ] 92.57 84.43 82.69 95.76 91.11 88.93 Voxel-RCNN[9 ] 92.38 85.29 82.86 95.52 91.25 88.99 PDV[31 ] 92.56 85.29 83.05 — — — VFF[32 ] 92.47 85.65 83.38 95.62 91.75 91.39 CT3D[8 ] 92.85 85.82 83.46 96.14 91.88 89.63 本文方法 93.27 86.00 83.57 96.66 92.11 89.75
4.3. Waymo数据集上不同算法的检测结果对比 如表3 所示为本文方法与先进方法的性能比较. 参与对比的模型有SECOND[20 ] 、PV-RCNN[30 ] 和Voxel-RCNN[9 ] ,所有模型都基于PyTorch实现,本文使用训练集的1/10进行训练,使用验证集的1/10进行测试. 与基线模型Voxel-RCNN[9 ] 相比,本文模型在等级1上的AP提升了1.02%,在等级2上提升了1.09%. 本文方法在所有期望的距离范围上都获得了良好的结果,其中在50 m以上的长距离范围内获得了最大的性能提升,在等级1和等级2上的AP分别提升了2.03%和1.72%. 从表3 可以看出,本文方法在2个难度级别上取得了较高的APH性能,验证了本文在捕获目标细节和空间关系方面具有优势,能够有效地处理各种目标难度. ...




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}