

在挖掘机作业对象识别的研究过程中,学者们进行了大量研究. 相关方法主要分为构建挖掘机与作业对象间的力学模型、使用视觉检测技术和机器学习的方法.
为了解决挖掘机作业对象识别现有技术存在的问题,本文提出基于蜜獾优化算法的CNN-LSTM-Attention神经网络模型. 该模型集成了空间特征提取、时序特征建模与注意力机制,具有如下创新点. 1)引入蜜獾优化算法,对模型超参数进行全局搜索与自动优化,提升网络性能并降低人工调参成本. 2)利用卷积神经网络(CNN),从输入数据中提取多层次的空间特征,充分捕捉数据的局部关联性,增强特征表达的有效性. 3)通过长短期记忆网络(LSTM)独特的门控机制,处理挖掘机作业过程中存在的时序依赖关系问题. 4)结合压缩与激励注意力机制(SE),引入通道权重自适应调整策略,强化关键特征表达,提升模型在复杂工况下的鲁棒性与泛化能力.
1. 数据收集与预处理
1.1. 作业对象选择与数据采集
根据物理特性,挖掘机作业对象可以分为软土、硬土、石方、砂岩、泥岩等类别. 每种土质的特性不同,挖掘机在作业时的各种运行参数有所差异. 选取软土、石方和砂岩这3类典型作业对象进行识别研究.
图 1

图 1 典型作业对象及数据采集设备
Fig.1 Typical operation object and data acquisition equipment
图 2

表 1 挖掘机实验平台的关键设备及主要参数
Tab.1
| 设备 | 型号 | 主要参数 |
| 液压挖掘机 | SY980H | 574/2 100 kW/(r·min−1) |
| 传感器 | HG3350G10NMPXM1 | 0~35 MPa/0.1%FS |
| 控制器 | BODAS RC28-14/30 | 50~250 Hz |
| CAN总线分析仪 | USBCAN-Ⅱ Pro | 50~8 000 kb/s |
| 数据记录仪 | ZLG CANDTU-200UR | 5~1 000 kb/s |
1.2. 特征选择
图 3
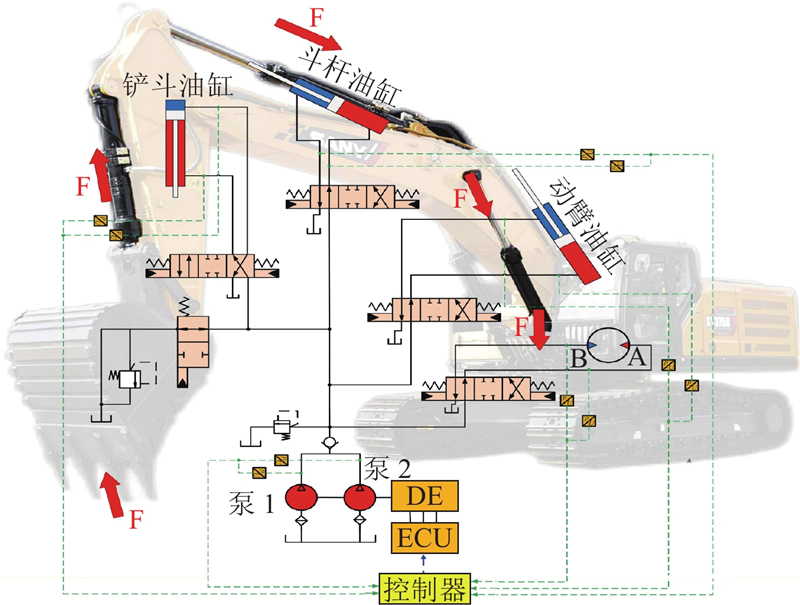
表 2 初步筛选的特征
Tab.2
| 特征 | 特征变量 |
| X1 | 发动机转速/(r·min−1) |
| X2 | 冷却液温度/℃ |
| X3 | 液压油温度/℃ |
| X4 | 铲斗挖掘先导压力/Pa |
| X5 | 铲斗挖掘先导电压/mV |
| X6 | 铲斗卸载先导压力/Pa |
| X7 | 铲斗卸载先导电压/mV |
| X8 | 铲斗大腔压力/Pa |
| X9 | 斗杆挖掘先导压力/Pa |
| X10 | 斗杆卸载先导压力/Pa |
| X11 | 斗杆挖掘先导电压/mV |
| X12 | 斗杆卸载先导电压/mV |
| X13 | 斗杆大腔压力/Pa |
| X14 | 斗杆小腔压力/Pa |
| X15 | 动臂大腔压力/Pa |
| X16 | 动臂小腔压力/Pa |
| X17 | 前泵压力/Pa |
| X18 | 后泵压力/Pa |
为了降低输入特征维度并提高分类性能,采用最大信息系数(maximum information coefficient, MIC)对特征间的相关性进行定量分析[12]. MIC是基于互信息和网格划分的相关性分析方法,无需事先假定变量之间的函数关系形式,即可有效识别变量之间的非线性关联.
根据MIC分析可知,不同变量之间都存在一定的相关性,为了避免数据冗余,选出12个最优输入特征参数作为特征集S2,如表3所示. 为了评估不同特征集对模型性能的影响,选取特征集S3和S4,其中特征集S3表示去除了前泵和后泵压力这2个参数,特征集S4表示去除了冷却液温度和液压油温度这2个特征参数.
表 3 基于MIC选择的特征
Tab.3
| 特征 | 特征变量 |
| X2 | 冷却液温度/℃ |
| X3 | 液压油温度/℃ |
| X5 | 铲斗挖掘先导电压/mV |
| X7 | 铲斗卸载先导电压/mV |
| X8 | 铲斗大腔压力/Pa |
| X11 | 斗杆挖掘先导电压/mV |
| X12 | 斗杆卸载先导电压/mV |
| X13 | 斗杆大腔压力/Pa |
| X14 | 斗杆小腔压力/Pa |
| X15 | 动臂大腔压力/Pa |
| X17 | 前泵压力/Pa |
| X18 | 后泵压力/Pa |
1.3. 数据预处理
受环境、设备及测量方法等因素的影响,在数据采集过程中容易产生误差点、冗余点及测量偏差,对神经网络的分类精度造成显著的影响. 噪声分析与降噪处理在数据预处理阶段具有重要的意义.
图 4
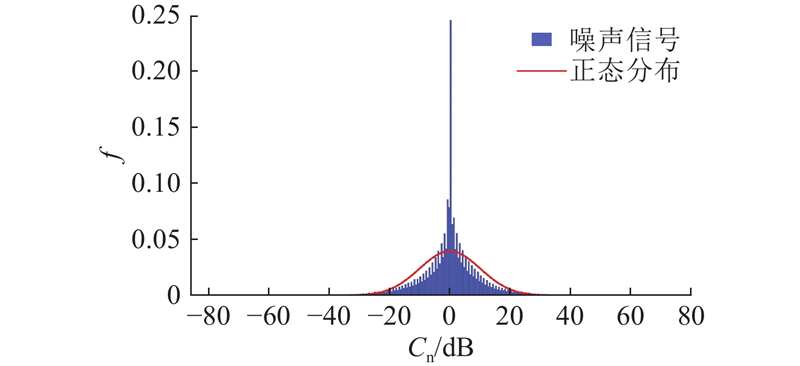
此外,PDF还用于描述噪声信号的振幅分布特征. 不同类型的噪声信号具有不同的PDF形状. 例如,高斯白噪声的PDF为正态分布的钟形曲线,而均匀噪声的PDF为矩形,在一定范围内均匀分布. 所采集数据的噪声概率密度f函数如图5所示. 其中,Cn为噪声幅度. 噪声信号基本符合正态分布,证明收集到的原始数据中含有大量的白噪声.
图 5
式中:
2. 基于组合神经网络的分类模型
2.1. 卷积神经网络
图 6
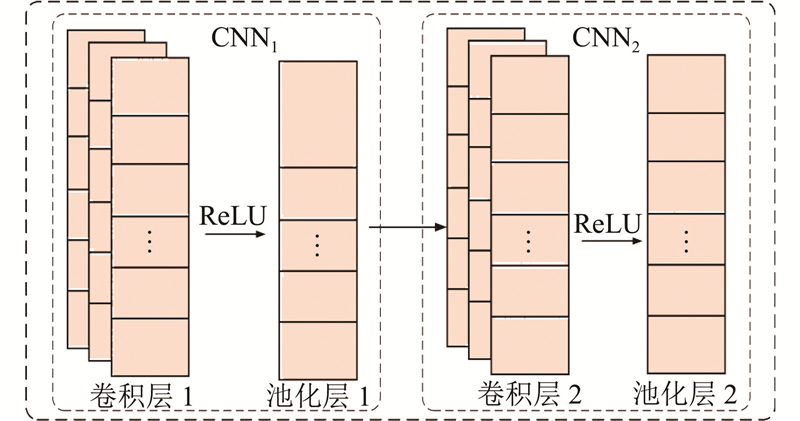
CNN用于提取一维时间序列中的局部特征. 这种一维卷积网络的设计思想与图像中的二维卷积类似,只是一维的卷积操作是沿着输入时间序列滑动,对局部时间窗口内的数据进行卷积操作. 其中,卷积层采用2层结构,第1层卷积核数为32,卷积核大小为3,使用ReLU激活函数;第2层卷积核数为64,卷积核大小为5. 采用ReLU激活函数.
2.2. 长短期记忆网络
图 7
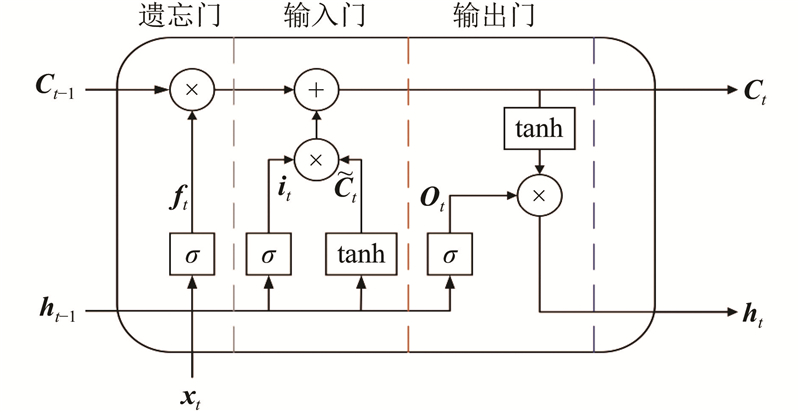
LSTM记忆细胞更新过程的公式如下.
遗忘门为
输入门为
输出门为
式中:ft为遗忘门,it为输入门,Ot为输出门,Ct为t时刻的单元状态,
2.3. SE注意力机制
SE注意力机制是增强特征表达能力的方法,旨在通过对通道维度的信息进行加权来提升模型的性能. 该机制使网络自适应地调整特征的权重. 结合SE注意力机制与CNN,强化关键特征表达,提升模型在复杂工况下的鲁棒性与泛化能力,工作步骤如下.
1)特征压缩. 通过全局平均池化(GAP)对输入特征进行空间维度的全局信息聚合,生成每个通道的全局特征:
式中:sc为通道c的全局特征,H和W分别为特征的高度和宽度,xc(i,j)为输入特征在通道c上的像素.
2)SE模块利用2个全连接层和非线性激活函数(ReLU和Sigmoid),计算通道间的权重分布:
式中:z为通道注意力权重,W1和W2分别为2个全连接层的权重矩阵,σ和δ分别为ReLU和Sigmoid激活函数,s为特征通道分配的重要性系数.
3) 通道加权. 通过通道权重对输入特征进行重新加权:
式中:
2.4. 蜜獾优化算法
蜜獾算法是Hashim等[19]提出的新的智能优化算法,核心思想是通过模拟蜜獾的觅食行为,将蜜獾的觅食行为划分为全局搜索和局部搜索2个阶段. 具体步骤如下.
1)初始化种群. 在搜索空间内随机初始化一组蜜獾个体,定义种群数量N、最大迭代次数T及每个个体的位置:
式中:xi为蜜獾的位置,ri为0~1.0的常数,lbi和ubi分别为搜索域的上、下界.
2)评估强度. 对每个蜂蜜与蜜獾的位置矢量强度进行评估,表示当前位置与下一个位置之间的关系:
式中:Ii为位置强度;r2为0~1.0的常数;xprey为最佳蜂蜜位置,即全局最优值.
3)全局搜索. 将蜜獾的位置更新为心形形状:
式中:xnew为蜜獾最新位置,F为搜索方向,
4)局部搜索. 蜜獾跟随蜂鸟到达蜂巢位置:
式中:r6为0~1.0的常数.
蜜獾更新位置主要受di及
2.5. HBA-CNN-LSTM-Attention分类模型
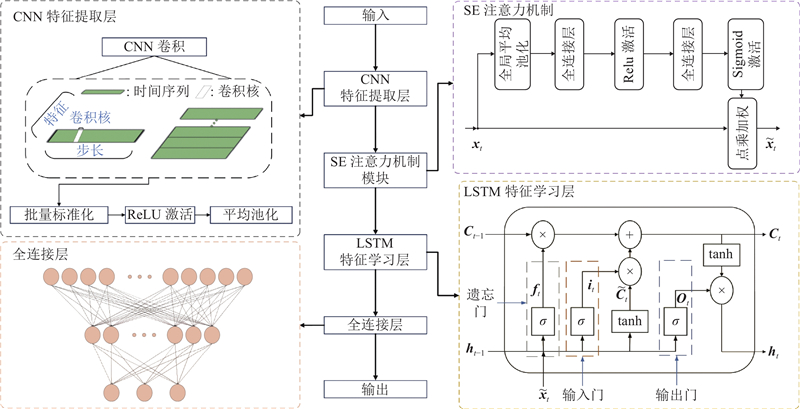
提出的HBA-CNN-LSTM-Attention组合模型主要包括特征提取、通道加权、时序建模和分类决策4个阶段,数据流向和各模块连接方式如下.
经过预处理的输入特征数据被送入CNN模块. CNN通过2层一维卷积操作提取局部时间窗口内的特征信息. 提取到的特征信息进入SE注意力机制模块,在通道维度上自适应地调整特征权重,以强化关键特征并抑制冗余信息. 经过SE模块加权后的特征被直接传递至LSTM模块,利用门控机制捕获挖掘机作业过程中的时序依赖特性. LSTM模块输出的高阶时序特征最终输入到全连接层,使用Softmax函数完成分类任务.
在训练过程中,采用蜜獾优化算法,在训练前对神经网络的主要超参数进行全局搜索与优化. 在超参数设定的范围内初始化种群,基于训练集上的初步分类准确率计算个体适应度,引导搜索方向,不断迭代更新,最终选择适应度最高的一组超参数用于网络的正式训练. HBA仅用于训练前的超参数搜索,未直接嵌入到神经网络的训练过程. 整体网络结构的数据流向如图8所示.
图 8
2.6. 评价指标
为了全面评估模型在分类任务中的性能,选取准确率A(accuracy)、精确率P(precision)、召回率R(recall)及F1分数(F1-score)作为主要的评价指标. 准确率用于衡量模型整体预测的正确性,即模型在所有预测样本中正确分类的比例. 精确率反映模型在预测某一特定类别时的准确性,表示在所有被判定为该类别的样本中实际为该类别的比例. 召回率用于评价模型识别该类别的能力,即在所有真实属于该类别的样本中被正确识别出来的比例. F1分数是精确率与召回率的调和平均值,综合体现了二者之间的平衡情况.
通常模型的分类性能越优异,这4项指标的数值越接近于1,意味着模型在识别目标类别时表现出较高的准确性和稳定性. 相反,若这些指标的数值接近于0,则表明模型在分类过程中存在较大的偏差或错误,识别能力较弱,难以满足实际应用的需求. 这些评价指标不仅有助于从不同维度分析模型的分类效果,而且为模型的优化与改进提供了有力的量化依据.
各评价指标的计算公式为
式中:TPi为正确预测为i的样本数,FPi为错误预测为i的样本数,FNi为错误预测为非i的样本数,TNi为正确预测为非i的样本数.
3. 实验结果与分析
3.1. 实验设置
使用的数据集由采样频率为5 Hz的
为了进一步验证HBA-CNN-LSTM-Attention模型在分类任务中的优越性,选取CNN、GRU和LSTM作为对比模型,使用相同的蜜獾优化方法对超参数进行调优,以确保对比实验结果的公平与合理性. 在实验中,蜜獾优化的迭代次数设置为30,如表4所示为蜜獾优化中各超参数的优化范围.
表 4 蜜獾优化的超参数
Tab.4
| 超参数 | 数值 |
| 隐含层神经元数量 Nh | [16, 128] |
| 神经元丢弃率 d | [0.1, 0.6] |
| 初始学习率 r | [1×10−6, 1×10−2] |
| L2正则化参数 CL | [1×10−10, 1×10−2] |
3.2. 实验结果与讨论
3.2.1. 不同作业对象的识别结果与分析
为了评估模型在不同作业对象上的分类性能,统计蜜獾优化后各模型在软土、石方、砂岩3类作业对象上的分类准确率,具体结果如图9所示.
图 9
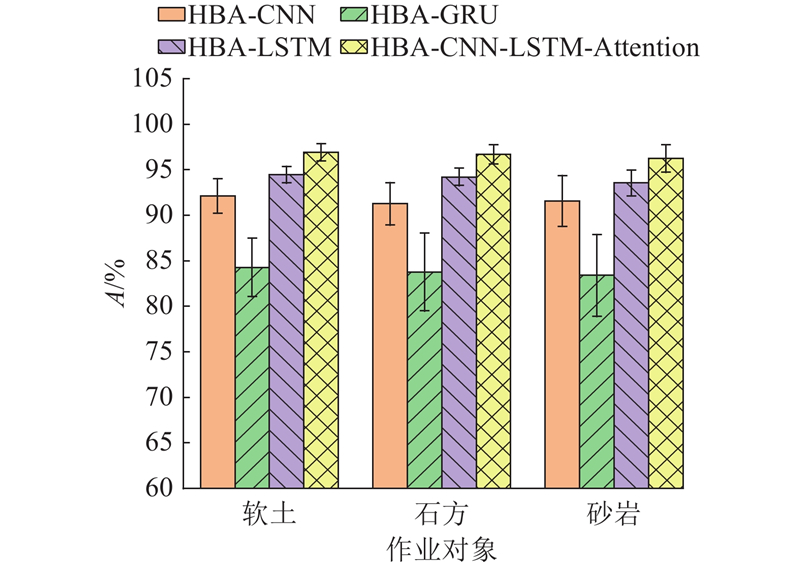
从图9可以看出,4种模型在不同作业对象上的识别准确率存在一定差异. 总体而言,HBA-CNN-LSTM-Attention模型在3类作业对象的分类任务中均取得了最优性能,软土、石方、砂岩的识别准确率分别达到96.93%、96.71%和96.23%. 这一结果验证了融合模型在综合特征提取与时间序列建模方面的优势.
当作业对象为软土时,各模型均取得了较高的分类准确率,其中HBA-LSTM和HBA-CNN-LSTM-Attention模型分别达到94.47%和96.93%. 这一现象主要归因于软土作业过程中的液压系统响应特性较平稳,特征波动模式明显,便于模型捕捉与学习.
在石方类别上,各模型的识别准确率较软土稍有下降,尤其是HBA-GRU模型的准确率最低,仅约为83.78%. 基于液压系统机理分析可知,石方作业时,由于作业对象为硬质介质,挖掘机承受的负载压力显著增大,导致主油路压力波动剧烈,特征分布复杂. 液压系统中各执行器的流量分配耦合增强,增加了特征间的关联性与噪声,进而加大了分类模型的学习难度. 尽管如此,HBA-CNN-LSTM-Attention模型在石方作业对象上的识别准确率仍达到96.71%,体现出该模型在复杂工况下的优越性能.
在砂岩类别的识别中,相较于软土和石方,分类准确率略低,但差距不显著. 这是由于在挖掘砂岩的过程中,挖掘机负载达到最高,液压系统主回路压力长期维持在高位,且系统响应整体稳定,但存在一定幅度的波动. 当挖掘砂岩时,挖掘机转速、液压油温和冷却液温度的变化幅度明显高于软土作业. 上述特性使得砂岩作业对象的特征模式既具有一定的规律性,又包含复杂的动态变化,从而对分类准确率带来一定的挑战. 总体来看,3类作业对象的识别准确率接近,表明所提出的模型具有较好的工况适应能力和泛化性能.
3.2.2. 模型性能提升机制的分析
为了评估模型性能提升机制的有效性,从超参数优化策略与网络结构设计2个方面展开分析,分别考察蜜獾优化算法与SE注意力机制对分类精度的贡献.
为了分析蜜獾优化对不同分类模型性能的提升作用,对比各模型在优化前、后分类性能的差异. 优化前,各模型的超参数通过传统的经验调参方法确定,即结合常见的经验值和试错实验逐步调整参数. 优化后,各模型的超参数配置严格依据蜜獾优化算法的搜索结果确定,从而更系统地探索模型的最优参数组合. 优化前、后各模型的具体超参数组合如表5所示,包括Nh、d、r、CL.
表 5 不同模型的超参数设置
Tab.5
| 模型 | Nh | d | r | CL |
| CNN | 32 | 0.2 | 0.001 | |
| HBA-CNN | 73 | 6.21×10−5 | ||
| GRU | 32 | 0.2 | 0.001 | |
| HBA-GRU | 66 | 4.04×10−9 | ||
| LSTM | 32 | 0.2 | 0.001 | |
| HBA-LSTM | 43 | 9.47×10−8 | ||
| CNN-LSTM-Attention | 32 | 0.2 | 0.001 | |
| HBA-CNN-LSTM-Attention | 76 | 4.37×10−6 |
实验结果表明,在未应用蜜獾优化的情况下,CNN模型的准确率为90.52%,LSTM模型为92.99%,融合模型CNN-LSTM-Attention的准确率达到93.07%. 相比之下,GRU模型的表现相对较弱,平均分类准确率仅为82.34%. 在采用蜜獾优化对超参数进行调整后,各模型的分类性能均有明显的提升. 其中,CNN提升了1.41%,LSTM提升了1.07%,CNN-LSTM-Attention提升了3.8%,GRU提升了1.86%. 这一结果证明蜜獾优化在超参数调节中的优势,高效的搜索策略能够挖掘出更适合各模型的超参数组合,从而显著提高模型的分类效果.
为了进一步验证SE注意力机制在组合模型中的有效性和实际贡献,设计消融实验. 在保持HBA优化策略及CNN-LSTM主干结构不变的条件下,将SE注意力机制模块从组合模型中移除,构建对比模型HBA-CNN-LSTM. 实验结果表明,在缺少注意力机制模块的情况下,模型的整体性能下降,其中分类准确率由原始模型的96.61%下降至94.85%,精确率、召回率和F1分数分别降低了约2.22%、1.68%和1.96%. 这一结果说明,SE模块通过引入特征通道间的权重分配机制,有效增强了模型对关键特征的关注能力,提升了特征表达的判别性,从而在面对复杂工况数据时显著增强了模型的泛化性能和稳健性.
此外,各模型在不同特征集上的分类性能各不一致. 这种差异与特征集的具体组成、数据的分布特性及模型结构对特定类型特征的适应性密切相关. 本节的分析主要聚焦于不同模型在综合性能上的提升情况,而关于不同模型在具体特征集上的分类表现将在后续章节中详细讨论.
3.2.3. 不同分类模型的综合性能
为了全面评估各模型在分类任务中的性能表现,采用准确率、精确率、召回率及F1分数作为模型性能的评价指标. 通过对4种模型在4个特征集上的分类结果进行对比分析,综合性能的评估采用评价指标的平均值作为参考标准. 如表6所示为各模型经过蜜獾优化后的综合分类性能指标.
表 6 蜜獾优化后模型的分类性能
Tab.6
| 模型 | A | P | R | F1 |
| CNN | ||||
| GRU | ||||
| LSTM | ||||
| CNN-LSTM-Attention |
实验结果表明,尽管所有模型均经过蜜獾优化处理,GRU模型的综合性能仍显著低于其他模型,准确率、精确率、召回率和F1分数分别为83.87%、84.16%、84.25%和83.80%. 在几种模型中,CNN-LSTM-Attention模型的综合性能表现最佳,分类准确率达到96.61%,精确率、召回率和F1分数均超过95%. 相比之下,单一模型CNN和LSTM在分类任务中存在各自的局限性:CNN在特征提取方面表现突出,但在时间序列建模上能力有限;LSTM在处理长时间序列依赖关系方面具备优势,但在处理高维复杂特征时表现欠佳.
GRU模型分类性能较低的主要原因是设计上取消了独立的遗忘门,削弱了处理长时间序列依赖关系的能力. 此外,GRU在高维特征处理能力上存在一定的局限性. 对比结果表明,CNN-LSTM-Attention模型能够有效结合CNN的特征提取能力和LSTM在时间序列建模方面的优势,同时注意力机制更加关注输入数据中的有用特征,抑制无关特征,增强了特征的表达能力.
对于压力传感器信号这类高频响且对挖掘机控制起重要影响的关键参数,在应用过程中必须考虑模型的实时性要求. 为了评估各模型在实际应用中的响应速度,选取30 s的实时作业数据作为测试集,记录各模型的预测总时间ta及单个数据点的平均预测时间ts. 如表7所示为不同模型在测试集上的实时预测时间.
表 7 各模型的实时预测时间
Tab.7
| 模型 | ta/s | ts/s |
| CNN | 1.61 | |
| HBA-CNN | 1.72 | |
| GRU | 2.19 | |
| HBA-GRU | 2.33 | |
| LSTM | 1.75 | |
| HBA-LSTM | 1.87 | |
| CNN-LSTM-Attention | 3.97 | |
| HBA-CNN-LSTM-Attention | 4.13 |
从表7可见,所有模型的预测总时间均远小于30 s,能够满足实时性的要求. 在逐点输入的数据流式处理场景中,各模型的单数据点平均预测时间均小于0.03 s. 其中,LSTM模型在未优化情况下的单点预测时间为0.011 7 s,优化后的HBA-LSTM模型为0.012 5 s,二者的时间差异较小. 整体来看,CNN及LSTM系列模型在推理速度上优于GRU系列,而CNN-LSTM-Attention和HBA-CNN-LSTM-Attention由于网络结构更复杂,推理时间略有增加,单数据点的平均预测时间分别为0.026 5与0.027 5 s,但仍处于可接受范围内.
此外,从同种模型的对比可以发现,应用HBA优化后,各模型的推理时间仅有微小增加,几乎不会对实时性能造成影响. 可以看出,本文提出的各模型在挖掘机作业对象的实时识别任务中均具备良好的实时响应能力,能够有效地支撑智能控制系统的快速决策需求.
3.2.4. 不同分类模型在各特征集上的表现
虽然经过蜜獾优化过的CNN-LSTM-Attention模型在综合性能方面表现最佳,但在不同特征集上模型的性能表现有所差异. 不同模型在各特征集上的性能评价指标采用准确率、精确率、召回率及F1分数,各项评价指标如表8所示.
表 8 不同模型在各特征集上的性能指标
Tab.8
| 模型 | 特征集 | A | P | R | F1 |
| HBA-CNN | S1 | ||||
| S2 | |||||
| S3 | |||||
| S4 | |||||
| HBA-GRU | S1 | ||||
| S2 | |||||
| S3 | |||||
| S4 | |||||
| HBA-LSTM | S1 | ||||
| S2 | |||||
| S3 | |||||
| S4 | |||||
| HBA-CNN- LSTM-Attention | S1 | ||||
| S2 | |||||
| S3 | |||||
| S4 |
经过蜜獾优化后的CNN模型,由于其强大的特征提取能力,在除特征集S4之外的其余特征集上,分类准确率均达到90%以上,而在特征集S4上的分类精度仅为87.98%. 特征集S4中去除了冷却液温度和液压油温度这2个特征参数,这一结果表明,CNN模型在对挖掘机作业对象识别时,对液压油和冷却液温度这2个特征参数具有较强的依赖性. 当使用LSTM模型对挖掘机作业对象进行分类时,在4个特征集上的分类精度均能达到90%以上. CNN-LSTM-Attention组合模型在特征集S1、S2和S3上的分类准确率均超过97.84%,表现出优异的学习能力与泛化性能. 在特征集S4上的分类精度只能达到92.43%,这是由于组合模型中的CNN部分在特征提取时对液压油和冷却液温度这2个特征参数产生了依赖.
此外,GRU模型在几个特征集上的分类精度均低于90%. GRU模型取消了独立的遗忘门后,不仅在特征提取的能力上不如CNN模型,而且在处理时间序列依赖关系的能力上远不如LSTM模型.
CNN模型和CNN-LSTM-Attention组合模型对液压油温度与冷却液温度这2个特征参数具有较强的依赖性. 液压油温度升高会导致黏度下降,从而影响液压系统的流动性和响应速度. 冷却液温度反映整机负载与热状态的波动,两者共同构成了动力与液压系统的重要热态特征,能够在传感器数据中体现出明显的趋势、周期性或突变信息,成为分类模型判别工况类别的重要依据. 特别是对于CNN模型而言,通过卷积操作捕捉局部模式,对这类热态特征极为敏感,因此在缺少温度参数时分类性能明显下降. 在CNN-LSTM-Attention组合模型中,尽管包含LSTM结构以处理时序依赖,但信息首先经由CNN进行特征提取,温度特征因其辨识度高,在卷积阶段被放大. 随后Attention机制对温度特征分配更高的权重,固化了模型对温度通道的依赖. 一旦温度特征被剔除,则组合模型的整体特征表达能力受限,难以通过LSTM补偿前端CNN信息损失. 单一LSTM模型直接处理原始多通道时间序列,可以通过门控机制灵活调整不同通道的影响权重,充分挖掘其余信号的时序模式,即便在缺失温度通道的情况下,也能维持较高的分类性能,表现出更强的鲁棒性. 这一差异说明,在特征设计阶段,对于结构复杂的深度融合模型,应特别关注核心特征的保留.
4. 结 语
针对传统挖掘机作业对象识别方法存在的复杂度高、适应性差的问题,提出基于多源传感器数据的组合神经网络模型. 该模型融合CNN的空间特征提取能力与LSTM的时序建模优势,结合注意力机制与蜜獾优化算法,实现模型结构和超参数的自适应优化. 实验结果表明,该模型针对软土、石方和砂岩3类作业对象的识别精度明显优于传统CNN、LSTM及GRU模型,验证了所提方法的有效性与鲁棒性.
未来的研究可以拓展该模型在更多类型作业对象和复杂施工环境下的应用. 结合多模态传感信息与轻量化网络结构,实现挖掘机作业识别的实时化与工程化应用,为智能化施工装备提供技术支撑.
参考文献
Task learning, intent prediction, and adaptive blended shared control with application to excavators
[J].DOI:10.1109/TCST.2019.2959536 [本文引用: 1]
智能建造: 工程机械智能化
[J].DOI:10.11832/j.issn.1000-4858.2022.06.001
Intelligent construction: construction machinery intelligentization
[J].DOI:10.11832/j.issn.1000-4858.2022.06.001
智能化挖掘机的研究现状与发展趋势
[J].DOI:10.3901/JME.2020.13.165 [本文引用: 1]
Research status and development trend of intelligent excavators
[J].DOI:10.3901/JME.2020.13.165 [本文引用: 1]
基于模糊控制算法的露天铁矿挖掘机控制研究
[J].
Research on control of open-pit iron mine excavator based on fuzzy control algorithm
[J].
Admittance control for robotic loading: design and experiments with a 1-tonne loader and a 14-tonne load-haul-dump machine
[J].DOI:10.1002/rob.21654 [本文引用: 1]
Method and apparatus for on-line estimation of soil parameters during excavation
[J].
Hybrid soil parameter measurement and estimation scheme for excavation automation
[J].DOI:10.1109/TIM.2009.2018699 [本文引用: 1]
Difficulty assessment of shoveling stacked materials based on the fusion of neural network and radar chart information
[J].DOI:10.1016/j.autcon.2021.103966 [本文引用: 1]
What lies beneath: material classification for autonomous excavators using proprioceptive force sensing and machine learning
[J].DOI:10.1016/j.autcon.2020.103374 [本文引用: 1]
Application of physics-informed machine learning for excavator working resistance modeling
[J].DOI:10.1016/j.ymssp.2024.111117 [本文引用: 1]
Feature selection method based on wavelet similarity combined with maximum information coefficient
[J].DOI:10.1016/j.ins.2024.121801 [本文引用: 1]
增强小波系数的飞行数据奇异值阈值降噪
[J].
Flight data de-noising using enhanced wavelet coefficients and threshold shrinkage in wavelet transform with singular value decomposition
[J].
Nonlinear comb narrow-band noise removal using unscented Kalman filter: feasibility and field test analysis
[J].DOI:10.1016/j.measurement.2024.115928 [本文引用: 1]
A CNN-based visual sorting system with cloud-edge computing for flexible manufacturing systems
[J].DOI:10.1109/TII.2019.2947539 [本文引用: 1]
Honey Badger algorithm: new metaheuristic algorithm for solving optimization problems
[J].DOI:10.1016/j.matcom.2021.08.013 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}