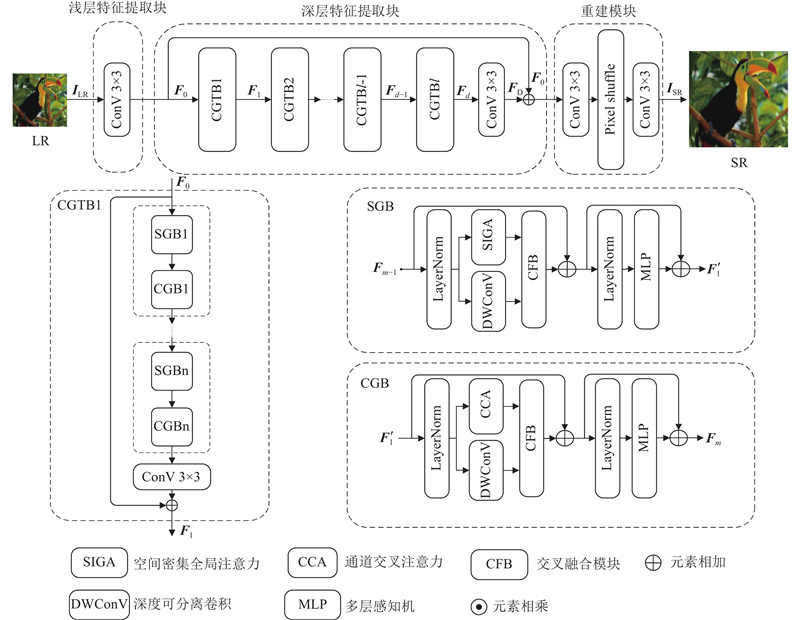
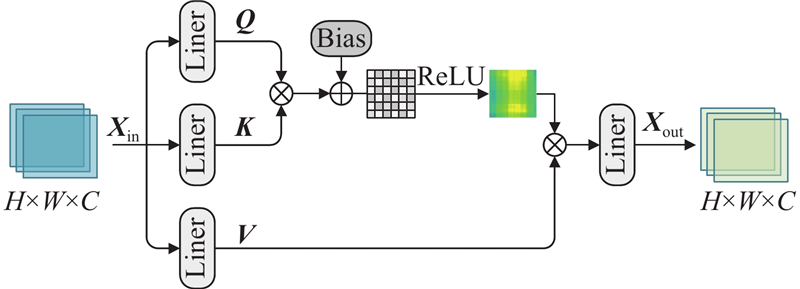
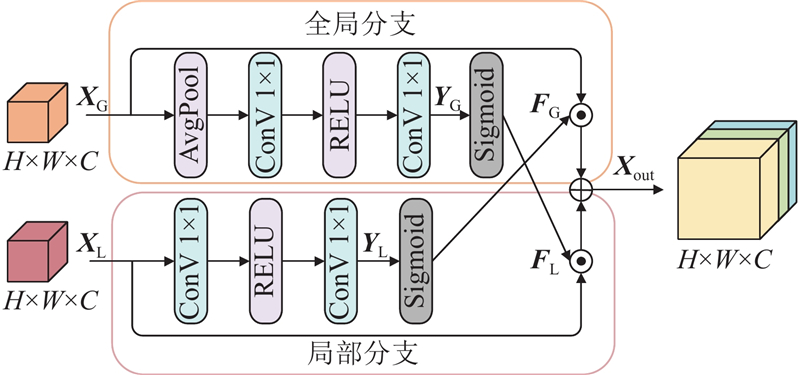
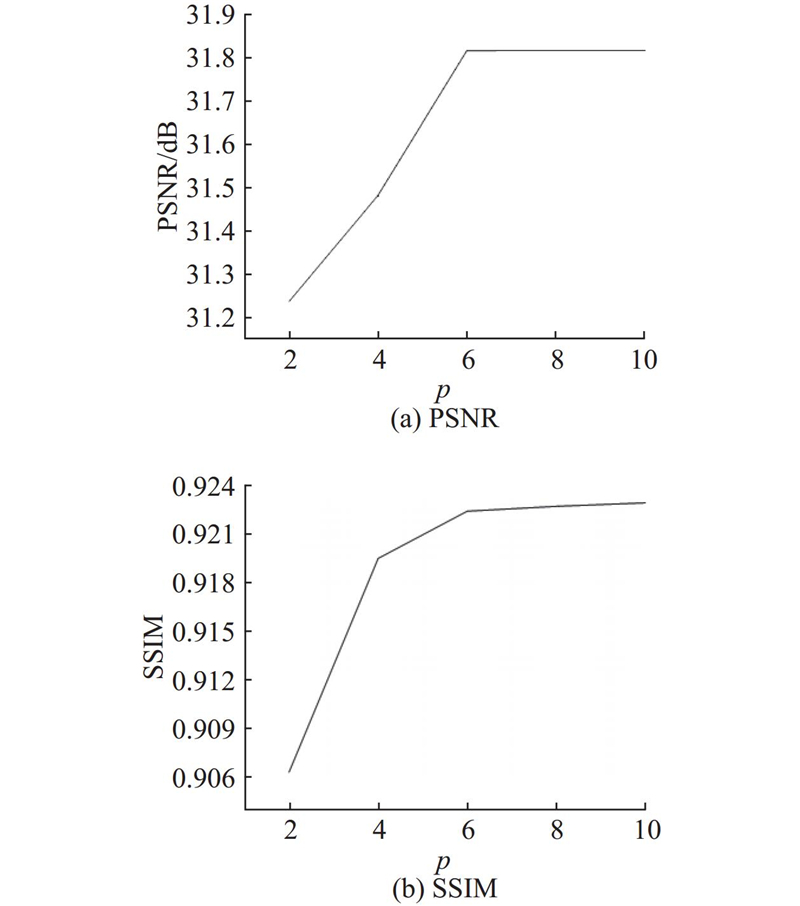
| 计算机技术 |
|


|
|
|
| 双维度交叉融合驱动的图像超分辨率重建方法 |
贾晓芬1,2( ),王子祥3,赵佰亭3,梁镇洹2,胡锐2 ),王子祥3,赵佰亭3,梁镇洹2,胡锐2 |
1. 安徽理工大学 煤炭无人化开采数智技术全国重点实验室,安徽 淮南 232001
2. 安徽理工大学 人工智能学院,安徽 淮南 232001
3. 安徽理工大学 电气与信息工程学院,安徽 淮南 232001 |
|
| Image super-resolution reconstruction method driven by two-dimensional cross-fusion |
| Xiaofen JIA1,2(),Zixiang WANG3,Baiting ZHAO3,Zhenhuan LIANG2,Rui HU2 |
1. State Key Laboratory of Digital Intelligent Technology for Unmanned Coal Mining, Anhui University of Science and Technology, Huainan 232001, China
2. Institute of Artificial Intelligence, Anhui University of Science and Technology, Huainan 232001, China
3. Institute of Electrical and Information Engineering, Anhui University of Science and Technology, Huainan 232001, China |
引用本文:
贾晓芬,王子祥,赵佰亭,梁镇洹,胡锐. 双维度交叉融合驱动的图像超分辨率重建方法[J]. 浙江大学学报(工学版), 2025, 59(12): 2516-2526.
Xiaofen JIA,Zixiang WANG,Baiting ZHAO,Zhenhuan LIANG,Rui HU. Image super-resolution reconstruction method driven by two-dimensional cross-fusion. Journal of ZheJiang University (Engineering Science), 2025, 59(12): 2516-2526.
链接本文:
https://www.zjujournals.com/eng/CN/10.3785/j.issn.1008-973X.2025.12.006
或
https://www.zjujournals.com/eng/CN/Y2025/V59/I12/2516
|
| 1 |
DENG C, LUO X, WANG W Multiple frame splicing and degradation learning for hyperspectral imagery super-resolution[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2022, 15: 8389- 8401
doi: 10.1109/JSTARS.2022.3207777
|
| 2 |
MA J, LIU S, CHENG S, et al STSRNet: self-texture transfer super-resolution and refocusing network[J]. IEEE Transactions on Medical Imaging, 2022, 41 (2): 383- 393
doi: 10.1109/TMI.2021.3112923
|
| 3 |
ZHAO Z, ZHANG Y, LI C, et al Thermal UAV image super-resolution guided by multiple visible cues[J]. IEEE Transactions on Geoscience and Remote Sensing, 2023, 61: 5000314
|
| 4 |
DONG C, LOY C C, HE K, et al Image super-resolution using deep convolutional networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38 (2): 295- 307
doi: 10.1109/TPAMI.2015.2439281
|
| 5 |
KIM J, LEE J K, LEE K M. Accurate image super-resolution using very deep convolutional networks [C]// IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 1646–1654.
|
| 6 |
ZHANG Y, TIAN Y, KONG Y, et al. Residual dense network for image super-resolution [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 2472–2481.
|
| 7 |
HU J, SHEN L, SUN G. Squeeze-and-excitation networks [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 7132–7141.
|
| 8 |
LIM B, SON S, KIM H, et al. Enhanced deep residual networks for single image super-resolution [C]// IEEE Conference on Computer Vision and Pattern Recognition Workshops. Honolulu: IEEE, 2017: 1132–1140.
|
| 9 |
VASWANI A, SHAZEER N M, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. California: Curran Associates Inc., 2017: 6000–6010.
|
| 10 |
LIANG J, CAO J, SUN G, et al. SwinIR: image restoration using swin transformer [C]// IEEE/CVF International Conference on Computer Vision Workshops. Montreal: IEEE, 2021: 1833–1844.
|
| 11 |
CHU X, TIAN Z, WANG Y, et al. Twins: revisiting the design of spatial attention in vision transformers [J]. Advances in Neural Information Processing Systems. 2021, 34: 9355–9366.
|
| 12 |
YANG R, MA H, WU J, et al. ScalableViT: rethinking the context-oriented generalization of vision transformer [C]// Proceedings of Computer Vision – ECCV 2022. Cham: Springer, 2022: 480–496.
|
| 13 |
CARION N, MASSA F, SYNNAEVE G, et al. End-to-end object detection with transformers [C]// Proceedings of Computer Vision – ECCV 2020. Cham: Springer, 2020: 213–229.
|
| 14 |
BEAL J, KIM E, TZENG E, et al. Toward Transformer-Based Object Detection [EB/OL]. (2020−12−17) [2025−09−15]. https://doi.org/10.48550/arXiv.2012.09958.
|
| 15 |
PENG Z, HUANG W, GU S, et al. Conformer: local features coupling global representations for visual recognition [C]// 2021 IEEE/CVF International Conference on Computer Vision (ICCV). Montreal: IEEE, 2021: 357−366.
|
| 16 |
WANG H, CHEN X, NI B, et al. Omni aggregation networks for lightweight image super-resolution [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver: IEEE, 2023: 22378–22387.
|
| 17 |
HUI Z, GAO X, YANG Y, et al. Lightweight image super-resolution with information multi-distillation network [C]// 27th ACM International Conference on Multimedia. [S.l.]: ACM, 2019: 2024−2032.
|
| 18 |
JI J, ZHONG B, WU Q, et al A channel-wise multi-scale network for single image super-resolution[J]. IEEE Signal Processing Letters, 2024, 31: 805- 809
doi: 10.1109/LSP.2024.3372781
|
| 19 |
WANG X, JI H, SHI C, et al. Heterogeneous Graph Attention Network [C]// The World Wide Web Conference. San Francisco: [s.n.], 2019: 2022–2032.
|
| 20 |
LI X, DONG J, TANG J, et al. DLGSANet: lightweight dynamic local and global self-attention network for image super-resolution [C]// IEEE/CVF International Conference on Computer Vision. Paris: IEEE, 2023: 12746–12755.
|
| 21 |
LIN H, CHENG X, WU X, et al. CAT: cross attention in vision transformer [C]// IEEE International Conference on Multimedia and Expo. Taipei: IEEE, 2022: 1–6.
|
| 22 |
CHEN Z, ZHANG Y, GU J, et al. Recursive Generalization Transformer for Image Super-Resolution [EB/OL]. (2023−03−11) [2025−09−15]. https://doi.org/10.48550/arXiv.2303.06373.
|
| 23 |
KINGMA D, BA J. Adam: a method for stochastic optimization [EB/OL]. (2014−12−14) [2025−09−15]. https://doi.org/10.48550/arXiv.1412.6980.
|
| 24 |
AGUSTSSON E, TIMOFTE R. NTIRE 2017 challenge on single image super-resolution: dataset and study [C]// IEEE Conference on Computer Vision and Pattern Recognition Workshops. Honolulu: IEEE, 2017: 1122–1131.
|
| 25 |
BEVILACQUA M, ROUMY A, GUILLEMOT C, et al. Low-complexity single-image super-resolution based on nonnegative neighbor embedding [C]// Proceedings of British Machine Vision Conference. Surrey: British Machine Vision Association, 2012.
|
| 26 |
ZEYDE R, ELAD M, PROTTER M. On single image scale-up using sparse-representations [C]// Proceedings of International Conference on Curves and Surfaces. Avignon: Springer, 2010: 711–730.
|
| 27 |
MARTIN D, FOWLKES C, TAL D, et al. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics [C]// 8th IEEE International Conference on Computer Vision. Vancouver: IEEE, 2001: 416–423.
|
| 28 |
HUANG J B, SINGH A, AHUJA N. Single image super-resolution from transformed self-exemplars [C]// IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 5197–5206.
|
| 29 |
MATSUI Y, ITO K, ARAMAKI Y, et al Sketch-based manga retrieval using manga109 dataset[J]. Multimedia Tools and Applications, 2017, 76 (20): 21811- 21838
doi: 10.1007/s11042-016-4020-z
|
| 30 |
WANG Z, BOVIK A C, SHEIKH H R, et al Image quality assessment: from error visibility to structural similarity[J]. IEEE Transactions on Image Processing, 2004, 13 (4): 600- 612
doi: 10.1109/TIP.2003.819861
|
| 31 |
ZHANG Y, TIAN Y, KONG Y, et al. Residual dense network for image super-resolution [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 2472–2481.
|
| 32 |
LYN J, YAN S. Non-local Second-order attention network for single image super resolution [C]// Proceedings of International Cross-Domain Conference for Machine Learning and Knowledge Extraction. Dublin: Springer, 2020: 267–279.
|
| 33 |
LIU J, ZHANG W, TANG Y, et al. Residual feature aggregation network for image super-resolution [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020: 2356–2365.
|
| 34 |
MEI Y, FAN Y, ZHOU Y. Image super-resolution with non-local sparse attention [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville: IEEE, 2021: 3516–3525.
|
| 35 |
ZHENG L, ZHU J, SHI J, et al Efficient mixed transformer for single image super-resolution[J]. Engineering Applications of Artificial Intelligence, 2024, 133: 108035
doi: 10.1016/j.engappai.2024.108035
|
| 36 |
HWANG K, YOON G, SONG J, et al Fusing bi-directional global–local features for single image super-resolution[J]. Engineering Applications of Artificial Intelligence, 2024, 127: 107336
doi: 10.1016/j.engappai.2023.107336
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|