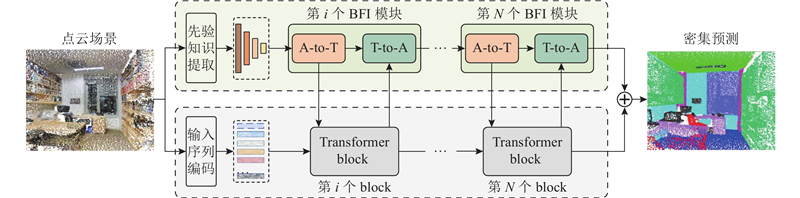
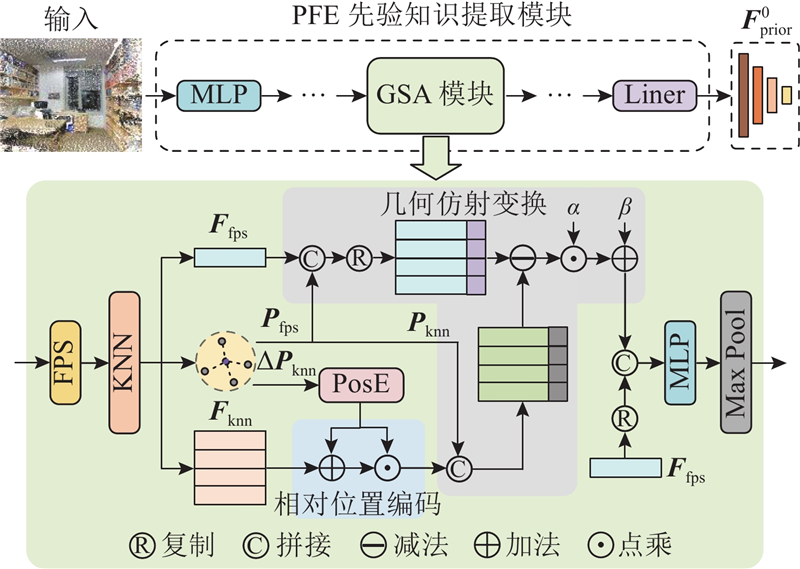
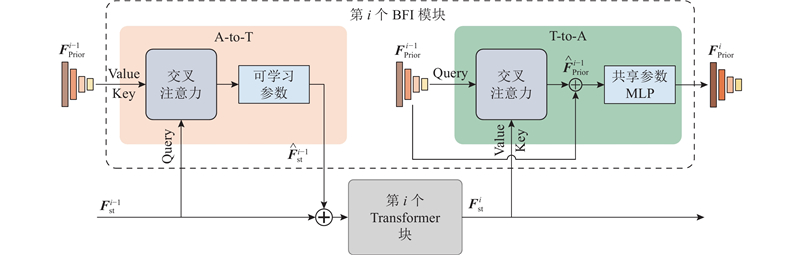
| 计算机技术、信息工程 |
|

|
|
|
| 面向密集预测任务的点云Transformer适配器 |
张德军1( ),白燕子1,曹锋1,吴亦奇1,徐战亚2,*() ),白燕子1,曹锋1,吴亦奇1,徐战亚2,*() |
1. 中国地质大学(武汉) 智能地学信息处理湖北省重点实验室,湖北 武汉 430074
2. 中国地质大学(武汉) 地理与信息工程学院,湖北 武汉 430074 |
|
| Point cloud Transformer adapter for dense prediction task |
| Dejun ZHANG1(),Yanzi BAI1,Feng CAO1,Yiqi WU1,Zhanya XU2,*() |
1. Hubei Key Laboratory of Intelligent Geo-Information Processing, China University of Geosciences, Wuhan 430074, China
2. School of Geography and Information Engineering, China University of Geosciences, Wuhan 430074, China |
引用本文:
张德军,白燕子,曹锋,吴亦奇,徐战亚. 面向密集预测任务的点云Transformer适配器[J]. 浙江大学学报(工学版), 2025, 59(5): 920-928.
Dejun ZHANG,Yanzi BAI,Feng CAO,Yiqi WU,Zhanya XU. Point cloud Transformer adapter for dense prediction task. Journal of ZheJiang University (Engineering Science), 2025, 59(5): 920-928.
链接本文:
https://www.zjujournals.com/eng/CN/10.3785/j.issn.1008-973X.2025.05.005
或
https://www.zjujournals.com/eng/CN/Y2025/V59/I5/920
|
| 1 |
CHOE J, PARK C, RAMEAU F, et al. Pointmixer: Mlp-mixer for point cloud understanding [C]// European Conference on Computer Vision . Israel: Springer, 2022: 620-640.
|
| 2 |
ZHAO H, JIANG L, FU C W, et al. Pointweb: enhancing local neighborhood features for point cloud processing [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 5565-5573.
|
| 3 |
QI Z, DONG R, FAN G, et al. Contrast with reconstruct: contrastive 3d representation learning guided by generative pretraining [C]// International Conference on Machine Learning . Honolulu: PMLR, 2023: 28223-28243.
|
| 4 |
YANG Y Q, GUO Y X, XIONG J Y, et al. Swin3D: a pretrained Transformer backbone for 3D indoor scene understanding [EB/OL]. (2023-08-26) [2024-05-25]. https://arxiv.org/abs/2304.06906.
|
| 5 |
ZHAO H, JIANG L, JIA J, et al. Point transformer [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 16259-16268.
|
| 6 |
GUO M H, CAI J X, LIU Z N, et al Pct: point cloud transformer[J]. Computational Visual Media, 2021, 7: 187- 199
doi: 10.1007/s41095-021-0229-5
|
| 7 |
DONG R, QI Z, ZHANG L, et al. Autoencoders as cross-modal teachers: can pretrained 2D image Transformers help 3D representation learning? [EB/OL]. (2023-02-02) [2024-05-25]. https://arxiv.org/abs/2212.08320.
|
| 8 |
LIU H, CAI M, LEE Y J. Masked discrimination for self-supervised learning on point clouds [C]// European Conference on Computer Vision . Tel Aviv: Springer, 2022: 657-675.
|
| 9 |
PANG Y, WANG W, TAY F E H, et al. Masked autoencoders for point cloud self-supervised learning [C]// European Conference on Computer Vision . Tel Aviv: Springer, 2022: 604-621.
|
| 10 |
YU X, TANG L, RAO Y, et al. Point-bert: pre-training 3d point cloud transformers with masked point modeling [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Oreans: IEEE, 2022: 19313-19322.
|
| 11 |
CHANG A X, FUNKHOUSER T, GUIBAS L, et al. Shapenet: an information-rich 3d model repository [EB/OL]. (2015-12-09) [2024-05-25]. http://arxiv.org/abs/1512.03012.
|
| 12 |
TANG Y, ZHANG R, GUO Z, et al. Point-PEFT: parameter-efficient fine-tuning for 3D pre-trained models [C]// Proceedings of the AAAI Conference on Artificial Intelligence . Vancouver: AAAI, 2024: 5171-5179.
|
| 13 |
ZHANG C, WAN H, SHEN X, et al. Patchformer: an efficient point transformer with patch attention [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 11799-11808.
|
| 14 |
SUN J, QING C, TAN J, et al. Superpoint transformer for 3d scene instance segmentation [C]// Proceedings of the AAAI Conference on Artificial Intelligence . Washington DC: AAAI, 2023: 2393-2401.
|
| 15 |
DEVLIN J, CHANG M W, LEE K, et al. Bert: pre-training of deep bidirectional transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies . Minneapolis: [s. n.], 2019: 4171–4186.
|
| 16 |
STICKLAND A C, MURRAY I. Bert and pals: projected attention layers for efficient adaptation in multi-task learning [C]// International Conference on Machine Learning . Long Beach: ACM, 2019: 5986-5995.
|
| 17 |
CHEN Z, DUAN Y, WANG W, et al. Vision transformer adapter for dense predictions [EB/OL]. (2023-02-13) [2024-05-25]. https://arxiv.org/abs/2205.08534.
|
| 18 |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems . Red Hook: Curran Associates Inc. , 2017: 6000–6010.
|
| 19 |
WANG W, XIE E, LI X, et al Pvt v2: improved baselines with pyramid vision transformer[J]. Computational Visual Media, 2022, 8 (3): 415- 424
doi: 10.1007/s41095-022-0274-8
|
| 20 |
WU X, TIAN Z, WEN X, et al. Towards large-scale 3d representation learning with multi-dataset point prompt training [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2024: 19551-19562.
|
| 21 |
ZHANG R, WANG L, WANG Y, et al. Starting from non-parametric networks for 3d point cloud analysis [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Vancouver: IEEE, 2023: 5344-5353.
|
| 22 |
MA X, QIN C, YOU H, et al. Rethinking network design and local geometry in point cloud: a simple residual MLP framework [EB/OL]. (2022-11-29) [2024-05-25]. https://arxiv.org/abs/2202.07123.
|
| 23 |
BEHLEY J, GARBADE M, MILIOTO A, et al. Semantickitti: a dataset for semantic scene understanding of lidar sequences [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 9297-9307.
|
| 24 |
ARMENI I, SENER O, ZAMIR A R, et al. 3d semantic parsing of large-scale indoor spaces [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 1534-1543.
|
| 25 |
HAN X F, HE Z Y, CHEN J, et al 3CROSSNet: cross-level cross-scale cross-attention network for point cloud representation[J]. IEEE Robotics and Automation Letters, 2022, 7 (2): 3718- 3725
doi: 10.1109/LRA.2022.3147907
|
| 26 |
QI C R, YI L, SU H, et al. Pointnet++: deep hierarchical feature learning on point sets in a metric space [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems . Red Hook: Curran Associates Inc. , 2017: 5105–5114.
|
| 27 |
YAN X, ZHENG C, LI Z, et al. Pointasnl: robust point clouds processing using nonlocal neural networks with adaptive sampling [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 5589-5598.
|
| 28 |
YANG X, JIN M, HE W, et al. PointCAT: cross-attention Transformer for point cloud [EB/OL]. (2023-04-06) [2024-05-25]. https://arxiv.org/abs/2304.03012.
|
| 29 |
YANG J, ZHANG Q, NI B, et al. Modeling point clouds with self-attention and gumbel subset sampling [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 3323-3332.
|
| 30 |
SU H, JAMPANI V, SUN D, et al. Splatnet: sparse lattice networks for point cloud processing [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake: IEEE, 2018: 2530-2539.
|
| 31 |
TATARCHENKO M, PARK J, KOLTUN V, et al. Tangent convolutions for dense prediction in 3d [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake: IEEE, 2018: 3887-3896.
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|