[1]
CHOE J, PARK C, RAMEAU F, et al. Pointmixer: Mlp-mixer for point cloud understanding [C]// European Conference on Computer Vision . Israel: Springer, 2022: 620-640.
[本文引用: 1]
[2]
ZHAO H, JIANG L, FU C W, et al. Pointweb: enhancing local neighborhood features for point cloud processing [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 5565-5573.
[本文引用: 2]
[3]
QI Z, DONG R, FAN G, et al. Contrast with reconstruct: contrastive 3d representation learning guided by generative pretraining [C]// International Conference on Machine Learning . Honolulu: PMLR, 2023: 28223-28243.
[本文引用: 5]
[4]
YANG Y Q, GUO Y X, XIONG J Y, et al. Swin3D: a pretrained Transformer backbone for 3D indoor scene understanding [EB/OL]. (2023-08-26) [2024-05-25]. https://arxiv.org/abs/2304.06906.
[本文引用: 4]
[5]
ZHAO H, JIANG L, JIA J, et al. Point transformer [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 16259-16268.
[本文引用: 4]
[7]
DONG R, QI Z, ZHANG L, et al. Autoencoders as cross-modal teachers: can pretrained 2D image Transformers help 3D representation learning? [EB/OL]. (2023-02-02) [2024-05-25]. https://arxiv.org/abs/2212.08320.
[本文引用: 7]
[8]
LIU H, CAI M, LEE Y J. Masked discrimination for self-supervised learning on point clouds [C]// European Conference on Computer Vision . Tel Aviv: Springer, 2022: 657-675.
[本文引用: 5]
[9]
PANG Y, WANG W, TAY F E H, et al. Masked autoencoders for point cloud self-supervised learning [C]// European Conference on Computer Vision . Tel Aviv: Springer, 2022: 604-621.
[本文引用: 5]
[10]
YU X, TANG L, RAO Y, et al. Point-bert: pre-training 3d point cloud transformers with masked point modeling [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Oreans: IEEE, 2022: 19313-19322.
[本文引用: 12]
[11]
CHANG A X, FUNKHOUSER T, GUIBAS L, et al. Shapenet: an information-rich 3d model repository [EB/OL]. (2015-12-09) [2024-05-25]. http://arxiv.org/abs/1512.03012.
[本文引用: 2]
[12]
TANG Y, ZHANG R, GUO Z, et al. Point-PEFT: parameter-efficient fine-tuning for 3D pre-trained models [C]// Proceedings of the AAAI Conference on Artificial Intelligence . Vancouver: AAAI, 2024: 5171-5179.
[本文引用: 2]
[13]
ZHANG C, WAN H, SHEN X, et al. Patchformer: an efficient point transformer with patch attention [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 11799-11808.
[本文引用: 4]
[14]
SUN J, QING C, TAN J, et al. Superpoint transformer for 3d scene instance segmentation [C]// Proceedings of the AAAI Conference on Artificial Intelligence . Washington DC: AAAI, 2023: 2393-2401.
[本文引用: 3]
[15]
DEVLIN J, CHANG M W, LEE K, et al. Bert: pre-training of deep bidirectional transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies . Minneapolis: [s. n.], 2019: 4171–4186.
[本文引用: 1]
[16]
STICKLAND A C, MURRAY I. Bert and pals: projected attention layers for efficient adaptation in multi-task learning [C]// International Conference on Machine Learning . Long Beach: ACM, 2019: 5986-5995.
[本文引用: 1]
[17]
CHEN Z, DUAN Y, WANG W, et al. Vision transformer adapter for dense predictions [EB/OL]. (2023-02-13) [2024-05-25]. https://arxiv.org/abs/2205.08534.
[本文引用: 2]
[18]
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems . Red Hook: Curran Associates Inc. , 2017: 6000–6010.
[本文引用: 2]
[19]
WANG W, XIE E, LI X, et al Pvt v2: improved baselines with pyramid vision transformer
[J]. Computational Visual Media , 2022 , 8 (3 ): 415 - 424
DOI:10.1007/s41095-022-0274-8
[本文引用: 1]
[20]
WU X, TIAN Z, WEN X, et al. Towards large-scale 3d representation learning with multi-dataset point prompt training [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2024: 19551-19562.
[本文引用: 1]
[21]
ZHANG R, WANG L, WANG Y, et al. Starting from non-parametric networks for 3d point cloud analysis [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Vancouver: IEEE, 2023: 5344-5353.
[本文引用: 1]
[22]
MA X, QIN C, YOU H, et al. Rethinking network design and local geometry in point cloud: a simple residual MLP framework [EB/OL]. (2022-11-29) [2024-05-25]. https://arxiv.org/abs/2202.07123.
[本文引用: 2]
[23]
BEHLEY J, GARBADE M, MILIOTO A, et al. Semantickitti: a dataset for semantic scene understanding of lidar sequences [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 9297-9307.
[本文引用: 4]
[24]
ARMENI I, SENER O, ZAMIR A R, et al. 3d semantic parsing of large-scale indoor spaces [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 1534-1543.
[本文引用: 3]
[25]
HAN X F, HE Z Y, CHEN J, et al 3CROSSNet: cross-level cross-scale cross-attention network for point cloud representation
[J]. IEEE Robotics and Automation Letters , 2022 , 7 (2 ): 3718 - 3725
DOI:10.1109/LRA.2022.3147907
[本文引用: 1]
[26]
QI C R, YI L, SU H, et al. Pointnet++: deep hierarchical feature learning on point sets in a metric space [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems . Red Hook: Curran Associates Inc. , 2017: 5105–5114.
[本文引用: 2]
[27]
YAN X, ZHENG C, LI Z, et al. Pointasnl: robust point clouds processing using nonlocal neural networks with adaptive sampling [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 5589-5598.
[本文引用: 3]
[28]
YANG X, JIN M, HE W, et al. PointCAT: cross-attention Transformer for point cloud [EB/OL]. (2023-04-06) [2024-05-25]. https://arxiv.org/abs/2304.03012.
[本文引用: 4]
[29]
YANG J, ZHANG Q, NI B, et al. Modeling point clouds with self-attention and gumbel subset sampling [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 3323-3332.
[本文引用: 1]
[30]
SU H, JAMPANI V, SUN D, et al. Splatnet: sparse lattice networks for point cloud processing [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake: IEEE, 2018: 2530-2539.
[本文引用: 1]
[31]
TATARCHENKO M, PARK J, KOLTUN V, et al. Tangent convolutions for dense prediction in 3d [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake: IEEE, 2018: 3887-3896.
[本文引用: 1]
[32]
WU B, ZHOU X, ZHAO S, et al. Squeezesegv2: improved model structure and unsupervised domain adaptation for road-object segmentation from a lidar point cloud [C]// IEEE International Conference on Robotics and Automation . Montreal: IEEE, 2019: 4376-4382.
[本文引用: 1]
1
... 点云密集预测任务通过为每个点预测相应的语义标签或属性,帮助自动驾驶和机器人完成对复杂场景的理解,是点云数据处理的关键前置任务. 相较于点云深度学习网络[1 -2 ] ,Transformer凭借其优秀的集合处理能力和点云数据适应性,在捕捉点云数据的局部特征和全局关系方面表现出色,在点云分类[3 ] 、语义分割[4 ] 任务中展现了卓越的性能. ...
2
... 点云密集预测任务通过为每个点预测相应的语义标签或属性,帮助自动驾驶和机器人完成对复杂场景的理解,是点云数据处理的关键前置任务. 相较于点云深度学习网络[1 -2 ] ,Transformer凭借其优秀的集合处理能力和点云数据适应性,在捕捉点云数据的局部特征和全局关系方面表现出色,在点云分类[3 ] 、语义分割[4 ] 任务中展现了卓越的性能. ...
... Semantic segmentation result of S3DIS dataset (area 5)
Tab.2 方法 mAcc/ mIoU/ mIoUcls /% 天花板 地板 墙壁 横梁 柱子 窗户 门 桌子 椅子 沙发 书柜 黑板 杂物 SPG[27 ] 66.5 58.0 89.4 96.9 78.1 0.0 42.8 48.9 61.6 84.7 75.4 69.8 52.6 2.1 52.2 PointWeb[2 ] 66.6 60.3 92.0 98.5 79.4 0.0 21.1 59.7 34.8 76.3 88.3 46.9 69.3 64.9 52.5 PAT[29 ] 70.8 60.1 93.0 98.5 72.3 1.0 41.5 85.1 38.2 57.7 83.6 48.1 67.0 61.3 33.6 PT[5 ] 76.5 70.4 94.0 98.5 86.3 0.0 38.0 63.4 74.3 89.1 82.4 74.3 80.2 76.0 59.3 PCT[6 ] 67.7 61.3 92.5 98.4 80.6 0.0 19.3 61.6 48.0 76.6 85.2 46.2 67.7 67.9 52.3 PatchF[13 ] — 67.3 91.8 98.7 86.2 0.0 34.1 48.9 62.4 81.6 89.8 47.2 74.9 74.4 58.6 PointCAT[28 ] 71.0 64.0 94.2 98.3 80.5 0.0 18.6 55.5 58.9 77.2 88.0 64.8 72.2 68.9 55.4 SPFormer[14 ] 77.3 68.9 91.5 98.2 81.4 0.0 23.3 65.3 40.0 75.5 87.7 59.5 67.8 65.6 49.4 Point-Bert[10 ] 75.7 63.5 91.3 92.3 73.1 0.0 33.9 65.6 60.4 76.5 82.7 86.8 64.0 41.7 43.0 PCT-Adapter 80.5 69.0 91.9 96.0 81.6 0.0 52.4 66.5 67.0 82.9 90.1 70.8 72.8 69.5 54.7
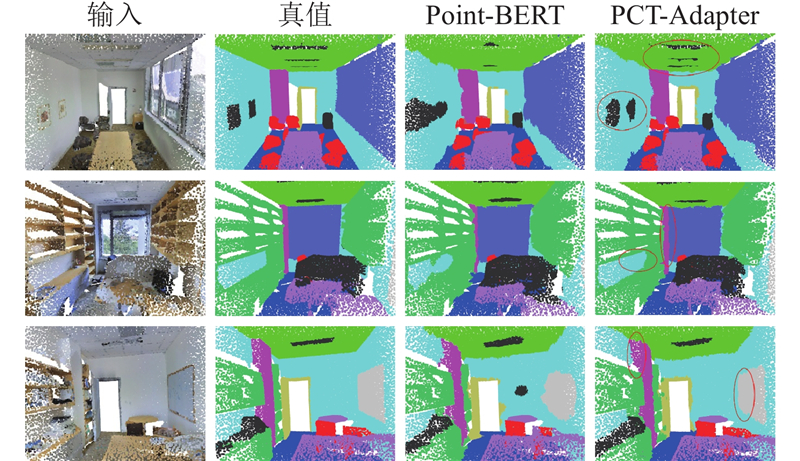
如图4 所示为PCT-Adapter与Point-Bert在区域5上的分割结果. PCT-Adapter在维持总体分割质量的同时,增强了细节的分割效果. 这些结果表明,PCT-Adapter有效地将标准Transformer扩展到下游任务,证明了设计的合理性. ...
5
... 点云密集预测任务通过为每个点预测相应的语义标签或属性,帮助自动驾驶和机器人完成对复杂场景的理解,是点云数据处理的关键前置任务. 相较于点云深度学习网络[1 -2 ] ,Transformer凭借其优秀的集合处理能力和点云数据适应性,在捕捉点云数据的局部特征和全局关系方面表现出色,在点云分类[3 ] 、语义分割[4 ] 任务中展现了卓越的性能. ...
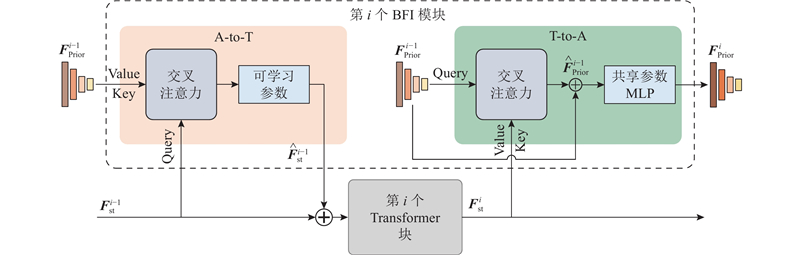
... 目前,主流的标准点云Transformer预训练模型,如Point-Bert[10 ] 、Point-MAE[9 ] 、ACT[7 ] 、ReCon[3 ] 等,虽然使用了不同的预训练策略来增强点云特征学习能力,但它们具有相同的点云Transformer主干网络和统一的预训练参数结构. PCT-Adapter中的Transformer主干属于通用结构,可以直接使用多种预训练策略的权重. 接下来阐述PCT-Adapter使用的标准Transformer模块. ...
... 为了证明PCT-Adapter在密集预测任务上具有跨模型通用性,比较多种预训练权重对PCT-Adapter适配效果的影响. 预训练模型包括Point-Bert[10 ] 、ReCon[3 ] 、ACT[7 ] 、Point-MAE[9 ] 和MaskPoint[8 ] . ...
... Quantitative comparison of loaded weights from various pretrained models
Tab.6 方法 预训练模型权重 mIoU/% mAcc/% 标准Transformer — 62.9 72.1 ACT[7 ] 63.1 73.2 Point-MAE[9 ] 63.1 72.1 MaskPoint[8 ] 64.4 72.7 Point-Bert[10 ] 63.5 75.7 ReCon[3 ] 64.8 73.3 PCT-Adapter — 66.2 73.7 ACT[7 ] 66.9 75.5 Point-MAE[9 ] 68.9 76.5 MaskPoint[8 ] 68.2 75.9 Point-Bert[10 ] 69.0 80.5 ReCon[3 ] 67.4 74.7
4. 结 语 本文提出将点云通用标准 Transform-er主干适配至密集预测任务的PCT-Adapter框架. 在不改变标准Transformer架构的情况下,通过免预训练的特征提取模块和双向特征交互模块,增强了标准Transformer的特征表达能力. 此外,提出的PCT-Adapter具有跨模型通用性,能够加载各种预训练方法的权重. 在以分割为代表的密集预测任务上,PCT-Adapter的任务适配性能得到验证,有效缩小了标准Transformer与变体Transformer的性能差异,为标准Transformer作为点云领域的统一架构提供了可行性. ...
... [
3 ]
67.4 74.7 4. 结 语 本文提出将点云通用标准 Transform-er主干适配至密集预测任务的PCT-Adapter框架. 在不改变标准Transformer架构的情况下,通过免预训练的特征提取模块和双向特征交互模块,增强了标准Transformer的特征表达能力. 此外,提出的PCT-Adapter具有跨模型通用性,能够加载各种预训练方法的权重. 在以分割为代表的密集预测任务上,PCT-Adapter的任务适配性能得到验证,有效缩小了标准Transformer与变体Transformer的性能差异,为标准Transformer作为点云领域的统一架构提供了可行性. ...
4
... 点云密集预测任务通过为每个点预测相应的语义标签或属性,帮助自动驾驶和机器人完成对复杂场景的理解,是点云数据处理的关键前置任务. 相较于点云深度学习网络[1 -2 ] ,Transformer凭借其优秀的集合处理能力和点云数据适应性,在捕捉点云数据的局部特征和全局关系方面表现出色,在点云分类[3 ] 、语义分割[4 ] 任务中展现了卓越的性能. ...
... 将点云Transformer的研究概括为以下2个主要方向. 1)针对点云任务特性添加特定归纳偏置的变体Transformer[4 -6 , 13 ] . 2)保持归纳偏置最小化初衷的标准Transformer[7 -10 ] . ...
... Guo等[6 ] 在注意力机制的基础上增加邻域编码和偏移注意力归纳偏置结构,增强了网络的几何感知能力. Zhao等[5 ] 设计矢量自注意力模块,为Transformer模块引入位置编码. Yang等[4 ,13 ] 将注意力机制限制在局部区域,以降低计算复杂度. 这些方法为特定任务设计了独特的归纳偏置,因而在各自的任务中取得了较好的效果. 这些模型的通用性不及标准Transformer,且这种设计偏离了Transformer归纳偏置最小化的初衷. ...
... 相比于变体Transformer[4 , 6 , 14 ] ,标准点云Transformer能够通过多样的预训练策略,充分挖掘通用模型的特征表达能力. Yu等[10 ] 将Bert[15 ] 自监督模型迁移至点云领域,通过重建被随机遮蔽的局部区域,对比原始点云与输出点云之间的特征表示进行预训练,在分类与部件分割任务上表现了良好的性能. Liu等[8 ] 通过构建间接任务预训练标准Transformer模型,将模糊的掩码点重建任务转化为判别任务,学习到丰富的点云特征. Pang等[9 ] 对输入的点云块进行随机遮掩,从未被遮掩的点云块中学习高级的潜在特征,在掩码点重建任务中自监督预训练标准Transformer. Dong等[7 ] 使用来自图像或自然语言处理领域的 Transformer辅助点云Transformer预训练,展示了标准点云Transformer跨模态特征学习的能力. ...
4
... 点云Transformer研究的普遍思路是引入任务特定的归纳偏置结构,提升模型对几何结构的感知能力. 本文将引入归纳偏置的Transformer称为变体Transformer,具有代表性的模型有point Transformer[5 ] 、point cloud Transformer[6 ] . 虽然变体Transformer在密集预测任务中取得了优异的性能,但损失了通用性和多模态特征表达能力. 相比之下,标准 Transformer[7 -10 ] 具有易于部署、架构通用、训练方法丰富和支持多模态等优势. ...
... Guo等[6 ] 在注意力机制的基础上增加邻域编码和偏移注意力归纳偏置结构,增强了网络的几何感知能力. Zhao等[5 ] 设计矢量自注意力模块,为Transformer模块引入位置编码. Yang等[4 ,13 ] 将注意力机制限制在局部区域,以降低计算复杂度. 这些方法为特定任务设计了独特的归纳偏置,因而在各自的任务中取得了较好的效果. 这些模型的通用性不及标准Transformer,且这种设计偏离了Transformer归纳偏置最小化的初衷. ...
... Part segmentation result of ShapeNetPart dataset
Tab.1 模型 mIoUcls /% mIoUins /% PointNet++[26 ] 81.9 85.1 PointASNL[27 ] — 86.1 PCT[6 ] — 86.4 PointTransformer[5 ] 83.7 86.6 PointCAT[28 ] 84.4 86.0 Point-Bert[10 ] 84.1 85.6 PCT-Adapter 84.5 86.0
PCT-Adapter有效缩小了标准Transformer与变体Transformer[6 , 28 ] 之间的性能差距. 这一结果表明,PCT-Adapter有助于解决标准Transformer的结构局限性问题. 随着点云预训练方法与数据集的发展,当标准Transformer预训练模型的特征提取能力被进一步开发时,PCT-Adapter的性能将优于变体Transformer. ...
... Semantic segmentation result of S3DIS dataset (area 5)
Tab.2 方法 mAcc/ mIoU/ mIoUcls /% 天花板 地板 墙壁 横梁 柱子 窗户 门 桌子 椅子 沙发 书柜 黑板 杂物 SPG[27 ] 66.5 58.0 89.4 96.9 78.1 0.0 42.8 48.9 61.6 84.7 75.4 69.8 52.6 2.1 52.2 PointWeb[2 ] 66.6 60.3 92.0 98.5 79.4 0.0 21.1 59.7 34.8 76.3 88.3 46.9 69.3 64.9 52.5 PAT[29 ] 70.8 60.1 93.0 98.5 72.3 1.0 41.5 85.1 38.2 57.7 83.6 48.1 67.0 61.3 33.6 PT[5 ] 76.5 70.4 94.0 98.5 86.3 0.0 38.0 63.4 74.3 89.1 82.4 74.3 80.2 76.0 59.3 PCT[6 ] 67.7 61.3 92.5 98.4 80.6 0.0 19.3 61.6 48.0 76.6 85.2 46.2 67.7 67.9 52.3 PatchF[13 ] — 67.3 91.8 98.7 86.2 0.0 34.1 48.9 62.4 81.6 89.8 47.2 74.9 74.4 58.6 PointCAT[28 ] 71.0 64.0 94.2 98.3 80.5 0.0 18.6 55.5 58.9 77.2 88.0 64.8 72.2 68.9 55.4 SPFormer[14 ] 77.3 68.9 91.5 98.2 81.4 0.0 23.3 65.3 40.0 75.5 87.7 59.5 67.8 65.6 49.4 Point-Bert[10 ] 75.7 63.5 91.3 92.3 73.1 0.0 33.9 65.6 60.4 76.5 82.7 86.8 64.0 41.7 43.0 PCT-Adapter 80.5 69.0 91.9 96.0 81.6 0.0 52.4 66.5 67.0 82.9 90.1 70.8 72.8 69.5 54.7
如图4 所示为PCT-Adapter与Point-Bert在区域5上的分割结果. PCT-Adapter在维持总体分割质量的同时,增强了细节的分割效果. 这些结果表明,PCT-Adapter有效地将标准Transformer扩展到下游任务,证明了设计的合理性. ...
Pct: point cloud transformer
8
2021
... 点云Transformer研究的普遍思路是引入任务特定的归纳偏置结构,提升模型对几何结构的感知能力. 本文将引入归纳偏置的Transformer称为变体Transformer,具有代表性的模型有point Transformer[5 ] 、point cloud Transformer[6 ] . 虽然变体Transformer在密集预测任务中取得了优异的性能,但损失了通用性和多模态特征表达能力. 相比之下,标准 Transformer[7 -10 ] 具有易于部署、架构通用、训练方法丰富和支持多模态等优势. ...
... 将点云Transformer的研究概括为以下2个主要方向. 1)针对点云任务特性添加特定归纳偏置的变体Transformer[4 -6 , 13 ] . 2)保持归纳偏置最小化初衷的标准Transformer[7 -10 ] . ...
... Guo等[6 ] 在注意力机制的基础上增加邻域编码和偏移注意力归纳偏置结构,增强了网络的几何感知能力. Zhao等[5 ] 设计矢量自注意力模块,为Transformer模块引入位置编码. Yang等[4 ,13 ] 将注意力机制限制在局部区域,以降低计算复杂度. 这些方法为特定任务设计了独特的归纳偏置,因而在各自的任务中取得了较好的效果. 这些模型的通用性不及标准Transformer,且这种设计偏离了Transformer归纳偏置最小化的初衷. ...
... 相比于变体Transformer[4 , 6 , 14 ] ,标准点云Transformer能够通过多样的预训练策略,充分挖掘通用模型的特征表达能力. Yu等[10 ] 将Bert[15 ] 自监督模型迁移至点云领域,通过重建被随机遮蔽的局部区域,对比原始点云与输出点云之间的特征表示进行预训练,在分类与部件分割任务上表现了良好的性能. Liu等[8 ] 通过构建间接任务预训练标准Transformer模型,将模糊的掩码点重建任务转化为判别任务,学习到丰富的点云特征. Pang等[9 ] 对输入的点云块进行随机遮掩,从未被遮掩的点云块中学习高级的潜在特征,在掩码点重建任务中自监督预训练标准Transformer. Dong等[7 ] 使用来自图像或自然语言处理领域的 Transformer辅助点云Transformer预训练,展示了标准点云Transformer跨模态特征学习的能力. ...
... Part segmentation result of ShapeNetPart dataset
Tab.1 模型 mIoUcls /% mIoUins /% PointNet++[26 ] 81.9 85.1 PointASNL[27 ] — 86.1 PCT[6 ] — 86.4 PointTransformer[5 ] 83.7 86.6 PointCAT[28 ] 84.4 86.0 Point-Bert[10 ] 84.1 85.6 PCT-Adapter 84.5 86.0
PCT-Adapter有效缩小了标准Transformer与变体Transformer[6 , 28 ] 之间的性能差距. 这一结果表明,PCT-Adapter有助于解决标准Transformer的结构局限性问题. 随着点云预训练方法与数据集的发展,当标准Transformer预训练模型的特征提取能力被进一步开发时,PCT-Adapter的性能将优于变体Transformer. ...
... PCT-Adapter有效缩小了标准Transformer与变体Transformer[6 , 28 ] 之间的性能差距. 这一结果表明,PCT-Adapter有助于解决标准Transformer的结构局限性问题. 随着点云预训练方法与数据集的发展,当标准Transformer预训练模型的特征提取能力被进一步开发时,PCT-Adapter的性能将优于变体Transformer. ...
... 如表2 所示,Point-Bert和PCT-Adapter均加载Point-Bert预训练权重,在真实室内数据集S3DIS上进行语义分割测试. 相较于标准Transformer,PCT-Adapter分别提高了4.8% 的mAcc与和5.5% 的mIoU. PCT-Adapter超过部分变体Transformer[6 , 13 -14 , 28 ] 的性能. ...
... Semantic segmentation result of S3DIS dataset (area 5)
Tab.2 方法 mAcc/ mIoU/ mIoUcls /% 天花板 地板 墙壁 横梁 柱子 窗户 门 桌子 椅子 沙发 书柜 黑板 杂物 SPG[27 ] 66.5 58.0 89.4 96.9 78.1 0.0 42.8 48.9 61.6 84.7 75.4 69.8 52.6 2.1 52.2 PointWeb[2 ] 66.6 60.3 92.0 98.5 79.4 0.0 21.1 59.7 34.8 76.3 88.3 46.9 69.3 64.9 52.5 PAT[29 ] 70.8 60.1 93.0 98.5 72.3 1.0 41.5 85.1 38.2 57.7 83.6 48.1 67.0 61.3 33.6 PT[5 ] 76.5 70.4 94.0 98.5 86.3 0.0 38.0 63.4 74.3 89.1 82.4 74.3 80.2 76.0 59.3 PCT[6 ] 67.7 61.3 92.5 98.4 80.6 0.0 19.3 61.6 48.0 76.6 85.2 46.2 67.7 67.9 52.3 PatchF[13 ] — 67.3 91.8 98.7 86.2 0.0 34.1 48.9 62.4 81.6 89.8 47.2 74.9 74.4 58.6 PointCAT[28 ] 71.0 64.0 94.2 98.3 80.5 0.0 18.6 55.5 58.9 77.2 88.0 64.8 72.2 68.9 55.4 SPFormer[14 ] 77.3 68.9 91.5 98.2 81.4 0.0 23.3 65.3 40.0 75.5 87.7 59.5 67.8 65.6 49.4 Point-Bert[10 ] 75.7 63.5 91.3 92.3 73.1 0.0 33.9 65.6 60.4 76.5 82.7 86.8 64.0 41.7 43.0 PCT-Adapter 80.5 69.0 91.9 96.0 81.6 0.0 52.4 66.5 67.0 82.9 90.1 70.8 72.8 69.5 54.7
如图4 所示为PCT-Adapter与Point-Bert在区域5上的分割结果. PCT-Adapter在维持总体分割质量的同时,增强了细节的分割效果. 这些结果表明,PCT-Adapter有效地将标准Transformer扩展到下游任务,证明了设计的合理性. ...
7
... 点云Transformer研究的普遍思路是引入任务特定的归纳偏置结构,提升模型对几何结构的感知能力. 本文将引入归纳偏置的Transformer称为变体Transformer,具有代表性的模型有point Transformer[5 ] 、point cloud Transformer[6 ] . 虽然变体Transformer在密集预测任务中取得了优异的性能,但损失了通用性和多模态特征表达能力. 相比之下,标准 Transformer[7 -10 ] 具有易于部署、架构通用、训练方法丰富和支持多模态等优势. ...
... 将点云Transformer的研究概括为以下2个主要方向. 1)针对点云任务特性添加特定归纳偏置的变体Transformer[4 -6 , 13 ] . 2)保持归纳偏置最小化初衷的标准Transformer[7 -10 ] . ...
... 相比于变体Transformer[4 , 6 , 14 ] ,标准点云Transformer能够通过多样的预训练策略,充分挖掘通用模型的特征表达能力. Yu等[10 ] 将Bert[15 ] 自监督模型迁移至点云领域,通过重建被随机遮蔽的局部区域,对比原始点云与输出点云之间的特征表示进行预训练,在分类与部件分割任务上表现了良好的性能. Liu等[8 ] 通过构建间接任务预训练标准Transformer模型,将模糊的掩码点重建任务转化为判别任务,学习到丰富的点云特征. Pang等[9 ] 对输入的点云块进行随机遮掩,从未被遮掩的点云块中学习高级的潜在特征,在掩码点重建任务中自监督预训练标准Transformer. Dong等[7 ] 使用来自图像或自然语言处理领域的 Transformer辅助点云Transformer预训练,展示了标准点云Transformer跨模态特征学习的能力. ...
... 目前,主流的标准点云Transformer预训练模型,如Point-Bert[10 ] 、Point-MAE[9 ] 、ACT[7 ] 、ReCon[3 ] 等,虽然使用了不同的预训练策略来增强点云特征学习能力,但它们具有相同的点云Transformer主干网络和统一的预训练参数结构. PCT-Adapter中的Transformer主干属于通用结构,可以直接使用多种预训练策略的权重. 接下来阐述PCT-Adapter使用的标准Transformer模块. ...
... 为了证明PCT-Adapter在密集预测任务上具有跨模型通用性,比较多种预训练权重对PCT-Adapter适配效果的影响. 预训练模型包括Point-Bert[10 ] 、ReCon[3 ] 、ACT[7 ] 、Point-MAE[9 ] 和MaskPoint[8 ] . ...
... Quantitative comparison of loaded weights from various pretrained models
Tab.6 方法 预训练模型权重 mIoU/% mAcc/% 标准Transformer — 62.9 72.1 ACT[7 ] 63.1 73.2 Point-MAE[9 ] 63.1 72.1 MaskPoint[8 ] 64.4 72.7 Point-Bert[10 ] 63.5 75.7 ReCon[3 ] 64.8 73.3 PCT-Adapter — 66.2 73.7 ACT[7 ] 66.9 75.5 Point-MAE[9 ] 68.9 76.5 MaskPoint[8 ] 68.2 75.9 Point-Bert[10 ] 69.0 80.5 ReCon[3 ] 67.4 74.7
4. 结 语 本文提出将点云通用标准 Transform-er主干适配至密集预测任务的PCT-Adapter框架. 在不改变标准Transformer架构的情况下,通过免预训练的特征提取模块和双向特征交互模块,增强了标准Transformer的特征表达能力. 此外,提出的PCT-Adapter具有跨模型通用性,能够加载各种预训练方法的权重. 在以分割为代表的密集预测任务上,PCT-Adapter的任务适配性能得到验证,有效缩小了标准Transformer与变体Transformer的性能差异,为标准Transformer作为点云领域的统一架构提供了可行性. ...
... [
7 ]
66.9 75.5 Point-MAE[9 ] 68.9 76.5 MaskPoint[8 ] 68.2 75.9 Point-Bert[10 ] 69.0 80.5 ReCon[3 ] 67.4 74.7 4. 结 语 本文提出将点云通用标准 Transform-er主干适配至密集预测任务的PCT-Adapter框架. 在不改变标准Transformer架构的情况下,通过免预训练的特征提取模块和双向特征交互模块,增强了标准Transformer的特征表达能力. 此外,提出的PCT-Adapter具有跨模型通用性,能够加载各种预训练方法的权重. 在以分割为代表的密集预测任务上,PCT-Adapter的任务适配性能得到验证,有效缩小了标准Transformer与变体Transformer的性能差异,为标准Transformer作为点云领域的统一架构提供了可行性. ...
5
... 标准Transformer存在以下明显的缺陷. 1)缺乏归纳偏置,对输入数据没有结构假设,需要大量数据才能学习通用特征表示,而基于ShapeNetPart数据集[11 ] 的预训练模型[8 -10 ] 泛化能力有限. 2)单一尺度设计难以捕获多尺度局部上下文信息,在包含不同尺度目标的密集预测任务中表现不佳. 3)原始的自注意力机制限制了标准Transformer在密集预测任务上的性能,尽管微调方法[12 ] 在点云分类和部件分割任务中表现良好,但在复杂三维场景分割方面的性能有待提升. ...
... 相比于变体Transformer[4 , 6 , 14 ] ,标准点云Transformer能够通过多样的预训练策略,充分挖掘通用模型的特征表达能力. Yu等[10 ] 将Bert[15 ] 自监督模型迁移至点云领域,通过重建被随机遮蔽的局部区域,对比原始点云与输出点云之间的特征表示进行预训练,在分类与部件分割任务上表现了良好的性能. Liu等[8 ] 通过构建间接任务预训练标准Transformer模型,将模糊的掩码点重建任务转化为判别任务,学习到丰富的点云特征. Pang等[9 ] 对输入的点云块进行随机遮掩,从未被遮掩的点云块中学习高级的潜在特征,在掩码点重建任务中自监督预训练标准Transformer. Dong等[7 ] 使用来自图像或自然语言处理领域的 Transformer辅助点云Transformer预训练,展示了标准点云Transformer跨模态特征学习的能力. ...
... 为了证明PCT-Adapter在密集预测任务上具有跨模型通用性,比较多种预训练权重对PCT-Adapter适配效果的影响. 预训练模型包括Point-Bert[10 ] 、ReCon[3 ] 、ACT[7 ] 、Point-MAE[9 ] 和MaskPoint[8 ] . ...
... Quantitative comparison of loaded weights from various pretrained models
Tab.6 方法 预训练模型权重 mIoU/% mAcc/% 标准Transformer — 62.9 72.1 ACT[7 ] 63.1 73.2 Point-MAE[9 ] 63.1 72.1 MaskPoint[8 ] 64.4 72.7 Point-Bert[10 ] 63.5 75.7 ReCon[3 ] 64.8 73.3 PCT-Adapter — 66.2 73.7 ACT[7 ] 66.9 75.5 Point-MAE[9 ] 68.9 76.5 MaskPoint[8 ] 68.2 75.9 Point-Bert[10 ] 69.0 80.5 ReCon[3 ] 67.4 74.7
4. 结 语 本文提出将点云通用标准 Transform-er主干适配至密集预测任务的PCT-Adapter框架. 在不改变标准Transformer架构的情况下,通过免预训练的特征提取模块和双向特征交互模块,增强了标准Transformer的特征表达能力. 此外,提出的PCT-Adapter具有跨模型通用性,能够加载各种预训练方法的权重. 在以分割为代表的密集预测任务上,PCT-Adapter的任务适配性能得到验证,有效缩小了标准Transformer与变体Transformer的性能差异,为标准Transformer作为点云领域的统一架构提供了可行性. ...
... [
8 ]
68.2 75.9 Point-Bert[10 ] 69.0 80.5 ReCon[3 ] 67.4 74.7 4. 结 语 本文提出将点云通用标准 Transform-er主干适配至密集预测任务的PCT-Adapter框架. 在不改变标准Transformer架构的情况下,通过免预训练的特征提取模块和双向特征交互模块,增强了标准Transformer的特征表达能力. 此外,提出的PCT-Adapter具有跨模型通用性,能够加载各种预训练方法的权重. 在以分割为代表的密集预测任务上,PCT-Adapter的任务适配性能得到验证,有效缩小了标准Transformer与变体Transformer的性能差异,为标准Transformer作为点云领域的统一架构提供了可行性. ...
5
... 相比于变体Transformer[4 , 6 , 14 ] ,标准点云Transformer能够通过多样的预训练策略,充分挖掘通用模型的特征表达能力. Yu等[10 ] 将Bert[15 ] 自监督模型迁移至点云领域,通过重建被随机遮蔽的局部区域,对比原始点云与输出点云之间的特征表示进行预训练,在分类与部件分割任务上表现了良好的性能. Liu等[8 ] 通过构建间接任务预训练标准Transformer模型,将模糊的掩码点重建任务转化为判别任务,学习到丰富的点云特征. Pang等[9 ] 对输入的点云块进行随机遮掩,从未被遮掩的点云块中学习高级的潜在特征,在掩码点重建任务中自监督预训练标准Transformer. Dong等[7 ] 使用来自图像或自然语言处理领域的 Transformer辅助点云Transformer预训练,展示了标准点云Transformer跨模态特征学习的能力. ...
... 目前,主流的标准点云Transformer预训练模型,如Point-Bert[10 ] 、Point-MAE[9 ] 、ACT[7 ] 、ReCon[3 ] 等,虽然使用了不同的预训练策略来增强点云特征学习能力,但它们具有相同的点云Transformer主干网络和统一的预训练参数结构. PCT-Adapter中的Transformer主干属于通用结构,可以直接使用多种预训练策略的权重. 接下来阐述PCT-Adapter使用的标准Transformer模块. ...
... 为了证明PCT-Adapter在密集预测任务上具有跨模型通用性,比较多种预训练权重对PCT-Adapter适配效果的影响. 预训练模型包括Point-Bert[10 ] 、ReCon[3 ] 、ACT[7 ] 、Point-MAE[9 ] 和MaskPoint[8 ] . ...
... Quantitative comparison of loaded weights from various pretrained models
Tab.6 方法 预训练模型权重 mIoU/% mAcc/% 标准Transformer — 62.9 72.1 ACT[7 ] 63.1 73.2 Point-MAE[9 ] 63.1 72.1 MaskPoint[8 ] 64.4 72.7 Point-Bert[10 ] 63.5 75.7 ReCon[3 ] 64.8 73.3 PCT-Adapter — 66.2 73.7 ACT[7 ] 66.9 75.5 Point-MAE[9 ] 68.9 76.5 MaskPoint[8 ] 68.2 75.9 Point-Bert[10 ] 69.0 80.5 ReCon[3 ] 67.4 74.7
4. 结 语 本文提出将点云通用标准 Transform-er主干适配至密集预测任务的PCT-Adapter框架. 在不改变标准Transformer架构的情况下,通过免预训练的特征提取模块和双向特征交互模块,增强了标准Transformer的特征表达能力. 此外,提出的PCT-Adapter具有跨模型通用性,能够加载各种预训练方法的权重. 在以分割为代表的密集预测任务上,PCT-Adapter的任务适配性能得到验证,有效缩小了标准Transformer与变体Transformer的性能差异,为标准Transformer作为点云领域的统一架构提供了可行性. ...
... [
9 ]
68.9 76.5 MaskPoint[8 ] 68.2 75.9 Point-Bert[10 ] 69.0 80.5 ReCon[3 ] 67.4 74.7 4. 结 语 本文提出将点云通用标准 Transform-er主干适配至密集预测任务的PCT-Adapter框架. 在不改变标准Transformer架构的情况下,通过免预训练的特征提取模块和双向特征交互模块,增强了标准Transformer的特征表达能力. 此外,提出的PCT-Adapter具有跨模型通用性,能够加载各种预训练方法的权重. 在以分割为代表的密集预测任务上,PCT-Adapter的任务适配性能得到验证,有效缩小了标准Transformer与变体Transformer的性能差异,为标准Transformer作为点云领域的统一架构提供了可行性. ...
12
... 点云Transformer研究的普遍思路是引入任务特定的归纳偏置结构,提升模型对几何结构的感知能力. 本文将引入归纳偏置的Transformer称为变体Transformer,具有代表性的模型有point Transformer[5 ] 、point cloud Transformer[6 ] . 虽然变体Transformer在密集预测任务中取得了优异的性能,但损失了通用性和多模态特征表达能力. 相比之下,标准 Transformer[7 -10 ] 具有易于部署、架构通用、训练方法丰富和支持多模态等优势. ...
... 标准Transformer存在以下明显的缺陷. 1)缺乏归纳偏置,对输入数据没有结构假设,需要大量数据才能学习通用特征表示,而基于ShapeNetPart数据集[11 ] 的预训练模型[8 -10 ] 泛化能力有限. 2)单一尺度设计难以捕获多尺度局部上下文信息,在包含不同尺度目标的密集预测任务中表现不佳. 3)原始的自注意力机制限制了标准Transformer在密集预测任务上的性能,尽管微调方法[12 ] 在点云分类和部件分割任务中表现良好,但在复杂三维场景分割方面的性能有待提升. ...
... 将点云Transformer的研究概括为以下2个主要方向. 1)针对点云任务特性添加特定归纳偏置的变体Transformer[4 -6 , 13 ] . 2)保持归纳偏置最小化初衷的标准Transformer[7 -10 ] . ...
... 相比于变体Transformer[4 , 6 , 14 ] ,标准点云Transformer能够通过多样的预训练策略,充分挖掘通用模型的特征表达能力. Yu等[10 ] 将Bert[15 ] 自监督模型迁移至点云领域,通过重建被随机遮蔽的局部区域,对比原始点云与输出点云之间的特征表示进行预训练,在分类与部件分割任务上表现了良好的性能. Liu等[8 ] 通过构建间接任务预训练标准Transformer模型,将模糊的掩码点重建任务转化为判别任务,学习到丰富的点云特征. Pang等[9 ] 对输入的点云块进行随机遮掩,从未被遮掩的点云块中学习高级的潜在特征,在掩码点重建任务中自监督预训练标准Transformer. Dong等[7 ] 使用来自图像或自然语言处理领域的 Transformer辅助点云Transformer预训练,展示了标准点云Transformer跨模态特征学习的能力. ...
... 目前,主流的标准点云Transformer预训练模型,如Point-Bert[10 ] 、Point-MAE[9 ] 、ACT[7 ] 、ReCon[3 ] 等,虽然使用了不同的预训练策略来增强点云特征学习能力,但它们具有相同的点云Transformer主干网络和统一的预训练参数结构. PCT-Adapter中的Transformer主干属于通用结构,可以直接使用多种预训练策略的权重. 接下来阐述PCT-Adapter使用的标准Transformer模块. ...
... 在模型设置上,严格遵循Point-Bert[10 ] ,随机选择2 048个点作为每个对象的输入,标准Transformer采样数目$ S $ $ K $ $ C = \left\{ n{\text{/}}8, n{\text{/}}16, n{\text{/32}} \right\} $
... Part segmentation result of ShapeNetPart dataset
Tab.1 模型 mIoUcls /% mIoUins /% PointNet++[26 ] 81.9 85.1 PointASNL[27 ] — 86.1 PCT[6 ] — 86.4 PointTransformer[5 ] 83.7 86.6 PointCAT[28 ] 84.4 86.0 Point-Bert[10 ] 84.1 85.6 PCT-Adapter 84.5 86.0
PCT-Adapter有效缩小了标准Transformer与变体Transformer[6 , 28 ] 之间的性能差距. 这一结果表明,PCT-Adapter有助于解决标准Transformer的结构局限性问题. 随着点云预训练方法与数据集的发展,当标准Transformer预训练模型的特征提取能力被进一步开发时,PCT-Adapter的性能将优于变体Transformer. ...
... Semantic segmentation result of S3DIS dataset (area 5)
Tab.2 方法 mAcc/ mIoU/ mIoUcls /% 天花板 地板 墙壁 横梁 柱子 窗户 门 桌子 椅子 沙发 书柜 黑板 杂物 SPG[27 ] 66.5 58.0 89.4 96.9 78.1 0.0 42.8 48.9 61.6 84.7 75.4 69.8 52.6 2.1 52.2 PointWeb[2 ] 66.6 60.3 92.0 98.5 79.4 0.0 21.1 59.7 34.8 76.3 88.3 46.9 69.3 64.9 52.5 PAT[29 ] 70.8 60.1 93.0 98.5 72.3 1.0 41.5 85.1 38.2 57.7 83.6 48.1 67.0 61.3 33.6 PT[5 ] 76.5 70.4 94.0 98.5 86.3 0.0 38.0 63.4 74.3 89.1 82.4 74.3 80.2 76.0 59.3 PCT[6 ] 67.7 61.3 92.5 98.4 80.6 0.0 19.3 61.6 48.0 76.6 85.2 46.2 67.7 67.9 52.3 PatchF[13 ] — 67.3 91.8 98.7 86.2 0.0 34.1 48.9 62.4 81.6 89.8 47.2 74.9 74.4 58.6 PointCAT[28 ] 71.0 64.0 94.2 98.3 80.5 0.0 18.6 55.5 58.9 77.2 88.0 64.8 72.2 68.9 55.4 SPFormer[14 ] 77.3 68.9 91.5 98.2 81.4 0.0 23.3 65.3 40.0 75.5 87.7 59.5 67.8 65.6 49.4 Point-Bert[10 ] 75.7 63.5 91.3 92.3 73.1 0.0 33.9 65.6 60.4 76.5 82.7 86.8 64.0 41.7 43.0 PCT-Adapter 80.5 69.0 91.9 96.0 81.6 0.0 52.4 66.5 67.0 82.9 90.1 70.8 72.8 69.5 54.7
如图4 所示为PCT-Adapter与Point-Bert在区域5上的分割结果. PCT-Adapter在维持总体分割质量的同时,增强了细节的分割效果. 这些结果表明,PCT-Adapter有效地将标准Transformer扩展到下游任务,证明了设计的合理性. ...
... Quantitative result of different methods on SemanticKITTI
Tab.3 方法 输入 mIoU/% PointNet++[26 ] 50 000个点 20.1 SPG[27 ] 17.4 SPLATNet[30 ] 18.4 TangentConv[31 ] 40.9 SqueezeSegV2[32 ] 64×2 048像素 39.7 DarkNet21Seg[23 ] 47.4 DarkNet53Seg[23 ] 49.9 Point-Bert[10 ] 20 000个点 44.5 PCT-Adapter 53.4
实验结果表明,相较于标准Transformer,PCT-Adapter的mIoU提高了8.9%. PCT-Adapter 在更复杂、多样化的真实室外场景中对室外Transformer性能的提升归因于Adapter对标准Transformer 结构的有益补充和高质量的特征交互, 这证明了PCT-Adapter的细粒度特征捕获能力和有效的辅助作用. ...
... 为了证明PCT-Adapter在密集预测任务上具有跨模型通用性,比较多种预训练权重对PCT-Adapter适配效果的影响. 预训练模型包括Point-Bert[10 ] 、ReCon[3 ] 、ACT[7 ] 、Point-MAE[9 ] 和MaskPoint[8 ] . ...
... Quantitative comparison of loaded weights from various pretrained models
Tab.6 方法 预训练模型权重 mIoU/% mAcc/% 标准Transformer — 62.9 72.1 ACT[7 ] 63.1 73.2 Point-MAE[9 ] 63.1 72.1 MaskPoint[8 ] 64.4 72.7 Point-Bert[10 ] 63.5 75.7 ReCon[3 ] 64.8 73.3 PCT-Adapter — 66.2 73.7 ACT[7 ] 66.9 75.5 Point-MAE[9 ] 68.9 76.5 MaskPoint[8 ] 68.2 75.9 Point-Bert[10 ] 69.0 80.5 ReCon[3 ] 67.4 74.7
4. 结 语 本文提出将点云通用标准 Transform-er主干适配至密集预测任务的PCT-Adapter框架. 在不改变标准Transformer架构的情况下,通过免预训练的特征提取模块和双向特征交互模块,增强了标准Transformer的特征表达能力. 此外,提出的PCT-Adapter具有跨模型通用性,能够加载各种预训练方法的权重. 在以分割为代表的密集预测任务上,PCT-Adapter的任务适配性能得到验证,有效缩小了标准Transformer与变体Transformer的性能差异,为标准Transformer作为点云领域的统一架构提供了可行性. ...
... [
10 ]
69.0 80.5 ReCon[3 ] 67.4 74.7 4. 结 语 本文提出将点云通用标准 Transform-er主干适配至密集预测任务的PCT-Adapter框架. 在不改变标准Transformer架构的情况下,通过免预训练的特征提取模块和双向特征交互模块,增强了标准Transformer的特征表达能力. 此外,提出的PCT-Adapter具有跨模型通用性,能够加载各种预训练方法的权重. 在以分割为代表的密集预测任务上,PCT-Adapter的任务适配性能得到验证,有效缩小了标准Transformer与变体Transformer的性能差异,为标准Transformer作为点云领域的统一架构提供了可行性. ...
2
... 标准Transformer存在以下明显的缺陷. 1)缺乏归纳偏置,对输入数据没有结构假设,需要大量数据才能学习通用特征表示,而基于ShapeNetPart数据集[11 ] 的预训练模型[8 -10 ] 泛化能力有限. 2)单一尺度设计难以捕获多尺度局部上下文信息,在包含不同尺度目标的密集预测任务中表现不佳. 3)原始的自注意力机制限制了标准Transformer在密集预测任务上的性能,尽管微调方法[12 ] 在点云分类和部件分割任务中表现良好,但在复杂三维场景分割方面的性能有待提升. ...
... ShapeNetPart[11 ] 数据集包含16 881个对象、16个类别,且拥有50个部分标签. 每个对象由2~6个部分组成. ...
2
... 标准Transformer存在以下明显的缺陷. 1)缺乏归纳偏置,对输入数据没有结构假设,需要大量数据才能学习通用特征表示,而基于ShapeNetPart数据集[11 ] 的预训练模型[8 -10 ] 泛化能力有限. 2)单一尺度设计难以捕获多尺度局部上下文信息,在包含不同尺度目标的密集预测任务中表现不佳. 3)原始的自注意力机制限制了标准Transformer在密集预测任务上的性能,尽管微调方法[12 ] 在点云分类和部件分割任务中表现良好,但在复杂三维场景分割方面的性能有待提升. ...
... Adapter也逐步应用于点云领域. Tang等[12 ] 设计点先验提示与几何感知适配器模块微调标准Transformer预训练模型,以较少的参数量在分类任务上取得了显著效果. 该方法在处理复杂场景的密集预测任务时表现不佳. Wu等[20 ] 将提示词适配器作为网络的关键模块,以提取数据集间的通用表示,实现多数据集的协同预训练,在下游任务中取得了优异的性能,但未深入探索将已有知识适配至特定任务的适配器思想. ...
4
... 将点云Transformer的研究概括为以下2个主要方向. 1)针对点云任务特性添加特定归纳偏置的变体Transformer[4 -6 , 13 ] . 2)保持归纳偏置最小化初衷的标准Transformer[7 -10 ] . ...
... Guo等[6 ] 在注意力机制的基础上增加邻域编码和偏移注意力归纳偏置结构,增强了网络的几何感知能力. Zhao等[5 ] 设计矢量自注意力模块,为Transformer模块引入位置编码. Yang等[4 ,13 ] 将注意力机制限制在局部区域,以降低计算复杂度. 这些方法为特定任务设计了独特的归纳偏置,因而在各自的任务中取得了较好的效果. 这些模型的通用性不及标准Transformer,且这种设计偏离了Transformer归纳偏置最小化的初衷. ...
... 如表2 所示,Point-Bert和PCT-Adapter均加载Point-Bert预训练权重,在真实室内数据集S3DIS上进行语义分割测试. 相较于标准Transformer,PCT-Adapter分别提高了4.8% 的mAcc与和5.5% 的mIoU. PCT-Adapter超过部分变体Transformer[6 , 13 -14 , 28 ] 的性能. ...
... Semantic segmentation result of S3DIS dataset (area 5)
Tab.2 方法 mAcc/ mIoU/ mIoUcls /% 天花板 地板 墙壁 横梁 柱子 窗户 门 桌子 椅子 沙发 书柜 黑板 杂物 SPG[27 ] 66.5 58.0 89.4 96.9 78.1 0.0 42.8 48.9 61.6 84.7 75.4 69.8 52.6 2.1 52.2 PointWeb[2 ] 66.6 60.3 92.0 98.5 79.4 0.0 21.1 59.7 34.8 76.3 88.3 46.9 69.3 64.9 52.5 PAT[29 ] 70.8 60.1 93.0 98.5 72.3 1.0 41.5 85.1 38.2 57.7 83.6 48.1 67.0 61.3 33.6 PT[5 ] 76.5 70.4 94.0 98.5 86.3 0.0 38.0 63.4 74.3 89.1 82.4 74.3 80.2 76.0 59.3 PCT[6 ] 67.7 61.3 92.5 98.4 80.6 0.0 19.3 61.6 48.0 76.6 85.2 46.2 67.7 67.9 52.3 PatchF[13 ] — 67.3 91.8 98.7 86.2 0.0 34.1 48.9 62.4 81.6 89.8 47.2 74.9 74.4 58.6 PointCAT[28 ] 71.0 64.0 94.2 98.3 80.5 0.0 18.6 55.5 58.9 77.2 88.0 64.8 72.2 68.9 55.4 SPFormer[14 ] 77.3 68.9 91.5 98.2 81.4 0.0 23.3 65.3 40.0 75.5 87.7 59.5 67.8 65.6 49.4 Point-Bert[10 ] 75.7 63.5 91.3 92.3 73.1 0.0 33.9 65.6 60.4 76.5 82.7 86.8 64.0 41.7 43.0 PCT-Adapter 80.5 69.0 91.9 96.0 81.6 0.0 52.4 66.5 67.0 82.9 90.1 70.8 72.8 69.5 54.7
如图4 所示为PCT-Adapter与Point-Bert在区域5上的分割结果. PCT-Adapter在维持总体分割质量的同时,增强了细节的分割效果. 这些结果表明,PCT-Adapter有效地将标准Transformer扩展到下游任务,证明了设计的合理性. ...
3
... 相比于变体Transformer[4 , 6 , 14 ] ,标准点云Transformer能够通过多样的预训练策略,充分挖掘通用模型的特征表达能力. Yu等[10 ] 将Bert[15 ] 自监督模型迁移至点云领域,通过重建被随机遮蔽的局部区域,对比原始点云与输出点云之间的特征表示进行预训练,在分类与部件分割任务上表现了良好的性能. Liu等[8 ] 通过构建间接任务预训练标准Transformer模型,将模糊的掩码点重建任务转化为判别任务,学习到丰富的点云特征. Pang等[9 ] 对输入的点云块进行随机遮掩,从未被遮掩的点云块中学习高级的潜在特征,在掩码点重建任务中自监督预训练标准Transformer. Dong等[7 ] 使用来自图像或自然语言处理领域的 Transformer辅助点云Transformer预训练,展示了标准点云Transformer跨模态特征学习的能力. ...
... 如表2 所示,Point-Bert和PCT-Adapter均加载Point-Bert预训练权重,在真实室内数据集S3DIS上进行语义分割测试. 相较于标准Transformer,PCT-Adapter分别提高了4.8% 的mAcc与和5.5% 的mIoU. PCT-Adapter超过部分变体Transformer[6 , 13 -14 , 28 ] 的性能. ...
... Semantic segmentation result of S3DIS dataset (area 5)
Tab.2 方法 mAcc/ mIoU/ mIoUcls /% 天花板 地板 墙壁 横梁 柱子 窗户 门 桌子 椅子 沙发 书柜 黑板 杂物 SPG[27 ] 66.5 58.0 89.4 96.9 78.1 0.0 42.8 48.9 61.6 84.7 75.4 69.8 52.6 2.1 52.2 PointWeb[2 ] 66.6 60.3 92.0 98.5 79.4 0.0 21.1 59.7 34.8 76.3 88.3 46.9 69.3 64.9 52.5 PAT[29 ] 70.8 60.1 93.0 98.5 72.3 1.0 41.5 85.1 38.2 57.7 83.6 48.1 67.0 61.3 33.6 PT[5 ] 76.5 70.4 94.0 98.5 86.3 0.0 38.0 63.4 74.3 89.1 82.4 74.3 80.2 76.0 59.3 PCT[6 ] 67.7 61.3 92.5 98.4 80.6 0.0 19.3 61.6 48.0 76.6 85.2 46.2 67.7 67.9 52.3 PatchF[13 ] — 67.3 91.8 98.7 86.2 0.0 34.1 48.9 62.4 81.6 89.8 47.2 74.9 74.4 58.6 PointCAT[28 ] 71.0 64.0 94.2 98.3 80.5 0.0 18.6 55.5 58.9 77.2 88.0 64.8 72.2 68.9 55.4 SPFormer[14 ] 77.3 68.9 91.5 98.2 81.4 0.0 23.3 65.3 40.0 75.5 87.7 59.5 67.8 65.6 49.4 Point-Bert[10 ] 75.7 63.5 91.3 92.3 73.1 0.0 33.9 65.6 60.4 76.5 82.7 86.8 64.0 41.7 43.0 PCT-Adapter 80.5 69.0 91.9 96.0 81.6 0.0 52.4 66.5 67.0 82.9 90.1 70.8 72.8 69.5 54.7
如图4 所示为PCT-Adapter与Point-Bert在区域5上的分割结果. PCT-Adapter在维持总体分割质量的同时,增强了细节的分割效果. 这些结果表明,PCT-Adapter有效地将标准Transformer扩展到下游任务,证明了设计的合理性. ...
1
... 相比于变体Transformer[4 , 6 , 14 ] ,标准点云Transformer能够通过多样的预训练策略,充分挖掘通用模型的特征表达能力. Yu等[10 ] 将Bert[15 ] 自监督模型迁移至点云领域,通过重建被随机遮蔽的局部区域,对比原始点云与输出点云之间的特征表示进行预训练,在分类与部件分割任务上表现了良好的性能. Liu等[8 ] 通过构建间接任务预训练标准Transformer模型,将模糊的掩码点重建任务转化为判别任务,学习到丰富的点云特征. Pang等[9 ] 对输入的点云块进行随机遮掩,从未被遮掩的点云块中学习高级的潜在特征,在掩码点重建任务中自监督预训练标准Transformer. Dong等[7 ] 使用来自图像或自然语言处理领域的 Transformer辅助点云Transformer预训练,展示了标准点云Transformer跨模态特征学习的能力. ...
1
... Adapter的概念源于工程中的模块化设计思想,通过对已有知识进行微调,适应特定的下游任务. 自然语言处理领域首次引入Adapter[16 ] ,用于将预训练模型快速迁移到下游任务. 在计算机视觉领域,Chen等[17 ] 结合Adapter与ViT[18 ] ,提出ViT-Adapter[17 ] 模型. ViT-Adapter在多项任务中超越了许多专门设计的视觉Transformer[19 ] . ...
2
... Adapter的概念源于工程中的模块化设计思想,通过对已有知识进行微调,适应特定的下游任务. 自然语言处理领域首次引入Adapter[16 ] ,用于将预训练模型快速迁移到下游任务. 在计算机视觉领域,Chen等[17 ] 结合Adapter与ViT[18 ] ,提出ViT-Adapter[17 ] 模型. ViT-Adapter在多项任务中超越了许多专门设计的视觉Transformer[19 ] . ...
... [17 ]模型. ViT-Adapter在多项任务中超越了许多专门设计的视觉Transformer[19 ] . ...
2
... Adapter的概念源于工程中的模块化设计思想,通过对已有知识进行微调,适应特定的下游任务. 自然语言处理领域首次引入Adapter[16 ] ,用于将预训练模型快速迁移到下游任务. 在计算机视觉领域,Chen等[17 ] 结合Adapter与ViT[18 ] ,提出ViT-Adapter[17 ] 模型. ViT-Adapter在多项任务中超越了许多专门设计的视觉Transformer[19 ] . ...
... 位置编码在Transformer结构中具有关键作用. 本文遵循视觉和点云领域中标准Transformer[18 ] 的设计架构,为序列特征添加了位置编码. 利用由2个线性层和1个GELU激活函数组成的MLP,将$ S $ $ D $ $ {{\boldsymbol{E}}_{{\text{pos}}}} \in {{\bf{R}}^{S \times D}} $ . 将点云编码$ {\boldsymbol{T}} $ $ {{\boldsymbol{E}}_{{\text{pos}}}} $ $ {{\boldsymbol{X}}_{{\text{patch}}}} $ . ...
Pvt v2: improved baselines with pyramid vision transformer
1
2022
... Adapter的概念源于工程中的模块化设计思想,通过对已有知识进行微调,适应特定的下游任务. 自然语言处理领域首次引入Adapter[16 ] ,用于将预训练模型快速迁移到下游任务. 在计算机视觉领域,Chen等[17 ] 结合Adapter与ViT[18 ] ,提出ViT-Adapter[17 ] 模型. ViT-Adapter在多项任务中超越了许多专门设计的视觉Transformer[19 ] . ...
1
... Adapter也逐步应用于点云领域. Tang等[12 ] 设计点先验提示与几何感知适配器模块微调标准Transformer预训练模型,以较少的参数量在分类任务上取得了显著效果. 该方法在处理复杂场景的密集预测任务时表现不佳. Wu等[20 ] 将提示词适配器作为网络的关键模块,以提取数据集间的通用表示,实现多数据集的协同预训练,在下游任务中取得了优异的性能,但未深入探索将已有知识适配至特定任务的适配器思想. ...
1
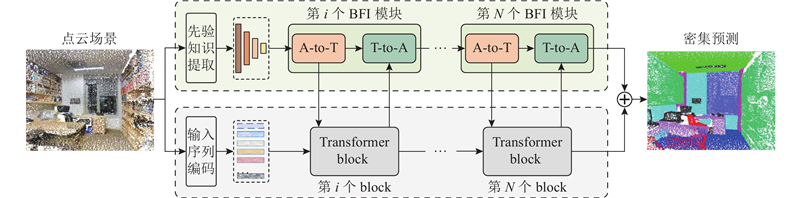
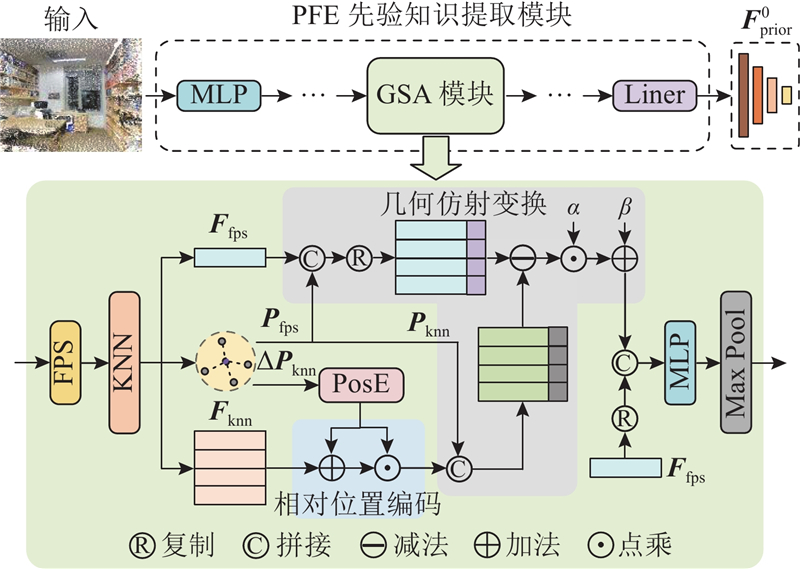
... 相比于图像,点云具有无序、稀疏、不规则的特性,传统的卷积难以完全概括点云的几何先验特征. 为此,设计先验特征提取(PFE)模块,灵活地提取点云先验特征. 如图2 所示,PFE模块层次化地使用多个几何抽象(geometric set abstraction,GSA)模块,提高对不同尺度目标的感知能力. GSA模块结合相对位置编码[21 ] 与几何变换[22 ] 模块,增强对局部几何特征的捕捉能力. ...
2
... 相比于图像,点云具有无序、稀疏、不规则的特性,传统的卷积难以完全概括点云的几何先验特征. 为此,设计先验特征提取(PFE)模块,灵活地提取点云先验特征. 如图2 所示,PFE模块层次化地使用多个几何抽象(geometric set abstraction,GSA)模块,提高对不同尺度目标的感知能力. GSA模块结合相对位置编码[21 ] 与几何变换[22 ] 模块,增强对局部几何特征的捕捉能力. ...
... 为了应对真实世界数据集[23 -24 ] 中某些区域的稀疏性和不规则几何结构所带来的挑战,引入可学习的几何仿射变换(geometric affine)[22 ] 模块,增强GSA模块的几何结构提取能力. 该模块使用$ {\boldsymbol{F}}_{{\text{fps}}}^j $ $ {\boldsymbol{F}}_{{\text{pos}}}^j $ $ {\boldsymbol{P}}_{{\text{fps}}}^j $ $ {\boldsymbol{P}}_{{\text{knn}}}^j $ $ {C^j} $ $ {{\boldsymbol{G}}^j} \in {{\bf{R}}^{{C^j} \times K \times {D^{j - 1}}}} $
4
... 为了应对真实世界数据集[23 -24 ] 中某些区域的稀疏性和不规则几何结构所带来的挑战,引入可学习的几何仿射变换(geometric affine)[22 ] 模块,增强GSA模块的几何结构提取能力. 该模块使用$ {\boldsymbol{F}}_{{\text{fps}}}^j $ $ {\boldsymbol{F}}_{{\text{pos}}}^j $ $ {\boldsymbol{P}}_{{\text{fps}}}^j $ $ {\boldsymbol{P}}_{{\text{knn}}}^j $ $ {C^j} $ $ {{\boldsymbol{G}}^j} \in {{\bf{R}}^{{C^j} \times K \times {D^{j - 1}}}} $
... SemanticKITTI[23 ] 是真实世界路况的数据集,包含21个序列和43 552帧点云. 使用序列00~07以及09、10共19 130 423帧作为训练集,序列08(4 071帧)作为验证集. ...
... Quantitative result of different methods on SemanticKITTI
Tab.3 方法 输入 mIoU/% PointNet++[26 ] 50 000个点 20.1 SPG[27 ] 17.4 SPLATNet[30 ] 18.4 TangentConv[31 ] 40.9 SqueezeSegV2[32 ] 64×2 048像素 39.7 DarkNet21Seg[23 ] 47.4 DarkNet53Seg[23 ] 49.9 Point-Bert[10 ] 20 000个点 44.5 PCT-Adapter 53.4
实验结果表明,相较于标准Transformer,PCT-Adapter的mIoU提高了8.9%. PCT-Adapter 在更复杂、多样化的真实室外场景中对室外Transformer性能的提升归因于Adapter对标准Transformer 结构的有益补充和高质量的特征交互, 这证明了PCT-Adapter的细粒度特征捕获能力和有效的辅助作用. ...
... [
23 ]
49.9 Point-Bert[10 ] 20 000个点 44.5 PCT-Adapter 53.4 实验结果表明,相较于标准Transformer,PCT-Adapter的mIoU提高了8.9%. PCT-Adapter 在更复杂、多样化的真实室外场景中对室外Transformer性能的提升归因于Adapter对标准Transformer 结构的有益补充和高质量的特征交互, 这证明了PCT-Adapter的细粒度特征捕获能力和有效的辅助作用. ...
3
... 为了应对真实世界数据集[23 -24 ] 中某些区域的稀疏性和不规则几何结构所带来的挑战,引入可学习的几何仿射变换(geometric affine)[22 ] 模块,增强GSA模块的几何结构提取能力. 该模块使用$ {\boldsymbol{F}}_{{\text{fps}}}^j $ $ {\boldsymbol{F}}_{{\text{pos}}}^j $ $ {\boldsymbol{P}}_{{\text{fps}}}^j $ $ {\boldsymbol{P}}_{{\text{knn}}}^j $ $ {C^j} $ $ {{\boldsymbol{G}}^j} \in {{\bf{R}}^{{C^j} \times K \times {D^{j - 1}}}} $
... 以S3DIS[24 ] 为例,若PFE模块的采样率设置为$ C = \left\{ {n/4,n/16,n/64,n/256} \right\} $ $ i $ $ {\boldsymbol{F}}_{{\text{Prior}}}^{i - 1} \in {{\bf{R}}^{\left( {n/4+n/16+n/64+n/256} \right) \times D}} $ $ {\boldsymbol{F}}_{{\text{st}}}^{i - 1} \in {{\bf{R}}^{(1+S) \times D}} $
... S3DIS[24 ] 数据集涵盖了来自3个不同建筑的6个大型室内区域,共2.73亿个点,标注有13个类别(天花板、地板、桌子等) . 使用区域5进行测试,其他区域用于训练. ...
3CROSSNet: cross-level cross-scale cross-attention network for point cloud representation
1
2022
... A-to-T模块能够在不破坏标准Transformer块的情况下,为Transformer注入多尺度先验特征,增强标准Transformer的特征学习能力. A-to-T模块使用交叉注意力[25 ] ,为Transformer注入多尺度几何信息. 在不同的密集预测任务中,不同的尺度先验特征在多尺度特征金字塔中具有不同的重要性. 针对多尺度特征金字塔,在A-to-T模块中引入一组可学习参数,能够在不同尺度下对特征的融合比例进行自适应调整,增强模型在各种任务和场景中的适应性和分割性能. ...
2
... Part segmentation result of ShapeNetPart dataset
Tab.1 模型 mIoUcls /% mIoUins /% PointNet++[26 ] 81.9 85.1 PointASNL[27 ] — 86.1 PCT[6 ] — 86.4 PointTransformer[5 ] 83.7 86.6 PointCAT[28 ] 84.4 86.0 Point-Bert[10 ] 84.1 85.6 PCT-Adapter 84.5 86.0
PCT-Adapter有效缩小了标准Transformer与变体Transformer[6 , 28 ] 之间的性能差距. 这一结果表明,PCT-Adapter有助于解决标准Transformer的结构局限性问题. 随着点云预训练方法与数据集的发展,当标准Transformer预训练模型的特征提取能力被进一步开发时,PCT-Adapter的性能将优于变体Transformer. ...
... Quantitative result of different methods on SemanticKITTI
Tab.3 方法 输入 mIoU/% PointNet++[26 ] 50 000个点 20.1 SPG[27 ] 17.4 SPLATNet[30 ] 18.4 TangentConv[31 ] 40.9 SqueezeSegV2[32 ] 64×2 048像素 39.7 DarkNet21Seg[23 ] 47.4 DarkNet53Seg[23 ] 49.9 Point-Bert[10 ] 20 000个点 44.5 PCT-Adapter 53.4
实验结果表明,相较于标准Transformer,PCT-Adapter的mIoU提高了8.9%. PCT-Adapter 在更复杂、多样化的真实室外场景中对室外Transformer性能的提升归因于Adapter对标准Transformer 结构的有益补充和高质量的特征交互, 这证明了PCT-Adapter的细粒度特征捕获能力和有效的辅助作用. ...
3
... Part segmentation result of ShapeNetPart dataset
Tab.1 模型 mIoUcls /% mIoUins /% PointNet++[26 ] 81.9 85.1 PointASNL[27 ] — 86.1 PCT[6 ] — 86.4 PointTransformer[5 ] 83.7 86.6 PointCAT[28 ] 84.4 86.0 Point-Bert[10 ] 84.1 85.6 PCT-Adapter 84.5 86.0
PCT-Adapter有效缩小了标准Transformer与变体Transformer[6 , 28 ] 之间的性能差距. 这一结果表明,PCT-Adapter有助于解决标准Transformer的结构局限性问题. 随着点云预训练方法与数据集的发展,当标准Transformer预训练模型的特征提取能力被进一步开发时,PCT-Adapter的性能将优于变体Transformer. ...
... Semantic segmentation result of S3DIS dataset (area 5)
Tab.2 方法 mAcc/ mIoU/ mIoUcls /% 天花板 地板 墙壁 横梁 柱子 窗户 门 桌子 椅子 沙发 书柜 黑板 杂物 SPG[27 ] 66.5 58.0 89.4 96.9 78.1 0.0 42.8 48.9 61.6 84.7 75.4 69.8 52.6 2.1 52.2 PointWeb[2 ] 66.6 60.3 92.0 98.5 79.4 0.0 21.1 59.7 34.8 76.3 88.3 46.9 69.3 64.9 52.5 PAT[29 ] 70.8 60.1 93.0 98.5 72.3 1.0 41.5 85.1 38.2 57.7 83.6 48.1 67.0 61.3 33.6 PT[5 ] 76.5 70.4 94.0 98.5 86.3 0.0 38.0 63.4 74.3 89.1 82.4 74.3 80.2 76.0 59.3 PCT[6 ] 67.7 61.3 92.5 98.4 80.6 0.0 19.3 61.6 48.0 76.6 85.2 46.2 67.7 67.9 52.3 PatchF[13 ] — 67.3 91.8 98.7 86.2 0.0 34.1 48.9 62.4 81.6 89.8 47.2 74.9 74.4 58.6 PointCAT[28 ] 71.0 64.0 94.2 98.3 80.5 0.0 18.6 55.5 58.9 77.2 88.0 64.8 72.2 68.9 55.4 SPFormer[14 ] 77.3 68.9 91.5 98.2 81.4 0.0 23.3 65.3 40.0 75.5 87.7 59.5 67.8 65.6 49.4 Point-Bert[10 ] 75.7 63.5 91.3 92.3 73.1 0.0 33.9 65.6 60.4 76.5 82.7 86.8 64.0 41.7 43.0 PCT-Adapter 80.5 69.0 91.9 96.0 81.6 0.0 52.4 66.5 67.0 82.9 90.1 70.8 72.8 69.5 54.7
如图4 所示为PCT-Adapter与Point-Bert在区域5上的分割结果. PCT-Adapter在维持总体分割质量的同时,增强了细节的分割效果. 这些结果表明,PCT-Adapter有效地将标准Transformer扩展到下游任务,证明了设计的合理性. ...
... Quantitative result of different methods on SemanticKITTI
Tab.3 方法 输入 mIoU/% PointNet++[26 ] 50 000个点 20.1 SPG[27 ] 17.4 SPLATNet[30 ] 18.4 TangentConv[31 ] 40.9 SqueezeSegV2[32 ] 64×2 048像素 39.7 DarkNet21Seg[23 ] 47.4 DarkNet53Seg[23 ] 49.9 Point-Bert[10 ] 20 000个点 44.5 PCT-Adapter 53.4
实验结果表明,相较于标准Transformer,PCT-Adapter的mIoU提高了8.9%. PCT-Adapter 在更复杂、多样化的真实室外场景中对室外Transformer性能的提升归因于Adapter对标准Transformer 结构的有益补充和高质量的特征交互, 这证明了PCT-Adapter的细粒度特征捕获能力和有效的辅助作用. ...
4
... Part segmentation result of ShapeNetPart dataset
Tab.1 模型 mIoUcls /% mIoUins /% PointNet++[26 ] 81.9 85.1 PointASNL[27 ] — 86.1 PCT[6 ] — 86.4 PointTransformer[5 ] 83.7 86.6 PointCAT[28 ] 84.4 86.0 Point-Bert[10 ] 84.1 85.6 PCT-Adapter 84.5 86.0
PCT-Adapter有效缩小了标准Transformer与变体Transformer[6 , 28 ] 之间的性能差距. 这一结果表明,PCT-Adapter有助于解决标准Transformer的结构局限性问题. 随着点云预训练方法与数据集的发展,当标准Transformer预训练模型的特征提取能力被进一步开发时,PCT-Adapter的性能将优于变体Transformer. ...
... PCT-Adapter有效缩小了标准Transformer与变体Transformer[6 , 28 ] 之间的性能差距. 这一结果表明,PCT-Adapter有助于解决标准Transformer的结构局限性问题. 随着点云预训练方法与数据集的发展,当标准Transformer预训练模型的特征提取能力被进一步开发时,PCT-Adapter的性能将优于变体Transformer. ...
... 如表2 所示,Point-Bert和PCT-Adapter均加载Point-Bert预训练权重,在真实室内数据集S3DIS上进行语义分割测试. 相较于标准Transformer,PCT-Adapter分别提高了4.8% 的mAcc与和5.5% 的mIoU. PCT-Adapter超过部分变体Transformer[6 , 13 -14 , 28 ] 的性能. ...
... Semantic segmentation result of S3DIS dataset (area 5)
Tab.2 方法 mAcc/ mIoU/ mIoUcls /% 天花板 地板 墙壁 横梁 柱子 窗户 门 桌子 椅子 沙发 书柜 黑板 杂物 SPG[27 ] 66.5 58.0 89.4 96.9 78.1 0.0 42.8 48.9 61.6 84.7 75.4 69.8 52.6 2.1 52.2 PointWeb[2 ] 66.6 60.3 92.0 98.5 79.4 0.0 21.1 59.7 34.8 76.3 88.3 46.9 69.3 64.9 52.5 PAT[29 ] 70.8 60.1 93.0 98.5 72.3 1.0 41.5 85.1 38.2 57.7 83.6 48.1 67.0 61.3 33.6 PT[5 ] 76.5 70.4 94.0 98.5 86.3 0.0 38.0 63.4 74.3 89.1 82.4 74.3 80.2 76.0 59.3 PCT[6 ] 67.7 61.3 92.5 98.4 80.6 0.0 19.3 61.6 48.0 76.6 85.2 46.2 67.7 67.9 52.3 PatchF[13 ] — 67.3 91.8 98.7 86.2 0.0 34.1 48.9 62.4 81.6 89.8 47.2 74.9 74.4 58.6 PointCAT[28 ] 71.0 64.0 94.2 98.3 80.5 0.0 18.6 55.5 58.9 77.2 88.0 64.8 72.2 68.9 55.4 SPFormer[14 ] 77.3 68.9 91.5 98.2 81.4 0.0 23.3 65.3 40.0 75.5 87.7 59.5 67.8 65.6 49.4 Point-Bert[10 ] 75.7 63.5 91.3 92.3 73.1 0.0 33.9 65.6 60.4 76.5 82.7 86.8 64.0 41.7 43.0 PCT-Adapter 80.5 69.0 91.9 96.0 81.6 0.0 52.4 66.5 67.0 82.9 90.1 70.8 72.8 69.5 54.7
如图4 所示为PCT-Adapter与Point-Bert在区域5上的分割结果. PCT-Adapter在维持总体分割质量的同时,增强了细节的分割效果. 这些结果表明,PCT-Adapter有效地将标准Transformer扩展到下游任务,证明了设计的合理性. ...
1
... Semantic segmentation result of S3DIS dataset (area 5)
Tab.2 方法 mAcc/ mIoU/ mIoUcls /% 天花板 地板 墙壁 横梁 柱子 窗户 门 桌子 椅子 沙发 书柜 黑板 杂物 SPG[27 ] 66.5 58.0 89.4 96.9 78.1 0.0 42.8 48.9 61.6 84.7 75.4 69.8 52.6 2.1 52.2 PointWeb[2 ] 66.6 60.3 92.0 98.5 79.4 0.0 21.1 59.7 34.8 76.3 88.3 46.9 69.3 64.9 52.5 PAT[29 ] 70.8 60.1 93.0 98.5 72.3 1.0 41.5 85.1 38.2 57.7 83.6 48.1 67.0 61.3 33.6 PT[5 ] 76.5 70.4 94.0 98.5 86.3 0.0 38.0 63.4 74.3 89.1 82.4 74.3 80.2 76.0 59.3 PCT[6 ] 67.7 61.3 92.5 98.4 80.6 0.0 19.3 61.6 48.0 76.6 85.2 46.2 67.7 67.9 52.3 PatchF[13 ] — 67.3 91.8 98.7 86.2 0.0 34.1 48.9 62.4 81.6 89.8 47.2 74.9 74.4 58.6 PointCAT[28 ] 71.0 64.0 94.2 98.3 80.5 0.0 18.6 55.5 58.9 77.2 88.0 64.8 72.2 68.9 55.4 SPFormer[14 ] 77.3 68.9 91.5 98.2 81.4 0.0 23.3 65.3 40.0 75.5 87.7 59.5 67.8 65.6 49.4 Point-Bert[10 ] 75.7 63.5 91.3 92.3 73.1 0.0 33.9 65.6 60.4 76.5 82.7 86.8 64.0 41.7 43.0 PCT-Adapter 80.5 69.0 91.9 96.0 81.6 0.0 52.4 66.5 67.0 82.9 90.1 70.8 72.8 69.5 54.7
如图4 所示为PCT-Adapter与Point-Bert在区域5上的分割结果. PCT-Adapter在维持总体分割质量的同时,增强了细节的分割效果. 这些结果表明,PCT-Adapter有效地将标准Transformer扩展到下游任务,证明了设计的合理性. ...
1
... Quantitative result of different methods on SemanticKITTI
Tab.3 方法 输入 mIoU/% PointNet++[26 ] 50 000个点 20.1 SPG[27 ] 17.4 SPLATNet[30 ] 18.4 TangentConv[31 ] 40.9 SqueezeSegV2[32 ] 64×2 048像素 39.7 DarkNet21Seg[23 ] 47.4 DarkNet53Seg[23 ] 49.9 Point-Bert[10 ] 20 000个点 44.5 PCT-Adapter 53.4
实验结果表明,相较于标准Transformer,PCT-Adapter的mIoU提高了8.9%. PCT-Adapter 在更复杂、多样化的真实室外场景中对室外Transformer性能的提升归因于Adapter对标准Transformer 结构的有益补充和高质量的特征交互, 这证明了PCT-Adapter的细粒度特征捕获能力和有效的辅助作用. ...
1
... Quantitative result of different methods on SemanticKITTI
Tab.3 方法 输入 mIoU/% PointNet++[26 ] 50 000个点 20.1 SPG[27 ] 17.4 SPLATNet[30 ] 18.4 TangentConv[31 ] 40.9 SqueezeSegV2[32 ] 64×2 048像素 39.7 DarkNet21Seg[23 ] 47.4 DarkNet53Seg[23 ] 49.9 Point-Bert[10 ] 20 000个点 44.5 PCT-Adapter 53.4
实验结果表明,相较于标准Transformer,PCT-Adapter的mIoU提高了8.9%. PCT-Adapter 在更复杂、多样化的真实室外场景中对室外Transformer性能的提升归因于Adapter对标准Transformer 结构的有益补充和高质量的特征交互, 这证明了PCT-Adapter的细粒度特征捕获能力和有效的辅助作用. ...
1
... Quantitative result of different methods on SemanticKITTI
Tab.3 方法 输入 mIoU/% PointNet++[26 ] 50 000个点 20.1 SPG[27 ] 17.4 SPLATNet[30 ] 18.4 TangentConv[31 ] 40.9 SqueezeSegV2[32 ] 64×2 048像素 39.7 DarkNet21Seg[23 ] 47.4 DarkNet53Seg[23 ] 49.9 Point-Bert[10 ] 20 000个点 44.5 PCT-Adapter 53.4
实验结果表明,相较于标准Transformer,PCT-Adapter的mIoU提高了8.9%. PCT-Adapter 在更复杂、多样化的真实室外场景中对室外Transformer性能的提升归因于Adapter对标准Transformer 结构的有益补充和高质量的特征交互, 这证明了PCT-Adapter的细粒度特征捕获能力和有效的辅助作用. ...



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}