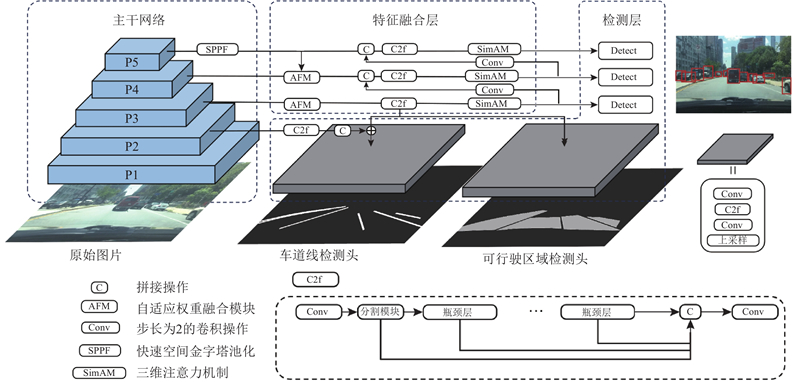
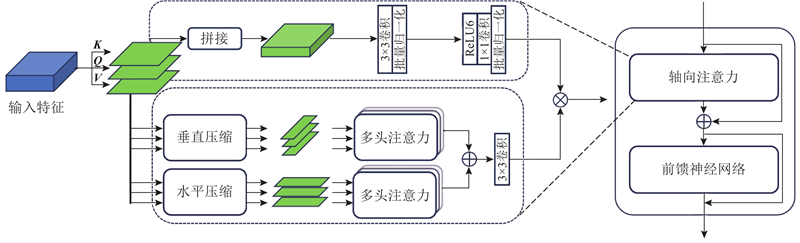
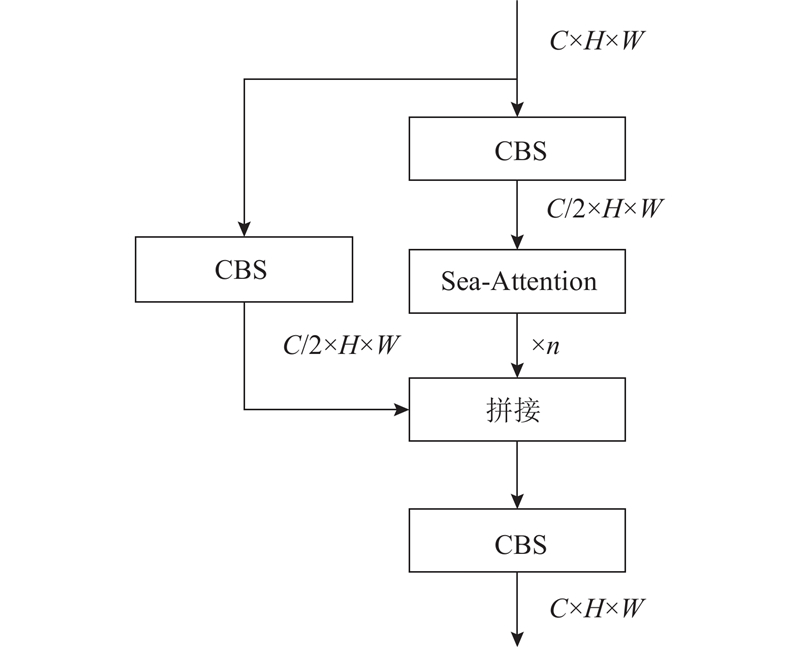
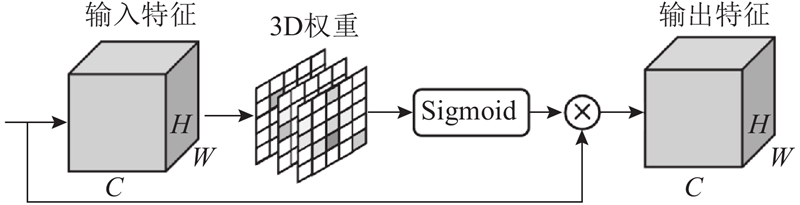
| 计算机技术与控制工程 |
|

|
|
|
| 基于轴向注意力的多任务自动驾驶环境感知算法 |
李沈崇1( ),曾新华2,*(),林传渠1 ),曾新华2,*(),林传渠1 |
1. 湖州师范学院 信息工程学院,浙江 湖州 313000
2. 复旦大学 工程与应用技术研究院,上海 200433 |
|
| Multi-task environment perception algorithm for autonomous driving based on axial attention |
| Shenchong LI1(),Xinhua ZENG2,*(),Chuanqu LIN1 |
1. School of Information Engineering, Huzhou University, Huzhou 313000, China
2. Academy for Engineering and Technology, Fudan University, Shanghai 200433, China |
| 1 |
LIANG X, NIU M, HAN J, et al. Visual exemplar driven task-prompting for unified perception in autonomous driving [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Vancouver: IEEE, 2023: 9611–9621.
|
| 2 |
LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot MultiBox detector [C]// Computer Vision – ECCV 2016 . [S. l.]: Springer, 2016: 21–37.
|
| 3 |
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 779–788.
|
| 4 |
REDMON J, FARHADI A. YOLOv3: an incremental improvement [EB/OL]. (2018–04–08)[2024–03–08]. https://www.arxiv.org/pdf/1804.02767.
|
| 5 |
BOCHKOVSKIY A, WANG C Y, LIAO H M, et al. YOLOv4: optimal speed and accuracy of object detection [EB/OL]. (2020–4–23)[2024–01–22]. https://arxiv.org/pdf/2004.10934.
|
| 6 |
蒋超, 张豪, 章恩泽, 等 基于改进YOLOv5s的行人车辆目标检测算法[J]. 扬州大学学报: 自然科学版, 2022, 25 (6): 45- 49
JIANG Chao, ZHANG Hao, ZHANG Enze, et al Pedestrian and vehicle target detection algorithm based on the improved YOLOv5s[J]. Journal of Yangzhou University: Natural Science Edition, 2022, 25 (6): 45- 49
|
| 7 |
韩俊, 袁小平, 王准, 等 基于YOLOv5s的无人机密集小目标检测算法[J]. 浙江大学学报: 工学版, 2023, 57 (6): 1224- 1233
HAN Jun, YUAN Xiaoping, WANG Zhun, et al UAV dense small target detection algorithm based on YOLOv5s[J]. Journal of Zhejiang University: Engineering Science, 2023, 57 (6): 1224- 1233
|
| 8 |
GIRSHICK R. Fast R-CNN [C]// Proceedings of the IEEE International Conference on Computer Vision . Santiago: IEEE, 2015: 1440–1448.
|
| 9 |
REN S, HE K, GIRSHICK R, et al Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39 (6): 1137- 1149
doi: 10.1109/TPAMI.2016.2577031
|
| 10 |
CHEN L C, PAPANDREOU G, KOKKINOS I, et al DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40 (4): 834- 848
|
| 11 |
LIN G, MILAN A, SHEN C, et al. RefineNet: multi-path refinement networks for high-resolution semantic segmentation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 5168–5177.
|
| 12 |
ZHAO H, SHI J, QI X, et al. Pyramid scene parsing network [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu. IEEE, 2017: 6230–6239.
|
| 13 |
YU C, WANG J, PENG C, et al. BiSeNet: bilateral segmentation network for real-time semantic segmentation [C]// Computer Vision – ECCV 2018 . [S.l.]: Springe, 2018: 334–349.
|
| 14 |
FAN M, LAI S, HUANG J, et al. Rethinking BiSeNet for real-time semantic segmentation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 9711–9720.
|
| 15 |
WANG Z, REN W, QIU Q. LaneNet: real-time lane detection networks for autonomous driving [EB/OL]. (2018–07–04)[2024–03–08]. https://arxiv.org/pdf/1807.01726.
|
| 16 |
TEICHMANN M, WEBER M, ZOELLNER M, et al. MultiNet: real-time joint semantic reasoning for autonomous driving [EB/OL]. (2016–12–22)[2024–03–08]. https://arxiv.org/pdf/1612.07695.
|
| 17 |
QIAN Y, DOLAN J M, YANG M DLT-Net: joint detection of drivable areas, lane lines, and traffic objects[J]. IEEE Transactions on Intelligent Transportation Systems, 2020, 21 (11): 4670- 4679
|
| 18 |
WU D, LIAO M W, ZHANG W T, et al YOLOP: you only look once for panoptic driving perception[J]. Machine Intelligence Research, 2022, 19 (6): 550- 562
|
| 19 |
VU D, NGO B, PHAN H. HybridNets: end-to-end perception network [EB/OL]. (2022–03–17)[2024–03–08]. https://arxiv.org/pdf/2203.09035.
|
| 20 |
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: transformers for image recognition at scale [EB/OL]. (2021–06–03)[2024–03–08]. https://arxiv.org/pdf/2010.11929.
|
| 21 |
CARION N, MASSA F, SYNNAEVE G, et al. End-to-end object detection with transformers [C]// Computer Vision – ECCV 2020 . [S.l.]: Springer, 2020: 213–229.
|
| 22 |
LIU Z, LIN Y, CAO Y, et al. Swin Transformer: hierarchical vision transformer using shifted windows [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 9992–10002.
|
| 23 |
WAN Q, HUANG Z, LU J, et al. SeaFormer++: squeeze-enhanced axial transformer for mobile semantic segmentation [EB/OL]. (2023–06–09)[2024–03–08]. https://arxiv.org/pdf/2301.13156.
|
| 24 |
LIU S, QI L, QIN H, et al. Path aggregation network for instance segmentation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 8759–8768.
|
| 25 |
WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module [C]// Computer Vision – ECCV 2018 . [S.l.]: Springer, 2018: 3–19.
|
| 26 |
YANG L, ZHANG R Y, LI L, et al. SimAM: a simple, parameter-free attention module for convolutional neural networks [C]// Proceeding of the 38th International Conference on Machine Learning . Vienna: ACM, 2021: 11863-11874.
|
| 27 |
DUAN K, BAI S, XIE L, et al. CenterNet: keypoint triplets for object detection [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 6569–6578.
|
| 28 |
ZHANG Y, ZHANG W, YU J, et al Complete and accurate holly fruits counting using YOLOX object detection[J]. Computers and Electronics in Agriculture, 2022, 198: 107062
|
| 29 |
LI X, WANG W, WU L, et al Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection[J]. Advances in Neural Information Processing Systems, 2020, 33: 21002- 21012
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|