[1]
LIANG X, NIU M, HAN J, et al. Visual exemplar driven task-prompting for unified perception in autonomous driving [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Vancouver: IEEE, 2023: 9611–9621.
[本文引用: 1]
[2]
LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot MultiBox detector [C]// Computer Vision – ECCV 2016 . [S. l.]: Springer, 2016: 21–37.
[本文引用: 1]
[3]
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 779–788.
[本文引用: 1]
[4]
REDMON J, FARHADI A. YOLOv3: an incremental improvement [EB/OL]. (2018–04–08)[2024–03–08]. https://www.arxiv.org/pdf/1804.02767.
[5]
BOCHKOVSKIY A, WANG C Y, LIAO H M, et al. YOLOv4: optimal speed and accuracy of object detection [EB/OL]. (2020–4–23)[2024–01–22]. https://arxiv.org/pdf/2004.10934.
[本文引用: 1]
[6]
蒋超, 张豪, 章恩泽, 等 基于改进YOLOv5s的行人车辆目标检测算法
[J]. 扬州大学学报: 自然科学版 , 2022 , 25 (6 ): 45 - 49
JIANG Chao, ZHANG Hao, ZHANG Enze, et al Pedestrian and vehicle target detection algorithm based on the improved YOLOv5s
[J]. Journal of Yangzhou University: Natural Science Edition , 2022 , 25 (6 ): 45 - 49
[7]
韩俊, 袁小平, 王准, 等 基于YOLOv5s的无人机密集小目标检测算法
[J]. 浙江大学学报: 工学版 , 2023 , 57 (6 ): 1224 - 1233
[本文引用: 1]
HAN Jun, YUAN Xiaoping, WANG Zhun, et al UAV dense small target detection algorithm based on YOLOv5s
[J]. Journal of Zhejiang University: Engineering Science , 2023 , 57 (6 ): 1224 - 1233
[本文引用: 1]
[8]
GIRSHICK R. Fast R-CNN [C]// Proceedings of the IEEE International Conference on Computer Vision . Santiago: IEEE, 2015: 1440–1448.
[本文引用: 1]
[9]
REN S, HE K, GIRSHICK R, et al Faster R-CNN: towards real-time object detection with region proposal networks
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2017 , 39 (6 ): 1137 - 1149
DOI:10.1109/TPAMI.2016.2577031
[本文引用: 1]
[10]
CHEN L C, PAPANDREOU G, KOKKINOS I, et al DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2018 , 40 (4 ): 834 - 848
[本文引用: 1]
[11]
LIN G, MILAN A, SHEN C, et al. RefineNet: multi-path refinement networks for high-resolution semantic segmentation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 5168–5177.
[本文引用: 1]
[12]
ZHAO H, SHI J, QI X, et al. Pyramid scene parsing network [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu. IEEE, 2017: 6230–6239.
[本文引用: 1]
[13]
YU C, WANG J, PENG C, et al. BiSeNet: bilateral segmentation network for real-time semantic segmentation [C]// Computer Vision – ECCV 2018 . [S.l.]: Springe, 2018: 334–349.
[本文引用: 1]
[14]
FAN M, LAI S, HUANG J, et al. Rethinking BiSeNet for real-time semantic segmentation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 9711–9720.
[本文引用: 2]
[15]
WANG Z, REN W, QIU Q. LaneNet: real-time lane detection networks for autonomous driving [EB/OL]. (2018–07–04)[2024–03–08]. https://arxiv.org/pdf/1807.01726.
[本文引用: 1]
[16]
TEICHMANN M, WEBER M, ZOELLNER M, et al. MultiNet: real-time joint semantic reasoning for autonomous driving [EB/OL]. (2016–12–22)[2024–03–08]. https://arxiv.org/pdf/1612.07695.
[本文引用: 1]
[17]
QIAN Y, DOLAN J M, YANG M DLT-Net: joint detection of drivable areas, lane lines, and traffic objects
[J]. IEEE Transactions on Intelligent Transportation Systems , 2020 , 21 (11 ): 4670 - 4679
[本文引用: 1]
[18]
WU D, LIAO M W, ZHANG W T, et al YOLOP: you only look once for panoptic driving perception
[J]. Machine Intelligence Research , 2022 , 19 (6 ): 550 - 562
[本文引用: 1]
[19]
VU D, NGO B, PHAN H. HybridNets: end-to-end perception network [EB/OL]. (2022–03–17)[2024–03–08]. https://arxiv.org/pdf/2203.09035.
[本文引用: 1]
[20]
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: transformers for image recognition at scale [EB/OL]. (2021–06–03)[2024–03–08]. https://arxiv.org/pdf/2010.11929.
[本文引用: 1]
[21]
CARION N, MASSA F, SYNNAEVE G, et al. End-to-end object detection with transformers [C]// Computer Vision – ECCV 2020 . [S.l.]: Springer, 2020: 213–229.
[22]
LIU Z, LIN Y, CAO Y, et al. Swin Transformer: hierarchical vision transformer using shifted windows [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 9992–10002.
[本文引用: 1]
[23]
WAN Q, HUANG Z, LU J, et al. SeaFormer++: squeeze-enhanced axial transformer for mobile semantic segmentation [EB/OL]. (2023–06–09)[2024–03–08]. https://arxiv.org/pdf/2301.13156.
[本文引用: 1]
[24]
LIU S, QI L, QIN H, et al. Path aggregation network for instance segmentation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 8759–8768.
[本文引用: 1]
[25]
WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module [C]// Computer Vision – ECCV 2018 . [S.l.]: Springer, 2018: 3–19.
[本文引用: 1]
[26]
YANG L, ZHANG R Y, LI L, et al. SimAM: a simple, parameter-free attention module for convolutional neural networks [C]// Proceeding of the 38th International Conference on Machine Learning . Vienna: ACM, 2021: 11863-11874.
[本文引用: 1]
[27]
DUAN K, BAI S, XIE L, et al. CenterNet: keypoint triplets for object detection [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 6569–6578.
[本文引用: 1]
[28]
ZHANG Y, ZHANG W, YU J, et al Complete and accurate holly fruits counting using YOLOX object detection
[J]. Computers and Electronics in Agriculture , 2022 , 198 : 107062
[本文引用: 1]
[29]
LI X, WANG W, WU L, et al Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection
[J]. Advances in Neural Information Processing Systems , 2020 , 33 : 21002 - 21012
[本文引用: 1]
[30]
SELVARAJU R R, COGSWELL M, DAS A, et al. Grad-CAM: visual explanations from deep networks via gradient-based localization [C]// Proceedings of the IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 618–626.
[本文引用: 1]
1
... 环境感知是自动驾驶的先决条件,摄像头获得的道路图像信息为车辆动作提供决策依据,保证车内人员在自动驾驶中的安全性和舒适性[1 ] . 在复杂的交通环境中,自动驾驶车辆如何快速准确识别道路信息以及行人、车辆和障碍物的位置和类别是亟待解决的问题. ...
1
... 在交通任务场景中,现有技术处理交通目标检测、可行驶区域分割和车道线检测等3种单独任务水平已达到较高水平. 目标检测模型根据处理流程的不同分为以SSD[2 ] 、YOLO[3 -7 ] 系列为代表的单阶段模型与Fast R-CNN[8 ] 、Faster R-CNN[9 ] 为代表的双阶段模型. 单阶段目标检测模型是端到端的方法,直接在输入图像上生成目标的边界框和类别标签;双阶段目标检测方法须通过感兴趣区域的分类和回归得到最终的目标检测结果. 一般来说,单阶段目标检测检测速度较快,精度相较偏低,双阶段模型与之相反,因此单阶段模型往往更符合实际需求. 在语义分割研究方面,Chen等[10 ] 提出DeepLab图像分割模型,对VGG网络(visual geometry group)进行改写,将该网络最后的2个池化层替换成空洞卷积以增加感受野,引入条件随机场以提高分割精度. 为了适应不同分辨率的目标,Lin等[11 ] 提出RefineNet,以多路径的方式提取网络特征,利用多级抽象特征进行高分辨率的语义分割,以递归方式细化低分辨语义特征和细粒度低级语义特征,生成高分辨率特征;Zhao等[12 ] 提出的PSPNet利用金字塔池提取多尺度特征以提升检测性能. 为了提高网络实时性能,BiSeNet[13 ] 利用空间路径和上下文路径双支结构,解决空间信息丢失和感受野收缩问题. Fan等[14 ] 提出短期密集级联网络(short-term dense concatenate network, STDC),使用较少的参数提取多尺度特征,改进BiSeNet中的多路径结构,在提取底层细节特征的同时减少网络计算量. 在车道检测中,LaneNet[15 ] 使用语义分割与像素聚类方法,进一步提高小目标检测准确度. ...
1
... 在交通任务场景中,现有技术处理交通目标检测、可行驶区域分割和车道线检测等3种单独任务水平已达到较高水平. 目标检测模型根据处理流程的不同分为以SSD[2 ] 、YOLO[3 -7 ] 系列为代表的单阶段模型与Fast R-CNN[8 ] 、Faster R-CNN[9 ] 为代表的双阶段模型. 单阶段目标检测模型是端到端的方法,直接在输入图像上生成目标的边界框和类别标签;双阶段目标检测方法须通过感兴趣区域的分类和回归得到最终的目标检测结果. 一般来说,单阶段目标检测检测速度较快,精度相较偏低,双阶段模型与之相反,因此单阶段模型往往更符合实际需求. 在语义分割研究方面,Chen等[10 ] 提出DeepLab图像分割模型,对VGG网络(visual geometry group)进行改写,将该网络最后的2个池化层替换成空洞卷积以增加感受野,引入条件随机场以提高分割精度. 为了适应不同分辨率的目标,Lin等[11 ] 提出RefineNet,以多路径的方式提取网络特征,利用多级抽象特征进行高分辨率的语义分割,以递归方式细化低分辨语义特征和细粒度低级语义特征,生成高分辨率特征;Zhao等[12 ] 提出的PSPNet利用金字塔池提取多尺度特征以提升检测性能. 为了提高网络实时性能,BiSeNet[13 ] 利用空间路径和上下文路径双支结构,解决空间信息丢失和感受野收缩问题. Fan等[14 ] 提出短期密集级联网络(short-term dense concatenate network, STDC),使用较少的参数提取多尺度特征,改进BiSeNet中的多路径结构,在提取底层细节特征的同时减少网络计算量. 在车道检测中,LaneNet[15 ] 使用语义分割与像素聚类方法,进一步提高小目标检测准确度. ...
1
... 为了节约计算资源、挖掘不同任务间的潜在关系,不同任务将共享主干网络,这要求主干网络根据不同任务需求提取不同目标、不同尺度的特征信息,并且保持网络的实时性. YOLO系列的检测性能出色,为此将CSPDarknet[5 ] 作为所提算法的主干网络,为了提高主干网络的特征提取能力,在跨阶段局部(cross stage partial, CSP)层添加轴向注意力,借此引入全局信息,引导不同任务更好拟合. ...
基于改进YOLOv5s的行人车辆目标检测算法
0
2022
基于改进YOLOv5s的行人车辆目标检测算法
0
2022
基于YOLOv5s的无人机密集小目标检测算法
1
2023
... 在交通任务场景中,现有技术处理交通目标检测、可行驶区域分割和车道线检测等3种单独任务水平已达到较高水平. 目标检测模型根据处理流程的不同分为以SSD[2 ] 、YOLO[3 -7 ] 系列为代表的单阶段模型与Fast R-CNN[8 ] 、Faster R-CNN[9 ] 为代表的双阶段模型. 单阶段目标检测模型是端到端的方法,直接在输入图像上生成目标的边界框和类别标签;双阶段目标检测方法须通过感兴趣区域的分类和回归得到最终的目标检测结果. 一般来说,单阶段目标检测检测速度较快,精度相较偏低,双阶段模型与之相反,因此单阶段模型往往更符合实际需求. 在语义分割研究方面,Chen等[10 ] 提出DeepLab图像分割模型,对VGG网络(visual geometry group)进行改写,将该网络最后的2个池化层替换成空洞卷积以增加感受野,引入条件随机场以提高分割精度. 为了适应不同分辨率的目标,Lin等[11 ] 提出RefineNet,以多路径的方式提取网络特征,利用多级抽象特征进行高分辨率的语义分割,以递归方式细化低分辨语义特征和细粒度低级语义特征,生成高分辨率特征;Zhao等[12 ] 提出的PSPNet利用金字塔池提取多尺度特征以提升检测性能. 为了提高网络实时性能,BiSeNet[13 ] 利用空间路径和上下文路径双支结构,解决空间信息丢失和感受野收缩问题. Fan等[14 ] 提出短期密集级联网络(short-term dense concatenate network, STDC),使用较少的参数提取多尺度特征,改进BiSeNet中的多路径结构,在提取底层细节特征的同时减少网络计算量. 在车道检测中,LaneNet[15 ] 使用语义分割与像素聚类方法,进一步提高小目标检测准确度. ...
基于YOLOv5s的无人机密集小目标检测算法
1
2023
... 在交通任务场景中,现有技术处理交通目标检测、可行驶区域分割和车道线检测等3种单独任务水平已达到较高水平. 目标检测模型根据处理流程的不同分为以SSD[2 ] 、YOLO[3 -7 ] 系列为代表的单阶段模型与Fast R-CNN[8 ] 、Faster R-CNN[9 ] 为代表的双阶段模型. 单阶段目标检测模型是端到端的方法,直接在输入图像上生成目标的边界框和类别标签;双阶段目标检测方法须通过感兴趣区域的分类和回归得到最终的目标检测结果. 一般来说,单阶段目标检测检测速度较快,精度相较偏低,双阶段模型与之相反,因此单阶段模型往往更符合实际需求. 在语义分割研究方面,Chen等[10 ] 提出DeepLab图像分割模型,对VGG网络(visual geometry group)进行改写,将该网络最后的2个池化层替换成空洞卷积以增加感受野,引入条件随机场以提高分割精度. 为了适应不同分辨率的目标,Lin等[11 ] 提出RefineNet,以多路径的方式提取网络特征,利用多级抽象特征进行高分辨率的语义分割,以递归方式细化低分辨语义特征和细粒度低级语义特征,生成高分辨率特征;Zhao等[12 ] 提出的PSPNet利用金字塔池提取多尺度特征以提升检测性能. 为了提高网络实时性能,BiSeNet[13 ] 利用空间路径和上下文路径双支结构,解决空间信息丢失和感受野收缩问题. Fan等[14 ] 提出短期密集级联网络(short-term dense concatenate network, STDC),使用较少的参数提取多尺度特征,改进BiSeNet中的多路径结构,在提取底层细节特征的同时减少网络计算量. 在车道检测中,LaneNet[15 ] 使用语义分割与像素聚类方法,进一步提高小目标检测准确度. ...
1
... 在交通任务场景中,现有技术处理交通目标检测、可行驶区域分割和车道线检测等3种单独任务水平已达到较高水平. 目标检测模型根据处理流程的不同分为以SSD[2 ] 、YOLO[3 -7 ] 系列为代表的单阶段模型与Fast R-CNN[8 ] 、Faster R-CNN[9 ] 为代表的双阶段模型. 单阶段目标检测模型是端到端的方法,直接在输入图像上生成目标的边界框和类别标签;双阶段目标检测方法须通过感兴趣区域的分类和回归得到最终的目标检测结果. 一般来说,单阶段目标检测检测速度较快,精度相较偏低,双阶段模型与之相反,因此单阶段模型往往更符合实际需求. 在语义分割研究方面,Chen等[10 ] 提出DeepLab图像分割模型,对VGG网络(visual geometry group)进行改写,将该网络最后的2个池化层替换成空洞卷积以增加感受野,引入条件随机场以提高分割精度. 为了适应不同分辨率的目标,Lin等[11 ] 提出RefineNet,以多路径的方式提取网络特征,利用多级抽象特征进行高分辨率的语义分割,以递归方式细化低分辨语义特征和细粒度低级语义特征,生成高分辨率特征;Zhao等[12 ] 提出的PSPNet利用金字塔池提取多尺度特征以提升检测性能. 为了提高网络实时性能,BiSeNet[13 ] 利用空间路径和上下文路径双支结构,解决空间信息丢失和感受野收缩问题. Fan等[14 ] 提出短期密集级联网络(short-term dense concatenate network, STDC),使用较少的参数提取多尺度特征,改进BiSeNet中的多路径结构,在提取底层细节特征的同时减少网络计算量. 在车道检测中,LaneNet[15 ] 使用语义分割与像素聚类方法,进一步提高小目标检测准确度. ...
Faster R-CNN: towards real-time object detection with region proposal networks
1
2017
... 在交通任务场景中,现有技术处理交通目标检测、可行驶区域分割和车道线检测等3种单独任务水平已达到较高水平. 目标检测模型根据处理流程的不同分为以SSD[2 ] 、YOLO[3 -7 ] 系列为代表的单阶段模型与Fast R-CNN[8 ] 、Faster R-CNN[9 ] 为代表的双阶段模型. 单阶段目标检测模型是端到端的方法,直接在输入图像上生成目标的边界框和类别标签;双阶段目标检测方法须通过感兴趣区域的分类和回归得到最终的目标检测结果. 一般来说,单阶段目标检测检测速度较快,精度相较偏低,双阶段模型与之相反,因此单阶段模型往往更符合实际需求. 在语义分割研究方面,Chen等[10 ] 提出DeepLab图像分割模型,对VGG网络(visual geometry group)进行改写,将该网络最后的2个池化层替换成空洞卷积以增加感受野,引入条件随机场以提高分割精度. 为了适应不同分辨率的目标,Lin等[11 ] 提出RefineNet,以多路径的方式提取网络特征,利用多级抽象特征进行高分辨率的语义分割,以递归方式细化低分辨语义特征和细粒度低级语义特征,生成高分辨率特征;Zhao等[12 ] 提出的PSPNet利用金字塔池提取多尺度特征以提升检测性能. 为了提高网络实时性能,BiSeNet[13 ] 利用空间路径和上下文路径双支结构,解决空间信息丢失和感受野收缩问题. Fan等[14 ] 提出短期密集级联网络(short-term dense concatenate network, STDC),使用较少的参数提取多尺度特征,改进BiSeNet中的多路径结构,在提取底层细节特征的同时减少网络计算量. 在车道检测中,LaneNet[15 ] 使用语义分割与像素聚类方法,进一步提高小目标检测准确度. ...
DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs
1
2018
... 在交通任务场景中,现有技术处理交通目标检测、可行驶区域分割和车道线检测等3种单独任务水平已达到较高水平. 目标检测模型根据处理流程的不同分为以SSD[2 ] 、YOLO[3 -7 ] 系列为代表的单阶段模型与Fast R-CNN[8 ] 、Faster R-CNN[9 ] 为代表的双阶段模型. 单阶段目标检测模型是端到端的方法,直接在输入图像上生成目标的边界框和类别标签;双阶段目标检测方法须通过感兴趣区域的分类和回归得到最终的目标检测结果. 一般来说,单阶段目标检测检测速度较快,精度相较偏低,双阶段模型与之相反,因此单阶段模型往往更符合实际需求. 在语义分割研究方面,Chen等[10 ] 提出DeepLab图像分割模型,对VGG网络(visual geometry group)进行改写,将该网络最后的2个池化层替换成空洞卷积以增加感受野,引入条件随机场以提高分割精度. 为了适应不同分辨率的目标,Lin等[11 ] 提出RefineNet,以多路径的方式提取网络特征,利用多级抽象特征进行高分辨率的语义分割,以递归方式细化低分辨语义特征和细粒度低级语义特征,生成高分辨率特征;Zhao等[12 ] 提出的PSPNet利用金字塔池提取多尺度特征以提升检测性能. 为了提高网络实时性能,BiSeNet[13 ] 利用空间路径和上下文路径双支结构,解决空间信息丢失和感受野收缩问题. Fan等[14 ] 提出短期密集级联网络(short-term dense concatenate network, STDC),使用较少的参数提取多尺度特征,改进BiSeNet中的多路径结构,在提取底层细节特征的同时减少网络计算量. 在车道检测中,LaneNet[15 ] 使用语义分割与像素聚类方法,进一步提高小目标检测准确度. ...
1
... 在交通任务场景中,现有技术处理交通目标检测、可行驶区域分割和车道线检测等3种单独任务水平已达到较高水平. 目标检测模型根据处理流程的不同分为以SSD[2 ] 、YOLO[3 -7 ] 系列为代表的单阶段模型与Fast R-CNN[8 ] 、Faster R-CNN[9 ] 为代表的双阶段模型. 单阶段目标检测模型是端到端的方法,直接在输入图像上生成目标的边界框和类别标签;双阶段目标检测方法须通过感兴趣区域的分类和回归得到最终的目标检测结果. 一般来说,单阶段目标检测检测速度较快,精度相较偏低,双阶段模型与之相反,因此单阶段模型往往更符合实际需求. 在语义分割研究方面,Chen等[10 ] 提出DeepLab图像分割模型,对VGG网络(visual geometry group)进行改写,将该网络最后的2个池化层替换成空洞卷积以增加感受野,引入条件随机场以提高分割精度. 为了适应不同分辨率的目标,Lin等[11 ] 提出RefineNet,以多路径的方式提取网络特征,利用多级抽象特征进行高分辨率的语义分割,以递归方式细化低分辨语义特征和细粒度低级语义特征,生成高分辨率特征;Zhao等[12 ] 提出的PSPNet利用金字塔池提取多尺度特征以提升检测性能. 为了提高网络实时性能,BiSeNet[13 ] 利用空间路径和上下文路径双支结构,解决空间信息丢失和感受野收缩问题. Fan等[14 ] 提出短期密集级联网络(short-term dense concatenate network, STDC),使用较少的参数提取多尺度特征,改进BiSeNet中的多路径结构,在提取底层细节特征的同时减少网络计算量. 在车道检测中,LaneNet[15 ] 使用语义分割与像素聚类方法,进一步提高小目标检测准确度. ...
1
... 在交通任务场景中,现有技术处理交通目标检测、可行驶区域分割和车道线检测等3种单独任务水平已达到较高水平. 目标检测模型根据处理流程的不同分为以SSD[2 ] 、YOLO[3 -7 ] 系列为代表的单阶段模型与Fast R-CNN[8 ] 、Faster R-CNN[9 ] 为代表的双阶段模型. 单阶段目标检测模型是端到端的方法,直接在输入图像上生成目标的边界框和类别标签;双阶段目标检测方法须通过感兴趣区域的分类和回归得到最终的目标检测结果. 一般来说,单阶段目标检测检测速度较快,精度相较偏低,双阶段模型与之相反,因此单阶段模型往往更符合实际需求. 在语义分割研究方面,Chen等[10 ] 提出DeepLab图像分割模型,对VGG网络(visual geometry group)进行改写,将该网络最后的2个池化层替换成空洞卷积以增加感受野,引入条件随机场以提高分割精度. 为了适应不同分辨率的目标,Lin等[11 ] 提出RefineNet,以多路径的方式提取网络特征,利用多级抽象特征进行高分辨率的语义分割,以递归方式细化低分辨语义特征和细粒度低级语义特征,生成高分辨率特征;Zhao等[12 ] 提出的PSPNet利用金字塔池提取多尺度特征以提升检测性能. 为了提高网络实时性能,BiSeNet[13 ] 利用空间路径和上下文路径双支结构,解决空间信息丢失和感受野收缩问题. Fan等[14 ] 提出短期密集级联网络(short-term dense concatenate network, STDC),使用较少的参数提取多尺度特征,改进BiSeNet中的多路径结构,在提取底层细节特征的同时减少网络计算量. 在车道检测中,LaneNet[15 ] 使用语义分割与像素聚类方法,进一步提高小目标检测准确度. ...
1
... 在交通任务场景中,现有技术处理交通目标检测、可行驶区域分割和车道线检测等3种单独任务水平已达到较高水平. 目标检测模型根据处理流程的不同分为以SSD[2 ] 、YOLO[3 -7 ] 系列为代表的单阶段模型与Fast R-CNN[8 ] 、Faster R-CNN[9 ] 为代表的双阶段模型. 单阶段目标检测模型是端到端的方法,直接在输入图像上生成目标的边界框和类别标签;双阶段目标检测方法须通过感兴趣区域的分类和回归得到最终的目标检测结果. 一般来说,单阶段目标检测检测速度较快,精度相较偏低,双阶段模型与之相反,因此单阶段模型往往更符合实际需求. 在语义分割研究方面,Chen等[10 ] 提出DeepLab图像分割模型,对VGG网络(visual geometry group)进行改写,将该网络最后的2个池化层替换成空洞卷积以增加感受野,引入条件随机场以提高分割精度. 为了适应不同分辨率的目标,Lin等[11 ] 提出RefineNet,以多路径的方式提取网络特征,利用多级抽象特征进行高分辨率的语义分割,以递归方式细化低分辨语义特征和细粒度低级语义特征,生成高分辨率特征;Zhao等[12 ] 提出的PSPNet利用金字塔池提取多尺度特征以提升检测性能. 为了提高网络实时性能,BiSeNet[13 ] 利用空间路径和上下文路径双支结构,解决空间信息丢失和感受野收缩问题. Fan等[14 ] 提出短期密集级联网络(short-term dense concatenate network, STDC),使用较少的参数提取多尺度特征,改进BiSeNet中的多路径结构,在提取底层细节特征的同时减少网络计算量. 在车道检测中,LaneNet[15 ] 使用语义分割与像素聚类方法,进一步提高小目标检测准确度. ...
2
... 在交通任务场景中,现有技术处理交通目标检测、可行驶区域分割和车道线检测等3种单独任务水平已达到较高水平. 目标检测模型根据处理流程的不同分为以SSD[2 ] 、YOLO[3 -7 ] 系列为代表的单阶段模型与Fast R-CNN[8 ] 、Faster R-CNN[9 ] 为代表的双阶段模型. 单阶段目标检测模型是端到端的方法,直接在输入图像上生成目标的边界框和类别标签;双阶段目标检测方法须通过感兴趣区域的分类和回归得到最终的目标检测结果. 一般来说,单阶段目标检测检测速度较快,精度相较偏低,双阶段模型与之相反,因此单阶段模型往往更符合实际需求. 在语义分割研究方面,Chen等[10 ] 提出DeepLab图像分割模型,对VGG网络(visual geometry group)进行改写,将该网络最后的2个池化层替换成空洞卷积以增加感受野,引入条件随机场以提高分割精度. 为了适应不同分辨率的目标,Lin等[11 ] 提出RefineNet,以多路径的方式提取网络特征,利用多级抽象特征进行高分辨率的语义分割,以递归方式细化低分辨语义特征和细粒度低级语义特征,生成高分辨率特征;Zhao等[12 ] 提出的PSPNet利用金字塔池提取多尺度特征以提升检测性能. 为了提高网络实时性能,BiSeNet[13 ] 利用空间路径和上下文路径双支结构,解决空间信息丢失和感受野收缩问题. Fan等[14 ] 提出短期密集级联网络(short-term dense concatenate network, STDC),使用较少的参数提取多尺度特征,改进BiSeNet中的多路径结构,在提取底层细节特征的同时减少网络计算量. 在车道检测中,LaneNet[15 ] 使用语义分割与像素聚类方法,进一步提高小目标检测准确度. ...
... 式中:y 为边界框带小数的真实坐标, y i y 向下取整,y i +1y 向上取整. 在语义分割损失函数的设计上,原始损失函数BCELoss容易受类别不均衡影响,将它优化为在线难样本挖掘交叉熵损失函数(online hard example mining cross-entropy loss, OhemCELoss)[14 ] 在线选择困难挖掘样本,其核心思想是在训练过程中选择损失值较大的难分样本进行模型的梯度更新,提高模型对难分样本的适应程度. OhemCELoss由交叉熵损失函数 (cross entropy loss,CELoss)改进而来: ...
1
... 在交通任务场景中,现有技术处理交通目标检测、可行驶区域分割和车道线检测等3种单独任务水平已达到较高水平. 目标检测模型根据处理流程的不同分为以SSD[2 ] 、YOLO[3 -7 ] 系列为代表的单阶段模型与Fast R-CNN[8 ] 、Faster R-CNN[9 ] 为代表的双阶段模型. 单阶段目标检测模型是端到端的方法,直接在输入图像上生成目标的边界框和类别标签;双阶段目标检测方法须通过感兴趣区域的分类和回归得到最终的目标检测结果. 一般来说,单阶段目标检测检测速度较快,精度相较偏低,双阶段模型与之相反,因此单阶段模型往往更符合实际需求. 在语义分割研究方面,Chen等[10 ] 提出DeepLab图像分割模型,对VGG网络(visual geometry group)进行改写,将该网络最后的2个池化层替换成空洞卷积以增加感受野,引入条件随机场以提高分割精度. 为了适应不同分辨率的目标,Lin等[11 ] 提出RefineNet,以多路径的方式提取网络特征,利用多级抽象特征进行高分辨率的语义分割,以递归方式细化低分辨语义特征和细粒度低级语义特征,生成高分辨率特征;Zhao等[12 ] 提出的PSPNet利用金字塔池提取多尺度特征以提升检测性能. 为了提高网络实时性能,BiSeNet[13 ] 利用空间路径和上下文路径双支结构,解决空间信息丢失和感受野收缩问题. Fan等[14 ] 提出短期密集级联网络(short-term dense concatenate network, STDC),使用较少的参数提取多尺度特征,改进BiSeNet中的多路径结构,在提取底层细节特征的同时减少网络计算量. 在车道检测中,LaneNet[15 ] 使用语义分割与像素聚类方法,进一步提高小目标检测准确度. ...
1
... 单一任务模型独立训练如交通目标检测、可行驶区域分割以及车道线检测等任务费时费力,不能挖掘任务间的潜在关系. 采用多任务模型共享主干网络的编码信息,既能够提取不同任务之间的潜在关系,又能够降低计算开销. Teichmann等[16 ] 提出的MultiNet统一了分割、检测和分类任务,实现端到端检测,但是不支持车道线检测. Qian等[17 ] 提出DLT-Net,通过上下文张量共享可行驶区域、车道线检测和交通目标之间潜在关系,但是编码器不够轻便,不利于模型实时推理. Wu等[18 ] 提出多任务网络YOLOP来同时执行3个检测任务. YOLOP由1个用于特征提取的共享编码器和3个用于处理特定任务的解码器组成,它虽然优化了编码器和解码器结构,节省了计算成本,提升了模型实时性,但是未考虑类别不均衡导致的性能下降. HybridNets[19 ] 将主干网络替换为EfficientNet-B3,颈部网络由特征金字塔网络(feature pyramid networks, FPN)替换为BiFPN,分割任务损失修改为Focal损失+Tversky损失,改善了多任务中类别不平衡问题,但是未利用全局上下文信息,致使全局空间位置信息缺失,模型的精度下降. ...
DLT-Net: joint detection of drivable areas, lane lines, and traffic objects
1
2020
... 单一任务模型独立训练如交通目标检测、可行驶区域分割以及车道线检测等任务费时费力,不能挖掘任务间的潜在关系. 采用多任务模型共享主干网络的编码信息,既能够提取不同任务之间的潜在关系,又能够降低计算开销. Teichmann等[16 ] 提出的MultiNet统一了分割、检测和分类任务,实现端到端检测,但是不支持车道线检测. Qian等[17 ] 提出DLT-Net,通过上下文张量共享可行驶区域、车道线检测和交通目标之间潜在关系,但是编码器不够轻便,不利于模型实时推理. Wu等[18 ] 提出多任务网络YOLOP来同时执行3个检测任务. YOLOP由1个用于特征提取的共享编码器和3个用于处理特定任务的解码器组成,它虽然优化了编码器和解码器结构,节省了计算成本,提升了模型实时性,但是未考虑类别不均衡导致的性能下降. HybridNets[19 ] 将主干网络替换为EfficientNet-B3,颈部网络由特征金字塔网络(feature pyramid networks, FPN)替换为BiFPN,分割任务损失修改为Focal损失+Tversky损失,改善了多任务中类别不平衡问题,但是未利用全局上下文信息,致使全局空间位置信息缺失,模型的精度下降. ...
YOLOP: you only look once for panoptic driving perception
1
2022
... 单一任务模型独立训练如交通目标检测、可行驶区域分割以及车道线检测等任务费时费力,不能挖掘任务间的潜在关系. 采用多任务模型共享主干网络的编码信息,既能够提取不同任务之间的潜在关系,又能够降低计算开销. Teichmann等[16 ] 提出的MultiNet统一了分割、检测和分类任务,实现端到端检测,但是不支持车道线检测. Qian等[17 ] 提出DLT-Net,通过上下文张量共享可行驶区域、车道线检测和交通目标之间潜在关系,但是编码器不够轻便,不利于模型实时推理. Wu等[18 ] 提出多任务网络YOLOP来同时执行3个检测任务. YOLOP由1个用于特征提取的共享编码器和3个用于处理特定任务的解码器组成,它虽然优化了编码器和解码器结构,节省了计算成本,提升了模型实时性,但是未考虑类别不均衡导致的性能下降. HybridNets[19 ] 将主干网络替换为EfficientNet-B3,颈部网络由特征金字塔网络(feature pyramid networks, FPN)替换为BiFPN,分割任务损失修改为Focal损失+Tversky损失,改善了多任务中类别不平衡问题,但是未利用全局上下文信息,致使全局空间位置信息缺失,模型的精度下降. ...
1
... 单一任务模型独立训练如交通目标检测、可行驶区域分割以及车道线检测等任务费时费力,不能挖掘任务间的潜在关系. 采用多任务模型共享主干网络的编码信息,既能够提取不同任务之间的潜在关系,又能够降低计算开销. Teichmann等[16 ] 提出的MultiNet统一了分割、检测和分类任务,实现端到端检测,但是不支持车道线检测. Qian等[17 ] 提出DLT-Net,通过上下文张量共享可行驶区域、车道线检测和交通目标之间潜在关系,但是编码器不够轻便,不利于模型实时推理. Wu等[18 ] 提出多任务网络YOLOP来同时执行3个检测任务. YOLOP由1个用于特征提取的共享编码器和3个用于处理特定任务的解码器组成,它虽然优化了编码器和解码器结构,节省了计算成本,提升了模型实时性,但是未考虑类别不均衡导致的性能下降. HybridNets[19 ] 将主干网络替换为EfficientNet-B3,颈部网络由特征金字塔网络(feature pyramid networks, FPN)替换为BiFPN,分割任务损失修改为Focal损失+Tversky损失,改善了多任务中类别不平衡问题,但是未利用全局上下文信息,致使全局空间位置信息缺失,模型的精度下降. ...
1
... 本研究提出基于轴向注意力的,能够同时处理交通目标检测、可行驶区域分割、车道线检测的多任务自动驾驶环境感知算法T-YOLOP. 虽然Transformer框架在计算机视觉领域取得颇多先进成果 [20 -22 ] ,但是高计算成本和高内存须限制该框架在实时性模型中的应用. 本研究以轴向注意力机制代替Transformer,分别从水平、垂直方向作注意力,将全局信息处理能力引入编码器. 为了降低融合过程中不同尺度之间的语义冲突,设计自适应权重融合模块(adaptive fusion module,AFM),通过空间注意力实现自适应不同尺度信息,使用三维注意力精准定位交通目标. 采用轻量检测头进一步提高模型的实时性. 针对真实交通场景中道路类别和背景类别不平衡的问题,重新设计加权损失函数. ...
1
... 本研究提出基于轴向注意力的,能够同时处理交通目标检测、可行驶区域分割、车道线检测的多任务自动驾驶环境感知算法T-YOLOP. 虽然Transformer框架在计算机视觉领域取得颇多先进成果 [20 -22 ] ,但是高计算成本和高内存须限制该框架在实时性模型中的应用. 本研究以轴向注意力机制代替Transformer,分别从水平、垂直方向作注意力,将全局信息处理能力引入编码器. 为了降低融合过程中不同尺度之间的语义冲突,设计自适应权重融合模块(adaptive fusion module,AFM),通过空间注意力实现自适应不同尺度信息,使用三维注意力精准定位交通目标. 采用轻量检测头进一步提高模型的实时性. 针对真实交通场景中道路类别和背景类别不平衡的问题,重新设计加权损失函数. ...
1
... 在真实驾驶场景中,微小物体、狭长道路和细窄车道线难以提取足够的高级语义信息和空间细节信息,如何在高效提取特征的同时保持模型轻量化成为亟待解决的问题. Sea-Former[23 ] 中的Sea-Attention模块用轴向注意力机制代替传统的自注意力机制,兼顾了全局信息处理能力和低计算开销. 如图2 所示为Sea-Attention模块结构,输入特征X C ×H ×W, 经过3个1×1卷积分别生成查询矩阵Q、 K V Q K C qk ×H ×W ,V C v ×H ×W . 分别沿着水平和垂直方向提取轴向压缩信息,压缩公式分别为 ...
1
... 特征融合层对骨干网络提取的特征通常使用对尺度进行融合,PANet[24 ] 为自顶向下和自底向上的双向融合结构,但是不同尺度的特征不相同,简单拼接不能够适应不同尺寸的特征差异. 进行PANet结构调整:在自顶向下特征融合过程中,采用自适应权重融合模块(adaptive-weight fusion module, AFM)代替原来的堆叠和卷积操作,利用类似空间注意力模块(spatial attention module, SAM)[25 ] 的空间注意力机制寻找网络中最重要的部分. 通过低层细节信息与高层语义信息的交互,加强不同尺度特征图之间的信息交流,提高模型的检测能力. 如图4 所示为基于空间注意力机制的AFM. 小尺度特征图经过双线性插值上采样到与大特征图同样的大小,分别对2个特征图进行最大池化和平均池化,获取图像空间特征. 接着通过1×1卷积降维生成权重矩阵,由Sigmoid函数将权重矩阵映射到0~1.0. 之后左分支输入特征乘以权重矩阵,右分支输入特征经上采样后乘以(1 −权重均矩阵),将得到的2个加权后的特征相加的到融合后结果. AFM的主要作用是在特征解码生成特征图,融合来自不同来源的特征信息,通过自适应计算2个特征层权重得到较优的融合方式. ...
1
... 特征融合层对骨干网络提取的特征通常使用对尺度进行融合,PANet[24 ] 为自顶向下和自底向上的双向融合结构,但是不同尺度的特征不相同,简单拼接不能够适应不同尺寸的特征差异. 进行PANet结构调整:在自顶向下特征融合过程中,采用自适应权重融合模块(adaptive-weight fusion module, AFM)代替原来的堆叠和卷积操作,利用类似空间注意力模块(spatial attention module, SAM)[25 ] 的空间注意力机制寻找网络中最重要的部分. 通过低层细节信息与高层语义信息的交互,加强不同尺度特征图之间的信息交流,提高模型的检测能力. 如图4 所示为基于空间注意力机制的AFM. 小尺度特征图经过双线性插值上采样到与大特征图同样的大小,分别对2个特征图进行最大池化和平均池化,获取图像空间特征. 接着通过1×1卷积降维生成权重矩阵,由Sigmoid函数将权重矩阵映射到0~1.0. 之后左分支输入特征乘以权重矩阵,右分支输入特征经上采样后乘以(1 −权重均矩阵),将得到的2个加权后的特征相加的到融合后结果. AFM的主要作用是在特征解码生成特征图,融合来自不同来源的特征信息,通过自适应计算2个特征层权重得到较优的融合方式. ...
1
... 在真实交通场景中,交通目标样本分布极不平衡,在网络中加入注意力机制可以帮助模型过滤图片中大量无效信息,提取有用的关注对象,提升检测精度. 在网络中集成SimAM[26 ] 三维注意力机制,可以提升检测头的抽象特征理解能力,进一步提高检测精度. 如图5 所示,SimAM三维注意力机制根据输入特征中的参数推理出特征映射所需的三维注意力权重,再经过Sigmoid函数后与原始特征图逐元素相乘,实现特征的自适应细化. SimAM基于神经元间的重要性定义能量函数,用于推导三维注意力权重. 最小能量函数计算式为 ...
1
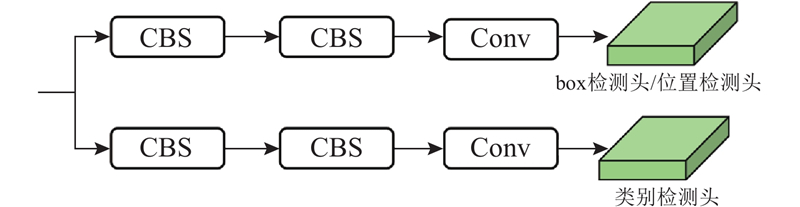
... 为了实现快速推理,2个分割头均由3个卷积层组成,双线性插值上采样得到输入网络的图像大小. 考虑到车道线是较为细小的目标,在主干网络P2层引入补偿信息,以增强特征表达. 在检测头方面,采用无锚框的范式[27 -28 ] ,结合如图6 所示的解耦检测头方法在预测前解耦分类和定位的特征表达,降低两者在预测时的冲突,提升目标检测任务中识别准确率. ...
Complete and accurate holly fruits counting using YOLOX object detection
1
2022
... 为了实现快速推理,2个分割头均由3个卷积层组成,双线性插值上采样得到输入网络的图像大小. 考虑到车道线是较为细小的目标,在主干网络P2层引入补偿信息,以增强特征表达. 在检测头方面,采用无锚框的范式[27 -28 ] ,结合如图6 所示的解耦检测头方法在预测前解耦分类和定位的特征表达,降低两者在预测时的冲突,提升目标检测任务中识别准确率. ...
Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection
1
2020
... 式中:$ {{{L}}_{{\text{box}}}} $ $ {{{L}}_{{\text{dfl}}}} $ $ {{{L}}_{{\text{cls}}}} $ $ {\lambda _{{\text{box}}}} $ $ {\lambda _{{\text{dfl}}}} $ $ {\lambda _{{\text{cls}}}} $ $ {{{L}}_{{\text{dfl}}}} $ $ {{{L}}_{{\text{box}}}} $ $ {{{L}}_{{\text{cls}}}} $ $ {\lambda _{{\text{box}}}} $ $ {\lambda _{{\text{dfl}}}} $ [29 ] . ...
1
... 利用可视化技术梯度加权类激活映射(gradient weighted class activation mapping, Grad-CAM)[30 ] 对各子任务重点区域进行可视化操作,注意力关注区域细节如图10 所示. Grad-CAM的优点是可以对训练好的权重中任意一层进行可视化,为了展示在主干网络中加入Sea-Attention模块前后各子任务的效果差异,将对3个子任务的检测层的第一层进行可视化操作. 由图10 (b)可以看出,加入Sea-Attention后算法对交通目标的关注更加集中,交通目标检测中的前后景的区别能力得到改善. 由图10 (c)可以看出,加入Sea-Attention后算法在可驾驶区域的关注更加重视当前行驶车道,说明Sea-Attention加入提高了算法提取车道高级语义信息的能力. 由图10 (d)可以看出,加入Sea-Attention后,注意力更加重视车道线位置,提高算法对车道线的识别准确度. ...












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}