[1]
DENG C, LUO X, WANG W Multiple frame splicing and degradation learning for hyperspectral imagery super-resolution
[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , 2022 , 15 : 8389 - 8401
DOI:10.1109/JSTARS.2022.3207777
[本文引用: 1]
[2]
MA J, LIU S, CHENG S, et al STSRNet: self-texture transfer super-resolution and refocusing network
[J]. IEEE Transactions on Medical Imaging , 2022 , 41 (2 ): 383 - 393
DOI:10.1109/TMI.2021.3112923
[本文引用: 1]
[3]
ZHAO Z, ZHANG Y, LI C, et al Thermal UAV image super-resolution guided by multiple visible cues
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2023 , 61 : 5000314
[本文引用: 1]
[4]
DONG C, LOY C C, HE K, et al Image super-resolution using deep convolutional networks
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2016 , 38 (2 ): 295 - 307
DOI:10.1109/TPAMI.2015.2439281
[本文引用: 1]
[5]
KIM J, LEE J K, LEE K M. Accurate image super-resolution using very deep convolutional networks [C]// IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 1646–1654.
[本文引用: 1]
[6]
ZHANG Y, TIAN Y, KONG Y, et al. Residual dense network for image super-resolution [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 2472–2481.
[本文引用: 3]
[7]
HU J, SHEN L, SUN G. Squeeze-and-excitation networks [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 7132–7141.
[本文引用: 3]
[8]
LIM B, SON S, KIM H, et al. Enhanced deep residual networks for single image super-resolution [C]// IEEE Conference on Computer Vision and Pattern Recognition Workshops . Honolulu: IEEE, 2017: 1132–1140.
[本文引用: 3]
[9]
VASWANI A, SHAZEER N M, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems . California: Curran Associates Inc., 2017: 6000–6010.
[本文引用: 2]
[10]
LIANG J, CAO J, SUN G, et al. SwinIR: image restoration using swin transformer [C]// IEEE/CVF International Conference on Computer Vision Workshops . Montreal: IEEE, 2021: 1833–1844.
[本文引用: 7]
[11]
CHU X, TIAN Z, WANG Y, et al. Twins: revisiting the design of spatial attention in vision transformers [J]. Advances in Neural Information Processing Systems. 2021, 34: 9355–9366.
[本文引用: 1]
[12]
YANG R, MA H, WU J, et al. ScalableViT: rethinking the context-oriented generalization of vision transformer [C]// Proceedings of Computer Vision – ECCV 2022 . Cham: Springer, 2022: 480–496.
[本文引用: 2]
[13]
CARION N, MASSA F, SYNNAEVE G, et al. End-to-end object detection with transformers [C]// Proceedings of Computer Vision – ECCV 2020 . Cham: Springer, 2020: 213–229.
[本文引用: 1]
[14]
BEAL J, KIM E, TZENG E, et al. Toward Transformer-Based Object Detection [EB/OL]. (2020−12−17) [2025−09−15]. https://doi.org/10.48550/arXiv.2012.09958.
[本文引用: 1]
[15]
PENG Z, HUANG W, GU S, et al. Conformer: local features coupling global representations for visual recognition [C]// 2021 IEEE/CVF International Conference on Computer Vision (ICCV) . Montreal: IEEE, 2021: 357−366.
[本文引用: 2]
[16]
WANG H, CHEN X, NI B, et al. Omni aggregation networks for lightweight image super-resolution [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Vancouver: IEEE, 2023: 22378–22387.
[本文引用: 2]
[17]
HUI Z, GAO X, YANG Y, et al. Lightweight image super-resolution with information multi-distillation network [C]// 27th ACM International Conference on Multimedia . [S.l.]: ACM, 2019: 2024−2032.
[本文引用: 5]
[18]
JI J, ZHONG B, WU Q, et al A channel-wise multi-scale network for single image super-resolution
[J]. IEEE Signal Processing Letters , 2024 , 31 : 805 - 809
DOI:10.1109/LSP.2024.3372781
[本文引用: 1]
[19]
WANG X, JI H, SHI C, et al. Heterogeneous Graph Attention Network [C]// The World Wide Web Conference . San Francisco: [s.n.], 2019: 2022–2032.
[本文引用: 6]
[20]
LI X, DONG J, TANG J, et al. DLGSANet: lightweight dynamic local and global self-attention network for image super-resolution [C]// IEEE/CVF International Conference on Computer Vision . Paris: IEEE, 2023: 12746–12755.
[本文引用: 1]
[21]
LIN H, CHENG X, WU X, et al. CAT: cross attention in vision transformer [C]// IEEE International Conference on Multimedia and Expo . Taipei: IEEE, 2022: 1–6.
[本文引用: 1]
[22]
CHEN Z, ZHANG Y, GU J, et al. Recursive Generalization Transformer for Image Super-Resolution [EB/OL]. (2023−03−11) [2025−09−15]. https://doi.org/10.48550/arXiv.2303.06373.
[本文引用: 1]
[23]
KINGMA D, BA J. Adam: a method for stochastic optimization [EB/OL]. (2014−12−14) [2025−09−15]. https://doi.org/10.48550/arXiv.1412.6980.
[本文引用: 1]
[24]
AGUSTSSON E, TIMOFTE R. NTIRE 2017 challenge on single image super-resolution: dataset and study [C]// IEEE Conference on Computer Vision and Pattern Recognition Workshops . Honolulu: IEEE, 2017: 1122–1131.
[本文引用: 1]
[25]
BEVILACQUA M, ROUMY A, GUILLEMOT C, et al. Low-complexity single-image super-resolution based on nonnegative neighbor embedding [C]// Proceedings of British Machine Vision Conference . Surrey: British Machine Vision Association, 2012.
[本文引用: 1]
[26]
ZEYDE R, ELAD M, PROTTER M. On single image scale-up using sparse-representations [C]// Proceedings of International Conference on Curves and Surfaces . Avignon: Springer, 2010: 711–730.
[本文引用: 1]
[27]
MARTIN D, FOWLKES C, TAL D, et al. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics [C]// 8th IEEE International Conference on Computer Vision . Vancouver: IEEE, 2001: 416–423.
[本文引用: 1]
[28]
HUANG J B, SINGH A, AHUJA N. Single image super-resolution from transformed self-exemplars [C]// IEEE Conference on Computer Vision and Pattern Recognition . Boston: IEEE, 2015: 5197–5206.
[本文引用: 1]
[29]
MATSUI Y, ITO K, ARAMAKI Y, et al Sketch-based manga retrieval using manga109 dataset
[J]. Multimedia Tools and Applications , 2017 , 76 (20 ): 21811 - 21838
DOI:10.1007/s11042-016-4020-z
[本文引用: 1]
[30]
WANG Z, BOVIK A C, SHEIKH H R, et al Image quality assessment: from error visibility to structural similarity
[J]. IEEE Transactions on Image Processing , 2004 , 13 (4 ): 600 - 612
DOI:10.1109/TIP.2003.819861
[本文引用: 1]
[31]
ZHANG Y, TIAN Y, KONG Y, et al. Residual dense network for image super-resolution [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 2472–2481.
[本文引用: 1]
[32]
LYN J, YAN S. Non-local Second-order attention network for single image super resolution [C]// Proceedings of International Cross-Domain Conference for Machine Learning and Knowledge Extraction . Dublin: Springer, 2020: 267–279.
[本文引用: 6]
[33]
LIU J, ZHANG W, TANG Y, et al. Residual feature aggregation network for image super-resolution [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 2356–2365.
[本文引用: 7]
[34]
MEI Y, FAN Y, ZHOU Y. Image super-resolution with non-local sparse attention [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 3516–3525.
[本文引用: 7]
[35]
ZHENG L, ZHU J, SHI J, et al Efficient mixed transformer for single image super-resolution
[J]. Engineering Applications of Artificial Intelligence , 2024 , 133 : 108035
DOI:10.1016/j.engappai.2024.108035
[本文引用: 4]
[36]
HWANG K, YOON G, SONG J, et al Fusing bi-directional global–local features for single image super-resolution
[J]. Engineering Applications of Artificial Intelligence , 2024 , 127 : 107336
DOI:10.1016/j.engappai.2023.107336
[本文引用: 4]
[37]
JI J, ZHONG B, WU Q, et al A channel-wise multi-scale network for single image super-resolution
[J]. IEEE Signal Processing Letters , 2024 , 31 : 805 - 809
DOI:10.1109/LSP.2024.3372781
[本文引用: 5]
Multiple frame splicing and degradation learning for hyperspectral imagery super-resolution
1
2022
... 单幅图像超分辨率(single image super resolution, SISR)重建旨在将一幅低分辨率(low resolution, LR)图像恢复成高分辨率(high resolution,HR)图像. SISR可以解决图像纹理丢失、色彩失真或重影模糊等问题,已广泛应用在卫星遥感[1 ] 、医学影像[2 ] 和无人机等领域[3 ] . ...
STSRNet: self-texture transfer super-resolution and refocusing network
1
2022
... 单幅图像超分辨率(single image super resolution, SISR)重建旨在将一幅低分辨率(low resolution, LR)图像恢复成高分辨率(high resolution,HR)图像. SISR可以解决图像纹理丢失、色彩失真或重影模糊等问题,已广泛应用在卫星遥感[1 ] 、医学影像[2 ] 和无人机等领域[3 ] . ...
Thermal UAV image super-resolution guided by multiple visible cues
1
2023
... 单幅图像超分辨率(single image super resolution, SISR)重建旨在将一幅低分辨率(low resolution, LR)图像恢复成高分辨率(high resolution,HR)图像. SISR可以解决图像纹理丢失、色彩失真或重影模糊等问题,已广泛应用在卫星遥感[1 ] 、医学影像[2 ] 和无人机等领域[3 ] . ...
Image super-resolution using deep convolutional networks
1
2016
... 传统SISR方法重建的图像质量较低,卷积神经网络(convolutional neural network, CNN)可以提高重建质量. SRCNN[4 ] 首次将CNN应用至SISR. Kim等[5 ] 采用深度残差网络的思想构建深度网络VDSR,获得了比SRCNN更好的重建图像质量,证明加深网络深度有助于学习图像特征. RCAN[6 ] 首次将通道注意力用于图像SR,使用嵌套残差结构并自适应地调整不同通道的权重,提高了图像重建质量. SENet[7 ] 通过建模各个特征通道的重要程度,实现了对不同任务针对性的增强或者抑制. 增加网络深度、建立残差结构和注意力机制[8 ] ,在SR任务中均有着较好表现. 但是,CNN的局部机制会限制对长距离关系信息的建模效果,从而限制模型性能的提升. ...
1
... 传统SISR方法重建的图像质量较低,卷积神经网络(convolutional neural network, CNN)可以提高重建质量. SRCNN[4 ] 首次将CNN应用至SISR. Kim等[5 ] 采用深度残差网络的思想构建深度网络VDSR,获得了比SRCNN更好的重建图像质量,证明加深网络深度有助于学习图像特征. RCAN[6 ] 首次将通道注意力用于图像SR,使用嵌套残差结构并自适应地调整不同通道的权重,提高了图像重建质量. SENet[7 ] 通过建模各个特征通道的重要程度,实现了对不同任务针对性的增强或者抑制. 增加网络深度、建立残差结构和注意力机制[8 ] ,在SR任务中均有着较好表现. 但是,CNN的局部机制会限制对长距离关系信息的建模效果,从而限制模型性能的提升. ...
3
... 传统SISR方法重建的图像质量较低,卷积神经网络(convolutional neural network, CNN)可以提高重建质量. SRCNN[4 ] 首次将CNN应用至SISR. Kim等[5 ] 采用深度残差网络的思想构建深度网络VDSR,获得了比SRCNN更好的重建图像质量,证明加深网络深度有助于学习图像特征. RCAN[6 ] 首次将通道注意力用于图像SR,使用嵌套残差结构并自适应地调整不同通道的权重,提高了图像重建质量. SENet[7 ] 通过建模各个特征通道的重要程度,实现了对不同任务针对性的增强或者抑制. 增加网络深度、建立残差结构和注意力机制[8 ] ,在SR任务中均有着较好表现. 但是,CNN的局部机制会限制对长距离关系信息的建模效果,从而限制模型性能的提升. ...
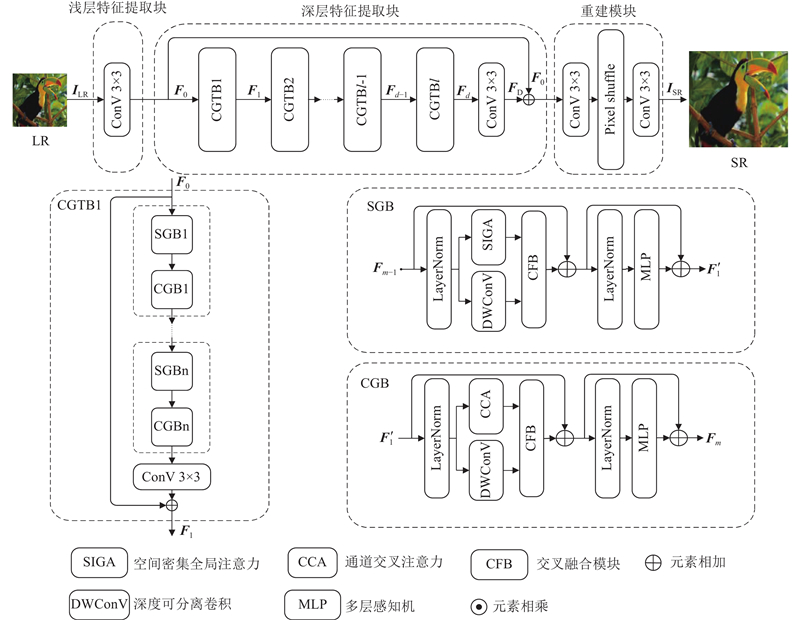
... 重建高质量图像意味着需要更多的深层语义信息. 单维度特征提取方法[6 ] 效果较差,并且随着网络加深,重要图像信息会分散在不同维度. 为了更全面地挖掘出分布于不同维度的深层次信息,在空间、通道双维度上设计CGTB,见图1 ,整体采用Transformer的注意力和前馈网络框架,参考ScalableViT[12 ] 双注意力先空间后通道的交替级联方式,从空间与通道维度建立特征聚合模块SGB与CGB. 两者采用相同结构,即深度可分离卷积并联注意力模块,接着分别连接CFB的局部分支和全局分支,最后,再通过层归一化和多层感知机MLP对各维度特征进一步整合. ...
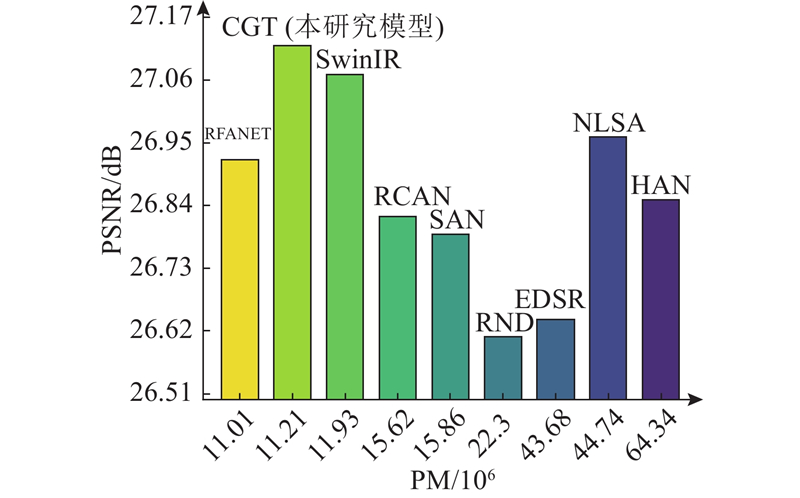
... 网络参数的大小也是衡量模型优劣的指标之一,更少的网络参数意味着更低的计算成本. 为了衡量CGT的参数量,在Urban100(×4)上,与RCAN[6 ] 、EDSR[8 ] 、SwinIR[10 ] 、HAN[19 ] 、RDN[31 ] 、SAN[32 ] 、RFANET[33 ] 和NLSA[34 ] 开展了对比测试,结果见图7 . SwinIR[10 ] 在Urban100(×4)中PSNR为27.07 dB,参数量为11.9×106 . RFANET[33 ] 虽然获得了最低的参数量,但重建效果不佳. 针对Transformer的高计算开销,CGT通过优化其核心注意力模块,并引入CNN降低计算量. CGT参数量为11.21×106 ,比SwinIR小0.69×106 ,而PSNR较之提升了0.05 dB,可见在保持较低参网络数量的同时,依旧能拥有优秀的性能表现. ...
3
... 传统SISR方法重建的图像质量较低,卷积神经网络(convolutional neural network, CNN)可以提高重建质量. SRCNN[4 ] 首次将CNN应用至SISR. Kim等[5 ] 采用深度残差网络的思想构建深度网络VDSR,获得了比SRCNN更好的重建图像质量,证明加深网络深度有助于学习图像特征. RCAN[6 ] 首次将通道注意力用于图像SR,使用嵌套残差结构并自适应地调整不同通道的权重,提高了图像重建质量. SENet[7 ] 通过建模各个特征通道的重要程度,实现了对不同任务针对性的增强或者抑制. 增加网络深度、建立残差结构和注意力机制[8 ] ,在SR任务中均有着较好表现. 但是,CNN的局部机制会限制对长距离关系信息的建模效果,从而限制模型性能的提升. ...
... 结合CNN与Transformer的优点,增强网络对高频特征因子的聚合能力,成为当下新的研究方向. DETR[13 ] 采用先CNN再Transformer的串联拼接方式. ViT-FRCNN[14 ] 采用先Transformer再CNN的串联拼接,并验证了以Transformer作为主体骨干架构可以保留足够的空间信息. Conformer[15 ] 将CNN和Transformer并联拼接,并设计特征耦合单元(feature coupling unit, FCU)实现并行融合两者特征. 上述方法均在单个维度中获取图像语义特征,空间注意力能丰富空间层次的特征表达,有助于通道与通道之间相关性建模. 通道注意力为空间提供全局通道特征信息,拓展了空间窗口的感受域[7 ] . Omni-SR[16 ] 分别从空间与通道维度建立注意力模型,2个维度的特征信息互为补充,更充分地捕获高频特征信息. 综上,利用串联或并联的方式结合CNN与Transformer可以提高SR重建质量. 不过,虽然上述CNN与Transformer结合的方法行之有效,但仍未能充分提取图像深层语义中的底层特征. ...
... Transformer注意力机制与深度可分离卷积对应的感兴趣区域特征存在显著差异,单纯增加卷积或激活分支并不能有效地耦合全局与局部特征. SENet[7 ] 沿维度压缩输入,通过卷积、激活操作自适应生成相应的权重. 受其启发,对两者分支提取到的信息流分别采取不同空间压缩策略,使用分支交叉结构设计如图4 所示的CFB. ...
3
... 传统SISR方法重建的图像质量较低,卷积神经网络(convolutional neural network, CNN)可以提高重建质量. SRCNN[4 ] 首次将CNN应用至SISR. Kim等[5 ] 采用深度残差网络的思想构建深度网络VDSR,获得了比SRCNN更好的重建图像质量,证明加深网络深度有助于学习图像特征. RCAN[6 ] 首次将通道注意力用于图像SR,使用嵌套残差结构并自适应地调整不同通道的权重,提高了图像重建质量. SENet[7 ] 通过建模各个特征通道的重要程度,实现了对不同任务针对性的增强或者抑制. 增加网络深度、建立残差结构和注意力机制[8 ] ,在SR任务中均有着较好表现. 但是,CNN的局部机制会限制对长距离关系信息的建模效果,从而限制模型性能的提升. ...
... 网络参数的大小也是衡量模型优劣的指标之一,更少的网络参数意味着更低的计算成本. 为了衡量CGT的参数量,在Urban100(×4)上,与RCAN[6 ] 、EDSR[8 ] 、SwinIR[10 ] 、HAN[19 ] 、RDN[31 ] 、SAN[32 ] 、RFANET[33 ] 和NLSA[34 ] 开展了对比测试,结果见图7 . SwinIR[10 ] 在Urban100(×4)中PSNR为27.07 dB,参数量为11.9×106 . RFANET[33 ] 虽然获得了最低的参数量,但重建效果不佳. 针对Transformer的高计算开销,CGT通过优化其核心注意力模块,并引入CNN降低计算量. CGT参数量为11.21×106 ,比SwinIR小0.69×106 ,而PSNR较之提升了0.05 dB,可见在保持较低参网络数量的同时,依旧能拥有优秀的性能表现. ...
... 如图8 ~10 所示为CGT与不同先进算法重建图像的细节对比. 左侧为原高清图像,右侧部分为不同方法重建图像红框部分放大图,包括原图、Bicubic、IMDN[16 ] 、EDSR[8 ] 、SAN[32 ] 、SwinIR-S[10 ] 、RFANet[33 ] 和CGT. 主观视觉上,图8 (b)~(f)重建的纵向斜纹细节均存在明显缺失,图8 (g)左上角的纵向斜纹重建不充分,视觉上CGT对纹理和边缘细节的恢复比其余方法更为清晰;图9 (b)~(g)均存在不同程度的边缘扭曲;图10 (b)~(g)的远处物体边缘轮廓均表现出不同程度的模糊和伪影. 通过对比各方法重建后的图像,展示了CGT能更有效地恢复图像的边缘以及局部纹理细节,且恢复的图像更接近原图. 综上,通过定量与定性比较与分析,验证了本研究提出的CNN与Transformer驱动的双维度融合方法的有效性. ...
2
... Transformer[9 ] 的自注意力机制能够有效捕获全局关系,此特性在SR任务中比CNN表现更优. SwinIR[10 ] 采用空间窗口注意和移位操作,将滑动窗口策略引入Transformer用于SR任务. Chu等[11 ] 提出在空间维度中可分离的注意力模型,分别计算各局部空间的自注意力,再利用全局自注意力机制对其进行融合. Yang等[12 ] 采用分层结构交替排列2个不同的注意力模块,沿着2个维度运行以更高效地获取特征信息. 然而,Transformer对局部信息的处理能力较弱,往往忽略一些至关重要的图像局部表征. ...
... Transformer[9 ] 早期应用于自然语言、处理序列相关的任务. 近几年被应用于视觉领域,并有着出色的性能表现. Transformer的核心为注意力机制,激活函数以softmax为例时,SISR数学模型为 ...
7
... Transformer[9 ] 的自注意力机制能够有效捕获全局关系,此特性在SR任务中比CNN表现更优. SwinIR[10 ] 采用空间窗口注意和移位操作,将滑动窗口策略引入Transformer用于SR任务. Chu等[11 ] 提出在空间维度中可分离的注意力模型,分别计算各局部空间的自注意力,再利用全局自注意力机制对其进行融合. Yang等[12 ] 采用分层结构交替排列2个不同的注意力模块,沿着2个维度运行以更高效地获取特征信息. 然而,Transformer对局部信息的处理能力较弱,往往忽略一些至关重要的图像局部表征. ...
... 式中:${H_{{\text{CGT}}{{\text{B}}_l}}}\left( \cdot \right)$ $l$ ${{\boldsymbol{F}}_{\text{d}}}$ $l$ [10 ] 相同,在CGTB最后引入一个3×3卷积层以细化每个块内提取的特征,并且每个CGTB内部也采用残差连接提高网络稠密程度. 提取深层特征为 ...
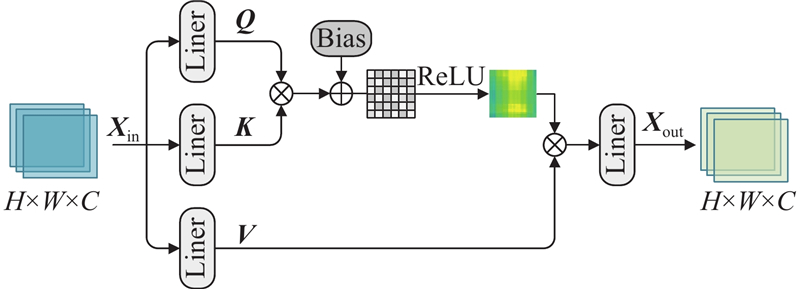
... 空间注意力旨在从空间维度赋予相关性较高的区域更高的关注度,而非平等考虑图像中的所有空间区域. 现有的空间注意力模块使用Softmax激活函数,用以保持查询矩阵${\boldsymbol{Q}}$ $ {\boldsymbol{K }}$ ${\boldsymbol{Q}}$ ${\boldsymbol{ K}} $ [20 ] . 在空间注意力模块的基础上,使用ReLU搭建SIGA,结构见图2 . 同时,为了提高空间维度整体特征的建模能力,保持全文上下空间信息因子有效聚合,借鉴SwinIR[10 ] 中的移位窗口操作,在SIGA中使用矩形移位窗口获取更丰富的深层空间特征. ...
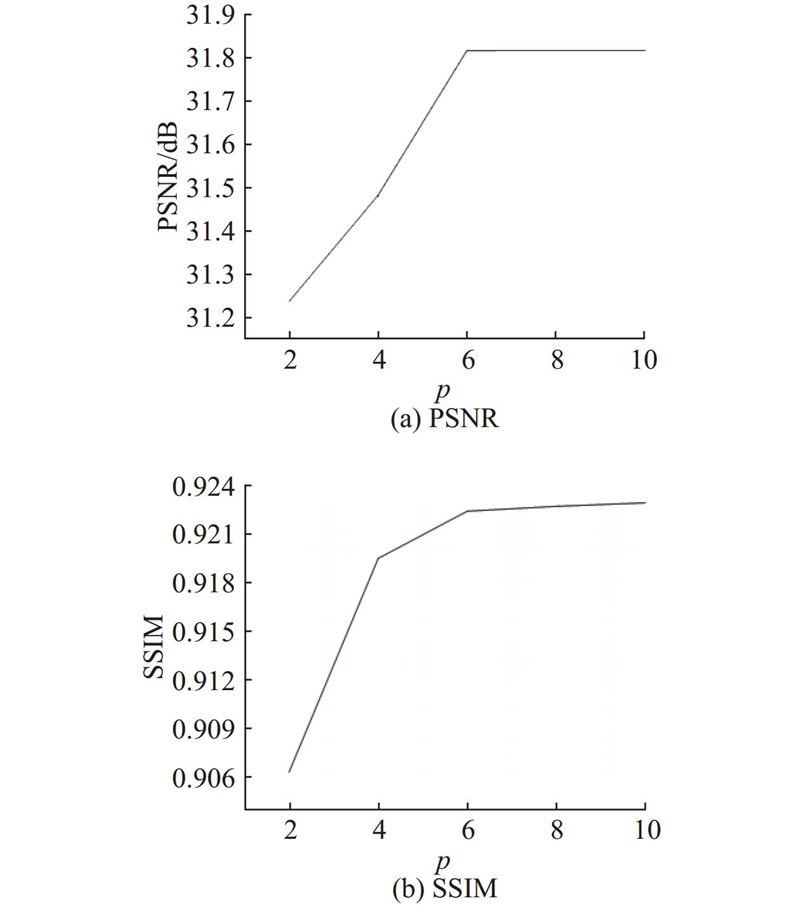
... 参考SwinIR[10 ] 先固定内部为3个“SGB+CGB”串联,仅改变CGTB层数p ,在Manga109(×4)上测试,结果如图5 和表1 所示. 由图5 可知,模型性能指标PSNR与SSIM均在CGTB个数为6之前上升趋势较为明显,在CGTB层数超过6时,虽然性能指标仍在上升但变化趋势较为缓慢. ...
... 网络参数的大小也是衡量模型优劣的指标之一,更少的网络参数意味着更低的计算成本. 为了衡量CGT的参数量,在Urban100(×4)上,与RCAN[6 ] 、EDSR[8 ] 、SwinIR[10 ] 、HAN[19 ] 、RDN[31 ] 、SAN[32 ] 、RFANET[33 ] 和NLSA[34 ] 开展了对比测试,结果见图7 . SwinIR[10 ] 在Urban100(×4)中PSNR为27.07 dB,参数量为11.9×106 . RFANET[33 ] 虽然获得了最低的参数量,但重建效果不佳. 针对Transformer的高计算开销,CGT通过优化其核心注意力模块,并引入CNN降低计算量. CGT参数量为11.21×106 ,比SwinIR小0.69×106 ,而PSNR较之提升了0.05 dB,可见在保持较低参网络数量的同时,依旧能拥有优秀的性能表现. ...
... [10 ]在Urban100(×4)中PSNR为27.07 dB,参数量为11.9×106 . RFANET[33 ] 虽然获得了最低的参数量,但重建效果不佳. 针对Transformer的高计算开销,CGT通过优化其核心注意力模块,并引入CNN降低计算量. CGT参数量为11.21×106 ,比SwinIR小0.69×106 ,而PSNR较之提升了0.05 dB,可见在保持较低参网络数量的同时,依旧能拥有优秀的性能表现. ...
... 如图8 ~10 所示为CGT与不同先进算法重建图像的细节对比. 左侧为原高清图像,右侧部分为不同方法重建图像红框部分放大图,包括原图、Bicubic、IMDN[16 ] 、EDSR[8 ] 、SAN[32 ] 、SwinIR-S[10 ] 、RFANet[33 ] 和CGT. 主观视觉上,图8 (b)~(f)重建的纵向斜纹细节均存在明显缺失,图8 (g)左上角的纵向斜纹重建不充分,视觉上CGT对纹理和边缘细节的恢复比其余方法更为清晰;图9 (b)~(g)均存在不同程度的边缘扭曲;图10 (b)~(g)的远处物体边缘轮廓均表现出不同程度的模糊和伪影. 通过对比各方法重建后的图像,展示了CGT能更有效地恢复图像的边缘以及局部纹理细节,且恢复的图像更接近原图. 综上,通过定量与定性比较与分析,验证了本研究提出的CNN与Transformer驱动的双维度融合方法的有效性. ...
1
... Transformer[9 ] 的自注意力机制能够有效捕获全局关系,此特性在SR任务中比CNN表现更优. SwinIR[10 ] 采用空间窗口注意和移位操作,将滑动窗口策略引入Transformer用于SR任务. Chu等[11 ] 提出在空间维度中可分离的注意力模型,分别计算各局部空间的自注意力,再利用全局自注意力机制对其进行融合. Yang等[12 ] 采用分层结构交替排列2个不同的注意力模块,沿着2个维度运行以更高效地获取特征信息. 然而,Transformer对局部信息的处理能力较弱,往往忽略一些至关重要的图像局部表征. ...
2
... Transformer[9 ] 的自注意力机制能够有效捕获全局关系,此特性在SR任务中比CNN表现更优. SwinIR[10 ] 采用空间窗口注意和移位操作,将滑动窗口策略引入Transformer用于SR任务. Chu等[11 ] 提出在空间维度中可分离的注意力模型,分别计算各局部空间的自注意力,再利用全局自注意力机制对其进行融合. Yang等[12 ] 采用分层结构交替排列2个不同的注意力模块,沿着2个维度运行以更高效地获取特征信息. 然而,Transformer对局部信息的处理能力较弱,往往忽略一些至关重要的图像局部表征. ...
... 重建高质量图像意味着需要更多的深层语义信息. 单维度特征提取方法[6 ] 效果较差,并且随着网络加深,重要图像信息会分散在不同维度. 为了更全面地挖掘出分布于不同维度的深层次信息,在空间、通道双维度上设计CGTB,见图1 ,整体采用Transformer的注意力和前馈网络框架,参考ScalableViT[12 ] 双注意力先空间后通道的交替级联方式,从空间与通道维度建立特征聚合模块SGB与CGB. 两者采用相同结构,即深度可分离卷积并联注意力模块,接着分别连接CFB的局部分支和全局分支,最后,再通过层归一化和多层感知机MLP对各维度特征进一步整合. ...
1
... 结合CNN与Transformer的优点,增强网络对高频特征因子的聚合能力,成为当下新的研究方向. DETR[13 ] 采用先CNN再Transformer的串联拼接方式. ViT-FRCNN[14 ] 采用先Transformer再CNN的串联拼接,并验证了以Transformer作为主体骨干架构可以保留足够的空间信息. Conformer[15 ] 将CNN和Transformer并联拼接,并设计特征耦合单元(feature coupling unit, FCU)实现并行融合两者特征. 上述方法均在单个维度中获取图像语义特征,空间注意力能丰富空间层次的特征表达,有助于通道与通道之间相关性建模. 通道注意力为空间提供全局通道特征信息,拓展了空间窗口的感受域[7 ] . Omni-SR[16 ] 分别从空间与通道维度建立注意力模型,2个维度的特征信息互为补充,更充分地捕获高频特征信息. 综上,利用串联或并联的方式结合CNN与Transformer可以提高SR重建质量. 不过,虽然上述CNN与Transformer结合的方法行之有效,但仍未能充分提取图像深层语义中的底层特征. ...
1
... 结合CNN与Transformer的优点,增强网络对高频特征因子的聚合能力,成为当下新的研究方向. DETR[13 ] 采用先CNN再Transformer的串联拼接方式. ViT-FRCNN[14 ] 采用先Transformer再CNN的串联拼接,并验证了以Transformer作为主体骨干架构可以保留足够的空间信息. Conformer[15 ] 将CNN和Transformer并联拼接,并设计特征耦合单元(feature coupling unit, FCU)实现并行融合两者特征. 上述方法均在单个维度中获取图像语义特征,空间注意力能丰富空间层次的特征表达,有助于通道与通道之间相关性建模. 通道注意力为空间提供全局通道特征信息,拓展了空间窗口的感受域[7 ] . Omni-SR[16 ] 分别从空间与通道维度建立注意力模型,2个维度的特征信息互为补充,更充分地捕获高频特征信息. 综上,利用串联或并联的方式结合CNN与Transformer可以提高SR重建质量. 不过,虽然上述CNN与Transformer结合的方法行之有效,但仍未能充分提取图像深层语义中的底层特征. ...
2
... 结合CNN与Transformer的优点,增强网络对高频特征因子的聚合能力,成为当下新的研究方向. DETR[13 ] 采用先CNN再Transformer的串联拼接方式. ViT-FRCNN[14 ] 采用先Transformer再CNN的串联拼接,并验证了以Transformer作为主体骨干架构可以保留足够的空间信息. Conformer[15 ] 将CNN和Transformer并联拼接,并设计特征耦合单元(feature coupling unit, FCU)实现并行融合两者特征. 上述方法均在单个维度中获取图像语义特征,空间注意力能丰富空间层次的特征表达,有助于通道与通道之间相关性建模. 通道注意力为空间提供全局通道特征信息,拓展了空间窗口的感受域[7 ] . Omni-SR[16 ] 分别从空间与通道维度建立注意力模型,2个维度的特征信息互为补充,更充分地捕获高频特征信息. 综上,利用串联或并联的方式结合CNN与Transformer可以提高SR重建质量. 不过,虽然上述CNN与Transformer结合的方法行之有效,但仍未能充分提取图像深层语义中的底层特征. ...
... CNN的固有特性决定了它对整体特征建模能力差,而Transformer容易忽略重要的深层纹理信息. 借鉴Peng等[15 ] 的经验,将两者并联并添加融合单元FCU,设计双分支交叉融合模块CFB,增强对局部和全局特征的建模能力. ...
2
... 结合CNN与Transformer的优点,增强网络对高频特征因子的聚合能力,成为当下新的研究方向. DETR[13 ] 采用先CNN再Transformer的串联拼接方式. ViT-FRCNN[14 ] 采用先Transformer再CNN的串联拼接,并验证了以Transformer作为主体骨干架构可以保留足够的空间信息. Conformer[15 ] 将CNN和Transformer并联拼接,并设计特征耦合单元(feature coupling unit, FCU)实现并行融合两者特征. 上述方法均在单个维度中获取图像语义特征,空间注意力能丰富空间层次的特征表达,有助于通道与通道之间相关性建模. 通道注意力为空间提供全局通道特征信息,拓展了空间窗口的感受域[7 ] . Omni-SR[16 ] 分别从空间与通道维度建立注意力模型,2个维度的特征信息互为补充,更充分地捕获高频特征信息. 综上,利用串联或并联的方式结合CNN与Transformer可以提高SR重建质量. 不过,虽然上述CNN与Transformer结合的方法行之有效,但仍未能充分提取图像深层语义中的底层特征. ...
... 如图8 ~10 所示为CGT与不同先进算法重建图像的细节对比. 左侧为原高清图像,右侧部分为不同方法重建图像红框部分放大图,包括原图、Bicubic、IMDN[16 ] 、EDSR[8 ] 、SAN[32 ] 、SwinIR-S[10 ] 、RFANet[33 ] 和CGT. 主观视觉上,图8 (b)~(f)重建的纵向斜纹细节均存在明显缺失,图8 (g)左上角的纵向斜纹重建不充分,视觉上CGT对纹理和边缘细节的恢复比其余方法更为清晰;图9 (b)~(g)均存在不同程度的边缘扭曲;图10 (b)~(g)的远处物体边缘轮廓均表现出不同程度的模糊和伪影. 通过对比各方法重建后的图像,展示了CGT能更有效地恢复图像的边缘以及局部纹理细节,且恢复的图像更接近原图. 综上,通过定量与定性比较与分析,验证了本研究提出的CNN与Transformer驱动的双维度融合方法的有效性. ...
5
... 首先,定义输入图像为$ {\boldsymbol{I}}_{\text{LR}}\in {{\bf{R}}}^{H\times W\times C} $ [17 ] 、CMSN[18 ] 、HAN[19 ] ,对浅层特征提取仅使用一个3×3卷积,其结构简单且能将低级语义信息有效地映射到高维空间,实现过程为 ...
... 为了衡量CGT的重建效果,在5个数据集上开展测试,对比方法包括IMDN[17 ] 、HAN[19 ] 、SAN[32 ] 、RFANET[33 ] 、NLSA[34 ] 、EMT[35 ] 、BiGLFE[36 ] 、CMSN[37 ] 和CGT. 具体见表4 ,其中黑体字代表最优数值,斜体下划线代表次优值. 可以看出,CGT在5个数据集×2,×3和×4的比例因子下都表现优异. 与同为双注意力的NLSA[34 ] 相比,为了从高级语义中充分提取底层特征,CGT模型通过融合双维度注意力与并联深度可分离卷积的策略来实现这一目标. 与NLSA[34 ] 相比,在Urban100(×4)和Manga109(×4)中,PSNR分别提高0.27、0.39 dB. 当前最新方法CMSN[37 ] 使用多尺度通道注意力有效捕获通道维度特征,但对空间维度信息提取不充分,CGT从空间与通道双维度更全面地捕获高级局部与全局信息,从而取得了更好的重建效果,在Urban100(×2)中PSNR提高了0.83 dB,在Urban100(×4)中PSNR提高了0.68 dB. 此外,训练数据集丰富度欠佳会导致模型泛化性能下降,面对Set14与BSD100之类包含更多复杂现实场景的数据集,在比例因子为2时CGT未能表现最优. 后续将针对现实复杂场景,丰富训练数据集并优化模型结构. ...
... Comparison with advanced methods on five benchmark datasets
Tab.4 方法 年份 倍数 Set5 Set14 BSD100 Urban100 Manga109 PSNR/dB SSIM PSNR/dB SSIM PSNR/dB SSIM PSNR/dB SSIM PSNR/dB SSIM IMDN[17 ] 2019 ×2 38.00 0.9605 33.63 0.9177 32.19 0.8996 32.17 0.9283 — — HAN[19 ] 2019 ×2 38.27 0.9614 34.16 0.9217 32.41 0.9027 33.35 0.9385 39.46 0.9785 SAN[32 ] 2020 ×2 38.31 0.9620 34.07 0.9213 32.42 0.9028 33.10 0.9370 39.32 0.9792 RFANET[33 ] 2020 ×2 38.26 0.9615 34.16 0.9220 32.41 0.9026 33.33 0.9389 39.44 0.9783 NLSN[34 ] 2021 ×2 38.34 0.9618 34.08 0.9231 32.43 0.9027 33.42 0.9394 39.59 0.9789 EMT[35 ] 2024 ×2 38.29 0.9615 34.23 0.9229 32.40 0.9027 33.28 0.9385 39.59 0.9789 BiGLFE[36 ] 2024 ×2 38.15 0.9601 33.80 0.9194 32.29 0.8994 32.71 0.9329 38.96 0.9771 CMSN[37 ] 2024 ×2 38.18 0.9612 33.84 0.9195 32.30 0.9014 32.65 0.9329 39.11 0.9780 CGT(本研究模型) 2024 ×2 38.36 0.9618 34.11 0.9220 32.41 0.9026 33.48 0.9395 39.67 0.9792 IMDN[17 ] 2019 ×3 34.36 0.9270 30.32 0.8417 29.09 0.8046 28.17 0.8519 33.61 0.9445 HAN[19 ] 2019 ×3 34.75 0.9299 30.67 0.8483 29.32 0.8110 29.10 0.8705 34.48 0.9500 SAN[32 ] 2020 ×3 34.75 0.9300 30.59 0.8476 29.33 0.8112 28.93 0.8671 34.30 0.9494 RFANET[33 ] 2020 ×3 34.79 0.9300 30.67 0.8487 29.34 0.8115 29.15 0.8720 34.59 0.9506 NLSN[34 ] 2021 ×3 34.85 0.9306 30.70 0.8485 29.34 0.8117 29.25 0.8726 34.57 0.9508 EMT[35 ] 2024 ×3 34.80 0.9303 30.71 0.8489 29.33 0.8113 29.16 0.8716 34.65 0.9508 BiGLFE[36 ] 2024 ×3 34.59 0.9276 30.33 0.8449 29.24 0.8059 28.76 0.8642 34.03 0.9460 CMSN[37 ] 2024 ×3 34.62 0.9288 30.50 0.8452 29.22 0.8082 28.60 0.8612 34.12 0.9476 CGT(本研究模型) 2024 ×3 34.91 0.9308 30.75 0.8496 29.36 0.8119 29.26 0.8729 34.77 0.9514 IMDN[17 ] 2019 ×4 32.21 0.8948 28.58 0.7811 27.56 0.7353 26.04 0.7838 — — HAN[19 ] 2019 ×4 32.59 0.9000 28.87 0.7891 27.78 0.7444 26.96 0.8109 31.27 0.9184 SAN[32 ] 2020 ×4 32.64 0.9003 28.92 0.7888 27.78 0.7436 26.79 0.8068 31.18 0.9169 RFANET[33 ] 2020 ×4 32.66 0.9004 28.88 0.7894 27.79 0.7442 26.92 0.8112 31.41 0.9187 NLSN[34 ] 2021 ×4 32.64 0.9002 28.90 0.7890 27.80 0.7442 26.85 0.8094 31.42 0.9177 EMT[35 ] 2024 ×4 32.64 0.9003 28.97 0.7901 27.81 0.7441 26.98 0.8118 31.48 0.9190 BiGLFE[36 ] 2024 ×4 32.52 0.8971 28.64 0.7858 27.74 0.7377 26.60 0.8016 31.00 0.9123 CMSN[37 ] 2024 ×4 32.41 0.8975 28.77 0.7851 27.68 0.7398 26.44 0.7964 31.00 0.9133 CGT(本研究模型) 2024 ×4 32.81 0.9024 29.03 0.7921 27.85 0.7456 27.12 0.8155 31.81 0.9224
模型定量分析表明,相比于现有基于注意力的SR方法,CGT通过CFB高效融合来自注意力模块与深度可分离卷积的深层语义信息,SGB与CGB级联交互,进一步保证了模型在空间和通道维度上的深层语义信息交织互补,提高了模型整体的特征表达能力. ...
... [
17 ]
2019 ×3 34.36 0.9270 30.32 0.8417 29.09 0.8046 28.17 0.8519 33.61 0.9445 HAN[19 ] 2019 ×3 34.75 0.9299 30.67 0.8483 29.32 0.8110 29.10 0.8705 34.48 0.9500 SAN[32 ] 2020 ×3 34.75 0.9300 30.59 0.8476 29.33 0.8112 28.93 0.8671 34.30 0.9494 RFANET[33 ] 2020 ×3 34.79 0.9300 30.67 0.8487 29.34 0.8115 29.15 0.8720 34.59 0.9506 NLSN[34 ] 2021 ×3 34.85 0.9306 30.70 0.8485 29.34 0.8117 29.25 0.8726 34.57 0.9508 EMT[35 ] 2024 ×3 34.80 0.9303 30.71 0.8489 29.33 0.8113 29.16 0.8716 34.65 0.9508 BiGLFE[36 ] 2024 ×3 34.59 0.9276 30.33 0.8449 29.24 0.8059 28.76 0.8642 34.03 0.9460 CMSN[37 ] 2024 ×3 34.62 0.9288 30.50 0.8452 29.22 0.8082 28.60 0.8612 34.12 0.9476 CGT(本研究模型) 2024 ×3 34.91 0.9308 30.75 0.8496 29.36 0.8119 29.26 0.8729 34.77 0.9514 IMDN[17 ] 2019 ×4 32.21 0.8948 28.58 0.7811 27.56 0.7353 26.04 0.7838 — — HAN[19 ] 2019 ×4 32.59 0.9000 28.87 0.7891 27.78 0.7444 26.96 0.8109 31.27 0.9184 SAN[32 ] 2020 ×4 32.64 0.9003 28.92 0.7888 27.78 0.7436 26.79 0.8068 31.18 0.9169 RFANET[33 ] 2020 ×4 32.66 0.9004 28.88 0.7894 27.79 0.7442 26.92 0.8112 31.41 0.9187 NLSN[34 ] 2021 ×4 32.64 0.9002 28.90 0.7890 27.80 0.7442 26.85 0.8094 31.42 0.9177 EMT[35 ] 2024 ×4 32.64 0.9003 28.97 0.7901 27.81 0.7441 26.98 0.8118 31.48 0.9190 BiGLFE[36 ] 2024 ×4 32.52 0.8971 28.64 0.7858 27.74 0.7377 26.60 0.8016 31.00 0.9123 CMSN[37 ] 2024 ×4 32.41 0.8975 28.77 0.7851 27.68 0.7398 26.44 0.7964 31.00 0.9133 CGT(本研究模型) 2024 ×4 32.81 0.9024 29.03 0.7921 27.85 0.7456 27.12 0.8155 31.81 0.9224 模型定量分析表明,相比于现有基于注意力的SR方法,CGT通过CFB高效融合来自注意力模块与深度可分离卷积的深层语义信息,SGB与CGB级联交互,进一步保证了模型在空间和通道维度上的深层语义信息交织互补,提高了模型整体的特征表达能力. ...
... [
17 ]
2019 ×4 32.21 0.8948 28.58 0.7811 27.56 0.7353 26.04 0.7838 — — HAN[19 ] 2019 ×4 32.59 0.9000 28.87 0.7891 27.78 0.7444 26.96 0.8109 31.27 0.9184 SAN[32 ] 2020 ×4 32.64 0.9003 28.92 0.7888 27.78 0.7436 26.79 0.8068 31.18 0.9169 RFANET[33 ] 2020 ×4 32.66 0.9004 28.88 0.7894 27.79 0.7442 26.92 0.8112 31.41 0.9187 NLSN[34 ] 2021 ×4 32.64 0.9002 28.90 0.7890 27.80 0.7442 26.85 0.8094 31.42 0.9177 EMT[35 ] 2024 ×4 32.64 0.9003 28.97 0.7901 27.81 0.7441 26.98 0.8118 31.48 0.9190 BiGLFE[36 ] 2024 ×4 32.52 0.8971 28.64 0.7858 27.74 0.7377 26.60 0.8016 31.00 0.9123 CMSN[37 ] 2024 ×4 32.41 0.8975 28.77 0.7851 27.68 0.7398 26.44 0.7964 31.00 0.9133 CGT(本研究模型) 2024 ×4 32.81 0.9024 29.03 0.7921 27.85 0.7456 27.12 0.8155 31.81 0.9224 模型定量分析表明,相比于现有基于注意力的SR方法,CGT通过CFB高效融合来自注意力模块与深度可分离卷积的深层语义信息,SGB与CGB级联交互,进一步保证了模型在空间和通道维度上的深层语义信息交织互补,提高了模型整体的特征表达能力. ...
A channel-wise multi-scale network for single image super-resolution
1
2024
... 首先,定义输入图像为$ {\boldsymbol{I}}_{\text{LR}}\in {{\bf{R}}}^{H\times W\times C} $ [17 ] 、CMSN[18 ] 、HAN[19 ] ,对浅层特征提取仅使用一个3×3卷积,其结构简单且能将低级语义信息有效地映射到高维空间,实现过程为 ...
6
... 首先,定义输入图像为$ {\boldsymbol{I}}_{\text{LR}}\in {{\bf{R}}}^{H\times W\times C} $ [17 ] 、CMSN[18 ] 、HAN[19 ] ,对浅层特征提取仅使用一个3×3卷积,其结构简单且能将低级语义信息有效地映射到高维空间,实现过程为 ...
... 网络参数的大小也是衡量模型优劣的指标之一,更少的网络参数意味着更低的计算成本. 为了衡量CGT的参数量,在Urban100(×4)上,与RCAN[6 ] 、EDSR[8 ] 、SwinIR[10 ] 、HAN[19 ] 、RDN[31 ] 、SAN[32 ] 、RFANET[33 ] 和NLSA[34 ] 开展了对比测试,结果见图7 . SwinIR[10 ] 在Urban100(×4)中PSNR为27.07 dB,参数量为11.9×106 . RFANET[33 ] 虽然获得了最低的参数量,但重建效果不佳. 针对Transformer的高计算开销,CGT通过优化其核心注意力模块,并引入CNN降低计算量. CGT参数量为11.21×106 ,比SwinIR小0.69×106 ,而PSNR较之提升了0.05 dB,可见在保持较低参网络数量的同时,依旧能拥有优秀的性能表现. ...
... 为了衡量CGT的重建效果,在5个数据集上开展测试,对比方法包括IMDN[17 ] 、HAN[19 ] 、SAN[32 ] 、RFANET[33 ] 、NLSA[34 ] 、EMT[35 ] 、BiGLFE[36 ] 、CMSN[37 ] 和CGT. 具体见表4 ,其中黑体字代表最优数值,斜体下划线代表次优值. 可以看出,CGT在5个数据集×2,×3和×4的比例因子下都表现优异. 与同为双注意力的NLSA[34 ] 相比,为了从高级语义中充分提取底层特征,CGT模型通过融合双维度注意力与并联深度可分离卷积的策略来实现这一目标. 与NLSA[34 ] 相比,在Urban100(×4)和Manga109(×4)中,PSNR分别提高0.27、0.39 dB. 当前最新方法CMSN[37 ] 使用多尺度通道注意力有效捕获通道维度特征,但对空间维度信息提取不充分,CGT从空间与通道双维度更全面地捕获高级局部与全局信息,从而取得了更好的重建效果,在Urban100(×2)中PSNR提高了0.83 dB,在Urban100(×4)中PSNR提高了0.68 dB. 此外,训练数据集丰富度欠佳会导致模型泛化性能下降,面对Set14与BSD100之类包含更多复杂现实场景的数据集,在比例因子为2时CGT未能表现最优. 后续将针对现实复杂场景,丰富训练数据集并优化模型结构. ...
... Comparison with advanced methods on five benchmark datasets
Tab.4 方法 年份 倍数 Set5 Set14 BSD100 Urban100 Manga109 PSNR/dB SSIM PSNR/dB SSIM PSNR/dB SSIM PSNR/dB SSIM PSNR/dB SSIM IMDN[17 ] 2019 ×2 38.00 0.9605 33.63 0.9177 32.19 0.8996 32.17 0.9283 — — HAN[19 ] 2019 ×2 38.27 0.9614 34.16 0.9217 32.41 0.9027 33.35 0.9385 39.46 0.9785 SAN[32 ] 2020 ×2 38.31 0.9620 34.07 0.9213 32.42 0.9028 33.10 0.9370 39.32 0.9792 RFANET[33 ] 2020 ×2 38.26 0.9615 34.16 0.9220 32.41 0.9026 33.33 0.9389 39.44 0.9783 NLSN[34 ] 2021 ×2 38.34 0.9618 34.08 0.9231 32.43 0.9027 33.42 0.9394 39.59 0.9789 EMT[35 ] 2024 ×2 38.29 0.9615 34.23 0.9229 32.40 0.9027 33.28 0.9385 39.59 0.9789 BiGLFE[36 ] 2024 ×2 38.15 0.9601 33.80 0.9194 32.29 0.8994 32.71 0.9329 38.96 0.9771 CMSN[37 ] 2024 ×2 38.18 0.9612 33.84 0.9195 32.30 0.9014 32.65 0.9329 39.11 0.9780 CGT(本研究模型) 2024 ×2 38.36 0.9618 34.11 0.9220 32.41 0.9026 33.48 0.9395 39.67 0.9792 IMDN[17 ] 2019 ×3 34.36 0.9270 30.32 0.8417 29.09 0.8046 28.17 0.8519 33.61 0.9445 HAN[19 ] 2019 ×3 34.75 0.9299 30.67 0.8483 29.32 0.8110 29.10 0.8705 34.48 0.9500 SAN[32 ] 2020 ×3 34.75 0.9300 30.59 0.8476 29.33 0.8112 28.93 0.8671 34.30 0.9494 RFANET[33 ] 2020 ×3 34.79 0.9300 30.67 0.8487 29.34 0.8115 29.15 0.8720 34.59 0.9506 NLSN[34 ] 2021 ×3 34.85 0.9306 30.70 0.8485 29.34 0.8117 29.25 0.8726 34.57 0.9508 EMT[35 ] 2024 ×3 34.80 0.9303 30.71 0.8489 29.33 0.8113 29.16 0.8716 34.65 0.9508 BiGLFE[36 ] 2024 ×3 34.59 0.9276 30.33 0.8449 29.24 0.8059 28.76 0.8642 34.03 0.9460 CMSN[37 ] 2024 ×3 34.62 0.9288 30.50 0.8452 29.22 0.8082 28.60 0.8612 34.12 0.9476 CGT(本研究模型) 2024 ×3 34.91 0.9308 30.75 0.8496 29.36 0.8119 29.26 0.8729 34.77 0.9514 IMDN[17 ] 2019 ×4 32.21 0.8948 28.58 0.7811 27.56 0.7353 26.04 0.7838 — — HAN[19 ] 2019 ×4 32.59 0.9000 28.87 0.7891 27.78 0.7444 26.96 0.8109 31.27 0.9184 SAN[32 ] 2020 ×4 32.64 0.9003 28.92 0.7888 27.78 0.7436 26.79 0.8068 31.18 0.9169 RFANET[33 ] 2020 ×4 32.66 0.9004 28.88 0.7894 27.79 0.7442 26.92 0.8112 31.41 0.9187 NLSN[34 ] 2021 ×4 32.64 0.9002 28.90 0.7890 27.80 0.7442 26.85 0.8094 31.42 0.9177 EMT[35 ] 2024 ×4 32.64 0.9003 28.97 0.7901 27.81 0.7441 26.98 0.8118 31.48 0.9190 BiGLFE[36 ] 2024 ×4 32.52 0.8971 28.64 0.7858 27.74 0.7377 26.60 0.8016 31.00 0.9123 CMSN[37 ] 2024 ×4 32.41 0.8975 28.77 0.7851 27.68 0.7398 26.44 0.7964 31.00 0.9133 CGT(本研究模型) 2024 ×4 32.81 0.9024 29.03 0.7921 27.85 0.7456 27.12 0.8155 31.81 0.9224
模型定量分析表明,相比于现有基于注意力的SR方法,CGT通过CFB高效融合来自注意力模块与深度可分离卷积的深层语义信息,SGB与CGB级联交互,进一步保证了模型在空间和通道维度上的深层语义信息交织互补,提高了模型整体的特征表达能力. ...
... [
19 ]
2019 ×3 34.75 0.9299 30.67 0.8483 29.32 0.8110 29.10 0.8705 34.48 0.9500 SAN[32 ] 2020 ×3 34.75 0.9300 30.59 0.8476 29.33 0.8112 28.93 0.8671 34.30 0.9494 RFANET[33 ] 2020 ×3 34.79 0.9300 30.67 0.8487 29.34 0.8115 29.15 0.8720 34.59 0.9506 NLSN[34 ] 2021 ×3 34.85 0.9306 30.70 0.8485 29.34 0.8117 29.25 0.8726 34.57 0.9508 EMT[35 ] 2024 ×3 34.80 0.9303 30.71 0.8489 29.33 0.8113 29.16 0.8716 34.65 0.9508 BiGLFE[36 ] 2024 ×3 34.59 0.9276 30.33 0.8449 29.24 0.8059 28.76 0.8642 34.03 0.9460 CMSN[37 ] 2024 ×3 34.62 0.9288 30.50 0.8452 29.22 0.8082 28.60 0.8612 34.12 0.9476 CGT(本研究模型) 2024 ×3 34.91 0.9308 30.75 0.8496 29.36 0.8119 29.26 0.8729 34.77 0.9514 IMDN[17 ] 2019 ×4 32.21 0.8948 28.58 0.7811 27.56 0.7353 26.04 0.7838 — — HAN[19 ] 2019 ×4 32.59 0.9000 28.87 0.7891 27.78 0.7444 26.96 0.8109 31.27 0.9184 SAN[32 ] 2020 ×4 32.64 0.9003 28.92 0.7888 27.78 0.7436 26.79 0.8068 31.18 0.9169 RFANET[33 ] 2020 ×4 32.66 0.9004 28.88 0.7894 27.79 0.7442 26.92 0.8112 31.41 0.9187 NLSN[34 ] 2021 ×4 32.64 0.9002 28.90 0.7890 27.80 0.7442 26.85 0.8094 31.42 0.9177 EMT[35 ] 2024 ×4 32.64 0.9003 28.97 0.7901 27.81 0.7441 26.98 0.8118 31.48 0.9190 BiGLFE[36 ] 2024 ×4 32.52 0.8971 28.64 0.7858 27.74 0.7377 26.60 0.8016 31.00 0.9123 CMSN[37 ] 2024 ×4 32.41 0.8975 28.77 0.7851 27.68 0.7398 26.44 0.7964 31.00 0.9133 CGT(本研究模型) 2024 ×4 32.81 0.9024 29.03 0.7921 27.85 0.7456 27.12 0.8155 31.81 0.9224 模型定量分析表明,相比于现有基于注意力的SR方法,CGT通过CFB高效融合来自注意力模块与深度可分离卷积的深层语义信息,SGB与CGB级联交互,进一步保证了模型在空间和通道维度上的深层语义信息交织互补,提高了模型整体的特征表达能力. ...
... [
19 ]
2019 ×4 32.59 0.9000 28.87 0.7891 27.78 0.7444 26.96 0.8109 31.27 0.9184 SAN[32 ] 2020 ×4 32.64 0.9003 28.92 0.7888 27.78 0.7436 26.79 0.8068 31.18 0.9169 RFANET[33 ] 2020 ×4 32.66 0.9004 28.88 0.7894 27.79 0.7442 26.92 0.8112 31.41 0.9187 NLSN[34 ] 2021 ×4 32.64 0.9002 28.90 0.7890 27.80 0.7442 26.85 0.8094 31.42 0.9177 EMT[35 ] 2024 ×4 32.64 0.9003 28.97 0.7901 27.81 0.7441 26.98 0.8118 31.48 0.9190 BiGLFE[36 ] 2024 ×4 32.52 0.8971 28.64 0.7858 27.74 0.7377 26.60 0.8016 31.00 0.9123 CMSN[37 ] 2024 ×4 32.41 0.8975 28.77 0.7851 27.68 0.7398 26.44 0.7964 31.00 0.9133 CGT(本研究模型) 2024 ×4 32.81 0.9024 29.03 0.7921 27.85 0.7456 27.12 0.8155 31.81 0.9224 模型定量分析表明,相比于现有基于注意力的SR方法,CGT通过CFB高效融合来自注意力模块与深度可分离卷积的深层语义信息,SGB与CGB级联交互,进一步保证了模型在空间和通道维度上的深层语义信息交织互补,提高了模型整体的特征表达能力. ...
1
... 空间注意力旨在从空间维度赋予相关性较高的区域更高的关注度,而非平等考虑图像中的所有空间区域. 现有的空间注意力模块使用Softmax激活函数,用以保持查询矩阵${\boldsymbol{Q}}$ $ {\boldsymbol{K }}$ ${\boldsymbol{Q}}$ ${\boldsymbol{ K}} $ [20 ] . 在空间注意力模块的基础上,使用ReLU搭建SIGA,结构见图2 . 同时,为了提高空间维度整体特征的建模能力,保持全文上下空间信息因子有效聚合,借鉴SwinIR[10 ] 中的移位窗口操作,在SIGA中使用矩形移位窗口获取更丰富的深层空间特征. ...
1
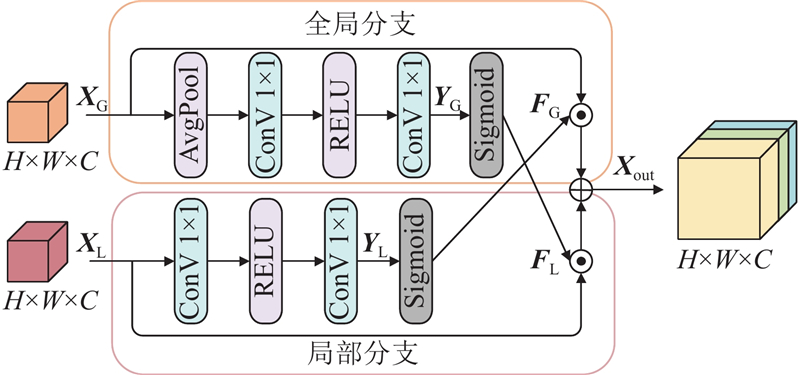
... Lin等[21 ] 提出的交叉注意力,其核心思想为在图像块内捕获特征信息而非传统的在整幅图像上捕获,不仅降低了注意力层的计算开销,同时提高了通道间特征交互信息的捕获能力,有助于减少模型计算消耗. 受其启发,为了补充空间维度通道间特征关系,本研究使用通道交叉策略构建通道交叉注意力CCA,结构见图3 . 对输入图像${\boldsymbol{X}_{\rm{in}}} \in {{{\bf{R}}}^{H \times W \times C}}$ ${\boldsymbol{Q}}$ $ {\boldsymbol{K}} $ $ {\boldsymbol{V}} $ $ {{{\bf{R}}}^{HW \times C}} $ $ {{\boldsymbol{Q}}_{\text{c}}} $ $ {{\boldsymbol{K}}_{\text{c}}} $ $ {{\boldsymbol{V}}_{\text{c}}} $
1
... 实验基于PyTorch框架,1块NVIDIA GeForce RTX 3080Ti的GPU实现. 通道维度为180,扩展因子为2,空间窗口设置成8×16,块大小(patch size)为64×64,批大小(batch size)为32,多头注意力头数为6[22 ] . 采用${L_1}$ [23 ] ($ \beta_ 1 $ $ \beta_2 $ −4 ,并在迭代次数分别为[250000 ,400000 ,450000 ,475000 ]时减半,总训练迭代次数设置成500000 . 重建的比例因子为×2、×3和×4. ...
1
... 实验基于PyTorch框架,1块NVIDIA GeForce RTX 3080Ti的GPU实现. 通道维度为180,扩展因子为2,空间窗口设置成8×16,块大小(patch size)为64×64,批大小(batch size)为32,多头注意力头数为6[22 ] . 采用${L_1}$ [23 ] ($ \beta_ 1 $ $ \beta_2 $ −4 ,并在迭代次数分别为[250000 ,400000 ,450000 ,475000 ]时减半,总训练迭代次数设置成500000 . 重建的比例因子为×2、×3和×4. ...
1
... 训练数据集DF2K,由DIV2K[24 ] 和Flick2K组成,包含3000 张分辨率为2000 的高质量图像. 除裁剪外,还进行了90°、180°、270°和水平翻转. 测试集选择5个数据集:Set5[25 ] 、Set14[26 ] 、BSD100[27 ] 、Urban100[28 ] 和Manga109[29 ] . LR图像由HR图像经过双三次退化生成. 在YCbCr色彩空间的Y通道(亮度)上计算峰值信噪比(PSNR)和结构相似度(SSIM)[30 ] . PSNR与SSIM越大,说明模型重建后的图像质量越高. ...
1
... 训练数据集DF2K,由DIV2K[24 ] 和Flick2K组成,包含3000 张分辨率为2000 的高质量图像. 除裁剪外,还进行了90°、180°、270°和水平翻转. 测试集选择5个数据集:Set5[25 ] 、Set14[26 ] 、BSD100[27 ] 、Urban100[28 ] 和Manga109[29 ] . LR图像由HR图像经过双三次退化生成. 在YCbCr色彩空间的Y通道(亮度)上计算峰值信噪比(PSNR)和结构相似度(SSIM)[30 ] . PSNR与SSIM越大,说明模型重建后的图像质量越高. ...
1
... 训练数据集DF2K,由DIV2K[24 ] 和Flick2K组成,包含3000 张分辨率为2000 的高质量图像. 除裁剪外,还进行了90°、180°、270°和水平翻转. 测试集选择5个数据集:Set5[25 ] 、Set14[26 ] 、BSD100[27 ] 、Urban100[28 ] 和Manga109[29 ] . LR图像由HR图像经过双三次退化生成. 在YCbCr色彩空间的Y通道(亮度)上计算峰值信噪比(PSNR)和结构相似度(SSIM)[30 ] . PSNR与SSIM越大,说明模型重建后的图像质量越高. ...
1
... 训练数据集DF2K,由DIV2K[24 ] 和Flick2K组成,包含3000 张分辨率为2000 的高质量图像. 除裁剪外,还进行了90°、180°、270°和水平翻转. 测试集选择5个数据集:Set5[25 ] 、Set14[26 ] 、BSD100[27 ] 、Urban100[28 ] 和Manga109[29 ] . LR图像由HR图像经过双三次退化生成. 在YCbCr色彩空间的Y通道(亮度)上计算峰值信噪比(PSNR)和结构相似度(SSIM)[30 ] . PSNR与SSIM越大,说明模型重建后的图像质量越高. ...
1
... 训练数据集DF2K,由DIV2K[24 ] 和Flick2K组成,包含3000 张分辨率为2000 的高质量图像. 除裁剪外,还进行了90°、180°、270°和水平翻转. 测试集选择5个数据集:Set5[25 ] 、Set14[26 ] 、BSD100[27 ] 、Urban100[28 ] 和Manga109[29 ] . LR图像由HR图像经过双三次退化生成. 在YCbCr色彩空间的Y通道(亮度)上计算峰值信噪比(PSNR)和结构相似度(SSIM)[30 ] . PSNR与SSIM越大,说明模型重建后的图像质量越高. ...
Sketch-based manga retrieval using manga109 dataset
1
2017
... 训练数据集DF2K,由DIV2K[24 ] 和Flick2K组成,包含3000 张分辨率为2000 的高质量图像. 除裁剪外,还进行了90°、180°、270°和水平翻转. 测试集选择5个数据集:Set5[25 ] 、Set14[26 ] 、BSD100[27 ] 、Urban100[28 ] 和Manga109[29 ] . LR图像由HR图像经过双三次退化生成. 在YCbCr色彩空间的Y通道(亮度)上计算峰值信噪比(PSNR)和结构相似度(SSIM)[30 ] . PSNR与SSIM越大,说明模型重建后的图像质量越高. ...
Image quality assessment: from error visibility to structural similarity
1
2004
... 训练数据集DF2K,由DIV2K[24 ] 和Flick2K组成,包含3000 张分辨率为2000 的高质量图像. 除裁剪外,还进行了90°、180°、270°和水平翻转. 测试集选择5个数据集:Set5[25 ] 、Set14[26 ] 、BSD100[27 ] 、Urban100[28 ] 和Manga109[29 ] . LR图像由HR图像经过双三次退化生成. 在YCbCr色彩空间的Y通道(亮度)上计算峰值信噪比(PSNR)和结构相似度(SSIM)[30 ] . PSNR与SSIM越大,说明模型重建后的图像质量越高. ...
1
... 网络参数的大小也是衡量模型优劣的指标之一,更少的网络参数意味着更低的计算成本. 为了衡量CGT的参数量,在Urban100(×4)上,与RCAN[6 ] 、EDSR[8 ] 、SwinIR[10 ] 、HAN[19 ] 、RDN[31 ] 、SAN[32 ] 、RFANET[33 ] 和NLSA[34 ] 开展了对比测试,结果见图7 . SwinIR[10 ] 在Urban100(×4)中PSNR为27.07 dB,参数量为11.9×106 . RFANET[33 ] 虽然获得了最低的参数量,但重建效果不佳. 针对Transformer的高计算开销,CGT通过优化其核心注意力模块,并引入CNN降低计算量. CGT参数量为11.21×106 ,比SwinIR小0.69×106 ,而PSNR较之提升了0.05 dB,可见在保持较低参网络数量的同时,依旧能拥有优秀的性能表现. ...
6
... 网络参数的大小也是衡量模型优劣的指标之一,更少的网络参数意味着更低的计算成本. 为了衡量CGT的参数量,在Urban100(×4)上,与RCAN[6 ] 、EDSR[8 ] 、SwinIR[10 ] 、HAN[19 ] 、RDN[31 ] 、SAN[32 ] 、RFANET[33 ] 和NLSA[34 ] 开展了对比测试,结果见图7 . SwinIR[10 ] 在Urban100(×4)中PSNR为27.07 dB,参数量为11.9×106 . RFANET[33 ] 虽然获得了最低的参数量,但重建效果不佳. 针对Transformer的高计算开销,CGT通过优化其核心注意力模块,并引入CNN降低计算量. CGT参数量为11.21×106 ,比SwinIR小0.69×106 ,而PSNR较之提升了0.05 dB,可见在保持较低参网络数量的同时,依旧能拥有优秀的性能表现. ...
... 为了衡量CGT的重建效果,在5个数据集上开展测试,对比方法包括IMDN[17 ] 、HAN[19 ] 、SAN[32 ] 、RFANET[33 ] 、NLSA[34 ] 、EMT[35 ] 、BiGLFE[36 ] 、CMSN[37 ] 和CGT. 具体见表4 ,其中黑体字代表最优数值,斜体下划线代表次优值. 可以看出,CGT在5个数据集×2,×3和×4的比例因子下都表现优异. 与同为双注意力的NLSA[34 ] 相比,为了从高级语义中充分提取底层特征,CGT模型通过融合双维度注意力与并联深度可分离卷积的策略来实现这一目标. 与NLSA[34 ] 相比,在Urban100(×4)和Manga109(×4)中,PSNR分别提高0.27、0.39 dB. 当前最新方法CMSN[37 ] 使用多尺度通道注意力有效捕获通道维度特征,但对空间维度信息提取不充分,CGT从空间与通道双维度更全面地捕获高级局部与全局信息,从而取得了更好的重建效果,在Urban100(×2)中PSNR提高了0.83 dB,在Urban100(×4)中PSNR提高了0.68 dB. 此外,训练数据集丰富度欠佳会导致模型泛化性能下降,面对Set14与BSD100之类包含更多复杂现实场景的数据集,在比例因子为2时CGT未能表现最优. 后续将针对现实复杂场景,丰富训练数据集并优化模型结构. ...
... Comparison with advanced methods on five benchmark datasets
Tab.4 方法 年份 倍数 Set5 Set14 BSD100 Urban100 Manga109 PSNR/dB SSIM PSNR/dB SSIM PSNR/dB SSIM PSNR/dB SSIM PSNR/dB SSIM IMDN[17 ] 2019 ×2 38.00 0.9605 33.63 0.9177 32.19 0.8996 32.17 0.9283 — — HAN[19 ] 2019 ×2 38.27 0.9614 34.16 0.9217 32.41 0.9027 33.35 0.9385 39.46 0.9785 SAN[32 ] 2020 ×2 38.31 0.9620 34.07 0.9213 32.42 0.9028 33.10 0.9370 39.32 0.9792 RFANET[33 ] 2020 ×2 38.26 0.9615 34.16 0.9220 32.41 0.9026 33.33 0.9389 39.44 0.9783 NLSN[34 ] 2021 ×2 38.34 0.9618 34.08 0.9231 32.43 0.9027 33.42 0.9394 39.59 0.9789 EMT[35 ] 2024 ×2 38.29 0.9615 34.23 0.9229 32.40 0.9027 33.28 0.9385 39.59 0.9789 BiGLFE[36 ] 2024 ×2 38.15 0.9601 33.80 0.9194 32.29 0.8994 32.71 0.9329 38.96 0.9771 CMSN[37 ] 2024 ×2 38.18 0.9612 33.84 0.9195 32.30 0.9014 32.65 0.9329 39.11 0.9780 CGT(本研究模型) 2024 ×2 38.36 0.9618 34.11 0.9220 32.41 0.9026 33.48 0.9395 39.67 0.9792 IMDN[17 ] 2019 ×3 34.36 0.9270 30.32 0.8417 29.09 0.8046 28.17 0.8519 33.61 0.9445 HAN[19 ] 2019 ×3 34.75 0.9299 30.67 0.8483 29.32 0.8110 29.10 0.8705 34.48 0.9500 SAN[32 ] 2020 ×3 34.75 0.9300 30.59 0.8476 29.33 0.8112 28.93 0.8671 34.30 0.9494 RFANET[33 ] 2020 ×3 34.79 0.9300 30.67 0.8487 29.34 0.8115 29.15 0.8720 34.59 0.9506 NLSN[34 ] 2021 ×3 34.85 0.9306 30.70 0.8485 29.34 0.8117 29.25 0.8726 34.57 0.9508 EMT[35 ] 2024 ×3 34.80 0.9303 30.71 0.8489 29.33 0.8113 29.16 0.8716 34.65 0.9508 BiGLFE[36 ] 2024 ×3 34.59 0.9276 30.33 0.8449 29.24 0.8059 28.76 0.8642 34.03 0.9460 CMSN[37 ] 2024 ×3 34.62 0.9288 30.50 0.8452 29.22 0.8082 28.60 0.8612 34.12 0.9476 CGT(本研究模型) 2024 ×3 34.91 0.9308 30.75 0.8496 29.36 0.8119 29.26 0.8729 34.77 0.9514 IMDN[17 ] 2019 ×4 32.21 0.8948 28.58 0.7811 27.56 0.7353 26.04 0.7838 — — HAN[19 ] 2019 ×4 32.59 0.9000 28.87 0.7891 27.78 0.7444 26.96 0.8109 31.27 0.9184 SAN[32 ] 2020 ×4 32.64 0.9003 28.92 0.7888 27.78 0.7436 26.79 0.8068 31.18 0.9169 RFANET[33 ] 2020 ×4 32.66 0.9004 28.88 0.7894 27.79 0.7442 26.92 0.8112 31.41 0.9187 NLSN[34 ] 2021 ×4 32.64 0.9002 28.90 0.7890 27.80 0.7442 26.85 0.8094 31.42 0.9177 EMT[35 ] 2024 ×4 32.64 0.9003 28.97 0.7901 27.81 0.7441 26.98 0.8118 31.48 0.9190 BiGLFE[36 ] 2024 ×4 32.52 0.8971 28.64 0.7858 27.74 0.7377 26.60 0.8016 31.00 0.9123 CMSN[37 ] 2024 ×4 32.41 0.8975 28.77 0.7851 27.68 0.7398 26.44 0.7964 31.00 0.9133 CGT(本研究模型) 2024 ×4 32.81 0.9024 29.03 0.7921 27.85 0.7456 27.12 0.8155 31.81 0.9224
模型定量分析表明,相比于现有基于注意力的SR方法,CGT通过CFB高效融合来自注意力模块与深度可分离卷积的深层语义信息,SGB与CGB级联交互,进一步保证了模型在空间和通道维度上的深层语义信息交织互补,提高了模型整体的特征表达能力. ...
... [
32 ]
2020 ×3 34.75 0.9300 30.59 0.8476 29.33 0.8112 28.93 0.8671 34.30 0.9494 RFANET[33 ] 2020 ×3 34.79 0.9300 30.67 0.8487 29.34 0.8115 29.15 0.8720 34.59 0.9506 NLSN[34 ] 2021 ×3 34.85 0.9306 30.70 0.8485 29.34 0.8117 29.25 0.8726 34.57 0.9508 EMT[35 ] 2024 ×3 34.80 0.9303 30.71 0.8489 29.33 0.8113 29.16 0.8716 34.65 0.9508 BiGLFE[36 ] 2024 ×3 34.59 0.9276 30.33 0.8449 29.24 0.8059 28.76 0.8642 34.03 0.9460 CMSN[37 ] 2024 ×3 34.62 0.9288 30.50 0.8452 29.22 0.8082 28.60 0.8612 34.12 0.9476 CGT(本研究模型) 2024 ×3 34.91 0.9308 30.75 0.8496 29.36 0.8119 29.26 0.8729 34.77 0.9514 IMDN[17 ] 2019 ×4 32.21 0.8948 28.58 0.7811 27.56 0.7353 26.04 0.7838 — — HAN[19 ] 2019 ×4 32.59 0.9000 28.87 0.7891 27.78 0.7444 26.96 0.8109 31.27 0.9184 SAN[32 ] 2020 ×4 32.64 0.9003 28.92 0.7888 27.78 0.7436 26.79 0.8068 31.18 0.9169 RFANET[33 ] 2020 ×4 32.66 0.9004 28.88 0.7894 27.79 0.7442 26.92 0.8112 31.41 0.9187 NLSN[34 ] 2021 ×4 32.64 0.9002 28.90 0.7890 27.80 0.7442 26.85 0.8094 31.42 0.9177 EMT[35 ] 2024 ×4 32.64 0.9003 28.97 0.7901 27.81 0.7441 26.98 0.8118 31.48 0.9190 BiGLFE[36 ] 2024 ×4 32.52 0.8971 28.64 0.7858 27.74 0.7377 26.60 0.8016 31.00 0.9123 CMSN[37 ] 2024 ×4 32.41 0.8975 28.77 0.7851 27.68 0.7398 26.44 0.7964 31.00 0.9133 CGT(本研究模型) 2024 ×4 32.81 0.9024 29.03 0.7921 27.85 0.7456 27.12 0.8155 31.81 0.9224 模型定量分析表明,相比于现有基于注意力的SR方法,CGT通过CFB高效融合来自注意力模块与深度可分离卷积的深层语义信息,SGB与CGB级联交互,进一步保证了模型在空间和通道维度上的深层语义信息交织互补,提高了模型整体的特征表达能力. ...
... [
32 ]
2020 ×4 32.64 0.9003 28.92 0.7888 27.78 0.7436 26.79 0.8068 31.18 0.9169 RFANET[33 ] 2020 ×4 32.66 0.9004 28.88 0.7894 27.79 0.7442 26.92 0.8112 31.41 0.9187 NLSN[34 ] 2021 ×4 32.64 0.9002 28.90 0.7890 27.80 0.7442 26.85 0.8094 31.42 0.9177 EMT[35 ] 2024 ×4 32.64 0.9003 28.97 0.7901 27.81 0.7441 26.98 0.8118 31.48 0.9190 BiGLFE[36 ] 2024 ×4 32.52 0.8971 28.64 0.7858 27.74 0.7377 26.60 0.8016 31.00 0.9123 CMSN[37 ] 2024 ×4 32.41 0.8975 28.77 0.7851 27.68 0.7398 26.44 0.7964 31.00 0.9133 CGT(本研究模型) 2024 ×4 32.81 0.9024 29.03 0.7921 27.85 0.7456 27.12 0.8155 31.81 0.9224 模型定量分析表明,相比于现有基于注意力的SR方法,CGT通过CFB高效融合来自注意力模块与深度可分离卷积的深层语义信息,SGB与CGB级联交互,进一步保证了模型在空间和通道维度上的深层语义信息交织互补,提高了模型整体的特征表达能力. ...
... 如图8 ~10 所示为CGT与不同先进算法重建图像的细节对比. 左侧为原高清图像,右侧部分为不同方法重建图像红框部分放大图,包括原图、Bicubic、IMDN[16 ] 、EDSR[8 ] 、SAN[32 ] 、SwinIR-S[10 ] 、RFANet[33 ] 和CGT. 主观视觉上,图8 (b)~(f)重建的纵向斜纹细节均存在明显缺失,图8 (g)左上角的纵向斜纹重建不充分,视觉上CGT对纹理和边缘细节的恢复比其余方法更为清晰;图9 (b)~(g)均存在不同程度的边缘扭曲;图10 (b)~(g)的远处物体边缘轮廓均表现出不同程度的模糊和伪影. 通过对比各方法重建后的图像,展示了CGT能更有效地恢复图像的边缘以及局部纹理细节,且恢复的图像更接近原图. 综上,通过定量与定性比较与分析,验证了本研究提出的CNN与Transformer驱动的双维度融合方法的有效性. ...
7
... 网络参数的大小也是衡量模型优劣的指标之一,更少的网络参数意味着更低的计算成本. 为了衡量CGT的参数量,在Urban100(×4)上,与RCAN[6 ] 、EDSR[8 ] 、SwinIR[10 ] 、HAN[19 ] 、RDN[31 ] 、SAN[32 ] 、RFANET[33 ] 和NLSA[34 ] 开展了对比测试,结果见图7 . SwinIR[10 ] 在Urban100(×4)中PSNR为27.07 dB,参数量为11.9×106 . RFANET[33 ] 虽然获得了最低的参数量,但重建效果不佳. 针对Transformer的高计算开销,CGT通过优化其核心注意力模块,并引入CNN降低计算量. CGT参数量为11.21×106 ,比SwinIR小0.69×106 ,而PSNR较之提升了0.05 dB,可见在保持较低参网络数量的同时,依旧能拥有优秀的性能表现. ...
... [33 ]虽然获得了最低的参数量,但重建效果不佳. 针对Transformer的高计算开销,CGT通过优化其核心注意力模块,并引入CNN降低计算量. CGT参数量为11.21×106 ,比SwinIR小0.69×106 ,而PSNR较之提升了0.05 dB,可见在保持较低参网络数量的同时,依旧能拥有优秀的性能表现. ...
... 为了衡量CGT的重建效果,在5个数据集上开展测试,对比方法包括IMDN[17 ] 、HAN[19 ] 、SAN[32 ] 、RFANET[33 ] 、NLSA[34 ] 、EMT[35 ] 、BiGLFE[36 ] 、CMSN[37 ] 和CGT. 具体见表4 ,其中黑体字代表最优数值,斜体下划线代表次优值. 可以看出,CGT在5个数据集×2,×3和×4的比例因子下都表现优异. 与同为双注意力的NLSA[34 ] 相比,为了从高级语义中充分提取底层特征,CGT模型通过融合双维度注意力与并联深度可分离卷积的策略来实现这一目标. 与NLSA[34 ] 相比,在Urban100(×4)和Manga109(×4)中,PSNR分别提高0.27、0.39 dB. 当前最新方法CMSN[37 ] 使用多尺度通道注意力有效捕获通道维度特征,但对空间维度信息提取不充分,CGT从空间与通道双维度更全面地捕获高级局部与全局信息,从而取得了更好的重建效果,在Urban100(×2)中PSNR提高了0.83 dB,在Urban100(×4)中PSNR提高了0.68 dB. 此外,训练数据集丰富度欠佳会导致模型泛化性能下降,面对Set14与BSD100之类包含更多复杂现实场景的数据集,在比例因子为2时CGT未能表现最优. 后续将针对现实复杂场景,丰富训练数据集并优化模型结构. ...
... Comparison with advanced methods on five benchmark datasets
Tab.4 方法 年份 倍数 Set5 Set14 BSD100 Urban100 Manga109 PSNR/dB SSIM PSNR/dB SSIM PSNR/dB SSIM PSNR/dB SSIM PSNR/dB SSIM IMDN[17 ] 2019 ×2 38.00 0.9605 33.63 0.9177 32.19 0.8996 32.17 0.9283 — — HAN[19 ] 2019 ×2 38.27 0.9614 34.16 0.9217 32.41 0.9027 33.35 0.9385 39.46 0.9785 SAN[32 ] 2020 ×2 38.31 0.9620 34.07 0.9213 32.42 0.9028 33.10 0.9370 39.32 0.9792 RFANET[33 ] 2020 ×2 38.26 0.9615 34.16 0.9220 32.41 0.9026 33.33 0.9389 39.44 0.9783 NLSN[34 ] 2021 ×2 38.34 0.9618 34.08 0.9231 32.43 0.9027 33.42 0.9394 39.59 0.9789 EMT[35 ] 2024 ×2 38.29 0.9615 34.23 0.9229 32.40 0.9027 33.28 0.9385 39.59 0.9789 BiGLFE[36 ] 2024 ×2 38.15 0.9601 33.80 0.9194 32.29 0.8994 32.71 0.9329 38.96 0.9771 CMSN[37 ] 2024 ×2 38.18 0.9612 33.84 0.9195 32.30 0.9014 32.65 0.9329 39.11 0.9780 CGT(本研究模型) 2024 ×2 38.36 0.9618 34.11 0.9220 32.41 0.9026 33.48 0.9395 39.67 0.9792 IMDN[17 ] 2019 ×3 34.36 0.9270 30.32 0.8417 29.09 0.8046 28.17 0.8519 33.61 0.9445 HAN[19 ] 2019 ×3 34.75 0.9299 30.67 0.8483 29.32 0.8110 29.10 0.8705 34.48 0.9500 SAN[32 ] 2020 ×3 34.75 0.9300 30.59 0.8476 29.33 0.8112 28.93 0.8671 34.30 0.9494 RFANET[33 ] 2020 ×3 34.79 0.9300 30.67 0.8487 29.34 0.8115 29.15 0.8720 34.59 0.9506 NLSN[34 ] 2021 ×3 34.85 0.9306 30.70 0.8485 29.34 0.8117 29.25 0.8726 34.57 0.9508 EMT[35 ] 2024 ×3 34.80 0.9303 30.71 0.8489 29.33 0.8113 29.16 0.8716 34.65 0.9508 BiGLFE[36 ] 2024 ×3 34.59 0.9276 30.33 0.8449 29.24 0.8059 28.76 0.8642 34.03 0.9460 CMSN[37 ] 2024 ×3 34.62 0.9288 30.50 0.8452 29.22 0.8082 28.60 0.8612 34.12 0.9476 CGT(本研究模型) 2024 ×3 34.91 0.9308 30.75 0.8496 29.36 0.8119 29.26 0.8729 34.77 0.9514 IMDN[17 ] 2019 ×4 32.21 0.8948 28.58 0.7811 27.56 0.7353 26.04 0.7838 — — HAN[19 ] 2019 ×4 32.59 0.9000 28.87 0.7891 27.78 0.7444 26.96 0.8109 31.27 0.9184 SAN[32 ] 2020 ×4 32.64 0.9003 28.92 0.7888 27.78 0.7436 26.79 0.8068 31.18 0.9169 RFANET[33 ] 2020 ×4 32.66 0.9004 28.88 0.7894 27.79 0.7442 26.92 0.8112 31.41 0.9187 NLSN[34 ] 2021 ×4 32.64 0.9002 28.90 0.7890 27.80 0.7442 26.85 0.8094 31.42 0.9177 EMT[35 ] 2024 ×4 32.64 0.9003 28.97 0.7901 27.81 0.7441 26.98 0.8118 31.48 0.9190 BiGLFE[36 ] 2024 ×4 32.52 0.8971 28.64 0.7858 27.74 0.7377 26.60 0.8016 31.00 0.9123 CMSN[37 ] 2024 ×4 32.41 0.8975 28.77 0.7851 27.68 0.7398 26.44 0.7964 31.00 0.9133 CGT(本研究模型) 2024 ×4 32.81 0.9024 29.03 0.7921 27.85 0.7456 27.12 0.8155 31.81 0.9224
模型定量分析表明,相比于现有基于注意力的SR方法,CGT通过CFB高效融合来自注意力模块与深度可分离卷积的深层语义信息,SGB与CGB级联交互,进一步保证了模型在空间和通道维度上的深层语义信息交织互补,提高了模型整体的特征表达能力. ...
... [
33 ]
2020 ×3 34.79 0.9300 30.67 0.8487 29.34 0.8115 29.15 0.8720 34.59 0.9506 NLSN[34 ] 2021 ×3 34.85 0.9306 30.70 0.8485 29.34 0.8117 29.25 0.8726 34.57 0.9508 EMT[35 ] 2024 ×3 34.80 0.9303 30.71 0.8489 29.33 0.8113 29.16 0.8716 34.65 0.9508 BiGLFE[36 ] 2024 ×3 34.59 0.9276 30.33 0.8449 29.24 0.8059 28.76 0.8642 34.03 0.9460 CMSN[37 ] 2024 ×3 34.62 0.9288 30.50 0.8452 29.22 0.8082 28.60 0.8612 34.12 0.9476 CGT(本研究模型) 2024 ×3 34.91 0.9308 30.75 0.8496 29.36 0.8119 29.26 0.8729 34.77 0.9514 IMDN[17 ] 2019 ×4 32.21 0.8948 28.58 0.7811 27.56 0.7353 26.04 0.7838 — — HAN[19 ] 2019 ×4 32.59 0.9000 28.87 0.7891 27.78 0.7444 26.96 0.8109 31.27 0.9184 SAN[32 ] 2020 ×4 32.64 0.9003 28.92 0.7888 27.78 0.7436 26.79 0.8068 31.18 0.9169 RFANET[33 ] 2020 ×4 32.66 0.9004 28.88 0.7894 27.79 0.7442 26.92 0.8112 31.41 0.9187 NLSN[34 ] 2021 ×4 32.64 0.9002 28.90 0.7890 27.80 0.7442 26.85 0.8094 31.42 0.9177 EMT[35 ] 2024 ×4 32.64 0.9003 28.97 0.7901 27.81 0.7441 26.98 0.8118 31.48 0.9190 BiGLFE[36 ] 2024 ×4 32.52 0.8971 28.64 0.7858 27.74 0.7377 26.60 0.8016 31.00 0.9123 CMSN[37 ] 2024 ×4 32.41 0.8975 28.77 0.7851 27.68 0.7398 26.44 0.7964 31.00 0.9133 CGT(本研究模型) 2024 ×4 32.81 0.9024 29.03 0.7921 27.85 0.7456 27.12 0.8155 31.81 0.9224 模型定量分析表明,相比于现有基于注意力的SR方法,CGT通过CFB高效融合来自注意力模块与深度可分离卷积的深层语义信息,SGB与CGB级联交互,进一步保证了模型在空间和通道维度上的深层语义信息交织互补,提高了模型整体的特征表达能力. ...
... [
33 ]
2020 ×4 32.66 0.9004 28.88 0.7894 27.79 0.7442 26.92 0.8112 31.41 0.9187 NLSN[34 ] 2021 ×4 32.64 0.9002 28.90 0.7890 27.80 0.7442 26.85 0.8094 31.42 0.9177 EMT[35 ] 2024 ×4 32.64 0.9003 28.97 0.7901 27.81 0.7441 26.98 0.8118 31.48 0.9190 BiGLFE[36 ] 2024 ×4 32.52 0.8971 28.64 0.7858 27.74 0.7377 26.60 0.8016 31.00 0.9123 CMSN[37 ] 2024 ×4 32.41 0.8975 28.77 0.7851 27.68 0.7398 26.44 0.7964 31.00 0.9133 CGT(本研究模型) 2024 ×4 32.81 0.9024 29.03 0.7921 27.85 0.7456 27.12 0.8155 31.81 0.9224 模型定量分析表明,相比于现有基于注意力的SR方法,CGT通过CFB高效融合来自注意力模块与深度可分离卷积的深层语义信息,SGB与CGB级联交互,进一步保证了模型在空间和通道维度上的深层语义信息交织互补,提高了模型整体的特征表达能力. ...
... 如图8 ~10 所示为CGT与不同先进算法重建图像的细节对比. 左侧为原高清图像,右侧部分为不同方法重建图像红框部分放大图,包括原图、Bicubic、IMDN[16 ] 、EDSR[8 ] 、SAN[32 ] 、SwinIR-S[10 ] 、RFANet[33 ] 和CGT. 主观视觉上,图8 (b)~(f)重建的纵向斜纹细节均存在明显缺失,图8 (g)左上角的纵向斜纹重建不充分,视觉上CGT对纹理和边缘细节的恢复比其余方法更为清晰;图9 (b)~(g)均存在不同程度的边缘扭曲;图10 (b)~(g)的远处物体边缘轮廓均表现出不同程度的模糊和伪影. 通过对比各方法重建后的图像,展示了CGT能更有效地恢复图像的边缘以及局部纹理细节,且恢复的图像更接近原图. 综上,通过定量与定性比较与分析,验证了本研究提出的CNN与Transformer驱动的双维度融合方法的有效性. ...
7
... 网络参数的大小也是衡量模型优劣的指标之一,更少的网络参数意味着更低的计算成本. 为了衡量CGT的参数量,在Urban100(×4)上,与RCAN[6 ] 、EDSR[8 ] 、SwinIR[10 ] 、HAN[19 ] 、RDN[31 ] 、SAN[32 ] 、RFANET[33 ] 和NLSA[34 ] 开展了对比测试,结果见图7 . SwinIR[10 ] 在Urban100(×4)中PSNR为27.07 dB,参数量为11.9×106 . RFANET[33 ] 虽然获得了最低的参数量,但重建效果不佳. 针对Transformer的高计算开销,CGT通过优化其核心注意力模块,并引入CNN降低计算量. CGT参数量为11.21×106 ,比SwinIR小0.69×106 ,而PSNR较之提升了0.05 dB,可见在保持较低参网络数量的同时,依旧能拥有优秀的性能表现. ...
... 为了衡量CGT的重建效果,在5个数据集上开展测试,对比方法包括IMDN[17 ] 、HAN[19 ] 、SAN[32 ] 、RFANET[33 ] 、NLSA[34 ] 、EMT[35 ] 、BiGLFE[36 ] 、CMSN[37 ] 和CGT. 具体见表4 ,其中黑体字代表最优数值,斜体下划线代表次优值. 可以看出,CGT在5个数据集×2,×3和×4的比例因子下都表现优异. 与同为双注意力的NLSA[34 ] 相比,为了从高级语义中充分提取底层特征,CGT模型通过融合双维度注意力与并联深度可分离卷积的策略来实现这一目标. 与NLSA[34 ] 相比,在Urban100(×4)和Manga109(×4)中,PSNR分别提高0.27、0.39 dB. 当前最新方法CMSN[37 ] 使用多尺度通道注意力有效捕获通道维度特征,但对空间维度信息提取不充分,CGT从空间与通道双维度更全面地捕获高级局部与全局信息,从而取得了更好的重建效果,在Urban100(×2)中PSNR提高了0.83 dB,在Urban100(×4)中PSNR提高了0.68 dB. 此外,训练数据集丰富度欠佳会导致模型泛化性能下降,面对Set14与BSD100之类包含更多复杂现实场景的数据集,在比例因子为2时CGT未能表现最优. 后续将针对现实复杂场景,丰富训练数据集并优化模型结构. ...
... [34 ]相比,为了从高级语义中充分提取底层特征,CGT模型通过融合双维度注意力与并联深度可分离卷积的策略来实现这一目标. 与NLSA[34 ] 相比,在Urban100(×4)和Manga109(×4)中,PSNR分别提高0.27、0.39 dB. 当前最新方法CMSN[37 ] 使用多尺度通道注意力有效捕获通道维度特征,但对空间维度信息提取不充分,CGT从空间与通道双维度更全面地捕获高级局部与全局信息,从而取得了更好的重建效果,在Urban100(×2)中PSNR提高了0.83 dB,在Urban100(×4)中PSNR提高了0.68 dB. 此外,训练数据集丰富度欠佳会导致模型泛化性能下降,面对Set14与BSD100之类包含更多复杂现实场景的数据集,在比例因子为2时CGT未能表现最优. 后续将针对现实复杂场景,丰富训练数据集并优化模型结构. ...
... [34 ]相比,在Urban100(×4)和Manga109(×4)中,PSNR分别提高0.27、0.39 dB. 当前最新方法CMSN[37 ] 使用多尺度通道注意力有效捕获通道维度特征,但对空间维度信息提取不充分,CGT从空间与通道双维度更全面地捕获高级局部与全局信息,从而取得了更好的重建效果,在Urban100(×2)中PSNR提高了0.83 dB,在Urban100(×4)中PSNR提高了0.68 dB. 此外,训练数据集丰富度欠佳会导致模型泛化性能下降,面对Set14与BSD100之类包含更多复杂现实场景的数据集,在比例因子为2时CGT未能表现最优. 后续将针对现实复杂场景,丰富训练数据集并优化模型结构. ...
... Comparison with advanced methods on five benchmark datasets
Tab.4 方法 年份 倍数 Set5 Set14 BSD100 Urban100 Manga109 PSNR/dB SSIM PSNR/dB SSIM PSNR/dB SSIM PSNR/dB SSIM PSNR/dB SSIM IMDN[17 ] 2019 ×2 38.00 0.9605 33.63 0.9177 32.19 0.8996 32.17 0.9283 — — HAN[19 ] 2019 ×2 38.27 0.9614 34.16 0.9217 32.41 0.9027 33.35 0.9385 39.46 0.9785 SAN[32 ] 2020 ×2 38.31 0.9620 34.07 0.9213 32.42 0.9028 33.10 0.9370 39.32 0.9792 RFANET[33 ] 2020 ×2 38.26 0.9615 34.16 0.9220 32.41 0.9026 33.33 0.9389 39.44 0.9783 NLSN[34 ] 2021 ×2 38.34 0.9618 34.08 0.9231 32.43 0.9027 33.42 0.9394 39.59 0.9789 EMT[35 ] 2024 ×2 38.29 0.9615 34.23 0.9229 32.40 0.9027 33.28 0.9385 39.59 0.9789 BiGLFE[36 ] 2024 ×2 38.15 0.9601 33.80 0.9194 32.29 0.8994 32.71 0.9329 38.96 0.9771 CMSN[37 ] 2024 ×2 38.18 0.9612 33.84 0.9195 32.30 0.9014 32.65 0.9329 39.11 0.9780 CGT(本研究模型) 2024 ×2 38.36 0.9618 34.11 0.9220 32.41 0.9026 33.48 0.9395 39.67 0.9792 IMDN[17 ] 2019 ×3 34.36 0.9270 30.32 0.8417 29.09 0.8046 28.17 0.8519 33.61 0.9445 HAN[19 ] 2019 ×3 34.75 0.9299 30.67 0.8483 29.32 0.8110 29.10 0.8705 34.48 0.9500 SAN[32 ] 2020 ×3 34.75 0.9300 30.59 0.8476 29.33 0.8112 28.93 0.8671 34.30 0.9494 RFANET[33 ] 2020 ×3 34.79 0.9300 30.67 0.8487 29.34 0.8115 29.15 0.8720 34.59 0.9506 NLSN[34 ] 2021 ×3 34.85 0.9306 30.70 0.8485 29.34 0.8117 29.25 0.8726 34.57 0.9508 EMT[35 ] 2024 ×3 34.80 0.9303 30.71 0.8489 29.33 0.8113 29.16 0.8716 34.65 0.9508 BiGLFE[36 ] 2024 ×3 34.59 0.9276 30.33 0.8449 29.24 0.8059 28.76 0.8642 34.03 0.9460 CMSN[37 ] 2024 ×3 34.62 0.9288 30.50 0.8452 29.22 0.8082 28.60 0.8612 34.12 0.9476 CGT(本研究模型) 2024 ×3 34.91 0.9308 30.75 0.8496 29.36 0.8119 29.26 0.8729 34.77 0.9514 IMDN[17 ] 2019 ×4 32.21 0.8948 28.58 0.7811 27.56 0.7353 26.04 0.7838 — — HAN[19 ] 2019 ×4 32.59 0.9000 28.87 0.7891 27.78 0.7444 26.96 0.8109 31.27 0.9184 SAN[32 ] 2020 ×4 32.64 0.9003 28.92 0.7888 27.78 0.7436 26.79 0.8068 31.18 0.9169 RFANET[33 ] 2020 ×4 32.66 0.9004 28.88 0.7894 27.79 0.7442 26.92 0.8112 31.41 0.9187 NLSN[34 ] 2021 ×4 32.64 0.9002 28.90 0.7890 27.80 0.7442 26.85 0.8094 31.42 0.9177 EMT[35 ] 2024 ×4 32.64 0.9003 28.97 0.7901 27.81 0.7441 26.98 0.8118 31.48 0.9190 BiGLFE[36 ] 2024 ×4 32.52 0.8971 28.64 0.7858 27.74 0.7377 26.60 0.8016 31.00 0.9123 CMSN[37 ] 2024 ×4 32.41 0.8975 28.77 0.7851 27.68 0.7398 26.44 0.7964 31.00 0.9133 CGT(本研究模型) 2024 ×4 32.81 0.9024 29.03 0.7921 27.85 0.7456 27.12 0.8155 31.81 0.9224
模型定量分析表明,相比于现有基于注意力的SR方法,CGT通过CFB高效融合来自注意力模块与深度可分离卷积的深层语义信息,SGB与CGB级联交互,进一步保证了模型在空间和通道维度上的深层语义信息交织互补,提高了模型整体的特征表达能力. ...
... [
34 ]
2021 ×3 34.85 0.9306 30.70 0.8485 29.34 0.8117 29.25 0.8726 34.57 0.9508 EMT[35 ] 2024 ×3 34.80 0.9303 30.71 0.8489 29.33 0.8113 29.16 0.8716 34.65 0.9508 BiGLFE[36 ] 2024 ×3 34.59 0.9276 30.33 0.8449 29.24 0.8059 28.76 0.8642 34.03 0.9460 CMSN[37 ] 2024 ×3 34.62 0.9288 30.50 0.8452 29.22 0.8082 28.60 0.8612 34.12 0.9476 CGT(本研究模型) 2024 ×3 34.91 0.9308 30.75 0.8496 29.36 0.8119 29.26 0.8729 34.77 0.9514 IMDN[17 ] 2019 ×4 32.21 0.8948 28.58 0.7811 27.56 0.7353 26.04 0.7838 — — HAN[19 ] 2019 ×4 32.59 0.9000 28.87 0.7891 27.78 0.7444 26.96 0.8109 31.27 0.9184 SAN[32 ] 2020 ×4 32.64 0.9003 28.92 0.7888 27.78 0.7436 26.79 0.8068 31.18 0.9169 RFANET[33 ] 2020 ×4 32.66 0.9004 28.88 0.7894 27.79 0.7442 26.92 0.8112 31.41 0.9187 NLSN[34 ] 2021 ×4 32.64 0.9002 28.90 0.7890 27.80 0.7442 26.85 0.8094 31.42 0.9177 EMT[35 ] 2024 ×4 32.64 0.9003 28.97 0.7901 27.81 0.7441 26.98 0.8118 31.48 0.9190 BiGLFE[36 ] 2024 ×4 32.52 0.8971 28.64 0.7858 27.74 0.7377 26.60 0.8016 31.00 0.9123 CMSN[37 ] 2024 ×4 32.41 0.8975 28.77 0.7851 27.68 0.7398 26.44 0.7964 31.00 0.9133 CGT(本研究模型) 2024 ×4 32.81 0.9024 29.03 0.7921 27.85 0.7456 27.12 0.8155 31.81 0.9224 模型定量分析表明,相比于现有基于注意力的SR方法,CGT通过CFB高效融合来自注意力模块与深度可分离卷积的深层语义信息,SGB与CGB级联交互,进一步保证了模型在空间和通道维度上的深层语义信息交织互补,提高了模型整体的特征表达能力. ...
... [
34 ]
2021 ×4 32.64 0.9002 28.90 0.7890 27.80 0.7442 26.85 0.8094 31.42 0.9177 EMT[35 ] 2024 ×4 32.64 0.9003 28.97 0.7901 27.81 0.7441 26.98 0.8118 31.48 0.9190 BiGLFE[36 ] 2024 ×4 32.52 0.8971 28.64 0.7858 27.74 0.7377 26.60 0.8016 31.00 0.9123 CMSN[37 ] 2024 ×4 32.41 0.8975 28.77 0.7851 27.68 0.7398 26.44 0.7964 31.00 0.9133 CGT(本研究模型) 2024 ×4 32.81 0.9024 29.03 0.7921 27.85 0.7456 27.12 0.8155 31.81 0.9224 模型定量分析表明,相比于现有基于注意力的SR方法,CGT通过CFB高效融合来自注意力模块与深度可分离卷积的深层语义信息,SGB与CGB级联交互,进一步保证了模型在空间和通道维度上的深层语义信息交织互补,提高了模型整体的特征表达能力. ...
Efficient mixed transformer for single image super-resolution
4
2024
... 为了衡量CGT的重建效果,在5个数据集上开展测试,对比方法包括IMDN[17 ] 、HAN[19 ] 、SAN[32 ] 、RFANET[33 ] 、NLSA[34 ] 、EMT[35 ] 、BiGLFE[36 ] 、CMSN[37 ] 和CGT. 具体见表4 ,其中黑体字代表最优数值,斜体下划线代表次优值. 可以看出,CGT在5个数据集×2,×3和×4的比例因子下都表现优异. 与同为双注意力的NLSA[34 ] 相比,为了从高级语义中充分提取底层特征,CGT模型通过融合双维度注意力与并联深度可分离卷积的策略来实现这一目标. 与NLSA[34 ] 相比,在Urban100(×4)和Manga109(×4)中,PSNR分别提高0.27、0.39 dB. 当前最新方法CMSN[37 ] 使用多尺度通道注意力有效捕获通道维度特征,但对空间维度信息提取不充分,CGT从空间与通道双维度更全面地捕获高级局部与全局信息,从而取得了更好的重建效果,在Urban100(×2)中PSNR提高了0.83 dB,在Urban100(×4)中PSNR提高了0.68 dB. 此外,训练数据集丰富度欠佳会导致模型泛化性能下降,面对Set14与BSD100之类包含更多复杂现实场景的数据集,在比例因子为2时CGT未能表现最优. 后续将针对现实复杂场景,丰富训练数据集并优化模型结构. ...
... Comparison with advanced methods on five benchmark datasets
Tab.4 方法 年份 倍数 Set5 Set14 BSD100 Urban100 Manga109 PSNR/dB SSIM PSNR/dB SSIM PSNR/dB SSIM PSNR/dB SSIM PSNR/dB SSIM IMDN[17 ] 2019 ×2 38.00 0.9605 33.63 0.9177 32.19 0.8996 32.17 0.9283 — — HAN[19 ] 2019 ×2 38.27 0.9614 34.16 0.9217 32.41 0.9027 33.35 0.9385 39.46 0.9785 SAN[32 ] 2020 ×2 38.31 0.9620 34.07 0.9213 32.42 0.9028 33.10 0.9370 39.32 0.9792 RFANET[33 ] 2020 ×2 38.26 0.9615 34.16 0.9220 32.41 0.9026 33.33 0.9389 39.44 0.9783 NLSN[34 ] 2021 ×2 38.34 0.9618 34.08 0.9231 32.43 0.9027 33.42 0.9394 39.59 0.9789 EMT[35 ] 2024 ×2 38.29 0.9615 34.23 0.9229 32.40 0.9027 33.28 0.9385 39.59 0.9789 BiGLFE[36 ] 2024 ×2 38.15 0.9601 33.80 0.9194 32.29 0.8994 32.71 0.9329 38.96 0.9771 CMSN[37 ] 2024 ×2 38.18 0.9612 33.84 0.9195 32.30 0.9014 32.65 0.9329 39.11 0.9780 CGT(本研究模型) 2024 ×2 38.36 0.9618 34.11 0.9220 32.41 0.9026 33.48 0.9395 39.67 0.9792 IMDN[17 ] 2019 ×3 34.36 0.9270 30.32 0.8417 29.09 0.8046 28.17 0.8519 33.61 0.9445 HAN[19 ] 2019 ×3 34.75 0.9299 30.67 0.8483 29.32 0.8110 29.10 0.8705 34.48 0.9500 SAN[32 ] 2020 ×3 34.75 0.9300 30.59 0.8476 29.33 0.8112 28.93 0.8671 34.30 0.9494 RFANET[33 ] 2020 ×3 34.79 0.9300 30.67 0.8487 29.34 0.8115 29.15 0.8720 34.59 0.9506 NLSN[34 ] 2021 ×3 34.85 0.9306 30.70 0.8485 29.34 0.8117 29.25 0.8726 34.57 0.9508 EMT[35 ] 2024 ×3 34.80 0.9303 30.71 0.8489 29.33 0.8113 29.16 0.8716 34.65 0.9508 BiGLFE[36 ] 2024 ×3 34.59 0.9276 30.33 0.8449 29.24 0.8059 28.76 0.8642 34.03 0.9460 CMSN[37 ] 2024 ×3 34.62 0.9288 30.50 0.8452 29.22 0.8082 28.60 0.8612 34.12 0.9476 CGT(本研究模型) 2024 ×3 34.91 0.9308 30.75 0.8496 29.36 0.8119 29.26 0.8729 34.77 0.9514 IMDN[17 ] 2019 ×4 32.21 0.8948 28.58 0.7811 27.56 0.7353 26.04 0.7838 — — HAN[19 ] 2019 ×4 32.59 0.9000 28.87 0.7891 27.78 0.7444 26.96 0.8109 31.27 0.9184 SAN[32 ] 2020 ×4 32.64 0.9003 28.92 0.7888 27.78 0.7436 26.79 0.8068 31.18 0.9169 RFANET[33 ] 2020 ×4 32.66 0.9004 28.88 0.7894 27.79 0.7442 26.92 0.8112 31.41 0.9187 NLSN[34 ] 2021 ×4 32.64 0.9002 28.90 0.7890 27.80 0.7442 26.85 0.8094 31.42 0.9177 EMT[35 ] 2024 ×4 32.64 0.9003 28.97 0.7901 27.81 0.7441 26.98 0.8118 31.48 0.9190 BiGLFE[36 ] 2024 ×4 32.52 0.8971 28.64 0.7858 27.74 0.7377 26.60 0.8016 31.00 0.9123 CMSN[37 ] 2024 ×4 32.41 0.8975 28.77 0.7851 27.68 0.7398 26.44 0.7964 31.00 0.9133 CGT(本研究模型) 2024 ×4 32.81 0.9024 29.03 0.7921 27.85 0.7456 27.12 0.8155 31.81 0.9224
模型定量分析表明,相比于现有基于注意力的SR方法,CGT通过CFB高效融合来自注意力模块与深度可分离卷积的深层语义信息,SGB与CGB级联交互,进一步保证了模型在空间和通道维度上的深层语义信息交织互补,提高了模型整体的特征表达能力. ...
... [
35 ]
2024 ×3 34.80 0.9303 30.71 0.8489 29.33 0.8113 29.16 0.8716 34.65 0.9508 BiGLFE[36 ] 2024 ×3 34.59 0.9276 30.33 0.8449 29.24 0.8059 28.76 0.8642 34.03 0.9460 CMSN[37 ] 2024 ×3 34.62 0.9288 30.50 0.8452 29.22 0.8082 28.60 0.8612 34.12 0.9476 CGT(本研究模型) 2024 ×3 34.91 0.9308 30.75 0.8496 29.36 0.8119 29.26 0.8729 34.77 0.9514 IMDN[17 ] 2019 ×4 32.21 0.8948 28.58 0.7811 27.56 0.7353 26.04 0.7838 — — HAN[19 ] 2019 ×4 32.59 0.9000 28.87 0.7891 27.78 0.7444 26.96 0.8109 31.27 0.9184 SAN[32 ] 2020 ×4 32.64 0.9003 28.92 0.7888 27.78 0.7436 26.79 0.8068 31.18 0.9169 RFANET[33 ] 2020 ×4 32.66 0.9004 28.88 0.7894 27.79 0.7442 26.92 0.8112 31.41 0.9187 NLSN[34 ] 2021 ×4 32.64 0.9002 28.90 0.7890 27.80 0.7442 26.85 0.8094 31.42 0.9177 EMT[35 ] 2024 ×4 32.64 0.9003 28.97 0.7901 27.81 0.7441 26.98 0.8118 31.48 0.9190 BiGLFE[36 ] 2024 ×4 32.52 0.8971 28.64 0.7858 27.74 0.7377 26.60 0.8016 31.00 0.9123 CMSN[37 ] 2024 ×4 32.41 0.8975 28.77 0.7851 27.68 0.7398 26.44 0.7964 31.00 0.9133 CGT(本研究模型) 2024 ×4 32.81 0.9024 29.03 0.7921 27.85 0.7456 27.12 0.8155 31.81 0.9224 模型定量分析表明,相比于现有基于注意力的SR方法,CGT通过CFB高效融合来自注意力模块与深度可分离卷积的深层语义信息,SGB与CGB级联交互,进一步保证了模型在空间和通道维度上的深层语义信息交织互补,提高了模型整体的特征表达能力. ...
... [
35 ]
2024 ×4 32.64 0.9003 28.97 0.7901 27.81 0.7441 26.98 0.8118 31.48 0.9190 BiGLFE[36 ] 2024 ×4 32.52 0.8971 28.64 0.7858 27.74 0.7377 26.60 0.8016 31.00 0.9123 CMSN[37 ] 2024 ×4 32.41 0.8975 28.77 0.7851 27.68 0.7398 26.44 0.7964 31.00 0.9133 CGT(本研究模型) 2024 ×4 32.81 0.9024 29.03 0.7921 27.85 0.7456 27.12 0.8155 31.81 0.9224 模型定量分析表明,相比于现有基于注意力的SR方法,CGT通过CFB高效融合来自注意力模块与深度可分离卷积的深层语义信息,SGB与CGB级联交互,进一步保证了模型在空间和通道维度上的深层语义信息交织互补,提高了模型整体的特征表达能力. ...
Fusing bi-directional global–local features for single image super-resolution
4
2024
... 为了衡量CGT的重建效果,在5个数据集上开展测试,对比方法包括IMDN[17 ] 、HAN[19 ] 、SAN[32 ] 、RFANET[33 ] 、NLSA[34 ] 、EMT[35 ] 、BiGLFE[36 ] 、CMSN[37 ] 和CGT. 具体见表4 ,其中黑体字代表最优数值,斜体下划线代表次优值. 可以看出,CGT在5个数据集×2,×3和×4的比例因子下都表现优异. 与同为双注意力的NLSA[34 ] 相比,为了从高级语义中充分提取底层特征,CGT模型通过融合双维度注意力与并联深度可分离卷积的策略来实现这一目标. 与NLSA[34 ] 相比,在Urban100(×4)和Manga109(×4)中,PSNR分别提高0.27、0.39 dB. 当前最新方法CMSN[37 ] 使用多尺度通道注意力有效捕获通道维度特征,但对空间维度信息提取不充分,CGT从空间与通道双维度更全面地捕获高级局部与全局信息,从而取得了更好的重建效果,在Urban100(×2)中PSNR提高了0.83 dB,在Urban100(×4)中PSNR提高了0.68 dB. 此外,训练数据集丰富度欠佳会导致模型泛化性能下降,面对Set14与BSD100之类包含更多复杂现实场景的数据集,在比例因子为2时CGT未能表现最优. 后续将针对现实复杂场景,丰富训练数据集并优化模型结构. ...
... Comparison with advanced methods on five benchmark datasets
Tab.4 方法 年份 倍数 Set5 Set14 BSD100 Urban100 Manga109 PSNR/dB SSIM PSNR/dB SSIM PSNR/dB SSIM PSNR/dB SSIM PSNR/dB SSIM IMDN[17 ] 2019 ×2 38.00 0.9605 33.63 0.9177 32.19 0.8996 32.17 0.9283 — — HAN[19 ] 2019 ×2 38.27 0.9614 34.16 0.9217 32.41 0.9027 33.35 0.9385 39.46 0.9785 SAN[32 ] 2020 ×2 38.31 0.9620 34.07 0.9213 32.42 0.9028 33.10 0.9370 39.32 0.9792 RFANET[33 ] 2020 ×2 38.26 0.9615 34.16 0.9220 32.41 0.9026 33.33 0.9389 39.44 0.9783 NLSN[34 ] 2021 ×2 38.34 0.9618 34.08 0.9231 32.43 0.9027 33.42 0.9394 39.59 0.9789 EMT[35 ] 2024 ×2 38.29 0.9615 34.23 0.9229 32.40 0.9027 33.28 0.9385 39.59 0.9789 BiGLFE[36 ] 2024 ×2 38.15 0.9601 33.80 0.9194 32.29 0.8994 32.71 0.9329 38.96 0.9771 CMSN[37 ] 2024 ×2 38.18 0.9612 33.84 0.9195 32.30 0.9014 32.65 0.9329 39.11 0.9780 CGT(本研究模型) 2024 ×2 38.36 0.9618 34.11 0.9220 32.41 0.9026 33.48 0.9395 39.67 0.9792 IMDN[17 ] 2019 ×3 34.36 0.9270 30.32 0.8417 29.09 0.8046 28.17 0.8519 33.61 0.9445 HAN[19 ] 2019 ×3 34.75 0.9299 30.67 0.8483 29.32 0.8110 29.10 0.8705 34.48 0.9500 SAN[32 ] 2020 ×3 34.75 0.9300 30.59 0.8476 29.33 0.8112 28.93 0.8671 34.30 0.9494 RFANET[33 ] 2020 ×3 34.79 0.9300 30.67 0.8487 29.34 0.8115 29.15 0.8720 34.59 0.9506 NLSN[34 ] 2021 ×3 34.85 0.9306 30.70 0.8485 29.34 0.8117 29.25 0.8726 34.57 0.9508 EMT[35 ] 2024 ×3 34.80 0.9303 30.71 0.8489 29.33 0.8113 29.16 0.8716 34.65 0.9508 BiGLFE[36 ] 2024 ×3 34.59 0.9276 30.33 0.8449 29.24 0.8059 28.76 0.8642 34.03 0.9460 CMSN[37 ] 2024 ×3 34.62 0.9288 30.50 0.8452 29.22 0.8082 28.60 0.8612 34.12 0.9476 CGT(本研究模型) 2024 ×3 34.91 0.9308 30.75 0.8496 29.36 0.8119 29.26 0.8729 34.77 0.9514 IMDN[17 ] 2019 ×4 32.21 0.8948 28.58 0.7811 27.56 0.7353 26.04 0.7838 — — HAN[19 ] 2019 ×4 32.59 0.9000 28.87 0.7891 27.78 0.7444 26.96 0.8109 31.27 0.9184 SAN[32 ] 2020 ×4 32.64 0.9003 28.92 0.7888 27.78 0.7436 26.79 0.8068 31.18 0.9169 RFANET[33 ] 2020 ×4 32.66 0.9004 28.88 0.7894 27.79 0.7442 26.92 0.8112 31.41 0.9187 NLSN[34 ] 2021 ×4 32.64 0.9002 28.90 0.7890 27.80 0.7442 26.85 0.8094 31.42 0.9177 EMT[35 ] 2024 ×4 32.64 0.9003 28.97 0.7901 27.81 0.7441 26.98 0.8118 31.48 0.9190 BiGLFE[36 ] 2024 ×4 32.52 0.8971 28.64 0.7858 27.74 0.7377 26.60 0.8016 31.00 0.9123 CMSN[37 ] 2024 ×4 32.41 0.8975 28.77 0.7851 27.68 0.7398 26.44 0.7964 31.00 0.9133 CGT(本研究模型) 2024 ×4 32.81 0.9024 29.03 0.7921 27.85 0.7456 27.12 0.8155 31.81 0.9224
模型定量分析表明,相比于现有基于注意力的SR方法,CGT通过CFB高效融合来自注意力模块与深度可分离卷积的深层语义信息,SGB与CGB级联交互,进一步保证了模型在空间和通道维度上的深层语义信息交织互补,提高了模型整体的特征表达能力. ...
... [
36 ]
2024 ×3 34.59 0.9276 30.33 0.8449 29.24 0.8059 28.76 0.8642 34.03 0.9460 CMSN[37 ] 2024 ×3 34.62 0.9288 30.50 0.8452 29.22 0.8082 28.60 0.8612 34.12 0.9476 CGT(本研究模型) 2024 ×3 34.91 0.9308 30.75 0.8496 29.36 0.8119 29.26 0.8729 34.77 0.9514 IMDN[17 ] 2019 ×4 32.21 0.8948 28.58 0.7811 27.56 0.7353 26.04 0.7838 — — HAN[19 ] 2019 ×4 32.59 0.9000 28.87 0.7891 27.78 0.7444 26.96 0.8109 31.27 0.9184 SAN[32 ] 2020 ×4 32.64 0.9003 28.92 0.7888 27.78 0.7436 26.79 0.8068 31.18 0.9169 RFANET[33 ] 2020 ×4 32.66 0.9004 28.88 0.7894 27.79 0.7442 26.92 0.8112 31.41 0.9187 NLSN[34 ] 2021 ×4 32.64 0.9002 28.90 0.7890 27.80 0.7442 26.85 0.8094 31.42 0.9177 EMT[35 ] 2024 ×4 32.64 0.9003 28.97 0.7901 27.81 0.7441 26.98 0.8118 31.48 0.9190 BiGLFE[36 ] 2024 ×4 32.52 0.8971 28.64 0.7858 27.74 0.7377 26.60 0.8016 31.00 0.9123 CMSN[37 ] 2024 ×4 32.41 0.8975 28.77 0.7851 27.68 0.7398 26.44 0.7964 31.00 0.9133 CGT(本研究模型) 2024 ×4 32.81 0.9024 29.03 0.7921 27.85 0.7456 27.12 0.8155 31.81 0.9224 模型定量分析表明,相比于现有基于注意力的SR方法,CGT通过CFB高效融合来自注意力模块与深度可分离卷积的深层语义信息,SGB与CGB级联交互,进一步保证了模型在空间和通道维度上的深层语义信息交织互补,提高了模型整体的特征表达能力. ...
... [
36 ]
2024 ×4 32.52 0.8971 28.64 0.7858 27.74 0.7377 26.60 0.8016 31.00 0.9123 CMSN[37 ] 2024 ×4 32.41 0.8975 28.77 0.7851 27.68 0.7398 26.44 0.7964 31.00 0.9133 CGT(本研究模型) 2024 ×4 32.81 0.9024 29.03 0.7921 27.85 0.7456 27.12 0.8155 31.81 0.9224 模型定量分析表明,相比于现有基于注意力的SR方法,CGT通过CFB高效融合来自注意力模块与深度可分离卷积的深层语义信息,SGB与CGB级联交互,进一步保证了模型在空间和通道维度上的深层语义信息交织互补,提高了模型整体的特征表达能力. ...
A channel-wise multi-scale network for single image super-resolution
5
2024
... 为了衡量CGT的重建效果,在5个数据集上开展测试,对比方法包括IMDN[17 ] 、HAN[19 ] 、SAN[32 ] 、RFANET[33 ] 、NLSA[34 ] 、EMT[35 ] 、BiGLFE[36 ] 、CMSN[37 ] 和CGT. 具体见表4 ,其中黑体字代表最优数值,斜体下划线代表次优值. 可以看出,CGT在5个数据集×2,×3和×4的比例因子下都表现优异. 与同为双注意力的NLSA[34 ] 相比,为了从高级语义中充分提取底层特征,CGT模型通过融合双维度注意力与并联深度可分离卷积的策略来实现这一目标. 与NLSA[34 ] 相比,在Urban100(×4)和Manga109(×4)中,PSNR分别提高0.27、0.39 dB. 当前最新方法CMSN[37 ] 使用多尺度通道注意力有效捕获通道维度特征,但对空间维度信息提取不充分,CGT从空间与通道双维度更全面地捕获高级局部与全局信息,从而取得了更好的重建效果,在Urban100(×2)中PSNR提高了0.83 dB,在Urban100(×4)中PSNR提高了0.68 dB. 此外,训练数据集丰富度欠佳会导致模型泛化性能下降,面对Set14与BSD100之类包含更多复杂现实场景的数据集,在比例因子为2时CGT未能表现最优. 后续将针对现实复杂场景,丰富训练数据集并优化模型结构. ...
... [37 ]使用多尺度通道注意力有效捕获通道维度特征,但对空间维度信息提取不充分,CGT从空间与通道双维度更全面地捕获高级局部与全局信息,从而取得了更好的重建效果,在Urban100(×2)中PSNR提高了0.83 dB,在Urban100(×4)中PSNR提高了0.68 dB. 此外,训练数据集丰富度欠佳会导致模型泛化性能下降,面对Set14与BSD100之类包含更多复杂现实场景的数据集,在比例因子为2时CGT未能表现最优. 后续将针对现实复杂场景,丰富训练数据集并优化模型结构. ...
... Comparison with advanced methods on five benchmark datasets
Tab.4 方法 年份 倍数 Set5 Set14 BSD100 Urban100 Manga109 PSNR/dB SSIM PSNR/dB SSIM PSNR/dB SSIM PSNR/dB SSIM PSNR/dB SSIM IMDN[17 ] 2019 ×2 38.00 0.9605 33.63 0.9177 32.19 0.8996 32.17 0.9283 — — HAN[19 ] 2019 ×2 38.27 0.9614 34.16 0.9217 32.41 0.9027 33.35 0.9385 39.46 0.9785 SAN[32 ] 2020 ×2 38.31 0.9620 34.07 0.9213 32.42 0.9028 33.10 0.9370 39.32 0.9792 RFANET[33 ] 2020 ×2 38.26 0.9615 34.16 0.9220 32.41 0.9026 33.33 0.9389 39.44 0.9783 NLSN[34 ] 2021 ×2 38.34 0.9618 34.08 0.9231 32.43 0.9027 33.42 0.9394 39.59 0.9789 EMT[35 ] 2024 ×2 38.29 0.9615 34.23 0.9229 32.40 0.9027 33.28 0.9385 39.59 0.9789 BiGLFE[36 ] 2024 ×2 38.15 0.9601 33.80 0.9194 32.29 0.8994 32.71 0.9329 38.96 0.9771 CMSN[37 ] 2024 ×2 38.18 0.9612 33.84 0.9195 32.30 0.9014 32.65 0.9329 39.11 0.9780 CGT(本研究模型) 2024 ×2 38.36 0.9618 34.11 0.9220 32.41 0.9026 33.48 0.9395 39.67 0.9792 IMDN[17 ] 2019 ×3 34.36 0.9270 30.32 0.8417 29.09 0.8046 28.17 0.8519 33.61 0.9445 HAN[19 ] 2019 ×3 34.75 0.9299 30.67 0.8483 29.32 0.8110 29.10 0.8705 34.48 0.9500 SAN[32 ] 2020 ×3 34.75 0.9300 30.59 0.8476 29.33 0.8112 28.93 0.8671 34.30 0.9494 RFANET[33 ] 2020 ×3 34.79 0.9300 30.67 0.8487 29.34 0.8115 29.15 0.8720 34.59 0.9506 NLSN[34 ] 2021 ×3 34.85 0.9306 30.70 0.8485 29.34 0.8117 29.25 0.8726 34.57 0.9508 EMT[35 ] 2024 ×3 34.80 0.9303 30.71 0.8489 29.33 0.8113 29.16 0.8716 34.65 0.9508 BiGLFE[36 ] 2024 ×3 34.59 0.9276 30.33 0.8449 29.24 0.8059 28.76 0.8642 34.03 0.9460 CMSN[37 ] 2024 ×3 34.62 0.9288 30.50 0.8452 29.22 0.8082 28.60 0.8612 34.12 0.9476 CGT(本研究模型) 2024 ×3 34.91 0.9308 30.75 0.8496 29.36 0.8119 29.26 0.8729 34.77 0.9514 IMDN[17 ] 2019 ×4 32.21 0.8948 28.58 0.7811 27.56 0.7353 26.04 0.7838 — — HAN[19 ] 2019 ×4 32.59 0.9000 28.87 0.7891 27.78 0.7444 26.96 0.8109 31.27 0.9184 SAN[32 ] 2020 ×4 32.64 0.9003 28.92 0.7888 27.78 0.7436 26.79 0.8068 31.18 0.9169 RFANET[33 ] 2020 ×4 32.66 0.9004 28.88 0.7894 27.79 0.7442 26.92 0.8112 31.41 0.9187 NLSN[34 ] 2021 ×4 32.64 0.9002 28.90 0.7890 27.80 0.7442 26.85 0.8094 31.42 0.9177 EMT[35 ] 2024 ×4 32.64 0.9003 28.97 0.7901 27.81 0.7441 26.98 0.8118 31.48 0.9190 BiGLFE[36 ] 2024 ×4 32.52 0.8971 28.64 0.7858 27.74 0.7377 26.60 0.8016 31.00 0.9123 CMSN[37 ] 2024 ×4 32.41 0.8975 28.77 0.7851 27.68 0.7398 26.44 0.7964 31.00 0.9133 CGT(本研究模型) 2024 ×4 32.81 0.9024 29.03 0.7921 27.85 0.7456 27.12 0.8155 31.81 0.9224
模型定量分析表明,相比于现有基于注意力的SR方法,CGT通过CFB高效融合来自注意力模块与深度可分离卷积的深层语义信息,SGB与CGB级联交互,进一步保证了模型在空间和通道维度上的深层语义信息交织互补,提高了模型整体的特征表达能力. ...
... [
37 ]
2024 ×3 34.62 0.9288 30.50 0.8452 29.22 0.8082 28.60 0.8612 34.12 0.9476 CGT(本研究模型) 2024 ×3 34.91 0.9308 30.75 0.8496 29.36 0.8119 29.26 0.8729 34.77 0.9514 IMDN[17 ] 2019 ×4 32.21 0.8948 28.58 0.7811 27.56 0.7353 26.04 0.7838 — — HAN[19 ] 2019 ×4 32.59 0.9000 28.87 0.7891 27.78 0.7444 26.96 0.8109 31.27 0.9184 SAN[32 ] 2020 ×4 32.64 0.9003 28.92 0.7888 27.78 0.7436 26.79 0.8068 31.18 0.9169 RFANET[33 ] 2020 ×4 32.66 0.9004 28.88 0.7894 27.79 0.7442 26.92 0.8112 31.41 0.9187 NLSN[34 ] 2021 ×4 32.64 0.9002 28.90 0.7890 27.80 0.7442 26.85 0.8094 31.42 0.9177 EMT[35 ] 2024 ×4 32.64 0.9003 28.97 0.7901 27.81 0.7441 26.98 0.8118 31.48 0.9190 BiGLFE[36 ] 2024 ×4 32.52 0.8971 28.64 0.7858 27.74 0.7377 26.60 0.8016 31.00 0.9123 CMSN[37 ] 2024 ×4 32.41 0.8975 28.77 0.7851 27.68 0.7398 26.44 0.7964 31.00 0.9133 CGT(本研究模型) 2024 ×4 32.81 0.9024 29.03 0.7921 27.85 0.7456 27.12 0.8155 31.81 0.9224 模型定量分析表明,相比于现有基于注意力的SR方法,CGT通过CFB高效融合来自注意力模块与深度可分离卷积的深层语义信息,SGB与CGB级联交互,进一步保证了模型在空间和通道维度上的深层语义信息交织互补,提高了模型整体的特征表达能力. ...
... [
37 ]
2024 ×4 32.41 0.8975 28.77 0.7851 27.68 0.7398 26.44 0.7964 31.00 0.9133 CGT(本研究模型) 2024 ×4 32.81 0.9024 29.03 0.7921 27.85 0.7456 27.12 0.8155 31.81 0.9224 模型定量分析表明,相比于现有基于注意力的SR方法,CGT通过CFB高效融合来自注意力模块与深度可分离卷积的深层语义信息,SGB与CGB级联交互,进一步保证了模型在空间和通道维度上的深层语义信息交织互补,提高了模型整体的特征表达能力. ...








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}