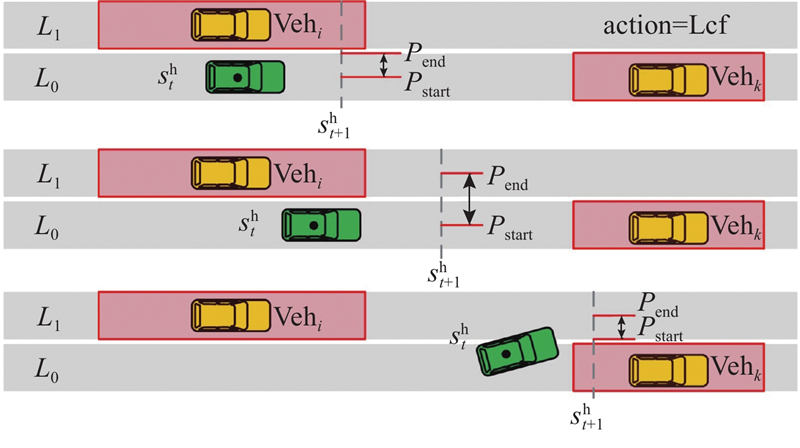
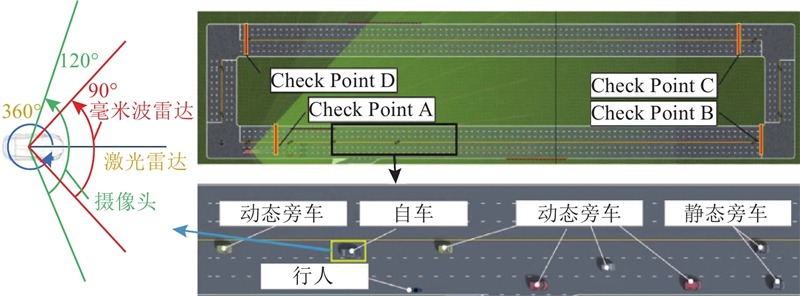
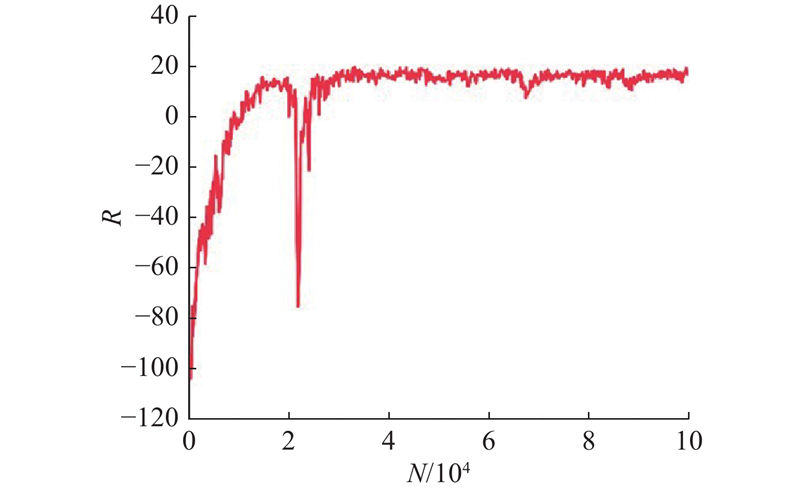
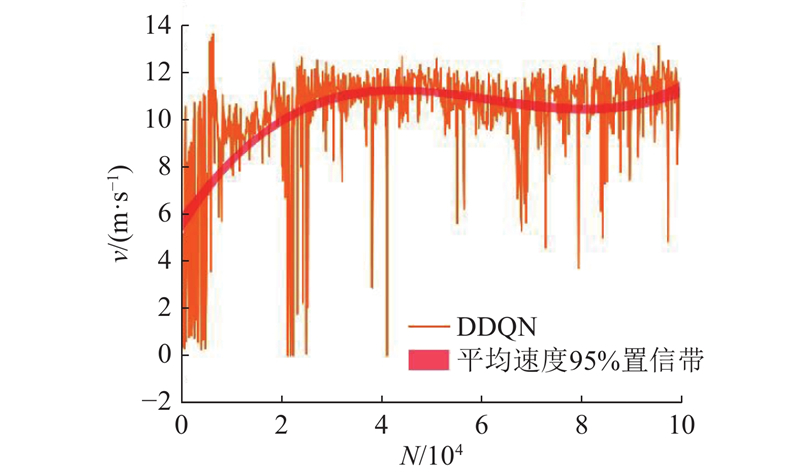
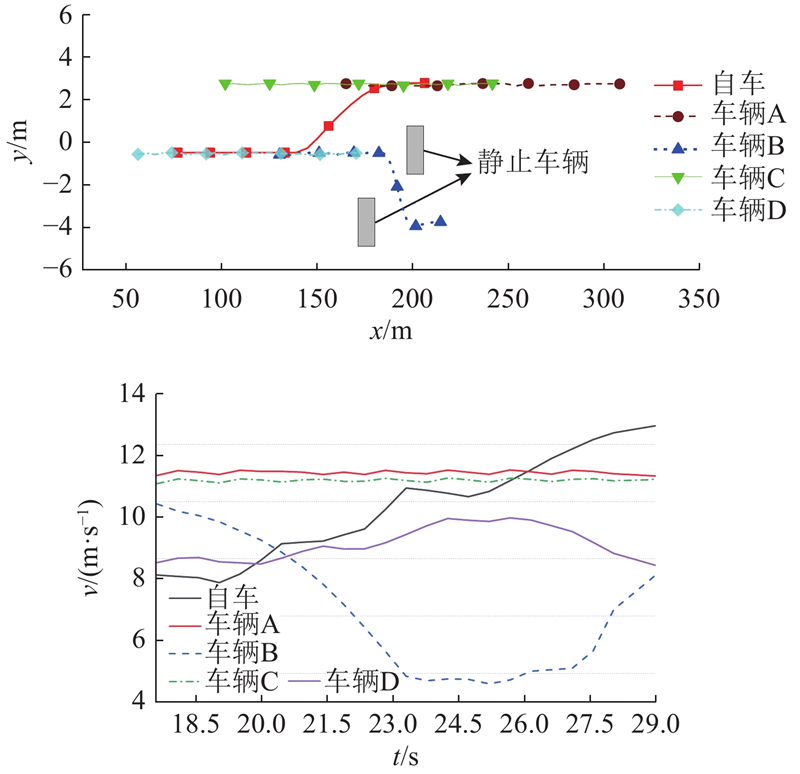
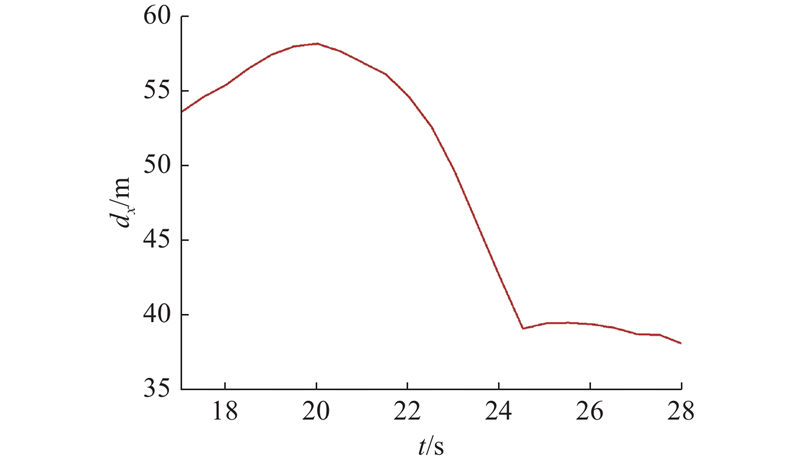
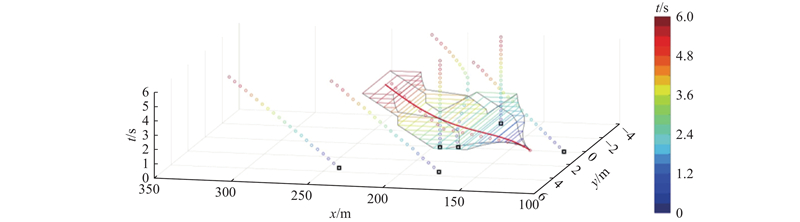
| 交通工程 |
|

|
|
|
| 基于可达集和强化学习的智能汽车决策规划 |
高洪伟1( ),尚秉旭1,张鑫康2,王洪峰1,何维2,裴晓飞2,*() ),尚秉旭1,张鑫康2,王洪峰1,何维2,裴晓飞2,*() |
1. 中国第一汽车集团有限公司研发总院,长春 130011
2. 武汉理工大学 汽车工程学院,湖北 武汉 430070 |
|
| Decision-making and planning of intelligent vehicle based on reachable set and reinforcement learning |
| Hongwei GAO1(),Bingxu SHANG1,Xinkang ZHANG2,Hongfeng WANG1,Wei HE2,Xiaofei PEI2,*() |
1. R&D Center, China FAW Group Corporation, Changchun 130011, China
2. School of Automotive Engineering, Wuhan University of Technology, Wuhan 430070, China |
引用本文:
高洪伟,尚秉旭,张鑫康,王洪峰,何维,裴晓飞. 基于可达集和强化学习的智能汽车决策规划[J]. 浙江大学学报(工学版), 2025, 59(9): 1996-2004.
Hongwei GAO,Bingxu SHANG,Xinkang ZHANG,Hongfeng WANG,Wei HE,Xiaofei PEI. Decision-making and planning of intelligent vehicle based on reachable set and reinforcement learning. Journal of ZheJiang University (Engineering Science), 2025, 59(9): 1996-2004.
链接本文:
https://www.zjujournals.com/eng/CN/10.3785/j.issn.1008-973X.2025.09.023
或
https://www.zjujournals.com/eng/CN/Y2025/V59/I9/1996
|
| 1 |
朱冰, 贾士政, 赵健, 等 自动驾驶车辆决策与规划研究综述[J]. 中国公路学报, 2024, 37 (1): 215- 240
ZHU Bing, JIA Shizheng, ZHAO Jian, et al Review of research on decision-making and planning for automated vehicles[J]. China Journal of Highway and Transport, 2024, 37 (1): 215- 240
|
| 2 |
NÉMETH B, GÁSPÁR P Hierarchical motion control strategies for handling interactions of automated vehicles[J]. Control Engineering Practice, 2023, 136: 105523
doi: 10.1016/j.conengprac.2023.105523
|
| 3 |
XIONG L, ZHANG Y, LIU Y, et al Integrated decision making and planning based on feasible region construction for autonomous vehicles considering prediction uncertainty[J]. IEEE Transactions on Intelligent Vehicles, 2023, 8 (11): 4515- 4523
doi: 10.1109/TIV.2023.3299845
|
| 4 |
XIN L, KONG Y, LI S E, et al Enable faster and smoother spatio-temporal trajectory planning for autonomous vehicles in constrained dynamic environment[J]. Proceedings of the Institution of Mechanical Engineers, Part D: Journal of Automobile Engineering, 2021, 235 (4): 1101- 1112
doi: 10.1177/0954407020906627
|
| 5 |
MARTINEZ ROCAMORA B, PEREIRA G A S Parallel sensor-space lattice planner for real-time obstacle avoidance[J]. Sensors, 2022, 22 (13): 4770
doi: 10.3390/s22134770
|
| 6 |
MANZINGER S, PEK C, ALTHOFF M Using reachable sets for trajectory planning of automated vehicles[J]. IEEE Transactions on Intelligent Vehicles, 2021, 6 (2): 232- 248
doi: 10.1109/TIV.2020.3017342
|
| 7 |
HANG P, LV C, HUANG C, et al An integrated framework of decision making and motion planning for autonomous vehicles considering social behaviors[J]. IEEE Transactions on Vehicular Technology, 2020, 69 (12): 14458- 14469
doi: 10.1109/TVT.2020.3040398
|
| 8 |
ZHANG X, YANG B, PEI X, et al Trajectory planning based on spatio-temporal reachable set considering dynamic probabilistic risk[J]. Engineering Applications of Artificial Intelligence, 2023, 123: 106291
doi: 10.1016/j.engappai.2023.106291
|
| 9 |
SÖNTGES S, ALTHOFF M Computing the drivable area of autonomous road vehicles in dynamic road scenes[J]. IEEE Transactions on Intelligent Transportation Systems, 2018, 19 (6): 1855- 1866
doi: 10.1109/TITS.2017.2742141
|
| 10 |
MASCETTA T, LIU E I, ALTHOFF M. Rule-compliant multi-agent driving corridor generation using reachable sets and combinatorial negotiations [C]// Proceedings of the IEEE Intelligent Vehicles Symposium. Jeju Island: IEEE, 2024: 1417–1423.
|
| 11 |
LERCHER F, ALTHOFF M. Specification-compliant reachability analysis for autonomous vehicles using on-the-fly model checking [C]// Proceedings of the IEEE Intelligent Vehicles Symposium. Jeju Island: IEEE, 2024: 1484–1491.
|
| 12 |
ZHU Z, ZHAO H A survey of deep RL and IL for autonomous driving policy learning[J]. IEEE Transactions on Intelligent Transportation Systems, 2022, 23 (9): 14043- 14065
doi: 10.1109/TITS.2021.3134702
|
| 13 |
DUAN J, EBEN LI S, GUAN Y, et al Hierarchical reinforcement learning for self-driving decision-making without reliance on labelled driving data[J]. IET Intelligent Transport Systems, 2020, 14 (5): 297- 305
doi: 10.1049/iet-its.2019.0317
|
| 14 |
TRAUTH R, HOBMEIER A, BETZ J. A reinforcement learning-boosted motion planning framework: comprehensive generalization performance in autonomous driving [EB/OL]. (2024-02-02)[2025-06-16]. https://arxiv.org/abs/2402.01465v1.
|
| 15 |
YU J, ARAB A, YI J, et al Hierarchical framework integrating rapidly-exploring random tree with deep reinforcement learning for autonomous vehicle[J]. Applied Intelligence, 2023, 53 (13): 16473- 16486
doi: 10.1007/s10489-022-04358-7
|
| 16 |
JAFARI R, ASHARI A E, HUBER M. CHAMP: integrated logic with reinforcement learning for hybrid decision making for autonomous vehicle planning [C]// Proceedings of the American Control Conference. San Diego: IEEE, 2023: 3310–3315.
|
| 17 |
CHEN D, JIANG L, WANG Y, et al. Autonomous driving using safe reinforcement learning by incorporating a regret-based human lane-changing decision model [C]// Proceedings of the American Control Conference. Denver: IEEE, 2020: 4355–4361.
|
| 18 |
ZHOU H, PEI X, LIU Y, et al. Trajectory planning for autonomous vehicles at urban intersections based on reachable sets [C]// IEEE Intelligent Vehicle Symposium. Cluj Napoca: IEEE, 2025: 1101–1107.
|
| 19 |
李国法, 陈耀昱, 吕辰, 等 智能汽车决策中的驾驶行为语义解析关键技术[J]. 汽车安全与节能学报, 2019, 10 (4): 391- 412
LI Guofa, CHEN Yaoyu, LV Chen, et al Key techniques of semantic analysis of driving behavior in decision making of autonomous vehicles[J]. Journal of Automotive Safety and Energy, 2019, 10 (4): 391- 412
doi: 10.3969/j.issn.1674-8484.2019.04.001
|
| 20 |
QIAN L, XU X, ZENG Y, et al Synchronous maneuver searching and trajectory planning for autonomous vehicles in dynamic traffic environments[J]. IEEE Intelligent Transportation Systems Magazine, 2022, 14 (1): 57- 73
doi: 10.1109/MITS.2019.2953551
|
| 21 |
TREIBER M, HENNECKE A, HELBING D Congested traffic states in empirical observations and microscopic simulations[J]. Physical Review E, Statistical Physics, Plasmas, Fluids, and Related Interdisciplinary Topics, 2000, 62 (2A): 1805- 1824
|
| 22 |
周兴珍, 裴晓飞, 张鑫康 基于可达集优化的智能汽车轨迹规划研究[J]. 武汉理工大学学报, 2022, 44 (6): 39- 48
ZHOU Xingzhen, PEI Xiaofei, ZHANG Xinkang Trajectory planning of intelligent vehicle based on reachable set and optimization[J]. Journal of Wuhan University of Technology, 2022, 44 (6): 39- 48
doi: 10.3963/j.issn.1671-4431.2022.06.007
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|