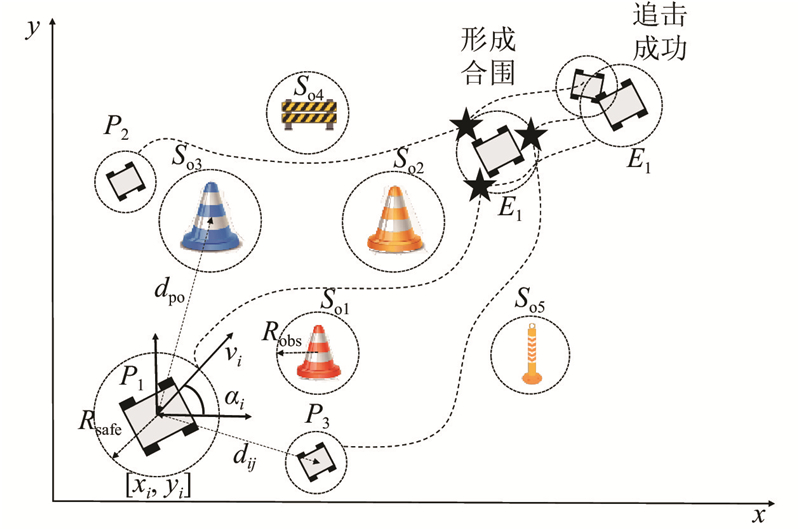
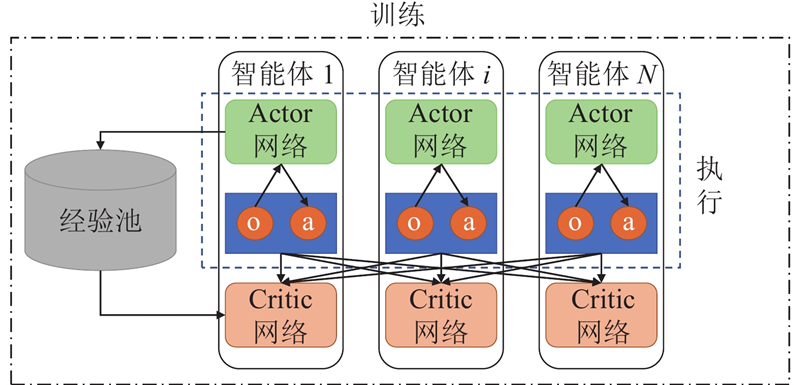
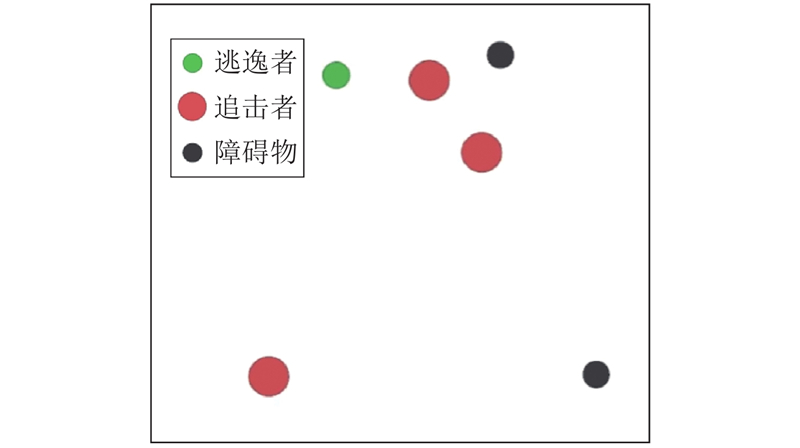
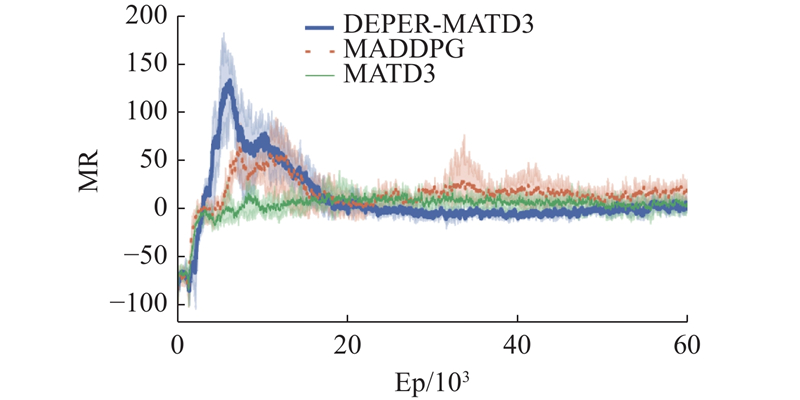
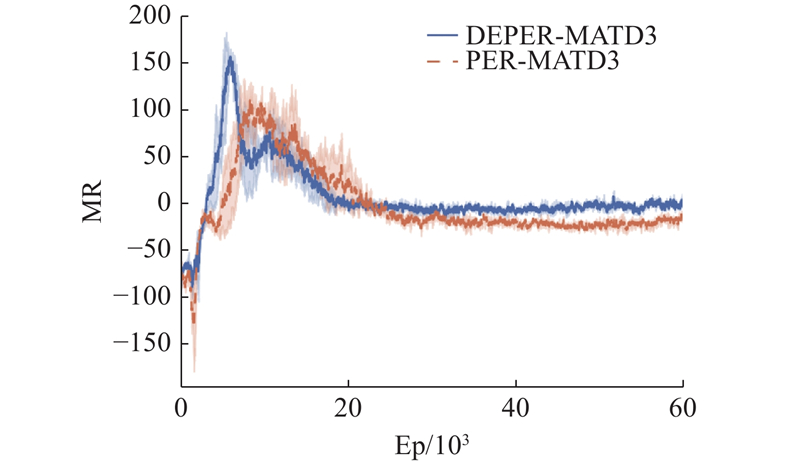
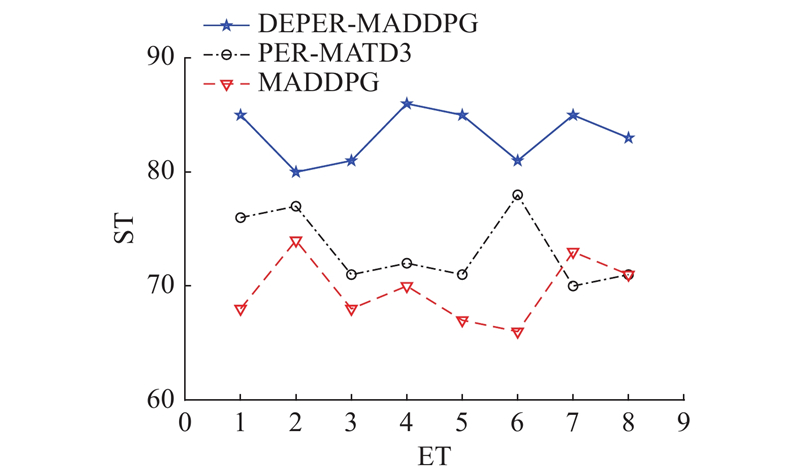
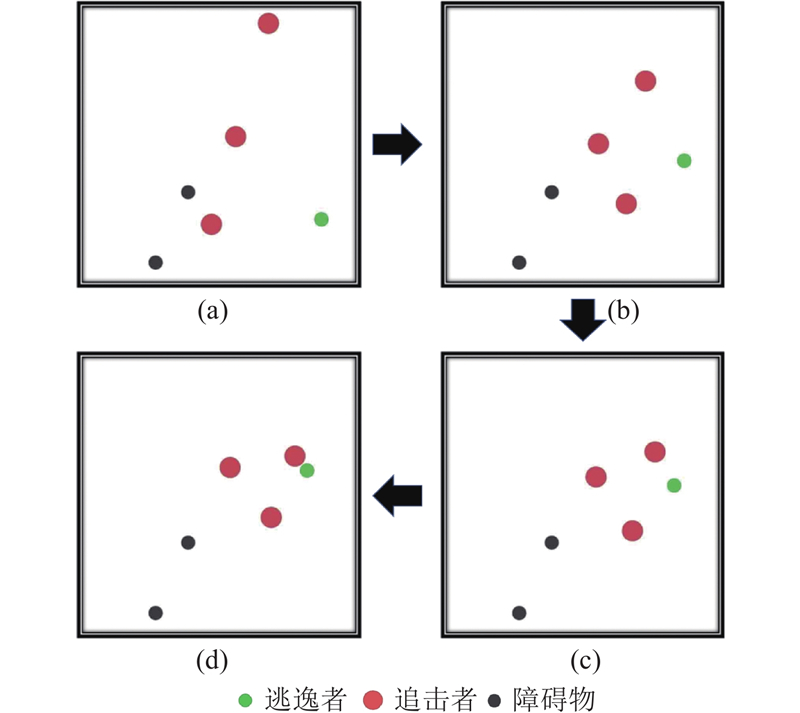
|
|
|
| 基于改进强化学习的多智能体追逃对抗 |
薛雅丽( ),叶金泽,李寒雁 ),叶金泽,李寒雁 |
| 南京航空航天大学 自动化学院,江苏 南京 211106 |
|
| Multi-agent pursuit and evasion games based on improved reinforcement learning |
| Ya-li XUE(),Jin-ze YE,Han-yan LI |
| College of Automation Engineering, Nanjing University of Aeronautics and Astronautics, Nanjing 211106, China |
| 1 |
周浦城, 洪炳镕 基于对策论的群机器人追捕-逃跑问题研究[J]. 哈尔滨工业大学学报, 2003, (9): 1056- 1059
ZHOU Pu-cheng, HONG Bing-rong Research on the pursuit and escape problem of swarm robots based on game theory[J]. Journal of Harbin Institute of Technology, 2003, (9): 1056- 1059
doi: 10.3321/j.issn:0367-6234.2003.09.010
|
| 2 |
李龙跃, 刘付显, 史向峰, 等 导弹攻防对抗中追逃对策模型与配点求解法[J]. 系统工程与电子技术, 2016, 38 (5): 1067- 1073
LI Long-yue, LIU Fu-xian, SHI Xiang-feng, et al Model of pursuit and escape countermeasures in missile attack and defense countermeasures and collocation solution[J]. Journal of Systems Engineering and Electronics, 2016, 38 (5): 1067- 1073
doi: 10.3969/j.issn.1001-506X.2016.05.15
|
| 3 |
刘坤, 郑晓帅, 林业茗, 等. 基于微分博弈的追逃问题最优策略设计[J]. 2021, 47(8): 1840-1854.
LIU Kun, ZHENG Xiao-shuai, LIN Ye-ming, et al. Optimal strategy design of pursuit and escape problem based on differential game [J]. Journal of Automatica Sinica, 2021, 47(8): 1840-1854.
|
| 4 |
刘肇隆, 宋耀, 徐翊铭, 等 图注意力网络的微分博弈追逃问题最优策略[J]. 计算机工程与应用, 2023, 59 (9): 313- 318
LIU Zhao-long, SONG Yao, XU Yi-ming, et al Optimal strategy of differential game pursuit problem in graph attention network[J]. Computer Engineering and Applications, 2023, 59 (9): 313- 318
|
| 5 |
FANG B, PAN Q, HONG B, et al Research on high speed evader vs. multi lower speed pursuers in multi pursuit-evasion games[J]. Information Technology Journal, 2012, 11 (8): 989- 997
doi: 10.3923/itj.2012.989.997
|
| 6 |
张澄安, 邓文, 王李瑞, 等 基于阿波罗尼奥斯圆的无人机追逃问题研究[J]. 航天电子对抗, 2021, 37 (5): 40- 43,48
ZHANG Cheng-an, DENG Wen, WANG Li-rui, et al Research on the pursuit and escape of UAVs based on Apollonius circle[J]. Aerospace Electronic Warfare, 2021, 37 (5): 40- 43,48
doi: 10.3969/j.issn.1673-2421.2021.05.008
|
| 7 |
苏义鑫, 石兵华, 张华军, 等 水面无人艇的抗追捕-逃跑策略[J]. 哈尔滨工程大学学报, 2018, 39 (6): 1019- 1025
SU Yi-xin, SHI Bing-hua, ZHANG Hua-jun, et al The anti-pursuit and escape strategy of unmanned surface craft[J]. Journal of Harbin Engineering University, 2018, 39 (6): 1019- 1025
doi: 10.11990/jheu.201705092
|
| 8 |
LI J, PAN Q, HONG B A new approach of multi-robot cooperative pursuit based on association rule data mining[J]. International Journal of Advanced Robotic Systems, 2010, 7 (3): 1169- 1174
|
| 9 |
LIU J, LIU S, WU H, et al. A pursuit-evasion algorithm based on hierarchical reinforcement learning[C]// International Conference on Measuring Technology and Mechatronics Automation. Zhangjiajie: IEEE, 2009: 482-486.
|
| 10 |
MOSTAFA D, HOWARD M A decentralized fuzzy learning algorithm for pursuit-evasion differential games with superior evaders[J]. Journal of Intelligent and Robotic Systems, 2016, 83 (1): 35- 53
doi: 10.1007/s10846-015-0315-y
|
| 11 |
ALEXANDRE B, MOULAY A. UAV pursuit using reinforcement learning[EB/OL]. [2022-11-01]. https://www.researchgate.net/publication/333122618_UAV_pursuit_using_reinforcement_learning
|
| 12 |
ZHANG B, HU B, CHEN L, et al. Probabilistic reward-based reinforcement learning for multi-agent pursuit and evasion [EB/OL]. (2021-05-22). https://kns.cnki.net/kcms2/article/abstract?v=YhL_Bl4XtC7yyLQqjQmWvQGFaHRks9Y7gEQxMHvbmL7fMP8_n99K976g8Gkzd7ga2CqCUiYClTJD65ep-1s-zhxIW8yOO67CYj63fkZ7BjY%3d&uniplatform=NZKPT.
|
| 13 |
ZHOU X, ZHOU S, MOU X, et al. Multirobot collaborative pursuit target robot by improved MADDPG [EB/OL]. (2022-02-25). https://www.hindawi.com/journals/cin/2022/4757394/.
|
| 14 |
夏家伟, 朱旭芳, 张建强, 等 基于多智能体强化学习的无人艇协同围捕方法[J]. 控制与决策, 2023, 38 (5): 1438- 1447
XIA Jia-wei, ZHU Xu-fang, ZHANG Jian-qiang, et al Research on the method of unmanned boat cooperative encirclement based on multi-agent reinforcement learning[J]. Control and Decision, 2023, 38 (5): 1438- 1447
doi: 10.13195/j.kzyjc.2022.0564
|
| 15 |
姜立标, 吴中伟 基于趋近律滑模控制的智能车辆轨迹跟踪研究[J]. 农业机械学报, 2018, 49 (3): 381- 386
JIANG Li-biao, WU Zhong-wei Research on intelligent vehicle trajectory tracking based on reaching law sliding mode control[J]. Transactions of the Chinese Society of Agricultural Machinery, 2018, 49 (3): 381- 386
doi: 10.6041/j.issn.1000-1298.2018.03.048
|
| 16 |
赵润晖, 文红, 侯文静 基于MADDPG的边缘网络任务卸载与资源管理[J]. 通信技术, 2021, 54 (4): 864- 868
ZHAO Run-hui, WEN Hong, HOU Wen-jing Edge network task offloading and resource management based on MADDPG[J]. Communication Technology, 2021, 54 (4): 864- 868
doi: 10.3969/j.issn.1002-0802.2021.04.014
|
| 17 |
FUJIMOTO S, HOOF H, MEGER D. Addressing function approximation error in actor-critic methods[EB/OL]. (2018-02-26). https://arxiv.org/abs/1802.09477v1.
|
| 18 |
TOM S, JOHN Q, IOANNIS A, et al. Prioritized experience replay[EB/OL]. (2015-11-18). https://arxiv.org/abs/1511.05952.
|
| 19 |
龚慧雯, 王桐, 陈立伟, 等 基于深度强化学习的多智能体对抗策略算法[J]. 应用科技, 2022, 49 (5): 1- 7
GONG Hui-wen, WANG Tong, CHEN Li-wei, et al Multi-agent confrontation strategy algorithm based on deep reinforcement learning[J]. Applied Science and Technology, 2022, 49 (5): 1- 7
|
| 20 |
SHEIKH H U, BOLONI L. Multi-agent reinforcement learning for problems with combined individual and team reward[C]// 2020 International Joint Conference on Neural Networks (IJCNN). Glasgow: IEEE, 2020: 1-8,
|
| 21 |
符小卫, 王辉, 徐哲 基于DE-MADDPG的多无人机协同追捕策略[J]. 航空学报, 2022, 43 (5): 530- 543
FU Xiao-wei, WANG Hui, XU Zhe Multi-UAV cooperative pursuit strategy based on DE-MADDPG[J]. Acta Aeronautica Et Astronautica Sinica, 2022, 43 (5): 530- 543
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|