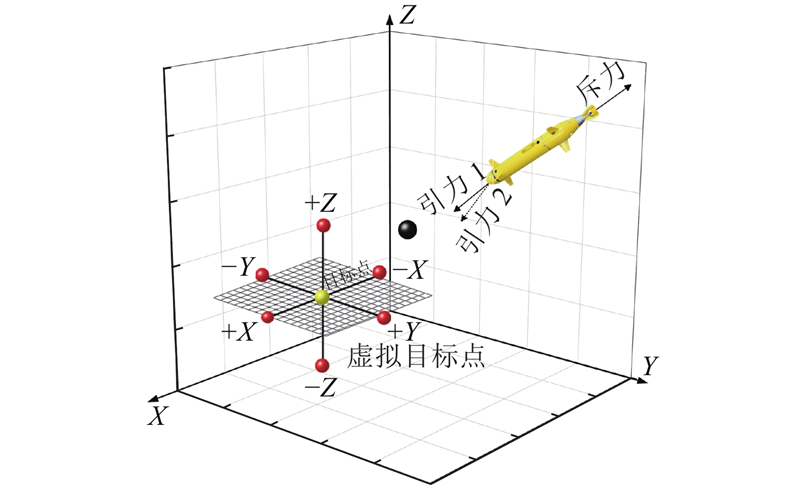
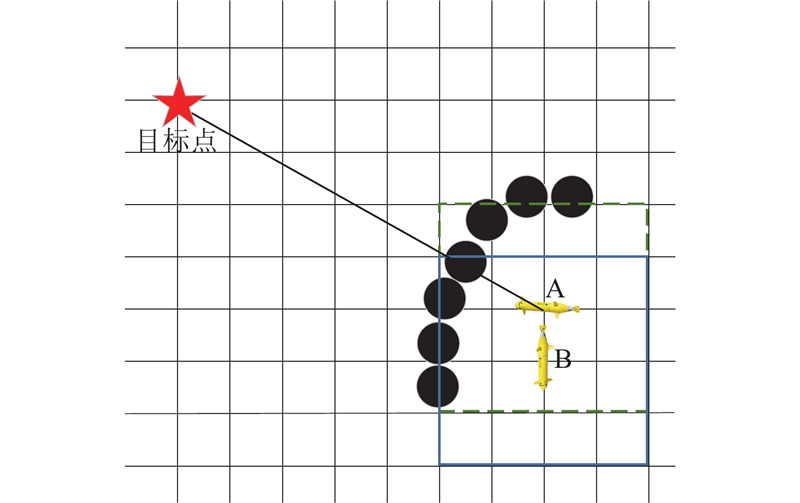
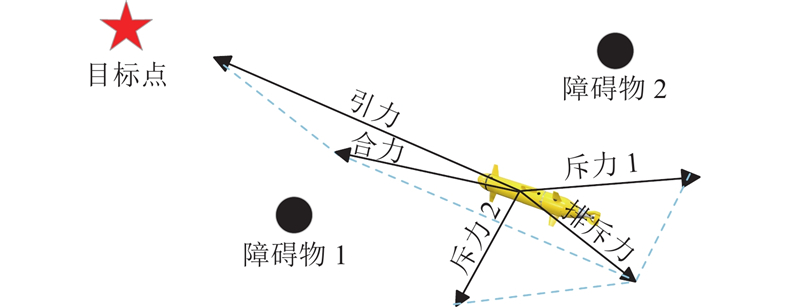
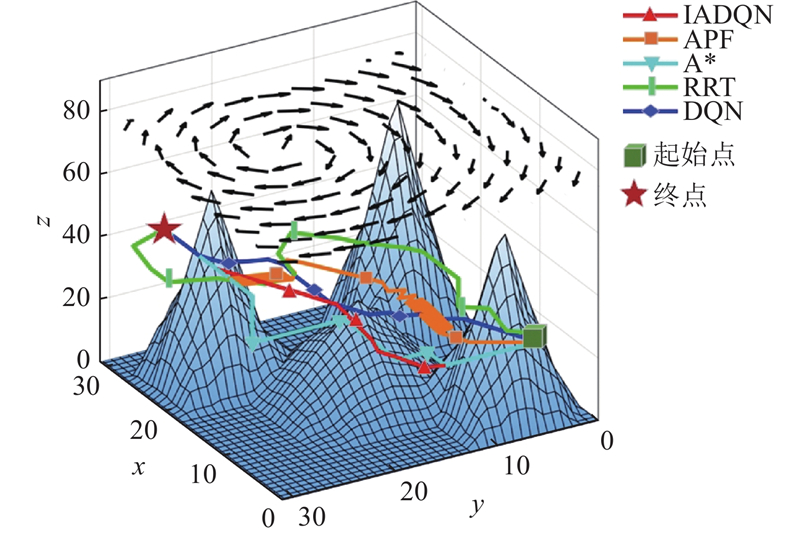
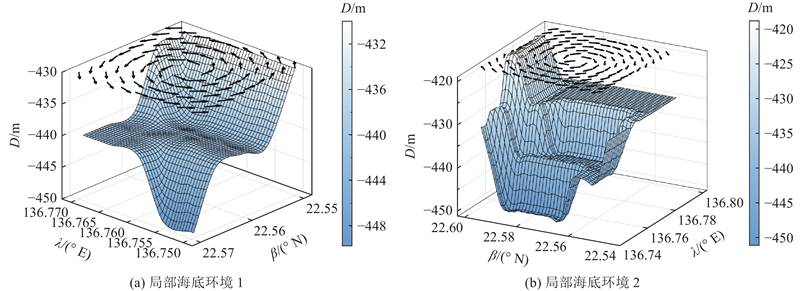
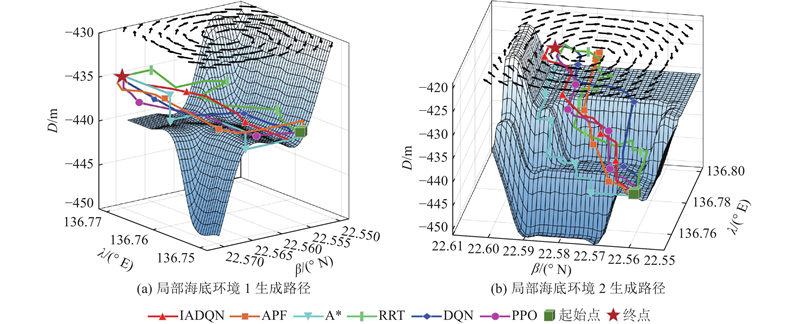
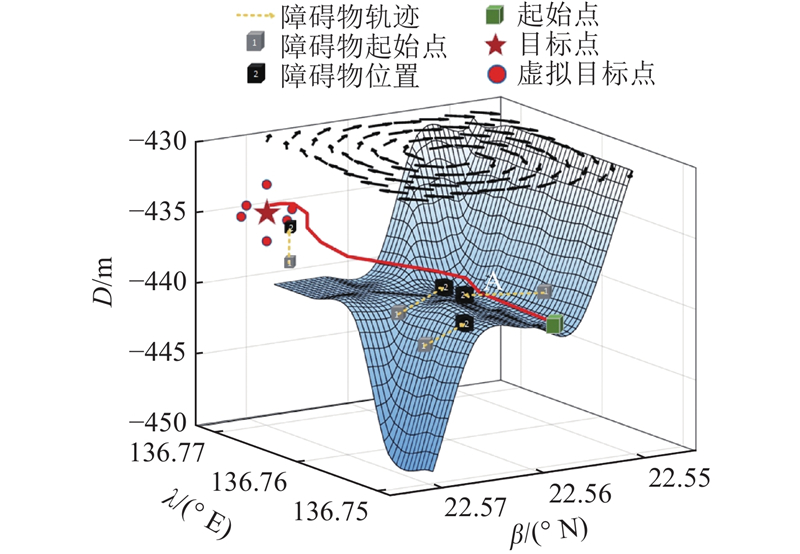
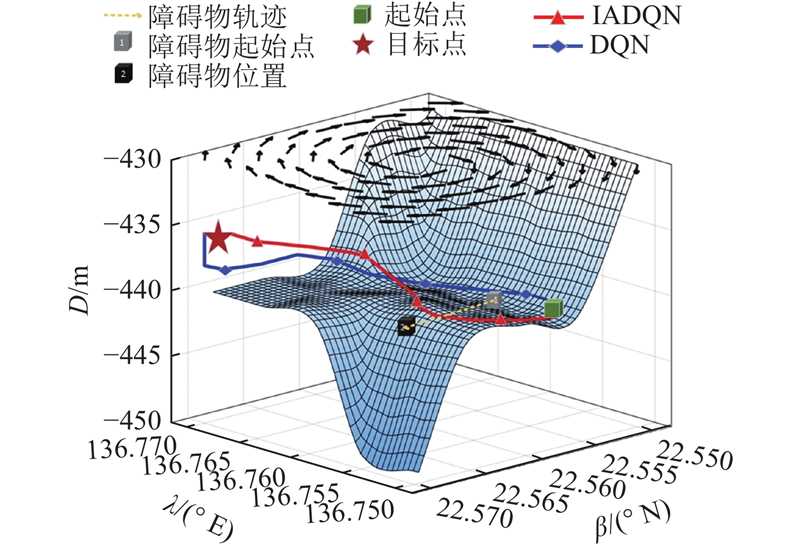
| 计算机技术与控制工程 |
|

|
|
|
| 融合自适应势场法和深度强化学习的三维水下AUV路径规划方法 |
郝琨( ),孟璇,赵晓芳*(),李志圣 ),孟璇,赵晓芳*(),李志圣 |
| 天津城建大学 计算机与信息工程学院,天津 300384 |
|
| 3D underwater AUV path planning method integrating adaptive potential field method and deep reinforcement learning |
| Kun HAO(),Xuan MENG,Xiaofang ZHAO*(),Zhisheng LI |
| School of Computer and Information Engineering, Tianjin Chengjian University, Tianjin 300384 |
引用本文:
郝琨,孟璇,赵晓芳,李志圣. 融合自适应势场法和深度强化学习的三维水下AUV路径规划方法[J]. 浙江大学学报(工学版), 2025, 59(7): 1451-1461.
Kun HAO,Xuan MENG,Xiaofang ZHAO,Zhisheng LI. 3D underwater AUV path planning method integrating adaptive potential field method and deep reinforcement learning. Journal of ZheJiang University (Engineering Science), 2025, 59(7): 1451-1461.
链接本文:
https://www.zjujournals.com/eng/CN/10.3785/j.issn.1008-973X.2025.07.013
或
https://www.zjujournals.com/eng/CN/Y2025/V59/I7/1451
|
| 1 |
杨波, 刘烨瑶, 廖佳伟 载人潜水器: 面向深海科考和海洋资源开发利用的“国之重器”[J]. 中国科学院院刊, 2021, 36 (5): 622- 631
YANG Bo, LIU Yeyao, LIAO Jiawei Manned submersibles: deep-sea scientific research and exploitation of marine resources[J]. Bulletin of Chinese Academy of Sciences, 2021, 36 (5): 622- 631
|
| 2 |
CHENG C, SHA Q, HE B, et al Path planning and obstacle avoidance for AUV: a review[J]. Ocean Engineering, 2021, 235: 109355
doi: 10.1016/j.oceaneng.2021.109355
|
| 3 |
刘晨霞, 朱大奇, 周蓓, 等 海流环境下多AUV多目标生物启发任务分配与路径规划算法[J]. 控制理论与应用, 2022, 39 (11): 2100- 2107
LIU Chenxia, ZHU Daqi, ZHOU Bei, et al A novel algorithm of multi-AUVs task assignment and path planning based on biologically inspired neural network for ocean current environment[J]. Control Theory and Applications, 2022, 39 (11): 2100- 2107
doi: 10.7641/CTA.2022.11019
|
| 4 |
MATSUO Y, LECUN Y, SAHANI M, et al Deep learning, reinforcement learning, and world models[J]. Neural Networks, 2022, 152: 267- 275
doi: 10.1016/j.neunet.2022.03.037
|
| 5 |
邢丽静, 李敏, 曾祥光, 等. 部分未知环境下基于行为克隆与改进DQN的AUV路径规划 [EB/OL]. (2024–11–06)[2025–06–20]. https://doi.org/10.16182/j.issn1004731x.joss.24-0678.
|
| 6 |
潘云伟, 李敏, 曾祥光, 等. 基于人工势场和改进强化学习的AUV避障和航迹规划 [EB/OL]. (2024–10–09)[2025–06–20]. https://link.cnki.net/urlid/11.2176.TJ.20241008.1329.002.
|
| 7 |
刘宇庭, 郭世杰, 唐术锋, 等 改进A*与ROA-DWA融合的机器人路径规划[J]. 浙江大学学报: 工学版, 2024, 58 (2): 360- 369
LIU Yuting, GUO Shijie, TANG Shufeng, et al Path planning based on fusion of improved A* and ROA-DWA for robot[J]. Journal of Zhejiang University: Engineering Science, 2024, 58 (2): 360- 369
|
| 8 |
万俊, 孙薇, 葛敏, 等 基于含避障角人工势场法的机器人路径规划[J]. 农业机械学报, 2024, 55 (1): 409- 418
WAN Jun, SUN Wei, GE Min, et al Robot path planning based on artificial potential field method with obstacle avoidance angles[J]. Transactions of the Chinese Society for Agricultural Machinery, 2024, 55 (1): 409- 418
doi: 10.6041/j.issn.1000-1298.2024.01.039
|
| 9 |
ZHANG W, WANG N, WU W A hybrid path planning algorithm considering AUV dynamic constraints based on improved A* algorithm and APF algorithm[J]. Ocean Engineering, 2023, 285: 115333
doi: 10.1016/j.oceaneng.2023.115333
|
| 10 |
CHEN G, CHENG D, CHEN W, et al Path planning for AUVs based on improved APF-AC algorithm[J]. Computers, Materials and Continua, 2024, 78 (3): 3721- 3741
doi: 10.32604/cmc.2024.047325
|
| 11 |
YU F, SHANG H, ZHU Q, et al An efficient RRT-based motion planning algorithm for autonomous underwater vehicles under cylindrical sampling constraints[J]. Autonomous Robots, 2023, 47 (3): 281- 297
doi: 10.1007/s10514-023-10083-y
|
| 12 |
QI C, WU C, LEI L, et al. UAV path planning based on the improved PPO algorithm [C]// Proceedings of the Asia Conference on Advanced Robotics, Automation, and Control Engineering. Qingdao: IEEE, 2022: 193–199.
|
| 13 |
YANG Y, LI J, PENG L Multi-robot path planning based on a deep reinforcement learning DQN algorithm[J]. CAAI Transactions on Intelligence Technology, 2020, 5 (3): 177- 183
doi: 10.1049/trit.2020.0024
|
| 14 |
WEN S, WEN Z, ZHANG D, et al A multi-robot path-planning algorithm for autonomous navigation using meta-reinforcement learning based on transfer learning[J]. Applied Soft Computing, 2021, 110: 107605
doi: 10.1016/j.asoc.2021.107605
|
| 15 |
祁璇, 周通, 王村松, 等 基于改进近端策略优化算法的AGV路径规划与任务调度[J]. 计算机集成制造系统, 2025, 31 (3): 955- 964
QI Xuan, ZHOU Tong, WANG Cunsong, et al AGV path planning and task scheduling based on improved proximal policy optimization algorithm[J]. Computer Integrated Manufacturing Systems, 2025, 31 (3): 955- 964
|
| 16 |
YANG J, NI J, XI M, et al Intelligent path planning of underwater robot based on reinforcement learning[J]. IEEE Transactions on Automation Science and Engineering, 2023, 20 (3): 1983- 1996
doi: 10.1109/TASE.2022.3190901
|
| 17 |
XING B, WANG X, YANG L, et al An algorithm of complete coverage path planning for unmanned surface vehicle based on reinforcement learning[J]. Journal of Marine Science and Engineering, 2023, 11 (3): 645
doi: 10.3390/jmse11030645
|
| 18 |
YANG J, HUO J, XI M, et al A time-saving path planning scheme for autonomous underwater vehicles with complex underwater conditions[J]. IEEE Internet of Things Journal, 2023, 10 (2): 1001- 1013
doi: 10.1109/JIOT.2022.3205685
|
| 19 |
孙月平, 方正, 袁必康, 等 基于FIA*-APF算法的蟹塘投饵船动态路径规划[J]. 农业工程学报, 2024, 40 (9): 137- 145
SUN Yueping, FANG Zheng, YUAN Bikang, et al Dynamic path planning for feeding boat in crab pond using FIA*-APF algorithm[J]. Transactions of the Chinese Society of Agricultural Engineering, 2024, 40 (9): 137- 145
doi: 10.11975/j.issn.1002-6819.202312211
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|