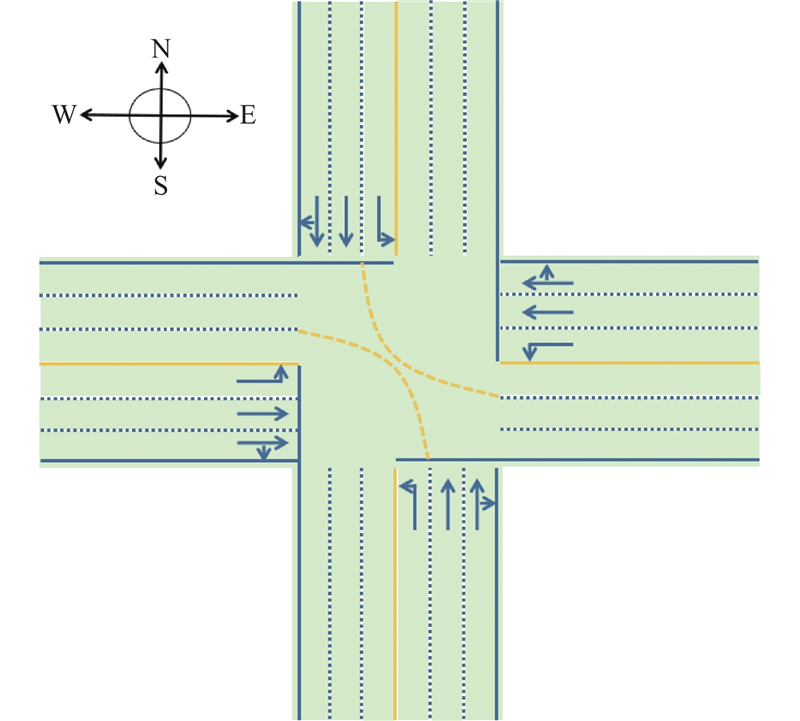
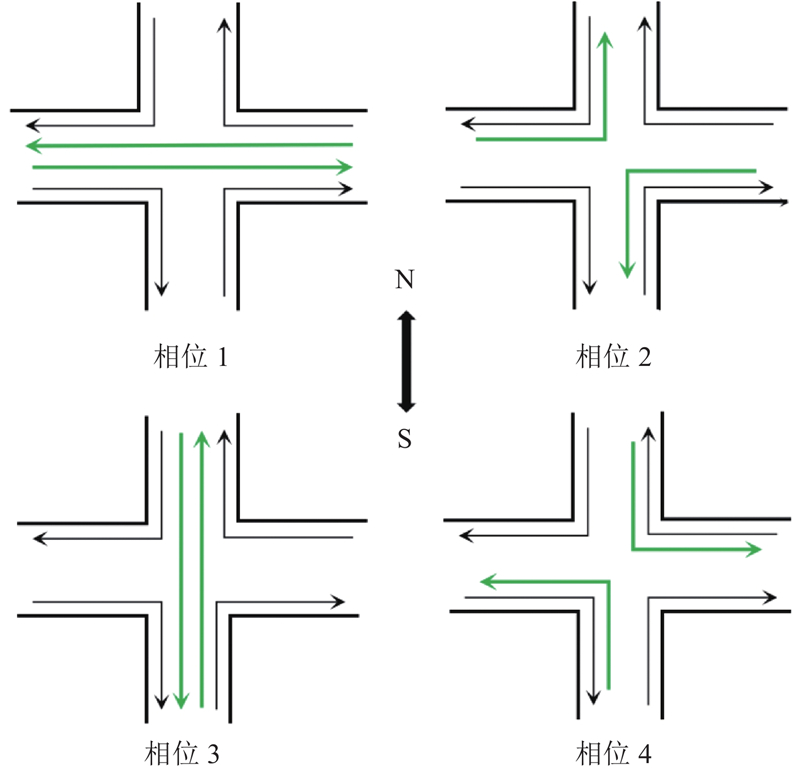
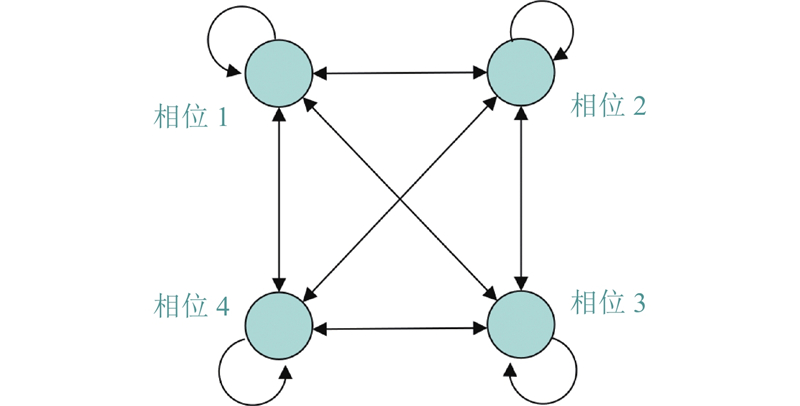
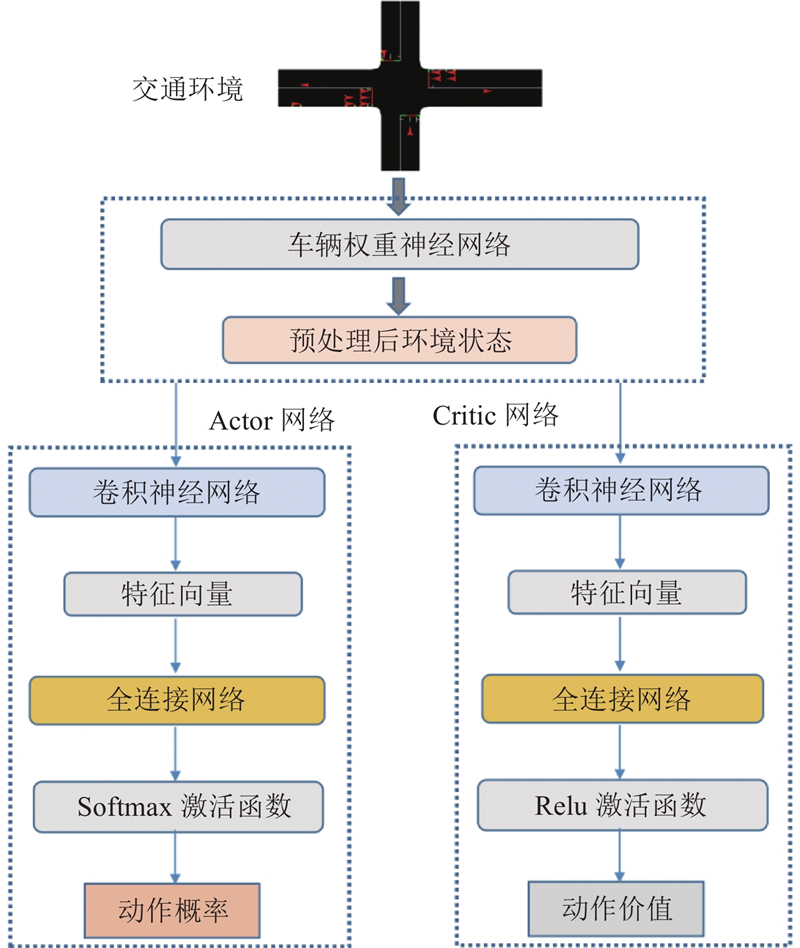
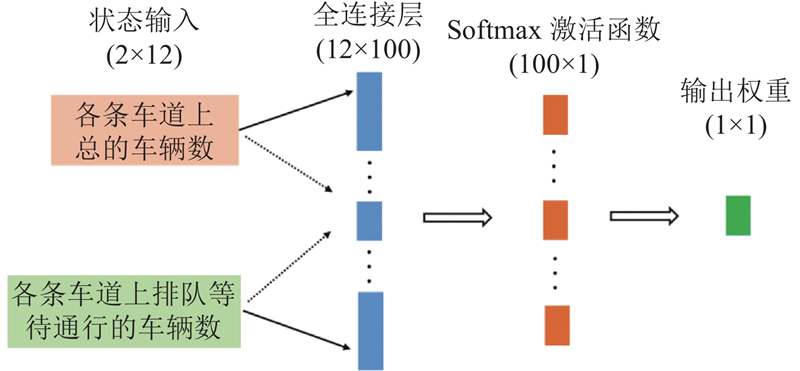
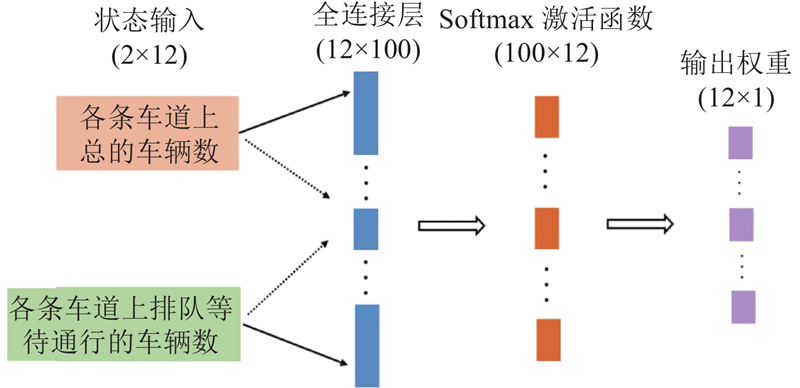
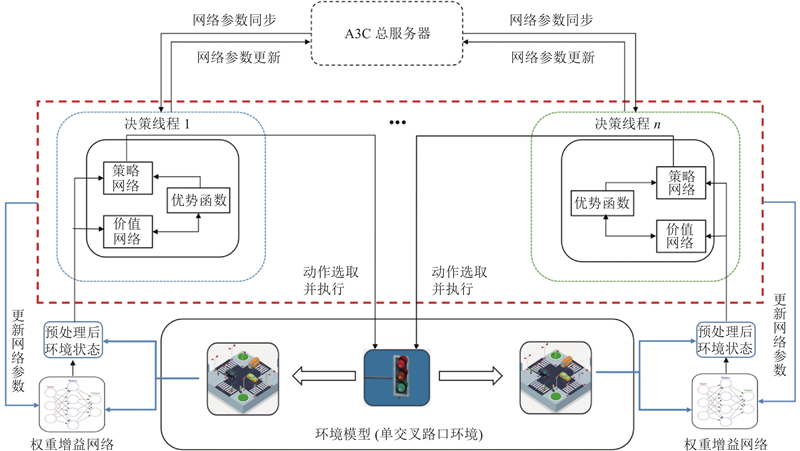
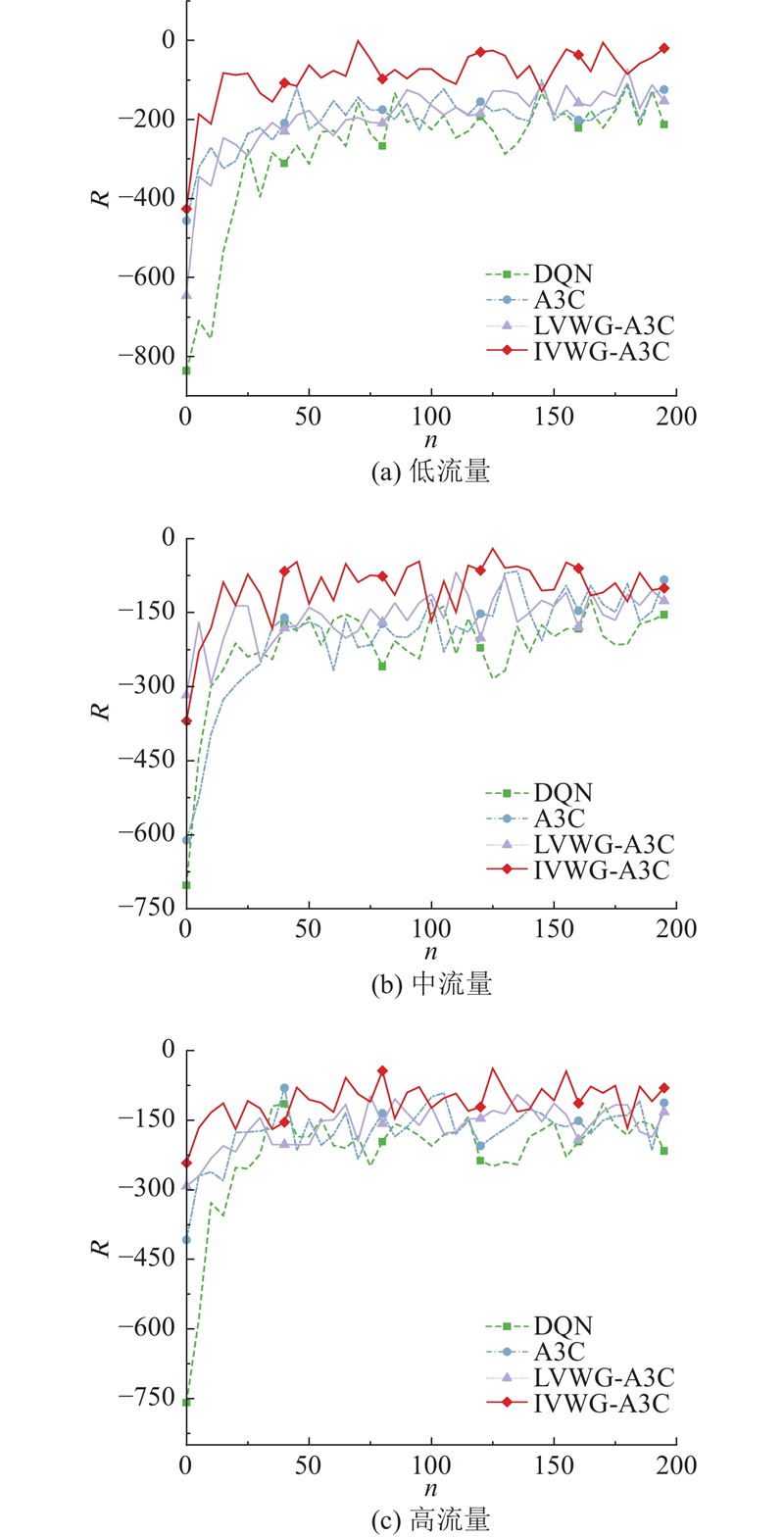
| 交通工程、土木工程 |
|

|
|
|
| 基于异步优势演员-评论家的交通信号控制方法 |
叶宝林1,2( ),孙瑞涛1,2,吴维敏3,陈滨2,姚青4 ),孙瑞涛1,2,吴维敏3,陈滨2,姚青4 |
1. 浙江理工大学 信息科学与工程学院,浙江 杭州 310018
2. 嘉兴大学 嘉兴市智慧交通重点实验室,浙江 嘉兴 314001
3. 浙江大学 工业控制技术全国重点实验室,智能系统与控制研究所,浙江 杭州 310027
4. 浙江理工大学 计算机科学与技术学院,浙江 杭州 310018 |
|
| Traffic signal control method based on asynchronous advantage actor-critic |
| Baolin YE1,2(),Ruitao SUN1,2,Weimin WU3,Bin CHEN2,Qing YAO4 |
1. School of Information Science and Engineering, Zhejiang Sci-Tech University, Hangzhou 310018, China
2. Jiaxing Key Laboratory of Smart Transportations, Jiaxing University, Jiaxing 314001, China
3. State Key Laboratory of Industrial Control Technology, Institute ofCyber-Systems and Control, Zhejiang University, Hangzhou 310027, China
4. School of Computer Science and Technology, Zhejiang Sci-Tech University, Hangzhou 310018, China |
引用本文:
叶宝林,孙瑞涛,吴维敏,陈滨,姚青. 基于异步优势演员-评论家的交通信号控制方法[J]. 浙江大学学报(工学版), 2024, 58(8): 1671-1680.
Baolin YE,Ruitao SUN,Weimin WU,Bin CHEN,Qing YAO. Traffic signal control method based on asynchronous advantage actor-critic. Journal of ZheJiang University (Engineering Science), 2024, 58(8): 1671-1680.
链接本文:
https://www.zjujournals.com/eng/CN/10.3785/j.issn.1008-973X.2024.08.014
或
https://www.zjujournals.com/eng/CN/Y2024/V58/I8/1671
|
| 1 |
YE B-L, WU W, RUAN K, et al A survey of model predictive control methods for traffic signal control[J]. IEEE/CAA Journal of Automatica Sinica, 2019, 6 (3): 623- 640
doi: 10.1109/JAS.2019.1911471
|
| 2 |
彭渠栩 优化双向“绿波带”关键路口控制参数算法的研究[J]. 应用数学进展, 2023, 12 (2): 781
PENG Quxu Research on the algorithm for optimizing the key intersection control parameters of two-way “Green Wave Belt”[J]. Advances in Applied Mathematics, 2023, 12 (2): 781
|
| 3 |
刘建伟, 高峰, 罗雄麟 基于值函数和策略梯度的深度强化学习综述[J]. 计算机学报, 2019, 42 (6): 1406- 1438
LIU Jianwei, GAO Feng, LUO Xionglin Review of deep reinforcement learning based on value functions and policy gradients[J]. Chinese Journal of Computers, 2019, 42 (6): 1406- 1438
doi: 10.11897/SP.J.1016.2019.01406
|
| 4 |
刘义, 何均宏 强化学习在城市交通信号灯控制方法中的应用[J]. 科技导报, 2019, 37 (6): 84- 90
LIU Yi, HE Junhong application of reinforcement learning in city traffic signal control methods.[J]. Science and Technology Review, 2019, 37 (6): 84- 90
|
| 5 |
FARID A, HUSSAIN F, KHAN K, et al A fast and accurate real-time vehicle detection method using deep learning for unconstrained environments[J]. Applied Sciences, 2023, 13 (5): 3059
doi: 10.3390/app13053059
|
| 6 |
MNIH V, KAVUKCUOGLU K, SILVER D, et al Human-level control through deep reinforcement learning[J]. Nature, 2015, 518 (7540): 529- 533
doi: 10.1038/nature14236
|
| 7 |
WANG M, WU L, LI J, et al Traffic signal control with reinforcement learning based on region-aware cooperative strategy[J]. IEEE Transactions on Intelligent Transportation Systems, 2021, 23 (7): 6774- 6785
|
| 8 |
WANG Z, YANG K, LI L, et al Traffic signal priority control based on shared experience multi-agent deep reinforcement learning[J]. IET Intelligent Transport Systems, 2023, 17 (7): 1363- 1379
|
| 9 |
MA D, ZHOU B, SONG X, et al A deep reinforcement learning approach to traffic signal control with temporal traffic pattern mining[J]. IEEE Transactions on Intelligent Transportation Systems, 2021, 23 (8): 11789- 11800
|
| 10 |
BOUKTIF S, CHENIKI A, OUNI A Traffic signal control using hybrid action space deep reinforcement learning[J]. Sensors, 2021, 21 (7): 2302
doi: 10.3390/s21072302
|
| 11 |
CHU T, WANG J, CODECA L, et al Multi-agent deep reinforcement learning for large-scale traffic signal control[J]. IEEE Transactions on Intelligent Transportation Systems, 2019, 21 (3): 1086- 1095
|
| 12 |
刘智敏, 叶宝林, 朱耀东, 等 基于深度强化学习的交通信号控制方法[J]. 浙江大学学报: 工学版, 2022, 56 (6): 1249- 1256
LIU Zhimin, YE Baolin, ZHU Yaodong, et al Traffic signal control methods based on deep reinforcement learning[J]. Journal of Zhejiang University: Engineering Science, 2022, 56 (6): 1249- 1256
|
| 13 |
WU T, ZHOU P, LIU K, et al Multi-agent deep reinforcement learning for urban traffic light control in vehicular networks[J]. IEEE Transactions on Vehicular Technology, 2020, 69 (8): 8243- 8256
doi: 10.1109/TVT.2020.2997896
|
| 14 |
赵乾, 张灵, 赵刚, 等 双环相位结构约束下的强化学习交通信号控制方法[J]. 交通运输工程与信息学报, 2023, 21 (1): 19- 28
ZHAO Qian, ZHANG Ling, ZHAO Gang, et al Reinforcement learning traffic signal control method under dual-ring phase structure constraints[J]. Journal of Transportation Engineering and Information, 2023, 21 (1): 19- 28
|
| 15 |
王安麟, 孙晓龙, 钟馥声 一种基于通行优先度规则的城市交通信号自组织控制方法[J]. 重庆交通大学学报: 自然科学版, 2018, 37 (2): 96
WANG Anlin, SUN Xiaolong, ZHONG Fusheng A self-organized control method for urban traffic signals based on priority rules for passage[J]. Journal of Chongqing Jiaotong University: Natural Science, 2018, 37 (2): 96
|
| 16 |
ASIAIN E, CLEMPNER J B, POZNYAK A S Controller exploitation-exploration reinforcement learning architecture for computing near-optimal policies[J]. Soft Computing, 2019, 23 (11): 3591- 3604
doi: 10.1007/s00500-018-3225-7
|
| 17 |
TROIA S, SAPIENZA F, VARÉ L, et al On deep reinforcement learning for traffic engineering in SD-WAN[J]. IEEE Journal on Selected Areas in Communications, 2021, 39 (7): 2198- 2212
doi: 10.1109/JSAC.2020.3041385
|
| 18 |
TAN K L, SHARMA A, SARKAR S Robust deep reinforcement learning for traffic signal control[J]. Journal of Big Data Analytics in Transportation, 2020, 2: 263- 274
doi: 10.1007/s42421-020-00029-6
|
| 19 |
LI M, LI Z, XU C, et al Deep reinforcement learning-based vehicle driving strategy to reduce crash risks in traffic oscillations[J]. Transportation Research Record, 2020, 2674 (10): 42- 54
doi: 10.1177/0361198120937976
|
| 20 |
CHU T, WANG J, CODECÀ L, et al Multi-agent deep reinforcement learning for large-scale traffic signal control[J]. IEEE Transactions on Intelligent Transportation Systems, 2020, 21 (3): 1086- 1095
doi: 10.1109/TITS.2019.2901791
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|