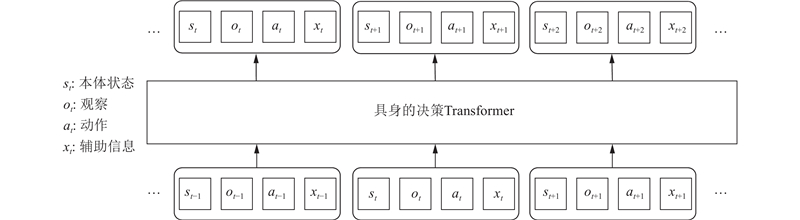
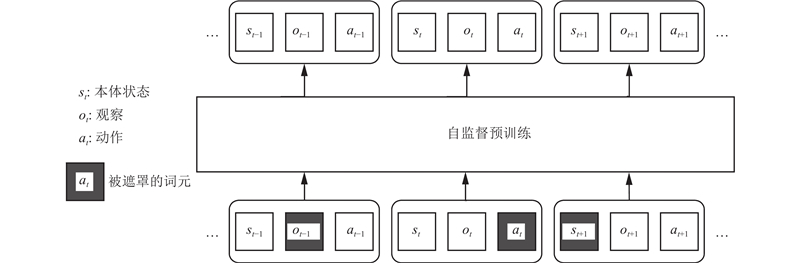
|
|
|
| 基座模型技术背景下的具身智能体综述 |
李颂元1( ),朱祥维1,李玺2,*() ),朱祥维1,李玺2,*() |
1. 中山大学 电子与通信工程学院,广东 深圳 518107
2. 浙江大学 计算机科学与技术学院,浙江 杭州 310058 |
|
| Survey of embodied agent in context of foundation model |
| Songyuan LI1(),Xiangwei ZHU1,Xi LI2,*() |
1. School of Electronics and Communication Engineering, Sun Yat-sen University, Shenzhen 518107, China
2. College of Computer Science and Technology, Zhejiang University, Hangzhou 310058, China |
| 1 |
TURING A Computing machinery and intelligence[J]. Mind, 1950, 59 (236): 433
|
| 2 |
BOMMASANI R, HUDSON D A, ADELI E, et al. On the opportunities and risks of foundation models [EB/OL]. [2021-06-12]. https://arxiv.org/abs/2108.07258.
|
| 3 |
DEVLIN J, CHANG M W, LEE K, et al. Bert: pretraining of deep bidirectional transformers for language understanding [EB/OL]. [2019-05-24]. https://arxiv.org/abs/1810.04805.
|
| 4 |
BROWN T, MANN B, RYDER N, et al. Language models are few-shot learners [C] // Advances in Neural Information Processing Systems . [S. 1. ]: Curran Associates, 2020 : 1877-1901.
|
| 5 |
RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision [C]// International Conference on Machine Learning. [S. l. ]: PMLR, 2021: 8748-8763.
|
| 6 |
PADALKAR A, POOLEY A, JAIN A, et al. Open X-embodiment: robotic learning datasets and RT-X models [EB/OL]. [2024-05-22]. https://arxiv.org/abs/2310.08864.
|
| 7 |
BUBECK S, CHANDRASEKARAN V, ELDAN R, et al. Sparks of artificial general intelligence: early experiments with gpt-4 [EB/OL]. [2023-04-13]. https://arxiv.org/abs/2303.12712.
|
| 8 |
ZADOR A, ESCOLA S, RICHARDS B, et al Catalyzing next-generation artificial intelligence through neuroai[J]. Nature Communications, 2023, 14 (1): 1597
|
| 9 |
BERGLUND L, TONG M, KAUFMANN M, et al. The reversal curse: Llms trained on “a is b” fail to learn “b is a” [EB/OL]. [2024-04-04]. https://arxiv.org/abs/2309.12288.
|
| 10 |
HARNAD S The symbol grounding problem[J]. Physica D: Nonlinear Phenomena, 1990, 42 (1-3): 335- 346
doi: 10.1016/0167-2789(90)90087-6
|
| 11 |
DRIESS D, XIA F, SAJJADI M S, et al. Palm-e: an embodied multimodal language model [EB/OL]. [2023-03-06]. https://arxiv.org/abs/2303.03378.
|
| 12 |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C] // Advances in Neural Information Processing Systems . Long Beach: Curran Associates, 2017: 5998-6008.
|
| 13 |
HINTON G E, SALAKHUTDINOV R R Reducing the dimensionality of data with neural networks[J]. Science, 2006, 313 (5786): 504- 507
doi: 10.1126/science.1127647
|
| 14 |
HINTON G E, OSINDERO S, TEH Y W A fast learning algorithm for deep belief nets[J]. Neural Computation, 2006, 18 (7): 1527- 1554
doi: 10.1162/neco.2006.18.7.1527
|
| 15 |
KAPLAN J, MCCANDLISH S, HENIGHAN T, et al. Scaling laws for neural language models [EB/OL]. [2020-01-22]. http://arxiv.org/abs/2001.08361.
|
| 16 |
RADFORD A, NARASIMHAN K, SALIMANS T, et al. Improving language understanding by generative pre-training [EB/OL]. [2018-06-09]. https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf.
|
| 17 |
RADFORD A, WU J, CHILD R, et al Language models are unsupervised multitask learners[J]. OpenAI Blog, 2019, 1 (8): 9
|
| 18 |
HE K, CHEN X, XIE S, et al. Masked autoencoders are scalable vision learners [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 16000-16009.
|
| 19 |
HE K, FAN H, WU Y, et al. Momentum contrast for unsupervised visual representation learning [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 9729-9738.
|
| 20 |
OPENAI. Gpt-4 technical report [EB/OL]. [2023-03-04]. https://arxiv.org/abs/2303.8774.
|
| 21 |
CHOWDHERY A, NARANG S, DEVLIN J, et al. Palm: scaling language modeling with pathways [EB/OL]. [2022-10-05]. https://arxiv.org/abs/2204.02311.
|
| 22 |
ANIL R, DAI A M, FIRAT O, et al. Palm 2 technical report [EB/OL]. [2023-09-13]. https://arxiv.org/abs/2305.10403.
|
| 23 |
TOUVRON H, LAVRIL T, IZACARD G, et al. Llama: open and efficient foundation language models [EB/OL]. [2023-02-27]. https://arxiv.org/abs/2302.13971.
|
| 24 |
TOUVRON H, MARTIN L, STONE K, et al. Llama 2: open foundation and fine-tuned chat models [EB/OL]. [2023-07-19]. https://arxiv.org/abs/2307.09288.
|
| 25 |
CHEN T, KORNBLITH S, NOROUZI M, et al. A simple framework for contrastive learning of visual representations [C] // International Conference on Machine Learning . [S. l. ]: PMLR, 2020: 1597-1607.
|
| 26 |
GRILL J B, STRUB F, ALTCHÉ F, et al. Bootstrap your own latent: a new approach to self-supervised learning [C] // Advances in Neural Information Processing Systems . [S. 1. ]: Curran Associates, 2020: 21271-21284.
|
| 27 |
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: transformers for image recognition at scale [EB/OL]. [2021-06-03]. https://arxiv.org/abs/2010.11929.
|
| 28 |
JIA C, YANG Y, XIA Y, et al. Scaling up visual and vision-language representation learning with noisy text supervision [C] // International Conference on Machine Learning. [S. l. ]: PMLR, 2021: 4904-4916.
|
| 29 |
CHEN X, WANG X, CHANGPINYO S, et al. Pali: a jointly-scaled multilingual language-image model [EB/OL]. [2023-06-05]. https://arxiv.org/abs/2209.06794.
|
| 30 |
CHEN X, DJOLONGA J, PADLEWSKI P, et al. Pali-x: on scaling up a multilingual vision and language model [EB/OL]. [2023-05-29]. https://arxiv.org/abs/2305.18565.
|
| 31 |
KIRILLOV A, MINTUN E, RAVI N, et al. Segment anything [EB/OL]. [2023-04-05]. https://arxiv.org/abs/2304.02643.
|
| 32 |
WANG X, WANG W, CAO Y, et al. Images speak in images: a generalist painter for in-context visual learning [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Vancouver: IEEE, 2023: 6830-6839.
|
| 33 |
SMITH L, GASSER M The development of embodied cognition: six lessons from babies[J]. Artificial Life, 2005, 11 (1/2): 13- 29
|
| 34 |
WEIZENBAUM J Eliza: a computer program for the study of natural language communication between man and machine[J]. Communications of the ACM, 1966, 9 (1): 36- 45
|
| 35 |
SEARLE J R Minds, brains, and programs[J]. Behavioral and Brain Sciences, 1980, 3 (3): 417- 424
doi: 10.1017/S0140525X00005756
|
| 36 |
BENDER E M, KOLLER A. Climbing towards nlu: on meaning, form, and understanding in the age of data [C] // Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. [S. l. ]: ACL, 2020: 5185-5198.
|
| 37 |
BISK Y, HOLTZMAN A, THOMASON J, et al. Experience grounds language [EB/OL]. [2020-11-02]. https://arxiv.org/abs/2004.10151.
|
| 38 |
HELD R, HEIN A Movement-produced stimulation in the development of visually guided behavior[J]. Journal of Comparative and Physiological Psychology, 1963, 56 (5): 872
|
| 39 |
GIBSON J J The ecological approach to the visual perception of pictures[J]. Leonardo, 1978, 11 (3): 227- 235
doi: 10.2307/1574154
|
| 40 |
EERLAND A, GUADALUPE T M, ZWAAN R A Leaning to the left makes the Eiffel tower seem smaller: posture-modulated estimation[J]. Psychological Science, 2011, 22 (12): 1511- 1514
|
| 41 |
LAKOFF G, JOHNSON M. Metaphors we live by [M]. Chicago: University of Chicago, 1980.
|
| 42 |
LAKOFF G, JOHNSON M, SOWA J F Philosophy in the flesh: the embodied mind and its challenge to western thought[J]. Computational Linguistics, 1999, 25 (4): 631- 634
|
| 43 |
BROOKS R A Elephants don’t play chess[J]. Robotics and Autonomous Systems, 1990, 6 (1/2): 3- 15
|
| 44 |
BROOKS R A Intelligence without representation[J]. Artificial Intelligence, 1991, 47 (1-3): 139- 159
doi: 10.1016/0004-3702(91)90053-M
|
| 45 |
BROOKS R A New approaches to robotics[J]. Science, 1991, 253 (5025): 1227- 1232
doi: 10.1126/science.253.5025.1227
|
| 46 |
PFEIFER R, SCHEIER C. Understanding intelligence [M]. Cambridge: MIT press, 2001.
|
| 47 |
PFEIFER R, BONGARD J. How the body shapes the way we think: a new view of intelligence [M]. Cambridge: MIT press, 2006.
|
| 48 |
ORTIZ JR C L Why we need a physically embodied Turing test and what it might look like[J]. AI Magazine, 2016, 37 (1): 55- 62
doi: 10.1609/aimag.v37i1.2645
|
| 49 |
CHEN L, LU K, RAJESWARAN A, et al. Decision transformer: reinforcement learning via sequence modeling [C] // Advances in Neural Information Processing Systems , [S. 1. ]: Curran Associates, 2021: 15084-15097.
|
| 50 |
ZHENG Q, ZHANG A, GROVER A. Online decision transformer [C] // International Conference on Machine Learning . Baltimore: PMLR, 2022: 27042-27059.
|
| 51 |
FURUTA H, MATSUO Y, GU S S. Generalized decision transformer for offline hindsight information matching [EB/OL]. [2022-02-04]. https://arxiv.org/abs/2111.10364.
|
| 52 |
JANNER M, LI Q, LEVINE S. Offline reinforcement learning as one big sequence modeling problem [C] // Advances in Neural Information Processing Systems . [S. 1. ]: Curran Associates, 2021: 1273-1286.
|
| 53 |
BROHAN A, BROWN N, CARBAJAL J, et al. Rt-1: robotics transformer for real-world control at scale [EB/OL]. [2023-08-11]. https://arxiv.org/abs/2212.06817.
|
| 54 |
REED S, ZOLNA K, PARISOTTO E, et al. A generalist agent [EB/OL]. [2022-05-12]. https://arxiv.org/abs/2205.06175.
|
| 55 |
BROHAN A, BROWN N, CARBAJAL J, et al. Rt-2: vision-language-action models transfer web knowledge to robotic control [EB/OL]. [2023-07-28]. https://arxiv.org/abs/2307.15818.
|
| 56 |
REID M, YAMADA Y, GU S S. Can Wikipedia help offline reinforcement learning? [EB/OL]. [2022-07-24]. https://arxiv.org/abs/2201.12122.
|
| 57 |
BOUSMALIS K, VEZZANI G, RAO D, et al. RoboCat: a self-improving foundation agent for robotic manipulation [EB/OL]. [2023-12-22]. https://arxiv.org/abs/2306.11706.
|
| 58 |
XIAO T, RADOSAVOVIC I, DARRELL T, et al. Masked visual pre-training for motor control [EB/OL]. [2022-03-11]. https://arxiv.org/abs/2203.06173.
|
| 59 |
RADOSAVOVIC I, XIAO T, JAMES S, et al. Real-world robot learning with masked visual pre-training [C] // Conference on Robot Learning . Atlanta: PMLR, 2023: 416-426.
|
| 60 |
SUN Y, MA S, MADAAN R, et al. SMART: self-supervised multi-task pretraining with control transformers [EB/OL]. [2023-01-24]. https://arxiv.org/pdf/2301.09816.
|
| 61 |
LIU F, LIU H, GROVER A, et al. Masked autoencoding for scalable and generalizable decision making [C] // Advances in Neural Information Processing Systems . New Orleans: Curran Associates, 2022: 12608-12618.
|
| 62 |
KARAMCHETI S, NAIR S, CHEN A S, et al. Language-driven representation learning for robotics [EB/OL]. [2023-02-24]. https://arxiv.org/pdf/2302.12766.
|
| 63 |
RADOSAVOVIC I, SHI B, FU L, et al. Robot learning with sensorimotor pre-training [EB/OL]. [2023-12-14]. https://arxiv.org/abs/2306.10007.
|
| 64 |
LU J, BATRA D, PARIKH D, et al. Vilbert: pretraining task-agnostic visiolinguistic representations for vision-and-language tasks [C] // Advances in Neural Information Processing Systems . Vancouver: Curran Associates, 2019: 13-23.
|
| 65 |
CHEN Y C, LI L, YU L, et al. Uniter: universal image-text representation learning [C] // Proceedings of the European Conference on Computer Vision . Glasgow: Springer, 2020: 104-120.
|
| 66 |
LI X, YIN X, LI C, et al. Oscar: object-semantics aligned pre-training for vision-language tasks [C] // Proceedings of the European Conference on Computer Vision . Glasgow: Springer, 2020: 121-137.
|
| 67 |
PHAM H, DAI Z, GHIASI G, et al Combined scaling for zero-shot transfer learning[J]. Neurocomputing, 2023, 555: 126658
|
| 68 |
MAJUMDAR A, SHRIVASTAVA A, LEE S, et al. Improving vision-and-language navigation with image-text pairs from the web [C] // Proceedings of the European Conference on Computer Vision . Glasgow: Springer, 2020: 259-274.
|
| 69 |
GUHUR P L, TAPASWI M, CHEN S, et al. Airbert: in-domain pretraining for vision-and-language navigation [C] // Proceedings of the IEEE/CVF International Conference on Computer Vision . [S. l. ]: IEEE, 2021: 1634-1643.
|
| 70 |
ZHU Y, MOTTAGHI R, KOLVE E, et al. Target-driven visual navigation in indoor scenes using deep reinforcement learning [C] // International Conference on Robotics and Automation . Singapore: IEEE, 2017: 3357-3364.
|
| 71 |
JANG E, IRPAN A, KHANSARI M, et al. Bc-z: zero-shot task generalization with robotic imitation learning [C] // Conference on Robot Learning. Auckland: PMLR, 2022: 991-1002.
|
| 72 |
FU Z, ZHAO T Z, FINN C. Mobile aloha: learning bimanual mobile manipulation with low-cost whole-body teleoperation [EB/OL]. [2024-01-04]. https://arxiv.org/abs/2401.02117.
|
| 73 |
CHI C, XU Z, PAN C, et al. Universal manipulation interface: in-the-wild robot teaching without in-the-wild robots [EB/OL]. [2024-02-15]. https://arxiv.org/abs/2402.10329.
|
| 74 |
GAN W, WAN S, PHILIP S Y. Model-as-a-service (MaaS): a survey [C] // IEEE International Conference on Big Data. Sorrento: IEEE, 2023: 4636-4645.
|
| 75 |
HUANG W, ABBEEL P, PATHAK D, et al. Language models as zero-shot planners: extracting actionable knowledge for embodied agents [C] // International Conference on Machine Learning . Baltimore: PMLR, 2022: 9118-9147.
|
| 76 |
SHAH D, OSIŃSKI B, LEVINE S, et al. LM-Nav: robotic navigation with large pre-trained models of language, vision, and action [C] // Conference on Robot Learning . Atlanta: PMLR, 2023: 492-504.
|
| 77 |
ZHOU G, HONG Y, WU Q. NavGPT: explicit reasoning in vision-and-language navigation with large language models [EB/OL]. [2023-10-19]. https://arxiv.org/abs/2305.16986.
|
| 78 |
DEHGHANI M, DJOLONGA J, MUSTAFA B, et al. Scaling vision transformers to 22 billion parameters [C] // International Conference on Machine Learning . Paris: PMLR, 2023: 7480-7512.
|
| 79 |
DENG J, DONG W, SOCHER R, et al. ImageNet: a large-scale hierarchical image database [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Miami: IEEE, 2009: 248-255.
|
| 80 |
LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft coco: common objects in context [C] // Proceedings of the European Conference on Computer Vision . Zurich: Springer, 2014: 740-755.
|
| 81 |
CORDTS M, OMRAN M, RAMOS S, et al. The cityscapes dataset for semantic urban scene understanding [C] // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 3213-3223.
|
| 82 |
KAPPLER D, BOHG J, SCHAAL S. Leveraging big data for grasp planning [C] // International Conference on Robotics and Automation . Seattle: IEEE, 2015: 4304-4311.
|
| 83 |
MAHLER J, LIANG J, NIYAZ S, et al. Dex-net 2.0: deep learning to plan robust grasps with synthetic point clouds and analytic grasp metrics [EB/OL]. [2017-08-08]. https://arxiv.org/abs/1703.09312.
|
| 84 |
DEPIERRE A, DELLANDRÉA E, CHEN L. Jacquard: a large scale dataset for robotic grasp detection [C] // IEEE/RSJ International Conference on Intelligent Robots and Systems . Madrid: IEEE, 2018: 3511-3516.
|
| 85 |
LEVINE S, PASTOR P, KRIZHEVSKY A, et al Learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection[J]. The International Journal of Robotics Research, 2018, 37 (4-5): 421- 436
doi: 10.1177/0278364917710318
|
| 86 |
KALASHNIKOV D, IRPAN A, PASTOR P, et al. Qt-opt: scalable deep reinforcement learning for vision-based robotic manipulation [EB/OL]. [2018-11-28]. https://arxiv.org/abs/1806.10293.
|
| 87 |
BOUSMALIS K, IRPAN A, WOHLHART P, et al. Using simulation and domain adaptation to improve efficiency of deep robotic grasping [C] // International Conference on Robotics and Automation . Brisbane: IEEE, 2018: 4243-4250.
|
| 88 |
BRAHMBHATT S, HAM C, KEMP C C, et al. ContactDB: analyzing and predicting grasp contact via thermal imaging [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 8709-8719.
|
| 89 |
FANG H S, WANG C, GOU M, et al. Graspnet-1billion: a large-scale benchmark for general object grasping [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . [S. l. ]: IEEE, 2020: 11444-11453.
|
| 90 |
EPPNER C, MOUSAVIAN A, FOX D. Acronym: a large-scale grasp dataset based on simulation [C] // International Conference on Robotics and Automation . Xi’an: IEEE, 2021: 6222-6227.
|
| 91 |
YU K T, BAUZA M, FAZELI N, et al. More than a million ways to be pushed. a high-fidelity experimental dataset of planar pushing [C] // IEEE/RSJ International Conference on Intelligent Robots and Systems . Daejeon: IEEE, 2016: 30-37.
|
| 92 |
FINN C, LEVINE S. Deep visual foresight for planning robot motion [C] // International Conference on Robotics and Automation . Singapore: IEEE, 2017: 2786-2793.
|
| 93 |
EBERT F, FINN C, DASARI S, et al. Visual foresight: model-based deep reinforcement learning for vision-based robotic control [EB/OL]. [2018-12-03]. https://arxiv.org/abs/1812.00568.
|
| 94 |
SAVVA M, CHANG A X, DOSOVITSKIY A, et al. Minos: multimodal indoor simulator for navigation in complex environments [EB/OL]. [2017-12-11]. https://arxiv.org/abs/1712.03931.
|
| 95 |
BATRA D, GOKASLAN A, KEMBHAVI A, et al. Objectnav revisited: on evaluation of embodied agents navigating to objects [EB/OL]. [2020-08-30]. https://arxiv.org/abs/2006.13171.
|
| 96 |
CHEN C, JAIN U, SCHISSLER C, et al. Soundspaces: audio-visual navigation in 3d environments [C] // Proceedings of the European Conference on Computer Vision . Glasgow: Springer, 2020: 17-36.
|
| 97 |
ANDERSON P, WU Q, TENEY D, et al. Vision-and-language navigation: interpreting visually-grounded navigation instructions in real environments [C] // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 3674-3683.
|
| 98 |
THOMASON J, MURRAY M, CAKMAK M, et al. Vision-and-dialog navigation [C] // Conference on Robot Learning . [S. l. ]: PMLR, 2020: 394-406.
|
| 99 |
QI Y, WU Q, ANDERSON P, et al. Reverie: remote embodied visual referring expression in real indoor environments [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . [S. l. ]: IEEE, 2020: 9982-9991.
|
| 100 |
SAVVA M, KADIAN A, MAKSYMETS O, et al. Habitat: a platform for embodied ai research [C] // Proceedings of the IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 9339-9347.
|
| 101 |
KARNAN H, NAIR A, XIAO X, et al. Socially compliant navigation dataset (SCAND): a large-scale dataset of demonstrations for social navigation [EB/OL]. [2022-03-28]. https://arxiv.org/abs/2203.15041.
|
| 102 |
SHAH D, SRIDHAR A, BHORKAR A, et al. GNM: a general navigation model to drive any robot [EB/OL]. [2022-10-07]. https://arxiv.org/abs/2210.03370.
|
| 103 |
DASARI S, EBERT F, TIAN S, et al. RoboNet: large-scale multi-robot learning [EB/OL]. [2020-01-02]. https://arxiv.org/abs/1910.11215.
|
| 104 |
EBERT F, YANG Y, SCHMECKPEPR K, et al. Bridge data: boosting generalization of robotic skills with cross-domain datasets [EB/OL]. [2021-09-27]. https://arxiv.org/abs/2109.13396.
|
| 105 |
FANG H, FANG, H, TANG Z, et al. RH20T: a comprehensive robotic dataset for learning diverse [EB/OL]. [2023-09-26]. https://arxiv.org/abs/2307.00595.
|
| 106 |
KOLVE E, MOTTAGHI R, HAN W, et al. Ai2-thor: an interactive 3d environment for visual AI [EB/OL]. [2022-08-26]. https://arxiv.org/abs/1712.05474.
|
| 107 |
DEITKE M, HAN W, HERRASTI A, et al. Robothor: an open simulation-to-real embodied ai platform [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 3164-3174.
|
| 108 |
DEITKE M, VANDERBILT E, HERRASTI A, et al. Procthor: large-scale embodied ai using procedural generation [C] // Advances in Neural Information Processing Systems , Vancouver: Curran Associates, 2022: 5982-5994.
|
| 109 |
XIANG F, QIN Y, MO K, et al. Sapien: a simulated part-based interactive environment [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 11097-11107.
|
| 110 |
GAN C, SCHWARTZ J, ALTER S, et al. ThreeD-world: a platform for interactive multi-modal physical simulation [EB/OL]. [2021-12-28]. https://arxiv.org/abs/2007.04954.
|
| 111 |
KU A, ANDERSON P, PATEL R, et al. Room-across-room: multilingual vision-and-language navigation with dense spatiotemporal grounding [EB/OL]. [2020-10-15]. https://arxiv.org/abs/2010.07954.
|
| 112 |
XIA F, ZAMIR A R, HE Z, et al. Gibson env: real-world perception for embodied agents [C] // Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 9068-9079.
|
| 113 |
YADAV K, RAMRAKHYA R, RAMAKRISHNAN S K, et al. Habitat-matterport 3d semantics dataset [C] // Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition . Vancouver: IEEE, 2023: 4927-4936.
|
| 114 |
LONG Y, LI X, CAI W, et al. Discuss before moving: visual language navigation via multi-expert discussions [EB/OL]. [2023-09-20]. https://arxiv.org/abs/2309.11382.
|
| 115 |
SHAH D, SRIDHAR A, DASHORA N, et al. Vint: a foundation model for visual navigation [EB/OL]. [2023-10-24]. https://arxiv.org/abs/2306.14846.
|
| 116 |
KADIAN A, TRUONG J, GOKASLAN A, et al Sim2real predictivity: does evaluation in simulation predict real-world performance?[J]. IEEE Robotics and Automation Letters, 2020, 5 (4): 6670- 6677
doi: 10.1109/LRA.2020.3013848
|
| 117 |
ANDERSON P, SHRIVASTAVA A, TRUONG J, et al. Sim-to-real transfer for vision-and-language navigation [C] // Conference on Robot Learning . London: PMLR, 2021: 671-681.
|
| 118 |
TRUONG J, ZITKOVICH A, CHERNOVA S, et al. Indoorsim-to-outdoorreal: learning to navigate outdoors without any outdoor experience [EB/OL]. [2023-05-10]. https://arxiv.org/abs/2305.01098.
|
| 119 |
KHANDELWAL A, WEIHS L, MOTTAGHI R, et al. Simple but effective: clip embeddings for embodied ai [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 14829-14838.
|
| 120 |
GADRE S Y, WORTSMAN M, ILHARCO G, et al. Clip on wheels: zero-shot object navigation as object localization and exploration [EB/OL]. [2022-03-20]. https://arxiv.org/abs/2203.10421.
|
| 121 |
MAJUMDAR A, AGGARWAL G, DEVNANI B, et al. ZSON: zero-shot object-goal navigation using multimodal goal embeddings [C]// Advances in Neural Information Processing Systems . Vancouver: Curran Associates, 2022: 32340-32352.
|
| 122 |
SHAH D, EQUI M R, OSIŃSKI B, et al. Navigation with large language models: semantic guesswork as a heuristic for planning [C] // Conference on Robot Learning . Atlanta: PMLR, 2023: 2683-2699.
|
| 123 |
WANG H, CHEN A G H, LI X, et al. Find what you want: learning demand-conditioned object attribute space for demand-driven navigation [EB/OL]. [2023-11-06]. https://arxiv.org/abs/2309.08138.
|
| 124 |
CAI W, HUANG S, CHENG G, et al. Bridging zero-shot object navigation and foundation models through pixel-guided navigation skill [EB/OL]. [2023-09-21]. https://arxiv.org/abs/2309.10309.
|
| 125 |
LI X, LI C, XIA Q, et al. Robust navigation with language pretraining and stochastic sampling [EB/OL]. [2019-09-05]. https://arxiv.org/abs/1909.02244.
|
| 126 |
KAMATH A, ANDERSON P, WANG S, et al. A new path: scaling vision-and-language navigation with synthetic instructions and imitation learning [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Vancouver: IEEE, 2023: 10813-10823.
|
| 127 |
WANG H, LIANG W, GOOL L V, et al. Towards versatile embodied navigation [C] // Advances in Neural Information Processing Systems , Vancouver: Curran Associates, 2022: 36858-36874.
|
| 128 |
ZHANG R, HAN J, ZHOU A, et al. Llama-adapter: efficient fine-tuning of language models with zero-init attention [EB/OL]. [2023-06-14]. https://arxiv.org/abs/2303.16199.
|
| 129 |
LIU S, ZENG Z, REN T, et al. Grounding dino: marrying dino with grounded pre-training for open-set object detection [EB/OL]. [2023-03-20]. https://arxiv.org/abs/2303.05499.
|
| 130 |
SHAH D, EYSENBACH B, KAHN G, et al. Ving: learning open-world navigation with visual goals [C] // International Conference on Robotics and Automation . Xi’an: IEEE, 2021: 13215-13222.
|
| 131 |
AHN M, BROHAN A, BROWN N, et al. Do as I can, not as i say: grounding language in robotic affordances [EB/OL]. [2022-08-16]. https://arxiv.org/abs/2204.01691.
|
| 132 |
NAIR S, RAJESWARAN A, KUMAR V, et al. R3m: a universal visual representation for robot manipulation [EB/OL]. [2022-11-18]. https://arxiv.org/abs/2203.12601.
|
| 133 |
YANG J, GLOSSOP C, BHORKAR A, et al. Pushing the limits of cross-embodiment learning for manipulation and navigation [EB/OL]. [2024-02-29]. https://arxiv.org/abs/2402.19432.
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|