[1]
TURING A Computing machinery and intelligence
[J]. Mind , 1950 , 59 (236 ): 433
[本文引用: 4]
[2]
BOMMASANI R, HUDSON D A, ADELI E, et al. On the opportunities and risks of foundation models [EB/OL]. [2021-06-12]. https://arxiv.org/abs/2108.07258.
[本文引用: 2]
[3]
DEVLIN J, CHANG M W, LEE K, et al. Bert: pretraining of deep bidirectional transformers for language understanding [EB/OL]. [2019-05-24]. https://arxiv.org/abs/1810.04805.
[本文引用: 7]
[4]
BROWN T, MANN B, RYDER N, et al. Language models are few-shot learners [C] // Advances in Neural Information Processing Systems . [S. 1. ]: Curran Associates, 2020 : 1877-1901.
[本文引用: 5]
[5]
RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision [C]// International Conference on Machine Learning. [S. l. ]: PMLR, 2021: 8748-8763.
[本文引用: 6]
[6]
PADALKAR A, POOLEY A, JAIN A, et al. Open X-embodiment: robotic learning datasets and RT-X models [EB/OL]. [2024-05-22]. https://arxiv.org/abs/2310.08864.
[本文引用: 3]
[7]
BUBECK S, CHANDRASEKARAN V, ELDAN R, et al. Sparks of artificial general intelligence: early experiments with gpt-4 [EB/OL]. [2023-04-13]. https://arxiv.org/abs/2303.12712.
[本文引用: 1]
[8]
ZADOR A, ESCOLA S, RICHARDS B, et al Catalyzing next-generation artificial intelligence through neuroai
[J]. Nature Communications , 2023 , 14 (1 ): 1597
[本文引用: 2]
[9]
BERGLUND L, TONG M, KAUFMANN M, et al. The reversal curse: Llms trained on “a is b” fail to learn “b is a” [EB/OL]. [2024-04-04]. https://arxiv.org/abs/2309.12288.
[本文引用: 1]
[11]
DRIESS D, XIA F, SAJJADI M S, et al. Palm-e: an embodied multimodal language model [EB/OL]. [2023-03-06]. https://arxiv.org/abs/2303.03378.
[本文引用: 7]
[12]
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C] // Advances in Neural Information Processing Systems . Long Beach: Curran Associates, 2017: 5998-6008.
[本文引用: 3]
[13]
HINTON G E, SALAKHUTDINOV R R Reducing the dimensionality of data with neural networks
[J]. Science , 2006 , 313 (5786 ): 504 - 507
DOI:10.1126/science.1127647
[本文引用: 2]
[15]
KAPLAN J, MCCANDLISH S, HENIGHAN T, et al. Scaling laws for neural language models [EB/OL]. [2020-01-22]. http://arxiv.org/abs/2001.08361.
[本文引用: 1]
[16]
RADFORD A, NARASIMHAN K, SALIMANS T, et al. Improving language understanding by generative pre-training [EB/OL]. [2018-06-09]. https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf.
[本文引用: 6]
[17]
RADFORD A, WU J, CHILD R, et al Language models are unsupervised multitask learners
[J]. OpenAI Blog , 2019 , 1 (8 ): 9
[本文引用: 3]
[18]
HE K, CHEN X, XIE S, et al. Masked autoencoders are scalable vision learners [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 16000-16009.
[本文引用: 2]
[19]
HE K, FAN H, WU Y, et al. Momentum contrast for unsupervised visual representation learning [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 9729-9738.
[本文引用: 2]
[20]
OPENAI. Gpt-4 technical report [EB/OL]. [2023-03-04]. https://arxiv.org/abs/2303.8774.
[本文引用: 3]
[21]
CHOWDHERY A, NARANG S, DEVLIN J, et al. Palm: scaling language modeling with pathways [EB/OL]. [2022-10-05]. https://arxiv.org/abs/2204.02311.
[本文引用: 3]
[22]
ANIL R, DAI A M, FIRAT O, et al. Palm 2 technical report [EB/OL]. [2023-09-13]. https://arxiv.org/abs/2305.10403.
[23]
TOUVRON H, LAVRIL T, IZACARD G, et al. Llama: open and efficient foundation language models [EB/OL]. [2023-02-27]. https://arxiv.org/abs/2302.13971.
[本文引用: 1]
[24]
TOUVRON H, MARTIN L, STONE K, et al. Llama 2: open foundation and fine-tuned chat models [EB/OL]. [2023-07-19]. https://arxiv.org/abs/2307.09288.
[本文引用: 2]
[25]
CHEN T, KORNBLITH S, NOROUZI M, et al. A simple framework for contrastive learning of visual representations [C] // International Conference on Machine Learning . [S. l. ]: PMLR, 2020: 1597-1607.
[本文引用: 1]
[26]
GRILL J B, STRUB F, ALTCHÉ F, et al. Bootstrap your own latent: a new approach to self-supervised learning [C] // Advances in Neural Information Processing Systems . [S. 1. ]: Curran Associates, 2020: 21271-21284.
[本文引用: 1]
[27]
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: transformers for image recognition at scale [EB/OL]. [2021-06-03]. https://arxiv.org/abs/2010.11929.
[本文引用: 1]
[28]
JIA C, YANG Y, XIA Y, et al. Scaling up visual and vision-language representation learning with noisy text supervision [C] // International Conference on Machine Learning. [S. l. ]: PMLR, 2021: 4904-4916.
[本文引用: 3]
[29]
CHEN X, WANG X, CHANGPINYO S, et al. Pali: a jointly-scaled multilingual language-image model [EB/OL]. [2023-06-05]. https://arxiv.org/abs/2209.06794.
[本文引用: 3]
[30]
CHEN X, DJOLONGA J, PADLEWSKI P, et al. Pali-x: on scaling up a multilingual vision and language model [EB/OL]. [2023-05-29]. https://arxiv.org/abs/2305.18565.
[本文引用: 4]
[31]
KIRILLOV A, MINTUN E, RAVI N, et al. Segment anything [EB/OL]. [2023-04-05]. https://arxiv.org/abs/2304.02643.
[本文引用: 2]
[32]
WANG X, WANG W, CAO Y, et al. Images speak in images: a generalist painter for in-context visual learning [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Vancouver: IEEE, 2023: 6830-6839.
[本文引用: 1]
[33]
SMITH L, GASSER M The development of embodied cognition: six lessons from babies
[J]. Artificial Life , 2005 , 11 (1/2 ): 13 - 29
[本文引用: 1]
[34]
WEIZENBAUM J Eliza: a computer program for the study of natural language communication between man and machine
[J]. Communications of the ACM , 1966 , 9 (1 ): 36 - 45
[本文引用: 1]
[36]
BENDER E M, KOLLER A. Climbing towards nlu: on meaning, form, and understanding in the age of data [C] // Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. [S. l. ]: ACL, 2020: 5185-5198.
[本文引用: 1]
[37]
BISK Y, HOLTZMAN A, THOMASON J, et al. Experience grounds language [EB/OL]. [2020-11-02]. https://arxiv.org/abs/2004.10151.
[本文引用: 1]
[38]
HELD R, HEIN A Movement-produced stimulation in the development of visually guided behavior
[J]. Journal of Comparative and Physiological Psychology , 1963 , 56 (5 ): 872
[本文引用: 1]
[39]
GIBSON J J The ecological approach to the visual perception of pictures
[J]. Leonardo , 1978 , 11 (3 ): 227 - 235
DOI:10.2307/1574154
[本文引用: 1]
[40]
EERLAND A, GUADALUPE T M, ZWAAN R A Leaning to the left makes the Eiffel tower seem smaller: posture-modulated estimation
[J]. Psychological Science , 2011 , 22 (12 ): 1511 - 1514
[本文引用: 1]
[41]
LAKOFF G, JOHNSON M. Metaphors we live by [M]. Chicago: University of Chicago, 1980.
[本文引用: 1]
[42]
LAKOFF G, JOHNSON M, SOWA J F Philosophy in the flesh: the embodied mind and its challenge to western thought
[J]. Computational Linguistics , 1999 , 25 (4 ): 631 - 634
[本文引用: 1]
[43]
BROOKS R A Elephants don’t play chess
[J]. Robotics and Autonomous Systems , 1990 , 6 (1/2 ): 3 - 15
[本文引用: 1]
[46]
PFEIFER R, SCHEIER C. Understanding intelligence [M]. Cambridge: MIT press, 2001.
[47]
PFEIFER R, BONGARD J. How the body shapes the way we think: a new view of intelligence [M]. Cambridge: MIT press, 2006.
[48]
ORTIZ JR C L Why we need a physically embodied Turing test and what it might look like
[J]. AI Magazine , 2016 , 37 (1 ): 55 - 62
DOI:10.1609/aimag.v37i1.2645
[本文引用: 1]
[49]
CHEN L, LU K, RAJESWARAN A, et al. Decision transformer: reinforcement learning via sequence modeling [C] // Advances in Neural Information Processing Systems , [S. 1. ]: Curran Associates, 2021: 15084-15097.
[本文引用: 1]
[50]
ZHENG Q, ZHANG A, GROVER A. Online decision transformer [C] // International Conference on Machine Learning . Baltimore: PMLR, 2022: 27042-27059.
[51]
FURUTA H, MATSUO Y, GU S S. Generalized decision transformer for offline hindsight information matching [EB/OL]. [2022-02-04]. https://arxiv.org/abs/2111.10364.
[本文引用: 1]
[52]
JANNER M, LI Q, LEVINE S. Offline reinforcement learning as one big sequence modeling problem [C] // Advances in Neural Information Processing Systems . [S. 1. ]: Curran Associates, 2021: 1273-1286.
[本文引用: 1]
[53]
BROHAN A, BROWN N, CARBAJAL J, et al. Rt-1: robotics transformer for real-world control at scale [EB/OL]. [2023-08-11]. https://arxiv.org/abs/2212.06817.
[本文引用: 3]
[54]
REED S, ZOLNA K, PARISOTTO E, et al. A generalist agent [EB/OL]. [2022-05-12]. https://arxiv.org/abs/2205.06175.
[本文引用: 7]
[55]
BROHAN A, BROWN N, CARBAJAL J, et al. Rt-2: vision-language-action models transfer web knowledge to robotic control [EB/OL]. [2023-07-28]. https://arxiv.org/abs/2307.15818.
[本文引用: 4]
[56]
REID M, YAMADA Y, GU S S. Can Wikipedia help offline reinforcement learning? [EB/OL]. [2022-07-24]. https://arxiv.org/abs/2201.12122.
[本文引用: 1]
[57]
BOUSMALIS K, VEZZANI G, RAO D, et al. RoboCat: a self-improving foundation agent for robotic manipulation [EB/OL]. [2023-12-22]. https://arxiv.org/abs/2306.11706.
[本文引用: 6]
[58]
XIAO T, RADOSAVOVIC I, DARRELL T, et al. Masked visual pre-training for motor control [EB/OL]. [2022-03-11]. https://arxiv.org/abs/2203.06173.
[本文引用: 3]
[59]
RADOSAVOVIC I, XIAO T, JAMES S, et al. Real-world robot learning with masked visual pre-training [C] // Conference on Robot Learning . Atlanta: PMLR, 2023: 416-426.
[本文引用: 4]
[60]
SUN Y, MA S, MADAAN R, et al. SMART: self-supervised multi-task pretraining with control transformers [EB/OL]. [2023-01-24]. https://arxiv.org/pdf/2301.09816.
[本文引用: 3]
[61]
LIU F, LIU H, GROVER A, et al. Masked autoencoding for scalable and generalizable decision making [C] // Advances in Neural Information Processing Systems . New Orleans: Curran Associates, 2022: 12608-12618.
[本文引用: 2]
[62]
KARAMCHETI S, NAIR S, CHEN A S, et al. Language-driven representation learning for robotics [EB/OL]. [2023-02-24]. https://arxiv.org/pdf/2302.12766.
[本文引用: 1]
[63]
RADOSAVOVIC I, SHI B, FU L, et al. Robot learning with sensorimotor pre-training [EB/OL]. [2023-12-14]. https://arxiv.org/abs/2306.10007.
[本文引用: 5]
[64]
LU J, BATRA D, PARIKH D, et al. Vilbert: pretraining task-agnostic visiolinguistic representations for vision-and-language tasks [C] // Advances in Neural Information Processing Systems . Vancouver: Curran Associates, 2019: 13-23.
[本文引用: 3]
[65]
CHEN Y C, LI L, YU L, et al. Uniter: universal image-text representation learning [C] // Proceedings of the European Conference on Computer Vision . Glasgow: Springer, 2020: 104-120.
[本文引用: 2]
[66]
LI X, YIN X, LI C, et al. Oscar: object-semantics aligned pre-training for vision-language tasks [C] // Proceedings of the European Conference on Computer Vision . Glasgow: Springer, 2020: 121-137.
[本文引用: 3]
[67]
PHAM H, DAI Z, GHIASI G, et al Combined scaling for zero-shot transfer learning
[J]. Neurocomputing , 2023 , 555 : 126658
[本文引用: 2]
[68]
MAJUMDAR A, SHRIVASTAVA A, LEE S, et al. Improving vision-and-language navigation with image-text pairs from the web [C] // Proceedings of the European Conference on Computer Vision . Glasgow: Springer, 2020: 259-274.
[本文引用: 3]
[69]
GUHUR P L, TAPASWI M, CHEN S, et al. Airbert: in-domain pretraining for vision-and-language navigation [C] // Proceedings of the IEEE/CVF International Conference on Computer Vision . [S. l. ]: IEEE, 2021: 1634-1643.
[本文引用: 2]
[70]
ZHU Y, MOTTAGHI R, KOLVE E, et al. Target-driven visual navigation in indoor scenes using deep reinforcement learning [C] // International Conference on Robotics and Automation . Singapore: IEEE, 2017: 3357-3364.
[本文引用: 2]
[71]
JANG E, IRPAN A, KHANSARI M, et al. Bc-z: zero-shot task generalization with robotic imitation learning [C] // Conference on Robot Learning. Auckland: PMLR, 2022: 991-1002.
[本文引用: 1]
[72]
FU Z, ZHAO T Z, FINN C. Mobile aloha: learning bimanual mobile manipulation with low-cost whole-body teleoperation [EB/OL]. [2024-01-04]. https://arxiv.org/abs/2401.02117.
[73]
CHI C, XU Z, PAN C, et al. Universal manipulation interface: in-the-wild robot teaching without in-the-wild robots [EB/OL]. [2024-02-15]. https://arxiv.org/abs/2402.10329.
[本文引用: 1]
[74]
GAN W, WAN S, PHILIP S Y. Model-as-a-service (MaaS): a survey [C] // IEEE International Conference on Big Data. Sorrento: IEEE, 2023: 4636-4645.
[本文引用: 1]
[75]
HUANG W, ABBEEL P, PATHAK D, et al. Language models as zero-shot planners: extracting actionable knowledge for embodied agents [C] // International Conference on Machine Learning . Baltimore: PMLR, 2022: 9118-9147.
[本文引用: 1]
[76]
SHAH D, OSIŃSKI B, LEVINE S, et al. LM-Nav: robotic navigation with large pre-trained models of language, vision, and action [C] // Conference on Robot Learning . Atlanta: PMLR, 2023: 492-504.
[本文引用: 3]
[77]
ZHOU G, HONG Y, WU Q. NavGPT: explicit reasoning in vision-and-language navigation with large language models [EB/OL]. [2023-10-19]. https://arxiv.org/abs/2305.16986.
[本文引用: 3]
[78]
DEHGHANI M, DJOLONGA J, MUSTAFA B, et al. Scaling vision transformers to 22 billion parameters [C] // International Conference on Machine Learning . Paris: PMLR, 2023: 7480-7512.
[本文引用: 1]
[79]
DENG J, DONG W, SOCHER R, et al. ImageNet: a large-scale hierarchical image database [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Miami: IEEE, 2009: 248-255.
[本文引用: 1]
[80]
LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft coco: common objects in context [C] // Proceedings of the European Conference on Computer Vision . Zurich: Springer, 2014: 740-755.
[本文引用: 1]
[81]
CORDTS M, OMRAN M, RAMOS S, et al. The cityscapes dataset for semantic urban scene understanding [C] // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 3213-3223.
[本文引用: 1]
[82]
KAPPLER D, BOHG J, SCHAAL S. Leveraging big data for grasp planning [C] // International Conference on Robotics and Automation . Seattle: IEEE, 2015: 4304-4311.
[本文引用: 1]
[83]
MAHLER J, LIANG J, NIYAZ S, et al. Dex-net 2.0: deep learning to plan robust grasps with synthetic point clouds and analytic grasp metrics [EB/OL]. [2017-08-08]. https://arxiv.org/abs/1703.09312.
[84]
DEPIERRE A, DELLANDRÉA E, CHEN L. Jacquard: a large scale dataset for robotic grasp detection [C] // IEEE/RSJ International Conference on Intelligent Robots and Systems . Madrid: IEEE, 2018: 3511-3516.
[85]
LEVINE S, PASTOR P, KRIZHEVSKY A, et al Learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection
[J]. The International Journal of Robotics Research , 2018 , 37 (4-5 ): 421 - 436
DOI:10.1177/0278364917710318
[86]
KALASHNIKOV D, IRPAN A, PASTOR P, et al. Qt-opt: scalable deep reinforcement learning for vision-based robotic manipulation [EB/OL]. [2018-11-28]. https://arxiv.org/abs/1806.10293.
[87]
BOUSMALIS K, IRPAN A, WOHLHART P, et al. Using simulation and domain adaptation to improve efficiency of deep robotic grasping [C] // International Conference on Robotics and Automation . Brisbane: IEEE, 2018: 4243-4250.
[88]
BRAHMBHATT S, HAM C, KEMP C C, et al. ContactDB: analyzing and predicting grasp contact via thermal imaging [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 8709-8719.
[89]
FANG H S, WANG C, GOU M, et al. Graspnet-1billion: a large-scale benchmark for general object grasping [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . [S. l. ]: IEEE, 2020: 11444-11453.
[90]
EPPNER C, MOUSAVIAN A, FOX D. Acronym: a large-scale grasp dataset based on simulation [C] // International Conference on Robotics and Automation . Xi’an: IEEE, 2021: 6222-6227.
[本文引用: 1]
[91]
YU K T, BAUZA M, FAZELI N, et al. More than a million ways to be pushed. a high-fidelity experimental dataset of planar pushing [C] // IEEE/RSJ International Conference on Intelligent Robots and Systems . Daejeon: IEEE, 2016: 30-37.
[本文引用: 1]
[92]
FINN C, LEVINE S. Deep visual foresight for planning robot motion [C] // International Conference on Robotics and Automation . Singapore: IEEE, 2017: 2786-2793.
[93]
EBERT F, FINN C, DASARI S, et al. Visual foresight: model-based deep reinforcement learning for vision-based robotic control [EB/OL]. [2018-12-03]. https://arxiv.org/abs/1812.00568.
[本文引用: 1]
[94]
SAVVA M, CHANG A X, DOSOVITSKIY A, et al. Minos: multimodal indoor simulator for navigation in complex environments [EB/OL]. [2017-12-11]. https://arxiv.org/abs/1712.03931.
[本文引用: 1]
[95]
BATRA D, GOKASLAN A, KEMBHAVI A, et al. Objectnav revisited: on evaluation of embodied agents navigating to objects [EB/OL]. [2020-08-30]. https://arxiv.org/abs/2006.13171.
[本文引用: 1]
[96]
CHEN C, JAIN U, SCHISSLER C, et al. Soundspaces: audio-visual navigation in 3d environments [C] // Proceedings of the European Conference on Computer Vision . Glasgow: Springer, 2020: 17-36.
[本文引用: 1]
[97]
ANDERSON P, WU Q, TENEY D, et al. Vision-and-language navigation: interpreting visually-grounded navigation instructions in real environments [C] // Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 3674-3683.
[本文引用: 4]
[98]
THOMASON J, MURRAY M, CAKMAK M, et al. Vision-and-dialog navigation [C] // Conference on Robot Learning . [S. l. ]: PMLR, 2020: 394-406.
[99]
QI Y, WU Q, ANDERSON P, et al. Reverie: remote embodied visual referring expression in real indoor environments [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . [S. l. ]: IEEE, 2020: 9982-9991.
[本文引用: 2]
[100]
SAVVA M, KADIAN A, MAKSYMETS O, et al. Habitat: a platform for embodied ai research [C] // Proceedings of the IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 9339-9347.
[本文引用: 4]
[101]
KARNAN H, NAIR A, XIAO X, et al. Socially compliant navigation dataset (SCAND): a large-scale dataset of demonstrations for social navigation [EB/OL]. [2022-03-28]. https://arxiv.org/abs/2203.15041.
[本文引用: 2]
[102]
SHAH D, SRIDHAR A, BHORKAR A, et al. GNM: a general navigation model to drive any robot [EB/OL]. [2022-10-07]. https://arxiv.org/abs/2210.03370.
[本文引用: 3]
[103]
DASARI S, EBERT F, TIAN S, et al. RoboNet: large-scale multi-robot learning [EB/OL]. [2020-01-02]. https://arxiv.org/abs/1910.11215.
[本文引用: 2]
[104]
EBERT F, YANG Y, SCHMECKPEPR K, et al. Bridge data: boosting generalization of robotic skills with cross-domain datasets [EB/OL]. [2021-09-27]. https://arxiv.org/abs/2109.13396.
[本文引用: 2]
[105]
FANG H, FANG, H, TANG Z, et al. RH20T: a comprehensive robotic dataset for learning diverse [EB/OL]. [2023-09-26]. https://arxiv.org/abs/2307.00595.
[本文引用: 2]
[106]
KOLVE E, MOTTAGHI R, HAN W, et al. Ai2-thor: an interactive 3d environment for visual AI [EB/OL]. [2022-08-26]. https://arxiv.org/abs/1712.05474.
[本文引用: 1]
[107]
DEITKE M, HAN W, HERRASTI A, et al. Robothor: an open simulation-to-real embodied ai platform [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 3164-3174.
[本文引用: 2]
[108]
DEITKE M, VANDERBILT E, HERRASTI A, et al. Procthor: large-scale embodied ai using procedural generation [C] // Advances in Neural Information Processing Systems , Vancouver: Curran Associates, 2022: 5982-5994.
[本文引用: 1]
[109]
XIANG F, QIN Y, MO K, et al. Sapien: a simulated part-based interactive environment [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 11097-11107.
[本文引用: 1]
[110]
GAN C, SCHWARTZ J, ALTER S, et al. ThreeD-world: a platform for interactive multi-modal physical simulation [EB/OL]. [2021-12-28]. https://arxiv.org/abs/2007.04954.
[本文引用: 1]
[111]
KU A, ANDERSON P, PATEL R, et al. Room-across-room: multilingual vision-and-language navigation with dense spatiotemporal grounding [EB/OL]. [2020-10-15]. https://arxiv.org/abs/2010.07954.
[本文引用: 1]
[112]
XIA F, ZAMIR A R, HE Z, et al. Gibson env: real-world perception for embodied agents [C] // Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 9068-9079.
[本文引用: 1]
[113]
YADAV K, RAMRAKHYA R, RAMAKRISHNAN S K, et al. Habitat-matterport 3d semantics dataset [C] // Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition . Vancouver: IEEE, 2023: 4927-4936.
[本文引用: 1]
[114]
LONG Y, LI X, CAI W, et al. Discuss before moving: visual language navigation via multi-expert discussions [EB/OL]. [2023-09-20]. https://arxiv.org/abs/2309.11382.
[本文引用: 3]
[115]
SHAH D, SRIDHAR A, DASHORA N, et al. Vint: a foundation model for visual navigation [EB/OL]. [2023-10-24]. https://arxiv.org/abs/2306.14846.
[本文引用: 3]
[116]
KADIAN A, TRUONG J, GOKASLAN A, et al Sim2real predictivity: does evaluation in simulation predict real-world performance?
[J]. IEEE Robotics and Automation Letters , 2020 , 5 (4 ): 6670 - 6677
DOI:10.1109/LRA.2020.3013848
[本文引用: 1]
[117]
ANDERSON P, SHRIVASTAVA A, TRUONG J, et al. Sim-to-real transfer for vision-and-language navigation [C] // Conference on Robot Learning . London: PMLR, 2021: 671-681.
[本文引用: 1]
[118]
TRUONG J, ZITKOVICH A, CHERNOVA S, et al. Indoorsim-to-outdoorreal: learning to navigate outdoors without any outdoor experience [EB/OL]. [2023-05-10]. https://arxiv.org/abs/2305.01098.
[本文引用: 1]
[119]
KHANDELWAL A, WEIHS L, MOTTAGHI R, et al. Simple but effective: clip embeddings for embodied ai [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 14829-14838.
[本文引用: 2]
[120]
GADRE S Y, WORTSMAN M, ILHARCO G, et al. Clip on wheels: zero-shot object navigation as object localization and exploration [EB/OL]. [2022-03-20]. https://arxiv.org/abs/2203.10421.
[本文引用: 2]
[121]
MAJUMDAR A, AGGARWAL G, DEVNANI B, et al. ZSON: zero-shot object-goal navigation using multimodal goal embeddings [C]// Advances in Neural Information Processing Systems . Vancouver: Curran Associates, 2022: 32340-32352.
[本文引用: 2]
[122]
SHAH D, EQUI M R, OSIŃSKI B, et al. Navigation with large language models: semantic guesswork as a heuristic for planning [C] // Conference on Robot Learning . Atlanta: PMLR, 2023: 2683-2699.
[本文引用: 2]
[123]
WANG H, CHEN A G H, LI X, et al. Find what you want: learning demand-conditioned object attribute space for demand-driven navigation [EB/OL]. [2023-11-06]. https://arxiv.org/abs/2309.08138.
[本文引用: 2]
[124]
CAI W, HUANG S, CHENG G, et al. Bridging zero-shot object navigation and foundation models through pixel-guided navigation skill [EB/OL]. [2023-09-21]. https://arxiv.org/abs/2309.10309.
[本文引用: 2]
[125]
LI X, LI C, XIA Q, et al. Robust navigation with language pretraining and stochastic sampling [EB/OL]. [2019-09-05]. https://arxiv.org/abs/1909.02244.
[本文引用: 2]
[126]
KAMATH A, ANDERSON P, WANG S, et al. A new path: scaling vision-and-language navigation with synthetic instructions and imitation learning [C] // Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Vancouver: IEEE, 2023: 10813-10823.
[本文引用: 2]
[127]
WANG H, LIANG W, GOOL L V, et al. Towards versatile embodied navigation [C] // Advances in Neural Information Processing Systems , Vancouver: Curran Associates, 2022: 36858-36874.
[本文引用: 2]
[128]
ZHANG R, HAN J, ZHOU A, et al. Llama-adapter: efficient fine-tuning of language models with zero-init attention [EB/OL]. [2023-06-14]. https://arxiv.org/abs/2303.16199.
[本文引用: 1]
[129]
LIU S, ZENG Z, REN T, et al. Grounding dino: marrying dino with grounded pre-training for open-set object detection [EB/OL]. [2023-03-20]. https://arxiv.org/abs/2303.05499.
[本文引用: 1]
[130]
SHAH D, EYSENBACH B, KAHN G, et al. Ving: learning open-world navigation with visual goals [C] // International Conference on Robotics and Automation . Xi’an: IEEE, 2021: 13215-13222.
[本文引用: 1]
[131]
AHN M, BROHAN A, BROWN N, et al. Do as I can, not as i say: grounding language in robotic affordances [EB/OL]. [2022-08-16]. https://arxiv.org/abs/2204.01691.
[本文引用: 2]
[132]
NAIR S, RAJESWARAN A, KUMAR V, et al. R3m: a universal visual representation for robot manipulation [EB/OL]. [2022-11-18]. https://arxiv.org/abs/2203.12601.
[本文引用: 2]
[133]
YANG J, GLOSSOP C, BHORKAR A, et al. Pushing the limits of cross-embodiment learning for manipulation and navigation [EB/OL]. [2024-02-29]. https://arxiv.org/abs/2402.19432.
[本文引用: 2]
[134]
WEI J, TAY Y, BOMMASANI R, et al. Emergent abilities of large language models [EB/OL]. [2022-10-26]. https://arxiv.org/abs/2206.07682.
[本文引用: 1]
Computing machinery and intelligence
4
1950
... “从哪种方法着手[人工智能]是最好的?这是一个困难的决定. 一些人认为,从抽象的活动,如下棋开始,可能是最佳路径. 而另一些人则认为,最好的方式是为机器装备顶级的传感器,然后教会它听说英语,这一过程类似于对一个小孩子进行教育,通过指向物体并告诉它们的名称来学习. 我不确定哪一种方法是正确的,但我相信这两种方法都应该尝试. ”——阿兰·图灵[1 ] ...
... 早在1950年,人工智能之父阿兰·图灵[1 ] 指出人工智能的发展存在着2条技术路线,分别被后人称作“无身的”(disembodied)和“具身的”(embodied)智能(以下简称“无身智能”和“具身智能”). 纵观人工智能的发展史,无身智能(如自然语言处理、计算机视觉)占据了主导地位,这是因为开发无身智能相对容易,无须构建复杂的物理身体. ...
... 长期以来,机器能否真正理解人类语言一直是热门的讨论话题. 图灵提出模仿游戏(即图灵测试),判断是否能够通过书面对话将机器与人类区分开来[1 ] . 研究表明,人类倾向于将自己所理解的含义投射到人工智能体所产生的输出上,以为人工智能体像人类一样“理解”了语言,需要谨慎设计评估机器理解能力的测试[34 ] . 为此,Searle通过他著名的“中文房间论证”(Chinese room argument)挑战了这样一个假设:一个与人类行为无法区分的系统必须拥有心智[35 ] . 在中文房间里,一个不懂中文的人仅通过遵循一套指令就能对中文请求作出回应,这表明机器可能仅仅在操作语言的符号而不理解其含义. 这意味着语言的意义不能完全脱离现实世界而单独存在于其形式之中. Harnad将该问题称为符号落地问题(symbol grounding problem)[10 ] ,指出一个人仅通过参照中文-中文字典来学习中文是困难的(作为第二语言)甚至不可能的(作为第一语言),这是因为在学习的过程中没有将符号与物理世界联系起来. 最近,针对大型语言模型的出现,Bender等[36 ] 设计了章鱼测试的思想实验,表明仅基于语言的形式训练的大型语言模型,由于缺乏将话语与现实世界联系起来的能力,无法通过更敏感的测试. 这说明尽管大型语言模型在自然语言处理方面取得了巨大进步,但不意味着它们真正具备了自然语言理解的能力. 语言模型要实现真正的情境语言理解,需要具备物理世界和社会背景的知识[37 ] . ...
... 实际上,具身认知科学在广泛的意义上研究行为和心智之间的关系,不仅限于语言和视觉. 许多实验已经证明,认知可以受到身体的影响[40 ] ,抽象的认知状态是基于身体状态的[41 -42 ] . 这一理念启发了一部分人工智能科学家们长期致力于具身人工智能[43 −48 ] . 最近,随着基座模型的出现和现代传感器及执行器的成熟,具身方向的研究工作重新被人们重视,经典的图灵测试的概念甚至被扩展到所谓的具身图灵测试[8 ] ,这反映了评估机器的理解能力正趋于考虑其与环境的物理互动. 这与图灵最初的设想相呼应,他认为机器智能的发展应该包含无形体和有形体的智能探索[1 ] . ...
2
... 近年来,无身的基座模型[2 ] 在自然语言处理和计算机视觉领域取得了显著成就,引发了学术界和产业界的广泛关注. 基座模型(foundation models),通称大模型,通常先从互联网抓取的海量数据中学习通用的表征,再通过微调(fine-tuning)[3 ] 或提示词工程(prompt engineering)[4 -5 ] ,在极少量甚至没有下游任务数据的情况下迁移到下游任务. 基座模型能够涌现出执行训练时未见过的任务的能力,这种能力被广泛认为是通用人工智能的重要标志. 现在出现了一种趋势:完成特定任务的最有效的方式是迁移通用模型,而非训练定制模型[6 ] . ...
... Bommasani等[2 ] 引入 “基座模型”这一术语,以标识机器学习领域的一次范式转变. 这类模型指的是通用的、大规模的预训练模型,它们通常基于Transformer架构[12 ] ,通过自监督学习的方法(self-supervised learning)[13 -14 ] 进行预训练. Transformer架构具有规模化定律(scaling law),即模型可以增大至极大的规模,性能仍有增长[15 ] . 自监督学习,如自回归语言建模(autoregressive language modeling)[4 ,16 -17 ] 、遮罩自编码(mask autoencoding)[3 ,18 ] 和对比学习(contrastive learning)[5 ,19 ] ,通过定义输入的一部分为预测目标,利用海量的未标注数据训练出模型强大的表征能力. 这些通过自监督学习训练出的大型模型能够适用于各种任务,特别是能够泛化到训练时未见的任务,在自然语言处理、计算机视觉、多模态学习等多个领域取得了成功. ...
7
... 近年来,无身的基座模型[2 ] 在自然语言处理和计算机视觉领域取得了显著成就,引发了学术界和产业界的广泛关注. 基座模型(foundation models),通称大模型,通常先从互联网抓取的海量数据中学习通用的表征,再通过微调(fine-tuning)[3 ] 或提示词工程(prompt engineering)[4 -5 ] ,在极少量甚至没有下游任务数据的情况下迁移到下游任务. 基座模型能够涌现出执行训练时未见过的任务的能力,这种能力被广泛认为是通用人工智能的重要标志. 现在出现了一种趋势:完成特定任务的最有效的方式是迁移通用模型,而非训练定制模型[6 ] . ...
... Bommasani等[2 ] 引入 “基座模型”这一术语,以标识机器学习领域的一次范式转变. 这类模型指的是通用的、大规模的预训练模型,它们通常基于Transformer架构[12 ] ,通过自监督学习的方法(self-supervised learning)[13 -14 ] 进行预训练. Transformer架构具有规模化定律(scaling law),即模型可以增大至极大的规模,性能仍有增长[15 ] . 自监督学习,如自回归语言建模(autoregressive language modeling)[4 ,16 -17 ] 、遮罩自编码(mask autoencoding)[3 ,18 ] 和对比学习(contrastive learning)[5 ,19 ] ,通过定义输入的一部分为预测目标,利用海量的未标注数据训练出模型强大的表征能力. 这些通过自监督学习训练出的大型模型能够适用于各种任务,特别是能够泛化到训练时未见的任务,在自然语言处理、计算机视觉、多模态学习等多个领域取得了成功. ...
... 基座模型是在自然语言处理(natural language processing, NLP)领域出现的,以BERT[3 ] 和GPT[16 ] 为代表. BERT采用遮罩自编码的方式,遮盖了大约15%的输入序列,使得模型预测被遮盖的词元(token),训练出通用的特征表示. 与BERT不同,GPT以自回归的方式预测输入序列中的下一个词元. 利用这2种方式训练出来的模型在自然语言处理领域实现了突破,激发了大型语言模型(large language models, LLMs)的研究热潮[20 -24 ] . 如表1 所示为代表性的大型语言模型的规模比较. ...
... Scale comparison of large language model
Tab.1 大型语言模型 参数量 BERT[3 ] 1.10×108 /3.40×108 GPT[16 ] 1.17×108 GPT-2[17 ] 1.5×109 GPT-3[4 ] 1.75×1011 PaLM[21 ] 8×109 /6.2×1010 /5.40×1011 LLaMA[23 ] 7×109 /1.3×1010 /3.3×1010 /6.5×1010 LLaMA 2[24 ] 7×109 /1.3×1010 /7.0×1010
受到自然语言处理成功的启发,大规模样本预训练的思想已扩展到计算机视觉领域. 与语言信号相比,视觉信号的维度更高,空间冗余性更大,需要更有效的特征表示方法. 这一需求催生了对比学习(contrastive learning)的引入,通过最大化正样本对的相似度和最小化负样本对的相似度来学习有效的特征表示[19 ,25 -26 ] . 视觉Transformer[27 ] (ViT)的引入,使得同时对视觉和语言2种模态基于Transformer进行建模成为可能. 得益于对比学习和视觉Transformer的结合,出现了多模态的视觉-语言模型,从自然语言和视觉的监督信号中学习多模态的表征[5 ,28 ] . 最近,文献中公开参数数据的多模态模型发展到了百亿级别的参数规模[29 -30 ] . 借助视觉Transformer,遮罩自编码器(masked autoencoder, MAE)[18 ] 在计算机视觉中获得了与自然语言处理中的遮罩自编码[3 ] 相仿的结果,推动了视觉基座模型的成功[31 -32 ] . ...
... 受到自然语言处理成功的启发,大规模样本预训练的思想已扩展到计算机视觉领域. 与语言信号相比,视觉信号的维度更高,空间冗余性更大,需要更有效的特征表示方法. 这一需求催生了对比学习(contrastive learning)的引入,通过最大化正样本对的相似度和最小化负样本对的相似度来学习有效的特征表示[19 ,25 -26 ] . 视觉Transformer[27 ] (ViT)的引入,使得同时对视觉和语言2种模态基于Transformer进行建模成为可能. 得益于对比学习和视觉Transformer的结合,出现了多模态的视觉-语言模型,从自然语言和视觉的监督信号中学习多模态的表征[5 ,28 ] . 最近,文献中公开参数数据的多模态模型发展到了百亿级别的参数规模[29 -30 ] . 借助视觉Transformer,遮罩自编码器(masked autoencoder, MAE)[18 ] 在计算机视觉中获得了与自然语言处理中的遮罩自编码[3 ] 相仿的结果,推动了视觉基座模型的成功[31 -32 ] . ...
... 现代人工智能经历了从监督预训练向自监督预训练的范式转变. 与监督预训练依靠标注好的数据不同,自监督预训练能够利用大量的未标注数据来学习具有通用性的表示. 这种方法使得自监督预训练可以广泛应用于众多的下游任务,并在这些任务上取得先进的性能. 例如,语言模型可以通过自回归或遮罩自编码的方式进行预训练. 在自回归的方式中,模型训练目标是预测给定前文单元序列的下一个单元[4 ,16 -17 ,20 ] . 在遮罩自编码的方式中,模型旨在预测在给定的未遮罩的单元序列基础上,那些被遮罩的单元是什么[3 ] . 这2种自监督预训练方法都利用大量的未标注数据来学习具有广泛适用性的表示,这些表示随后可以通过微调或各种零样本转移技术应用到各种下游任务上. 下面探讨如何将自监督预训练技术应用于具身智能体的场景. ...
... 视觉语言导航(vision-and-language navigation, VLN)是指智能体依据自然语言指令进行导航[97 ] . 随着大型语言模型如BERT[3 ] 和GPT[16 ] 的出现,将它们应用到视觉语言导航成为研究的新趋势. PreSS微调BERT和GPT以学习文本表征,这些表征能够更好地泛化到以前未见过的指令[125 ] . 此外,先预训练图像-文本对的视觉-语言多模态表征,再迁移到视觉语言任务,正逐渐成为一种主流方法,代表性的多模态模型包括ViLBERT[64 ] 和Oscar[66 ] . 对于导航任务,VLN-BERT采用ViLBERT[68 ] ,Airbert采用ViLBERT和Oscar[69 ] ,以更好地协调导航的视觉和语言指令. ...
5
... 近年来,无身的基座模型[2 ] 在自然语言处理和计算机视觉领域取得了显著成就,引发了学术界和产业界的广泛关注. 基座模型(foundation models),通称大模型,通常先从互联网抓取的海量数据中学习通用的表征,再通过微调(fine-tuning)[3 ] 或提示词工程(prompt engineering)[4 -5 ] ,在极少量甚至没有下游任务数据的情况下迁移到下游任务. 基座模型能够涌现出执行训练时未见过的任务的能力,这种能力被广泛认为是通用人工智能的重要标志. 现在出现了一种趋势:完成特定任务的最有效的方式是迁移通用模型,而非训练定制模型[6 ] . ...
... Bommasani等[2 ] 引入 “基座模型”这一术语,以标识机器学习领域的一次范式转变. 这类模型指的是通用的、大规模的预训练模型,它们通常基于Transformer架构[12 ] ,通过自监督学习的方法(self-supervised learning)[13 -14 ] 进行预训练. Transformer架构具有规模化定律(scaling law),即模型可以增大至极大的规模,性能仍有增长[15 ] . 自监督学习,如自回归语言建模(autoregressive language modeling)[4 ,16 -17 ] 、遮罩自编码(mask autoencoding)[3 ,18 ] 和对比学习(contrastive learning)[5 ,19 ] ,通过定义输入的一部分为预测目标,利用海量的未标注数据训练出模型强大的表征能力. 这些通过自监督学习训练出的大型模型能够适用于各种任务,特别是能够泛化到训练时未见的任务,在自然语言处理、计算机视觉、多模态学习等多个领域取得了成功. ...
... Scale comparison of large language model
Tab.1 大型语言模型 参数量 BERT[3 ] 1.10×108 /3.40×108 GPT[16 ] 1.17×108 GPT-2[17 ] 1.5×109 GPT-3[4 ] 1.75×1011 PaLM[21 ] 8×109 /6.2×1010 /5.40×1011 LLaMA[23 ] 7×109 /1.3×1010 /3.3×1010 /6.5×1010 LLaMA 2[24 ] 7×109 /1.3×1010 /7.0×1010
受到自然语言处理成功的启发,大规模样本预训练的思想已扩展到计算机视觉领域. 与语言信号相比,视觉信号的维度更高,空间冗余性更大,需要更有效的特征表示方法. 这一需求催生了对比学习(contrastive learning)的引入,通过最大化正样本对的相似度和最小化负样本对的相似度来学习有效的特征表示[19 ,25 -26 ] . 视觉Transformer[27 ] (ViT)的引入,使得同时对视觉和语言2种模态基于Transformer进行建模成为可能. 得益于对比学习和视觉Transformer的结合,出现了多模态的视觉-语言模型,从自然语言和视觉的监督信号中学习多模态的表征[5 ,28 ] . 最近,文献中公开参数数据的多模态模型发展到了百亿级别的参数规模[29 -30 ] . 借助视觉Transformer,遮罩自编码器(masked autoencoder, MAE)[18 ] 在计算机视觉中获得了与自然语言处理中的遮罩自编码[3 ] 相仿的结果,推动了视觉基座模型的成功[31 -32 ] . ...
... 现代人工智能经历了从监督预训练向自监督预训练的范式转变. 与监督预训练依靠标注好的数据不同,自监督预训练能够利用大量的未标注数据来学习具有通用性的表示. 这种方法使得自监督预训练可以广泛应用于众多的下游任务,并在这些任务上取得先进的性能. 例如,语言模型可以通过自回归或遮罩自编码的方式进行预训练. 在自回归的方式中,模型训练目标是预测给定前文单元序列的下一个单元[4 ,16 -17 ,20 ] . 在遮罩自编码的方式中,模型旨在预测在给定的未遮罩的单元序列基础上,那些被遮罩的单元是什么[3 ] . 这2种自监督预训练方法都利用大量的未标注数据来学习具有广泛适用性的表示,这些表示随后可以通过微调或各种零样本转移技术应用到各种下游任务上. 下面探讨如何将自监督预训练技术应用于具身智能体的场景. ...
... 在探索互联网规模的图像文本对预训练的同时,人类指令数据的稀缺成为研究的瓶颈. 为此,MARVAL 利用伴随的合成数据集Marky-Gibson,提供了具有合成指令的大规模数据增强[126 ] . 另一条研究路径利用外部大型语言模型. LM-Nav[76 ] 采用GPT-3[4 ] 来识别由视觉导航模型ViNG[130 ] 预定义的图上的地标,展示了基于预训练模型且无须任何微调的导航系统. 最近,NavGPT通过零样本动作预测,展示了大型语言模型在复杂具身场景中的推理能力[77 ] . DiscussNav用提示词在大语言模型上建立几个领域专家,用模拟的专家咨询会议来导航智能体,展示了令人印象深刻的零样本迁移性能[114 ] . ...
6
... 近年来,无身的基座模型[2 ] 在自然语言处理和计算机视觉领域取得了显著成就,引发了学术界和产业界的广泛关注. 基座模型(foundation models),通称大模型,通常先从互联网抓取的海量数据中学习通用的表征,再通过微调(fine-tuning)[3 ] 或提示词工程(prompt engineering)[4 -5 ] ,在极少量甚至没有下游任务数据的情况下迁移到下游任务. 基座模型能够涌现出执行训练时未见过的任务的能力,这种能力被广泛认为是通用人工智能的重要标志. 现在出现了一种趋势:完成特定任务的最有效的方式是迁移通用模型,而非训练定制模型[6 ] . ...
... Bommasani等[2 ] 引入 “基座模型”这一术语,以标识机器学习领域的一次范式转变. 这类模型指的是通用的、大规模的预训练模型,它们通常基于Transformer架构[12 ] ,通过自监督学习的方法(self-supervised learning)[13 -14 ] 进行预训练. Transformer架构具有规模化定律(scaling law),即模型可以增大至极大的规模,性能仍有增长[15 ] . 自监督学习,如自回归语言建模(autoregressive language modeling)[4 ,16 -17 ] 、遮罩自编码(mask autoencoding)[3 ,18 ] 和对比学习(contrastive learning)[5 ,19 ] ,通过定义输入的一部分为预测目标,利用海量的未标注数据训练出模型强大的表征能力. 这些通过自监督学习训练出的大型模型能够适用于各种任务,特别是能够泛化到训练时未见的任务,在自然语言处理、计算机视觉、多模态学习等多个领域取得了成功. ...
... 受到自然语言处理成功的启发,大规模样本预训练的思想已扩展到计算机视觉领域. 与语言信号相比,视觉信号的维度更高,空间冗余性更大,需要更有效的特征表示方法. 这一需求催生了对比学习(contrastive learning)的引入,通过最大化正样本对的相似度和最小化负样本对的相似度来学习有效的特征表示[19 ,25 -26 ] . 视觉Transformer[27 ] (ViT)的引入,使得同时对视觉和语言2种模态基于Transformer进行建模成为可能. 得益于对比学习和视觉Transformer的结合,出现了多模态的视觉-语言模型,从自然语言和视觉的监督信号中学习多模态的表征[5 ,28 ] . 最近,文献中公开参数数据的多模态模型发展到了百亿级别的参数规模[29 -30 ] . 借助视觉Transformer,遮罩自编码器(masked autoencoder, MAE)[18 ] 在计算机视觉中获得了与自然语言处理中的遮罩自编码[3 ] 相仿的结果,推动了视觉基座模型的成功[31 -32 ] . ...
... 多模态最常见的形态是将视觉和语言的模态连接起来. ViLBERT[64 ] 、UNITER[65 ] 和Oscar[66 ] 等视觉-语言模型在复杂的下游任务,例如视觉问答和视觉常识推理,展现了改进性能的潜力. 这些方法一般包括一个图像编码器、一个目标检测模型和一个预训练的语言模型,它们通过对比学习在图像-文本对上联合微调,以学习视觉-语言表征. 通过扩大模型规模,CLIP[5 ] 、ALIGN[28 ] 和BASIC从网页抓取丰富但嘈杂的视觉-语言数据来学习视觉表征,表现出了强大的任务泛化能力[67 ] . 最近,PaLI[29 ] 和PaLI-X[30 ] 继续扩大模型规模和数据量. 这些视觉-语言多模态模型可以应用于视觉-语言的具身智能体. 例如,VLN-BERT展示了对无身的网络的预训练可以改善具身智能体的视觉表征[68 ] . Airbert利用图像-标题二元组生成路径-指令二元组,改进了预训练的方法[69 ] . ...
... Large multimodal model
Tab.2 大型多模态模型 视觉 语言 本体 动作 参数量 图像-文本对数量 轨迹量 ViLBERT[64 ] ✓ ✓ — — 1.55×108 3.1×106 — UNITER[65 ] ✓ ✓ — — 8.6×107 /3.03×108 9.6×106 — Oscar[66 ] ✓ ✓ — — 1.10×108 /3.40×108 6.5×106 — CLIP[5 ] ✓ ✓ — — 3.70×108 4.00×108 — ALIGN[28 ] ✓ ✓ — — 7.90×108 1.8×109 — BASIC[67 ] ✓ ✓ — — 3×109 6.6×109 — PaLI[29 ] ✓ ✓ — — 1.7×1010 1×109 — PaLI-X[30 ] ✓ ✓ — — 5.5×1010 — — Gato[54 ] ✓ ✓ ✓ ✓ 1.2×109 2.1×109 6.3×107 RPT[63 ] ✓ — ✓ ✓ 3.08×108 — 2.0×104 RoboCat[57 ] ✓ — ✓ ✓ 1.18×109 — 2.8×106
2.5. 强化学习与模仿学习 具身智能体传统上是通过强化学习的方式进行训练[13 ] . 在这种方式下,智能体通过与环境的互动来学习,这包括基于智能体的当前状态采取行动,从环境中接收奖励作为反馈,基于这些奖励来更新智能体的决策策略[70 ] . 有时候,智能体与环境交互的任务很难定义出合适的奖励函数. 传统的强化学习方法存在样本效率低下、学习过程缓慢的问题. 强化学习的试错过程还会为一些任务带来安全问题. 为了解决这些问题,模仿学习被提出作为训练智能体的方法. 在模仿学习中,智能体通过观察专家(无论是人类还是其他智能体)的行为来学习. 这种方法允许智能体模仿专家的行为,之后可能通过强化学习进行进一步的微调. 在这一过程中,专家的行为被记录下来,构成了训练智能体的数据集. 近年来,模仿学习在具身智能体的训练中越来越受到关注,越来越多的具身智能体使用模仿学习进行训练[54 ,59 ,71 -73 ] ,出现了针对具身智能体的大规模数据集,以支持这种训练方式,详见3.1节. ...
... 进入基座模型的时代,自监督预训练在众多任务中展现出了优异的表征能力. 实际上,在很多情况下,自监督预训练的效果超过了监督式预训练[5 ,16 ] . 尽管如此,预训练的模型需要依赖特定任务的数据集进行微调,以更好地适应下游任务. 关于基座智能体自监督预训练的更多细节,参见2.3节. ...
3
... 近年来,无身的基座模型[2 ] 在自然语言处理和计算机视觉领域取得了显著成就,引发了学术界和产业界的广泛关注. 基座模型(foundation models),通称大模型,通常先从互联网抓取的海量数据中学习通用的表征,再通过微调(fine-tuning)[3 ] 或提示词工程(prompt engineering)[4 -5 ] ,在极少量甚至没有下游任务数据的情况下迁移到下游任务. 基座模型能够涌现出执行训练时未见过的任务的能力,这种能力被广泛认为是通用人工智能的重要标志. 现在出现了一种趋势:完成特定任务的最有效的方式是迁移通用模型,而非训练定制模型[6 ] . ...
... 在基座智能体的背景下,数据集往往涵盖多个任务、多个场景,甚至多种具身形式. 在导航方面,SCAND是面向户外场景的长距离数据集,支持2种不同的机器人[101 ] . GNM在6个不同的机器人上采集了60 h的导航轨迹数据[102 ] . 在机器人操控领域,RoboNet为7种机器人平台,不针对具体任务,提供了1 500万视频帧的预训练数据[103 ] . Bridge Data采集了71种任务的训练数据[104 ] . RH20T为7种不同配置的机器人平台提供了约150种技能的训练数据[105 ] . Open X-Embodiment数据库[6 ] 汇集了来自21个机构的22种不同机器人的数据集,展现了527项技能和160 266个任务. 在这些大规模数据集上训练的高容量模型展现了更好的泛化能力. 如表3 所示为多具身的智能体数据集. ...
... Real-world, large-scale dataset for multitask or cross-embodiment agent
Tab.3 数据集 技能数 轨迹量 帧数/106 时长/h 具身形态数 SCAND[101 ] — 138 — 8.7 2 RoboNet[103 ] — 1.62×105 15 — 7 Bridge Data[104 ] 71 7.2×103 — — 1 RH20T[105 ] 150 1.10×105 40 — 7 Open X-Embodiment[6 ] 527 106 — — 22 GNM[102 ] — — — 60 6
3.2. 模拟器 近年来,许多适用于具身智能的新模拟器被开发出来. 模拟器可以为智能体提供既安全又高效的学习环境. 此外,模拟器可以用于生成大量数据,这些在现实世界中的收集成本会非常高. 模拟器常用作基准测试,评估和比较不同方法的效果. ...
1
... 尽管基座模型涌现出了通用人工智能的火花[7 ] ,但越来越多的证据表明,它们在因果推理及物理世界的常识方面的表现远低于智能生物的水平[8 -9 ] . 当前的智能其实是“互联网智能”,缺少物理世界的生活经验,而真正的智能需要与物理世界互动,将自身的知识与物理世界建立起联系[10 -11 ] . 这是图灵提出的人工智能的另一个方向,现在被称作具身智能(embodied intelligence). 它在图灵的时代是难以实现的,但随着基座模型的出现和传感器与执行器的进步,发展具身智能的时机已经成熟. ...
Catalyzing next-generation arti?cial intelligence through neuroai
2
2023
... 尽管基座模型涌现出了通用人工智能的火花[7 ] ,但越来越多的证据表明,它们在因果推理及物理世界的常识方面的表现远低于智能生物的水平[8 -9 ] . 当前的智能其实是“互联网智能”,缺少物理世界的生活经验,而真正的智能需要与物理世界互动,将自身的知识与物理世界建立起联系[10 -11 ] . 这是图灵提出的人工智能的另一个方向,现在被称作具身智能(embodied intelligence). 它在图灵的时代是难以实现的,但随着基座模型的出现和传感器与执行器的进步,发展具身智能的时机已经成熟. ...
... 实际上,具身认知科学在广泛的意义上研究行为和心智之间的关系,不仅限于语言和视觉. 许多实验已经证明,认知可以受到身体的影响[40 ] ,抽象的认知状态是基于身体状态的[41 -42 ] . 这一理念启发了一部分人工智能科学家们长期致力于具身人工智能[43 −48 ] . 最近,随着基座模型的出现和现代传感器及执行器的成熟,具身方向的研究工作重新被人们重视,经典的图灵测试的概念甚至被扩展到所谓的具身图灵测试[8 ] ,这反映了评估机器的理解能力正趋于考虑其与环境的物理互动. 这与图灵最初的设想相呼应,他认为机器智能的发展应该包含无形体和有形体的智能探索[1 ] . ...
1
... 尽管基座模型涌现出了通用人工智能的火花[7 ] ,但越来越多的证据表明,它们在因果推理及物理世界的常识方面的表现远低于智能生物的水平[8 -9 ] . 当前的智能其实是“互联网智能”,缺少物理世界的生活经验,而真正的智能需要与物理世界互动,将自身的知识与物理世界建立起联系[10 -11 ] . 这是图灵提出的人工智能的另一个方向,现在被称作具身智能(embodied intelligence). 它在图灵的时代是难以实现的,但随着基座模型的出现和传感器与执行器的进步,发展具身智能的时机已经成熟. ...
The symbol grounding problem
2
1990
... 尽管基座模型涌现出了通用人工智能的火花[7 ] ,但越来越多的证据表明,它们在因果推理及物理世界的常识方面的表现远低于智能生物的水平[8 -9 ] . 当前的智能其实是“互联网智能”,缺少物理世界的生活经验,而真正的智能需要与物理世界互动,将自身的知识与物理世界建立起联系[10 -11 ] . 这是图灵提出的人工智能的另一个方向,现在被称作具身智能(embodied intelligence). 它在图灵的时代是难以实现的,但随着基座模型的出现和传感器与执行器的进步,发展具身智能的时机已经成熟. ...
... 长期以来,机器能否真正理解人类语言一直是热门的讨论话题. 图灵提出模仿游戏(即图灵测试),判断是否能够通过书面对话将机器与人类区分开来[1 ] . 研究表明,人类倾向于将自己所理解的含义投射到人工智能体所产生的输出上,以为人工智能体像人类一样“理解”了语言,需要谨慎设计评估机器理解能力的测试[34 ] . 为此,Searle通过他著名的“中文房间论证”(Chinese room argument)挑战了这样一个假设:一个与人类行为无法区分的系统必须拥有心智[35 ] . 在中文房间里,一个不懂中文的人仅通过遵循一套指令就能对中文请求作出回应,这表明机器可能仅仅在操作语言的符号而不理解其含义. 这意味着语言的意义不能完全脱离现实世界而单独存在于其形式之中. Harnad将该问题称为符号落地问题(symbol grounding problem)[10 ] ,指出一个人仅通过参照中文-中文字典来学习中文是困难的(作为第二语言)甚至不可能的(作为第一语言),这是因为在学习的过程中没有将符号与物理世界联系起来. 最近,针对大型语言模型的出现,Bender等[36 ] 设计了章鱼测试的思想实验,表明仅基于语言的形式训练的大型语言模型,由于缺乏将话语与现实世界联系起来的能力,无法通过更敏感的测试. 这说明尽管大型语言模型在自然语言处理方面取得了巨大进步,但不意味着它们真正具备了自然语言理解的能力. 语言模型要实现真正的情境语言理解,需要具备物理世界和社会背景的知识[37 ] . ...
7
... 尽管基座模型涌现出了通用人工智能的火花[7 ] ,但越来越多的证据表明,它们在因果推理及物理世界的常识方面的表现远低于智能生物的水平[8 -9 ] . 当前的智能其实是“互联网智能”,缺少物理世界的生活经验,而真正的智能需要与物理世界互动,将自身的知识与物理世界建立起联系[10 -11 ] . 这是图灵提出的人工智能的另一个方向,现在被称作具身智能(embodied intelligence). 它在图灵的时代是难以实现的,但随着基座模型的出现和传感器与执行器的进步,发展具身智能的时机已经成熟. ...
... 尽管决策Transformer最初被提出时采用了非具身的形式,但它完全可以扩展到具身的应用场景中. 如图1 所示为自回归的具身的决策Transformer实例. 决策Transformer的核心思想是将传统的强化学习问题转变为监督学习问题. 这种转变意味着奖励信号是可选的,使得根据这一架构训练出来的智能体既可以是传统意义上的强化学习智能体[53 ] ,也可以是不依赖于奖励信号的非强化学习智能体[11 ,54 -55 ] . ...
... 受到自回归的大型预训练语言模型的启发,Reid 等[56 ] 提出以自回归的方式预训练决策Transformer. 与原始决策Transformer相比,收敛速度显著加快. Gato将决策Transformer扩展到通用的具身智能体[54 ] . Gato的观察序列包括了分词文本、图像、离散值(例如Atari的按钮操作)和本体感知序列(被离散为1 024个均匀区间). RoboCat将Gato(西班牙语中“猫”的意思)扩展为机器人操控的基座智能体[57 ] . RoboCat采用VQ-GAN作为图像编码器,通过行为克隆自我提高性能. 一些其他的具身智能体将大型语言模型适配到具身模型. PaLM-E[11 ] 使大型语言模型PaLM[21 ] 能够在现实世界中做出决策. 观察和状态估计被嵌入为语言单元并送入PaLM. 输出为语言序列,可以被低级策略控制器解释. RT-2[55 ] 微调了视觉-语言模型,将动作表达为词元. 在测试时,文本单元被反词元化成动作,实现了机器人的控制. ...
... 在某些场景下,通过互联网服务来实现基座智能体变得可行. 模型即服务(model as a service, MaaS)作为创新的范式,极大地促进了基座模型的开发和部署[74 ] . 在模型即服务的范式下,成熟的无身基座模型可以部署到具身智能体. 研究发现,大型语言模型(LLMs)能够有效地将用自然语言表达的高级任务分解成一系列低级动作,无须额外训练[75 ] . 例如LM-Nav直接利用GPT-3在现实世界中导航[76 ] . NavGPT展示了在视觉语言导航任务中,如何利用GPT-3.5和GPT-4进行零样本的动作预测[77 ] . 此外,PaLM-E[11 ] 整合了540B的PaLM[21 ] 和22B的Vision Transformer[78 ] ,以执行多种具身推理任务. 所有这些智能体的运作都需要连接到互联网,以便访问这些外部的大型模型. ...
... 虽然在模拟器中训练得到的模型能够在模拟环境下表现良好,但模拟环境与现实世界之间存在的明显差异是其在物理机器人上应用的主要障碍[114 ] . 在这方面,一些具身方法同时在模拟和现实世界[11 ,57 ,115 ] ,或完全在现实世界中[60 ] 评估模型的表现. ...
... Comparison of foundation agent for robotic manipulation
Tab.6 智能体 语言 基座模型 真实世界 多具身 参数量 SayCan[131 ] ✓ PaLM ✓ ✓ 5.40×1011 R3M[132 ] ✓ — ✓ — — Gato[54 ] ✓ — ✓ ✓ 1.2×109 RT-1[53 ] ✓ SayCan ✓ — 5.40×1011 PaLM-E[11 ] ✓ PaLM, ViT-22B ✓ ✓ 5.62×1011 RT-2[55 ] ✓ PaLI-X ✓ — 5.5×1010 SMART[60 ] — — — — 1.08×107 MVP[58 ] — — — — 2.2×107 Real MVP[59 ] — — ✓ ✓ 3.07×108 RPT[63 ] — — ✓ ✓ 3.07×108 RoboCat[57 ] [133 ] — — ✓ ✓ 1.2×109 8
SayCan通过价值函数将大型语言模型与现实世界连接在一起,使其执行真实世界的动作[131 ] . R3M通过结合时间对比学习、视频-语言对齐和L1惩罚,预训练鼓励稀疏和紧凑的表征的多模态模型[132 ] . Gato将文本、图像、离散值和连续值转换为词元(token),并将它们输入到Transformer中,以学习一般性策略[54 ] . RT-1关注开放的任务无关的训练范式,以零样本迁移的方式泛化到更多的机器人任务[53 ] . PaLM-E[11 ] 将操控的规划问题形式转化为语言问题,将来自任意模态的输入转化为词元,并将词元输入到PaLM中. RT-2[55 ] 结合大型多模态模型,例如PaLI-X[30 ] ,并直接预测机器人动作. ...
... SayCan通过价值函数将大型语言模型与现实世界连接在一起,使其执行真实世界的动作[131 ] . R3M通过结合时间对比学习、视频-语言对齐和L1惩罚,预训练鼓励稀疏和紧凑的表征的多模态模型[132 ] . Gato将文本、图像、离散值和连续值转换为词元(token),并将它们输入到Transformer中,以学习一般性策略[54 ] . RT-1关注开放的任务无关的训练范式,以零样本迁移的方式泛化到更多的机器人任务[53 ] . PaLM-E[11 ] 将操控的规划问题形式转化为语言问题,将来自任意模态的输入转化为词元,并将词元输入到PaLM中. RT-2[55 ] 结合大型多模态模型,例如PaLI-X[30 ] ,并直接预测机器人动作. ...
3
... Bommasani等[2 ] 引入 “基座模型”这一术语,以标识机器学习领域的一次范式转变. 这类模型指的是通用的、大规模的预训练模型,它们通常基于Transformer架构[12 ] ,通过自监督学习的方法(self-supervised learning)[13 -14 ] 进行预训练. Transformer架构具有规模化定律(scaling law),即模型可以增大至极大的规模,性能仍有增长[15 ] . 自监督学习,如自回归语言建模(autoregressive language modeling)[4 ,16 -17 ] 、遮罩自编码(mask autoencoding)[3 ,18 ] 和对比学习(contrastive learning)[5 ,19 ] ,通过定义输入的一部分为预测目标,利用海量的未标注数据训练出模型强大的表征能力. 这些通过自监督学习训练出的大型模型能够适用于各种任务,特别是能够泛化到训练时未见的任务,在自然语言处理、计算机视觉、多模态学习等多个领域取得了成功. ...
... 具身智能中的“具身”源于认知科学的具身认知(embodied cognition)领域,它认为智能是在与环境的感知运动的行动中显现出来的[12 ,33 ] . 具身认知领域同样关注语言和视觉的理解. 下面,从语言和视觉2个方面,回顾具身认知领域的发展. ...
... Transformer架构[12 ] 已成为现代人工智能研究的核心架构. 它在以下3个关键方面促进了基座模型引发的范式转变. 1)Transformer架构能够捕捉长距离的依赖关系,训练出具有更强大表征能力的模型. 2)Transformer利用了硬件的并行处理能力,能够被扩展到极大的模型规模. 3)Transformer能够作为跨不同模态的统一编码器,例如式(1)中的$ {\boldsymbol{a}}_{t-T\to t} $ $ {\boldsymbol{s}}_{t-T\to t} $ $ {\boldsymbol{o}}_{t-T\to t} $ $ {\boldsymbol{x}}_{t-T\to t} $
Reducing the dimensionality of data with neural networks
2
2006
... Bommasani等[2 ] 引入 “基座模型”这一术语,以标识机器学习领域的一次范式转变. 这类模型指的是通用的、大规模的预训练模型,它们通常基于Transformer架构[12 ] ,通过自监督学习的方法(self-supervised learning)[13 -14 ] 进行预训练. Transformer架构具有规模化定律(scaling law),即模型可以增大至极大的规模,性能仍有增长[15 ] . 自监督学习,如自回归语言建模(autoregressive language modeling)[4 ,16 -17 ] 、遮罩自编码(mask autoencoding)[3 ,18 ] 和对比学习(contrastive learning)[5 ,19 ] ,通过定义输入的一部分为预测目标,利用海量的未标注数据训练出模型强大的表征能力. 这些通过自监督学习训练出的大型模型能够适用于各种任务,特别是能够泛化到训练时未见的任务,在自然语言处理、计算机视觉、多模态学习等多个领域取得了成功. ...
... 具身智能体传统上是通过强化学习的方式进行训练[13 ] . 在这种方式下,智能体通过与环境的互动来学习,这包括基于智能体的当前状态采取行动,从环境中接收奖励作为反馈,基于这些奖励来更新智能体的决策策略[70 ] . 有时候,智能体与环境交互的任务很难定义出合适的奖励函数. 传统的强化学习方法存在样本效率低下、学习过程缓慢的问题. 强化学习的试错过程还会为一些任务带来安全问题. 为了解决这些问题,模仿学习被提出作为训练智能体的方法. 在模仿学习中,智能体通过观察专家(无论是人类还是其他智能体)的行为来学习. 这种方法允许智能体模仿专家的行为,之后可能通过强化学习进行进一步的微调. 在这一过程中,专家的行为被记录下来,构成了训练智能体的数据集. 近年来,模仿学习在具身智能体的训练中越来越受到关注,越来越多的具身智能体使用模仿学习进行训练[54 ,59 ,71 -73 ] ,出现了针对具身智能体的大规模数据集,以支持这种训练方式,详见3.1节. ...
A fast learning algorithm for deep belief nets
1
2006
... Bommasani等[2 ] 引入 “基座模型”这一术语,以标识机器学习领域的一次范式转变. 这类模型指的是通用的、大规模的预训练模型,它们通常基于Transformer架构[12 ] ,通过自监督学习的方法(self-supervised learning)[13 -14 ] 进行预训练. Transformer架构具有规模化定律(scaling law),即模型可以增大至极大的规模,性能仍有增长[15 ] . 自监督学习,如自回归语言建模(autoregressive language modeling)[4 ,16 -17 ] 、遮罩自编码(mask autoencoding)[3 ,18 ] 和对比学习(contrastive learning)[5 ,19 ] ,通过定义输入的一部分为预测目标,利用海量的未标注数据训练出模型强大的表征能力. 这些通过自监督学习训练出的大型模型能够适用于各种任务,特别是能够泛化到训练时未见的任务,在自然语言处理、计算机视觉、多模态学习等多个领域取得了成功. ...
1
... Bommasani等[2 ] 引入 “基座模型”这一术语,以标识机器学习领域的一次范式转变. 这类模型指的是通用的、大规模的预训练模型,它们通常基于Transformer架构[12 ] ,通过自监督学习的方法(self-supervised learning)[13 -14 ] 进行预训练. Transformer架构具有规模化定律(scaling law),即模型可以增大至极大的规模,性能仍有增长[15 ] . 自监督学习,如自回归语言建模(autoregressive language modeling)[4 ,16 -17 ] 、遮罩自编码(mask autoencoding)[3 ,18 ] 和对比学习(contrastive learning)[5 ,19 ] ,通过定义输入的一部分为预测目标,利用海量的未标注数据训练出模型强大的表征能力. 这些通过自监督学习训练出的大型模型能够适用于各种任务,特别是能够泛化到训练时未见的任务,在自然语言处理、计算机视觉、多模态学习等多个领域取得了成功. ...
6
... Bommasani等[2 ] 引入 “基座模型”这一术语,以标识机器学习领域的一次范式转变. 这类模型指的是通用的、大规模的预训练模型,它们通常基于Transformer架构[12 ] ,通过自监督学习的方法(self-supervised learning)[13 -14 ] 进行预训练. Transformer架构具有规模化定律(scaling law),即模型可以增大至极大的规模,性能仍有增长[15 ] . 自监督学习,如自回归语言建模(autoregressive language modeling)[4 ,16 -17 ] 、遮罩自编码(mask autoencoding)[3 ,18 ] 和对比学习(contrastive learning)[5 ,19 ] ,通过定义输入的一部分为预测目标,利用海量的未标注数据训练出模型强大的表征能力. 这些通过自监督学习训练出的大型模型能够适用于各种任务,特别是能够泛化到训练时未见的任务,在自然语言处理、计算机视觉、多模态学习等多个领域取得了成功. ...
... 基座模型是在自然语言处理(natural language processing, NLP)领域出现的,以BERT[3 ] 和GPT[16 ] 为代表. BERT采用遮罩自编码的方式,遮盖了大约15%的输入序列,使得模型预测被遮盖的词元(token),训练出通用的特征表示. 与BERT不同,GPT以自回归的方式预测输入序列中的下一个词元. 利用这2种方式训练出来的模型在自然语言处理领域实现了突破,激发了大型语言模型(large language models, LLMs)的研究热潮[20 -24 ] . 如表1 所示为代表性的大型语言模型的规模比较. ...
... Scale comparison of large language model
Tab.1 大型语言模型 参数量 BERT[3 ] 1.10×108 /3.40×108 GPT[16 ] 1.17×108 GPT-2[17 ] 1.5×109 GPT-3[4 ] 1.75×1011 PaLM[21 ] 8×109 /6.2×1010 /5.40×1011 LLaMA[23 ] 7×109 /1.3×1010 /3.3×1010 /6.5×1010 LLaMA 2[24 ] 7×109 /1.3×1010 /7.0×1010
受到自然语言处理成功的启发,大规模样本预训练的思想已扩展到计算机视觉领域. 与语言信号相比,视觉信号的维度更高,空间冗余性更大,需要更有效的特征表示方法. 这一需求催生了对比学习(contrastive learning)的引入,通过最大化正样本对的相似度和最小化负样本对的相似度来学习有效的特征表示[19 ,25 -26 ] . 视觉Transformer[27 ] (ViT)的引入,使得同时对视觉和语言2种模态基于Transformer进行建模成为可能. 得益于对比学习和视觉Transformer的结合,出现了多模态的视觉-语言模型,从自然语言和视觉的监督信号中学习多模态的表征[5 ,28 ] . 最近,文献中公开参数数据的多模态模型发展到了百亿级别的参数规模[29 -30 ] . 借助视觉Transformer,遮罩自编码器(masked autoencoder, MAE)[18 ] 在计算机视觉中获得了与自然语言处理中的遮罩自编码[3 ] 相仿的结果,推动了视觉基座模型的成功[31 -32 ] . ...
... 现代人工智能经历了从监督预训练向自监督预训练的范式转变. 与监督预训练依靠标注好的数据不同,自监督预训练能够利用大量的未标注数据来学习具有通用性的表示. 这种方法使得自监督预训练可以广泛应用于众多的下游任务,并在这些任务上取得先进的性能. 例如,语言模型可以通过自回归或遮罩自编码的方式进行预训练. 在自回归的方式中,模型训练目标是预测给定前文单元序列的下一个单元[4 ,16 -17 ,20 ] . 在遮罩自编码的方式中,模型旨在预测在给定的未遮罩的单元序列基础上,那些被遮罩的单元是什么[3 ] . 这2种自监督预训练方法都利用大量的未标注数据来学习具有广泛适用性的表示,这些表示随后可以通过微调或各种零样本转移技术应用到各种下游任务上. 下面探讨如何将自监督预训练技术应用于具身智能体的场景. ...
... 进入基座模型的时代,自监督预训练在众多任务中展现出了优异的表征能力. 实际上,在很多情况下,自监督预训练的效果超过了监督式预训练[5 ,16 ] . 尽管如此,预训练的模型需要依赖特定任务的数据集进行微调,以更好地适应下游任务. 关于基座智能体自监督预训练的更多细节,参见2.3节. ...
... 视觉语言导航(vision-and-language navigation, VLN)是指智能体依据自然语言指令进行导航[97 ] . 随着大型语言模型如BERT[3 ] 和GPT[16 ] 的出现,将它们应用到视觉语言导航成为研究的新趋势. PreSS微调BERT和GPT以学习文本表征,这些表征能够更好地泛化到以前未见过的指令[125 ] . 此外,先预训练图像-文本对的视觉-语言多模态表征,再迁移到视觉语言任务,正逐渐成为一种主流方法,代表性的多模态模型包括ViLBERT[64 ] 和Oscar[66 ] . 对于导航任务,VLN-BERT采用ViLBERT[68 ] ,Airbert采用ViLBERT和Oscar[69 ] ,以更好地协调导航的视觉和语言指令. ...
Language models are unsupervised multitask learners
3
2019
... Bommasani等[2 ] 引入 “基座模型”这一术语,以标识机器学习领域的一次范式转变. 这类模型指的是通用的、大规模的预训练模型,它们通常基于Transformer架构[12 ] ,通过自监督学习的方法(self-supervised learning)[13 -14 ] 进行预训练. Transformer架构具有规模化定律(scaling law),即模型可以增大至极大的规模,性能仍有增长[15 ] . 自监督学习,如自回归语言建模(autoregressive language modeling)[4 ,16 -17 ] 、遮罩自编码(mask autoencoding)[3 ,18 ] 和对比学习(contrastive learning)[5 ,19 ] ,通过定义输入的一部分为预测目标,利用海量的未标注数据训练出模型强大的表征能力. 这些通过自监督学习训练出的大型模型能够适用于各种任务,特别是能够泛化到训练时未见的任务,在自然语言处理、计算机视觉、多模态学习等多个领域取得了成功. ...
... Scale comparison of large language model
Tab.1 大型语言模型 参数量 BERT[3 ] 1.10×108 /3.40×108 GPT[16 ] 1.17×108 GPT-2[17 ] 1.5×109 GPT-3[4 ] 1.75×1011 PaLM[21 ] 8×109 /6.2×1010 /5.40×1011 LLaMA[23 ] 7×109 /1.3×1010 /3.3×1010 /6.5×1010 LLaMA 2[24 ] 7×109 /1.3×1010 /7.0×1010
受到自然语言处理成功的启发,大规模样本预训练的思想已扩展到计算机视觉领域. 与语言信号相比,视觉信号的维度更高,空间冗余性更大,需要更有效的特征表示方法. 这一需求催生了对比学习(contrastive learning)的引入,通过最大化正样本对的相似度和最小化负样本对的相似度来学习有效的特征表示[19 ,25 -26 ] . 视觉Transformer[27 ] (ViT)的引入,使得同时对视觉和语言2种模态基于Transformer进行建模成为可能. 得益于对比学习和视觉Transformer的结合,出现了多模态的视觉-语言模型,从自然语言和视觉的监督信号中学习多模态的表征[5 ,28 ] . 最近,文献中公开参数数据的多模态模型发展到了百亿级别的参数规模[29 -30 ] . 借助视觉Transformer,遮罩自编码器(masked autoencoder, MAE)[18 ] 在计算机视觉中获得了与自然语言处理中的遮罩自编码[3 ] 相仿的结果,推动了视觉基座模型的成功[31 -32 ] . ...
... 现代人工智能经历了从监督预训练向自监督预训练的范式转变. 与监督预训练依靠标注好的数据不同,自监督预训练能够利用大量的未标注数据来学习具有通用性的表示. 这种方法使得自监督预训练可以广泛应用于众多的下游任务,并在这些任务上取得先进的性能. 例如,语言模型可以通过自回归或遮罩自编码的方式进行预训练. 在自回归的方式中,模型训练目标是预测给定前文单元序列的下一个单元[4 ,16 -17 ,20 ] . 在遮罩自编码的方式中,模型旨在预测在给定的未遮罩的单元序列基础上,那些被遮罩的单元是什么[3 ] . 这2种自监督预训练方法都利用大量的未标注数据来学习具有广泛适用性的表示,这些表示随后可以通过微调或各种零样本转移技术应用到各种下游任务上. 下面探讨如何将自监督预训练技术应用于具身智能体的场景. ...
2
... Bommasani等[2 ] 引入 “基座模型”这一术语,以标识机器学习领域的一次范式转变. 这类模型指的是通用的、大规模的预训练模型,它们通常基于Transformer架构[12 ] ,通过自监督学习的方法(self-supervised learning)[13 -14 ] 进行预训练. Transformer架构具有规模化定律(scaling law),即模型可以增大至极大的规模,性能仍有增长[15 ] . 自监督学习,如自回归语言建模(autoregressive language modeling)[4 ,16 -17 ] 、遮罩自编码(mask autoencoding)[3 ,18 ] 和对比学习(contrastive learning)[5 ,19 ] ,通过定义输入的一部分为预测目标,利用海量的未标注数据训练出模型强大的表征能力. 这些通过自监督学习训练出的大型模型能够适用于各种任务,特别是能够泛化到训练时未见的任务,在自然语言处理、计算机视觉、多模态学习等多个领域取得了成功. ...
... 受到自然语言处理成功的启发,大规模样本预训练的思想已扩展到计算机视觉领域. 与语言信号相比,视觉信号的维度更高,空间冗余性更大,需要更有效的特征表示方法. 这一需求催生了对比学习(contrastive learning)的引入,通过最大化正样本对的相似度和最小化负样本对的相似度来学习有效的特征表示[19 ,25 -26 ] . 视觉Transformer[27 ] (ViT)的引入,使得同时对视觉和语言2种模态基于Transformer进行建模成为可能. 得益于对比学习和视觉Transformer的结合,出现了多模态的视觉-语言模型,从自然语言和视觉的监督信号中学习多模态的表征[5 ,28 ] . 最近,文献中公开参数数据的多模态模型发展到了百亿级别的参数规模[29 -30 ] . 借助视觉Transformer,遮罩自编码器(masked autoencoder, MAE)[18 ] 在计算机视觉中获得了与自然语言处理中的遮罩自编码[3 ] 相仿的结果,推动了视觉基座模型的成功[31 -32 ] . ...
2
... Bommasani等[2 ] 引入 “基座模型”这一术语,以标识机器学习领域的一次范式转变. 这类模型指的是通用的、大规模的预训练模型,它们通常基于Transformer架构[12 ] ,通过自监督学习的方法(self-supervised learning)[13 -14 ] 进行预训练. Transformer架构具有规模化定律(scaling law),即模型可以增大至极大的规模,性能仍有增长[15 ] . 自监督学习,如自回归语言建模(autoregressive language modeling)[4 ,16 -17 ] 、遮罩自编码(mask autoencoding)[3 ,18 ] 和对比学习(contrastive learning)[5 ,19 ] ,通过定义输入的一部分为预测目标,利用海量的未标注数据训练出模型强大的表征能力. 这些通过自监督学习训练出的大型模型能够适用于各种任务,特别是能够泛化到训练时未见的任务,在自然语言处理、计算机视觉、多模态学习等多个领域取得了成功. ...
... 受到自然语言处理成功的启发,大规模样本预训练的思想已扩展到计算机视觉领域. 与语言信号相比,视觉信号的维度更高,空间冗余性更大,需要更有效的特征表示方法. 这一需求催生了对比学习(contrastive learning)的引入,通过最大化正样本对的相似度和最小化负样本对的相似度来学习有效的特征表示[19 ,25 -26 ] . 视觉Transformer[27 ] (ViT)的引入,使得同时对视觉和语言2种模态基于Transformer进行建模成为可能. 得益于对比学习和视觉Transformer的结合,出现了多模态的视觉-语言模型,从自然语言和视觉的监督信号中学习多模态的表征[5 ,28 ] . 最近,文献中公开参数数据的多模态模型发展到了百亿级别的参数规模[29 -30 ] . 借助视觉Transformer,遮罩自编码器(masked autoencoder, MAE)[18 ] 在计算机视觉中获得了与自然语言处理中的遮罩自编码[3 ] 相仿的结果,推动了视觉基座模型的成功[31 -32 ] . ...
3
... 基座模型是在自然语言处理(natural language processing, NLP)领域出现的,以BERT[3 ] 和GPT[16 ] 为代表. BERT采用遮罩自编码的方式,遮盖了大约15%的输入序列,使得模型预测被遮盖的词元(token),训练出通用的特征表示. 与BERT不同,GPT以自回归的方式预测输入序列中的下一个词元. 利用这2种方式训练出来的模型在自然语言处理领域实现了突破,激发了大型语言模型(large language models, LLMs)的研究热潮[20 -24 ] . 如表1 所示为代表性的大型语言模型的规模比较. ...
... 现代人工智能经历了从监督预训练向自监督预训练的范式转变. 与监督预训练依靠标注好的数据不同,自监督预训练能够利用大量的未标注数据来学习具有通用性的表示. 这种方法使得自监督预训练可以广泛应用于众多的下游任务,并在这些任务上取得先进的性能. 例如,语言模型可以通过自回归或遮罩自编码的方式进行预训练. 在自回归的方式中,模型训练目标是预测给定前文单元序列的下一个单元[4 ,16 -17 ,20 ] . 在遮罩自编码的方式中,模型旨在预测在给定的未遮罩的单元序列基础上,那些被遮罩的单元是什么[3 ] . 这2种自监督预训练方法都利用大量的未标注数据来学习具有广泛适用性的表示,这些表示随后可以通过微调或各种零样本转移技术应用到各种下游任务上. 下面探讨如何将自监督预训练技术应用于具身智能体的场景. ...
... 目标导航(object-goal navigation 或 visual goal navigation)的目标是指引智能体前往目标物体所在地. 基座模型的应用使得对目标导航的零样本迁移成为可能. 例如,EmbCLIP证明了CLIP编码的骨干相比于ImageNet预训练的骨干网络更有效,展示了在训练阶段未涉及的4个类别的测试成果[119 ] . CLIP on Wheels(简称CoW)[120 ] 采用结合启发式探索策略的模型,能够扩展到更多未见过的类别. ZSON在目标图片上进行训练,旨在适应开放世界场景而不仅限于预定义的物体类别[121 ] . LFG利用GPT-3.5作为搜索的启发式,进行路径规划[122 ] . Wang等[123 ] 将目标导航设定为需求驱动的任务,使用GPT-3.5将用户需求转化为物体目标. PixNav[124 ] 利用4个外部大型模型,包括LLaMA-Adapter[128 ] 、GPT-4[20 ] 、Grounding DINO[129 ] 和SAM[31 ] ,设计逐步细化的提示模板,探索了基座模型在自我定位和构建结构化记忆方面的潜力. ...
3
... Scale comparison of large language model
Tab.1 大型语言模型 参数量 BERT[3 ] 1.10×108 /3.40×108 GPT[16 ] 1.17×108 GPT-2[17 ] 1.5×109 GPT-3[4 ] 1.75×1011 PaLM[21 ] 8×109 /6.2×1010 /5.40×1011 LLaMA[23 ] 7×109 /1.3×1010 /3.3×1010 /6.5×1010 LLaMA 2[24 ] 7×109 /1.3×1010 /7.0×1010
受到自然语言处理成功的启发,大规模样本预训练的思想已扩展到计算机视觉领域. 与语言信号相比,视觉信号的维度更高,空间冗余性更大,需要更有效的特征表示方法. 这一需求催生了对比学习(contrastive learning)的引入,通过最大化正样本对的相似度和最小化负样本对的相似度来学习有效的特征表示[19 ,25 -26 ] . 视觉Transformer[27 ] (ViT)的引入,使得同时对视觉和语言2种模态基于Transformer进行建模成为可能. 得益于对比学习和视觉Transformer的结合,出现了多模态的视觉-语言模型,从自然语言和视觉的监督信号中学习多模态的表征[5 ,28 ] . 最近,文献中公开参数数据的多模态模型发展到了百亿级别的参数规模[29 -30 ] . 借助视觉Transformer,遮罩自编码器(masked autoencoder, MAE)[18 ] 在计算机视觉中获得了与自然语言处理中的遮罩自编码[3 ] 相仿的结果,推动了视觉基座模型的成功[31 -32 ] . ...
... 受到自回归的大型预训练语言模型的启发,Reid 等[56 ] 提出以自回归的方式预训练决策Transformer. 与原始决策Transformer相比,收敛速度显著加快. Gato将决策Transformer扩展到通用的具身智能体[54 ] . Gato的观察序列包括了分词文本、图像、离散值(例如Atari的按钮操作)和本体感知序列(被离散为1 024个均匀区间). RoboCat将Gato(西班牙语中“猫”的意思)扩展为机器人操控的基座智能体[57 ] . RoboCat采用VQ-GAN作为图像编码器,通过行为克隆自我提高性能. 一些其他的具身智能体将大型语言模型适配到具身模型. PaLM-E[11 ] 使大型语言模型PaLM[21 ] 能够在现实世界中做出决策. 观察和状态估计被嵌入为语言单元并送入PaLM. 输出为语言序列,可以被低级策略控制器解释. RT-2[55 ] 微调了视觉-语言模型,将动作表达为词元. 在测试时,文本单元被反词元化成动作,实现了机器人的控制. ...
... 在某些场景下,通过互联网服务来实现基座智能体变得可行. 模型即服务(model as a service, MaaS)作为创新的范式,极大地促进了基座模型的开发和部署[74 ] . 在模型即服务的范式下,成熟的无身基座模型可以部署到具身智能体. 研究发现,大型语言模型(LLMs)能够有效地将用自然语言表达的高级任务分解成一系列低级动作,无须额外训练[75 ] . 例如LM-Nav直接利用GPT-3在现实世界中导航[76 ] . NavGPT展示了在视觉语言导航任务中,如何利用GPT-3.5和GPT-4进行零样本的动作预测[77 ] . 此外,PaLM-E[11 ] 整合了540B的PaLM[21 ] 和22B的Vision Transformer[78 ] ,以执行多种具身推理任务. 所有这些智能体的运作都需要连接到互联网,以便访问这些外部的大型模型. ...
1
... Scale comparison of large language model
Tab.1 大型语言模型 参数量 BERT[3 ] 1.10×108 /3.40×108 GPT[16 ] 1.17×108 GPT-2[17 ] 1.5×109 GPT-3[4 ] 1.75×1011 PaLM[21 ] 8×109 /6.2×1010 /5.40×1011 LLaMA[23 ] 7×109 /1.3×1010 /3.3×1010 /6.5×1010 LLaMA 2[24 ] 7×109 /1.3×1010 /7.0×1010
受到自然语言处理成功的启发,大规模样本预训练的思想已扩展到计算机视觉领域. 与语言信号相比,视觉信号的维度更高,空间冗余性更大,需要更有效的特征表示方法. 这一需求催生了对比学习(contrastive learning)的引入,通过最大化正样本对的相似度和最小化负样本对的相似度来学习有效的特征表示[19 ,25 -26 ] . 视觉Transformer[27 ] (ViT)的引入,使得同时对视觉和语言2种模态基于Transformer进行建模成为可能. 得益于对比学习和视觉Transformer的结合,出现了多模态的视觉-语言模型,从自然语言和视觉的监督信号中学习多模态的表征[5 ,28 ] . 最近,文献中公开参数数据的多模态模型发展到了百亿级别的参数规模[29 -30 ] . 借助视觉Transformer,遮罩自编码器(masked autoencoder, MAE)[18 ] 在计算机视觉中获得了与自然语言处理中的遮罩自编码[3 ] 相仿的结果,推动了视觉基座模型的成功[31 -32 ] . ...
2
... 基座模型是在自然语言处理(natural language processing, NLP)领域出现的,以BERT[3 ] 和GPT[16 ] 为代表. BERT采用遮罩自编码的方式,遮盖了大约15%的输入序列,使得模型预测被遮盖的词元(token),训练出通用的特征表示. 与BERT不同,GPT以自回归的方式预测输入序列中的下一个词元. 利用这2种方式训练出来的模型在自然语言处理领域实现了突破,激发了大型语言模型(large language models, LLMs)的研究热潮[20 -24 ] . 如表1 所示为代表性的大型语言模型的规模比较. ...
... Scale comparison of large language model
Tab.1 大型语言模型 参数量 BERT[3 ] 1.10×108 /3.40×108 GPT[16 ] 1.17×108 GPT-2[17 ] 1.5×109 GPT-3[4 ] 1.75×1011 PaLM[21 ] 8×109 /6.2×1010 /5.40×1011 LLaMA[23 ] 7×109 /1.3×1010 /3.3×1010 /6.5×1010 LLaMA 2[24 ] 7×109 /1.3×1010 /7.0×1010
受到自然语言处理成功的启发,大规模样本预训练的思想已扩展到计算机视觉领域. 与语言信号相比,视觉信号的维度更高,空间冗余性更大,需要更有效的特征表示方法. 这一需求催生了对比学习(contrastive learning)的引入,通过最大化正样本对的相似度和最小化负样本对的相似度来学习有效的特征表示[19 ,25 -26 ] . 视觉Transformer[27 ] (ViT)的引入,使得同时对视觉和语言2种模态基于Transformer进行建模成为可能. 得益于对比学习和视觉Transformer的结合,出现了多模态的视觉-语言模型,从自然语言和视觉的监督信号中学习多模态的表征[5 ,28 ] . 最近,文献中公开参数数据的多模态模型发展到了百亿级别的参数规模[29 -30 ] . 借助视觉Transformer,遮罩自编码器(masked autoencoder, MAE)[18 ] 在计算机视觉中获得了与自然语言处理中的遮罩自编码[3 ] 相仿的结果,推动了视觉基座模型的成功[31 -32 ] . ...
1
... 受到自然语言处理成功的启发,大规模样本预训练的思想已扩展到计算机视觉领域. 与语言信号相比,视觉信号的维度更高,空间冗余性更大,需要更有效的特征表示方法. 这一需求催生了对比学习(contrastive learning)的引入,通过最大化正样本对的相似度和最小化负样本对的相似度来学习有效的特征表示[19 ,25 -26 ] . 视觉Transformer[27 ] (ViT)的引入,使得同时对视觉和语言2种模态基于Transformer进行建模成为可能. 得益于对比学习和视觉Transformer的结合,出现了多模态的视觉-语言模型,从自然语言和视觉的监督信号中学习多模态的表征[5 ,28 ] . 最近,文献中公开参数数据的多模态模型发展到了百亿级别的参数规模[29 -30 ] . 借助视觉Transformer,遮罩自编码器(masked autoencoder, MAE)[18 ] 在计算机视觉中获得了与自然语言处理中的遮罩自编码[3 ] 相仿的结果,推动了视觉基座模型的成功[31 -32 ] . ...
1
... 受到自然语言处理成功的启发,大规模样本预训练的思想已扩展到计算机视觉领域. 与语言信号相比,视觉信号的维度更高,空间冗余性更大,需要更有效的特征表示方法. 这一需求催生了对比学习(contrastive learning)的引入,通过最大化正样本对的相似度和最小化负样本对的相似度来学习有效的特征表示[19 ,25 -26 ] . 视觉Transformer[27 ] (ViT)的引入,使得同时对视觉和语言2种模态基于Transformer进行建模成为可能. 得益于对比学习和视觉Transformer的结合,出现了多模态的视觉-语言模型,从自然语言和视觉的监督信号中学习多模态的表征[5 ,28 ] . 最近,文献中公开参数数据的多模态模型发展到了百亿级别的参数规模[29 -30 ] . 借助视觉Transformer,遮罩自编码器(masked autoencoder, MAE)[18 ] 在计算机视觉中获得了与自然语言处理中的遮罩自编码[3 ] 相仿的结果,推动了视觉基座模型的成功[31 -32 ] . ...
1
... 受到自然语言处理成功的启发,大规模样本预训练的思想已扩展到计算机视觉领域. 与语言信号相比,视觉信号的维度更高,空间冗余性更大,需要更有效的特征表示方法. 这一需求催生了对比学习(contrastive learning)的引入,通过最大化正样本对的相似度和最小化负样本对的相似度来学习有效的特征表示[19 ,25 -26 ] . 视觉Transformer[27 ] (ViT)的引入,使得同时对视觉和语言2种模态基于Transformer进行建模成为可能. 得益于对比学习和视觉Transformer的结合,出现了多模态的视觉-语言模型,从自然语言和视觉的监督信号中学习多模态的表征[5 ,28 ] . 最近,文献中公开参数数据的多模态模型发展到了百亿级别的参数规模[29 -30 ] . 借助视觉Transformer,遮罩自编码器(masked autoencoder, MAE)[18 ] 在计算机视觉中获得了与自然语言处理中的遮罩自编码[3 ] 相仿的结果,推动了视觉基座模型的成功[31 -32 ] . ...
3
... 受到自然语言处理成功的启发,大规模样本预训练的思想已扩展到计算机视觉领域. 与语言信号相比,视觉信号的维度更高,空间冗余性更大,需要更有效的特征表示方法. 这一需求催生了对比学习(contrastive learning)的引入,通过最大化正样本对的相似度和最小化负样本对的相似度来学习有效的特征表示[19 ,25 -26 ] . 视觉Transformer[27 ] (ViT)的引入,使得同时对视觉和语言2种模态基于Transformer进行建模成为可能. 得益于对比学习和视觉Transformer的结合,出现了多模态的视觉-语言模型,从自然语言和视觉的监督信号中学习多模态的表征[5 ,28 ] . 最近,文献中公开参数数据的多模态模型发展到了百亿级别的参数规模[29 -30 ] . 借助视觉Transformer,遮罩自编码器(masked autoencoder, MAE)[18 ] 在计算机视觉中获得了与自然语言处理中的遮罩自编码[3 ] 相仿的结果,推动了视觉基座模型的成功[31 -32 ] . ...
... 多模态最常见的形态是将视觉和语言的模态连接起来. ViLBERT[64 ] 、UNITER[65 ] 和Oscar[66 ] 等视觉-语言模型在复杂的下游任务,例如视觉问答和视觉常识推理,展现了改进性能的潜力. 这些方法一般包括一个图像编码器、一个目标检测模型和一个预训练的语言模型,它们通过对比学习在图像-文本对上联合微调,以学习视觉-语言表征. 通过扩大模型规模,CLIP[5 ] 、ALIGN[28 ] 和BASIC从网页抓取丰富但嘈杂的视觉-语言数据来学习视觉表征,表现出了强大的任务泛化能力[67 ] . 最近,PaLI[29 ] 和PaLI-X[30 ] 继续扩大模型规模和数据量. 这些视觉-语言多模态模型可以应用于视觉-语言的具身智能体. 例如,VLN-BERT展示了对无身的网络的预训练可以改善具身智能体的视觉表征[68 ] . Airbert利用图像-标题二元组生成路径-指令二元组,改进了预训练的方法[69 ] . ...
... Large multimodal model
Tab.2 大型多模态模型 视觉 语言 本体 动作 参数量 图像-文本对数量 轨迹量 ViLBERT[64 ] ✓ ✓ — — 1.55×108 3.1×106 — UNITER[65 ] ✓ ✓ — — 8.6×107 /3.03×108 9.6×106 — Oscar[66 ] ✓ ✓ — — 1.10×108 /3.40×108 6.5×106 — CLIP[5 ] ✓ ✓ — — 3.70×108 4.00×108 — ALIGN[28 ] ✓ ✓ — — 7.90×108 1.8×109 — BASIC[67 ] ✓ ✓ — — 3×109 6.6×109 — PaLI[29 ] ✓ ✓ — — 1.7×1010 1×109 — PaLI-X[30 ] ✓ ✓ — — 5.5×1010 — — Gato[54 ] ✓ ✓ ✓ ✓ 1.2×109 2.1×109 6.3×107 RPT[63 ] ✓ — ✓ ✓ 3.08×108 — 2.0×104 RoboCat[57 ] ✓ — ✓ ✓ 1.18×109 — 2.8×106
2.5. 强化学习与模仿学习 具身智能体传统上是通过强化学习的方式进行训练[13 ] . 在这种方式下,智能体通过与环境的互动来学习,这包括基于智能体的当前状态采取行动,从环境中接收奖励作为反馈,基于这些奖励来更新智能体的决策策略[70 ] . 有时候,智能体与环境交互的任务很难定义出合适的奖励函数. 传统的强化学习方法存在样本效率低下、学习过程缓慢的问题. 强化学习的试错过程还会为一些任务带来安全问题. 为了解决这些问题,模仿学习被提出作为训练智能体的方法. 在模仿学习中,智能体通过观察专家(无论是人类还是其他智能体)的行为来学习. 这种方法允许智能体模仿专家的行为,之后可能通过强化学习进行进一步的微调. 在这一过程中,专家的行为被记录下来,构成了训练智能体的数据集. 近年来,模仿学习在具身智能体的训练中越来越受到关注,越来越多的具身智能体使用模仿学习进行训练[54 ,59 ,71 -73 ] ,出现了针对具身智能体的大规模数据集,以支持这种训练方式,详见3.1节. ...
3
... 受到自然语言处理成功的启发,大规模样本预训练的思想已扩展到计算机视觉领域. 与语言信号相比,视觉信号的维度更高,空间冗余性更大,需要更有效的特征表示方法. 这一需求催生了对比学习(contrastive learning)的引入,通过最大化正样本对的相似度和最小化负样本对的相似度来学习有效的特征表示[19 ,25 -26 ] . 视觉Transformer[27 ] (ViT)的引入,使得同时对视觉和语言2种模态基于Transformer进行建模成为可能. 得益于对比学习和视觉Transformer的结合,出现了多模态的视觉-语言模型,从自然语言和视觉的监督信号中学习多模态的表征[5 ,28 ] . 最近,文献中公开参数数据的多模态模型发展到了百亿级别的参数规模[29 -30 ] . 借助视觉Transformer,遮罩自编码器(masked autoencoder, MAE)[18 ] 在计算机视觉中获得了与自然语言处理中的遮罩自编码[3 ] 相仿的结果,推动了视觉基座模型的成功[31 -32 ] . ...
... 多模态最常见的形态是将视觉和语言的模态连接起来. ViLBERT[64 ] 、UNITER[65 ] 和Oscar[66 ] 等视觉-语言模型在复杂的下游任务,例如视觉问答和视觉常识推理,展现了改进性能的潜力. 这些方法一般包括一个图像编码器、一个目标检测模型和一个预训练的语言模型,它们通过对比学习在图像-文本对上联合微调,以学习视觉-语言表征. 通过扩大模型规模,CLIP[5 ] 、ALIGN[28 ] 和BASIC从网页抓取丰富但嘈杂的视觉-语言数据来学习视觉表征,表现出了强大的任务泛化能力[67 ] . 最近,PaLI[29 ] 和PaLI-X[30 ] 继续扩大模型规模和数据量. 这些视觉-语言多模态模型可以应用于视觉-语言的具身智能体. 例如,VLN-BERT展示了对无身的网络的预训练可以改善具身智能体的视觉表征[68 ] . Airbert利用图像-标题二元组生成路径-指令二元组,改进了预训练的方法[69 ] . ...
... Large multimodal model
Tab.2 大型多模态模型 视觉 语言 本体 动作 参数量 图像-文本对数量 轨迹量 ViLBERT[64 ] ✓ ✓ — — 1.55×108 3.1×106 — UNITER[65 ] ✓ ✓ — — 8.6×107 /3.03×108 9.6×106 — Oscar[66 ] ✓ ✓ — — 1.10×108 /3.40×108 6.5×106 — CLIP[5 ] ✓ ✓ — — 3.70×108 4.00×108 — ALIGN[28 ] ✓ ✓ — — 7.90×108 1.8×109 — BASIC[67 ] ✓ ✓ — — 3×109 6.6×109 — PaLI[29 ] ✓ ✓ — — 1.7×1010 1×109 — PaLI-X[30 ] ✓ ✓ — — 5.5×1010 — — Gato[54 ] ✓ ✓ ✓ ✓ 1.2×109 2.1×109 6.3×107 RPT[63 ] ✓ — ✓ ✓ 3.08×108 — 2.0×104 RoboCat[57 ] ✓ — ✓ ✓ 1.18×109 — 2.8×106
2.5. 强化学习与模仿学习 具身智能体传统上是通过强化学习的方式进行训练[13 ] . 在这种方式下,智能体通过与环境的互动来学习,这包括基于智能体的当前状态采取行动,从环境中接收奖励作为反馈,基于这些奖励来更新智能体的决策策略[70 ] . 有时候,智能体与环境交互的任务很难定义出合适的奖励函数. 传统的强化学习方法存在样本效率低下、学习过程缓慢的问题. 强化学习的试错过程还会为一些任务带来安全问题. 为了解决这些问题,模仿学习被提出作为训练智能体的方法. 在模仿学习中,智能体通过观察专家(无论是人类还是其他智能体)的行为来学习. 这种方法允许智能体模仿专家的行为,之后可能通过强化学习进行进一步的微调. 在这一过程中,专家的行为被记录下来,构成了训练智能体的数据集. 近年来,模仿学习在具身智能体的训练中越来越受到关注,越来越多的具身智能体使用模仿学习进行训练[54 ,59 ,71 -73 ] ,出现了针对具身智能体的大规模数据集,以支持这种训练方式,详见3.1节. ...
4
... 受到自然语言处理成功的启发,大规模样本预训练的思想已扩展到计算机视觉领域. 与语言信号相比,视觉信号的维度更高,空间冗余性更大,需要更有效的特征表示方法. 这一需求催生了对比学习(contrastive learning)的引入,通过最大化正样本对的相似度和最小化负样本对的相似度来学习有效的特征表示[19 ,25 -26 ] . 视觉Transformer[27 ] (ViT)的引入,使得同时对视觉和语言2种模态基于Transformer进行建模成为可能. 得益于对比学习和视觉Transformer的结合,出现了多模态的视觉-语言模型,从自然语言和视觉的监督信号中学习多模态的表征[5 ,28 ] . 最近,文献中公开参数数据的多模态模型发展到了百亿级别的参数规模[29 -30 ] . 借助视觉Transformer,遮罩自编码器(masked autoencoder, MAE)[18 ] 在计算机视觉中获得了与自然语言处理中的遮罩自编码[3 ] 相仿的结果,推动了视觉基座模型的成功[31 -32 ] . ...
... 多模态最常见的形态是将视觉和语言的模态连接起来. ViLBERT[64 ] 、UNITER[65 ] 和Oscar[66 ] 等视觉-语言模型在复杂的下游任务,例如视觉问答和视觉常识推理,展现了改进性能的潜力. 这些方法一般包括一个图像编码器、一个目标检测模型和一个预训练的语言模型,它们通过对比学习在图像-文本对上联合微调,以学习视觉-语言表征. 通过扩大模型规模,CLIP[5 ] 、ALIGN[28 ] 和BASIC从网页抓取丰富但嘈杂的视觉-语言数据来学习视觉表征,表现出了强大的任务泛化能力[67 ] . 最近,PaLI[29 ] 和PaLI-X[30 ] 继续扩大模型规模和数据量. 这些视觉-语言多模态模型可以应用于视觉-语言的具身智能体. 例如,VLN-BERT展示了对无身的网络的预训练可以改善具身智能体的视觉表征[68 ] . Airbert利用图像-标题二元组生成路径-指令二元组,改进了预训练的方法[69 ] . ...
... Large multimodal model
Tab.2 大型多模态模型 视觉 语言 本体 动作 参数量 图像-文本对数量 轨迹量 ViLBERT[64 ] ✓ ✓ — — 1.55×108 3.1×106 — UNITER[65 ] ✓ ✓ — — 8.6×107 /3.03×108 9.6×106 — Oscar[66 ] ✓ ✓ — — 1.10×108 /3.40×108 6.5×106 — CLIP[5 ] ✓ ✓ — — 3.70×108 4.00×108 — ALIGN[28 ] ✓ ✓ — — 7.90×108 1.8×109 — BASIC[67 ] ✓ ✓ — — 3×109 6.6×109 — PaLI[29 ] ✓ ✓ — — 1.7×1010 1×109 — PaLI-X[30 ] ✓ ✓ — — 5.5×1010 — — Gato[54 ] ✓ ✓ ✓ ✓ 1.2×109 2.1×109 6.3×107 RPT[63 ] ✓ — ✓ ✓ 3.08×108 — 2.0×104 RoboCat[57 ] ✓ — ✓ ✓ 1.18×109 — 2.8×106
2.5. 强化学习与模仿学习 具身智能体传统上是通过强化学习的方式进行训练[13 ] . 在这种方式下,智能体通过与环境的互动来学习,这包括基于智能体的当前状态采取行动,从环境中接收奖励作为反馈,基于这些奖励来更新智能体的决策策略[70 ] . 有时候,智能体与环境交互的任务很难定义出合适的奖励函数. 传统的强化学习方法存在样本效率低下、学习过程缓慢的问题. 强化学习的试错过程还会为一些任务带来安全问题. 为了解决这些问题,模仿学习被提出作为训练智能体的方法. 在模仿学习中,智能体通过观察专家(无论是人类还是其他智能体)的行为来学习. 这种方法允许智能体模仿专家的行为,之后可能通过强化学习进行进一步的微调. 在这一过程中,专家的行为被记录下来,构成了训练智能体的数据集. 近年来,模仿学习在具身智能体的训练中越来越受到关注,越来越多的具身智能体使用模仿学习进行训练[54 ,59 ,71 -73 ] ,出现了针对具身智能体的大规模数据集,以支持这种训练方式,详见3.1节. ...
... SayCan通过价值函数将大型语言模型与现实世界连接在一起,使其执行真实世界的动作[131 ] . R3M通过结合时间对比学习、视频-语言对齐和L1惩罚,预训练鼓励稀疏和紧凑的表征的多模态模型[132 ] . Gato将文本、图像、离散值和连续值转换为词元(token),并将它们输入到Transformer中,以学习一般性策略[54 ] . RT-1关注开放的任务无关的训练范式,以零样本迁移的方式泛化到更多的机器人任务[53 ] . PaLM-E[11 ] 将操控的规划问题形式转化为语言问题,将来自任意模态的输入转化为词元,并将词元输入到PaLM中. RT-2[55 ] 结合大型多模态模型,例如PaLI-X[30 ] ,并直接预测机器人动作. ...
2
... 受到自然语言处理成功的启发,大规模样本预训练的思想已扩展到计算机视觉领域. 与语言信号相比,视觉信号的维度更高,空间冗余性更大,需要更有效的特征表示方法. 这一需求催生了对比学习(contrastive learning)的引入,通过最大化正样本对的相似度和最小化负样本对的相似度来学习有效的特征表示[19 ,25 -26 ] . 视觉Transformer[27 ] (ViT)的引入,使得同时对视觉和语言2种模态基于Transformer进行建模成为可能. 得益于对比学习和视觉Transformer的结合,出现了多模态的视觉-语言模型,从自然语言和视觉的监督信号中学习多模态的表征[5 ,28 ] . 最近,文献中公开参数数据的多模态模型发展到了百亿级别的参数规模[29 -30 ] . 借助视觉Transformer,遮罩自编码器(masked autoencoder, MAE)[18 ] 在计算机视觉中获得了与自然语言处理中的遮罩自编码[3 ] 相仿的结果,推动了视觉基座模型的成功[31 -32 ] . ...
... 目标导航(object-goal navigation 或 visual goal navigation)的目标是指引智能体前往目标物体所在地. 基座模型的应用使得对目标导航的零样本迁移成为可能. 例如,EmbCLIP证明了CLIP编码的骨干相比于ImageNet预训练的骨干网络更有效,展示了在训练阶段未涉及的4个类别的测试成果[119 ] . CLIP on Wheels(简称CoW)[120 ] 采用结合启发式探索策略的模型,能够扩展到更多未见过的类别. ZSON在目标图片上进行训练,旨在适应开放世界场景而不仅限于预定义的物体类别[121 ] . LFG利用GPT-3.5作为搜索的启发式,进行路径规划[122 ] . Wang等[123 ] 将目标导航设定为需求驱动的任务,使用GPT-3.5将用户需求转化为物体目标. PixNav[124 ] 利用4个外部大型模型,包括LLaMA-Adapter[128 ] 、GPT-4[20 ] 、Grounding DINO[129 ] 和SAM[31 ] ,设计逐步细化的提示模板,探索了基座模型在自我定位和构建结构化记忆方面的潜力. ...
1
... 受到自然语言处理成功的启发,大规模样本预训练的思想已扩展到计算机视觉领域. 与语言信号相比,视觉信号的维度更高,空间冗余性更大,需要更有效的特征表示方法. 这一需求催生了对比学习(contrastive learning)的引入,通过最大化正样本对的相似度和最小化负样本对的相似度来学习有效的特征表示[19 ,25 -26 ] . 视觉Transformer[27 ] (ViT)的引入,使得同时对视觉和语言2种模态基于Transformer进行建模成为可能. 得益于对比学习和视觉Transformer的结合,出现了多模态的视觉-语言模型,从自然语言和视觉的监督信号中学习多模态的表征[5 ,28 ] . 最近,文献中公开参数数据的多模态模型发展到了百亿级别的参数规模[29 -30 ] . 借助视觉Transformer,遮罩自编码器(masked autoencoder, MAE)[18 ] 在计算机视觉中获得了与自然语言处理中的遮罩自编码[3 ] 相仿的结果,推动了视觉基座模型的成功[31 -32 ] . ...
The development of embodied cognition: six lessons from babies
1
2005
... 具身智能中的“具身”源于认知科学的具身认知(embodied cognition)领域,它认为智能是在与环境的感知运动的行动中显现出来的[12 ,33 ] . 具身认知领域同样关注语言和视觉的理解. 下面,从语言和视觉2个方面,回顾具身认知领域的发展. ...
Eliza: a computer program for the study of natural language communication between man and machine
1
1966
... 长期以来,机器能否真正理解人类语言一直是热门的讨论话题. 图灵提出模仿游戏(即图灵测试),判断是否能够通过书面对话将机器与人类区分开来[1 ] . 研究表明,人类倾向于将自己所理解的含义投射到人工智能体所产生的输出上,以为人工智能体像人类一样“理解”了语言,需要谨慎设计评估机器理解能力的测试[34 ] . 为此,Searle通过他著名的“中文房间论证”(Chinese room argument)挑战了这样一个假设:一个与人类行为无法区分的系统必须拥有心智[35 ] . 在中文房间里,一个不懂中文的人仅通过遵循一套指令就能对中文请求作出回应,这表明机器可能仅仅在操作语言的符号而不理解其含义. 这意味着语言的意义不能完全脱离现实世界而单独存在于其形式之中. Harnad将该问题称为符号落地问题(symbol grounding problem)[10 ] ,指出一个人仅通过参照中文-中文字典来学习中文是困难的(作为第二语言)甚至不可能的(作为第一语言),这是因为在学习的过程中没有将符号与物理世界联系起来. 最近,针对大型语言模型的出现,Bender等[36 ] 设计了章鱼测试的思想实验,表明仅基于语言的形式训练的大型语言模型,由于缺乏将话语与现实世界联系起来的能力,无法通过更敏感的测试. 这说明尽管大型语言模型在自然语言处理方面取得了巨大进步,但不意味着它们真正具备了自然语言理解的能力. 语言模型要实现真正的情境语言理解,需要具备物理世界和社会背景的知识[37 ] . ...
Minds, brains, and programs
1
1980
... 长期以来,机器能否真正理解人类语言一直是热门的讨论话题. 图灵提出模仿游戏(即图灵测试),判断是否能够通过书面对话将机器与人类区分开来[1 ] . 研究表明,人类倾向于将自己所理解的含义投射到人工智能体所产生的输出上,以为人工智能体像人类一样“理解”了语言,需要谨慎设计评估机器理解能力的测试[34 ] . 为此,Searle通过他著名的“中文房间论证”(Chinese room argument)挑战了这样一个假设:一个与人类行为无法区分的系统必须拥有心智[35 ] . 在中文房间里,一个不懂中文的人仅通过遵循一套指令就能对中文请求作出回应,这表明机器可能仅仅在操作语言的符号而不理解其含义. 这意味着语言的意义不能完全脱离现实世界而单独存在于其形式之中. Harnad将该问题称为符号落地问题(symbol grounding problem)[10 ] ,指出一个人仅通过参照中文-中文字典来学习中文是困难的(作为第二语言)甚至不可能的(作为第一语言),这是因为在学习的过程中没有将符号与物理世界联系起来. 最近,针对大型语言模型的出现,Bender等[36 ] 设计了章鱼测试的思想实验,表明仅基于语言的形式训练的大型语言模型,由于缺乏将话语与现实世界联系起来的能力,无法通过更敏感的测试. 这说明尽管大型语言模型在自然语言处理方面取得了巨大进步,但不意味着它们真正具备了自然语言理解的能力. 语言模型要实现真正的情境语言理解,需要具备物理世界和社会背景的知识[37 ] . ...
1
... 长期以来,机器能否真正理解人类语言一直是热门的讨论话题. 图灵提出模仿游戏(即图灵测试),判断是否能够通过书面对话将机器与人类区分开来[1 ] . 研究表明,人类倾向于将自己所理解的含义投射到人工智能体所产生的输出上,以为人工智能体像人类一样“理解”了语言,需要谨慎设计评估机器理解能力的测试[34 ] . 为此,Searle通过他著名的“中文房间论证”(Chinese room argument)挑战了这样一个假设:一个与人类行为无法区分的系统必须拥有心智[35 ] . 在中文房间里,一个不懂中文的人仅通过遵循一套指令就能对中文请求作出回应,这表明机器可能仅仅在操作语言的符号而不理解其含义. 这意味着语言的意义不能完全脱离现实世界而单独存在于其形式之中. Harnad将该问题称为符号落地问题(symbol grounding problem)[10 ] ,指出一个人仅通过参照中文-中文字典来学习中文是困难的(作为第二语言)甚至不可能的(作为第一语言),这是因为在学习的过程中没有将符号与物理世界联系起来. 最近,针对大型语言模型的出现,Bender等[36 ] 设计了章鱼测试的思想实验,表明仅基于语言的形式训练的大型语言模型,由于缺乏将话语与现实世界联系起来的能力,无法通过更敏感的测试. 这说明尽管大型语言模型在自然语言处理方面取得了巨大进步,但不意味着它们真正具备了自然语言理解的能力. 语言模型要实现真正的情境语言理解,需要具备物理世界和社会背景的知识[37 ] . ...
1
... 长期以来,机器能否真正理解人类语言一直是热门的讨论话题. 图灵提出模仿游戏(即图灵测试),判断是否能够通过书面对话将机器与人类区分开来[1 ] . 研究表明,人类倾向于将自己所理解的含义投射到人工智能体所产生的输出上,以为人工智能体像人类一样“理解”了语言,需要谨慎设计评估机器理解能力的测试[34 ] . 为此,Searle通过他著名的“中文房间论证”(Chinese room argument)挑战了这样一个假设:一个与人类行为无法区分的系统必须拥有心智[35 ] . 在中文房间里,一个不懂中文的人仅通过遵循一套指令就能对中文请求作出回应,这表明机器可能仅仅在操作语言的符号而不理解其含义. 这意味着语言的意义不能完全脱离现实世界而单独存在于其形式之中. Harnad将该问题称为符号落地问题(symbol grounding problem)[10 ] ,指出一个人仅通过参照中文-中文字典来学习中文是困难的(作为第二语言)甚至不可能的(作为第一语言),这是因为在学习的过程中没有将符号与物理世界联系起来. 最近,针对大型语言模型的出现,Bender等[36 ] 设计了章鱼测试的思想实验,表明仅基于语言的形式训练的大型语言模型,由于缺乏将话语与现实世界联系起来的能力,无法通过更敏感的测试. 这说明尽管大型语言模型在自然语言处理方面取得了巨大进步,但不意味着它们真正具备了自然语言理解的能力. 语言模型要实现真正的情境语言理解,需要具备物理世界和社会背景的知识[37 ] . ...
Movement-produced stimulation in the development of visually guided behavior
1
1963
... 具身认知的另一个研究方向是视觉系统. 早期对幼猫的实验表明,视觉能力不是独立发育的,运动对于幼猫的视觉感知的发育至关重要[38 ] . 在这项实验中,2只幼猫在完全黑暗的环境中成长,之后它们被暴露于相同的视觉刺激中. 他们唯一的不同是一个能够自动运动,另一个被前者牵引着等路程地被动移动. 实验结果表明,只有那只能自主运动的幼猫发育出了正常的视觉感知能力. Gibson[39 ] 进一步提出,视觉不仅仅依赖于眼睛,而是一个具身的过程,与个体在环境中的互动密切相关. ...
The ecological approach to the visual perception of pictures
1
1978
... 具身认知的另一个研究方向是视觉系统. 早期对幼猫的实验表明,视觉能力不是独立发育的,运动对于幼猫的视觉感知的发育至关重要[38 ] . 在这项实验中,2只幼猫在完全黑暗的环境中成长,之后它们被暴露于相同的视觉刺激中. 他们唯一的不同是一个能够自动运动,另一个被前者牵引着等路程地被动移动. 实验结果表明,只有那只能自主运动的幼猫发育出了正常的视觉感知能力. Gibson[39 ] 进一步提出,视觉不仅仅依赖于眼睛,而是一个具身的过程,与个体在环境中的互动密切相关. ...
Leaning to the left makes the Eiffel tower seem smaller: posture-modulated estimation
1
2011
... 实际上,具身认知科学在广泛的意义上研究行为和心智之间的关系,不仅限于语言和视觉. 许多实验已经证明,认知可以受到身体的影响[40 ] ,抽象的认知状态是基于身体状态的[41 -42 ] . 这一理念启发了一部分人工智能科学家们长期致力于具身人工智能[43 −48 ] . 最近,随着基座模型的出现和现代传感器及执行器的成熟,具身方向的研究工作重新被人们重视,经典的图灵测试的概念甚至被扩展到所谓的具身图灵测试[8 ] ,这反映了评估机器的理解能力正趋于考虑其与环境的物理互动. 这与图灵最初的设想相呼应,他认为机器智能的发展应该包含无形体和有形体的智能探索[1 ] . ...
1
... 实际上,具身认知科学在广泛的意义上研究行为和心智之间的关系,不仅限于语言和视觉. 许多实验已经证明,认知可以受到身体的影响[40 ] ,抽象的认知状态是基于身体状态的[41 -42 ] . 这一理念启发了一部分人工智能科学家们长期致力于具身人工智能[43 −48 ] . 最近,随着基座模型的出现和现代传感器及执行器的成熟,具身方向的研究工作重新被人们重视,经典的图灵测试的概念甚至被扩展到所谓的具身图灵测试[8 ] ,这反映了评估机器的理解能力正趋于考虑其与环境的物理互动. 这与图灵最初的设想相呼应,他认为机器智能的发展应该包含无形体和有形体的智能探索[1 ] . ...
Philosophy in the ?esh: the embodied mind and its challenge to western thought
1
1999
... 实际上,具身认知科学在广泛的意义上研究行为和心智之间的关系,不仅限于语言和视觉. 许多实验已经证明,认知可以受到身体的影响[40 ] ,抽象的认知状态是基于身体状态的[41 -42 ] . 这一理念启发了一部分人工智能科学家们长期致力于具身人工智能[43 −48 ] . 最近,随着基座模型的出现和现代传感器及执行器的成熟,具身方向的研究工作重新被人们重视,经典的图灵测试的概念甚至被扩展到所谓的具身图灵测试[8 ] ,这反映了评估机器的理解能力正趋于考虑其与环境的物理互动. 这与图灵最初的设想相呼应,他认为机器智能的发展应该包含无形体和有形体的智能探索[1 ] . ...
Elephants don’t play chess
1
1990
... 实际上,具身认知科学在广泛的意义上研究行为和心智之间的关系,不仅限于语言和视觉. 许多实验已经证明,认知可以受到身体的影响[40 ] ,抽象的认知状态是基于身体状态的[41 -42 ] . 这一理念启发了一部分人工智能科学家们长期致力于具身人工智能[43 −48 ] . 最近,随着基座模型的出现和现代传感器及执行器的成熟,具身方向的研究工作重新被人们重视,经典的图灵测试的概念甚至被扩展到所谓的具身图灵测试[8 ] ,这反映了评估机器的理解能力正趋于考虑其与环境的物理互动. 这与图灵最初的设想相呼应,他认为机器智能的发展应该包含无形体和有形体的智能探索[1 ] . ...
Intelligence without representation
0
1991
New approaches to robotics
0
1991
Why we need a physically embodied Turing test and what it might look like
1
2016
... 实际上,具身认知科学在广泛的意义上研究行为和心智之间的关系,不仅限于语言和视觉. 许多实验已经证明,认知可以受到身体的影响[40 ] ,抽象的认知状态是基于身体状态的[41 -42 ] . 这一理念启发了一部分人工智能科学家们长期致力于具身人工智能[43 −48 ] . 最近,随着基座模型的出现和现代传感器及执行器的成熟,具身方向的研究工作重新被人们重视,经典的图灵测试的概念甚至被扩展到所谓的具身图灵测试[8 ] ,这反映了评估机器的理解能力正趋于考虑其与环境的物理互动. 这与图灵最初的设想相呼应,他认为机器智能的发展应该包含无形体和有形体的智能探索[1 ] . ...
1
... 考虑到Transformer在自然语言处理领域的显著成功,将其应用于强化学习领域自然而然地显得极具吸引力. 决策Transformer[49 -51 ] 和轨迹Transformer[52 ] 将强化学习问题视作序列建模问题. 它们将轨迹视为状态、行动和奖励的序列,这可以被单元化并输入到Transformer中. ...
1
... 考虑到Transformer在自然语言处理领域的显著成功,将其应用于强化学习领域自然而然地显得极具吸引力. 决策Transformer[49 -51 ] 和轨迹Transformer[52 ] 将强化学习问题视作序列建模问题. 它们将轨迹视为状态、行动和奖励的序列,这可以被单元化并输入到Transformer中. ...
1
... 考虑到Transformer在自然语言处理领域的显著成功,将其应用于强化学习领域自然而然地显得极具吸引力. 决策Transformer[49 -51 ] 和轨迹Transformer[52 ] 将强化学习问题视作序列建模问题. 它们将轨迹视为状态、行动和奖励的序列,这可以被单元化并输入到Transformer中. ...
3
... 尽管决策Transformer最初被提出时采用了非具身的形式,但它完全可以扩展到具身的应用场景中. 如图1 所示为自回归的具身的决策Transformer实例. 决策Transformer的核心思想是将传统的强化学习问题转变为监督学习问题. 这种转变意味着奖励信号是可选的,使得根据这一架构训练出来的智能体既可以是传统意义上的强化学习智能体[53 ] ,也可以是不依赖于奖励信号的非强化学习智能体[11 ,54 -55 ] . ...
... Comparison of foundation agent for robotic manipulation
Tab.6 智能体 语言 基座模型 真实世界 多具身 参数量 SayCan[131 ] ✓ PaLM ✓ ✓ 5.40×1011 R3M[132 ] ✓ — ✓ — — Gato[54 ] ✓ — ✓ ✓ 1.2×109 RT-1[53 ] ✓ SayCan ✓ — 5.40×1011 PaLM-E[11 ] ✓ PaLM, ViT-22B ✓ ✓ 5.62×1011 RT-2[55 ] ✓ PaLI-X ✓ — 5.5×1010 SMART[60 ] — — — — 1.08×107 MVP[58 ] — — — — 2.2×107 Real MVP[59 ] — — ✓ ✓ 3.07×108 RPT[63 ] — — ✓ ✓ 3.07×108 RoboCat[57 ] [133 ] — — ✓ ✓ 1.2×109 8
SayCan通过价值函数将大型语言模型与现实世界连接在一起,使其执行真实世界的动作[131 ] . R3M通过结合时间对比学习、视频-语言对齐和L1惩罚,预训练鼓励稀疏和紧凑的表征的多模态模型[132 ] . Gato将文本、图像、离散值和连续值转换为词元(token),并将它们输入到Transformer中,以学习一般性策略[54 ] . RT-1关注开放的任务无关的训练范式,以零样本迁移的方式泛化到更多的机器人任务[53 ] . PaLM-E[11 ] 将操控的规划问题形式转化为语言问题,将来自任意模态的输入转化为词元,并将词元输入到PaLM中. RT-2[55 ] 结合大型多模态模型,例如PaLI-X[30 ] ,并直接预测机器人动作. ...
... SayCan通过价值函数将大型语言模型与现实世界连接在一起,使其执行真实世界的动作[131 ] . R3M通过结合时间对比学习、视频-语言对齐和L1惩罚,预训练鼓励稀疏和紧凑的表征的多模态模型[132 ] . Gato将文本、图像、离散值和连续值转换为词元(token),并将它们输入到Transformer中,以学习一般性策略[54 ] . RT-1关注开放的任务无关的训练范式,以零样本迁移的方式泛化到更多的机器人任务[53 ] . PaLM-E[11 ] 将操控的规划问题形式转化为语言问题,将来自任意模态的输入转化为词元,并将词元输入到PaLM中. RT-2[55 ] 结合大型多模态模型,例如PaLI-X[30 ] ,并直接预测机器人动作. ...
7
... 尽管决策Transformer最初被提出时采用了非具身的形式,但它完全可以扩展到具身的应用场景中. 如图1 所示为自回归的具身的决策Transformer实例. 决策Transformer的核心思想是将传统的强化学习问题转变为监督学习问题. 这种转变意味着奖励信号是可选的,使得根据这一架构训练出来的智能体既可以是传统意义上的强化学习智能体[53 ] ,也可以是不依赖于奖励信号的非强化学习智能体[11 ,54 -55 ] . ...
... 受到自回归的大型预训练语言模型的启发,Reid 等[56 ] 提出以自回归的方式预训练决策Transformer. 与原始决策Transformer相比,收敛速度显著加快. Gato将决策Transformer扩展到通用的具身智能体[54 ] . Gato的观察序列包括了分词文本、图像、离散值(例如Atari的按钮操作)和本体感知序列(被离散为1 024个均匀区间). RoboCat将Gato(西班牙语中“猫”的意思)扩展为机器人操控的基座智能体[57 ] . RoboCat采用VQ-GAN作为图像编码器,通过行为克隆自我提高性能. 一些其他的具身智能体将大型语言模型适配到具身模型. PaLM-E[11 ] 使大型语言模型PaLM[21 ] 能够在现实世界中做出决策. 观察和状态估计被嵌入为语言单元并送入PaLM. 输出为语言序列,可以被低级策略控制器解释. RT-2[55 ] 微调了视觉-语言模型,将动作表达为词元. 在测试时,文本单元被反词元化成动作,实现了机器人的控制. ...
... 除了视觉和语言,多模态学习的概念还可以扩展到动作和本体感知状态等其他模态,这些模态在具身智能体中至关重要. Gato编码文本、图像、游戏的离散值和机器人的连续值,以学习多任务和多具身(可拥有多种物理身体)的智能体[54 ] . RPT利用视觉、本体感知状态,并遮罩这些模态的学习单元,以学习视觉-动作模型[63 ] . RoboCat扩展了Gato,但在使用模态方面类似于RPT,以自我提升的方式构建基座智能体[57 ] . 如表2 所示为上述讨论的大型多模态模型. ...
... Large multimodal model
Tab.2 大型多模态模型 视觉 语言 本体 动作 参数量 图像-文本对数量 轨迹量 ViLBERT[64 ] ✓ ✓ — — 1.55×108 3.1×106 — UNITER[65 ] ✓ ✓ — — 8.6×107 /3.03×108 9.6×106 — Oscar[66 ] ✓ ✓ — — 1.10×108 /3.40×108 6.5×106 — CLIP[5 ] ✓ ✓ — — 3.70×108 4.00×108 — ALIGN[28 ] ✓ ✓ — — 7.90×108 1.8×109 — BASIC[67 ] ✓ ✓ — — 3×109 6.6×109 — PaLI[29 ] ✓ ✓ — — 1.7×1010 1×109 — PaLI-X[30 ] ✓ ✓ — — 5.5×1010 — — Gato[54 ] ✓ ✓ ✓ ✓ 1.2×109 2.1×109 6.3×107 RPT[63 ] ✓ — ✓ ✓ 3.08×108 — 2.0×104 RoboCat[57 ] ✓ — ✓ ✓ 1.18×109 — 2.8×106
2.5. 强化学习与模仿学习 具身智能体传统上是通过强化学习的方式进行训练[13 ] . 在这种方式下,智能体通过与环境的互动来学习,这包括基于智能体的当前状态采取行动,从环境中接收奖励作为反馈,基于这些奖励来更新智能体的决策策略[70 ] . 有时候,智能体与环境交互的任务很难定义出合适的奖励函数. 传统的强化学习方法存在样本效率低下、学习过程缓慢的问题. 强化学习的试错过程还会为一些任务带来安全问题. 为了解决这些问题,模仿学习被提出作为训练智能体的方法. 在模仿学习中,智能体通过观察专家(无论是人类还是其他智能体)的行为来学习. 这种方法允许智能体模仿专家的行为,之后可能通过强化学习进行进一步的微调. 在这一过程中,专家的行为被记录下来,构成了训练智能体的数据集. 近年来,模仿学习在具身智能体的训练中越来越受到关注,越来越多的具身智能体使用模仿学习进行训练[54 ,59 ,71 -73 ] ,出现了针对具身智能体的大规模数据集,以支持这种训练方式,详见3.1节. ...
... 具身智能体传统上是通过强化学习的方式进行训练[13 ] . 在这种方式下,智能体通过与环境的互动来学习,这包括基于智能体的当前状态采取行动,从环境中接收奖励作为反馈,基于这些奖励来更新智能体的决策策略[70 ] . 有时候,智能体与环境交互的任务很难定义出合适的奖励函数. 传统的强化学习方法存在样本效率低下、学习过程缓慢的问题. 强化学习的试错过程还会为一些任务带来安全问题. 为了解决这些问题,模仿学习被提出作为训练智能体的方法. 在模仿学习中,智能体通过观察专家(无论是人类还是其他智能体)的行为来学习. 这种方法允许智能体模仿专家的行为,之后可能通过强化学习进行进一步的微调. 在这一过程中,专家的行为被记录下来,构成了训练智能体的数据集. 近年来,模仿学习在具身智能体的训练中越来越受到关注,越来越多的具身智能体使用模仿学习进行训练[54 ,59 ,71 -73 ] ,出现了针对具身智能体的大规模数据集,以支持这种训练方式,详见3.1节. ...
... Comparison of foundation agent for robotic manipulation
Tab.6 智能体 语言 基座模型 真实世界 多具身 参数量 SayCan[131 ] ✓ PaLM ✓ ✓ 5.40×1011 R3M[132 ] ✓ — ✓ — — Gato[54 ] ✓ — ✓ ✓ 1.2×109 RT-1[53 ] ✓ SayCan ✓ — 5.40×1011 PaLM-E[11 ] ✓ PaLM, ViT-22B ✓ ✓ 5.62×1011 RT-2[55 ] ✓ PaLI-X ✓ — 5.5×1010 SMART[60 ] — — — — 1.08×107 MVP[58 ] — — — — 2.2×107 Real MVP[59 ] — — ✓ ✓ 3.07×108 RPT[63 ] — — ✓ ✓ 3.07×108 RoboCat[57 ] [133 ] — — ✓ ✓ 1.2×109 8
SayCan通过价值函数将大型语言模型与现实世界连接在一起,使其执行真实世界的动作[131 ] . R3M通过结合时间对比学习、视频-语言对齐和L1惩罚,预训练鼓励稀疏和紧凑的表征的多模态模型[132 ] . Gato将文本、图像、离散值和连续值转换为词元(token),并将它们输入到Transformer中,以学习一般性策略[54 ] . RT-1关注开放的任务无关的训练范式,以零样本迁移的方式泛化到更多的机器人任务[53 ] . PaLM-E[11 ] 将操控的规划问题形式转化为语言问题,将来自任意模态的输入转化为词元,并将词元输入到PaLM中. RT-2[55 ] 结合大型多模态模型,例如PaLI-X[30 ] ,并直接预测机器人动作. ...
... SayCan通过价值函数将大型语言模型与现实世界连接在一起,使其执行真实世界的动作[131 ] . R3M通过结合时间对比学习、视频-语言对齐和L1惩罚,预训练鼓励稀疏和紧凑的表征的多模态模型[132 ] . Gato将文本、图像、离散值和连续值转换为词元(token),并将它们输入到Transformer中,以学习一般性策略[54 ] . RT-1关注开放的任务无关的训练范式,以零样本迁移的方式泛化到更多的机器人任务[53 ] . PaLM-E[11 ] 将操控的规划问题形式转化为语言问题,将来自任意模态的输入转化为词元,并将词元输入到PaLM中. RT-2[55 ] 结合大型多模态模型,例如PaLI-X[30 ] ,并直接预测机器人动作. ...
4
... 尽管决策Transformer最初被提出时采用了非具身的形式,但它完全可以扩展到具身的应用场景中. 如图1 所示为自回归的具身的决策Transformer实例. 决策Transformer的核心思想是将传统的强化学习问题转变为监督学习问题. 这种转变意味着奖励信号是可选的,使得根据这一架构训练出来的智能体既可以是传统意义上的强化学习智能体[53 ] ,也可以是不依赖于奖励信号的非强化学习智能体[11 ,54 -55 ] . ...
... 受到自回归的大型预训练语言模型的启发,Reid 等[56 ] 提出以自回归的方式预训练决策Transformer. 与原始决策Transformer相比,收敛速度显著加快. Gato将决策Transformer扩展到通用的具身智能体[54 ] . Gato的观察序列包括了分词文本、图像、离散值(例如Atari的按钮操作)和本体感知序列(被离散为1 024个均匀区间). RoboCat将Gato(西班牙语中“猫”的意思)扩展为机器人操控的基座智能体[57 ] . RoboCat采用VQ-GAN作为图像编码器,通过行为克隆自我提高性能. 一些其他的具身智能体将大型语言模型适配到具身模型. PaLM-E[11 ] 使大型语言模型PaLM[21 ] 能够在现实世界中做出决策. 观察和状态估计被嵌入为语言单元并送入PaLM. 输出为语言序列,可以被低级策略控制器解释. RT-2[55 ] 微调了视觉-语言模型,将动作表达为词元. 在测试时,文本单元被反词元化成动作,实现了机器人的控制. ...
... Comparison of foundation agent for robotic manipulation
Tab.6 智能体 语言 基座模型 真实世界 多具身 参数量 SayCan[131 ] ✓ PaLM ✓ ✓ 5.40×1011 R3M[132 ] ✓ — ✓ — — Gato[54 ] ✓ — ✓ ✓ 1.2×109 RT-1[53 ] ✓ SayCan ✓ — 5.40×1011 PaLM-E[11 ] ✓ PaLM, ViT-22B ✓ ✓ 5.62×1011 RT-2[55 ] ✓ PaLI-X ✓ — 5.5×1010 SMART[60 ] — — — — 1.08×107 MVP[58 ] — — — — 2.2×107 Real MVP[59 ] — — ✓ ✓ 3.07×108 RPT[63 ] — — ✓ ✓ 3.07×108 RoboCat[57 ] [133 ] — — ✓ ✓ 1.2×109 8
SayCan通过价值函数将大型语言模型与现实世界连接在一起,使其执行真实世界的动作[131 ] . R3M通过结合时间对比学习、视频-语言对齐和L1惩罚,预训练鼓励稀疏和紧凑的表征的多模态模型[132 ] . Gato将文本、图像、离散值和连续值转换为词元(token),并将它们输入到Transformer中,以学习一般性策略[54 ] . RT-1关注开放的任务无关的训练范式,以零样本迁移的方式泛化到更多的机器人任务[53 ] . PaLM-E[11 ] 将操控的规划问题形式转化为语言问题,将来自任意模态的输入转化为词元,并将词元输入到PaLM中. RT-2[55 ] 结合大型多模态模型,例如PaLI-X[30 ] ,并直接预测机器人动作. ...
... SayCan通过价值函数将大型语言模型与现实世界连接在一起,使其执行真实世界的动作[131 ] . R3M通过结合时间对比学习、视频-语言对齐和L1惩罚,预训练鼓励稀疏和紧凑的表征的多模态模型[132 ] . Gato将文本、图像、离散值和连续值转换为词元(token),并将它们输入到Transformer中,以学习一般性策略[54 ] . RT-1关注开放的任务无关的训练范式,以零样本迁移的方式泛化到更多的机器人任务[53 ] . PaLM-E[11 ] 将操控的规划问题形式转化为语言问题,将来自任意模态的输入转化为词元,并将词元输入到PaLM中. RT-2[55 ] 结合大型多模态模型,例如PaLI-X[30 ] ,并直接预测机器人动作. ...
1
... 受到自回归的大型预训练语言模型的启发,Reid 等[56 ] 提出以自回归的方式预训练决策Transformer. 与原始决策Transformer相比,收敛速度显著加快. Gato将决策Transformer扩展到通用的具身智能体[54 ] . Gato的观察序列包括了分词文本、图像、离散值(例如Atari的按钮操作)和本体感知序列(被离散为1 024个均匀区间). RoboCat将Gato(西班牙语中“猫”的意思)扩展为机器人操控的基座智能体[57 ] . RoboCat采用VQ-GAN作为图像编码器,通过行为克隆自我提高性能. 一些其他的具身智能体将大型语言模型适配到具身模型. PaLM-E[11 ] 使大型语言模型PaLM[21 ] 能够在现实世界中做出决策. 观察和状态估计被嵌入为语言单元并送入PaLM. 输出为语言序列,可以被低级策略控制器解释. RT-2[55 ] 微调了视觉-语言模型,将动作表达为词元. 在测试时,文本单元被反词元化成动作,实现了机器人的控制. ...
6
... 受到自回归的大型预训练语言模型的启发,Reid 等[56 ] 提出以自回归的方式预训练决策Transformer. 与原始决策Transformer相比,收敛速度显著加快. Gato将决策Transformer扩展到通用的具身智能体[54 ] . Gato的观察序列包括了分词文本、图像、离散值(例如Atari的按钮操作)和本体感知序列(被离散为1 024个均匀区间). RoboCat将Gato(西班牙语中“猫”的意思)扩展为机器人操控的基座智能体[57 ] . RoboCat采用VQ-GAN作为图像编码器,通过行为克隆自我提高性能. 一些其他的具身智能体将大型语言模型适配到具身模型. PaLM-E[11 ] 使大型语言模型PaLM[21 ] 能够在现实世界中做出决策. 观察和状态估计被嵌入为语言单元并送入PaLM. 输出为语言序列,可以被低级策略控制器解释. RT-2[55 ] 微调了视觉-语言模型,将动作表达为词元. 在测试时,文本单元被反词元化成动作,实现了机器人的控制. ...
... 除了视觉和语言,多模态学习的概念还可以扩展到动作和本体感知状态等其他模态,这些模态在具身智能体中至关重要. Gato编码文本、图像、游戏的离散值和机器人的连续值,以学习多任务和多具身(可拥有多种物理身体)的智能体[54 ] . RPT利用视觉、本体感知状态,并遮罩这些模态的学习单元,以学习视觉-动作模型[63 ] . RoboCat扩展了Gato,但在使用模态方面类似于RPT,以自我提升的方式构建基座智能体[57 ] . 如表2 所示为上述讨论的大型多模态模型. ...
... Large multimodal model
Tab.2 大型多模态模型 视觉 语言 本体 动作 参数量 图像-文本对数量 轨迹量 ViLBERT[64 ] ✓ ✓ — — 1.55×108 3.1×106 — UNITER[65 ] ✓ ✓ — — 8.6×107 /3.03×108 9.6×106 — Oscar[66 ] ✓ ✓ — — 1.10×108 /3.40×108 6.5×106 — CLIP[5 ] ✓ ✓ — — 3.70×108 4.00×108 — ALIGN[28 ] ✓ ✓ — — 7.90×108 1.8×109 — BASIC[67 ] ✓ ✓ — — 3×109 6.6×109 — PaLI[29 ] ✓ ✓ — — 1.7×1010 1×109 — PaLI-X[30 ] ✓ ✓ — — 5.5×1010 — — Gato[54 ] ✓ ✓ ✓ ✓ 1.2×109 2.1×109 6.3×107 RPT[63 ] ✓ — ✓ ✓ 3.08×108 — 2.0×104 RoboCat[57 ] ✓ — ✓ ✓ 1.18×109 — 2.8×106
2.5. 强化学习与模仿学习 具身智能体传统上是通过强化学习的方式进行训练[13 ] . 在这种方式下,智能体通过与环境的互动来学习,这包括基于智能体的当前状态采取行动,从环境中接收奖励作为反馈,基于这些奖励来更新智能体的决策策略[70 ] . 有时候,智能体与环境交互的任务很难定义出合适的奖励函数. 传统的强化学习方法存在样本效率低下、学习过程缓慢的问题. 强化学习的试错过程还会为一些任务带来安全问题. 为了解决这些问题,模仿学习被提出作为训练智能体的方法. 在模仿学习中,智能体通过观察专家(无论是人类还是其他智能体)的行为来学习. 这种方法允许智能体模仿专家的行为,之后可能通过强化学习进行进一步的微调. 在这一过程中,专家的行为被记录下来,构成了训练智能体的数据集. 近年来,模仿学习在具身智能体的训练中越来越受到关注,越来越多的具身智能体使用模仿学习进行训练[54 ,59 ,71 -73 ] ,出现了针对具身智能体的大规模数据集,以支持这种训练方式,详见3.1节. ...
... 虽然在模拟器中训练得到的模型能够在模拟环境下表现良好,但模拟环境与现实世界之间存在的明显差异是其在物理机器人上应用的主要障碍[114 ] . 在这方面,一些具身方法同时在模拟和现实世界[11 ,57 ,115 ] ,或完全在现实世界中[60 ] 评估模型的表现. ...
... Comparison of foundation agent for robotic manipulation
Tab.6 智能体 语言 基座模型 真实世界 多具身 参数量 SayCan[131 ] ✓ PaLM ✓ ✓ 5.40×1011 R3M[132 ] ✓ — ✓ — — Gato[54 ] ✓ — ✓ ✓ 1.2×109 RT-1[53 ] ✓ SayCan ✓ — 5.40×1011 PaLM-E[11 ] ✓ PaLM, ViT-22B ✓ ✓ 5.62×1011 RT-2[55 ] ✓ PaLI-X ✓ — 5.5×1010 SMART[60 ] — — — — 1.08×107 MVP[58 ] — — — — 2.2×107 Real MVP[59 ] — — ✓ ✓ 3.07×108 RPT[63 ] — — ✓ ✓ 3.07×108 RoboCat[57 ] [133 ] — — ✓ ✓ 1.2×109 8
SayCan通过价值函数将大型语言模型与现实世界连接在一起,使其执行真实世界的动作[131 ] . R3M通过结合时间对比学习、视频-语言对齐和L1惩罚,预训练鼓励稀疏和紧凑的表征的多模态模型[132 ] . Gato将文本、图像、离散值和连续值转换为词元(token),并将它们输入到Transformer中,以学习一般性策略[54 ] . RT-1关注开放的任务无关的训练范式,以零样本迁移的方式泛化到更多的机器人任务[53 ] . PaLM-E[11 ] 将操控的规划问题形式转化为语言问题,将来自任意模态的输入转化为词元,并将词元输入到PaLM中. RT-2[55 ] 结合大型多模态模型,例如PaLI-X[30 ] ,并直接预测机器人动作. ...
... MVP[58 ] 展示了自然图像的自监督预训练对于学习机器人任务是有效的. Real MVP[59 ] 用更多的数据和更大的架构,将MVP扩展到真实世界环境中. MaskDP[61 ] 对状态和动作词元进行遮罩,使模型学习前向和逆向的动力学. RPT[63 ] 将遮罩自编码扩展到多模态,遮掩图像、本体感知状态和行动. RoboCat[57 ] 展示了能够泛化到新任务和新机器人的自我提升的基座智能体. Yang等[133 ] 通过利用导航和操控这2个任务的相似性,在多种机器人上训练单一目标导向策略,验证了跨具身学习的有效性,展示了该策略在各种实际环境中的适应能力. ...
3
... 另一种自监督具身智能体采用遮罩自编码的方式. MVP系列工作通过遮罩自编码预训练视觉表示,利用强化学习训练控制器,在模拟器中实现了机器臂控制,并将该工作扩展到现实世界的具身实例[58 -59 ] . SMART对动作进行了遮罩,训练模型恢复出被遮罩的动作,旨在让模型学到动作的特征[60 ] . MaskDP对状态和动作进行遮罩,且对前向和逆向的动力学都进行了训练[61 ] . Voltron沿用 MVP 的预训练思路,引入语言监督信号,对齐视觉和语言2个模态的信息,提高了语言控制任务的准确率[62 ] . RPT对图像、本体感知和动作的输入进行遮罩,这类似于在具身认知中讨论的具身智能假设[63 ] . 如图2 所示为具身智能体的遮罩自编码预训练. ...
... Comparison of foundation agent for robotic manipulation
Tab.6 智能体 语言 基座模型 真实世界 多具身 参数量 SayCan[131 ] ✓ PaLM ✓ ✓ 5.40×1011 R3M[132 ] ✓ — ✓ — — Gato[54 ] ✓ — ✓ ✓ 1.2×109 RT-1[53 ] ✓ SayCan ✓ — 5.40×1011 PaLM-E[11 ] ✓ PaLM, ViT-22B ✓ ✓ 5.62×1011 RT-2[55 ] ✓ PaLI-X ✓ — 5.5×1010 SMART[60 ] — — — — 1.08×107 MVP[58 ] — — — — 2.2×107 Real MVP[59 ] — — ✓ ✓ 3.07×108 RPT[63 ] — — ✓ ✓ 3.07×108 RoboCat[57 ] [133 ] — — ✓ ✓ 1.2×109 8
SayCan通过价值函数将大型语言模型与现实世界连接在一起,使其执行真实世界的动作[131 ] . R3M通过结合时间对比学习、视频-语言对齐和L1惩罚,预训练鼓励稀疏和紧凑的表征的多模态模型[132 ] . Gato将文本、图像、离散值和连续值转换为词元(token),并将它们输入到Transformer中,以学习一般性策略[54 ] . RT-1关注开放的任务无关的训练范式,以零样本迁移的方式泛化到更多的机器人任务[53 ] . PaLM-E[11 ] 将操控的规划问题形式转化为语言问题,将来自任意模态的输入转化为词元,并将词元输入到PaLM中. RT-2[55 ] 结合大型多模态模型,例如PaLI-X[30 ] ,并直接预测机器人动作. ...
... MVP[58 ] 展示了自然图像的自监督预训练对于学习机器人任务是有效的. Real MVP[59 ] 用更多的数据和更大的架构,将MVP扩展到真实世界环境中. MaskDP[61 ] 对状态和动作词元进行遮罩,使模型学习前向和逆向的动力学. RPT[63 ] 将遮罩自编码扩展到多模态,遮掩图像、本体感知状态和行动. RoboCat[57 ] 展示了能够泛化到新任务和新机器人的自我提升的基座智能体. Yang等[133 ] 通过利用导航和操控这2个任务的相似性,在多种机器人上训练单一目标导向策略,验证了跨具身学习的有效性,展示了该策略在各种实际环境中的适应能力. ...
4
... 另一种自监督具身智能体采用遮罩自编码的方式. MVP系列工作通过遮罩自编码预训练视觉表示,利用强化学习训练控制器,在模拟器中实现了机器臂控制,并将该工作扩展到现实世界的具身实例[58 -59 ] . SMART对动作进行了遮罩,训练模型恢复出被遮罩的动作,旨在让模型学到动作的特征[60 ] . MaskDP对状态和动作进行遮罩,且对前向和逆向的动力学都进行了训练[61 ] . Voltron沿用 MVP 的预训练思路,引入语言监督信号,对齐视觉和语言2个模态的信息,提高了语言控制任务的准确率[62 ] . RPT对图像、本体感知和动作的输入进行遮罩,这类似于在具身认知中讨论的具身智能假设[63 ] . 如图2 所示为具身智能体的遮罩自编码预训练. ...
... 具身智能体传统上是通过强化学习的方式进行训练[13 ] . 在这种方式下,智能体通过与环境的互动来学习,这包括基于智能体的当前状态采取行动,从环境中接收奖励作为反馈,基于这些奖励来更新智能体的决策策略[70 ] . 有时候,智能体与环境交互的任务很难定义出合适的奖励函数. 传统的强化学习方法存在样本效率低下、学习过程缓慢的问题. 强化学习的试错过程还会为一些任务带来安全问题. 为了解决这些问题,模仿学习被提出作为训练智能体的方法. 在模仿学习中,智能体通过观察专家(无论是人类还是其他智能体)的行为来学习. 这种方法允许智能体模仿专家的行为,之后可能通过强化学习进行进一步的微调. 在这一过程中,专家的行为被记录下来,构成了训练智能体的数据集. 近年来,模仿学习在具身智能体的训练中越来越受到关注,越来越多的具身智能体使用模仿学习进行训练[54 ,59 ,71 -73 ] ,出现了针对具身智能体的大规模数据集,以支持这种训练方式,详见3.1节. ...
... Comparison of foundation agent for robotic manipulation
Tab.6 智能体 语言 基座模型 真实世界 多具身 参数量 SayCan[131 ] ✓ PaLM ✓ ✓ 5.40×1011 R3M[132 ] ✓ — ✓ — — Gato[54 ] ✓ — ✓ ✓ 1.2×109 RT-1[53 ] ✓ SayCan ✓ — 5.40×1011 PaLM-E[11 ] ✓ PaLM, ViT-22B ✓ ✓ 5.62×1011 RT-2[55 ] ✓ PaLI-X ✓ — 5.5×1010 SMART[60 ] — — — — 1.08×107 MVP[58 ] — — — — 2.2×107 Real MVP[59 ] — — ✓ ✓ 3.07×108 RPT[63 ] — — ✓ ✓ 3.07×108 RoboCat[57 ] [133 ] — — ✓ ✓ 1.2×109 8
SayCan通过价值函数将大型语言模型与现实世界连接在一起,使其执行真实世界的动作[131 ] . R3M通过结合时间对比学习、视频-语言对齐和L1惩罚,预训练鼓励稀疏和紧凑的表征的多模态模型[132 ] . Gato将文本、图像、离散值和连续值转换为词元(token),并将它们输入到Transformer中,以学习一般性策略[54 ] . RT-1关注开放的任务无关的训练范式,以零样本迁移的方式泛化到更多的机器人任务[53 ] . PaLM-E[11 ] 将操控的规划问题形式转化为语言问题,将来自任意模态的输入转化为词元,并将词元输入到PaLM中. RT-2[55 ] 结合大型多模态模型,例如PaLI-X[30 ] ,并直接预测机器人动作. ...
... MVP[58 ] 展示了自然图像的自监督预训练对于学习机器人任务是有效的. Real MVP[59 ] 用更多的数据和更大的架构,将MVP扩展到真实世界环境中. MaskDP[61 ] 对状态和动作词元进行遮罩,使模型学习前向和逆向的动力学. RPT[63 ] 将遮罩自编码扩展到多模态,遮掩图像、本体感知状态和行动. RoboCat[57 ] 展示了能够泛化到新任务和新机器人的自我提升的基座智能体. Yang等[133 ] 通过利用导航和操控这2个任务的相似性,在多种机器人上训练单一目标导向策略,验证了跨具身学习的有效性,展示了该策略在各种实际环境中的适应能力. ...
3
... 另一种自监督具身智能体采用遮罩自编码的方式. MVP系列工作通过遮罩自编码预训练视觉表示,利用强化学习训练控制器,在模拟器中实现了机器臂控制,并将该工作扩展到现实世界的具身实例[58 -59 ] . SMART对动作进行了遮罩,训练模型恢复出被遮罩的动作,旨在让模型学到动作的特征[60 ] . MaskDP对状态和动作进行遮罩,且对前向和逆向的动力学都进行了训练[61 ] . Voltron沿用 MVP 的预训练思路,引入语言监督信号,对齐视觉和语言2个模态的信息,提高了语言控制任务的准确率[62 ] . RPT对图像、本体感知和动作的输入进行遮罩,这类似于在具身认知中讨论的具身智能假设[63 ] . 如图2 所示为具身智能体的遮罩自编码预训练. ...
... 虽然在模拟器中训练得到的模型能够在模拟环境下表现良好,但模拟环境与现实世界之间存在的明显差异是其在物理机器人上应用的主要障碍[114 ] . 在这方面,一些具身方法同时在模拟和现实世界[11 ,57 ,115 ] ,或完全在现实世界中[60 ] 评估模型的表现. ...
... Comparison of foundation agent for robotic manipulation
Tab.6 智能体 语言 基座模型 真实世界 多具身 参数量 SayCan[131 ] ✓ PaLM ✓ ✓ 5.40×1011 R3M[132 ] ✓ — ✓ — — Gato[54 ] ✓ — ✓ ✓ 1.2×109 RT-1[53 ] ✓ SayCan ✓ — 5.40×1011 PaLM-E[11 ] ✓ PaLM, ViT-22B ✓ ✓ 5.62×1011 RT-2[55 ] ✓ PaLI-X ✓ — 5.5×1010 SMART[60 ] — — — — 1.08×107 MVP[58 ] — — — — 2.2×107 Real MVP[59 ] — — ✓ ✓ 3.07×108 RPT[63 ] — — ✓ ✓ 3.07×108 RoboCat[57 ] [133 ] — — ✓ ✓ 1.2×109 8
SayCan通过价值函数将大型语言模型与现实世界连接在一起,使其执行真实世界的动作[131 ] . R3M通过结合时间对比学习、视频-语言对齐和L1惩罚,预训练鼓励稀疏和紧凑的表征的多模态模型[132 ] . Gato将文本、图像、离散值和连续值转换为词元(token),并将它们输入到Transformer中,以学习一般性策略[54 ] . RT-1关注开放的任务无关的训练范式,以零样本迁移的方式泛化到更多的机器人任务[53 ] . PaLM-E[11 ] 将操控的规划问题形式转化为语言问题,将来自任意模态的输入转化为词元,并将词元输入到PaLM中. RT-2[55 ] 结合大型多模态模型,例如PaLI-X[30 ] ,并直接预测机器人动作. ...
2
... 另一种自监督具身智能体采用遮罩自编码的方式. MVP系列工作通过遮罩自编码预训练视觉表示,利用强化学习训练控制器,在模拟器中实现了机器臂控制,并将该工作扩展到现实世界的具身实例[58 -59 ] . SMART对动作进行了遮罩,训练模型恢复出被遮罩的动作,旨在让模型学到动作的特征[60 ] . MaskDP对状态和动作进行遮罩,且对前向和逆向的动力学都进行了训练[61 ] . Voltron沿用 MVP 的预训练思路,引入语言监督信号,对齐视觉和语言2个模态的信息,提高了语言控制任务的准确率[62 ] . RPT对图像、本体感知和动作的输入进行遮罩,这类似于在具身认知中讨论的具身智能假设[63 ] . 如图2 所示为具身智能体的遮罩自编码预训练. ...
... MVP[58 ] 展示了自然图像的自监督预训练对于学习机器人任务是有效的. Real MVP[59 ] 用更多的数据和更大的架构,将MVP扩展到真实世界环境中. MaskDP[61 ] 对状态和动作词元进行遮罩,使模型学习前向和逆向的动力学. RPT[63 ] 将遮罩自编码扩展到多模态,遮掩图像、本体感知状态和行动. RoboCat[57 ] 展示了能够泛化到新任务和新机器人的自我提升的基座智能体. Yang等[133 ] 通过利用导航和操控这2个任务的相似性,在多种机器人上训练单一目标导向策略,验证了跨具身学习的有效性,展示了该策略在各种实际环境中的适应能力. ...
1
... 另一种自监督具身智能体采用遮罩自编码的方式. MVP系列工作通过遮罩自编码预训练视觉表示,利用强化学习训练控制器,在模拟器中实现了机器臂控制,并将该工作扩展到现实世界的具身实例[58 -59 ] . SMART对动作进行了遮罩,训练模型恢复出被遮罩的动作,旨在让模型学到动作的特征[60 ] . MaskDP对状态和动作进行遮罩,且对前向和逆向的动力学都进行了训练[61 ] . Voltron沿用 MVP 的预训练思路,引入语言监督信号,对齐视觉和语言2个模态的信息,提高了语言控制任务的准确率[62 ] . RPT对图像、本体感知和动作的输入进行遮罩,这类似于在具身认知中讨论的具身智能假设[63 ] . 如图2 所示为具身智能体的遮罩自编码预训练. ...
5
... 另一种自监督具身智能体采用遮罩自编码的方式. MVP系列工作通过遮罩自编码预训练视觉表示,利用强化学习训练控制器,在模拟器中实现了机器臂控制,并将该工作扩展到现实世界的具身实例[58 -59 ] . SMART对动作进行了遮罩,训练模型恢复出被遮罩的动作,旨在让模型学到动作的特征[60 ] . MaskDP对状态和动作进行遮罩,且对前向和逆向的动力学都进行了训练[61 ] . Voltron沿用 MVP 的预训练思路,引入语言监督信号,对齐视觉和语言2个模态的信息,提高了语言控制任务的准确率[62 ] . RPT对图像、本体感知和动作的输入进行遮罩,这类似于在具身认知中讨论的具身智能假设[63 ] . 如图2 所示为具身智能体的遮罩自编码预训练. ...
... 除了视觉和语言,多模态学习的概念还可以扩展到动作和本体感知状态等其他模态,这些模态在具身智能体中至关重要. Gato编码文本、图像、游戏的离散值和机器人的连续值,以学习多任务和多具身(可拥有多种物理身体)的智能体[54 ] . RPT利用视觉、本体感知状态,并遮罩这些模态的学习单元,以学习视觉-动作模型[63 ] . RoboCat扩展了Gato,但在使用模态方面类似于RPT,以自我提升的方式构建基座智能体[57 ] . 如表2 所示为上述讨论的大型多模态模型. ...
... Large multimodal model
Tab.2 大型多模态模型 视觉 语言 本体 动作 参数量 图像-文本对数量 轨迹量 ViLBERT[64 ] ✓ ✓ — — 1.55×108 3.1×106 — UNITER[65 ] ✓ ✓ — — 8.6×107 /3.03×108 9.6×106 — Oscar[66 ] ✓ ✓ — — 1.10×108 /3.40×108 6.5×106 — CLIP[5 ] ✓ ✓ — — 3.70×108 4.00×108 — ALIGN[28 ] ✓ ✓ — — 7.90×108 1.8×109 — BASIC[67 ] ✓ ✓ — — 3×109 6.6×109 — PaLI[29 ] ✓ ✓ — — 1.7×1010 1×109 — PaLI-X[30 ] ✓ ✓ — — 5.5×1010 — — Gato[54 ] ✓ ✓ ✓ ✓ 1.2×109 2.1×109 6.3×107 RPT[63 ] ✓ — ✓ ✓ 3.08×108 — 2.0×104 RoboCat[57 ] ✓ — ✓ ✓ 1.18×109 — 2.8×106
2.5. 强化学习与模仿学习 具身智能体传统上是通过强化学习的方式进行训练[13 ] . 在这种方式下,智能体通过与环境的互动来学习,这包括基于智能体的当前状态采取行动,从环境中接收奖励作为反馈,基于这些奖励来更新智能体的决策策略[70 ] . 有时候,智能体与环境交互的任务很难定义出合适的奖励函数. 传统的强化学习方法存在样本效率低下、学习过程缓慢的问题. 强化学习的试错过程还会为一些任务带来安全问题. 为了解决这些问题,模仿学习被提出作为训练智能体的方法. 在模仿学习中,智能体通过观察专家(无论是人类还是其他智能体)的行为来学习. 这种方法允许智能体模仿专家的行为,之后可能通过强化学习进行进一步的微调. 在这一过程中,专家的行为被记录下来,构成了训练智能体的数据集. 近年来,模仿学习在具身智能体的训练中越来越受到关注,越来越多的具身智能体使用模仿学习进行训练[54 ,59 ,71 -73 ] ,出现了针对具身智能体的大规模数据集,以支持这种训练方式,详见3.1节. ...
... Comparison of foundation agent for robotic manipulation
Tab.6 智能体 语言 基座模型 真实世界 多具身 参数量 SayCan[131 ] ✓ PaLM ✓ ✓ 5.40×1011 R3M[132 ] ✓ — ✓ — — Gato[54 ] ✓ — ✓ ✓ 1.2×109 RT-1[53 ] ✓ SayCan ✓ — 5.40×1011 PaLM-E[11 ] ✓ PaLM, ViT-22B ✓ ✓ 5.62×1011 RT-2[55 ] ✓ PaLI-X ✓ — 5.5×1010 SMART[60 ] — — — — 1.08×107 MVP[58 ] — — — — 2.2×107 Real MVP[59 ] — — ✓ ✓ 3.07×108 RPT[63 ] — — ✓ ✓ 3.07×108 RoboCat[57 ] [133 ] — — ✓ ✓ 1.2×109 8
SayCan通过价值函数将大型语言模型与现实世界连接在一起,使其执行真实世界的动作[131 ] . R3M通过结合时间对比学习、视频-语言对齐和L1惩罚,预训练鼓励稀疏和紧凑的表征的多模态模型[132 ] . Gato将文本、图像、离散值和连续值转换为词元(token),并将它们输入到Transformer中,以学习一般性策略[54 ] . RT-1关注开放的任务无关的训练范式,以零样本迁移的方式泛化到更多的机器人任务[53 ] . PaLM-E[11 ] 将操控的规划问题形式转化为语言问题,将来自任意模态的输入转化为词元,并将词元输入到PaLM中. RT-2[55 ] 结合大型多模态模型,例如PaLI-X[30 ] ,并直接预测机器人动作. ...
... MVP[58 ] 展示了自然图像的自监督预训练对于学习机器人任务是有效的. Real MVP[59 ] 用更多的数据和更大的架构,将MVP扩展到真实世界环境中. MaskDP[61 ] 对状态和动作词元进行遮罩,使模型学习前向和逆向的动力学. RPT[63 ] 将遮罩自编码扩展到多模态,遮掩图像、本体感知状态和行动. RoboCat[57 ] 展示了能够泛化到新任务和新机器人的自我提升的基座智能体. Yang等[133 ] 通过利用导航和操控这2个任务的相似性,在多种机器人上训练单一目标导向策略,验证了跨具身学习的有效性,展示了该策略在各种实际环境中的适应能力. ...
3
... 多模态最常见的形态是将视觉和语言的模态连接起来. ViLBERT[64 ] 、UNITER[65 ] 和Oscar[66 ] 等视觉-语言模型在复杂的下游任务,例如视觉问答和视觉常识推理,展现了改进性能的潜力. 这些方法一般包括一个图像编码器、一个目标检测模型和一个预训练的语言模型,它们通过对比学习在图像-文本对上联合微调,以学习视觉-语言表征. 通过扩大模型规模,CLIP[5 ] 、ALIGN[28 ] 和BASIC从网页抓取丰富但嘈杂的视觉-语言数据来学习视觉表征,表现出了强大的任务泛化能力[67 ] . 最近,PaLI[29 ] 和PaLI-X[30 ] 继续扩大模型规模和数据量. 这些视觉-语言多模态模型可以应用于视觉-语言的具身智能体. 例如,VLN-BERT展示了对无身的网络的预训练可以改善具身智能体的视觉表征[68 ] . Airbert利用图像-标题二元组生成路径-指令二元组,改进了预训练的方法[69 ] . ...
... Large multimodal model
Tab.2 大型多模态模型 视觉 语言 本体 动作 参数量 图像-文本对数量 轨迹量 ViLBERT[64 ] ✓ ✓ — — 1.55×108 3.1×106 — UNITER[65 ] ✓ ✓ — — 8.6×107 /3.03×108 9.6×106 — Oscar[66 ] ✓ ✓ — — 1.10×108 /3.40×108 6.5×106 — CLIP[5 ] ✓ ✓ — — 3.70×108 4.00×108 — ALIGN[28 ] ✓ ✓ — — 7.90×108 1.8×109 — BASIC[67 ] ✓ ✓ — — 3×109 6.6×109 — PaLI[29 ] ✓ ✓ — — 1.7×1010 1×109 — PaLI-X[30 ] ✓ ✓ — — 5.5×1010 — — Gato[54 ] ✓ ✓ ✓ ✓ 1.2×109 2.1×109 6.3×107 RPT[63 ] ✓ — ✓ ✓ 3.08×108 — 2.0×104 RoboCat[57 ] ✓ — ✓ ✓ 1.18×109 — 2.8×106
2.5. 强化学习与模仿学习 具身智能体传统上是通过强化学习的方式进行训练[13 ] . 在这种方式下,智能体通过与环境的互动来学习,这包括基于智能体的当前状态采取行动,从环境中接收奖励作为反馈,基于这些奖励来更新智能体的决策策略[70 ] . 有时候,智能体与环境交互的任务很难定义出合适的奖励函数. 传统的强化学习方法存在样本效率低下、学习过程缓慢的问题. 强化学习的试错过程还会为一些任务带来安全问题. 为了解决这些问题,模仿学习被提出作为训练智能体的方法. 在模仿学习中,智能体通过观察专家(无论是人类还是其他智能体)的行为来学习. 这种方法允许智能体模仿专家的行为,之后可能通过强化学习进行进一步的微调. 在这一过程中,专家的行为被记录下来,构成了训练智能体的数据集. 近年来,模仿学习在具身智能体的训练中越来越受到关注,越来越多的具身智能体使用模仿学习进行训练[54 ,59 ,71 -73 ] ,出现了针对具身智能体的大规模数据集,以支持这种训练方式,详见3.1节. ...
... 视觉语言导航(vision-and-language navigation, VLN)是指智能体依据自然语言指令进行导航[97 ] . 随着大型语言模型如BERT[3 ] 和GPT[16 ] 的出现,将它们应用到视觉语言导航成为研究的新趋势. PreSS微调BERT和GPT以学习文本表征,这些表征能够更好地泛化到以前未见过的指令[125 ] . 此外,先预训练图像-文本对的视觉-语言多模态表征,再迁移到视觉语言任务,正逐渐成为一种主流方法,代表性的多模态模型包括ViLBERT[64 ] 和Oscar[66 ] . 对于导航任务,VLN-BERT采用ViLBERT[68 ] ,Airbert采用ViLBERT和Oscar[69 ] ,以更好地协调导航的视觉和语言指令. ...
2
... 多模态最常见的形态是将视觉和语言的模态连接起来. ViLBERT[64 ] 、UNITER[65 ] 和Oscar[66 ] 等视觉-语言模型在复杂的下游任务,例如视觉问答和视觉常识推理,展现了改进性能的潜力. 这些方法一般包括一个图像编码器、一个目标检测模型和一个预训练的语言模型,它们通过对比学习在图像-文本对上联合微调,以学习视觉-语言表征. 通过扩大模型规模,CLIP[5 ] 、ALIGN[28 ] 和BASIC从网页抓取丰富但嘈杂的视觉-语言数据来学习视觉表征,表现出了强大的任务泛化能力[67 ] . 最近,PaLI[29 ] 和PaLI-X[30 ] 继续扩大模型规模和数据量. 这些视觉-语言多模态模型可以应用于视觉-语言的具身智能体. 例如,VLN-BERT展示了对无身的网络的预训练可以改善具身智能体的视觉表征[68 ] . Airbert利用图像-标题二元组生成路径-指令二元组,改进了预训练的方法[69 ] . ...
... Large multimodal model
Tab.2 大型多模态模型 视觉 语言 本体 动作 参数量 图像-文本对数量 轨迹量 ViLBERT[64 ] ✓ ✓ — — 1.55×108 3.1×106 — UNITER[65 ] ✓ ✓ — — 8.6×107 /3.03×108 9.6×106 — Oscar[66 ] ✓ ✓ — — 1.10×108 /3.40×108 6.5×106 — CLIP[5 ] ✓ ✓ — — 3.70×108 4.00×108 — ALIGN[28 ] ✓ ✓ — — 7.90×108 1.8×109 — BASIC[67 ] ✓ ✓ — — 3×109 6.6×109 — PaLI[29 ] ✓ ✓ — — 1.7×1010 1×109 — PaLI-X[30 ] ✓ ✓ — — 5.5×1010 — — Gato[54 ] ✓ ✓ ✓ ✓ 1.2×109 2.1×109 6.3×107 RPT[63 ] ✓ — ✓ ✓ 3.08×108 — 2.0×104 RoboCat[57 ] ✓ — ✓ ✓ 1.18×109 — 2.8×106
2.5. 强化学习与模仿学习 具身智能体传统上是通过强化学习的方式进行训练[13 ] . 在这种方式下,智能体通过与环境的互动来学习,这包括基于智能体的当前状态采取行动,从环境中接收奖励作为反馈,基于这些奖励来更新智能体的决策策略[70 ] . 有时候,智能体与环境交互的任务很难定义出合适的奖励函数. 传统的强化学习方法存在样本效率低下、学习过程缓慢的问题. 强化学习的试错过程还会为一些任务带来安全问题. 为了解决这些问题,模仿学习被提出作为训练智能体的方法. 在模仿学习中,智能体通过观察专家(无论是人类还是其他智能体)的行为来学习. 这种方法允许智能体模仿专家的行为,之后可能通过强化学习进行进一步的微调. 在这一过程中,专家的行为被记录下来,构成了训练智能体的数据集. 近年来,模仿学习在具身智能体的训练中越来越受到关注,越来越多的具身智能体使用模仿学习进行训练[54 ,59 ,71 -73 ] ,出现了针对具身智能体的大规模数据集,以支持这种训练方式,详见3.1节. ...
3
... 多模态最常见的形态是将视觉和语言的模态连接起来. ViLBERT[64 ] 、UNITER[65 ] 和Oscar[66 ] 等视觉-语言模型在复杂的下游任务,例如视觉问答和视觉常识推理,展现了改进性能的潜力. 这些方法一般包括一个图像编码器、一个目标检测模型和一个预训练的语言模型,它们通过对比学习在图像-文本对上联合微调,以学习视觉-语言表征. 通过扩大模型规模,CLIP[5 ] 、ALIGN[28 ] 和BASIC从网页抓取丰富但嘈杂的视觉-语言数据来学习视觉表征,表现出了强大的任务泛化能力[67 ] . 最近,PaLI[29 ] 和PaLI-X[30 ] 继续扩大模型规模和数据量. 这些视觉-语言多模态模型可以应用于视觉-语言的具身智能体. 例如,VLN-BERT展示了对无身的网络的预训练可以改善具身智能体的视觉表征[68 ] . Airbert利用图像-标题二元组生成路径-指令二元组,改进了预训练的方法[69 ] . ...
... Large multimodal model
Tab.2 大型多模态模型 视觉 语言 本体 动作 参数量 图像-文本对数量 轨迹量 ViLBERT[64 ] ✓ ✓ — — 1.55×108 3.1×106 — UNITER[65 ] ✓ ✓ — — 8.6×107 /3.03×108 9.6×106 — Oscar[66 ] ✓ ✓ — — 1.10×108 /3.40×108 6.5×106 — CLIP[5 ] ✓ ✓ — — 3.70×108 4.00×108 — ALIGN[28 ] ✓ ✓ — — 7.90×108 1.8×109 — BASIC[67 ] ✓ ✓ — — 3×109 6.6×109 — PaLI[29 ] ✓ ✓ — — 1.7×1010 1×109 — PaLI-X[30 ] ✓ ✓ — — 5.5×1010 — — Gato[54 ] ✓ ✓ ✓ ✓ 1.2×109 2.1×109 6.3×107 RPT[63 ] ✓ — ✓ ✓ 3.08×108 — 2.0×104 RoboCat[57 ] ✓ — ✓ ✓ 1.18×109 — 2.8×106
2.5. 强化学习与模仿学习 具身智能体传统上是通过强化学习的方式进行训练[13 ] . 在这种方式下,智能体通过与环境的互动来学习,这包括基于智能体的当前状态采取行动,从环境中接收奖励作为反馈,基于这些奖励来更新智能体的决策策略[70 ] . 有时候,智能体与环境交互的任务很难定义出合适的奖励函数. 传统的强化学习方法存在样本效率低下、学习过程缓慢的问题. 强化学习的试错过程还会为一些任务带来安全问题. 为了解决这些问题,模仿学习被提出作为训练智能体的方法. 在模仿学习中,智能体通过观察专家(无论是人类还是其他智能体)的行为来学习. 这种方法允许智能体模仿专家的行为,之后可能通过强化学习进行进一步的微调. 在这一过程中,专家的行为被记录下来,构成了训练智能体的数据集. 近年来,模仿学习在具身智能体的训练中越来越受到关注,越来越多的具身智能体使用模仿学习进行训练[54 ,59 ,71 -73 ] ,出现了针对具身智能体的大规模数据集,以支持这种训练方式,详见3.1节. ...
... 视觉语言导航(vision-and-language navigation, VLN)是指智能体依据自然语言指令进行导航[97 ] . 随着大型语言模型如BERT[3 ] 和GPT[16 ] 的出现,将它们应用到视觉语言导航成为研究的新趋势. PreSS微调BERT和GPT以学习文本表征,这些表征能够更好地泛化到以前未见过的指令[125 ] . 此外,先预训练图像-文本对的视觉-语言多模态表征,再迁移到视觉语言任务,正逐渐成为一种主流方法,代表性的多模态模型包括ViLBERT[64 ] 和Oscar[66 ] . 对于导航任务,VLN-BERT采用ViLBERT[68 ] ,Airbert采用ViLBERT和Oscar[69 ] ,以更好地协调导航的视觉和语言指令. ...
Combined scaling for zero-shot transfer learning
2
2023
... 多模态最常见的形态是将视觉和语言的模态连接起来. ViLBERT[64 ] 、UNITER[65 ] 和Oscar[66 ] 等视觉-语言模型在复杂的下游任务,例如视觉问答和视觉常识推理,展现了改进性能的潜力. 这些方法一般包括一个图像编码器、一个目标检测模型和一个预训练的语言模型,它们通过对比学习在图像-文本对上联合微调,以学习视觉-语言表征. 通过扩大模型规模,CLIP[5 ] 、ALIGN[28 ] 和BASIC从网页抓取丰富但嘈杂的视觉-语言数据来学习视觉表征,表现出了强大的任务泛化能力[67 ] . 最近,PaLI[29 ] 和PaLI-X[30 ] 继续扩大模型规模和数据量. 这些视觉-语言多模态模型可以应用于视觉-语言的具身智能体. 例如,VLN-BERT展示了对无身的网络的预训练可以改善具身智能体的视觉表征[68 ] . Airbert利用图像-标题二元组生成路径-指令二元组,改进了预训练的方法[69 ] . ...
... Large multimodal model
Tab.2 大型多模态模型 视觉 语言 本体 动作 参数量 图像-文本对数量 轨迹量 ViLBERT[64 ] ✓ ✓ — — 1.55×108 3.1×106 — UNITER[65 ] ✓ ✓ — — 8.6×107 /3.03×108 9.6×106 — Oscar[66 ] ✓ ✓ — — 1.10×108 /3.40×108 6.5×106 — CLIP[5 ] ✓ ✓ — — 3.70×108 4.00×108 — ALIGN[28 ] ✓ ✓ — — 7.90×108 1.8×109 — BASIC[67 ] ✓ ✓ — — 3×109 6.6×109 — PaLI[29 ] ✓ ✓ — — 1.7×1010 1×109 — PaLI-X[30 ] ✓ ✓ — — 5.5×1010 — — Gato[54 ] ✓ ✓ ✓ ✓ 1.2×109 2.1×109 6.3×107 RPT[63 ] ✓ — ✓ ✓ 3.08×108 — 2.0×104 RoboCat[57 ] ✓ — ✓ ✓ 1.18×109 — 2.8×106
2.5. 强化学习与模仿学习 具身智能体传统上是通过强化学习的方式进行训练[13 ] . 在这种方式下,智能体通过与环境的互动来学习,这包括基于智能体的当前状态采取行动,从环境中接收奖励作为反馈,基于这些奖励来更新智能体的决策策略[70 ] . 有时候,智能体与环境交互的任务很难定义出合适的奖励函数. 传统的强化学习方法存在样本效率低下、学习过程缓慢的问题. 强化学习的试错过程还会为一些任务带来安全问题. 为了解决这些问题,模仿学习被提出作为训练智能体的方法. 在模仿学习中,智能体通过观察专家(无论是人类还是其他智能体)的行为来学习. 这种方法允许智能体模仿专家的行为,之后可能通过强化学习进行进一步的微调. 在这一过程中,专家的行为被记录下来,构成了训练智能体的数据集. 近年来,模仿学习在具身智能体的训练中越来越受到关注,越来越多的具身智能体使用模仿学习进行训练[54 ,59 ,71 -73 ] ,出现了针对具身智能体的大规模数据集,以支持这种训练方式,详见3.1节. ...
3
... 多模态最常见的形态是将视觉和语言的模态连接起来. ViLBERT[64 ] 、UNITER[65 ] 和Oscar[66 ] 等视觉-语言模型在复杂的下游任务,例如视觉问答和视觉常识推理,展现了改进性能的潜力. 这些方法一般包括一个图像编码器、一个目标检测模型和一个预训练的语言模型,它们通过对比学习在图像-文本对上联合微调,以学习视觉-语言表征. 通过扩大模型规模,CLIP[5 ] 、ALIGN[28 ] 和BASIC从网页抓取丰富但嘈杂的视觉-语言数据来学习视觉表征,表现出了强大的任务泛化能力[67 ] . 最近,PaLI[29 ] 和PaLI-X[30 ] 继续扩大模型规模和数据量. 这些视觉-语言多模态模型可以应用于视觉-语言的具身智能体. 例如,VLN-BERT展示了对无身的网络的预训练可以改善具身智能体的视觉表征[68 ] . Airbert利用图像-标题二元组生成路径-指令二元组,改进了预训练的方法[69 ] . ...
... Comparison of agents for visual navigation
Tab.5 智能体 语言 基座模型 真实世界 模拟器 室内/室外 建图 参数量 EmbCLIP[119 ] ✓ CLIP — AI2-THOR 室内 — 8.8×107 CoW[120 ] ✓ CLIP ✓ AI2-THOR, Habitat 室内 ✓ 3.07×108 ZSON[121 ] ✓ CLIP — Habitat, Gibson 室内 — — LFG[122 ] ✓ GPT-3.5 ✓ Habitat 室内 ✓ 2.0×1010 DDN[123 ] ✓ GPT-3.5 — AI2-THOR 室内 — 2.0×1010 PixNav[124 ] ✓ LLaMA-Adapter, GPT-4, Grounding DINO, SAM ✓ Habitat 室内 — — PreSS[125 ] ✓ BERT, GPT — Matterport3D 室内 — 1.17×108 /3.40×108 VLN-BERT[68 ] ✓ ViLBERT — Matterport3D 室内 — 1.55×108 MARVAL[126 ] ✓ — — Matterport3D, Gibson 室内 — — LM-Nav[76 ] ✓ ViNG, CLIP GPT-3 ✓ — 室外 ✓ — NavGPT[77 ] ✓ GPT-3.5, GPT-4 — Matterport3D 室内 ✓ — DiscussNav[114 ] ✓ GPT-4 — Matterport3D 室内 — — Vienna[127 ] ✓ — — Matterport3D, Habitat 室内 — 3.1×107 ViNT[115 ] — — ✓ — 室内/室外 — 3.1×107
4.1.1. 目标导航 目标导航(object-goal navigation 或 visual goal navigation)的目标是指引智能体前往目标物体所在地. 基座模型的应用使得对目标导航的零样本迁移成为可能. 例如,EmbCLIP证明了CLIP编码的骨干相比于ImageNet预训练的骨干网络更有效,展示了在训练阶段未涉及的4个类别的测试成果[119 ] . CLIP on Wheels(简称CoW)[120 ] 采用结合启发式探索策略的模型,能够扩展到更多未见过的类别. ZSON在目标图片上进行训练,旨在适应开放世界场景而不仅限于预定义的物体类别[121 ] . LFG利用GPT-3.5作为搜索的启发式,进行路径规划[122 ] . Wang等[123 ] 将目标导航设定为需求驱动的任务,使用GPT-3.5将用户需求转化为物体目标. PixNav[124 ] 利用4个外部大型模型,包括LLaMA-Adapter[128 ] 、GPT-4[20 ] 、Grounding DINO[129 ] 和SAM[31 ] ,设计逐步细化的提示模板,探索了基座模型在自我定位和构建结构化记忆方面的潜力. ...
... 视觉语言导航(vision-and-language navigation, VLN)是指智能体依据自然语言指令进行导航[97 ] . 随着大型语言模型如BERT[3 ] 和GPT[16 ] 的出现,将它们应用到视觉语言导航成为研究的新趋势. PreSS微调BERT和GPT以学习文本表征,这些表征能够更好地泛化到以前未见过的指令[125 ] . 此外,先预训练图像-文本对的视觉-语言多模态表征,再迁移到视觉语言任务,正逐渐成为一种主流方法,代表性的多模态模型包括ViLBERT[64 ] 和Oscar[66 ] . 对于导航任务,VLN-BERT采用ViLBERT[68 ] ,Airbert采用ViLBERT和Oscar[69 ] ,以更好地协调导航的视觉和语言指令. ...
2
... 多模态最常见的形态是将视觉和语言的模态连接起来. ViLBERT[64 ] 、UNITER[65 ] 和Oscar[66 ] 等视觉-语言模型在复杂的下游任务,例如视觉问答和视觉常识推理,展现了改进性能的潜力. 这些方法一般包括一个图像编码器、一个目标检测模型和一个预训练的语言模型,它们通过对比学习在图像-文本对上联合微调,以学习视觉-语言表征. 通过扩大模型规模,CLIP[5 ] 、ALIGN[28 ] 和BASIC从网页抓取丰富但嘈杂的视觉-语言数据来学习视觉表征,表现出了强大的任务泛化能力[67 ] . 最近,PaLI[29 ] 和PaLI-X[30 ] 继续扩大模型规模和数据量. 这些视觉-语言多模态模型可以应用于视觉-语言的具身智能体. 例如,VLN-BERT展示了对无身的网络的预训练可以改善具身智能体的视觉表征[68 ] . Airbert利用图像-标题二元组生成路径-指令二元组,改进了预训练的方法[69 ] . ...
... 视觉语言导航(vision-and-language navigation, VLN)是指智能体依据自然语言指令进行导航[97 ] . 随着大型语言模型如BERT[3 ] 和GPT[16 ] 的出现,将它们应用到视觉语言导航成为研究的新趋势. PreSS微调BERT和GPT以学习文本表征,这些表征能够更好地泛化到以前未见过的指令[125 ] . 此外,先预训练图像-文本对的视觉-语言多模态表征,再迁移到视觉语言任务,正逐渐成为一种主流方法,代表性的多模态模型包括ViLBERT[64 ] 和Oscar[66 ] . 对于导航任务,VLN-BERT采用ViLBERT[68 ] ,Airbert采用ViLBERT和Oscar[69 ] ,以更好地协调导航的视觉和语言指令. ...
2
... 具身智能体传统上是通过强化学习的方式进行训练[13 ] . 在这种方式下,智能体通过与环境的互动来学习,这包括基于智能体的当前状态采取行动,从环境中接收奖励作为反馈,基于这些奖励来更新智能体的决策策略[70 ] . 有时候,智能体与环境交互的任务很难定义出合适的奖励函数. 传统的强化学习方法存在样本效率低下、学习过程缓慢的问题. 强化学习的试错过程还会为一些任务带来安全问题. 为了解决这些问题,模仿学习被提出作为训练智能体的方法. 在模仿学习中,智能体通过观察专家(无论是人类还是其他智能体)的行为来学习. 这种方法允许智能体模仿专家的行为,之后可能通过强化学习进行进一步的微调. 在这一过程中,专家的行为被记录下来,构成了训练智能体的数据集. 近年来,模仿学习在具身智能体的训练中越来越受到关注,越来越多的具身智能体使用模仿学习进行训练[54 ,59 ,71 -73 ] ,出现了针对具身智能体的大规模数据集,以支持这种训练方式,详见3.1节. ...
... 与机器人操控相似,传统视觉导航任务被细分为许多专门的数据集. 视觉导航任务通常围绕指定目标的方式展开研究,如智能体可导航至一个坐标点(点目标导航)[94 ] ,至给定物体类别的一个实例(对象目标导航)[95 ] ,至由目标图像给出的地点(图像目标导航)[70 ] ,至发声的物体[96 ] ,或根据自然语言指令导航(视觉-语言导航)[97 -99 ] . 视觉导航的基准测试可能涵盖一个或多个导航任务[100 ] . ...
1
... 具身智能体传统上是通过强化学习的方式进行训练[13 ] . 在这种方式下,智能体通过与环境的互动来学习,这包括基于智能体的当前状态采取行动,从环境中接收奖励作为反馈,基于这些奖励来更新智能体的决策策略[70 ] . 有时候,智能体与环境交互的任务很难定义出合适的奖励函数. 传统的强化学习方法存在样本效率低下、学习过程缓慢的问题. 强化学习的试错过程还会为一些任务带来安全问题. 为了解决这些问题,模仿学习被提出作为训练智能体的方法. 在模仿学习中,智能体通过观察专家(无论是人类还是其他智能体)的行为来学习. 这种方法允许智能体模仿专家的行为,之后可能通过强化学习进行进一步的微调. 在这一过程中,专家的行为被记录下来,构成了训练智能体的数据集. 近年来,模仿学习在具身智能体的训练中越来越受到关注,越来越多的具身智能体使用模仿学习进行训练[54 ,59 ,71 -73 ] ,出现了针对具身智能体的大规模数据集,以支持这种训练方式,详见3.1节. ...
1
... 具身智能体传统上是通过强化学习的方式进行训练[13 ] . 在这种方式下,智能体通过与环境的互动来学习,这包括基于智能体的当前状态采取行动,从环境中接收奖励作为反馈,基于这些奖励来更新智能体的决策策略[70 ] . 有时候,智能体与环境交互的任务很难定义出合适的奖励函数. 传统的强化学习方法存在样本效率低下、学习过程缓慢的问题. 强化学习的试错过程还会为一些任务带来安全问题. 为了解决这些问题,模仿学习被提出作为训练智能体的方法. 在模仿学习中,智能体通过观察专家(无论是人类还是其他智能体)的行为来学习. 这种方法允许智能体模仿专家的行为,之后可能通过强化学习进行进一步的微调. 在这一过程中,专家的行为被记录下来,构成了训练智能体的数据集. 近年来,模仿学习在具身智能体的训练中越来越受到关注,越来越多的具身智能体使用模仿学习进行训练[54 ,59 ,71 -73 ] ,出现了针对具身智能体的大规模数据集,以支持这种训练方式,详见3.1节. ...
1
... 在某些场景下,通过互联网服务来实现基座智能体变得可行. 模型即服务(model as a service, MaaS)作为创新的范式,极大地促进了基座模型的开发和部署[74 ] . 在模型即服务的范式下,成熟的无身基座模型可以部署到具身智能体. 研究发现,大型语言模型(LLMs)能够有效地将用自然语言表达的高级任务分解成一系列低级动作,无须额外训练[75 ] . 例如LM-Nav直接利用GPT-3在现实世界中导航[76 ] . NavGPT展示了在视觉语言导航任务中,如何利用GPT-3.5和GPT-4进行零样本的动作预测[77 ] . 此外,PaLM-E[11 ] 整合了540B的PaLM[21 ] 和22B的Vision Transformer[78 ] ,以执行多种具身推理任务. 所有这些智能体的运作都需要连接到互联网,以便访问这些外部的大型模型. ...
1
... 在某些场景下,通过互联网服务来实现基座智能体变得可行. 模型即服务(model as a service, MaaS)作为创新的范式,极大地促进了基座模型的开发和部署[74 ] . 在模型即服务的范式下,成熟的无身基座模型可以部署到具身智能体. 研究发现,大型语言模型(LLMs)能够有效地将用自然语言表达的高级任务分解成一系列低级动作,无须额外训练[75 ] . 例如LM-Nav直接利用GPT-3在现实世界中导航[76 ] . NavGPT展示了在视觉语言导航任务中,如何利用GPT-3.5和GPT-4进行零样本的动作预测[77 ] . 此外,PaLM-E[11 ] 整合了540B的PaLM[21 ] 和22B的Vision Transformer[78 ] ,以执行多种具身推理任务. 所有这些智能体的运作都需要连接到互联网,以便访问这些外部的大型模型. ...
3
... 在某些场景下,通过互联网服务来实现基座智能体变得可行. 模型即服务(model as a service, MaaS)作为创新的范式,极大地促进了基座模型的开发和部署[74 ] . 在模型即服务的范式下,成熟的无身基座模型可以部署到具身智能体. 研究发现,大型语言模型(LLMs)能够有效地将用自然语言表达的高级任务分解成一系列低级动作,无须额外训练[75 ] . 例如LM-Nav直接利用GPT-3在现实世界中导航[76 ] . NavGPT展示了在视觉语言导航任务中,如何利用GPT-3.5和GPT-4进行零样本的动作预测[77 ] . 此外,PaLM-E[11 ] 整合了540B的PaLM[21 ] 和22B的Vision Transformer[78 ] ,以执行多种具身推理任务. 所有这些智能体的运作都需要连接到互联网,以便访问这些外部的大型模型. ...
... Comparison of agents for visual navigation
Tab.5 智能体 语言 基座模型 真实世界 模拟器 室内/室外 建图 参数量 EmbCLIP[119 ] ✓ CLIP — AI2-THOR 室内 — 8.8×107 CoW[120 ] ✓ CLIP ✓ AI2-THOR, Habitat 室内 ✓ 3.07×108 ZSON[121 ] ✓ CLIP — Habitat, Gibson 室内 — — LFG[122 ] ✓ GPT-3.5 ✓ Habitat 室内 ✓ 2.0×1010 DDN[123 ] ✓ GPT-3.5 — AI2-THOR 室内 — 2.0×1010 PixNav[124 ] ✓ LLaMA-Adapter, GPT-4, Grounding DINO, SAM ✓ Habitat 室内 — — PreSS[125 ] ✓ BERT, GPT — Matterport3D 室内 — 1.17×108 /3.40×108 VLN-BERT[68 ] ✓ ViLBERT — Matterport3D 室内 — 1.55×108 MARVAL[126 ] ✓ — — Matterport3D, Gibson 室内 — — LM-Nav[76 ] ✓ ViNG, CLIP GPT-3 ✓ — 室外 ✓ — NavGPT[77 ] ✓ GPT-3.5, GPT-4 — Matterport3D 室内 ✓ — DiscussNav[114 ] ✓ GPT-4 — Matterport3D 室内 — — Vienna[127 ] ✓ — — Matterport3D, Habitat 室内 — 3.1×107 ViNT[115 ] — — ✓ — 室内/室外 — 3.1×107
4.1.1. 目标导航 目标导航(object-goal navigation 或 visual goal navigation)的目标是指引智能体前往目标物体所在地. 基座模型的应用使得对目标导航的零样本迁移成为可能. 例如,EmbCLIP证明了CLIP编码的骨干相比于ImageNet预训练的骨干网络更有效,展示了在训练阶段未涉及的4个类别的测试成果[119 ] . CLIP on Wheels(简称CoW)[120 ] 采用结合启发式探索策略的模型,能够扩展到更多未见过的类别. ZSON在目标图片上进行训练,旨在适应开放世界场景而不仅限于预定义的物体类别[121 ] . LFG利用GPT-3.5作为搜索的启发式,进行路径规划[122 ] . Wang等[123 ] 将目标导航设定为需求驱动的任务,使用GPT-3.5将用户需求转化为物体目标. PixNav[124 ] 利用4个外部大型模型,包括LLaMA-Adapter[128 ] 、GPT-4[20 ] 、Grounding DINO[129 ] 和SAM[31 ] ,设计逐步细化的提示模板,探索了基座模型在自我定位和构建结构化记忆方面的潜力. ...
... 在探索互联网规模的图像文本对预训练的同时,人类指令数据的稀缺成为研究的瓶颈. 为此,MARVAL 利用伴随的合成数据集Marky-Gibson,提供了具有合成指令的大规模数据增强[126 ] . 另一条研究路径利用外部大型语言模型. LM-Nav[76 ] 采用GPT-3[4 ] 来识别由视觉导航模型ViNG[130 ] 预定义的图上的地标,展示了基于预训练模型且无须任何微调的导航系统. 最近,NavGPT通过零样本动作预测,展示了大型语言模型在复杂具身场景中的推理能力[77 ] . DiscussNav用提示词在大语言模型上建立几个领域专家,用模拟的专家咨询会议来导航智能体,展示了令人印象深刻的零样本迁移性能[114 ] . ...
3
... 在某些场景下,通过互联网服务来实现基座智能体变得可行. 模型即服务(model as a service, MaaS)作为创新的范式,极大地促进了基座模型的开发和部署[74 ] . 在模型即服务的范式下,成熟的无身基座模型可以部署到具身智能体. 研究发现,大型语言模型(LLMs)能够有效地将用自然语言表达的高级任务分解成一系列低级动作,无须额外训练[75 ] . 例如LM-Nav直接利用GPT-3在现实世界中导航[76 ] . NavGPT展示了在视觉语言导航任务中,如何利用GPT-3.5和GPT-4进行零样本的动作预测[77 ] . 此外,PaLM-E[11 ] 整合了540B的PaLM[21 ] 和22B的Vision Transformer[78 ] ,以执行多种具身推理任务. 所有这些智能体的运作都需要连接到互联网,以便访问这些外部的大型模型. ...
... Comparison of agents for visual navigation
Tab.5 智能体 语言 基座模型 真实世界 模拟器 室内/室外 建图 参数量 EmbCLIP[119 ] ✓ CLIP — AI2-THOR 室内 — 8.8×107 CoW[120 ] ✓ CLIP ✓ AI2-THOR, Habitat 室内 ✓ 3.07×108 ZSON[121 ] ✓ CLIP — Habitat, Gibson 室内 — — LFG[122 ] ✓ GPT-3.5 ✓ Habitat 室内 ✓ 2.0×1010 DDN[123 ] ✓ GPT-3.5 — AI2-THOR 室内 — 2.0×1010 PixNav[124 ] ✓ LLaMA-Adapter, GPT-4, Grounding DINO, SAM ✓ Habitat 室内 — — PreSS[125 ] ✓ BERT, GPT — Matterport3D 室内 — 1.17×108 /3.40×108 VLN-BERT[68 ] ✓ ViLBERT — Matterport3D 室内 — 1.55×108 MARVAL[126 ] ✓ — — Matterport3D, Gibson 室内 — — LM-Nav[76 ] ✓ ViNG, CLIP GPT-3 ✓ — 室外 ✓ — NavGPT[77 ] ✓ GPT-3.5, GPT-4 — Matterport3D 室内 ✓ — DiscussNav[114 ] ✓ GPT-4 — Matterport3D 室内 — — Vienna[127 ] ✓ — — Matterport3D, Habitat 室内 — 3.1×107 ViNT[115 ] — — ✓ — 室内/室外 — 3.1×107
4.1.1. 目标导航 目标导航(object-goal navigation 或 visual goal navigation)的目标是指引智能体前往目标物体所在地. 基座模型的应用使得对目标导航的零样本迁移成为可能. 例如,EmbCLIP证明了CLIP编码的骨干相比于ImageNet预训练的骨干网络更有效,展示了在训练阶段未涉及的4个类别的测试成果[119 ] . CLIP on Wheels(简称CoW)[120 ] 采用结合启发式探索策略的模型,能够扩展到更多未见过的类别. ZSON在目标图片上进行训练,旨在适应开放世界场景而不仅限于预定义的物体类别[121 ] . LFG利用GPT-3.5作为搜索的启发式,进行路径规划[122 ] . Wang等[123 ] 将目标导航设定为需求驱动的任务,使用GPT-3.5将用户需求转化为物体目标. PixNav[124 ] 利用4个外部大型模型,包括LLaMA-Adapter[128 ] 、GPT-4[20 ] 、Grounding DINO[129 ] 和SAM[31 ] ,设计逐步细化的提示模板,探索了基座模型在自我定位和构建结构化记忆方面的潜力. ...
... 在探索互联网规模的图像文本对预训练的同时,人类指令数据的稀缺成为研究的瓶颈. 为此,MARVAL 利用伴随的合成数据集Marky-Gibson,提供了具有合成指令的大规模数据增强[126 ] . 另一条研究路径利用外部大型语言模型. LM-Nav[76 ] 采用GPT-3[4 ] 来识别由视觉导航模型ViNG[130 ] 预定义的图上的地标,展示了基于预训练模型且无须任何微调的导航系统. 最近,NavGPT通过零样本动作预测,展示了大型语言模型在复杂具身场景中的推理能力[77 ] . DiscussNav用提示词在大语言模型上建立几个领域专家,用模拟的专家咨询会议来导航智能体,展示了令人印象深刻的零样本迁移性能[114 ] . ...
1
... 在某些场景下,通过互联网服务来实现基座智能体变得可行. 模型即服务(model as a service, MaaS)作为创新的范式,极大地促进了基座模型的开发和部署[74 ] . 在模型即服务的范式下,成熟的无身基座模型可以部署到具身智能体. 研究发现,大型语言模型(LLMs)能够有效地将用自然语言表达的高级任务分解成一系列低级动作,无须额外训练[75 ] . 例如LM-Nav直接利用GPT-3在现实世界中导航[76 ] . NavGPT展示了在视觉语言导航任务中,如何利用GPT-3.5和GPT-4进行零样本的动作预测[77 ] . 此外,PaLM-E[11 ] 整合了540B的PaLM[21 ] 和22B的Vision Transformer[78 ] ,以执行多种具身推理任务. 所有这些智能体的运作都需要连接到互联网,以便访问这些外部的大型模型. ...
1
... 在监督学习的时代,数据集是模型成功的关键. 数据集既提供了监督信号,又充当了任务性能的基准测试. 大规模数据集不仅服务于特定的任务,还通过监督预训练为下游任务提供了重要的支持. 通常,模型会先在大规模数据集(如ImageNet[79 ] )上进行预训练,随后在特定的数据集(如COCO[80 ] 、Cityscapes[81 ] )上进行微调,以完成目标检测、语义分割、全景分割等下游任务. ...
1
... 在监督学习的时代,数据集是模型成功的关键. 数据集既提供了监督信号,又充当了任务性能的基准测试. 大规模数据集不仅服务于特定的任务,还通过监督预训练为下游任务提供了重要的支持. 通常,模型会先在大规模数据集(如ImageNet[79 ] )上进行预训练,随后在特定的数据集(如COCO[80 ] 、Cityscapes[81 ] )上进行微调,以完成目标检测、语义分割、全景分割等下游任务. ...
1
... 在监督学习的时代,数据集是模型成功的关键. 数据集既提供了监督信号,又充当了任务性能的基准测试. 大规模数据集不仅服务于特定的任务,还通过监督预训练为下游任务提供了重要的支持. 通常,模型会先在大规模数据集(如ImageNet[79 ] )上进行预训练,随后在特定的数据集(如COCO[80 ] 、Cityscapes[81 ] )上进行微调,以完成目标检测、语义分割、全景分割等下游任务. ...
1
... 早年的机器人学习(robot learning)方法通常专注于执行特定的任务,需要对应的特定数据集. 例如,在机器人操控领域,基本动作如抓取和推动各自有着专属的数据集. 抓取数据集关注的是使用机器人手或夹持器安全、稳定地抓持物体的行为[82 -90 ] . 推动数据集常用于处理难以直接抓取的物体. 当物体过大、过重或被其他物体所包围时,推动物体以达到预期效果或重新定位可能更实际[91 -93 ] . ...
Learning hand-eye coordination for robotic grasping with deep learning and large-scale data collection
0
2018
1
... 早年的机器人学习(robot learning)方法通常专注于执行特定的任务,需要对应的特定数据集. 例如,在机器人操控领域,基本动作如抓取和推动各自有着专属的数据集. 抓取数据集关注的是使用机器人手或夹持器安全、稳定地抓持物体的行为[82 -90 ] . 推动数据集常用于处理难以直接抓取的物体. 当物体过大、过重或被其他物体所包围时,推动物体以达到预期效果或重新定位可能更实际[91 -93 ] . ...
1
... 早年的机器人学习(robot learning)方法通常专注于执行特定的任务,需要对应的特定数据集. 例如,在机器人操控领域,基本动作如抓取和推动各自有着专属的数据集. 抓取数据集关注的是使用机器人手或夹持器安全、稳定地抓持物体的行为[82 -90 ] . 推动数据集常用于处理难以直接抓取的物体. 当物体过大、过重或被其他物体所包围时,推动物体以达到预期效果或重新定位可能更实际[91 -93 ] . ...
1
... 早年的机器人学习(robot learning)方法通常专注于执行特定的任务,需要对应的特定数据集. 例如,在机器人操控领域,基本动作如抓取和推动各自有着专属的数据集. 抓取数据集关注的是使用机器人手或夹持器安全、稳定地抓持物体的行为[82 -90 ] . 推动数据集常用于处理难以直接抓取的物体. 当物体过大、过重或被其他物体所包围时,推动物体以达到预期效果或重新定位可能更实际[91 -93 ] . ...
1
... 与机器人操控相似,传统视觉导航任务被细分为许多专门的数据集. 视觉导航任务通常围绕指定目标的方式展开研究,如智能体可导航至一个坐标点(点目标导航)[94 ] ,至给定物体类别的一个实例(对象目标导航)[95 ] ,至由目标图像给出的地点(图像目标导航)[70 ] ,至发声的物体[96 ] ,或根据自然语言指令导航(视觉-语言导航)[97 -99 ] . 视觉导航的基准测试可能涵盖一个或多个导航任务[100 ] . ...
1
... 与机器人操控相似,传统视觉导航任务被细分为许多专门的数据集. 视觉导航任务通常围绕指定目标的方式展开研究,如智能体可导航至一个坐标点(点目标导航)[94 ] ,至给定物体类别的一个实例(对象目标导航)[95 ] ,至由目标图像给出的地点(图像目标导航)[70 ] ,至发声的物体[96 ] ,或根据自然语言指令导航(视觉-语言导航)[97 -99 ] . 视觉导航的基准测试可能涵盖一个或多个导航任务[100 ] . ...
1
... 与机器人操控相似,传统视觉导航任务被细分为许多专门的数据集. 视觉导航任务通常围绕指定目标的方式展开研究,如智能体可导航至一个坐标点(点目标导航)[94 ] ,至给定物体类别的一个实例(对象目标导航)[95 ] ,至由目标图像给出的地点(图像目标导航)[70 ] ,至发声的物体[96 ] ,或根据自然语言指令导航(视觉-语言导航)[97 -99 ] . 视觉导航的基准测试可能涵盖一个或多个导航任务[100 ] . ...
4
... 与机器人操控相似,传统视觉导航任务被细分为许多专门的数据集. 视觉导航任务通常围绕指定目标的方式展开研究,如智能体可导航至一个坐标点(点目标导航)[94 ] ,至给定物体类别的一个实例(对象目标导航)[95 ] ,至由目标图像给出的地点(图像目标导航)[70 ] ,至发声的物体[96 ] ,或根据自然语言指令导航(视觉-语言导航)[97 -99 ] . 视觉导航的基准测试可能涵盖一个或多个导航任务[100 ] . ...
... Simulator and dataset for embodied agent
Tab.4 模拟器 数据集 任务 室内/室外 AI2-THOR[106 ] ObjectNav 2021[107 ] [108 ] 目标导航 室内 SAPIEN[109 ] SAPIEN 操控 室内 TDW[110 ] TDW 操控 室内/室外 Matterport3D[97 ] R2R[97 ] [111 ] [99 ] 视觉语言导航 室内 Gibson[112 ] Gibson 导航 室内 Habitat-Sim[100 ] HP3D[100 ] [113 ] 导航 室内
虽然在模拟器中训练得到的模型能够在模拟环境下表现良好,但模拟环境与现实世界之间存在的明显差异是其在物理机器人上应用的主要障碍[114 ] . 在这方面,一些具身方法同时在模拟和现实世界[11 ,57 ,115 ] ,或完全在现实世界中[60 ] 评估模型的表现. ...
... [
97 ]
RxR
[111 ] REVERIE
[99 ] 视觉语言导航 室内 Gibson[112 ] Gibson 导航 室内 Habitat-Sim[100 ] HP3D[100 ] [113 ] 导航 室内 虽然在模拟器中训练得到的模型能够在模拟环境下表现良好,但模拟环境与现实世界之间存在的明显差异是其在物理机器人上应用的主要障碍[114 ] . 在这方面,一些具身方法同时在模拟和现实世界[11 ,57 ,115 ] ,或完全在现实世界中[60 ] 评估模型的表现. ...
... 视觉语言导航(vision-and-language navigation, VLN)是指智能体依据自然语言指令进行导航[97 ] . 随着大型语言模型如BERT[3 ] 和GPT[16 ] 的出现,将它们应用到视觉语言导航成为研究的新趋势. PreSS微调BERT和GPT以学习文本表征,这些表征能够更好地泛化到以前未见过的指令[125 ] . 此外,先预训练图像-文本对的视觉-语言多模态表征,再迁移到视觉语言任务,正逐渐成为一种主流方法,代表性的多模态模型包括ViLBERT[64 ] 和Oscar[66 ] . 对于导航任务,VLN-BERT采用ViLBERT[68 ] ,Airbert采用ViLBERT和Oscar[69 ] ,以更好地协调导航的视觉和语言指令. ...
2
... 与机器人操控相似,传统视觉导航任务被细分为许多专门的数据集. 视觉导航任务通常围绕指定目标的方式展开研究,如智能体可导航至一个坐标点(点目标导航)[94 ] ,至给定物体类别的一个实例(对象目标导航)[95 ] ,至由目标图像给出的地点(图像目标导航)[70 ] ,至发声的物体[96 ] ,或根据自然语言指令导航(视觉-语言导航)[97 -99 ] . 视觉导航的基准测试可能涵盖一个或多个导航任务[100 ] . ...
... Simulator and dataset for embodied agent
Tab.4 模拟器 数据集 任务 室内/室外 AI2-THOR[106 ] ObjectNav 2021[107 ] [108 ] 目标导航 室内 SAPIEN[109 ] SAPIEN 操控 室内 TDW[110 ] TDW 操控 室内/室外 Matterport3D[97 ] R2R[97 ] [111 ] [99 ] 视觉语言导航 室内 Gibson[112 ] Gibson 导航 室内 Habitat-Sim[100 ] HP3D[100 ] [113 ] 导航 室内
虽然在模拟器中训练得到的模型能够在模拟环境下表现良好,但模拟环境与现实世界之间存在的明显差异是其在物理机器人上应用的主要障碍[114 ] . 在这方面,一些具身方法同时在模拟和现实世界[11 ,57 ,115 ] ,或完全在现实世界中[60 ] 评估模型的表现. ...
4
... 与机器人操控相似,传统视觉导航任务被细分为许多专门的数据集. 视觉导航任务通常围绕指定目标的方式展开研究,如智能体可导航至一个坐标点(点目标导航)[94 ] ,至给定物体类别的一个实例(对象目标导航)[95 ] ,至由目标图像给出的地点(图像目标导航)[70 ] ,至发声的物体[96 ] ,或根据自然语言指令导航(视觉-语言导航)[97 -99 ] . 视觉导航的基准测试可能涵盖一个或多个导航任务[100 ] . ...
... 如表4 所示为常用于具身智能体研究的模拟器. 模拟器中使用的数据既可以是合成的,也可以是基于现实世界扫描得到的. 例如Matterport3D[102 ] 和Habitat-Sim[100 ] 模拟器是基于现实世界环境扫描构建的. 这类“现实世界”模拟器极大地增强了智能体从模型到现实应用的能力. ...
... Simulator and dataset for embodied agent
Tab.4 模拟器 数据集 任务 室内/室外 AI2-THOR[106 ] ObjectNav 2021[107 ] [108 ] 目标导航 室内 SAPIEN[109 ] SAPIEN 操控 室内 TDW[110 ] TDW 操控 室内/室外 Matterport3D[97 ] R2R[97 ] [111 ] [99 ] 视觉语言导航 室内 Gibson[112 ] Gibson 导航 室内 Habitat-Sim[100 ] HP3D[100 ] [113 ] 导航 室内
虽然在模拟器中训练得到的模型能够在模拟环境下表现良好,但模拟环境与现实世界之间存在的明显差异是其在物理机器人上应用的主要障碍[114 ] . 在这方面,一些具身方法同时在模拟和现实世界[11 ,57 ,115 ] ,或完全在现实世界中[60 ] 评估模型的表现. ...
... [
100 ]
HM3D
[113 ] 导航 室内 虽然在模拟器中训练得到的模型能够在模拟环境下表现良好,但模拟环境与现实世界之间存在的明显差异是其在物理机器人上应用的主要障碍[114 ] . 在这方面,一些具身方法同时在模拟和现实世界[11 ,57 ,115 ] ,或完全在现实世界中[60 ] 评估模型的表现. ...
2
... 在基座智能体的背景下,数据集往往涵盖多个任务、多个场景,甚至多种具身形式. 在导航方面,SCAND是面向户外场景的长距离数据集,支持2种不同的机器人[101 ] . GNM在6个不同的机器人上采集了60 h的导航轨迹数据[102 ] . 在机器人操控领域,RoboNet为7种机器人平台,不针对具体任务,提供了1 500万视频帧的预训练数据[103 ] . Bridge Data采集了71种任务的训练数据[104 ] . RH20T为7种不同配置的机器人平台提供了约150种技能的训练数据[105 ] . Open X-Embodiment数据库[6 ] 汇集了来自21个机构的22种不同机器人的数据集,展现了527项技能和160 266个任务. 在这些大规模数据集上训练的高容量模型展现了更好的泛化能力. 如表3 所示为多具身的智能体数据集. ...
... Real-world, large-scale dataset for multitask or cross-embodiment agent
Tab.3 数据集 技能数 轨迹量 帧数/106 时长/h 具身形态数 SCAND[101 ] — 138 — 8.7 2 RoboNet[103 ] — 1.62×105 15 — 7 Bridge Data[104 ] 71 7.2×103 — — 1 RH20T[105 ] 150 1.10×105 40 — 7 Open X-Embodiment[6 ] 527 106 — — 22 GNM[102 ] — — — 60 6
3.2. 模拟器 近年来,许多适用于具身智能的新模拟器被开发出来. 模拟器可以为智能体提供既安全又高效的学习环境. 此外,模拟器可以用于生成大量数据,这些在现实世界中的收集成本会非常高. 模拟器常用作基准测试,评估和比较不同方法的效果. ...
3
... 在基座智能体的背景下,数据集往往涵盖多个任务、多个场景,甚至多种具身形式. 在导航方面,SCAND是面向户外场景的长距离数据集,支持2种不同的机器人[101 ] . GNM在6个不同的机器人上采集了60 h的导航轨迹数据[102 ] . 在机器人操控领域,RoboNet为7种机器人平台,不针对具体任务,提供了1 500万视频帧的预训练数据[103 ] . Bridge Data采集了71种任务的训练数据[104 ] . RH20T为7种不同配置的机器人平台提供了约150种技能的训练数据[105 ] . Open X-Embodiment数据库[6 ] 汇集了来自21个机构的22种不同机器人的数据集,展现了527项技能和160 266个任务. 在这些大规模数据集上训练的高容量模型展现了更好的泛化能力. 如表3 所示为多具身的智能体数据集. ...
... Real-world, large-scale dataset for multitask or cross-embodiment agent
Tab.3 数据集 技能数 轨迹量 帧数/106 时长/h 具身形态数 SCAND[101 ] — 138 — 8.7 2 RoboNet[103 ] — 1.62×105 15 — 7 Bridge Data[104 ] 71 7.2×103 — — 1 RH20T[105 ] 150 1.10×105 40 — 7 Open X-Embodiment[6 ] 527 106 — — 22 GNM[102 ] — — — 60 6
3.2. 模拟器 近年来,许多适用于具身智能的新模拟器被开发出来. 模拟器可以为智能体提供既安全又高效的学习环境. 此外,模拟器可以用于生成大量数据,这些在现实世界中的收集成本会非常高. 模拟器常用作基准测试,评估和比较不同方法的效果. ...
... 如表4 所示为常用于具身智能体研究的模拟器. 模拟器中使用的数据既可以是合成的,也可以是基于现实世界扫描得到的. 例如Matterport3D[102 ] 和Habitat-Sim[100 ] 模拟器是基于现实世界环境扫描构建的. 这类“现实世界”模拟器极大地增强了智能体从模型到现实应用的能力. ...
2
... 在基座智能体的背景下,数据集往往涵盖多个任务、多个场景,甚至多种具身形式. 在导航方面,SCAND是面向户外场景的长距离数据集,支持2种不同的机器人[101 ] . GNM在6个不同的机器人上采集了60 h的导航轨迹数据[102 ] . 在机器人操控领域,RoboNet为7种机器人平台,不针对具体任务,提供了1 500万视频帧的预训练数据[103 ] . Bridge Data采集了71种任务的训练数据[104 ] . RH20T为7种不同配置的机器人平台提供了约150种技能的训练数据[105 ] . Open X-Embodiment数据库[6 ] 汇集了来自21个机构的22种不同机器人的数据集,展现了527项技能和160 266个任务. 在这些大规模数据集上训练的高容量模型展现了更好的泛化能力. 如表3 所示为多具身的智能体数据集. ...
... Real-world, large-scale dataset for multitask or cross-embodiment agent
Tab.3 数据集 技能数 轨迹量 帧数/106 时长/h 具身形态数 SCAND[101 ] — 138 — 8.7 2 RoboNet[103 ] — 1.62×105 15 — 7 Bridge Data[104 ] 71 7.2×103 — — 1 RH20T[105 ] 150 1.10×105 40 — 7 Open X-Embodiment[6 ] 527 106 — — 22 GNM[102 ] — — — 60 6
3.2. 模拟器 近年来,许多适用于具身智能的新模拟器被开发出来. 模拟器可以为智能体提供既安全又高效的学习环境. 此外,模拟器可以用于生成大量数据,这些在现实世界中的收集成本会非常高. 模拟器常用作基准测试,评估和比较不同方法的效果. ...
2
... 在基座智能体的背景下,数据集往往涵盖多个任务、多个场景,甚至多种具身形式. 在导航方面,SCAND是面向户外场景的长距离数据集,支持2种不同的机器人[101 ] . GNM在6个不同的机器人上采集了60 h的导航轨迹数据[102 ] . 在机器人操控领域,RoboNet为7种机器人平台,不针对具体任务,提供了1 500万视频帧的预训练数据[103 ] . Bridge Data采集了71种任务的训练数据[104 ] . RH20T为7种不同配置的机器人平台提供了约150种技能的训练数据[105 ] . Open X-Embodiment数据库[6 ] 汇集了来自21个机构的22种不同机器人的数据集,展现了527项技能和160 266个任务. 在这些大规模数据集上训练的高容量模型展现了更好的泛化能力. 如表3 所示为多具身的智能体数据集. ...
... Real-world, large-scale dataset for multitask or cross-embodiment agent
Tab.3 数据集 技能数 轨迹量 帧数/106 时长/h 具身形态数 SCAND[101 ] — 138 — 8.7 2 RoboNet[103 ] — 1.62×105 15 — 7 Bridge Data[104 ] 71 7.2×103 — — 1 RH20T[105 ] 150 1.10×105 40 — 7 Open X-Embodiment[6 ] 527 106 — — 22 GNM[102 ] — — — 60 6
3.2. 模拟器 近年来,许多适用于具身智能的新模拟器被开发出来. 模拟器可以为智能体提供既安全又高效的学习环境. 此外,模拟器可以用于生成大量数据,这些在现实世界中的收集成本会非常高. 模拟器常用作基准测试,评估和比较不同方法的效果. ...
2
... 在基座智能体的背景下,数据集往往涵盖多个任务、多个场景,甚至多种具身形式. 在导航方面,SCAND是面向户外场景的长距离数据集,支持2种不同的机器人[101 ] . GNM在6个不同的机器人上采集了60 h的导航轨迹数据[102 ] . 在机器人操控领域,RoboNet为7种机器人平台,不针对具体任务,提供了1 500万视频帧的预训练数据[103 ] . Bridge Data采集了71种任务的训练数据[104 ] . RH20T为7种不同配置的机器人平台提供了约150种技能的训练数据[105 ] . Open X-Embodiment数据库[6 ] 汇集了来自21个机构的22种不同机器人的数据集,展现了527项技能和160 266个任务. 在这些大规模数据集上训练的高容量模型展现了更好的泛化能力. 如表3 所示为多具身的智能体数据集. ...
... Real-world, large-scale dataset for multitask or cross-embodiment agent
Tab.3 数据集 技能数 轨迹量 帧数/106 时长/h 具身形态数 SCAND[101 ] — 138 — 8.7 2 RoboNet[103 ] — 1.62×105 15 — 7 Bridge Data[104 ] 71 7.2×103 — — 1 RH20T[105 ] 150 1.10×105 40 — 7 Open X-Embodiment[6 ] 527 106 — — 22 GNM[102 ] — — — 60 6
3.2. 模拟器 近年来,许多适用于具身智能的新模拟器被开发出来. 模拟器可以为智能体提供既安全又高效的学习环境. 此外,模拟器可以用于生成大量数据,这些在现实世界中的收集成本会非常高. 模拟器常用作基准测试,评估和比较不同方法的效果. ...
1
... Simulator and dataset for embodied agent
Tab.4 模拟器 数据集 任务 室内/室外 AI2-THOR[106 ] ObjectNav 2021[107 ] [108 ] 目标导航 室内 SAPIEN[109 ] SAPIEN 操控 室内 TDW[110 ] TDW 操控 室内/室外 Matterport3D[97 ] R2R[97 ] [111 ] [99 ] 视觉语言导航 室内 Gibson[112 ] Gibson 导航 室内 Habitat-Sim[100 ] HP3D[100 ] [113 ] 导航 室内
虽然在模拟器中训练得到的模型能够在模拟环境下表现良好,但模拟环境与现实世界之间存在的明显差异是其在物理机器人上应用的主要障碍[114 ] . 在这方面,一些具身方法同时在模拟和现实世界[11 ,57 ,115 ] ,或完全在现实世界中[60 ] 评估模型的表现. ...
2
... Simulator and dataset for embodied agent
Tab.4 模拟器 数据集 任务 室内/室外 AI2-THOR[106 ] ObjectNav 2021[107 ] [108 ] 目标导航 室内 SAPIEN[109 ] SAPIEN 操控 室内 TDW[110 ] TDW 操控 室内/室外 Matterport3D[97 ] R2R[97 ] [111 ] [99 ] 视觉语言导航 室内 Gibson[112 ] Gibson 导航 室内 Habitat-Sim[100 ] HP3D[100 ] [113 ] 导航 室内
虽然在模拟器中训练得到的模型能够在模拟环境下表现良好,但模拟环境与现实世界之间存在的明显差异是其在物理机器人上应用的主要障碍[114 ] . 在这方面,一些具身方法同时在模拟和现实世界[11 ,57 ,115 ] ,或完全在现实世界中[60 ] 评估模型的表现. ...
... 此外,一系列研究专注于模拟到现实的迁移. Kadian等[116 ] 提出名为 Sim-vs-Real 相关系数 (SRCC) 的度量,用于量化从模拟到现实的可预测性,发现模拟器的性能差异在部署到现实世界后不一致. 他们建议通过微调模拟器参数,提高模拟到现实的转换效果. RoboTHOR提供了与物理对应物相匹配的模拟环境[107 ] . Anderson等[117 ] 将具有预先收集和标注的占用图和导航图的视觉-语言导航智能体进行迁移. Truong等[118 ] 使用Context-Map 技术,将在室内模拟器上训练的智能体迁移到室外的现实世界环境中. 目前模拟到现实的迁移工作主要集中在有限的场景中. 对于面向多任务、多场景甚至多具身的基座智能体的迁移,仍然有巨大挑战. ...
1
... Simulator and dataset for embodied agent
Tab.4 模拟器 数据集 任务 室内/室外 AI2-THOR[106 ] ObjectNav 2021[107 ] [108 ] 目标导航 室内 SAPIEN[109 ] SAPIEN 操控 室内 TDW[110 ] TDW 操控 室内/室外 Matterport3D[97 ] R2R[97 ] [111 ] [99 ] 视觉语言导航 室内 Gibson[112 ] Gibson 导航 室内 Habitat-Sim[100 ] HP3D[100 ] [113 ] 导航 室内
虽然在模拟器中训练得到的模型能够在模拟环境下表现良好,但模拟环境与现实世界之间存在的明显差异是其在物理机器人上应用的主要障碍[114 ] . 在这方面,一些具身方法同时在模拟和现实世界[11 ,57 ,115 ] ,或完全在现实世界中[60 ] 评估模型的表现. ...
1
... Simulator and dataset for embodied agent
Tab.4 模拟器 数据集 任务 室内/室外 AI2-THOR[106 ] ObjectNav 2021[107 ] [108 ] 目标导航 室内 SAPIEN[109 ] SAPIEN 操控 室内 TDW[110 ] TDW 操控 室内/室外 Matterport3D[97 ] R2R[97 ] [111 ] [99 ] 视觉语言导航 室内 Gibson[112 ] Gibson 导航 室内 Habitat-Sim[100 ] HP3D[100 ] [113 ] 导航 室内
虽然在模拟器中训练得到的模型能够在模拟环境下表现良好,但模拟环境与现实世界之间存在的明显差异是其在物理机器人上应用的主要障碍[114 ] . 在这方面,一些具身方法同时在模拟和现实世界[11 ,57 ,115 ] ,或完全在现实世界中[60 ] 评估模型的表现. ...
1
... Simulator and dataset for embodied agent
Tab.4 模拟器 数据集 任务 室内/室外 AI2-THOR[106 ] ObjectNav 2021[107 ] [108 ] 目标导航 室内 SAPIEN[109 ] SAPIEN 操控 室内 TDW[110 ] TDW 操控 室内/室外 Matterport3D[97 ] R2R[97 ] [111 ] [99 ] 视觉语言导航 室内 Gibson[112 ] Gibson 导航 室内 Habitat-Sim[100 ] HP3D[100 ] [113 ] 导航 室内
虽然在模拟器中训练得到的模型能够在模拟环境下表现良好,但模拟环境与现实世界之间存在的明显差异是其在物理机器人上应用的主要障碍[114 ] . 在这方面,一些具身方法同时在模拟和现实世界[11 ,57 ,115 ] ,或完全在现实世界中[60 ] 评估模型的表现. ...
1
... Simulator and dataset for embodied agent
Tab.4 模拟器 数据集 任务 室内/室外 AI2-THOR[106 ] ObjectNav 2021[107 ] [108 ] 目标导航 室内 SAPIEN[109 ] SAPIEN 操控 室内 TDW[110 ] TDW 操控 室内/室外 Matterport3D[97 ] R2R[97 ] [111 ] [99 ] 视觉语言导航 室内 Gibson[112 ] Gibson 导航 室内 Habitat-Sim[100 ] HP3D[100 ] [113 ] 导航 室内
虽然在模拟器中训练得到的模型能够在模拟环境下表现良好,但模拟环境与现实世界之间存在的明显差异是其在物理机器人上应用的主要障碍[114 ] . 在这方面,一些具身方法同时在模拟和现实世界[11 ,57 ,115 ] ,或完全在现实世界中[60 ] 评估模型的表现. ...
1
... Simulator and dataset for embodied agent
Tab.4 模拟器 数据集 任务 室内/室外 AI2-THOR[106 ] ObjectNav 2021[107 ] [108 ] 目标导航 室内 SAPIEN[109 ] SAPIEN 操控 室内 TDW[110 ] TDW 操控 室内/室外 Matterport3D[97 ] R2R[97 ] [111 ] [99 ] 视觉语言导航 室内 Gibson[112 ] Gibson 导航 室内 Habitat-Sim[100 ] HP3D[100 ] [113 ] 导航 室内
虽然在模拟器中训练得到的模型能够在模拟环境下表现良好,但模拟环境与现实世界之间存在的明显差异是其在物理机器人上应用的主要障碍[114 ] . 在这方面,一些具身方法同时在模拟和现实世界[11 ,57 ,115 ] ,或完全在现实世界中[60 ] 评估模型的表现. ...
1
... Simulator and dataset for embodied agent
Tab.4 模拟器 数据集 任务 室内/室外 AI2-THOR[106 ] ObjectNav 2021[107 ] [108 ] 目标导航 室内 SAPIEN[109 ] SAPIEN 操控 室内 TDW[110 ] TDW 操控 室内/室外 Matterport3D[97 ] R2R[97 ] [111 ] [99 ] 视觉语言导航 室内 Gibson[112 ] Gibson 导航 室内 Habitat-Sim[100 ] HP3D[100 ] [113 ] 导航 室内
虽然在模拟器中训练得到的模型能够在模拟环境下表现良好,但模拟环境与现实世界之间存在的明显差异是其在物理机器人上应用的主要障碍[114 ] . 在这方面,一些具身方法同时在模拟和现实世界[11 ,57 ,115 ] ,或完全在现实世界中[60 ] 评估模型的表现. ...
3
... 虽然在模拟器中训练得到的模型能够在模拟环境下表现良好,但模拟环境与现实世界之间存在的明显差异是其在物理机器人上应用的主要障碍[114 ] . 在这方面,一些具身方法同时在模拟和现实世界[11 ,57 ,115 ] ,或完全在现实世界中[60 ] 评估模型的表现. ...
... Comparison of agents for visual navigation
Tab.5 智能体 语言 基座模型 真实世界 模拟器 室内/室外 建图 参数量 EmbCLIP[119 ] ✓ CLIP — AI2-THOR 室内 — 8.8×107 CoW[120 ] ✓ CLIP ✓ AI2-THOR, Habitat 室内 ✓ 3.07×108 ZSON[121 ] ✓ CLIP — Habitat, Gibson 室内 — — LFG[122 ] ✓ GPT-3.5 ✓ Habitat 室内 ✓ 2.0×1010 DDN[123 ] ✓ GPT-3.5 — AI2-THOR 室内 — 2.0×1010 PixNav[124 ] ✓ LLaMA-Adapter, GPT-4, Grounding DINO, SAM ✓ Habitat 室内 — — PreSS[125 ] ✓ BERT, GPT — Matterport3D 室内 — 1.17×108 /3.40×108 VLN-BERT[68 ] ✓ ViLBERT — Matterport3D 室内 — 1.55×108 MARVAL[126 ] ✓ — — Matterport3D, Gibson 室内 — — LM-Nav[76 ] ✓ ViNG, CLIP GPT-3 ✓ — 室外 ✓ — NavGPT[77 ] ✓ GPT-3.5, GPT-4 — Matterport3D 室内 ✓ — DiscussNav[114 ] ✓ GPT-4 — Matterport3D 室内 — — Vienna[127 ] ✓ — — Matterport3D, Habitat 室内 — 3.1×107 ViNT[115 ] — — ✓ — 室内/室外 — 3.1×107
4.1.1. 目标导航 目标导航(object-goal navigation 或 visual goal navigation)的目标是指引智能体前往目标物体所在地. 基座模型的应用使得对目标导航的零样本迁移成为可能. 例如,EmbCLIP证明了CLIP编码的骨干相比于ImageNet预训练的骨干网络更有效,展示了在训练阶段未涉及的4个类别的测试成果[119 ] . CLIP on Wheels(简称CoW)[120 ] 采用结合启发式探索策略的模型,能够扩展到更多未见过的类别. ZSON在目标图片上进行训练,旨在适应开放世界场景而不仅限于预定义的物体类别[121 ] . LFG利用GPT-3.5作为搜索的启发式,进行路径规划[122 ] . Wang等[123 ] 将目标导航设定为需求驱动的任务,使用GPT-3.5将用户需求转化为物体目标. PixNav[124 ] 利用4个外部大型模型,包括LLaMA-Adapter[128 ] 、GPT-4[20 ] 、Grounding DINO[129 ] 和SAM[31 ] ,设计逐步细化的提示模板,探索了基座模型在自我定位和构建结构化记忆方面的潜力. ...
... 在探索互联网规模的图像文本对预训练的同时,人类指令数据的稀缺成为研究的瓶颈. 为此,MARVAL 利用伴随的合成数据集Marky-Gibson,提供了具有合成指令的大规模数据增强[126 ] . 另一条研究路径利用外部大型语言模型. LM-Nav[76 ] 采用GPT-3[4 ] 来识别由视觉导航模型ViNG[130 ] 预定义的图上的地标,展示了基于预训练模型且无须任何微调的导航系统. 最近,NavGPT通过零样本动作预测,展示了大型语言模型在复杂具身场景中的推理能力[77 ] . DiscussNav用提示词在大语言模型上建立几个领域专家,用模拟的专家咨询会议来导航智能体,展示了令人印象深刻的零样本迁移性能[114 ] . ...
3
... 虽然在模拟器中训练得到的模型能够在模拟环境下表现良好,但模拟环境与现实世界之间存在的明显差异是其在物理机器人上应用的主要障碍[114 ] . 在这方面,一些具身方法同时在模拟和现实世界[11 ,57 ,115 ] ,或完全在现实世界中[60 ] 评估模型的表现. ...
... Comparison of agents for visual navigation
Tab.5 智能体 语言 基座模型 真实世界 模拟器 室内/室外 建图 参数量 EmbCLIP[119 ] ✓ CLIP — AI2-THOR 室内 — 8.8×107 CoW[120 ] ✓ CLIP ✓ AI2-THOR, Habitat 室内 ✓ 3.07×108 ZSON[121 ] ✓ CLIP — Habitat, Gibson 室内 — — LFG[122 ] ✓ GPT-3.5 ✓ Habitat 室内 ✓ 2.0×1010 DDN[123 ] ✓ GPT-3.5 — AI2-THOR 室内 — 2.0×1010 PixNav[124 ] ✓ LLaMA-Adapter, GPT-4, Grounding DINO, SAM ✓ Habitat 室内 — — PreSS[125 ] ✓ BERT, GPT — Matterport3D 室内 — 1.17×108 /3.40×108 VLN-BERT[68 ] ✓ ViLBERT — Matterport3D 室内 — 1.55×108 MARVAL[126 ] ✓ — — Matterport3D, Gibson 室内 — — LM-Nav[76 ] ✓ ViNG, CLIP GPT-3 ✓ — 室外 ✓ — NavGPT[77 ] ✓ GPT-3.5, GPT-4 — Matterport3D 室内 ✓ — DiscussNav[114 ] ✓ GPT-4 — Matterport3D 室内 — — Vienna[127 ] ✓ — — Matterport3D, Habitat 室内 — 3.1×107 ViNT[115 ] — — ✓ — 室内/室外 — 3.1×107
4.1.1. 目标导航 目标导航(object-goal navigation 或 visual goal navigation)的目标是指引智能体前往目标物体所在地. 基座模型的应用使得对目标导航的零样本迁移成为可能. 例如,EmbCLIP证明了CLIP编码的骨干相比于ImageNet预训练的骨干网络更有效,展示了在训练阶段未涉及的4个类别的测试成果[119 ] . CLIP on Wheels(简称CoW)[120 ] 采用结合启发式探索策略的模型,能够扩展到更多未见过的类别. ZSON在目标图片上进行训练,旨在适应开放世界场景而不仅限于预定义的物体类别[121 ] . LFG利用GPT-3.5作为搜索的启发式,进行路径规划[122 ] . Wang等[123 ] 将目标导航设定为需求驱动的任务,使用GPT-3.5将用户需求转化为物体目标. PixNav[124 ] 利用4个外部大型模型,包括LLaMA-Adapter[128 ] 、GPT-4[20 ] 、Grounding DINO[129 ] 和SAM[31 ] ,设计逐步细化的提示模板,探索了基座模型在自我定位和构建结构化记忆方面的潜力. ...
... 面对多样化的视觉导航任务和特定任务的解决方案,研究者们努力构建能够应对多项导航任务的统一智能体. Vienna是通用的具身导航智能体,它依托于庞大的数据集VXN进行训练[127 ] . 通过结合目标描述和任务编码,Vienna 展示了统一的方法,处理不同的输入域或模态之间的导航任务,实现了知识的跨任务重用. Vienna 在简化问题复杂度的同时,实现了与分别学习各个视觉导航任务相媲美甚至更优的性能. ViNT[115 ] 在来自不同机器人平台的多个导航数据集上进行训练,设定了通用的“达到目标”的目标,使其能够兼容任何导航数据集. 它采用灵活的基于Transformer的架构来学习导航技能,并且能够微调,以适用于多种下游导航任务. ViNT 展示了正向迁移的能力,超越了在小数据集上训练的专家模型的表现. ...
Sim2real predictivity: does evaluation in simulation predict real-world performance?
1
2020
... 此外,一系列研究专注于模拟到现实的迁移. Kadian等[116 ] 提出名为 Sim-vs-Real 相关系数 (SRCC) 的度量,用于量化从模拟到现实的可预测性,发现模拟器的性能差异在部署到现实世界后不一致. 他们建议通过微调模拟器参数,提高模拟到现实的转换效果. RoboTHOR提供了与物理对应物相匹配的模拟环境[107 ] . Anderson等[117 ] 将具有预先收集和标注的占用图和导航图的视觉-语言导航智能体进行迁移. Truong等[118 ] 使用Context-Map 技术,将在室内模拟器上训练的智能体迁移到室外的现实世界环境中. 目前模拟到现实的迁移工作主要集中在有限的场景中. 对于面向多任务、多场景甚至多具身的基座智能体的迁移,仍然有巨大挑战. ...
1
... 此外,一系列研究专注于模拟到现实的迁移. Kadian等[116 ] 提出名为 Sim-vs-Real 相关系数 (SRCC) 的度量,用于量化从模拟到现实的可预测性,发现模拟器的性能差异在部署到现实世界后不一致. 他们建议通过微调模拟器参数,提高模拟到现实的转换效果. RoboTHOR提供了与物理对应物相匹配的模拟环境[107 ] . Anderson等[117 ] 将具有预先收集和标注的占用图和导航图的视觉-语言导航智能体进行迁移. Truong等[118 ] 使用Context-Map 技术,将在室内模拟器上训练的智能体迁移到室外的现实世界环境中. 目前模拟到现实的迁移工作主要集中在有限的场景中. 对于面向多任务、多场景甚至多具身的基座智能体的迁移,仍然有巨大挑战. ...
1
... 此外,一系列研究专注于模拟到现实的迁移. Kadian等[116 ] 提出名为 Sim-vs-Real 相关系数 (SRCC) 的度量,用于量化从模拟到现实的可预测性,发现模拟器的性能差异在部署到现实世界后不一致. 他们建议通过微调模拟器参数,提高模拟到现实的转换效果. RoboTHOR提供了与物理对应物相匹配的模拟环境[107 ] . Anderson等[117 ] 将具有预先收集和标注的占用图和导航图的视觉-语言导航智能体进行迁移. Truong等[118 ] 使用Context-Map 技术,将在室内模拟器上训练的智能体迁移到室外的现实世界环境中. 目前模拟到现实的迁移工作主要集中在有限的场景中. 对于面向多任务、多场景甚至多具身的基座智能体的迁移,仍然有巨大挑战. ...
2
... Comparison of agents for visual navigation
Tab.5 智能体 语言 基座模型 真实世界 模拟器 室内/室外 建图 参数量 EmbCLIP[119 ] ✓ CLIP — AI2-THOR 室内 — 8.8×107 CoW[120 ] ✓ CLIP ✓ AI2-THOR, Habitat 室内 ✓ 3.07×108 ZSON[121 ] ✓ CLIP — Habitat, Gibson 室内 — — LFG[122 ] ✓ GPT-3.5 ✓ Habitat 室内 ✓ 2.0×1010 DDN[123 ] ✓ GPT-3.5 — AI2-THOR 室内 — 2.0×1010 PixNav[124 ] ✓ LLaMA-Adapter, GPT-4, Grounding DINO, SAM ✓ Habitat 室内 — — PreSS[125 ] ✓ BERT, GPT — Matterport3D 室内 — 1.17×108 /3.40×108 VLN-BERT[68 ] ✓ ViLBERT — Matterport3D 室内 — 1.55×108 MARVAL[126 ] ✓ — — Matterport3D, Gibson 室内 — — LM-Nav[76 ] ✓ ViNG, CLIP GPT-3 ✓ — 室外 ✓ — NavGPT[77 ] ✓ GPT-3.5, GPT-4 — Matterport3D 室内 ✓ — DiscussNav[114 ] ✓ GPT-4 — Matterport3D 室内 — — Vienna[127 ] ✓ — — Matterport3D, Habitat 室内 — 3.1×107 ViNT[115 ] — — ✓ — 室内/室外 — 3.1×107
4.1.1. 目标导航 目标导航(object-goal navigation 或 visual goal navigation)的目标是指引智能体前往目标物体所在地. 基座模型的应用使得对目标导航的零样本迁移成为可能. 例如,EmbCLIP证明了CLIP编码的骨干相比于ImageNet预训练的骨干网络更有效,展示了在训练阶段未涉及的4个类别的测试成果[119 ] . CLIP on Wheels(简称CoW)[120 ] 采用结合启发式探索策略的模型,能够扩展到更多未见过的类别. ZSON在目标图片上进行训练,旨在适应开放世界场景而不仅限于预定义的物体类别[121 ] . LFG利用GPT-3.5作为搜索的启发式,进行路径规划[122 ] . Wang等[123 ] 将目标导航设定为需求驱动的任务,使用GPT-3.5将用户需求转化为物体目标. PixNav[124 ] 利用4个外部大型模型,包括LLaMA-Adapter[128 ] 、GPT-4[20 ] 、Grounding DINO[129 ] 和SAM[31 ] ,设计逐步细化的提示模板,探索了基座模型在自我定位和构建结构化记忆方面的潜力. ...
... 目标导航(object-goal navigation 或 visual goal navigation)的目标是指引智能体前往目标物体所在地. 基座模型的应用使得对目标导航的零样本迁移成为可能. 例如,EmbCLIP证明了CLIP编码的骨干相比于ImageNet预训练的骨干网络更有效,展示了在训练阶段未涉及的4个类别的测试成果[119 ] . CLIP on Wheels(简称CoW)[120 ] 采用结合启发式探索策略的模型,能够扩展到更多未见过的类别. ZSON在目标图片上进行训练,旨在适应开放世界场景而不仅限于预定义的物体类别[121 ] . LFG利用GPT-3.5作为搜索的启发式,进行路径规划[122 ] . Wang等[123 ] 将目标导航设定为需求驱动的任务,使用GPT-3.5将用户需求转化为物体目标. PixNav[124 ] 利用4个外部大型模型,包括LLaMA-Adapter[128 ] 、GPT-4[20 ] 、Grounding DINO[129 ] 和SAM[31 ] ,设计逐步细化的提示模板,探索了基座模型在自我定位和构建结构化记忆方面的潜力. ...
2
... Comparison of agents for visual navigation
Tab.5 智能体 语言 基座模型 真实世界 模拟器 室内/室外 建图 参数量 EmbCLIP[119 ] ✓ CLIP — AI2-THOR 室内 — 8.8×107 CoW[120 ] ✓ CLIP ✓ AI2-THOR, Habitat 室内 ✓ 3.07×108 ZSON[121 ] ✓ CLIP — Habitat, Gibson 室内 — — LFG[122 ] ✓ GPT-3.5 ✓ Habitat 室内 ✓ 2.0×1010 DDN[123 ] ✓ GPT-3.5 — AI2-THOR 室内 — 2.0×1010 PixNav[124 ] ✓ LLaMA-Adapter, GPT-4, Grounding DINO, SAM ✓ Habitat 室内 — — PreSS[125 ] ✓ BERT, GPT — Matterport3D 室内 — 1.17×108 /3.40×108 VLN-BERT[68 ] ✓ ViLBERT — Matterport3D 室内 — 1.55×108 MARVAL[126 ] ✓ — — Matterport3D, Gibson 室内 — — LM-Nav[76 ] ✓ ViNG, CLIP GPT-3 ✓ — 室外 ✓ — NavGPT[77 ] ✓ GPT-3.5, GPT-4 — Matterport3D 室内 ✓ — DiscussNav[114 ] ✓ GPT-4 — Matterport3D 室内 — — Vienna[127 ] ✓ — — Matterport3D, Habitat 室内 — 3.1×107 ViNT[115 ] — — ✓ — 室内/室外 — 3.1×107
4.1.1. 目标导航 目标导航(object-goal navigation 或 visual goal navigation)的目标是指引智能体前往目标物体所在地. 基座模型的应用使得对目标导航的零样本迁移成为可能. 例如,EmbCLIP证明了CLIP编码的骨干相比于ImageNet预训练的骨干网络更有效,展示了在训练阶段未涉及的4个类别的测试成果[119 ] . CLIP on Wheels(简称CoW)[120 ] 采用结合启发式探索策略的模型,能够扩展到更多未见过的类别. ZSON在目标图片上进行训练,旨在适应开放世界场景而不仅限于预定义的物体类别[121 ] . LFG利用GPT-3.5作为搜索的启发式,进行路径规划[122 ] . Wang等[123 ] 将目标导航设定为需求驱动的任务,使用GPT-3.5将用户需求转化为物体目标. PixNav[124 ] 利用4个外部大型模型,包括LLaMA-Adapter[128 ] 、GPT-4[20 ] 、Grounding DINO[129 ] 和SAM[31 ] ,设计逐步细化的提示模板,探索了基座模型在自我定位和构建结构化记忆方面的潜力. ...
... 目标导航(object-goal navigation 或 visual goal navigation)的目标是指引智能体前往目标物体所在地. 基座模型的应用使得对目标导航的零样本迁移成为可能. 例如,EmbCLIP证明了CLIP编码的骨干相比于ImageNet预训练的骨干网络更有效,展示了在训练阶段未涉及的4个类别的测试成果[119 ] . CLIP on Wheels(简称CoW)[120 ] 采用结合启发式探索策略的模型,能够扩展到更多未见过的类别. ZSON在目标图片上进行训练,旨在适应开放世界场景而不仅限于预定义的物体类别[121 ] . LFG利用GPT-3.5作为搜索的启发式,进行路径规划[122 ] . Wang等[123 ] 将目标导航设定为需求驱动的任务,使用GPT-3.5将用户需求转化为物体目标. PixNav[124 ] 利用4个外部大型模型,包括LLaMA-Adapter[128 ] 、GPT-4[20 ] 、Grounding DINO[129 ] 和SAM[31 ] ,设计逐步细化的提示模板,探索了基座模型在自我定位和构建结构化记忆方面的潜力. ...
2
... Comparison of agents for visual navigation
Tab.5 智能体 语言 基座模型 真实世界 模拟器 室内/室外 建图 参数量 EmbCLIP[119 ] ✓ CLIP — AI2-THOR 室内 — 8.8×107 CoW[120 ] ✓ CLIP ✓ AI2-THOR, Habitat 室内 ✓ 3.07×108 ZSON[121 ] ✓ CLIP — Habitat, Gibson 室内 — — LFG[122 ] ✓ GPT-3.5 ✓ Habitat 室内 ✓ 2.0×1010 DDN[123 ] ✓ GPT-3.5 — AI2-THOR 室内 — 2.0×1010 PixNav[124 ] ✓ LLaMA-Adapter, GPT-4, Grounding DINO, SAM ✓ Habitat 室内 — — PreSS[125 ] ✓ BERT, GPT — Matterport3D 室内 — 1.17×108 /3.40×108 VLN-BERT[68 ] ✓ ViLBERT — Matterport3D 室内 — 1.55×108 MARVAL[126 ] ✓ — — Matterport3D, Gibson 室内 — — LM-Nav[76 ] ✓ ViNG, CLIP GPT-3 ✓ — 室外 ✓ — NavGPT[77 ] ✓ GPT-3.5, GPT-4 — Matterport3D 室内 ✓ — DiscussNav[114 ] ✓ GPT-4 — Matterport3D 室内 — — Vienna[127 ] ✓ — — Matterport3D, Habitat 室内 — 3.1×107 ViNT[115 ] — — ✓ — 室内/室外 — 3.1×107
4.1.1. 目标导航 目标导航(object-goal navigation 或 visual goal navigation)的目标是指引智能体前往目标物体所在地. 基座模型的应用使得对目标导航的零样本迁移成为可能. 例如,EmbCLIP证明了CLIP编码的骨干相比于ImageNet预训练的骨干网络更有效,展示了在训练阶段未涉及的4个类别的测试成果[119 ] . CLIP on Wheels(简称CoW)[120 ] 采用结合启发式探索策略的模型,能够扩展到更多未见过的类别. ZSON在目标图片上进行训练,旨在适应开放世界场景而不仅限于预定义的物体类别[121 ] . LFG利用GPT-3.5作为搜索的启发式,进行路径规划[122 ] . Wang等[123 ] 将目标导航设定为需求驱动的任务,使用GPT-3.5将用户需求转化为物体目标. PixNav[124 ] 利用4个外部大型模型,包括LLaMA-Adapter[128 ] 、GPT-4[20 ] 、Grounding DINO[129 ] 和SAM[31 ] ,设计逐步细化的提示模板,探索了基座模型在自我定位和构建结构化记忆方面的潜力. ...
... 目标导航(object-goal navigation 或 visual goal navigation)的目标是指引智能体前往目标物体所在地. 基座模型的应用使得对目标导航的零样本迁移成为可能. 例如,EmbCLIP证明了CLIP编码的骨干相比于ImageNet预训练的骨干网络更有效,展示了在训练阶段未涉及的4个类别的测试成果[119 ] . CLIP on Wheels(简称CoW)[120 ] 采用结合启发式探索策略的模型,能够扩展到更多未见过的类别. ZSON在目标图片上进行训练,旨在适应开放世界场景而不仅限于预定义的物体类别[121 ] . LFG利用GPT-3.5作为搜索的启发式,进行路径规划[122 ] . Wang等[123 ] 将目标导航设定为需求驱动的任务,使用GPT-3.5将用户需求转化为物体目标. PixNav[124 ] 利用4个外部大型模型,包括LLaMA-Adapter[128 ] 、GPT-4[20 ] 、Grounding DINO[129 ] 和SAM[31 ] ,设计逐步细化的提示模板,探索了基座模型在自我定位和构建结构化记忆方面的潜力. ...
2
... Comparison of agents for visual navigation
Tab.5 智能体 语言 基座模型 真实世界 模拟器 室内/室外 建图 参数量 EmbCLIP[119 ] ✓ CLIP — AI2-THOR 室内 — 8.8×107 CoW[120 ] ✓ CLIP ✓ AI2-THOR, Habitat 室内 ✓ 3.07×108 ZSON[121 ] ✓ CLIP — Habitat, Gibson 室内 — — LFG[122 ] ✓ GPT-3.5 ✓ Habitat 室内 ✓ 2.0×1010 DDN[123 ] ✓ GPT-3.5 — AI2-THOR 室内 — 2.0×1010 PixNav[124 ] ✓ LLaMA-Adapter, GPT-4, Grounding DINO, SAM ✓ Habitat 室内 — — PreSS[125 ] ✓ BERT, GPT — Matterport3D 室内 — 1.17×108 /3.40×108 VLN-BERT[68 ] ✓ ViLBERT — Matterport3D 室内 — 1.55×108 MARVAL[126 ] ✓ — — Matterport3D, Gibson 室内 — — LM-Nav[76 ] ✓ ViNG, CLIP GPT-3 ✓ — 室外 ✓ — NavGPT[77 ] ✓ GPT-3.5, GPT-4 — Matterport3D 室内 ✓ — DiscussNav[114 ] ✓ GPT-4 — Matterport3D 室内 — — Vienna[127 ] ✓ — — Matterport3D, Habitat 室内 — 3.1×107 ViNT[115 ] — — ✓ — 室内/室外 — 3.1×107
4.1.1. 目标导航 目标导航(object-goal navigation 或 visual goal navigation)的目标是指引智能体前往目标物体所在地. 基座模型的应用使得对目标导航的零样本迁移成为可能. 例如,EmbCLIP证明了CLIP编码的骨干相比于ImageNet预训练的骨干网络更有效,展示了在训练阶段未涉及的4个类别的测试成果[119 ] . CLIP on Wheels(简称CoW)[120 ] 采用结合启发式探索策略的模型,能够扩展到更多未见过的类别. ZSON在目标图片上进行训练,旨在适应开放世界场景而不仅限于预定义的物体类别[121 ] . LFG利用GPT-3.5作为搜索的启发式,进行路径规划[122 ] . Wang等[123 ] 将目标导航设定为需求驱动的任务,使用GPT-3.5将用户需求转化为物体目标. PixNav[124 ] 利用4个外部大型模型,包括LLaMA-Adapter[128 ] 、GPT-4[20 ] 、Grounding DINO[129 ] 和SAM[31 ] ,设计逐步细化的提示模板,探索了基座模型在自我定位和构建结构化记忆方面的潜力. ...
... 目标导航(object-goal navigation 或 visual goal navigation)的目标是指引智能体前往目标物体所在地. 基座模型的应用使得对目标导航的零样本迁移成为可能. 例如,EmbCLIP证明了CLIP编码的骨干相比于ImageNet预训练的骨干网络更有效,展示了在训练阶段未涉及的4个类别的测试成果[119 ] . CLIP on Wheels(简称CoW)[120 ] 采用结合启发式探索策略的模型,能够扩展到更多未见过的类别. ZSON在目标图片上进行训练,旨在适应开放世界场景而不仅限于预定义的物体类别[121 ] . LFG利用GPT-3.5作为搜索的启发式,进行路径规划[122 ] . Wang等[123 ] 将目标导航设定为需求驱动的任务,使用GPT-3.5将用户需求转化为物体目标. PixNav[124 ] 利用4个外部大型模型,包括LLaMA-Adapter[128 ] 、GPT-4[20 ] 、Grounding DINO[129 ] 和SAM[31 ] ,设计逐步细化的提示模板,探索了基座模型在自我定位和构建结构化记忆方面的潜力. ...
2
... Comparison of agents for visual navigation
Tab.5 智能体 语言 基座模型 真实世界 模拟器 室内/室外 建图 参数量 EmbCLIP[119 ] ✓ CLIP — AI2-THOR 室内 — 8.8×107 CoW[120 ] ✓ CLIP ✓ AI2-THOR, Habitat 室内 ✓ 3.07×108 ZSON[121 ] ✓ CLIP — Habitat, Gibson 室内 — — LFG[122 ] ✓ GPT-3.5 ✓ Habitat 室内 ✓ 2.0×1010 DDN[123 ] ✓ GPT-3.5 — AI2-THOR 室内 — 2.0×1010 PixNav[124 ] ✓ LLaMA-Adapter, GPT-4, Grounding DINO, SAM ✓ Habitat 室内 — — PreSS[125 ] ✓ BERT, GPT — Matterport3D 室内 — 1.17×108 /3.40×108 VLN-BERT[68 ] ✓ ViLBERT — Matterport3D 室内 — 1.55×108 MARVAL[126 ] ✓ — — Matterport3D, Gibson 室内 — — LM-Nav[76 ] ✓ ViNG, CLIP GPT-3 ✓ — 室外 ✓ — NavGPT[77 ] ✓ GPT-3.5, GPT-4 — Matterport3D 室内 ✓ — DiscussNav[114 ] ✓ GPT-4 — Matterport3D 室内 — — Vienna[127 ] ✓ — — Matterport3D, Habitat 室内 — 3.1×107 ViNT[115 ] — — ✓ — 室内/室外 — 3.1×107
4.1.1. 目标导航 目标导航(object-goal navigation 或 visual goal navigation)的目标是指引智能体前往目标物体所在地. 基座模型的应用使得对目标导航的零样本迁移成为可能. 例如,EmbCLIP证明了CLIP编码的骨干相比于ImageNet预训练的骨干网络更有效,展示了在训练阶段未涉及的4个类别的测试成果[119 ] . CLIP on Wheels(简称CoW)[120 ] 采用结合启发式探索策略的模型,能够扩展到更多未见过的类别. ZSON在目标图片上进行训练,旨在适应开放世界场景而不仅限于预定义的物体类别[121 ] . LFG利用GPT-3.5作为搜索的启发式,进行路径规划[122 ] . Wang等[123 ] 将目标导航设定为需求驱动的任务,使用GPT-3.5将用户需求转化为物体目标. PixNav[124 ] 利用4个外部大型模型,包括LLaMA-Adapter[128 ] 、GPT-4[20 ] 、Grounding DINO[129 ] 和SAM[31 ] ,设计逐步细化的提示模板,探索了基座模型在自我定位和构建结构化记忆方面的潜力. ...
... 目标导航(object-goal navigation 或 visual goal navigation)的目标是指引智能体前往目标物体所在地. 基座模型的应用使得对目标导航的零样本迁移成为可能. 例如,EmbCLIP证明了CLIP编码的骨干相比于ImageNet预训练的骨干网络更有效,展示了在训练阶段未涉及的4个类别的测试成果[119 ] . CLIP on Wheels(简称CoW)[120 ] 采用结合启发式探索策略的模型,能够扩展到更多未见过的类别. ZSON在目标图片上进行训练,旨在适应开放世界场景而不仅限于预定义的物体类别[121 ] . LFG利用GPT-3.5作为搜索的启发式,进行路径规划[122 ] . Wang等[123 ] 将目标导航设定为需求驱动的任务,使用GPT-3.5将用户需求转化为物体目标. PixNav[124 ] 利用4个外部大型模型,包括LLaMA-Adapter[128 ] 、GPT-4[20 ] 、Grounding DINO[129 ] 和SAM[31 ] ,设计逐步细化的提示模板,探索了基座模型在自我定位和构建结构化记忆方面的潜力. ...
2
... Comparison of agents for visual navigation
Tab.5 智能体 语言 基座模型 真实世界 模拟器 室内/室外 建图 参数量 EmbCLIP[119 ] ✓ CLIP — AI2-THOR 室内 — 8.8×107 CoW[120 ] ✓ CLIP ✓ AI2-THOR, Habitat 室内 ✓ 3.07×108 ZSON[121 ] ✓ CLIP — Habitat, Gibson 室内 — — LFG[122 ] ✓ GPT-3.5 ✓ Habitat 室内 ✓ 2.0×1010 DDN[123 ] ✓ GPT-3.5 — AI2-THOR 室内 — 2.0×1010 PixNav[124 ] ✓ LLaMA-Adapter, GPT-4, Grounding DINO, SAM ✓ Habitat 室内 — — PreSS[125 ] ✓ BERT, GPT — Matterport3D 室内 — 1.17×108 /3.40×108 VLN-BERT[68 ] ✓ ViLBERT — Matterport3D 室内 — 1.55×108 MARVAL[126 ] ✓ — — Matterport3D, Gibson 室内 — — LM-Nav[76 ] ✓ ViNG, CLIP GPT-3 ✓ — 室外 ✓ — NavGPT[77 ] ✓ GPT-3.5, GPT-4 — Matterport3D 室内 ✓ — DiscussNav[114 ] ✓ GPT-4 — Matterport3D 室内 — — Vienna[127 ] ✓ — — Matterport3D, Habitat 室内 — 3.1×107 ViNT[115 ] — — ✓ — 室内/室外 — 3.1×107
4.1.1. 目标导航 目标导航(object-goal navigation 或 visual goal navigation)的目标是指引智能体前往目标物体所在地. 基座模型的应用使得对目标导航的零样本迁移成为可能. 例如,EmbCLIP证明了CLIP编码的骨干相比于ImageNet预训练的骨干网络更有效,展示了在训练阶段未涉及的4个类别的测试成果[119 ] . CLIP on Wheels(简称CoW)[120 ] 采用结合启发式探索策略的模型,能够扩展到更多未见过的类别. ZSON在目标图片上进行训练,旨在适应开放世界场景而不仅限于预定义的物体类别[121 ] . LFG利用GPT-3.5作为搜索的启发式,进行路径规划[122 ] . Wang等[123 ] 将目标导航设定为需求驱动的任务,使用GPT-3.5将用户需求转化为物体目标. PixNav[124 ] 利用4个外部大型模型,包括LLaMA-Adapter[128 ] 、GPT-4[20 ] 、Grounding DINO[129 ] 和SAM[31 ] ,设计逐步细化的提示模板,探索了基座模型在自我定位和构建结构化记忆方面的潜力. ...
... 目标导航(object-goal navigation 或 visual goal navigation)的目标是指引智能体前往目标物体所在地. 基座模型的应用使得对目标导航的零样本迁移成为可能. 例如,EmbCLIP证明了CLIP编码的骨干相比于ImageNet预训练的骨干网络更有效,展示了在训练阶段未涉及的4个类别的测试成果[119 ] . CLIP on Wheels(简称CoW)[120 ] 采用结合启发式探索策略的模型,能够扩展到更多未见过的类别. ZSON在目标图片上进行训练,旨在适应开放世界场景而不仅限于预定义的物体类别[121 ] . LFG利用GPT-3.5作为搜索的启发式,进行路径规划[122 ] . Wang等[123 ] 将目标导航设定为需求驱动的任务,使用GPT-3.5将用户需求转化为物体目标. PixNav[124 ] 利用4个外部大型模型,包括LLaMA-Adapter[128 ] 、GPT-4[20 ] 、Grounding DINO[129 ] 和SAM[31 ] ,设计逐步细化的提示模板,探索了基座模型在自我定位和构建结构化记忆方面的潜力. ...
2
... Comparison of agents for visual navigation
Tab.5 智能体 语言 基座模型 真实世界 模拟器 室内/室外 建图 参数量 EmbCLIP[119 ] ✓ CLIP — AI2-THOR 室内 — 8.8×107 CoW[120 ] ✓ CLIP ✓ AI2-THOR, Habitat 室内 ✓ 3.07×108 ZSON[121 ] ✓ CLIP — Habitat, Gibson 室内 — — LFG[122 ] ✓ GPT-3.5 ✓ Habitat 室内 ✓ 2.0×1010 DDN[123 ] ✓ GPT-3.5 — AI2-THOR 室内 — 2.0×1010 PixNav[124 ] ✓ LLaMA-Adapter, GPT-4, Grounding DINO, SAM ✓ Habitat 室内 — — PreSS[125 ] ✓ BERT, GPT — Matterport3D 室内 — 1.17×108 /3.40×108 VLN-BERT[68 ] ✓ ViLBERT — Matterport3D 室内 — 1.55×108 MARVAL[126 ] ✓ — — Matterport3D, Gibson 室内 — — LM-Nav[76 ] ✓ ViNG, CLIP GPT-3 ✓ — 室外 ✓ — NavGPT[77 ] ✓ GPT-3.5, GPT-4 — Matterport3D 室内 ✓ — DiscussNav[114 ] ✓ GPT-4 — Matterport3D 室内 — — Vienna[127 ] ✓ — — Matterport3D, Habitat 室内 — 3.1×107 ViNT[115 ] — — ✓ — 室内/室外 — 3.1×107
4.1.1. 目标导航 目标导航(object-goal navigation 或 visual goal navigation)的目标是指引智能体前往目标物体所在地. 基座模型的应用使得对目标导航的零样本迁移成为可能. 例如,EmbCLIP证明了CLIP编码的骨干相比于ImageNet预训练的骨干网络更有效,展示了在训练阶段未涉及的4个类别的测试成果[119 ] . CLIP on Wheels(简称CoW)[120 ] 采用结合启发式探索策略的模型,能够扩展到更多未见过的类别. ZSON在目标图片上进行训练,旨在适应开放世界场景而不仅限于预定义的物体类别[121 ] . LFG利用GPT-3.5作为搜索的启发式,进行路径规划[122 ] . Wang等[123 ] 将目标导航设定为需求驱动的任务,使用GPT-3.5将用户需求转化为物体目标. PixNav[124 ] 利用4个外部大型模型,包括LLaMA-Adapter[128 ] 、GPT-4[20 ] 、Grounding DINO[129 ] 和SAM[31 ] ,设计逐步细化的提示模板,探索了基座模型在自我定位和构建结构化记忆方面的潜力. ...
... 视觉语言导航(vision-and-language navigation, VLN)是指智能体依据自然语言指令进行导航[97 ] . 随着大型语言模型如BERT[3 ] 和GPT[16 ] 的出现,将它们应用到视觉语言导航成为研究的新趋势. PreSS微调BERT和GPT以学习文本表征,这些表征能够更好地泛化到以前未见过的指令[125 ] . 此外,先预训练图像-文本对的视觉-语言多模态表征,再迁移到视觉语言任务,正逐渐成为一种主流方法,代表性的多模态模型包括ViLBERT[64 ] 和Oscar[66 ] . 对于导航任务,VLN-BERT采用ViLBERT[68 ] ,Airbert采用ViLBERT和Oscar[69 ] ,以更好地协调导航的视觉和语言指令. ...
2
... Comparison of agents for visual navigation
Tab.5 智能体 语言 基座模型 真实世界 模拟器 室内/室外 建图 参数量 EmbCLIP[119 ] ✓ CLIP — AI2-THOR 室内 — 8.8×107 CoW[120 ] ✓ CLIP ✓ AI2-THOR, Habitat 室内 ✓ 3.07×108 ZSON[121 ] ✓ CLIP — Habitat, Gibson 室内 — — LFG[122 ] ✓ GPT-3.5 ✓ Habitat 室内 ✓ 2.0×1010 DDN[123 ] ✓ GPT-3.5 — AI2-THOR 室内 — 2.0×1010 PixNav[124 ] ✓ LLaMA-Adapter, GPT-4, Grounding DINO, SAM ✓ Habitat 室内 — — PreSS[125 ] ✓ BERT, GPT — Matterport3D 室内 — 1.17×108 /3.40×108 VLN-BERT[68 ] ✓ ViLBERT — Matterport3D 室内 — 1.55×108 MARVAL[126 ] ✓ — — Matterport3D, Gibson 室内 — — LM-Nav[76 ] ✓ ViNG, CLIP GPT-3 ✓ — 室外 ✓ — NavGPT[77 ] ✓ GPT-3.5, GPT-4 — Matterport3D 室内 ✓ — DiscussNav[114 ] ✓ GPT-4 — Matterport3D 室内 — — Vienna[127 ] ✓ — — Matterport3D, Habitat 室内 — 3.1×107 ViNT[115 ] — — ✓ — 室内/室外 — 3.1×107
4.1.1. 目标导航 目标导航(object-goal navigation 或 visual goal navigation)的目标是指引智能体前往目标物体所在地. 基座模型的应用使得对目标导航的零样本迁移成为可能. 例如,EmbCLIP证明了CLIP编码的骨干相比于ImageNet预训练的骨干网络更有效,展示了在训练阶段未涉及的4个类别的测试成果[119 ] . CLIP on Wheels(简称CoW)[120 ] 采用结合启发式探索策略的模型,能够扩展到更多未见过的类别. ZSON在目标图片上进行训练,旨在适应开放世界场景而不仅限于预定义的物体类别[121 ] . LFG利用GPT-3.5作为搜索的启发式,进行路径规划[122 ] . Wang等[123 ] 将目标导航设定为需求驱动的任务,使用GPT-3.5将用户需求转化为物体目标. PixNav[124 ] 利用4个外部大型模型,包括LLaMA-Adapter[128 ] 、GPT-4[20 ] 、Grounding DINO[129 ] 和SAM[31 ] ,设计逐步细化的提示模板,探索了基座模型在自我定位和构建结构化记忆方面的潜力. ...
... 在探索互联网规模的图像文本对预训练的同时,人类指令数据的稀缺成为研究的瓶颈. 为此,MARVAL 利用伴随的合成数据集Marky-Gibson,提供了具有合成指令的大规模数据增强[126 ] . 另一条研究路径利用外部大型语言模型. LM-Nav[76 ] 采用GPT-3[4 ] 来识别由视觉导航模型ViNG[130 ] 预定义的图上的地标,展示了基于预训练模型且无须任何微调的导航系统. 最近,NavGPT通过零样本动作预测,展示了大型语言模型在复杂具身场景中的推理能力[77 ] . DiscussNav用提示词在大语言模型上建立几个领域专家,用模拟的专家咨询会议来导航智能体,展示了令人印象深刻的零样本迁移性能[114 ] . ...
2
... Comparison of agents for visual navigation
Tab.5 智能体 语言 基座模型 真实世界 模拟器 室内/室外 建图 参数量 EmbCLIP[119 ] ✓ CLIP — AI2-THOR 室内 — 8.8×107 CoW[120 ] ✓ CLIP ✓ AI2-THOR, Habitat 室内 ✓ 3.07×108 ZSON[121 ] ✓ CLIP — Habitat, Gibson 室内 — — LFG[122 ] ✓ GPT-3.5 ✓ Habitat 室内 ✓ 2.0×1010 DDN[123 ] ✓ GPT-3.5 — AI2-THOR 室内 — 2.0×1010 PixNav[124 ] ✓ LLaMA-Adapter, GPT-4, Grounding DINO, SAM ✓ Habitat 室内 — — PreSS[125 ] ✓ BERT, GPT — Matterport3D 室内 — 1.17×108 /3.40×108 VLN-BERT[68 ] ✓ ViLBERT — Matterport3D 室内 — 1.55×108 MARVAL[126 ] ✓ — — Matterport3D, Gibson 室内 — — LM-Nav[76 ] ✓ ViNG, CLIP GPT-3 ✓ — 室外 ✓ — NavGPT[77 ] ✓ GPT-3.5, GPT-4 — Matterport3D 室内 ✓ — DiscussNav[114 ] ✓ GPT-4 — Matterport3D 室内 — — Vienna[127 ] ✓ — — Matterport3D, Habitat 室内 — 3.1×107 ViNT[115 ] — — ✓ — 室内/室外 — 3.1×107
4.1.1. 目标导航 目标导航(object-goal navigation 或 visual goal navigation)的目标是指引智能体前往目标物体所在地. 基座模型的应用使得对目标导航的零样本迁移成为可能. 例如,EmbCLIP证明了CLIP编码的骨干相比于ImageNet预训练的骨干网络更有效,展示了在训练阶段未涉及的4个类别的测试成果[119 ] . CLIP on Wheels(简称CoW)[120 ] 采用结合启发式探索策略的模型,能够扩展到更多未见过的类别. ZSON在目标图片上进行训练,旨在适应开放世界场景而不仅限于预定义的物体类别[121 ] . LFG利用GPT-3.5作为搜索的启发式,进行路径规划[122 ] . Wang等[123 ] 将目标导航设定为需求驱动的任务,使用GPT-3.5将用户需求转化为物体目标. PixNav[124 ] 利用4个外部大型模型,包括LLaMA-Adapter[128 ] 、GPT-4[20 ] 、Grounding DINO[129 ] 和SAM[31 ] ,设计逐步细化的提示模板,探索了基座模型在自我定位和构建结构化记忆方面的潜力. ...
... 面对多样化的视觉导航任务和特定任务的解决方案,研究者们努力构建能够应对多项导航任务的统一智能体. Vienna是通用的具身导航智能体,它依托于庞大的数据集VXN进行训练[127 ] . 通过结合目标描述和任务编码,Vienna 展示了统一的方法,处理不同的输入域或模态之间的导航任务,实现了知识的跨任务重用. Vienna 在简化问题复杂度的同时,实现了与分别学习各个视觉导航任务相媲美甚至更优的性能. ViNT[115 ] 在来自不同机器人平台的多个导航数据集上进行训练,设定了通用的“达到目标”的目标,使其能够兼容任何导航数据集. 它采用灵活的基于Transformer的架构来学习导航技能,并且能够微调,以适用于多种下游导航任务. ViNT 展示了正向迁移的能力,超越了在小数据集上训练的专家模型的表现. ...
1
... 目标导航(object-goal navigation 或 visual goal navigation)的目标是指引智能体前往目标物体所在地. 基座模型的应用使得对目标导航的零样本迁移成为可能. 例如,EmbCLIP证明了CLIP编码的骨干相比于ImageNet预训练的骨干网络更有效,展示了在训练阶段未涉及的4个类别的测试成果[119 ] . CLIP on Wheels(简称CoW)[120 ] 采用结合启发式探索策略的模型,能够扩展到更多未见过的类别. ZSON在目标图片上进行训练,旨在适应开放世界场景而不仅限于预定义的物体类别[121 ] . LFG利用GPT-3.5作为搜索的启发式,进行路径规划[122 ] . Wang等[123 ] 将目标导航设定为需求驱动的任务,使用GPT-3.5将用户需求转化为物体目标. PixNav[124 ] 利用4个外部大型模型,包括LLaMA-Adapter[128 ] 、GPT-4[20 ] 、Grounding DINO[129 ] 和SAM[31 ] ,设计逐步细化的提示模板,探索了基座模型在自我定位和构建结构化记忆方面的潜力. ...
1
... 目标导航(object-goal navigation 或 visual goal navigation)的目标是指引智能体前往目标物体所在地. 基座模型的应用使得对目标导航的零样本迁移成为可能. 例如,EmbCLIP证明了CLIP编码的骨干相比于ImageNet预训练的骨干网络更有效,展示了在训练阶段未涉及的4个类别的测试成果[119 ] . CLIP on Wheels(简称CoW)[120 ] 采用结合启发式探索策略的模型,能够扩展到更多未见过的类别. ZSON在目标图片上进行训练,旨在适应开放世界场景而不仅限于预定义的物体类别[121 ] . LFG利用GPT-3.5作为搜索的启发式,进行路径规划[122 ] . Wang等[123 ] 将目标导航设定为需求驱动的任务,使用GPT-3.5将用户需求转化为物体目标. PixNav[124 ] 利用4个外部大型模型,包括LLaMA-Adapter[128 ] 、GPT-4[20 ] 、Grounding DINO[129 ] 和SAM[31 ] ,设计逐步细化的提示模板,探索了基座模型在自我定位和构建结构化记忆方面的潜力. ...
1
... 在探索互联网规模的图像文本对预训练的同时,人类指令数据的稀缺成为研究的瓶颈. 为此,MARVAL 利用伴随的合成数据集Marky-Gibson,提供了具有合成指令的大规模数据增强[126 ] . 另一条研究路径利用外部大型语言模型. LM-Nav[76 ] 采用GPT-3[4 ] 来识别由视觉导航模型ViNG[130 ] 预定义的图上的地标,展示了基于预训练模型且无须任何微调的导航系统. 最近,NavGPT通过零样本动作预测,展示了大型语言模型在复杂具身场景中的推理能力[77 ] . DiscussNav用提示词在大语言模型上建立几个领域专家,用模拟的专家咨询会议来导航智能体,展示了令人印象深刻的零样本迁移性能[114 ] . ...
2
... Comparison of foundation agent for robotic manipulation
Tab.6 智能体 语言 基座模型 真实世界 多具身 参数量 SayCan[131 ] ✓ PaLM ✓ ✓ 5.40×1011 R3M[132 ] ✓ — ✓ — — Gato[54 ] ✓ — ✓ ✓ 1.2×109 RT-1[53 ] ✓ SayCan ✓ — 5.40×1011 PaLM-E[11 ] ✓ PaLM, ViT-22B ✓ ✓ 5.62×1011 RT-2[55 ] ✓ PaLI-X ✓ — 5.5×1010 SMART[60 ] — — — — 1.08×107 MVP[58 ] — — — — 2.2×107 Real MVP[59 ] — — ✓ ✓ 3.07×108 RPT[63 ] — — ✓ ✓ 3.07×108 RoboCat[57 ] [133 ] — — ✓ ✓ 1.2×109 8
SayCan通过价值函数将大型语言模型与现实世界连接在一起,使其执行真实世界的动作[131 ] . R3M通过结合时间对比学习、视频-语言对齐和L1惩罚,预训练鼓励稀疏和紧凑的表征的多模态模型[132 ] . Gato将文本、图像、离散值和连续值转换为词元(token),并将它们输入到Transformer中,以学习一般性策略[54 ] . RT-1关注开放的任务无关的训练范式,以零样本迁移的方式泛化到更多的机器人任务[53 ] . PaLM-E[11 ] 将操控的规划问题形式转化为语言问题,将来自任意模态的输入转化为词元,并将词元输入到PaLM中. RT-2[55 ] 结合大型多模态模型,例如PaLI-X[30 ] ,并直接预测机器人动作. ...
... SayCan通过价值函数将大型语言模型与现实世界连接在一起,使其执行真实世界的动作[131 ] . R3M通过结合时间对比学习、视频-语言对齐和L1惩罚,预训练鼓励稀疏和紧凑的表征的多模态模型[132 ] . Gato将文本、图像、离散值和连续值转换为词元(token),并将它们输入到Transformer中,以学习一般性策略[54 ] . RT-1关注开放的任务无关的训练范式,以零样本迁移的方式泛化到更多的机器人任务[53 ] . PaLM-E[11 ] 将操控的规划问题形式转化为语言问题,将来自任意模态的输入转化为词元,并将词元输入到PaLM中. RT-2[55 ] 结合大型多模态模型,例如PaLI-X[30 ] ,并直接预测机器人动作. ...
2
... Comparison of foundation agent for robotic manipulation
Tab.6 智能体 语言 基座模型 真实世界 多具身 参数量 SayCan[131 ] ✓ PaLM ✓ ✓ 5.40×1011 R3M[132 ] ✓ — ✓ — — Gato[54 ] ✓ — ✓ ✓ 1.2×109 RT-1[53 ] ✓ SayCan ✓ — 5.40×1011 PaLM-E[11 ] ✓ PaLM, ViT-22B ✓ ✓ 5.62×1011 RT-2[55 ] ✓ PaLI-X ✓ — 5.5×1010 SMART[60 ] — — — — 1.08×107 MVP[58 ] — — — — 2.2×107 Real MVP[59 ] — — ✓ ✓ 3.07×108 RPT[63 ] — — ✓ ✓ 3.07×108 RoboCat[57 ] [133 ] — — ✓ ✓ 1.2×109 8
SayCan通过价值函数将大型语言模型与现实世界连接在一起,使其执行真实世界的动作[131 ] . R3M通过结合时间对比学习、视频-语言对齐和L1惩罚,预训练鼓励稀疏和紧凑的表征的多模态模型[132 ] . Gato将文本、图像、离散值和连续值转换为词元(token),并将它们输入到Transformer中,以学习一般性策略[54 ] . RT-1关注开放的任务无关的训练范式,以零样本迁移的方式泛化到更多的机器人任务[53 ] . PaLM-E[11 ] 将操控的规划问题形式转化为语言问题,将来自任意模态的输入转化为词元,并将词元输入到PaLM中. RT-2[55 ] 结合大型多模态模型,例如PaLI-X[30 ] ,并直接预测机器人动作. ...
... SayCan通过价值函数将大型语言模型与现实世界连接在一起,使其执行真实世界的动作[131 ] . R3M通过结合时间对比学习、视频-语言对齐和L1惩罚,预训练鼓励稀疏和紧凑的表征的多模态模型[132 ] . Gato将文本、图像、离散值和连续值转换为词元(token),并将它们输入到Transformer中,以学习一般性策略[54 ] . RT-1关注开放的任务无关的训练范式,以零样本迁移的方式泛化到更多的机器人任务[53 ] . PaLM-E[11 ] 将操控的规划问题形式转化为语言问题,将来自任意模态的输入转化为词元,并将词元输入到PaLM中. RT-2[55 ] 结合大型多模态模型,例如PaLI-X[30 ] ,并直接预测机器人动作. ...
2
... Comparison of foundation agent for robotic manipulation
Tab.6 智能体 语言 基座模型 真实世界 多具身 参数量 SayCan[131 ] ✓ PaLM ✓ ✓ 5.40×1011 R3M[132 ] ✓ — ✓ — — Gato[54 ] ✓ — ✓ ✓ 1.2×109 RT-1[53 ] ✓ SayCan ✓ — 5.40×1011 PaLM-E[11 ] ✓ PaLM, ViT-22B ✓ ✓ 5.62×1011 RT-2[55 ] ✓ PaLI-X ✓ — 5.5×1010 SMART[60 ] — — — — 1.08×107 MVP[58 ] — — — — 2.2×107 Real MVP[59 ] — — ✓ ✓ 3.07×108 RPT[63 ] — — ✓ ✓ 3.07×108 RoboCat[57 ] [133 ] — — ✓ ✓ 1.2×109 8
SayCan通过价值函数将大型语言模型与现实世界连接在一起,使其执行真实世界的动作[131 ] . R3M通过结合时间对比学习、视频-语言对齐和L1惩罚,预训练鼓励稀疏和紧凑的表征的多模态模型[132 ] . Gato将文本、图像、离散值和连续值转换为词元(token),并将它们输入到Transformer中,以学习一般性策略[54 ] . RT-1关注开放的任务无关的训练范式,以零样本迁移的方式泛化到更多的机器人任务[53 ] . PaLM-E[11 ] 将操控的规划问题形式转化为语言问题,将来自任意模态的输入转化为词元,并将词元输入到PaLM中. RT-2[55 ] 结合大型多模态模型,例如PaLI-X[30 ] ,并直接预测机器人动作. ...
... MVP[58 ] 展示了自然图像的自监督预训练对于学习机器人任务是有效的. Real MVP[59 ] 用更多的数据和更大的架构,将MVP扩展到真实世界环境中. MaskDP[61 ] 对状态和动作词元进行遮罩,使模型学习前向和逆向的动力学. RPT[63 ] 将遮罩自编码扩展到多模态,遮掩图像、本体感知状态和行动. RoboCat[57 ] 展示了能够泛化到新任务和新机器人的自我提升的基座智能体. Yang等[133 ] 通过利用导航和操控这2个任务的相似性,在多种机器人上训练单一目标导向策略,验证了跨具身学习的有效性,展示了该策略在各种实际环境中的适应能力. ...
1
... 大规模智能体虽然能够展现出良好的性能,但由于规模庞大、耗时耗能,不适合在边缘设备上部署,轻量级部署成为基座智能体面临的一大挑战. Wei等[134 ] 提出,目前还不清楚大型语言模型的能力在何种规模下会涌现. 需要在智能体的复杂性与性能之间找到平衡点. ...


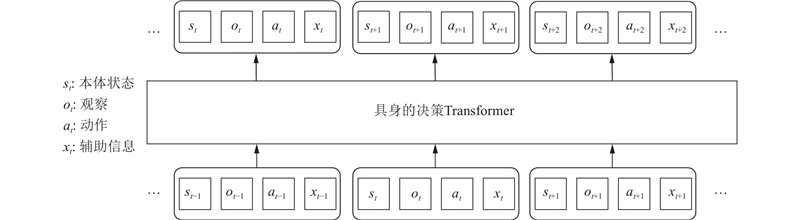
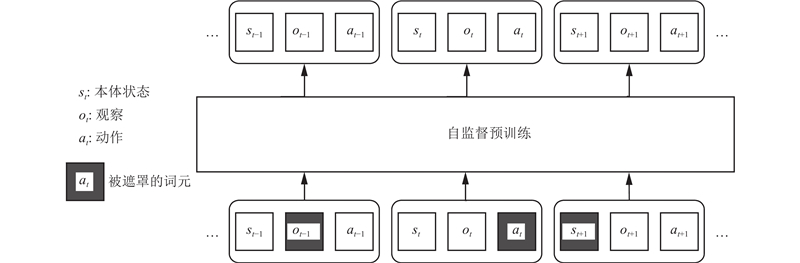

{kind=link}
{kind=link}
{kind=link}
{kind=link}