

实现多个相互关联任务的并发学习和推理一直是多任务场景理解的目标. 在面向自动驾驶领域的交通场景感知[1]中,语义分割[2-4]对图像中关键区域的像素进行语义解析,单目深度估计[5-7]通过推理图像中的像素来描述场景中物体的空间几何位置关系. 二者都需要对视觉场景进行像素级理解,因此存在相当密切的直接或间接关联. 充分挖掘这些相关性,不仅有利于不同任务之间共享低级简单特征,而且能够实现高级抽象特征的交互,这个过程一般被称为跨任务特征交互[8]. 其重要性在于能够促进任务之间的正迁移,即一个任务的学习有助于提升其他任务的性能. 因此,如何在多任务学习[9-10]中高效地进行跨任务特征交互是一个值得探索的问题.
过去主流的多任务交通场景感知算法大多基于卷积神经网络(CNN)框架. 例如,LeTFuser算法[11]通过感知模块中的卷积标记嵌入来处理2D输入图像,并利用从RGB-D相机获得的观测数据进行编码,通过CNN从多张RGB图像中提取和融合特征. EHSINet算法[12]依托全卷积网络实现邻域特征之间的长距离和高阶空间交互,能够自适应地处理多项任务. Tan等[13]通过引入C2SPD模块提取特征,并基于各种任务之间的差异提出双颈架构来进行优化. 这些方法通过建立多任务特征交互机制,增强了协调学习效果,但由于受到卷积网络架构的局部计算特性影响,语义信息不连贯,导致跨任务交互机制无法充分发挥预期作用,并带来了不必要的噪声. 为此,越来越多的研究者引入Transformer来捕获密集预测问题中的长距离依赖关系[14],诞生了诸如InvPT++[15]等众多优秀的多任务环境感知算法. 在本研究团队的早期工作中,提出了联合语义分割和深度估计的交通环境感知算法SDFormer[16],并在当时取得了最优的综合性能. 然而,其特征交互质量还有待于进一步的提升,具体表现在:1)由于不同任务具有显著不同的优化目标,特征间的互补机制未必都能起到积极作用,而冗余信息的融合可能会限制跨任务交互的效果;2)直接使用编码器抽取的共性信息来增强特定任务特征,但是未对这些信息本身进行强化,这种较弱的任务表征导致特征交互机制无法充分发挥作用;3)只使用具有深层表示的特定任务特征参与任务推理,而舍弃包含丰富细节的浅层表示特征,可能削弱了模型的整体性能.
针对这些问题,着眼于改善多任务学习的交互质量,进一步改进SDFormer,提出采用双向注意力机制的SDFormer++. 该模型主要面向具有路面等级良好、划线清晰完整、交通标志标识完备、交通信号灯规范等特点的城市街道交通环境,旨在实现像素级别的语义分割和深度估计视觉任务. 为了提升对交通场景的多任务协同感知和理解的准确性,对交通环境图像中的多尺度特征空间信息以及跨任务上下文间的长程关联性进行建模,同时整合深层语义信息和浅层语义信息. 不同于现有的以Transformer为架构的算法模型,在SDFormer++中使用特定任务特征编码器,并在该编码器中加入交互门控线性单元(interaction gated linear units, IGLU)来区分不同任务类别的特征,减少跨任务交互过程中冗余特征带来的干扰,从而形成更为清晰有序且具有高度区分性的特征表示. 这种策略与过去仅提取和利用深层语义信息而舍弃浅层语义信息的做法不同,能够让不同层次的语义信息的交互更加完整. 此外,在SDFormer++中设计多尺度特征融合模块来融合不同尺度的特征,增强模型对复杂交通环境的适应性和鲁棒性. 实验结果证明了SDFormer++的良好性能.
1. 网络结构设计
1.1. 整体结构
SDFormer++模型由任务特征编码网络和任务特征解码网络构成,整体框架如图1所示. 输入的图像首先经过基础特征编码器,Swin-Transformer作为骨干网络从图像中提取多尺度的任务基础特征图(E3、E4、E5). 这些基础特征不直接参与交互,而是被输入到特定编码器作进一步的处理. 在对特定任务特征进行编码的过程中选择具有高级抽象特征的E3,将其传递给跨任务特征提取(cross-task feature extraction, CFE)模块,用于提取初始特定任务特征,其中IGLU负责抑制与当前任务无关的像素信息,并生成更有判别性的特征表示以用于后续特征交互. 在任务特征解码网络中,解码器由连续堆叠的多任务特征交互(multi-task feature interaction, MFI)模块组成. 该模块在解码过程中对任务自身特征序列和任务间特征序列执行双向注意力机制,以此获取高质量的特定任务特征. 此外,采用多尺度特征融合(multi-scale feature fusion, MFF)模块来整合不同尺度的特征图,使模型在保持足够细节的同时能够进行有效的抽象,从而提高各任务的精确度. 最终输出的特征由各任务的解码分支进行推理.
图 1
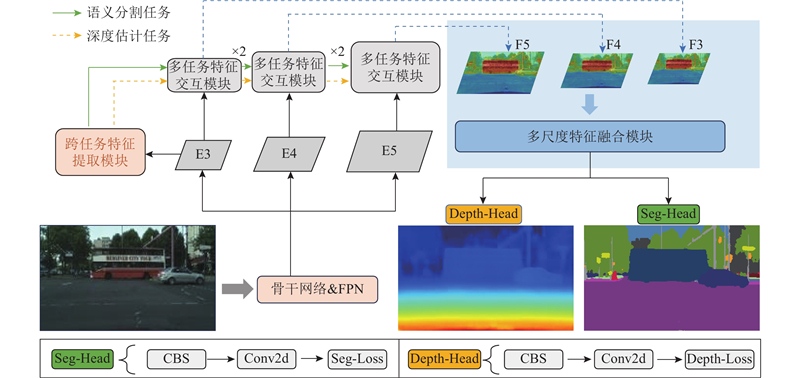
图 1 交通场景感知算法SDFormer++的整体结构
Fig.1 Overall structure of traffic scene perception algorithm SDFormer++
1.2. 跨任务特征提取模块
在使用共享编码器的多任务网络模型中,因为不同任务的优化目标不同,所以在进行特征提取时互补信息可能会携带杂质信息. 为了减少杂质信息参与交互带来的负面影响,设计CFE模块,具体结构如图2所示.
图 2
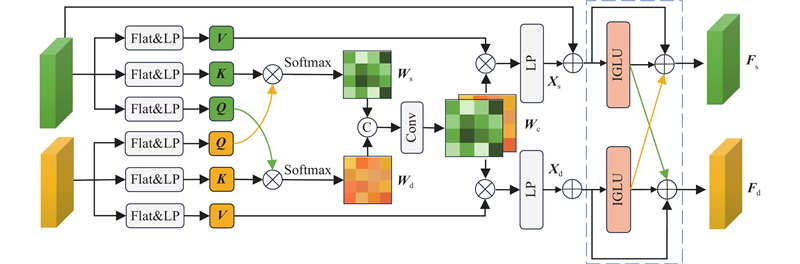
图 2 跨任务特征提取模块结构图
Fig.2 Structure diagram of cross-task feature extraction module
在前期编码阶段,通过交互语义分割和深度估计2个任务分支的查询(Q)和关键字(K),生成注意力图Ws和Wd. 将共享任务模式特征图Wc与各自任务分支的值矩阵相乘,通过线性投射得到信息特征Xs和Xd. 采用IGLU来滤除与当前任务需求不符的冗余信息,并进行残差连接. 通过内设更新门和重置门来控制信息的流动,得到2个任务分支的特定任务特征Fs和Fd:
式中:SiLu表示激活函数,LP表示线性投射处理. 该模块中IGLU的引入是SDFormer++相对于SDFormer作出的一项改进.
1.3. 多任务特征交互模块
MFI模块接收来自各任务的特定特征{Fs, Fd}∈RH×W×C(H、W和C分别为特征张量的高、宽和通道数)和基础特征Fb,具体结构如图3所示. 该模块既在单一任务特征序列中进行自注意力增强,又在不同任务特征序列之间执行交叉注意力操作. 通过连续堆叠该模块,能够更好地对不同尺度特征图的信息进行建模. MFI的主要工作原理为:1)利用卷积块对齐Fs、Fd与基础特征Fb的通道数,将经过卷积处理的特定任务特征和基础特征相加,得到融合空间细节与跨任务语义的特征F;2)分别采用卷积和池化的方式处理F,获得包含不同层次梯度信息的任务特征序列Fc与Fp;3)对注意力矩阵执行交叉注意力操作,得到注意力增强后的权重矩阵Am;4)将特征序列Fc与Am进行加权融合;5)利用多层感知机(MLP)对融合后的特征进行拆分和残差连接,得到2个任务分支的输出特征.
图 3
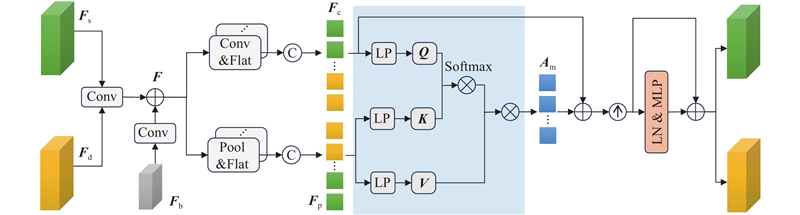
图 3 多任务特征交互模块结构图
Fig.3 Structure diagram of multi-task feature interaction module
1.4. 多尺度特征融合模块
城市街道交通场景中的物体往往具有较为广泛的尺度范围,这容易降低算法的性能. 通常采用特征金字塔网络(feature pyramid network, FPN)等特征聚合策略来缓解这个问题,但是大部分方法没有对具有不同分辨率的特征进行深度融合. 为此,针对性地设计MFF模块,具体结构如图4所示. 向MFF模块输入特征图F3、F4、F5,其分辨率分别为初始输入图像的1/32、1/16、1/8. 特别地,为了融合多尺度特征,在特征图F3之后使用金字塔池模型(pyramid pooling model, PPM)来扩大感受野. 分别使用卷积块和转置卷积块将不同特征图的分辨率都调整为输入图像的1/16后,将这些尺度一致的特定任务特征进行拼接,输入到对应的任务预测头中,得到最终推理结果.
图 4
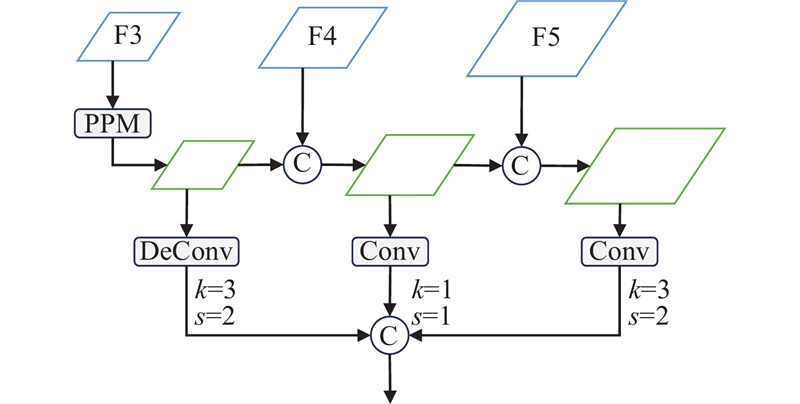
1.5. 损失函数
采用交叉熵作为语义分割任务的网络训练损失函数,记为
式中:
式中:
2. 实验与分析
2.1. 数据集
利用Cityscapes[17]数据集展开验证实验. 数据集中精细的像素级语义标注覆盖了道路、车辆等19类城市场景要素,同时RGB图像均配有经立体匹配生成的视差图;其多任务标注体系满足实验需求. 鉴于官方测试集标注未公开,为了保证评估过程的规范性与不同算法之间的可比性,所有消融实验和对比实验均在验证集中的2 975张标准图像上进行.
2.2. 实验平台与参数设置
实验主机的操作系统为64位 Windows 10,硬件采用Intel(R) Core(TM) i7-14700KF CPU和NVIDIA GeForce RTX
2.3. 评价指标
选择平均交并比(mean intersection over union, mIoU)作为分割性能的评价指标:
式中:n为类别总数,
式中:N为图像中的像素总数,
2.4. 网络组件消融实验
为了深入分析SDFormer++模型的不同组件对最终性能的影响,进行网络组件消融实验,结果如表1所示. 表中,MTL表示多任务学习基线模型. 该模型以Swin-S为主干网络,配备由语义分割与深度估计2个解码头构成的并行预测头. 以MTL为基础逐步添加CFE、MFI和MFF模块. 实验数据表明,引入CFE模块后模型的mIoU提升4.6个百分点,深度估计的RMSE和ARE分别降低5.4%和21.1%;进一步加入MFI模块后,mIoU提升了0.8个百分点,RMSE和ARE再降低了5.5%和6.1%;加入MFF模块后的完整模型的mIoU达到79.3%,RMSE和ARE降低至4.698和0.154,各项指标均达到最优值,说明多任务模型SDFormer++能够较好地权衡推理速度与整体性能.
表 1 不同网络组件的消融实验结果
Tab.1
| 模块 | mIoU/% | RMSE | ARE | Np/106 | GFLOPs |
| MTL | 73.2 | 5.355 | 0.227 | 66.3 | 131.1 |
| +CFE | 77.8 | 5.068 | 0.179 | 74.5 | 157.4 |
| +MFI | 78.6 | 4.790 | 0.168 | 75.6 | 168.4 |
| +MFF | 79.3 | 4.698 | 0.154 | 76.1 | 177.0 |
2.5. 跨任务特征提取模块对比实验
为了证实CFE模块的有效性,将该模块替换为SDFormer算法中的双向跨任务注意力模块BCTA,以此为对照组,在语义分割分支上进行注意力模式可视化对比实验,结果如图5所示. 可以看出,BCTA在处理信息时无法清晰明确地聚焦于图中的公交车或骑行者等任务目标,存在明显的特征表示干扰问题. 而使用CFE模块处理的特征图表现出与真实分布更相似的特征表示,其中突出显示的区域拥有明确边界,呈现出更完整的关联信息.
图 5
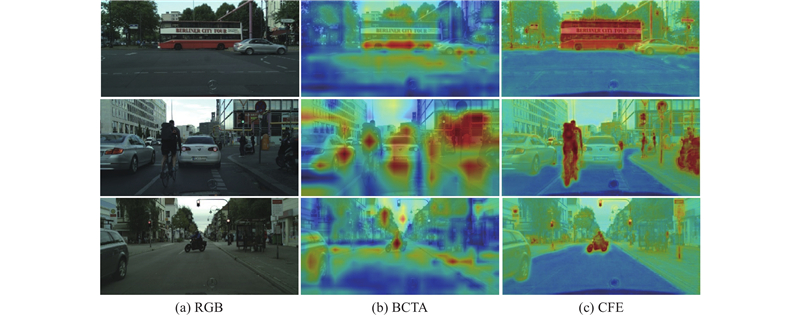
图 5 不同特征提取模块的注意力模式可视化对比
Fig.5 Visualization comparison of attention patterns in different feature extraction modules
2.6. 多尺度特征融合模块消融实验
MFF模块使用单张特征图进行预测. 为了加快推理速度,须选择合适的输出特征图分辨率. 将按照不同尺度调整特征图的MFF模块记为MFFS、MFFM与MFFL,对应的输出分辨率分别为原图的1/32、1/16和1/8,对比结果如表2所示.结果表明,较大特征图的检测准确率更高,但是性能提升和计算负担的增加不成正比. 当采用中等分辨率时,检测准确率有轻微下降,但是推理效率提高至原先的2.5倍. 这对于满足自动驾驶过程中的实时性要求是有利的. 因此,在SDFormer++中的多尺度特征融合模块中,选择输出特征分辨率为原图大小的1/16.
表 2 多尺度特征融合模块消融实验结果
Tab.2
| 模块 | 骨干网络 | mIoU/% | RMSE | ARE | FPS |
| MFFS | Swin-S | 75.8 | 4.811 | 0.176 | 30.8 |
| MFFM | Swin-S | 79.3 | 4.698 | 0.154 | 26.2 |
| MFFL | Swin-S | 79.5 | 4.662 | 0.151 | 10.6 |
2.7. 与其他多任务算法的性能对比
表 3 不同多任务算法的性能对比结果
Tab.3
| 算法 | 骨干网络 | mIoU/% | RMSE | ARE | Np/106 |
| JTR | SegNet | 72.3 | 5.582 | 0.163 | 79.6 |
| MTPSL | SegNet | 73.6 | 5.135 | 0.165 | 84.5 |
| DenseMTL | ResNet-101 | 75.0 | 6.649 | 0.194 | 124.3 |
| SwinMTL | Swin-B | 76.4 | 4.489 | 0.134 | 65.2 |
| SDFormer | Swin-B | 79.2 | 4.485 | 0.132 | 116.7 |
| InvPT++ | ViT-B | 82.0 | 4.527 | 0.146 | 156.9 |
| SDFormer++ | Swin-B | 82.4 | 4.453 | 0.130 | 129.4 |
可以看出,在使用相同编码器的情况下,与SDFormer相比,SDFormer++在mIoU指标上高出3.2个百分点,在RMSE和ARE指标上分别降低了0.7%和1.5%. 与其他算法中表现最优的InvPT++相比,虽然使用了不同的编码器,但是SDFormer++的mIoU指标高出0.4个百分点,RMSE和ARE指标分别进一步降低了1.6%和11.0%. 这些结果表明,SDFormer++算法达到了当前最优的准确率,并且在推理效率上取得了当前次优结果.
图6展示了SDFormer++与对比算法在语义分割任务上的推理结果差异. 在黄色虚线框指示的易混淆类别区域中,SDFormer将建筑物全部判定为其他类别,InvPT++虽然能够正确识别部分建筑物,但是仍有错判区域,而SDFormer++不仅很少出现错判问题,而且能够很好地区分易混淆类别区域和其他类别区域. 例如,SDFormer和InvPT++都将人行道的一部分错判为道路或植被,相比之下,SDFormer++关于地面的错判面积大幅减小. 图7展示了SDFormer++与对比算法在深度估计任务上的推理结果差异. 可以看出,SDFormer++通过多尺度特征融合机制有效保留了高频细节特征,在深度估计任务中展现出卓越的结构完整性保持率,特别是在远距离目标表征方面(如红色虚线框标注的行人). InvPT++出现了深度不连续与梯度突变问题,而SDFormer++得益于跨任务特征交互,实现了空间连续性的优化,其深度预测结果在物体边缘区域展现出更符合视觉认知的平滑过渡特性.
图 6

图 6 SDFormer++、SDFormer与次优算法在语义分割任务上的推理效果对比
Fig.6 Comparison of semantic segmentation inference performance of SDFormer++, SDFormer and suboptimal algorithm
图 7
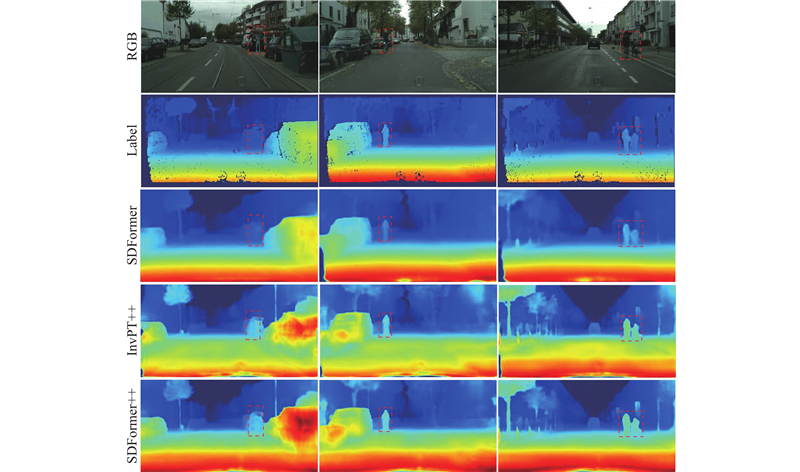
图 7 SDFormer++、SDFormer与次优算法在深度估计任务上的推理效果对比
Fig.7 Comparison of depth estimation inference performance of SDFormer++, SDFormer and suboptimal algorithm
2.8. 与单任务算法的性能对比
表 4 SDFormer++与单任务语义分割算法的性能对比
Tab.4
| 方法 | 骨干网络 | mIoU/% | Np/106 | GFLOPs |
| CSFNet-2 | STDC2 | 76.3 | 19.4 | 47.8 |
| WaveMix | WaveMix | 80.7 | 63.2 | 161.5 |
| DSNet-Base | DSNet-Base | 82.0 | 68.0 | 226.6 |
| CMX(B4) | MiT-B4 | 82.6 | 140.0 | 134.0 |
| EfficientViT-B3 | EfficientViT-L2 | 83.2 | 53.1 | 396.2 |
| SDFormer++ | Swin-B | 82.4 | 129.4 | 272.5 |
表 5 SDFormer++与单任务深度估计算法的性能对比
Tab.5
| 方法 | 骨干网络 | RMSE | ARE | Np/106 | GFLOPs |
| Manydepth2 | HRNet 16 | 5.827 | 0.097 | 123.1 | 246.4 |
| DepthFormer | Swin-B | 4.326 | 0.127 | 151.3 | 282.0 |
| PixelFormer | Swin-B | 4.258 | 0.115 | 146.1 | 346.4 |
| SDFormer++ | Swin-B | 4.453 | 0.130 | 129.4 | 272.5 |
可以看出,在语义分割任务中,性能较优的EfficientViT-B3的mIoU指标仅比SDFormer++高出0.8个百分点,计算复杂度却是SDFormer++的1.45倍;与SDFormer++参数量相近的CMX(B4)在mIoU指标上仅高出0.2个百分点. 在深度估计任务中,在RMSE指标上SDFormer++与当前性能较优的PixelFormer相比高了0.195;在ARE指标上与当前性能较优的Manydepth2相比仅高了0.033.
为了更好地评估SDFormer++的深度估计准确度,从Cityscapes验证集中随机抽取200张图像,计算其中的行人、骑行者、小车、公交车和卡车这5类典型交通参与者的真实距离与算法预测距离之间的平均相对误差. 根据双目立体视觉中的三角测量原理,目标物体的三维空间距离的计算公式为
式中:b为双目传感器的光心间距,f为成像系统的等效焦距参数,d为通过立体匹配算法获取的视差值. 据此可以分别计算出场景中第i个目标与成像系统之间的测距真值
计算结果如表6所示. 表中,Avg表示每种方法在预测5种不同交通参与者上的MRE均值. 可以看出,在面向自动驾驶场景的关键障碍物测距任务中,针对行人、公交车和卡车这3类典型交通参与者的距离估计,SDFormer++取得了最小误差. SDFormer++通过跨任务双向特征交互机制将平均相对误差优化至6.0%,优于对比算法.
表 6 不同交通参与者的距离估计误差对比
Tab.6
| 方法 | MRE/% | Avg/% | ||||
| 行人 | 骑行者 | 小车 | 公交车 | 卡车 | ||
| DenseMTL | 7.7 | 8.6 | 8.8 | 6.7 | 8.2 | 8.0 |
| JTR | 8.5 | 6.5 | 8.0 | 7.1 | 6.7 | 7.3 |
| MTPSL | 8.6 | 6.3 | 7.7 | 5.4 | 7.3 | 7.0 |
| SwinMTL | 7.3 | 6.8 | 7.0 | 6.4 | 6.7 | 6.8 |
| InvPT++ | 6.6 | 6.2 | 6.6 | 5.8 | 6.3 | 6.3 |
| SDFormer | 6.1 | 5.4 | 7.4 | 5.2 | 6.5 | 6.1 |
| SDFormer++ | 5.8 | 5.5 | 7.2 | 4.9 | 6.4 | 6.0 |
SDFormer++针对5类典型交通参与者分别处在车辆的近(< 20 m)、中(20~50 m)、远(> 50 m)3种距离范围时的距离估计误差如表7所示. 可以看出,目标物距与测距误差间存在显著的空间相关性. 近距离目标的MRE均值为最小值4.0%;当目标处于中距离时,MRE均值为5.1%;远程目标MRE均值升至最大值10.1%. 这说明目标物距与估计误差之间呈显著的正相关趋势. 在自动驾驶场景中,近距离目标对行驶安全的影响通常比中、远距离目标更大,SDFormer++的检测结果符合现实应用中不同距离对算法准确性的要求.
表 7 不同距离范围下的距离估计误差
Tab.7
| 距离 | MRE/% | Avg/% | ||||
| 行人 | 骑行者 | 小车 | 公交车 | 卡车 | ||
| 近 | 3.3 | 4.7 | 5.0 | 4.1 | 3.0 | 4.0 |
| 中 | 5.2 | 5.3 | 4.5 | 5.0 | 5.4 | 5.1 |
| 远 | 11.7 | 10.2 | 9.5 | 9.3 | 9.8 | 10.1 |
SDFormer++在不同光照和天气条件下对典型交通参与者的实测距离和预测结果如图8所示,其中白色和黄色背景标签分别表示预测距离值和真实距离值. 可以看出,算法在白天、夜间的不同光线条件和晴天、小雨、雪后的天气环境下都保持了较好的预测精度,体现出良好的适应能力.
图 8

图 8 典型交通参与者在不同光照和天气条件下的距离预测效果
Fig.8 Distance prediction performance of typical traffic participants under different lighting and weather conditions
3. 结 语
本研究提出基于跨任务双向特征交互的交通感知算法SDFormer++,用于城市街道交通场景中语义分割和深度估计任务的协同感知,旨在通过增强任务之间的交互质量来提高多任务模型的整体性能. 在多任务编码过程中构建跨任务特征提取模块,以过滤跨任务交互过程中产生的冗余信息,获取更符合任务需求的特征,从而提高跨任务交互质量. 在任务解码阶段设计多任务特征交互模块,利用双向注意力机制和任务基础特征来增强特定任务特征,促进任务之间的信息交互. 此外,设计多尺度特征融合模块来融合不同层次的特征细节信息,确保输出的特征图既包含完整语义信息又具有浅层结构信息,并将其用于最终预测. 在Cityscapes数据集上的实验结果表明,相较于现有的主流多任务算法,SDFormer++在针对语义分割和深度估计2个视觉任务上展现出了更优越的综合性能. 未来考虑将双任务协同感知进一步拓展为包含3D目标检测的三任务协同感知,使算法能够感知更丰富的交通场景信息.
参考文献
基于优化DeepSort的前方车辆多目标跟踪
[J].
Multi-target tracking of vehicles based on optimized DeepSort
[J].
BASeg: boundary aware semantic segmentation for autonomous driving
[J].
Joint multiclass object detection and semantic segmentation for autonomous driving
[J].DOI:10.1109/ACCESS.2023.3266284
Deep learning-based stereopsis and monocular depth estimation techniques: a review
[J].DOI:10.3390/vehicles6010013 [本文引用: 1]
Synthetic data enhancement and network compression technology of monocular depth estimation for real-time autonomous driving system
[J].
Deep learning-based depth estimation methods from monocular image and videos: a comprehensive survey
[J].
Height aware understanding of remote sensing images based on cross-task interaction
[J].
Framework for deep learning-based language models using multi-task learning in natural language understanding: a systematic literature review and future directions
[J].DOI:10.1109/ACCESS.2022.3149798 [本文引用: 1]
Semantic and instance segmentation in coastal urban spatial perception: a multi-task learning framework with an attention mechanism
[J].DOI:10.3390/su16020833 [本文引用: 1]
EHSINet: efficient high-order spatial interaction multi-task network for adaptive autonomous driving perception
[J].DOI:10.1007/s11063-023-11379-x [本文引用: 1]
A multi-task network based on dual-neck structure for autonomous driving perception
[J].DOI:10.3390/s24051547 [本文引用: 1]
InvPT++: inverted pyramid multi-task Transformer for visual scene understanding
[J].DOI:10.1109/TPAMI.2024.3397031 [本文引用: 2]
联合语义分割和深度估计的交通场景感知算法
[J].
Traffic scene perception algorithm with joint semantic segmentation and depth estimation
[J].
CMX: cross-modal fusion for RGB-X semantic segmentation with Transformers
[J].DOI:10.1109/TITS.2023.3300537 [本文引用: 1]
DepthFormer: exploiting long-range correlation and local information for accurate monocular depth estimation
[J].DOI:10.1007/s11633-023-1458-0 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}