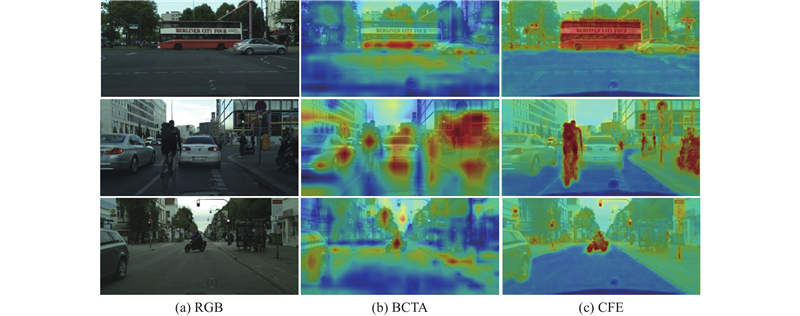
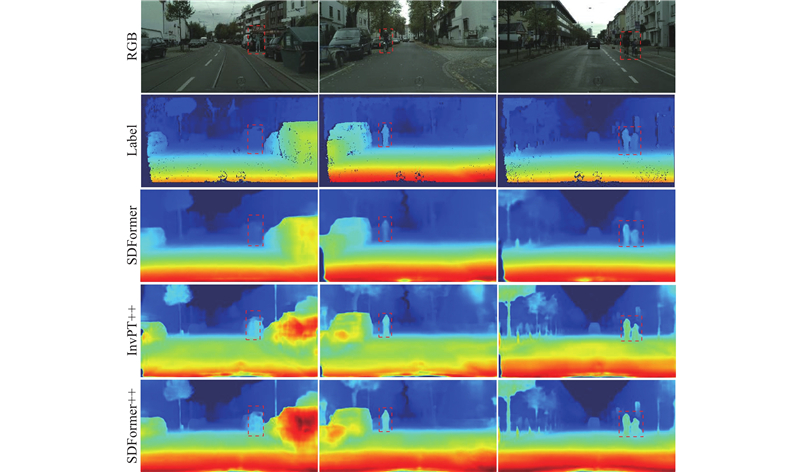
|
|
|
| Traffic scene perception algorithm based on cross-task bidirectional feature interaction |
Pengzhi LIN1( ),Ming’en ZHONG1,*(),Kang FAN2,Jiawei TAN2,Zhiqiang LIN1 ),Ming’en ZHONG1,*(),Kang FAN2,Jiawei TAN2,Zhiqiang LIN1 |
1. School of Mechanical and Automotive Engineering, Xiamen University of Technology, Xiamen 361024, China
2. School of Aerospace Engineering, Xiamen University, Xiamen 361005, China |
|
|
|
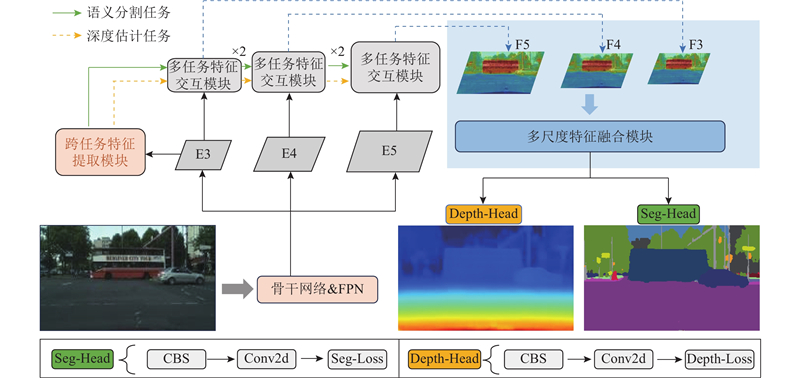
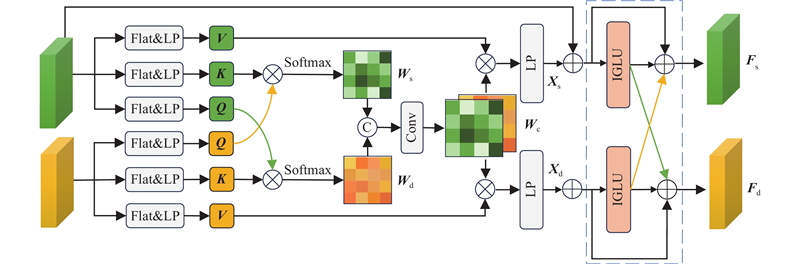
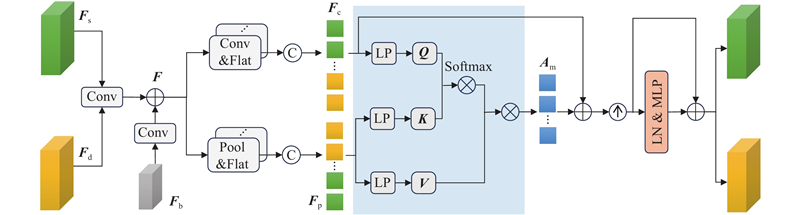
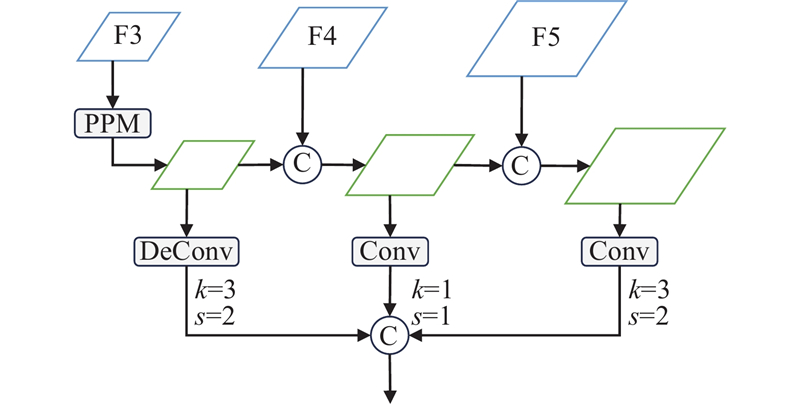
Abstract A traffic scene perception algorithm (SDFormer++) based on the principle of cross-task bidirectional feature interaction for autonomous driving in urban street scenarios was proposed by leveraging the explicit and implicit correlations between the semantic segmentation tasks and the depth estimation tasks to improve the overall performance of traffic scene perception algorithms. An interaction-gated linear unit was added into the cross-task feature extraction stage to form high-quality task-specific feature representations. A multi-task feature interaction module that used the bidirectional attention mechanism was constructed to enhance the initial task-specific features by utilizing the feature information of shared cross-domain tasks. A multi-scale feature fusion module was designed to integrate information at different levels to obtain fine high-resolution features. Experimental results on the Cityscapes dataset showed that the algorithm achieved a mean intersection over union (mIoU) of 82.4% for pixel segmentation, a root mean square error (RMSE) of 4.453 for depth estimation, an absolute relative error (ARE) of 0.130 for depth estimation, and an average distance estimation error of 6.0% for five typical traffic participants, all of which outperformed the existing mainstream multi-task algorithms such as InvPT++ and SDFormer.
|
|
Received: 05 December 2024
Published: 25 August 2025
|
|
|
| Fund: 福建省自然科学基金资助项目(2023J011439). |
|
Corresponding Authors:
Ming’en ZHONG
E-mail: 2477541661@qq.com;zhongmingen@xmut.edu.cn
|
基于跨任务双向特征交互的交通场景感知算法
为了提高交通场景感知算法的整体性能,利用语义分割任务和深度估计任务之间的显式和隐式相关性,依据跨任务双向特征交互原理,提出面向城市街道自动驾驶的感知算法SDFormer++. 在跨任务特征提取阶段加入交互门控线性单元,形成高质量的特定任务特征表达;构建多任务特征交互模块,应用双向注意力机制,借助跨域共享任务的特征信息来增强初始特定任务特征;设计多尺度特征融合模块,整合不同层次的信息,以获取精细的高分辨率特征. 在Cityscapes数据集上的实验结果表明,算法的像素分割平均交并比mIoU为82.4%,深度估计平均平方根误差RMSE和绝对相对误差ARE分别为4.453和0.130,针对5类典型交通参与者的平均距离估计误差为6.0%,均超越InvPT++、SDFormer等主流多任务算法.
关键词:
跨任务交互,
多任务学习,
交通环境感知,
语义分割,
深度估计
|
|
| [1] |
金立生, 华强, 郭柏苍, 等 基于优化DeepSort的前方车辆多目标跟踪[J]. 浙江大学学报: 工学版, 2021, 55 (6): 1056- 1064
JIN Lisheng, HUA Qiang, GUO Baicang, et al Multi-target tracking of vehicles based on optimized DeepSort[J]. Journal of Zhejiang University: Engineering Science, 2021, 55 (6): 1056- 1064
|
|
|
| [2] |
XIAO X, ZHAO Y, ZHANG F, et al BASeg: boundary aware semantic segmentation for autonomous driving[J]. Neural Networks, 2023, 157 (12): 460- 470
|
|
|
| [3] |
ABDIGAPPOROV S, MIRALIEV S, KAKANI V, et al Joint multiclass object detection and semantic segmentation for autonomous driving[J]. IEEE Access, 2023, 11: 37637- 37649
doi: 10.1109/ACCESS.2023.3266284
|
|
|
| [4] |
LV J, TONG H, PAN Q, et al. Importance-aware image segmentation-based semantic communication for autonomous driving [EB/OL]. (2024-01-06) [2024-12-05]. https://arxiv.org/pdf/2401.10153.
|
|
|
| [5] |
LAHIRI S, REN J, LIN X Deep learning-based stereopsis and monocular depth estimation techniques: a review[J]. Vehicles, 2024, 6 (1): 305- 351
doi: 10.3390/vehicles6010013
|
|
|
| [6] |
JUN W, YOO J, LEE S Synthetic data enhancement and network compression technology of monocular depth estimation for real-time autonomous driving system[J]. Sensors, 2024, 24 (13): 4205
doi: 10.3390/s24134205
|
|
|
| [7] |
RAJAPAKSHA U, SOHEL F, LAGA H, et al Deep learning-based depth estimation methods from monocular image and videos: a comprehensive survey[J]. ACM Computing Surveys, 2024, 56 (12): 1- 51
|
|
|
| [8] |
FENG Y, SUN X, DIAO W, et al Height aware understanding of remote sensing images based on cross-task interaction[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2023, 195 (4): 233- 249
|
|
|
| [9] |
SAMANT R M, BACHUTE M R, GITE S, et al Framework for deep learning-based language models using multi-task learning in natural language understanding: a systematic literature review and future directions[J]. IEEE Access, 2022, 10: 17078- 17097
doi: 10.1109/ACCESS.2022.3149798
|
|
|
| [10] |
ZHANG H, LIU H, KIM C Semantic and instance segmentation in coastal urban spatial perception: a multi-task learning framework with an attention mechanism[J]. Sustainability, 2024, 16 (2): 833
doi: 10.3390/su16020833
|
|
|
| [11] |
AGAND P, MAHDAVIAN M, SAVVA M, et al. LeTFuser: light-weight end-to-end Transformer-based sensor fusion for autonomous driving with multi-task learning [EB/OL]. (2023-10-19) [2024-12-05]. https://arxiv.org/pdf/2310.13135.
|
|
|
| [12] |
YAO J, LI Y, LIU C, et al EHSINet: efficient high-order spatial interaction multi-task network for adaptive autonomous driving perception[J]. Neural Processing Letters, 2023, 55 (8): 11353- 11370
doi: 10.1007/s11063-023-11379-x
|
|
|
| [13] |
TAN G, WANG C, LI Z, et al A multi-task network based on dual-neck structure for autonomous driving perception[J]. Sensors, 2024, 24 (5): 1547
doi: 10.3390/s24051547
|
|
|
| [14] |
WEI X, CHEN Y. Joint extraction of long-distance entity relation by aggregating local- and semantic-dependent features [J]. Wireless Communications and Mobile Computing, 2022: 3763940.
|
|
|
| [15] |
YE H, XU D InvPT++: inverted pyramid multi-task Transformer for visual scene understanding[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024, 46 (12): 7493- 7508
doi: 10.1109/TPAMI.2024.3397031
|
|
|
| [16] |
范康, 钟铭恩, 谭佳威, 等 联合语义分割和深度估计的交通场景感知算法[J]. 浙江大学学报: 工学版, 2024, 58 (4): 684- 695
FAN Kang, ZHONG Ming’en, TAN Jiawei, et al Traffic scene perception algorithm with joint semantic segmentation and depth estimation[J]. Journal of Zhejiang University: Engineering Science, 2024, 58 (4): 684- 695
|
|
|
| [17] |
CORDTS M, OMRAN M, RAMOS S, et al. The Cityscapes dataset for semantic urban scene understanding [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 3213–3223.
|
|
|
| [18] |
NISHI K, KIM J, LI W, et al. Joint-task regularization for partially labeled multi-task learning [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2024: 16152–16162.
|
|
|
| [19] |
LI W, LIU X, BILEN H. Learning multiple dense prediction tasks from partially annotated data [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 18857–18867.
|
|
|
| [20] |
LOPES I, VU T H, CHARETTE R. Cross-task attention mechanism for dense multi-task learning [C]// IEEE/CVF Winter Conference on Applications of Computer Vision. Waikoloa: IEEE, 2023: 2328–2337.
|
|
|
| [21] |
TAGHAVI P, LANGARI R, PANDEY G. SwinMTL: a shared architecture for simultaneous depth estimation and semantic segmentation from monocular camera images [EB/OL]. (2024-03-15) [2024-12-05]. https://arxiv.org/abs/2403.10662.
|
|
|
| [22] |
QASHQAI D, MOUSAVIAN E, SHOKOUHI S B, et al. CSFNet: a cosine similarity fusion network for real-time RGB-X semantic segmentation of driving scenes [EB/OL]. (2024-07-01) [2024-12-05]. https://arxiv.org/pdf/2407.01328.
|
|
|
| [23] |
JEEVAN P, VISWABATHAN K, SETHI A. WaveMix: a resource-efficient neural network for image analysis [EB/OL]. (2024-03-28) [2024-12-05]. https://arxiv.org/pdf/2205.143755.
|
|
|
| [24] |
GUO Z, BIAN L, HUANG X, et al. DSNet: a novel way to use atrous convolutions in semantic segmentation [EB/OL]. (2024-06-06) [2024-12-05]. https://arxiv.org/pdf/2406.03702.
|
|
|
| [25] |
ZHANG J, LIU H, YANG K, et al CMX: cross-modal fusion for RGB-X semantic segmentation with Transformers[J]. IEEE Transactions on Intelligent Transportation Systems, 2023, 24 (12): 14679- 14694
doi: 10.1109/TITS.2023.3300537
|
|
|
| [26] |
CAI H, LI J, HU M, et al. EfficientViT: multi-scale linear attention for high-resolution dense prediction [EB/OL]. (2024-02-06) [2024-12-05]. https://arxiv.org/pdf/2205.14756.
|
|
|
| [27] |
ZHOU K, BIAN J, XIE Q, et al. Manydepth2: motion-aware self-supervised multi-frame monocular depth estimation in dynamic scenes [EB/OL]. (2024-10-11) [2024-12-05]. https://arxiv.org/pdf/2312.15268v6.
|
|
|
| [28] |
LI Z, CHEN Z, LIU X, et al DepthFormer: exploiting long-range correlation and local information for accurate monocular depth estimation[J]. Machine Intelligence Research, 2023, 20 (6): 837- 854
doi: 10.1007/s11633-023-1458-0
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|