1. School of Computer and Communication Engineering, Zhengzhou University of Light Industry, Zhengzhou 450000, China 2. School of Computer Science and Technology, China University of Mining and Technology, Xuzhou 221116, China 3. Department of Computer Science and Engineering, Shanghai Jiao Tong University, Shanghai 200240, China
The semantic segmentation method Trans-nightSeg was proposed aiming at the issues of low brightness and lack of annotated semantic segmentation dataset in nighttime road scenes. The annotated daytime road scene semantic segmentation dataset Cityscapes was converted into low-light road scene images by TransCartoonGAN, which shared the same semantic segmentation annotation, thereby enriching the nighttime road scene dataset. The result together with the real road scene dataset was used as input of N-Refinenet. The N-Refinenet network introduced a low-light image adaptive enhancement network to improve the semantic segmentation performance of the nighttime road scene. Depth-separable convolution was used instead of normal convolution in order to reduce the computational complexity. The experimental results show that the mean intersection over union (mIoU) of the proposed algorithm on the Dark Zurich-test dataset and Nighttime Driving-test dataset reaches 56.0% and 56.6%, respectively, outperforming other semantic segmentation algorithms for nighttime road scene.
Canlin LI,Wenjiao ZHANG,Zhiwen SHAO,Lizhuang MA,Xinyue WANG. Semantic segmentation method on nighttime road scene based on Trans-nightSeg. Journal of ZheJiang University (Engineering Science), 2024, 58(2): 294-303.
Fig.2Comparison of original image with filtered image
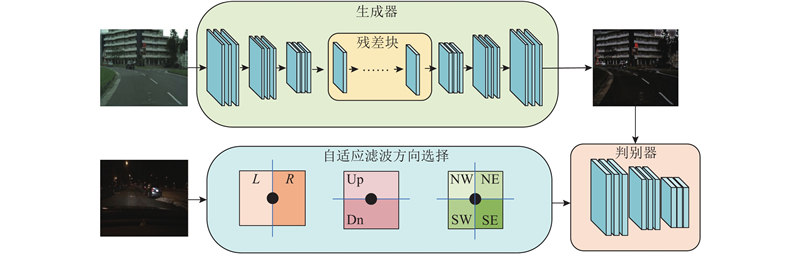
Fig.3Structure of TransCartoonGAN
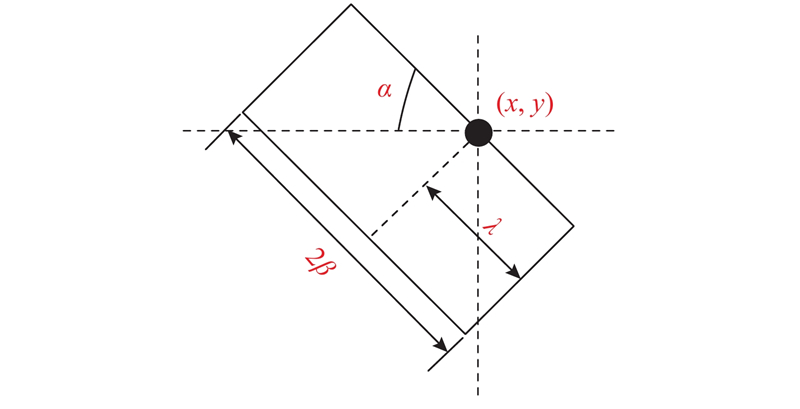
Fig.4Side window view in continuous condition
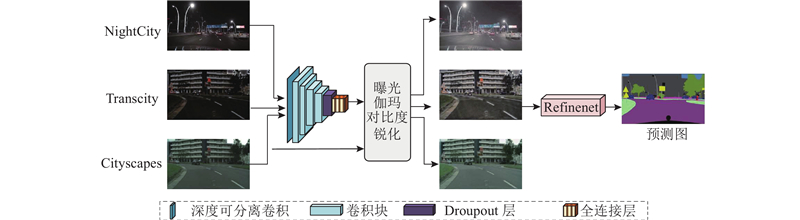
Fig.5Structure of N-Refinenet
Fig.6Effect of different network synthesis nighttime road scene image
方法
PSNR/dB
SSIM
FID
CycleGAN
13.62
0.62
86.46
CartoonGAN
15.44
0.61
114.45
TransCartoonGAN
17.36
0.75
77.83
Tab.1Comparison of similarity among methods
类别
IOU/%
DMAda
GCMA
MGCDA
DANNet
DANIA
本文方法
道路
75.5
81.7
80.3
88.6
90.8
93.1
人行道
29.1
46.9
49.3
53.4
59.7
69.4
建筑
48.6
58.8
66.2
69.8
73.7
82.2
墙体
21.3
22
7.8
34
39.9
52.1
栅栏
14.3
20
11
20
26.3
27.1
杆
34.3
41.2
41.4
25
36.7
57.0
交通灯
36.8
40.5
38.9
31.5
33.8
50.8
交通标志
29.9
41.6
39
35.9
32.4
56.2
植物
49.4
64.8
64.1
69.5
70.5
77.8
地形
13.8
31
18
32.2
32.1
32.3
天空
0.4
32.1
55.8
82.3
85.1
89.3
行人
43.3
53.5
52.1
44.2
43.0
55.0
骑手
50.2
47.5
53.5
43.7
42.2
50.4
汽车
69.4
72.5
74.7
54.1
72.8
81.9
卡车
18.4
39.2
66
22
13.4
0.0
公共汽车
0.0
0.0
0.0
0.1
0.0
17.9
火车
27.6
49.6
37.5
40.9
71.6
88.5
摩托车
34.9
30.7
29.1
36
48.9
46.4
自行车
11.9
21
22.7
24.1
23.9
36.3
mIoU/%
32.1
42
42.5
42.5
47.2
56.0
Tab.2Results of IoU for different methods on Dark Zurich-test
Fig.7Comparison of different nighttime semantic segmentation algorithms on Dark Zurich-test
方法
mIoU/%
方法
mIoU/%
DMAda
36.1
DANNet
47.7
GCMA
45.6
DANIA
48.4
MGCDA
49.4
本文方法
56.6
Tab.3Comparison of results on Night Driving-test
Fig.8Comparison of different nighttime semantic segmentation algorithms on Night Driving-test
序号
方法
cityscapes
CartoonGAN
NightCity
mIoU/%
A
baseline
√
—
—
26.5
B
—
√
√
—
30.9
C
—
√
√
√
31.8
D
N-RefineNet
√
√
√
41.5
E(Our)
Trans-nightSeg
√
√
√
56.0
Tab.4Ablation experiment results on Dark Zurich-test dataset
Fig.9Results plotted for parts on Dark Zurich-test dataset
Fig.10Results of Trans-nightSeg under extreme darkness conditions
[1]
CORDTS M, OMRAN M, RAMOS S, et al. The Cityscapes dataset for semantic urban scene understanding [C]// IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 3213-3223.
[2]
SAKARIDIS C, DAI D, GOOL L V. ACDC: the adverse conditions dataset with correspondences for semantic driving scene understanding [C]// IEEE International Conference on Computer Vision. Montreal: IEEE, 2021: 10765-10775.
[3]
GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al Generative adversarial networks[J]. Communications of the ACM, 2020, 63 (11): 139- 144
doi: 10.1145/3422622
[4]
REED S, AKATA Z, YAN X, et al. Generative adversarial text to image synthesis [C]// International Conference on Machine Learning. New York: PMLR, 2016: 1060-1069.
[5]
YEH R, CHEN C, LIM T Y, et al. Semantic image inpainting with perceptual and contextual losses [EB/OL]. [2016-07-26]. https://arxiv.org/abs/1607.07539.
[6]
LEDIG C, THEIS L, HUSZAR F, et al. Photo-realistic single image super-resolution using a generative adversarial network [C]// IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 4681-4690.
[7]
ISOLA P, ZHU J Y, ZHOU T, et al. Image-to-image translation with conditional adversarial networks [C]// IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 1125-1134.
[8]
KARACAN L, AKATA Z, ERDEM A, et al. Learning to generate images of outdoor scenes from attributes and semantic layouts [EB/OL]. [2016-12-01]. https://arxiv.org/abs/1612.00215.
[9]
ZHU J Y, PARK T, ISOLA P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks [C]// IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 2223-2232.
[10]
WANG H, CHEN Y, CAI Y, et al SFNet-N: an improved SFNet algorithm for semantic segmentation of low-light autonomous driving road scenes[J]. IEEE Transactions on Intelligent Transportation Systems, 2022, 23 (11): 21405- 21417
doi: 10.1109/TITS.2022.3177615
[11]
CHEN Y, LAI Y K, LIU Y J. Cartoongan: generative adversarial networks for photo cartoonization [C]// IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 9465-9474.
[12]
YIN H, GONG Y, QIU G. Side window filtering [C]// IEEE Conference on Computer Vision and Pattern Recognition. Los Angeles: IEEE, 2019: 8758-8766.
[13]
SHELHAMER E, LONG J, DARRELL T Fully convolutional networks for semantic segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39 (4): 640- 651
doi: 10.1109/TPAMI.2016.2572683
[14]
LIN G, MILAN A, SHEN C, et al. Refinenet: multi-path refinement networks for high-resolution semantic segmentation [C]// IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 1925-1934.
[15]
BIJELIC M, GRUBER T, RITTER W. Benchmarking image sensors under adverse weather conditions for autonomous driving [C]// IEEE Intelligent Vehicles Symposium. Changshu: IEEE, 2018: 1773-1779.
[16]
WULFMEIER M, BEWLEY A, POSNER I. Addressing appearance change in outdoor robotics with adversarial domain adaptation [C] // IEEE International Conference on Intelligent Robots and Systems. Vancouver: IEEE, 2017: 1551-1558.
[17]
DAI D, GOOL L V. Dark model adaptation: semantic image segmentation from daytime to nighttime [C]// IEEE International Conference on Intelligent Transportation Systems. Hawaii: IEEE, 2018: 3819-3824.
[18]
SAKARIDIS C, DAI D, GOOL L V. Guided curriculum model adaptation and uncertainty-aware evaluation for semantic nighttime image segmentation [C]// IEEE International Conference on Computer Vision. Seoul: IEEE, 2019: 7374-7383.
[19]
SAKARIDIS C, DAI D, GOOL L V Map-guided curriculum domain adaptation and uncertainty-aware evaluation for semantic nighttime image segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44 (6): 3139- 3153
doi: 10.1109/TPAMI.2020.3045882
[20]
XU Q, MA Y, WU J, et al. CDAda: a curriculum do-main adaptation for nighttime semantic segmentation[C]// IEEE International Conference on Computer Vision. Montreal: IEEE, 2021: 2962-2971.
[21]
ROMERA E, BERGASA L M, YANG K, et al. Bridging the day and night domain gap for semantic segmentation [C]// IEEE Intelligent Vehicles Symposium. Paris: IEEE, 2019: 1312-1318.
[22]
SUN L, WANG K, YANG K, et al. See clearer at night: towards robust nighttime semantic segmentation through day-night image conversion [C]// Artificial Intelligence and Machine Learning in Defense Applications. Bellingham: SPIE, 2019, 11169: 77-89.
[23]
WU X, WU Z, GUO H, et al. Dannet: a one-stage domain adaptation network for unsupervised nighttime semantic segmentation [C]// IEEE Conference on Computer Vision and Pattern Recognition. Nashville: IEEE, 2021: 15769-15778.
[24]
WU X, WU Z, JU L, et al A one-stage domain adaptation network with image alignment for unsupervised nighttime semantic segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023, 45 (1): 58- 72
doi: 10.1109/TPAMI.2021.3138829
[25]
HU Y, HU H, XU C, et al Exposure: a white-box photo post-processing framework[J]. ACM Transactions on Graphics, 2018, 37 (2): 26.1- 26.17
[26]
CHOLLET F. Xception: deep learning with depthwise separable convolutions [C]// IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 1251-1258.
[27]
HOWARD A G, ZHU M, CHEN B, et al. Mobilenets: efficient convolutional neural networks for mobile vis-ion applications [EB/OL]. [2017-04-17]. https://arxiv.org/abs/1704.04861.
[28]
TAN X, XU K, CAO Y, et al Nighttime scene parsing with a large real dataset[J]. IEEE Transactions on Image Processing, 2021, (30): 9085- 9098