|
|
|
| Efficient and adaptive semantic segmentation network based on Transformer |
Hai-bo ZHANG1,2( ),Lei CAI1,2,Jun-ping REN1,2,Ru-yan WANG1,Fu LIU3 ),Lei CAI1,2,Jun-ping REN1,2,Ru-yan WANG1,Fu LIU3 |
1. School of Communications and Information Engineering, Chongqing University of Posts and Telecommunications, Chongqing 400065, China
2. Chongqing Key Laboratory of Ubiquitous Sensing and Networking, Chongqing 400065, China
3. Chongqing Urban Lighting Center, Chongqing 400023, China |
|
|
|
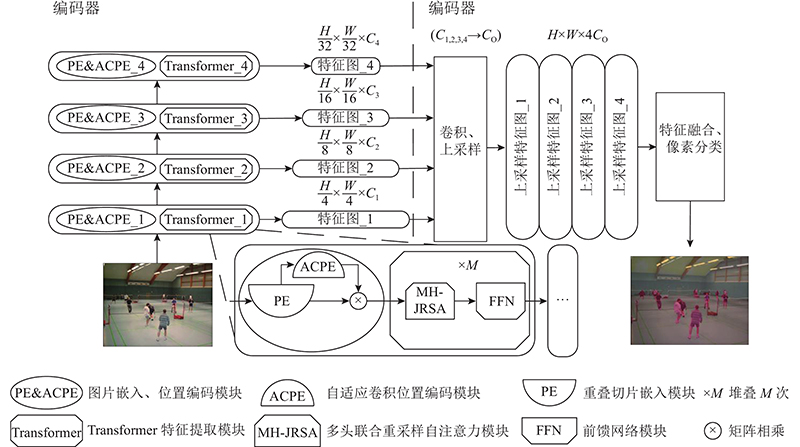
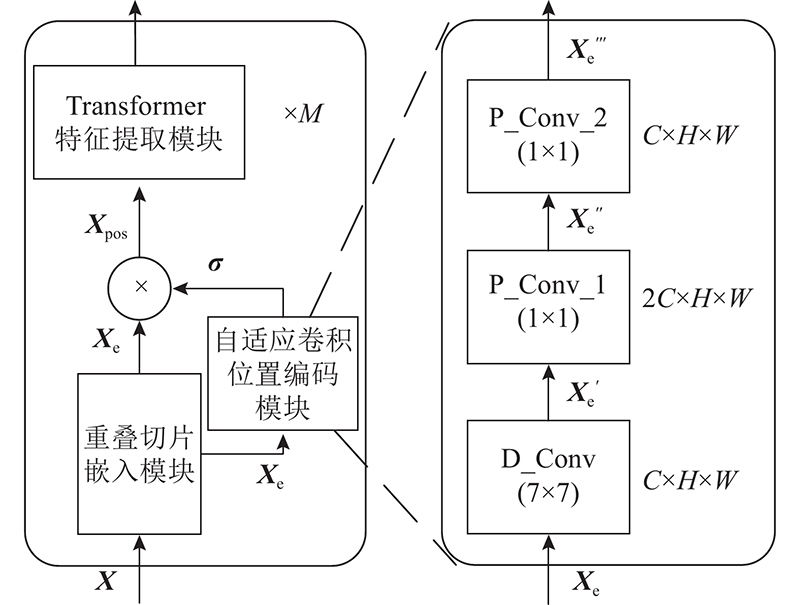
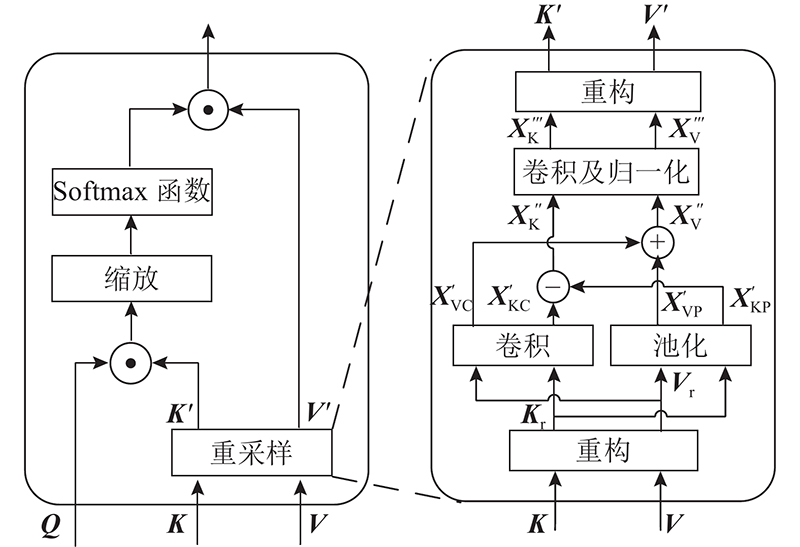
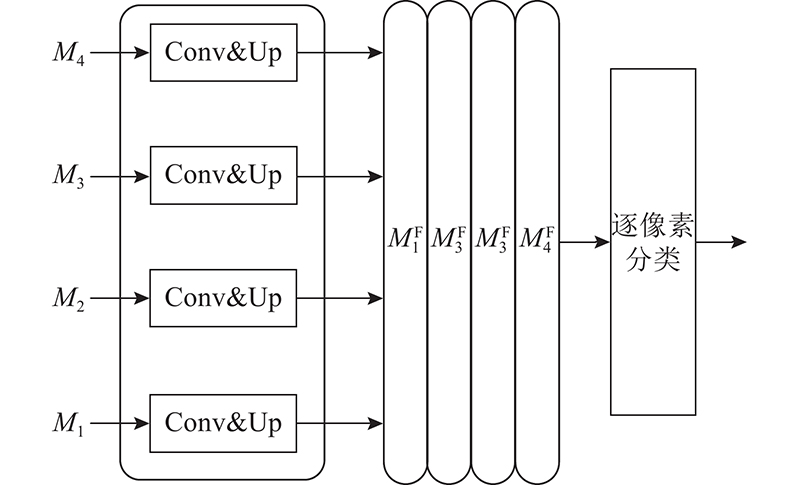
Abstract There are two problems at semantic segmentation network based on Transformer: significant drop of the segmentation accuracy due to the resolution variation and high computational complexity of self-attention. An adaptive convolutional positional encoding module was proposed, using a property of zero-padding convolution to retain positional information. Using the property that the dimensions of specific matrices can cancel each other in the self-attention computation. A joint resampling self-attention module to reduce the computational burden was proposed. A decoder was designed to fuse feature maps from different stages, resulting in the construction of an efficient segmentation network EA-Former which was capable of adapting to different resolution inputs. The mean intersection over union of EA-Former on the ADE20K was 51.0% and on the Cityscapes was 83.9%. Compared with the mainstream segmentation methods, the proposed network could achieve competitive accuracy with lower computational complexity, and the degradation of the segmentation performance caused by the variation of the input resolution was alleviated.
|
|
Received: 24 June 2022
Published: 30 June 2023
|
|
|
| Fund: 国家自然科学基金资助项目(62271094);长江学者和创新团队发展计划基金资助项目(IRT16R72);重庆市留创计划创新类资助项目(cx2020059) |
基于Transformer的高效自适应语义分割网络
基于Transformer的语义分割网络存在2个问题:分辨率变化引起的分割精度显著下降,自注意力机制计算复杂度过高。为此,利用零值填充的卷积可保留位置信息的特性,提出自适应卷积位置编码模块;利用自注意力计算中特定矩阵的维度可相互抵消的特性,提出降低自注意力计算量的联合重采样自注意力模块;设计用于融合不同阶段特征图的解码器,构造能够自适应不同分辨率输入的高效分割网络EA-Former. EA-Former在数据集ADE20K、Cityscapes上的最优平均交并比分别为51.0%、83.9%. 与主流分割算法相比,EA-Former能够以更低的计算复杂度得到具有竞争力的分割精度,由输入分辨率变化引起的分割性能下降问题得以缓解.
关键词:
语义分割,
Transformer,
自注意力,
位置编码,
神经网络
|
|
| [1] |
LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 3431-3440.
|
|
|
| [2] |
EVERINGHAM M, ESLAMI S M, VAN G L, et al The Pascal visual object classes challenge: a retrospective[J]. International Journal of Computer Vision, 2015, 111: 98- 136
doi: 10.1007/s11263-014-0733-5
|
|
|
| [3] |
ZHAO H, SHI J, QI X, et al. Pyramid scene parsing network [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 2881-2890.
|
|
|
| [4] |
CHEN L C, PAPANDREOU G, KOKKINOS I, et al. Semantic image segmentation with deep convolutional nets and fully connected CRFs [EB/OL]. (2016-06-07)[2022-04-25]. https://arxiv.org/pdf/1412.7062.pdf.
|
|
|
| [5] |
CHEN L C, PAPANDREOU G, KOKKINOS I, et al Deeplab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 40 (4): 834- 848
|
|
|
| [6] |
CHEN L C, PAPANDREOU G, SCHROFF F, et al. Rethinking atrous convolution for semantic image seg-mentation [EB/OL]. (2017-06-17)[2022-04-26]. https://arxiv.org/abs/1706.05587.
|
|
|
| [7] |
CHEN L C, ZHU Y, PAPANDREOU G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation [C]// Proceedings of the European Conference on Computer Vision. Munich: Springer, 2018: 801-818.
|
|
|
| [8] |
ZHAO H, ZHANG Y, LIU S, et al. PSANet: point-wise spatial attention network for scene parsing [C]// Proceedings of the European Conference on Computer Vision. Munich: Springer, 2018: 267-283.
|
|
|
| [9] |
HUANG Z, WANG X, HUANG L, et al. CCNet: criss-cross attention for semantic segmentation [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 603-612.
|
|
|
| [10] |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Advances in Neural Information Processing Systems. Long Beach: MIT Press, 2017: 5998-6008.
|
|
|
| [11] |
ZHENG S, LU J, ZHAO H, et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers [C]// Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. Nashville: IEEE, 2021: 6881-6890.
|
|
|
| [12] |
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: transformers for image recognition at scale [EB/OL]. (2020-10-22)[2022-04-27]. https://arxiv.org/pdf/2010.11929.pdf.
|
|
|
| [13] |
ZHOU B, ZHAO H, PUIG X, et al. Scene parsing through ADE20K dataset [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 633-641.
|
|
|
| [14] |
ISLAM M A, JIA S, BRUCE N D B. How much p-osition information do convolutional neural networks encode? [EB/OL]. (2020-01-22)[2022-04-28]. https://ar-xiv.org/pdf/2001.08248.pdf.
|
|
|
| [15] |
CHU X, TIAN Z, ZHANG B, et al. Conditional posi-tional encodings for vision transformers [EB/OL]. (2021-02-22)[2022-04-29]. https://arxiv.org/pdf/2102.10882.pdf.
|
|
|
| [16] |
YUAN K, GUO S, LIU Z, et al. Incorporating conv-olution designs into visual transformers [C]// Proceed-ings of the IEEE/CVF International Conference on Computer Vision. Montreal: IEEE, 2021: 579-588.
|
|
|
| [17] |
WU H, XIAO B, CODELLA N, et al. CvT: introducing convolutions to vision transformers [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal: IEEE, 2021: 22-31.
|
|
|
| [18] |
CORDTS M, OMRAN M, RAMOS S, et al. The Cityscapes dataset for semantic urban scene understanding [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 3213-3223.
|
|
|
| [19] |
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770-778.
|
|
|
| [20] |
XIE E, WANG W, YU Z, et al. SegFormer: simple and efficient design for semantic segmentation with transformers [C]// Advances in Neural Information Processing Systems. [S.l.]: MIT Press, 2021: 12077-12090.
|
|
|
| [21] |
ZHANG H, WU C, ZHANG Z, et al. ResNeSt: split-attention networks [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. New Orleans: IEEE, 2022: 2736-2746.
|
|
|
| [22] |
XIAO T, LIU Y, ZHOU B, et al. Unified perceptual parsing for scene understanding [C]// Proceedings of the European Conference on Computer Vision. Munich: Springer, 2018: 418-434.
|
|
|
| [23] |
TOUVRON H, CORD M, DOUZE M, et al. Training data-efficient image transformers & distillation through attention [C]// Proceedings of the 38th International Conference on Machine Learning. [S.l.]: PMLR, 2021: 10347-10357.
|
|
|
| [24] |
LIU Z, LIN Y, CAO Y, et al. Swin transformer: hierarchical vision transformer using shifted windows [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal: IEEE, 2021: 10012-10022.
|
|
|
| [25] |
LIU Z, MAO H, WU C Y, et al. A convnet for the 2020s [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 11976-11986.
|
|
|
| [26] |
YANG J, LI C, ZHANG P, et al. Focal self-attention for local-global interactions in vision transformers [EB/OL]. (2021-07-01)[2022-05-06]. https://arxiv.org/pdf/21-07.00641.pdf.
|
|
|
| [27] |
CHEN Z, ZHU Y, ZHAO C, et al. DPT: deformable patch-based transformer for visual recognition [C]// Proceedings of the 29th ACM International Conference on Multimedia. [S.l.]: ACM, 2021: 2899-2907.
|
|
|
| [28] |
STRUDEL R, GARCIA R, LAPTEV I, et al. Segmenter: transformer for semantic segmentation [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal: IEEE, 2021: 7262-7272.
|
|
|
| [29] |
KIRILLOV A, GIRSHICK R, HE K, et al. Panoptic feature pyramid networks [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 6399-6408.
|
|
|
| [30] |
WANG W, XIE E, LI X, et al PVT v2: Improved baselines with pyramid vision transformer[J]. Computational Visual Media, 2022, 8: 415- 424
doi: 10.1007/s41095-022-0274-8
|
|
|
| [31] |
GUO M H, LU C Z, LIU Z N, et al. Visual attenti-on network [EB/OL]. (2022-02-20)[2022-05-16]. https://arxiv.org/pdf/2202.09741.pdf.
|
|
|
| [32] |
JAIN J, SINGH A, ORLOV N, et al. Semask: seman-tically masked transformers for semantic segmentation[EB/OL]. (2021-12-23)[2022-05-23]. https://arxiv.org/pdf/2112.12782.pdf.
|
|
|
| [33] |
YUAN Y, CHEN X, WANG J. Object-contextual representations for semantic segmentation [C]// European Conference on Computer Vision. [S.l.]: Springer, 2020: 173-190.
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|