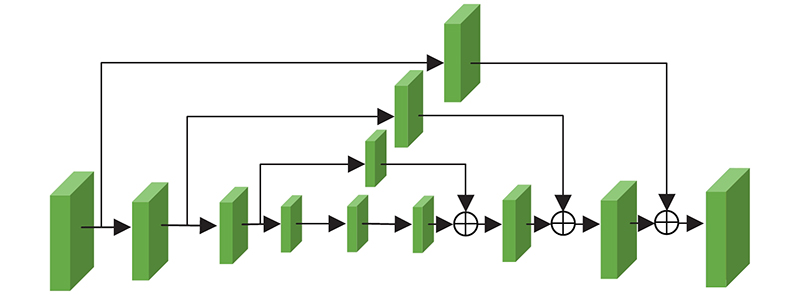
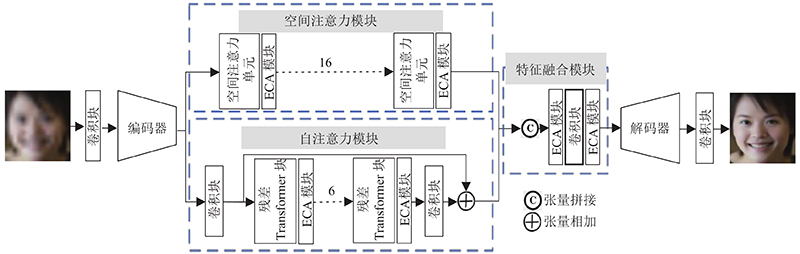
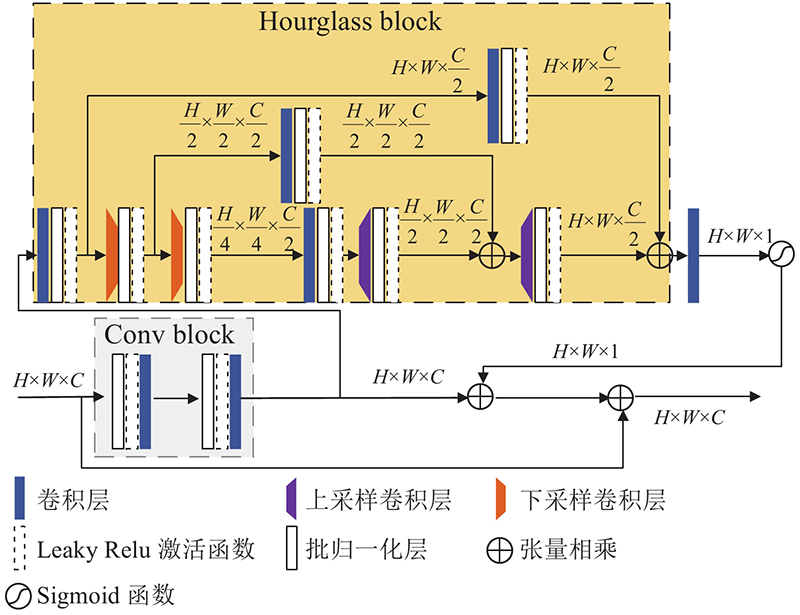
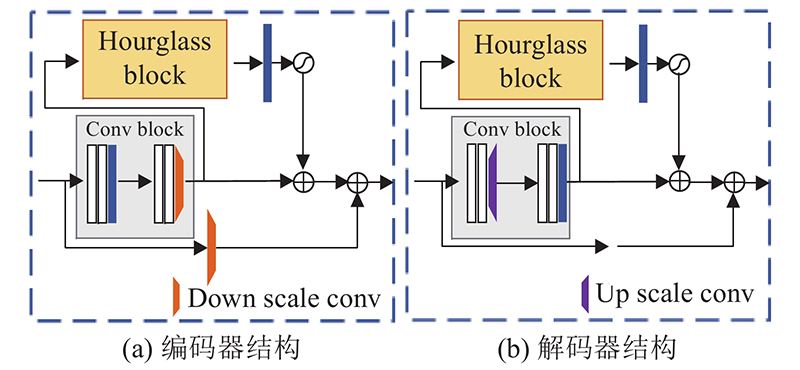
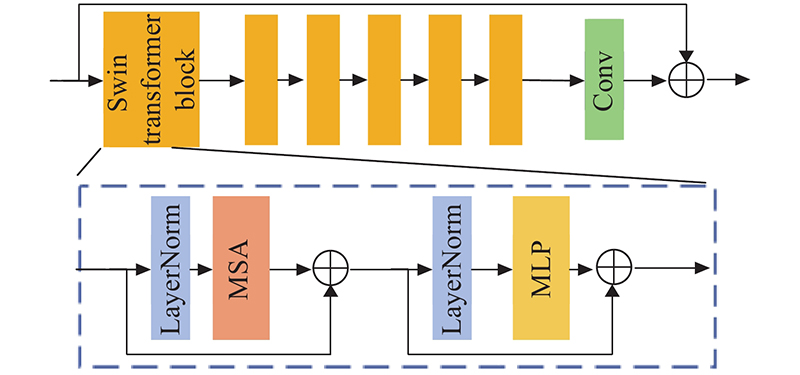
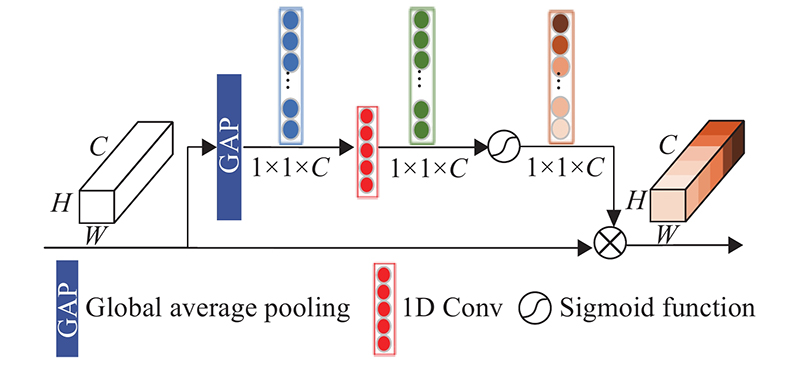
Most of existing structural image super-resolution reconstruction algorithms can only solve a specific single type of structural image super-resolution problem. A structural image super-resolution network based on improved Transformer (TransSRNet) was proposed. The network used the self-attention mechanism of Transformer mine a wide range of global information in spatial sequences. A spatial attention unit was built by using the hourglass block structure. The mapping relationship between the low-resolution space and the high-resolution space in the local area was concerned. The structured information in the image mapping process was extracted. The channel attention module was used to fuse the features of the self-attention module and the spatial attention module. The TransSRNet was evaluated on highly-structured CelebA, Helen, TCGA-ESCA and TCGA-COAD datasets. Results of evaluation showed that the TransSRNet model had a better overall performance compared with the super-resolution algorithms. With a upscale factor of 8, the PSNR of the face dataset and the medical image dataset could reach 28.726 and 26.392 dB respectively, and the SSIM could reach 0.844 and 0.881 respectively.
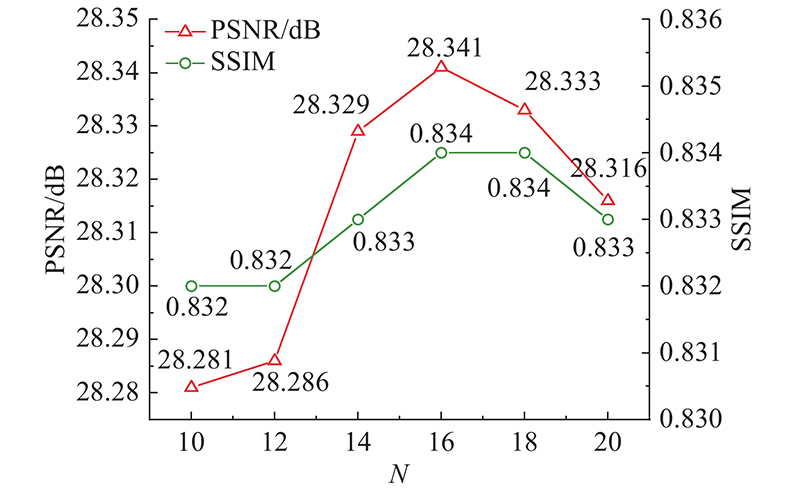
Fig.7Effects of different numbers of spatial attention units on PSNR and SSIM
NT
PSNR/dB
SSIM
2
28.479
0.838
4
28.535
0.839
6
28.568
0.839
8
28.343
0.834
Tab.1Effects of different numbers of residual Transformer blocks on PSNR and SSIM
实验
PSNR/dB
SSIM
1
28.341
0.834
2
26.089
0.763
3
28.568
0.839
Tab.2Effects of retaining different attention modules on PSNR and SSIM
损失函数
PSNR/dB
SSIM
lpix
28.568
0.839
lpix和lstyle联合
28.598
0.839
lpix、lstyle和lssim联合
28.632
0.841
Tab.3Effect of joint different loss functions on PSNR and SSIM
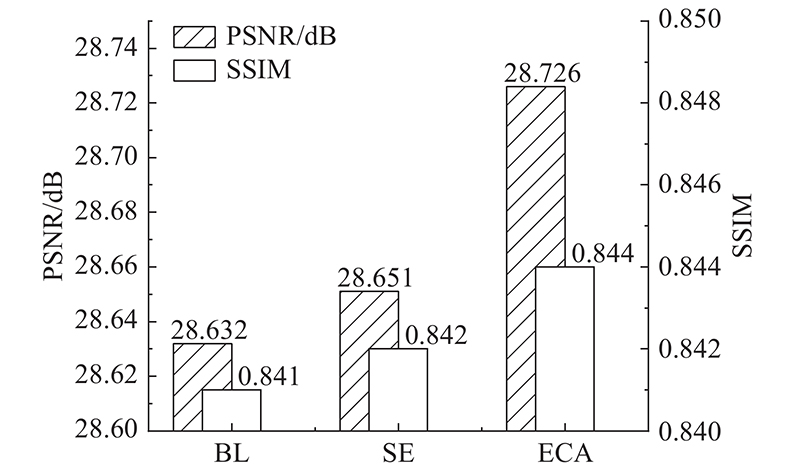
Fig.8Effects of SE module and ECA module on PSNR and SSIM
放大因子
Bicubic
SRGAN
FSRNet
SPSR
EIPNet
TransSRNet(Our)
PSNR/dB, SSIM
PSNR/dB, SSIM
PSNR/dB, SSIM
PSNR/dB, SSIM
PSNR/dB, SSIM
PSNR/dB, SSIM
2
34.942, 0.955
35.831, 0.962
37.699, 0.971
37.729, 0.966
37.899, 0.972
38.930, 0.975
3
31.130, 0.901
32.400, 0.920
33.526, 0.935
33.268, 0.921
33.942, 0.940
35.227, 0.949
4
28.999, 0.850
30.034, 0.871
32.338, 0.916
30.580, 0.872
32.569, 0.919
33.215, 0.925
8
24.531, 0.698
25.278, 0.717
26.934, 0.795
25.579, 0.722
26.898, 0.791
28.726, 0.844
Tab.4Comparison results of different methods on Helen dataset
Fig.9Comparison of subjective effects with upscalefactors of 2, 3, 4 and 8 on Helen dataset
放大因子
Bicubic
SRGAN
RNAN
SPSR
NLSN
TransSRNet(Our)
PSNR/dB, SSIM
PSNR/dB, SSIM
PSNR/dB, SSIM
PSNR/dB, SSIM
PSNR/dB, SSIM
PSNR/dB, SSIM
2
30.111, 0.937
31.838, 0.942
36.223, 0.976
34.917, 0.969
36.514, 0.977
36.378, 0.976
3
27.310, 0.889
28.635, 0.909
31.764, 0.951
30.648, 0.941
31.840, 0.952
32.829, 0.956
4
25.751, 0.852
26.357, 0.875
29.467, 0.928
28.092, 0.914
29.552, 0.929
30.449, 0.936
8
22.872, 0.774
23.005, 0.802
24.546, 0.838
23.677, 0.828
24.597, 0.840
26.392, 0.881
Tab.5Comparison results of different methods on medical CT dataset
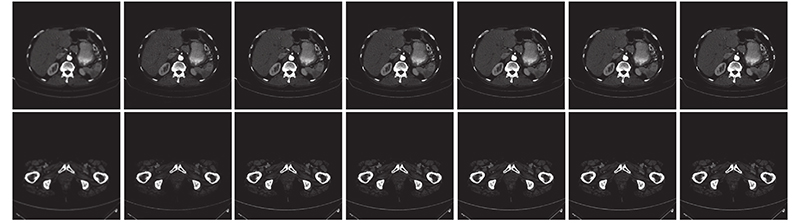
Fig.10Comparison of subjective effects with upscale factor of 2 on medical CT dataset
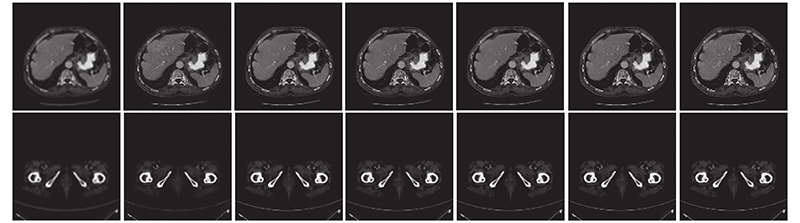
Fig.11Comparison of subjective effects with upscale factor of 3 on medical CT dataset
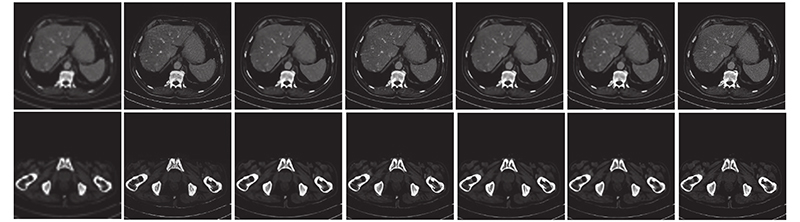
Fig.12Comparison of subjective effects with upscale factor 4 on medical CT dataset
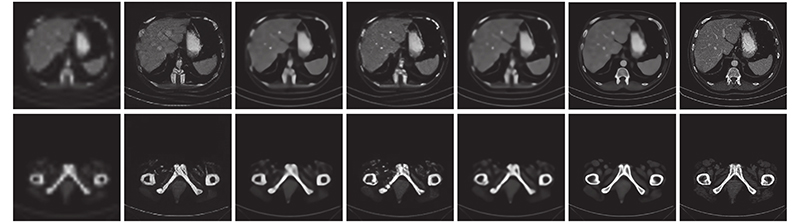
Fig.13Comparison of subjective effects with upscale factor 8 on medical CT dataset
[1]
DONG C, LOY C C, HE K, et al. Learning a deep convolutional network for image super-resolution [C]// Proceedings of the European Conference on Computer Vision. Columbus: CVPR, 2014: 184-199.
[2]
LEDIG C, THEIS L, HUSZAR F, et al. Photo-realistic single image super-resolution using a generative adversarial network [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Honolulu: CVPR, 2017: 105-114.
[3]
MA C, RAO Y, CHENG Y, et al. Structure-preserving super-resolution with gradient guidance [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: CVPR, 2020: 7766-7775.
[4]
ZHANG Y, LI K, LI K, et al. Residual non-local attention networks for image restoration [EB/OL]. [2019-03-24]. https://arxiv.org/pdf/1903.10082.pdf.
ZHOU E, FAN H, CAO Z, et al. Learning face hallucination in the wild [C]// Proceeding of the Association or the Advancement of Artificial Intelligence. San Francisco: AAAI, 2015: 3871-3877.
[7]
LIU H, HAN Z, GUO J, et al. A noise robust face hallucination framework via cascaded model of deep convolutional networks and manifold learning [C]// Proceeding of the IEEE International Conference on Multimedia and Expo. Santiago: ICME, 2018: 1-6.
[8]
LIU S, XIONG C Y, SHI X D, et al Progressive face super-resolution with cascaded recurrent convolutional network[J]. Neurocomputing, 2021, 449 (8): 357- 367
[9]
CHEN Y, TAI Y, LIU X, et al. FSRNet: end-to-end learning face super-resolution with facial priors [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: CVPR, 2018: 2492-2501.
[10]
ZHANG Y, WU Y, CHEN L. MSFSR: a multi-stage face super-resolution with accurate facial representation via enhanced facial boundaries [C]// Proceeding of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Seattle: CVPR, 2020: 2120-2129.
[11]
YIN Y, ROBINSON J P, ZHANG Y, et al. Joint super-resolution and alignment of tiny faces [C]// Proceeding of the Association for the Advancement of Artificial Intelligence. Honolulu: AAAI, 2019: 12693–12700.
[12]
KIM J, LI G, YUN I, et al Edge and identity preserving network for face super-resolution[J]. Neurocomputing, 2021, 446 (7): 11- 22
[13]
刘朋伟, 高媛, 秦品乐, 等 基于多感受野的生成对抗网络医学MRI影像超分辨率重建[J]. 计算机应用, 2022, 42 (3): 938- 945 LIU Peng-wei, GAO Yuan, QIN Pin-le, et al Medical MRI image super-resolution reconstruction based on multi-receptive field generative adversarial network[J]. Journal of Computer Applications, 2022, 42 (3): 938- 945
[14]
NEWELL A, YANG K, DENG J. Stacked hourglass networks for human pose estimations [C]// Proceedings of the European Conference on Computer Vision. Amsterdam: ECCV, 2016: 483-499.
[15]
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [EB/OL]. [2017-06-12]. https://arxiv.org/pdf/1706.03762.pdf.
[16]
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: transformers for image recognition at scale [EB/OL]. [2020-10-22]. https://arxiv.org/pdf/2010.11929.pdf.
[17]
LIU Z, LIN Y, CAO Y, et al. Swin transformer: hierarchical vision transformer using shifted windows [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Montreal: ICCV, 2021: 9992-10002.
[18]
HU J, SHEN L, SUN G. Squeeze-and-excitation networks [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: CVPR, 2018: 7132-7141.
[19]
WANG Q, WU B, ZHU P, et al. ECA-Net: efficient channel attention for deep convolutional neural networks [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: CVPR, 2020: 11531-11539.
[20]
SHAW P, USZKOREIT J, VASWANI A. Self-attention with relative position representations [EB/OL]. [2018-03-06]. https://arxiv.org/pdf/1803.02155.pdf.
[21]
RAFFEL C, SHAZEER N, ROBERTS A, et al. Exploring the limits of transfer learning with a unified text-to-text transformer [EB/OL]. [2019-10-23]. https://arxiv.org/ pdf/1910.10683.pdf.
[22]
GATYS L A, ECKER A S, BETHGE M. Image style transfer using convolutional neural networks [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Las Vegas: CVPR, 2016: 2414-2423.
[23]
LIU Z, LUO P, WANG X, et al. Deep learning face attributes in the wild [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Santiago: ICCV, 2015: 3730-3738.
[24]
LE V, BRANDT J, LIN Z, et al. Interactive facial feature localization [C]// Proceedings of the European Conference on Computer Vision. Florence: ECCV, 2012: 679-692.
[25]
ZHANG K, ZHANG Z, LI Z, et al Joint face detection and alignment using multitask cascaded convolutional networks[J]. IEEE Signal Processing Letters, 2016, 23 (10): 1499- 1503
doi: 10.1109/LSP.2016.2603342