|
|
|
| Face reconstruction from voice based on age-supervised learning and face prior information |
Li HE( ),Shan-min PANG*() ),Shan-min PANG*() |
| School of Software Engineering, Xi’an Jiaotong University, Xi’an 710049, China |
|
|
|
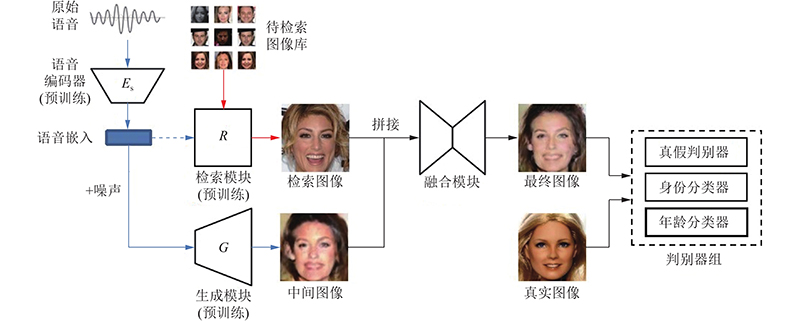
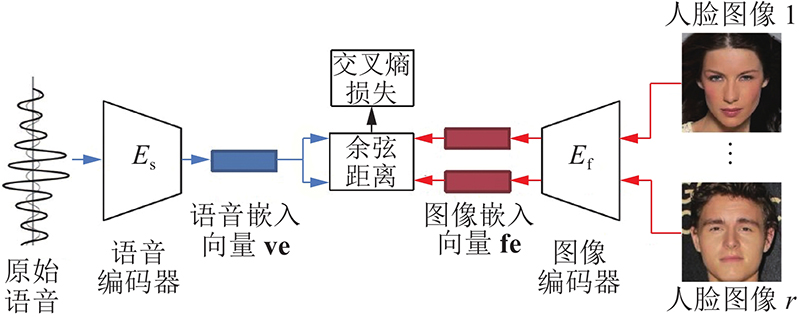
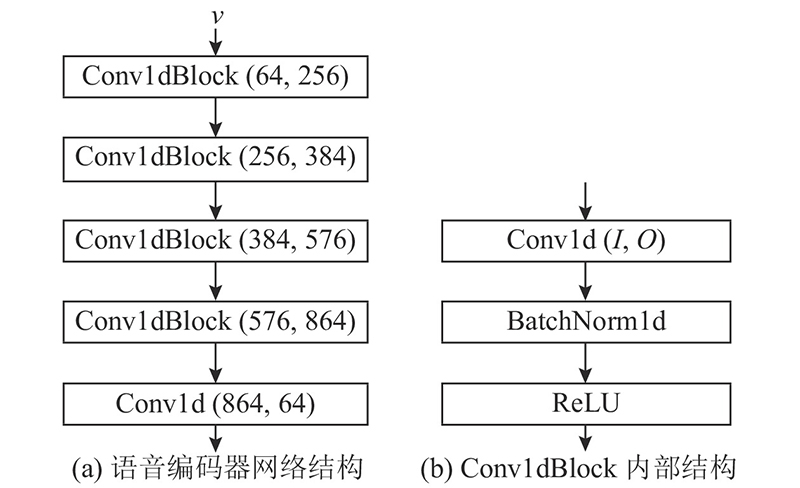
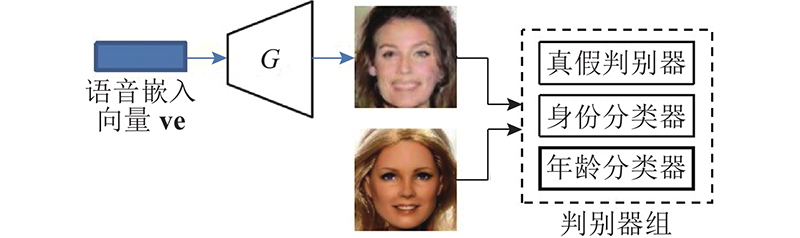
Abstract Previous voice-face image reconstruction methods lack effective supervised constraints from different dimensions and face prior information, which may lead to a low similarity between reconstructed and real images. Thus, a face reconstruction method based on age-supervised learning and face prior information was proposed. Age related data were provided for the present dataset through a pre-trained age estimation model, which strengthened age supervision. For given voice samples, voice-face cross-modal identity matching was applied to retrieve images similar to real speakers, where the retrieved results were considered as face prior information. A joint loss function that consists of the cross entropy loss and the adversarial loss was defined to improve age coincidence, low-frequency content and high-frequency textures of the reconstructed images. Results of face retrieval experiments conducted with dataset Voxceleb 1 showed that the proposed method can improve the similarity between generated and ground truth images. The images generated by the proposed method have better subjective and objective evaluation results than that of the compared methods.
|
|
Received: 19 November 2021
Published: 31 May 2022
|
|
|
| Fund: 国家自然科学基金资助项目(61972312);陕西省重点研发计划一般工业资助项目(2020GY-002) |
|
Corresponding Authors:
Shan-min PANG
E-mail: heliwushi@qq.com;pangsm@xjtu.edu.cn
|
结合年龄监督和人脸先验的语音-人脸图像重建
针对语音-人脸图像重建方法缺乏来自不同维度的监督约束及未利用人脸先验信息,导致生成图像和真实图像相似度不高的问题,提出结合年龄监督和人脸先验信息的语音-人脸图像重建方法. 通过预训练的年龄评估模型为当前数据集扩充年龄数据,弥补来自年龄监督信息的缺乏. 通过语音-人脸图像跨模态身份匹配方法,为给定语音检索接近真实人脸的面部图像,将得到的图像作为人脸先验信息使用. 该方法通过定义结合交叉熵损失和对抗损失的联合损失函数,从年龄感、低频内容和局部纹理等方面均衡提升重建图像质量. 基于数据集Voxceleb 1,通过人脸检索实验的方式进行测试,与当前主流方法进行比较和分析. 结果表明,该方法能有效提升生成图像与真实图像的相似度,所生成的图像具有更好的主客观评价结果.
关键词:
深度学习,
图像重建,
卷积神经网络,
生成对抗网络,
人脸先验信息
|
|
| [1] |
孙颖, 胡艳香, 张雪英, 等 面向情感语音识别的情感维度PAD预测[J]. 浙江大学学报:工学版, 2019, 53 (10): 2041- 2048
SUN Ying, HU Yan-xiang, ZHANG Xue-ying, et al Prediction of emotional dimensions PAD for emotional speech recognition[J]. Journal of Zhejiang University: Engineering Science, 2019, 53 (10): 2041- 2048
|
|
|
| [2] |
SINGH R, RAJ B, GENCAGA D. Forensic anthropometry from voice: an articulatory-phonetic approach [C]// 2016 39th International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO). Opatija: IEEE, 2016: 1375-1380.
|
|
|
| [3] |
李江, 赵雅琼, 包晔华 基于混沌和替代数据法的中风病人声音分析[J]. 浙江大学学报:工学版, 2015, 49 (1): 36- 41
LI Jiang, ZHAO Ya-qiong, BAO Ye-hua Voice processing technique for patients with stroke based on chao theory and surrogate data analysis[J]. Journal of Zhejiang University: Engineering Science, 2015, 49 (1): 36- 41
|
|
|
| [4] |
BELIN P, FECTEAU S, BEDARD C Thinking the voice: neural correlates of voice perception[J]. Trends in Cognitive Sciences, 2004, 8 (3): 129- 135
|
|
|
| [5] |
KAMACHI M, HILL H, LANDER K, et al Putting the face to the voice’: matching identity across modality[J]. Current Biology, 2003, 13 (19): 1709- 1714
|
|
|
| [6] |
GOODFELLOW I J, POUGET A J, MIRZA M, et al Generative adversarial networks[J]. Advances in Neural Information Processing Systems, 2014, 3: 2672- 2680
|
|
|
| [7] |
MIRZA M, OSINDERO S. Conditional generative adversarial nets [EB/OL]. (2014-11-06). https://arxiv.org/pdf/1411.1784.pdf.
|
|
|
| [8] |
YU Y, GONG Z, ZHONG P, et al. Unsupervised representation learning with deep convolutional neural network for remote sensing images [C]// International Conference on Image and Graphics. Shanghai: Springer, 2017: 97-108.
|
|
|
| [9] |
ISOLA P, ZHU J Y, ZHOU T, et al. Image-to-image translation with conditional adversarial networks [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Hawaii: IEEE, 2017: 1125-1134.
|
|
|
| [10] |
ZHU J Y, PARK T, ISOLA P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks [C]// Proceedings of the IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 2223-2232.
|
|
|
| [11] |
王凯, 岳泊暄, 傅骏伟, 等 基于生成对抗网络的图像恢复与SLAM容错研究[J]. 浙江大学学报: 工学版, 2019, 53 (1): 115- 125
WANG Kai, YUE Bo-xuan, FU Jun-wei, et al Image restoration and fault tolerance of stereo SLAM based on generative adversarial net[J]. Journal of Zhejiang University: Engineering Science, 2019, 53 (1): 115- 125
|
|
|
| [12] |
段然, 周登文, 赵丽娟, 等 基于多尺度特征映射网络的图像超分辨率重建[J]. 浙江大学学报: 工学版, 2019, 53 (7): 1331- 1339
DUAN Ran, ZHOU Deng-wen, ZHAO Li-juan, et al Classification and detection method of blood cells images based on multi-scale conditional generative adversarial network[J]. Journal of Zhejiang University: Engineering Science, 2019, 53 (7): 1331- 1339
|
|
|
| [13] |
OH T H, DEKEL T, KIM C, et al. Speech2face: learning the face behind a voice [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 7539-7548.
|
|
|
| [14] |
DUARTE A C, ROLDAN F, TUBAU M, et al. WAV2PIX: speech-conditioned face generation using generative adversarial networks [C]// International Conference on Acoustics, Speech, and Signal Processing. Brighton: IEEE, 2019: 8633-8637.
|
|
|
| [15] |
WEN Y, RAJ B, SINGH R Face reconstruction from voice using generative adversarial networks[J]. Advances in Neural Information Processing Systems, 2019, 32: 5265- 5274
|
|
|
| [16] |
ODENA A, OLAH C, SHLENS J. Conditional image synthesis with auxiliary classifier gans [C]// International Conference on Machine Learning. Sydney: ICML, 2017: 2642-2651.
|
|
|
| [17] |
CHOI H S, PARK C, LEE K. From inference to generation: end-to-end fully self-supervised generation of human face from speech [C]// International Conference on Learning Representations. Addis Ababaa: ICLR, 2020.
|
|
|
| [18] |
RONNEBRGER O, FISCHER P, BROX T. U-Net: convolutional networks for biomedical image segmentation [C]// International Conference on Medical Image Computing and Computer Assisted Intervention. Munich: Springer, 2015: 234–241.
|
|
|
| [19] |
LI C, WAND M. Precomputed real-time texture synthesis with markovian generative adversarial networks [C]// European Conference on Computer Vision. Amsterdam: Springer, 2016: 702-716.
|
|
|
| [20] |
CHEN Y, TAI Y, LIU X, et al. FSRNet: end-to-end learning face super-resolution with facial priors [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake: IEEE, 2018: 2492-2501.
|
|
|
| [21] |
ARANDJELOVIC R, ZISSERMAN A. Look, listen and learn [C]// Proceedings of the IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 609-617.
|
|
|
| [22] |
CASTREJON L, AYTAR Y, VONDRICK C, et al. Learning aligned cross-modal representations from weakly aligned data [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 2940-2949.
|
|
|
| [23] |
YANG D W, ISMAIL M A, LIU W Y, et al. Disjoint mapping network for crossmodal matching of voices and faces [C]// International Conference on Learning Representations. Addis Ababaa: ICLR, 2018.
|
|
|
| [24] |
张晓冰, 龚海刚, 杨帆, 等 基于端到端句子级别的中文唇语识别研究[J]. 软件学报, 2020, 31 (6): 1747- 1760
ZHANG Xiao-bing, GONG Hai-gang, YANG Fan, et al Chinese sentence-level lip reading based on end-to-end model[J]. Journal of Software, 2020, 31 (6): 1747- 1760
|
|
|
| [25] |
HOOVER K, CHAUDHURI S, PANTOFARU C, et al. Putting a face to the voice: fusing audio and visual signals across a video to determine speakers [EB/OL]. (2017-5-31) [2021-10-24]. https://arxiv.org/pdf/1706.00079.pdf.
|
|
|
| [26] |
唐郅, 侯进 基于深度神经网络的语音驱动发音器官的运动合成[J]. 自动化学报, 2016, 42 (6): 923- 930
TANG Zhi, HOU Jin Speech driven articulator motion synthesis with deep neural networks[J]. Acta Automatica Sinica, 2016, 42 (6): 923- 930
|
|
|
| [27] |
SUN Y, ZHOU H, LIU Z, et al. Speech2Talking-Face: inferring and driving a face with synchronized audio-visual representation [C]// International Joint Conference on Artificial Intelligence. Montreal: IJCAI, 2021: 1018-1024.
|
|
|
| [28] |
ZHOU H, SUN Y, WU W, et al. Pose-controllable talking face generation by implicitly modularized audio-visual representation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Virtual reality: IEEE, 2021: 4176-4186.
|
|
|
| [29] |
NAGRANI A, ALBANIE S, ZISSERMAN A. Seeing voices and hearing faces: cross-modal biometric matching [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 8427-8436.
|
|
|
| [30] |
OMKAR M P, ANDREA V, ANDREW Z, et al. Deep face recognition [C]// British Machine Vision Conference. Swansea: BMVC, 2015: 1, 6.
|
|
|
| [31] |
NAGRANI A, ALBANIE S, ZISSERMAN A. Seeing voices and hearing faces: cross-modal biometric matching [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake: BMVC, 2018: 8427-8436.
|
|
|
| [32] |
ROTHE R, TIMOFTE R, VAN GOOL L Deep expectation of real and apparent age from a single image without facial landmarks[J]. International Journal of Computer Vision, 2018, 126 (2): 144- 157
|
|
|
| [33] |
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770-778.
|
|
|
| [34] |
KING D E Dlib-ml: a machine learning toolkit[J]. The Journal of Machine Learning Research, 2009, 10: 1755- 1758
|
|
|
| [35] |
EPHRAT A, MOSSERI I, LANG O, et al Looking to listen at the cocktail party: a speaker-independent audio-visual model for speech separation[J]. ACM Transactions on Graphics (TOG), 2018, 37 (4): 1- 11
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|