|
|
|
| Efficient approximate query processing framework based on conditional generative model |
Wen-chao BAI( ),Xi-xian HAN*(),Jin-bao WANG ),Xi-xian HAN*(),Jin-bao WANG |
| College of Computer Science and Technology, Harbin Institute of Technology, Weihai 264201, China |
|
|
|
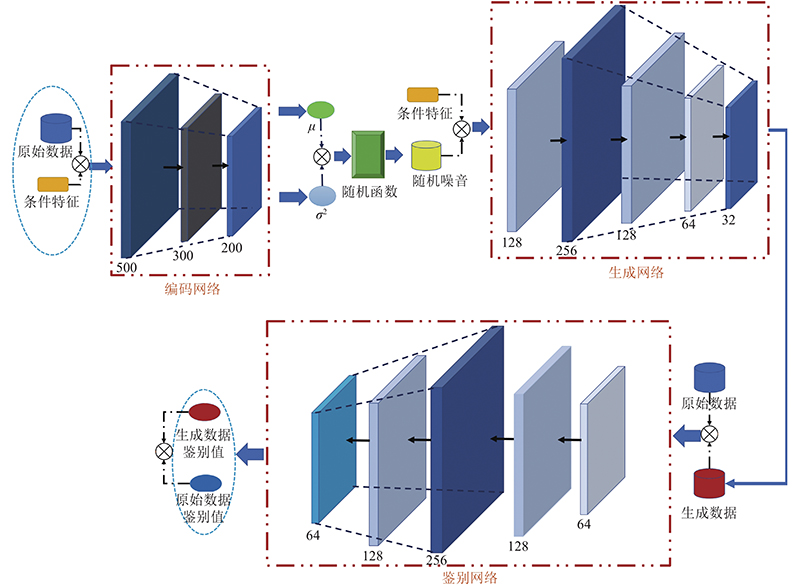
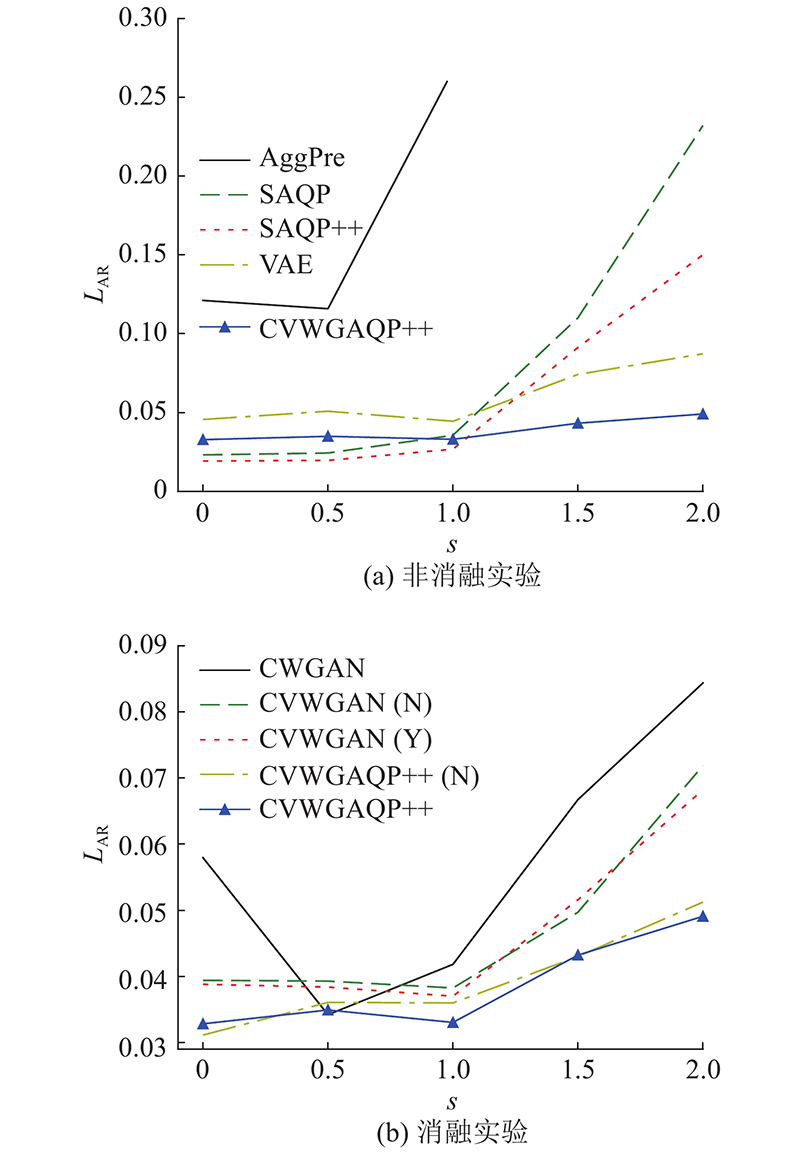
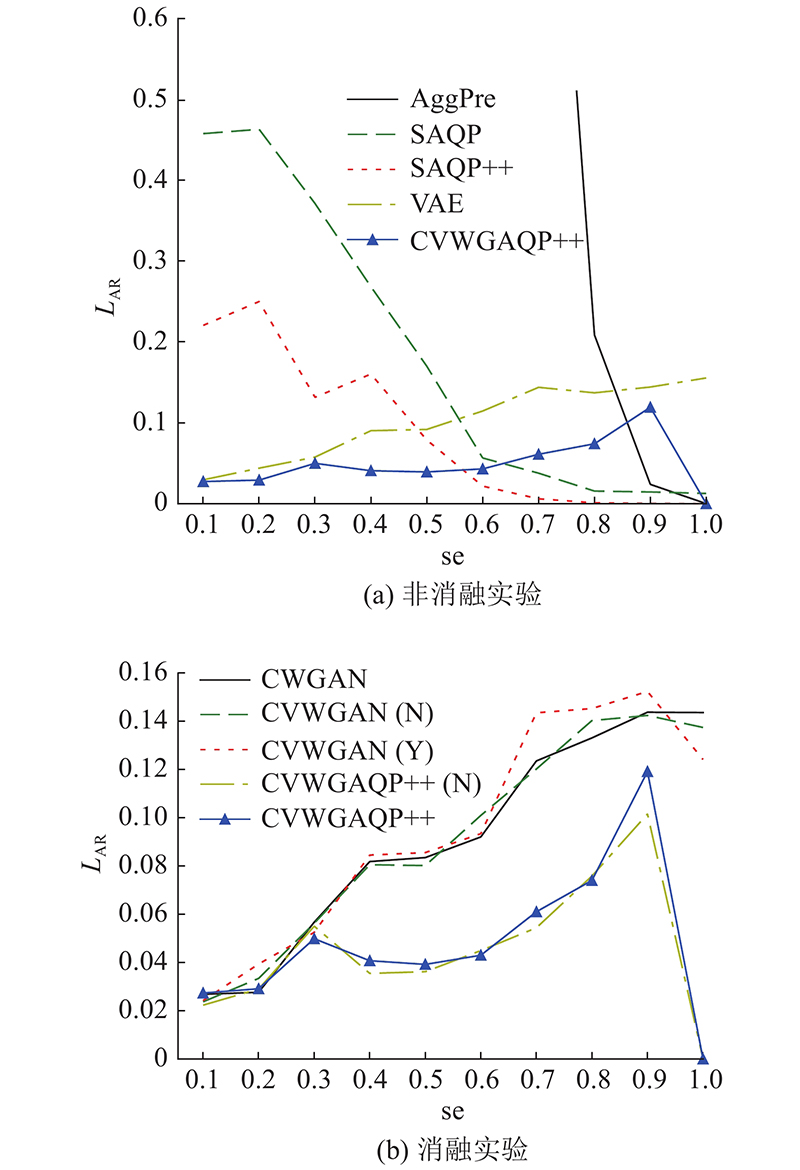
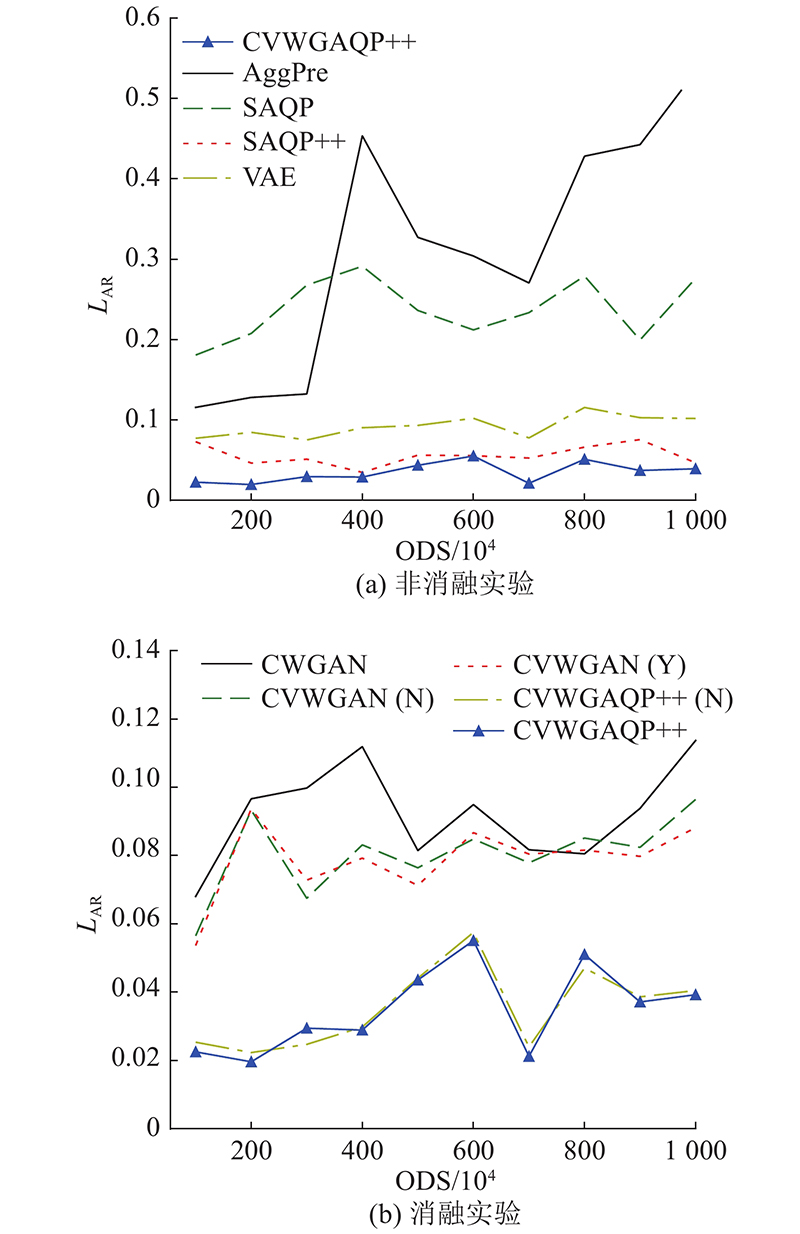
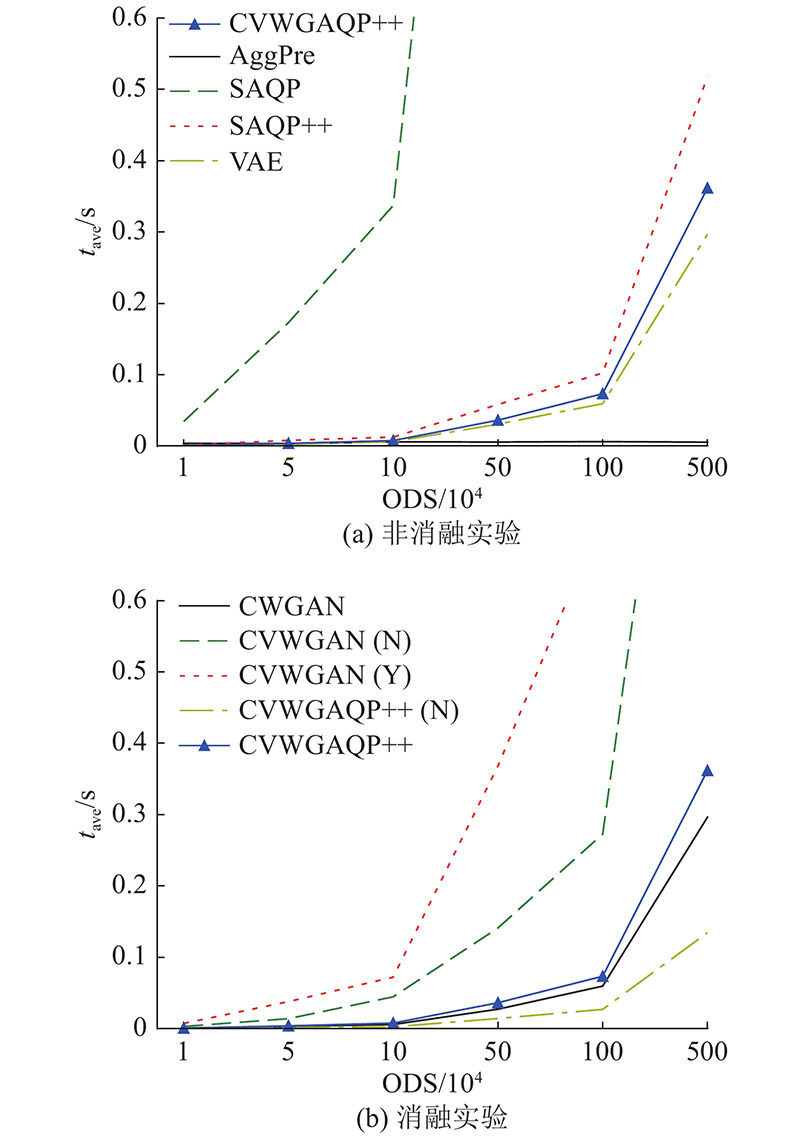
Abstract A new approximate query processing method was proposed to solve the problem of low query accuracy caused by data skew in the approximate query processing. First of all, the algorithm was based on the conditional generative adversarial network and incorporated the conditional variational auto-encoder to ensure the stability and the accuracy of the algorithm. The Wasserstein distance was used to measure the model error to eliminate model collapse. Secondly, based on the above generative model, approximate query processing was achieved and users’ queries were answered without accessing the underlying data, avoiding disk interaction. The model was combined with aggregate precomputation to form an efficient approximate query processing framework to answer interactive queries more accurately and quickly. Finally, an efficient voting algorithm was designed to filter the samples generated by the model and the internal data of the samples, so as to improve the quality of the generated samples and minimize the query error. Experimental results show that, compared with other approximate query processing algorithms, the method proposed can effectively overcome the influence of data skew and answer queries more accurately in shorter interaction time.
|
|
Received: 02 August 2021
Published: 31 May 2022
|
|
|
| Fund: 国家自然科学基金资助项目 (61872106, 61832003, 61632010) |
|
Corresponding Authors:
Xi-xian HAN
E-mail: baiwenchao1998@163.com;hanxx@hit.edu.cn
|
基于条件生成模型的高效近似查询处理框架
提出新型的近似查询处理方法,以克服近似查询处理任务中数据偏斜所导致的查询准确率低的问题. 该方法以条件生成对抗神经网络为基础,融入条件变分自编码器,保证算法执行的稳定性,提高模型准确率;使用Wasserstein距离衡量模型误差,防止模型坍塌. 基于该条件生成模型实现近似查询处理,回答用户查询而无须访问底层数据,避免磁盘交互,并与聚集预计算相结合,构成高效的近似查询处理框架,能更加准确、快速地回答交互式查询. 设计高效的表决算法,对模型生成的样本以及样本内部数据进行过滤,提高生成的样本质量,最小化查询误差. 实验结果表明,与其他近似查询处理算法相比,该方法可以有效克服数据偏斜的影响,同时能够在更短的交互时间内更加准确地回答用户查询.
关键词:
条件生成对抗网络,
条件变分自编码器,
近似查询处理,
聚集预计算,
数据偏斜
|
|
| [1] |
CHAUDHURI S, DING B, KANDULA S. Approximate query processing: no silver bullet [C]// Proceedings of the 2017 ACM International Conference on Management of Data. New York: ACM, 2017: 511-519.
|
|
|
| [2] |
LI K Y, LI G L Approximate query processing: what is new and where to go?[J]. Data Science and Engineering, 2018, 3 (4): 379- 397
doi: 10.1007/s41019-018-0074-4
|
|
|
| [3] |
OLKEN F, ROTEM D Random sampling from databases: a survey[J]. Statistics and Computing, 1995, 5 (1): 25- 42
doi: 10.1007/BF00140664
|
|
|
| [4] |
PANAHBEHAGH B Stratified and ranked composite sampling[J]. Communications in Statistics-simulation and Computation, 2020, 49 (2): 504- 515
doi: 10.1080/03610918.2018.1487067
|
|
|
| [5] |
ESCOBAR P, CANDELA G, TRUJILLO J, et al Adding value to linked open data using a multidimensional model approach based on the RDF data cube vocabulary[J]. Computer Standards and Interfaces, 1994, 5 (1): 25- 42
|
|
|
| [6] |
HILPRECHT B, SCHMIDT A, KULESSA M, et al Deepdb: learn from data, not from queries![J]. Proceedings of the VLDB Endowment, 2020, 13 (7): 992- 1005
doi: 10.14778/3384345.3384349
|
|
|
| [7] |
YAN L C, YOSHUA B, GEOFFREY H Deep learning[J]. Nature, 2015, 521 (7553): 436- 444
doi: 10.1038/nature14539
|
|
|
| [8] |
CRESWELL A, WHITE T, DUMOULIN V, et al Generative adversarial networks: an overview[J]. IEEE Signal Processing Magazine, 2018, 35 (1): 53- 65
doi: 10.1109/MSP.2017.2765202
|
|
|
| [9] |
CORMODE G, GAROFALAKIS M, HASS P J, et al Synopses for massive data: samples, histograms, wavelets, sketches[J]. Foundations and Trends in Databases, 2012, 4 (1−3): 1- 294
|
|
|
| [10] |
CHAUDHURI S, DAS G, NARASAYYA V Optimized stratified sampling for approximate query processing[J]. ACM Transactions on Database Systems (TODS), 2007, 32 (2): 1- 50
|
|
|
| [11] |
NGUYEN T D, SHIH M H, PARVATHANENI S S, et al. Random sampling for group-by queries [C]// 2020 IEEE 36th International Conference on Data Engineering (ICDE). Piscataway: IEEE, 2020: 541-552.
|
|
|
| [12] |
DING B, HUANG S, CHAUDHURI S, et al. Sample+ seek: approximating aggregates with distribution precision guarantee [C]// Proceedings of the 2016 International Conference on Management of Data. New York: ACM, 2016: 679-694.
|
|
|
| [13] |
AGARWAL S, MOZAFARI B, PANDA A, et al. Blinkdb: queries with bounded errors and bounded response times on very large data [C]// Proceedings of the 8th ACM European Conference on Computer Systems. New York: ACM, 2013: 29-42.
|
|
|
| [14] |
VITTER J S, WANG M Approximate computation of multidimensional aggregates of sparse data using wavelets[J]. ACM Sigmod Record, 1999, 28 (2): 193- 204
doi: 10.1145/304181.304199
|
|
|
| [15] |
MA Q, TRIANTAFILLOU P. Dbest: revisiting approximate query processing engines with machine learning models [C]// Proceedings of the 2019 International Conference on Management of Data. New York: ACM, 2019: 1553-1570.
|
|
|
| [16] |
THIRUMURUGANATHAN S, HASAN S, KOUDAS N, et al. Approximate query processing for data exploration using deep generative models [C]// 2020 IEEE 36th International Conference on Data Engineering (ICDE). Piscataway: IEEE, 2020: 1309-1320.
|
|
|
| [17] |
ZHANG M, WANG H. Approximate query processing for group-by queries based on conditional generative models[EB/OL]. (2021-01-08). https://arxiv.org/abs/2101.02914v1.
|
|
|
| [18] |
YUN H, KIM Y, KANG T, et al Pairwise context similarity for image retrieval system using variational auto-encoder[J]. IEEE Access, 2021, 9 (1): 34067- 34077
|
|
|
| [19] |
CAO Y, LIU B, LONG M, et al. Hashgan: deep learning to hash with pair conditional Wasserstein gan [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 1287-1296.
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|