|
|
|
| Construction method of extraction dataset of Al-Si alloy entity relationship |
Ying-li LIU1,2( ),Rui-gang WU1,2,Chang-hui YAO1,2,Tao SHEN1,2,*() ),Rui-gang WU1,2,Chang-hui YAO1,2,Tao SHEN1,2,*() |
1. Faculty of Information Engineering and Automation, Kunming University of Science and Technology, Kunming 650500, China
2. Yunnan Key Laboratory of Computer Technologies Application, Kunming University of Science and Technology, Kunming 650500, China |
|
|
|
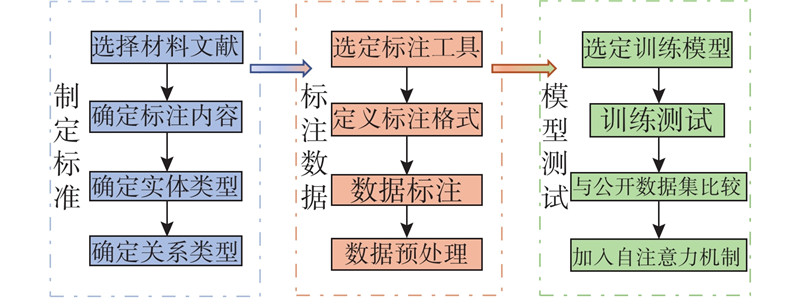
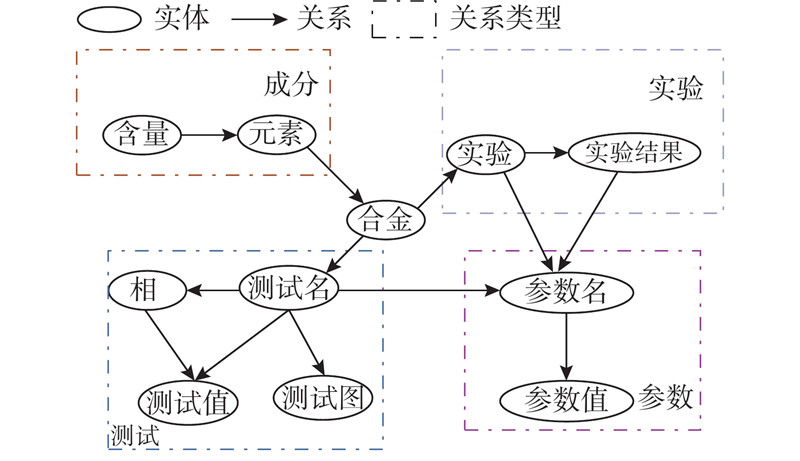
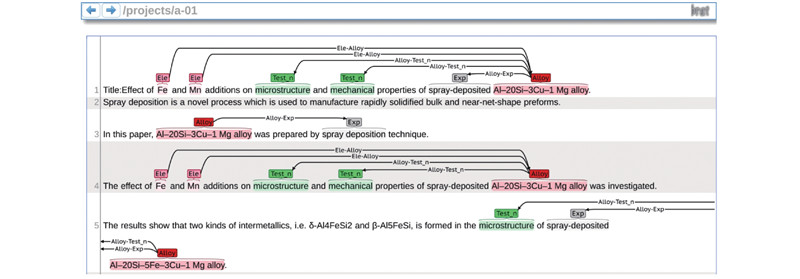
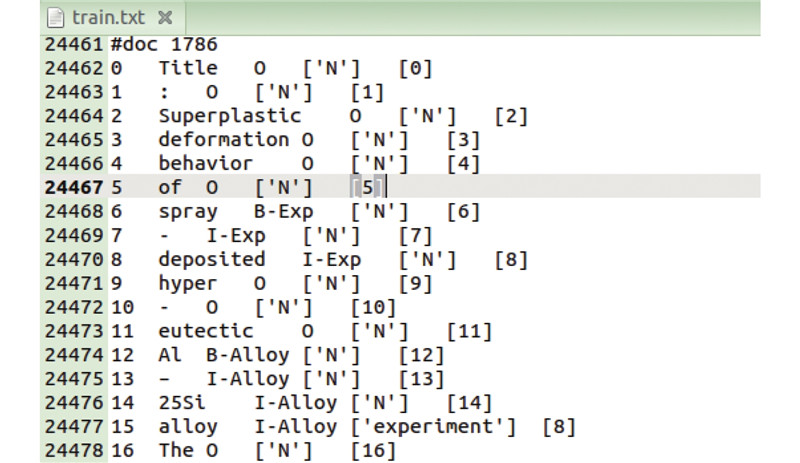
Abstract At present, there is no public dataset suitable for the research work of material entity relationship extraction technology in the field of materials. Aiming at the above problem, the construction method of aluminum-silicon alloy entity relationship extraction dataset was proposed through the literature of high-silicon aluminum alloy spray deposition. The construction standards of the aluminum-silicon alloy entity relationship extraction dataset were formulated under the guidance of experts in the material field, and the collected data were marked with entities and relationships according to the construction standards. After the annotation was completed, the aluminum-silicon alloy entity relationship extraction dataset was generated through data preprocessing. Experiments were conducted through the entity-relationship joint extraction model to verify that the dataset can be applied to entity-relationship extraction tasks. Compared with the public dataset, the semantics and grammar of the sentence in the material dataset were more complicated, and there were more long sentences, which led to a slightly worse performance of the entity relationship joint extraction model on the material dataset. Therefore, a self-attention mechanism was added to the entity relationship joint extraction model, which increased the overall F1 value by about 5.8%. The method of constructing the dataset is universal, and the material dataset can be constructed by the construction method.
|
|
Received: 12 July 2021
Published: 03 March 2022
|
|
|
|
Corresponding Authors:
Tao SHEN
E-mail: lyl2002@126.com;shentao@kust.edu.cn
|
铝硅合金实体关系抽取数据集的构建方法
针对材料领域没有适合材料实体关系抽取技术研究工作的公开数据集这一问题,通过研究高硅铝合金喷射沉积文献提出铝硅合金实体关系抽取数据集的构建方法. 在材料领域专家的指导下制定铝硅合金实体关系抽取数据集的构建标准,并根据构建标准对收集的数据进行实体标注和关系标注. 在标注完成后,通过数据预处理生成铝硅合金实体关系抽取数据集. 通过实体关系联合抽取模型进行实验,验证该数据集可以应用于实体关系抽取任务. 与公开数据集相比,材料数据集句子的语义和语法更为复杂,长句更多,导致实体关系联合抽取模型在材料数据集上的表现略差. 针对上述问题,在实体关系联合抽取模型上加入自注意力机制,使该模型整体的F1值提高了约5.8%. 该数据集的构建方法具有普适性,可以通过该构建方法构建材料数据集.
关键词:
数据集,
构建标准,
数据标注,
实体关系联合抽取模型,
自注意力机制
|
|
| [1] |
NOSENGO N, CEDER G Can artificial intelligence create the next wonder material?[J]. Nature, 2016, 533 (7601): 22- 25
doi: 10.1038/533022a
|
|
|
| [2] |
WANG Y, SEO B, WANG B, et al Fundamentals, materials, and machine learning of polymer electrolyte membrane fuel cell technology[J]. Energy and AI, 2020, 1: 100014
doi: 10.1016/j.egyai.2020.100014
|
|
|
| [3] |
JABLONKA K M, ONGARI D, MOOSAVI S M, et al Big-data science in porous materials: materials genomics and machine learning[J]. Chemical Reviews, 2020, 120 (16): 8066- 8129
doi: 10.1021/acs.chemrev.0c00004
|
|
|
| [4] |
GREEN M, CHOI C, HATTRICK-SIMPERS J, et al Fulfilling the promise of the materials genome initiative with high-throughput experimental methodologies[J]. Applied Physics Reviews, 2017, 4 (1): 011105
doi: 10.1063/1.4977487
|
|
|
| [5] |
KIM E, HUANG K, SAUNDERS A, et al Materials synthesis insights from scientific literature via text extraction and machine learning[J]. Chemistry of Materials, 2017, 29: 9436- 9444
doi: 10.1021/acs.chemmater.7b03500
|
|
|
| [6] |
RACCUGLIA P, ELBERT K C, ADLER P, et al Machine-learning-assisted materials discovery using failed experiments[J]. Nature, 2016, 533 (7601): 73- 76
doi: 10.1038/nature17439
|
|
|
| [7] |
TIAN C, CHEN G Y, YANG L, et al Microstructures and properties of Si-Al alloy for electronic packaging prepared by spray deposition technique[J]. Journal of Functional Materials and Devices, 2006, 12 (1): 54- 58
|
|
|
| [8] |
BEKOULIS G, DELEU J, DEMEESTER T, et al Joint entity recognition and relation extraction as a multi-head selection problem[J]. Expert Systems with Application, 2018, 114: 34- 45
doi: 10.1016/j.eswa.2018.07.032
|
|
|
| [9] |
SANG E T K J A Introduction to the CoNLL-2002 shared task: language-independent named entity recognition[J]. Computer Science, 2002, 20: 1- 4
|
|
|
| [10] |
CARRERAS X. Introduction to the CoNLL-2004 shared task: semantic role labeling[C]// Proceedings of the 8th Conference on Computational Natural Language Learning at HLT-NAACL 2004. Boston: [s.n.], 2004: 89-97.
|
|
|
| [11] |
BARRY P, HENRY S, YETISGEN M, et al. Jointly learning clinical entities and relations with contextual language models and explicit context[EB/OL]. [2021-07-01]. https://arxiv.org/abs/2102.11031.
|
|
|
| [12] |
DODDIOGTON G, MITCHELL A, PRIZYBOCKI M A, et al. The automatic content extraction (ACE) program: tasks, data, and evaluation [EB/OL]. [2021-07-01]. http://www.lrec-conf.org/proceedings/lrec2004/pdf/5.pdf.
|
|
|
| [13] |
KONONOVA O, HUO H, HE T, et al Author correction: text-mined dataset of inorganic materials synthesis recipes[J]. Scientific Data, 2019, 6 (1): 273
doi: 10.1038/s41597-019-0297-x
|
|
|
| [14] |
LI Z, YANG Z, XIANG Y, et al Exploiting sequence labeling framework to extract document-level relations from biomedical texts[J]. BMC Bioinformatics, 2020, 21 (1): 1- 14
doi: 10.1186/s12859-019-3325-0
|
|
|
| [15] |
GURULINGAPPA H, RAJPUT A, ROBERTS A, et al Development of a benchmark corpus to support the automatic extraction of drug-related adverse effects from medical case reports[J]. Journal of Biomedical Informatics, 2012, 45 (5): 885- 892
doi: 10.1016/j.jbi.2012.04.008
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|