|
|
|
| Traffic scene perception algorithm with joint semantic segmentation and depth estimation |
Kang FAN1( ),Ming’en ZHONG1,*(),Jiawei TAN2,Zehui ZHAN1,Yan FENG1 ),Ming’en ZHONG1,*(),Jiawei TAN2,Zehui ZHAN1,Yan FENG1 |
1. Fujian Key Laboratory of Bus Advanced Design and Manufacture, Xiamen University of Technology, Xiamen 361024, China
2. School of Aerospace Engineering, Xiamen University, Xiamen 361102, China |
|
|
|
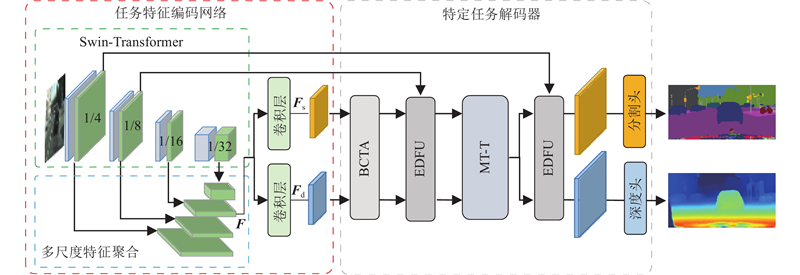
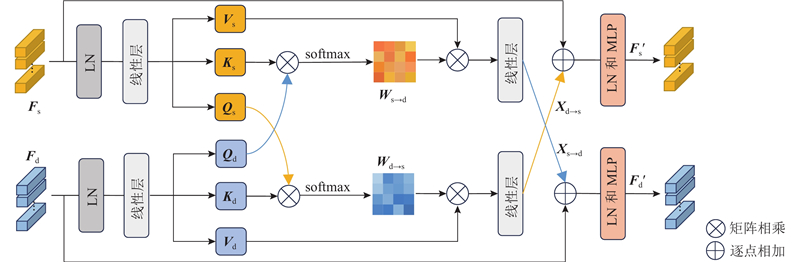
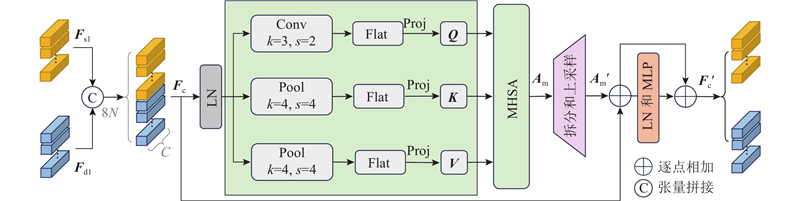
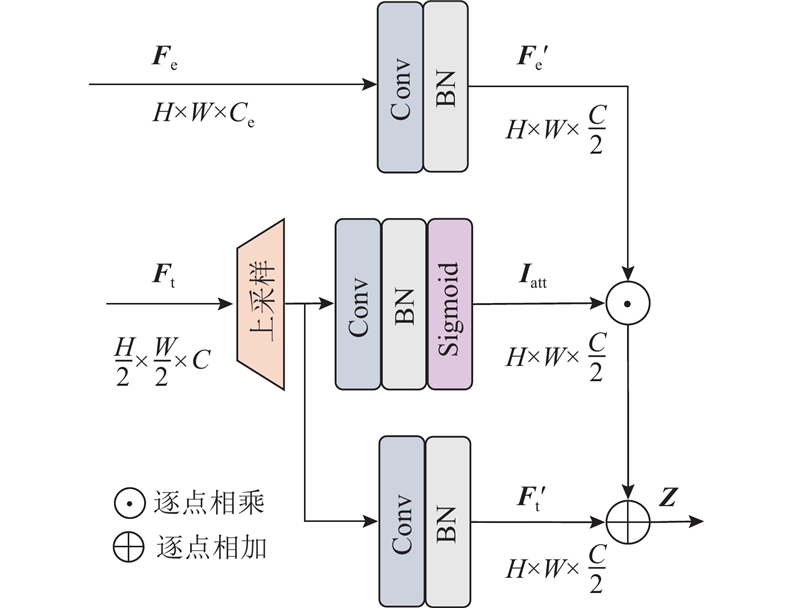
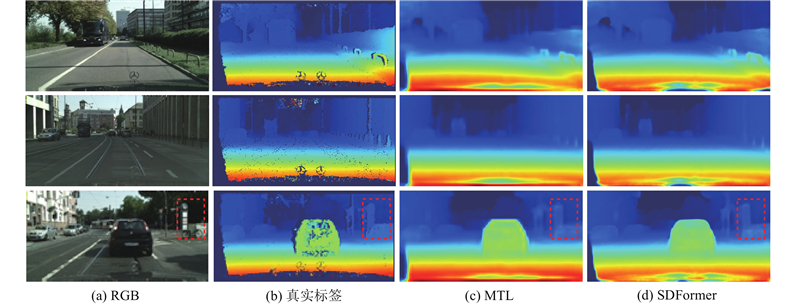
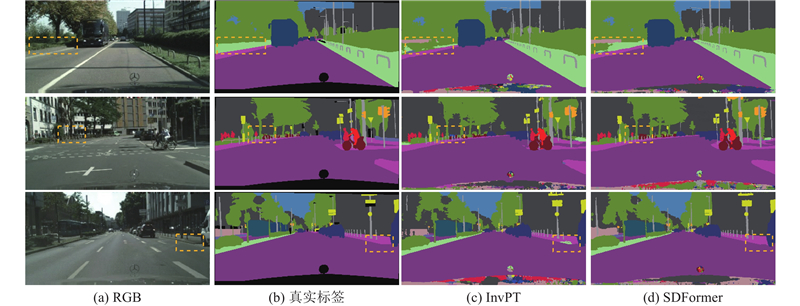
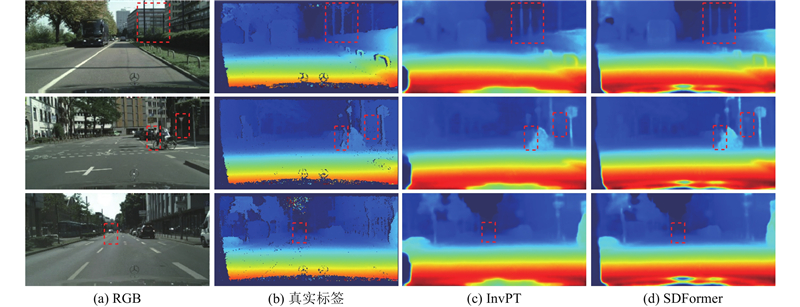
Abstract Inspired by the idea that feature information between different pixel-level visual tasks can guide and optimize each other, a traffic scene perception algorithm based on multi-task learning theory was proposed for joint semantic segmentation and depth estimation. A bidirectional cross-task attention mechanism was proposed to achieve explicit modeling of global correlation between tasks, guiding the network to fully explore and utilize complementary pattern information between tasks. A multi-task Transformer was constructed to enhance the spatial global representation of specific task features, implicitly model the cross-task global context relationship, and promote the fusion of complementary pattern information between tasks. An encoder-decoder fusion upsampling module was designed to effectively fuse the spatial details contained in the encoder to generate fine-grained high-resolution specific task features. The experimental results on the Cityscapes dataset showed that the mean IoU of semantic segmentation of the proposed algorithm reached 79.2%, the root mean square error of depth estimation was 4.485, and the mean relative error of distance estimation for five typical traffic participants was 6.1%. Compared with the mainstream algorithms, the proposed algorithm can achieve better comprehensive performance with lower computational complexity.
|
|
Received: 06 September 2023
Published: 27 March 2024
|
|
|
| Fund: 福建省自然科学基金资助项目(2023J011439,2019J01859). |
|
Corresponding Authors:
Ming’en ZHONG
E-mail: 476863019@qq.com;zhongmingen@xmut.edu.cn
|
联合语义分割和深度估计的交通场景感知算法
受不同像素级视觉任务间的特征信息能够相互指导和优化的思路启发,基于多任务学习理论提出联合语义分割和深度估计的交通场景感知算法. 提出双向跨任务注意力机制,实现任务间的全局相关性显式建模,引导网络充分挖掘和利用任务间互补模式信息. 构建多任务Transformer,增强特定任务特征的空间全局表示,实现跨任务全局上下文关系的隐式建模,促进任务间互补模式信息的融合. 设计编-解码融合上采样模块来有效融合编码器蕴含的空间细节信息,生成精细的高分辨率特定任务特征. 在Cityscapes数据集上的实验结果表明,所提算法的语义分割平均交并比达到79.2%,深度估计均方根误差为4.485,针对5类典型交通参与者的距离估计平均相对误差为6.1%,能够以比现有主流算法更低的计算复杂度获得更优的综合性能.
关键词:
交通环境感知,
多任务学习,
语义分割,
深度估计,
Transformer
|
|
| [1] |
李琳辉, 钱波, 连静, 等 基于卷积神经网络的交通场景语义分割方法研究[J]. 通信学报, 2018, 39 (4): 2018053
LI Linhui, QIAN Bo, LIAN Jing, et al Study on traffic scene semantic segmentation method based on convolutional neural network[J]. Journal on Communications, 2018, 39 (4): 2018053
|
|
|
| [2] |
PAN H, HONG Y, SUN W, et al Deep dual-resolution networks for real-time and accurate semantic segmentation of traffic scenes[J]. IEEE Transactions on Intelligent Transportation Systems, 2023, 24 (3): 3448- 3460
doi: 10.1109/TITS.2022.3228042
|
|
|
| [3] |
张海波, 蔡磊, 任俊平, 等 基于Transformer的高效自适应语义分割网络[J]. 浙江大学学报: 工学版, 2023, 57 (6): 1205- 1214
ZHANG Haibo, CAI Lei, REN Junping, et al Efficient and adaptive semantic segmentation network based on Transformer[J]. Journal of Zhejiang University: Engineering Science, 2023, 57 (6): 1205- 1214
|
|
|
| [4] |
EIGEN D, PUHRSCH C, FERGUS R. Depth map prediction from a single image using a multi-scale deep network [C]// Proceedings of the 27th International Conference on Neural Information Processing Systems . Cambridge: MIT Press, 2014: 2366–2374.
|
|
|
| [5] |
SONG M, LIM S, KIM W Monocular depth estimation using laplacian pyramid-based depth residuals[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2021, 31 (11): 4381- 4393
doi: 10.1109/TCSVT.2021.3049869
|
|
|
| [6] |
LI Z, CHEN Z, LIU X, et al DepthFormer: exploiting long-range correlation and local information for accurate monocular depth estimation[J]. Machine Intelligence Research, 2023, 20 (6): 837- 854
doi: 10.1007/s11633-023-1458-0
|
|
|
| [7] |
WANG P, SHEN X, LIN Z, et al. Towards unified depth and semantic prediction from a single image [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Boston: IEEE, 2015: 2800–2809.
|
|
|
| [8] |
SHOOURI S, YANG M, FAN Z, et al. Efficient computation sharing for multi-task visual scene understanding [EB/OL]. (2023-08-14)[2023-08-23]. https://arxiv.org/pdf/2303.09663.pdf.
|
|
|
| [9] |
VANDENHENDE S, GEORGOULIS S, VAN GANSBEKE W, et al Multi-task learning for dense prediction tasks: a survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44 (7): 3614- 3633
|
|
|
| [10] |
YE H, XU D. Inverted pyramid multi-task transformer for dense scene understanding [C]// European Conference on Computer Vision . [S.l.]: Springer, 2022: 514–530
|
|
|
| [11] |
XU D, OUYANG W, WANG X, et al. PAD-Net: multi-tasks guided prediction-and-distillation network for simultaneous depth estimation and scene parsing [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 675–684.
|
|
|
| [12] |
VANDENHENDE S, GEORGOULIS S, VAN GOOL L. MTI-Net: multi-scale task interaction networks for multi-task learning [C]// European Conference on Computer Vision . [S.l.]: Springer, 2020: 527–543.
|
|
|
| [13] |
ZHOU L, CUI Z, XU C, et al. Pattern-structure diffusion for multi-task learning [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 4514–4523.
|
|
|
| [14] |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Advances in Neural Information Processing Systems . Long Beach: MIT Press, 2017: 5998–6008.
|
|
|
| [15] |
ZHANG X, ZHOU L, LI Y, et al. Transfer vision patterns for multi-task pixel learning [C]// Proceedings of the 29th ACM International Conference on Multimedia . [S.l.]: ACM, 2021: 97–106.
|
|
|
| [16] |
LIU Z, LIN Y, CAO Y, et al. Swin Transformer: hierarchical vision transformer using shifted windows [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 10012–10022.
|
|
|
| [17] |
ZHANG X, CHEN Y, ZHANG H, et al When visual disparity generation meets semantic segmentation: a mutual encouragement approach[J]. IEEE Transactions on Intelligent Transportation Systems, 2021, 22 (3): 1853- 1867
doi: 10.1109/TITS.2020.3027556
|
|
|
| [18] |
LAINA I, RUPPRECHT C, BELAGIANNIS V, et al. Deeper depth prediction with fully convolutional residual networks [C]// 2016 Fourth International Conference on 3D Vision . Stanford: IEEE, 2016: 239–248.
|
|
|
| [19] |
CORDTS M, OMRAN M, RAMOS S, et al. The Cityscapes dataset for semantic urban scene understanding [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 3213–3223.
|
|
|
| [20] |
XIE E, WANG W, YU Z, et al. SegFormer: simple and efficient design for semantic segmentation with transformers [C]// Advances in Neural Information Processing Systems . [S.1.]: MIT Press, 2021: 12077–12090.
|
|
|
| [21] |
WANG W, XIE E, LI X, et al. Pyramid vision transformer: a versatile backbone for dense prediction without convolutions [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 568–578.
|
|
|
| [22] |
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 770–778.
|
|
|
| [23] |
ZHAO H, SHI J, QI X, et al. Pyramid scene parsing network [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 2881–2890.
|
|
|
| [24] |
ZHENG S, LU J, ZHAO H, et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Nashville: IEEE, 2021: 6881–6890.
|
|
|
| [25] |
CHENG B, MISRA I, SCHWING A G, et al. Masked-attention mask transformer for universal image segmentation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 1290–1299.
|
|
|
| [26] |
AGARWAL A, ARORA C. Attention attention everywhere: monocular depth prediction with skip attention [C]// Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision . Waikoloa: IEEE, 2023: 5861–5870.
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|