|
|
|
| Multimodal sentiment analysis model based on multi-task learning and stacked cross-modal Transformer |
Qiao-hong CHEN( ),Jia-jin SUN,Yang-bo LOU,Zhi-jian FANG ),Jia-jin SUN,Yang-bo LOU,Zhi-jian FANG |
| School of Computer Science and Technology, Zhejiang Sci-Tech University, Hangzhou 310018, China |
|
|
|
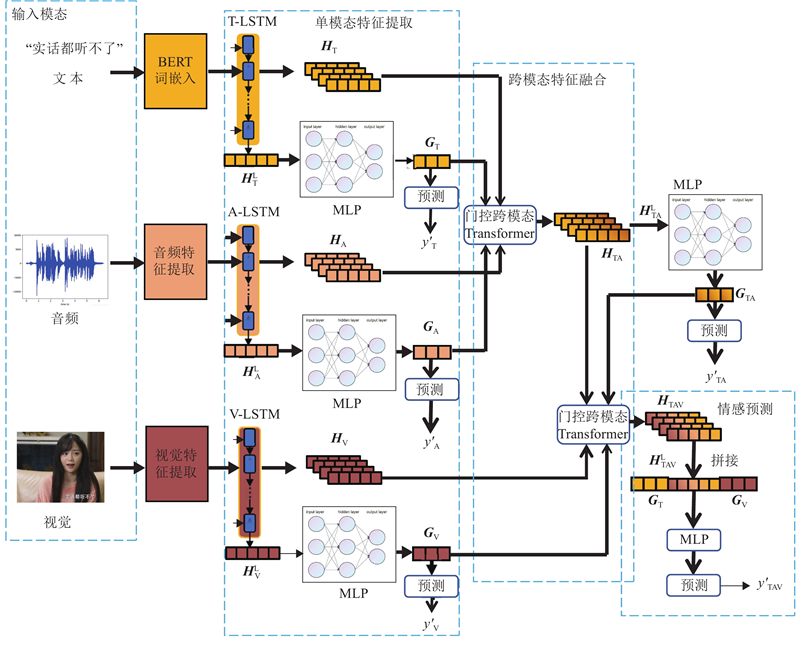
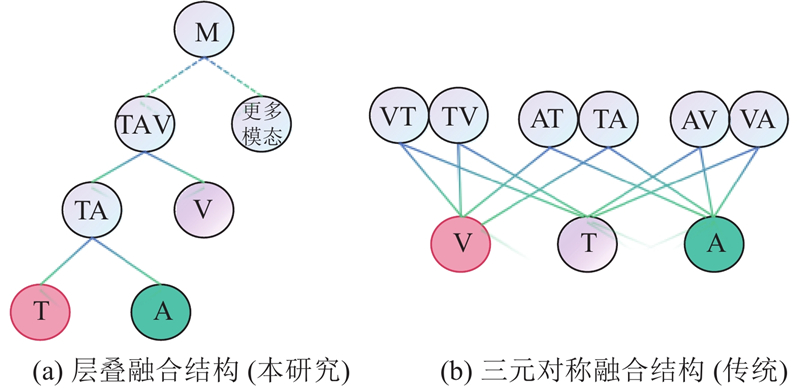
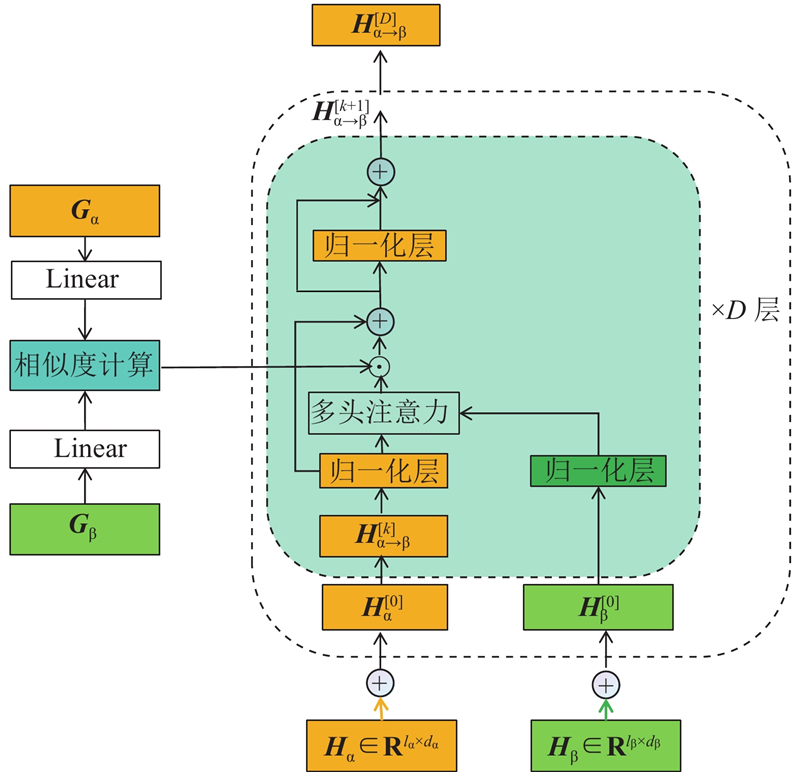
Abstract A new multimodal sentiment analysis model (MTSA) was proposed on the basis of cross-modal Transformer, aiming at the difficult retention of the modal feature heterogeneity for single-modal feature extraction and feature redundancy for cross-modal feature fusion. Long short-term memory (LSTM) and multi-task learning framework were used to extract single-modal contextual semantic information, the noise was removed and the modal feature heterogeneity was preserved by adding up auxiliary modal task losses. Multi-tasking gating mechanism was used to adjust cross-modal feature fusion. Text, audio and visual modal features were fused in a stacked cross-modal Transformer structure to improve fusion depth and avoid feature redundancy. MTSA was evaluated in the MOSEI and SIMS data sets, results show that compared with other advanced models, MTSA has better overall performance, the accuracy of binary classification reached 83.51% and 84.18% respectively.
|
|
Received: 11 February 2023
Published: 27 December 2023
|
|
|
| Fund: 浙江理工大学中青年骨干人才培养经费项目 |
基于多任务学习与层叠 Transformer 的多模态情感分析模型
针对单模态特征提取存在的模态特征异质性难以保留问题和跨模态特征融合存在的特征冗余问题,基于跨模态Transformer,提出新的多模态情感分析模型(MTSA). 使用长短时记忆(LSTM)与多任务学习框架提取单模态上下文语义信息,通过累加辅助模态任务损失以筛除噪声并保留模态特征异质性. 使用多任务门控机制调整跨模态特征融合,通过层叠Transformer结构融合文本、音频与视觉模态特征,提升融合深度,避免融合特征冗余. 在2个公开数据集MOSEI和SIMS上的实验结果表明,相较于其他先进模型,MTSA的整体性能表现更好,二分类准确率分别达到83.51%和84.18%.
关键词:
多模态情感分析,
长短时记忆(LSTM),
Transformer,
多任务学习,
跨模态特征融合
|
|
| [1] |
HUANG Y, DU C, XUE Z, et al. What makes multi-modal learning better than single [C]// Advances in Neural Information Processing Systems. [S.l.]: NIPS, 2021: 10944-10956.
|
|
|
| [2] |
WANG H, MEGHAWAT A, MORENCY L P, et al. Select-additive learning: improving generalization in multimodal sentiment analysis [C]// 2017 IEEE International Conference on Multimedia and Expo. Hong Kong: IEEE, 2017: 949-954.
|
|
|
| [3] |
WILLIAMS J, COMANESCU R, RADU O, et al. DNN multimodal fusion techniques for predicting video sentiment [C]// Proceedings of Grand Challenge and Workshop on Human Multimodal Language. [S.l.]: ACL, 2018: 64-72.
|
|
|
| [4] |
NOJAVANASGHARI B, GOPINATH D, KOUSHIK J, et al. Deep multimodal fusion for persuasiveness prediction [C]// Proceedings of the 18th ACM International Conference on Multimodal Interaction. Tokyo: ACM, 2016: 284-288.
|
|
|
| [5] |
CAMBRIA E, HAZARIKA D, PORIA S, et al. Benchmarking multimodal sentiment analysis [C]// Computational Linguistics and Intelligent Text Processing. Budapest: Springer, 2018: 166-179.
|
|
|
| [6] |
WANG Y, SHEN Y, LIU Z, et al. Words can shift: dynamically adjusting word representations using nonverbal behaviors [C]// Proceedings of the Thirty-third AAAI Conference on Artificial Intelligence and Thirty-First Innovative Applications of Artificial Intelligence Conference and Ninth AAAI Symposium on Educational Advances in Artificial Intelligence. [S.l.]: AAAI, 2019: 7216-7223.
|
|
|
| [7] |
ZADEH A, CHEN M, PORIA S, et al. Tensor fusion network for multimodal sentiment analysis [C]// Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. Copenhagen: ACL, 2017: 1103-1114.
|
|
|
| [8] |
YU W, XU H, MENG F, et al. CH-SIMS: a chinese multimodal sentiment analysis dataset with fine-grained annotation of modality [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. [S.l.]: ACL, 2020: 3718-3727.
|
|
|
| [9] |
YU W, XU H, YUAN Z, et al. Learning modality-specific representations with self-supervised multi-task learning for multimodal sentiment analysis [C]// Proceedings of the AAAI Conference on Artificial Intelligence. [S.l.]: AAAI, 2021, 35(12): 10790-10797.
|
|
|
| [10] |
TSAI Y H H, BAI S, LIANG P P, et al. Multimodal Transformer for unaligned multimodal language sequences [C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence: ACL, 2019: 6558-6569.
|
|
|
| [11] |
WU J, MAI S, HU H. Graph capsule aggregation for unaligned multimodal sequences [C]// Proceedings of the 2021 International Conference on Multimodal Interaction. [S.l.]: ACM, 2021: 521-529.
|
|
|
| [12] |
MA H, HAN Z, ZHANG C, et al. Trustworthy multimodal regression with mixture of normal-inverse gamma distributions [C]// Advances in Neural Information Processing Systems. [S.l.]: NIPS, 2021: 6881-6893.
|
|
|
| [13] |
SIRIWARDHANA S, KALUARACHCHI T, BILLINGHURST M, et al Multimodal emotion recognition with Transformer-based self supervised feature fusion[J]. IEEE Access, 2020, 8: 176274- 176285
doi: 10.1109/ACCESS.2020.3026823
|
|
|
| [14] |
MAJUMDER N, HAZARIKA D, GELBUKH A, et al Multimodal sentiment analysis using hierarchical fusion with context modeling[J]. Knowledge-Based Systems, 2018, 161: 124- 133
doi: 10.1016/j.knosys.2018.07.041
|
|
|
| [15] |
DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume1 (Long and Short Papers). Minneapolis: ACL, 2019: 4171-4186.
|
|
|
| [16] |
MCFEE B, RAFFEL C, LIANG D, et al. librosa: audio and music signal analysis in python [C]// Proceedings of the Python in Science Conference (SCIPY 2015). Austin: SciPy, 2015.
|
|
|
| [17] |
BALTRUSAITIS T, ZADEH A, LIM Y C, et al. OpenFace 2.0: facial behavior analysis toolkit [C]// 2018 13th IEEE International Conference on Automatic Face and Gesture Recognition. Xi’an: IEEE, 2018: 59-66.
|
|
|
| [18] |
HOCHREITER S, SCHMIDHUBER J Long short-term memory[J]. Neural Computation, 1997, 9 (8): 1735- 1780
doi: 10.1162/neco.1997.9.8.1735
|
|
|
| [19] |
HAN W, CHEN H, GELBUKH A, et al. Bi-bimodal modality fusion for correlation-controlled multimodal sentiment analysis [C]// Proceedings of the 2021 International Conference on Multimodal Interaction. [S.l.]: ACM, 2021: 6-15.
|
|
|
| [20] |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. [S.l.]: NIPS, 2017: 6000-6010.
|
|
|
| [21] |
CHEN Z, BADRINARAYANAN V, LEE C Y, et al. GradNorm: gradient normalization for adaptive loss balancing in deep multitask networks [C]// Proceedings of the 35th International Conference on Machine Learning. [S.l.]: PMLR, 2018: 794-803.
|
|
|
| [22] |
ZADEH A, LIANG P P, PORIA S, et al. Multimodal language analysis in the wild: CMU-MOSEI dataset and interpretable dynamic fusion graph [C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics. Melbourne: ACL, 2018: 2236-2246.
|
|
|
| [23] |
ZADEH A, ZELLERS R, PINCUS E, et al. MOSI: multimodal corpus of sentiment intensity and subjectivity analysis in online opinion videos [EB/OL]. (2016-08-12)[2022-11-25]. https://arxiv.org/ftp/arxiv/papers/1606/1606.06259.pdf.
|
|
|
| [24] |
LIU Z, SHEN Y, LAKSHMINARASIMHAN V B, et al. Efficient low-rank multimodal fusion with modality-specific factors [C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics. [S.l.]: ACL, 2018: 2247-2256.
|
|
|
| [25] |
ZADEH A, LIANG P P, PORIA S, et al. Multi-attention recurrent network for human communication comprehension [EB/OL]. (2018-02-03)[2022-11-29]. https://arxiv.org/pdf/1802.00923.pdf.
|
|
|
| [26] |
HAZARIKA D, ZIMMERMANN R, PORIA S. MISA: modality-invariant and-specific representations for multimodal sentiment analysis [C]// Proceedings of the 28th ACM International Conference on Multimedia. Nice: ACM, 2020: 1122-1131.
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|