|
|
|
| Remote sensing image semantic segmentation network based on global information extraction and reconstruction |
Longxue LIANG1( ),Chenglong HE1,Xiaosuo WU1,*(),Haowen YAN2 ),Chenglong HE1,Xiaosuo WU1,*(),Haowen YAN2 |
1. School of Electronic and Information Engineering, Lanzhou Jiaotong University, Lanzhou 730070, China
2. School of Surveying and Mapping and Geographic Information, Lanzhou Jiaotong University, Lanzhou 730070, China |
|
|
|
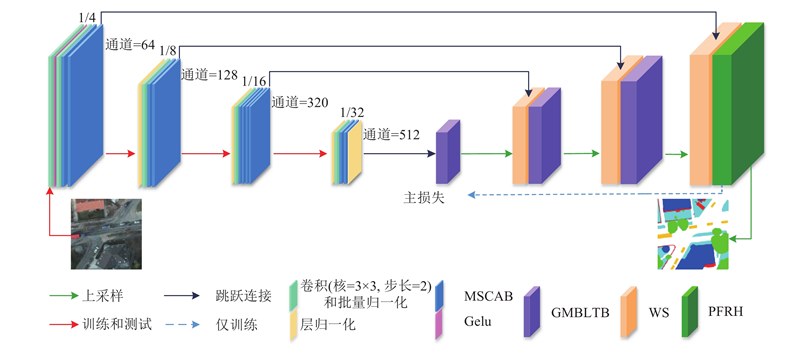
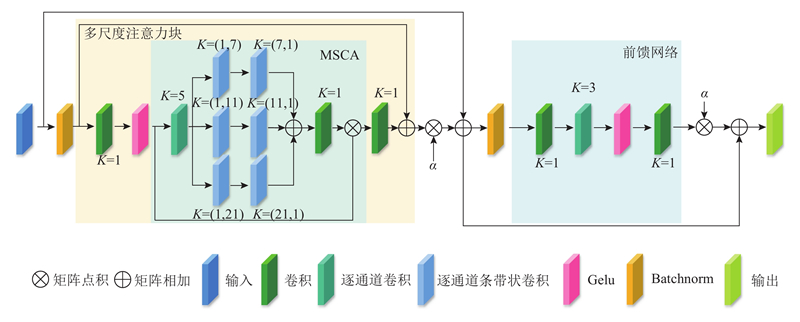
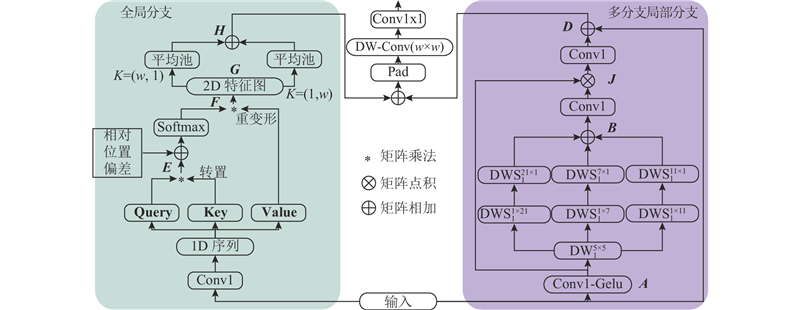
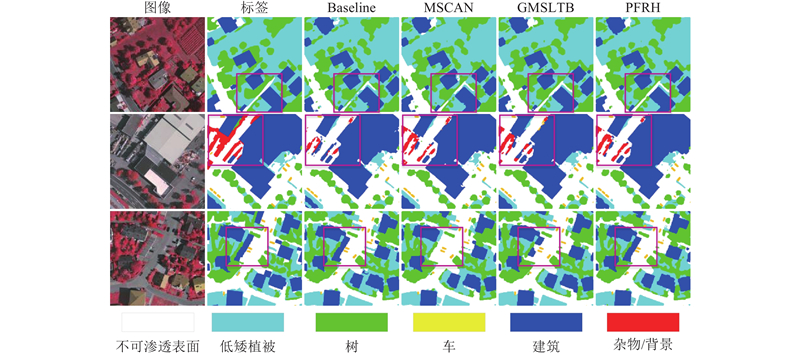
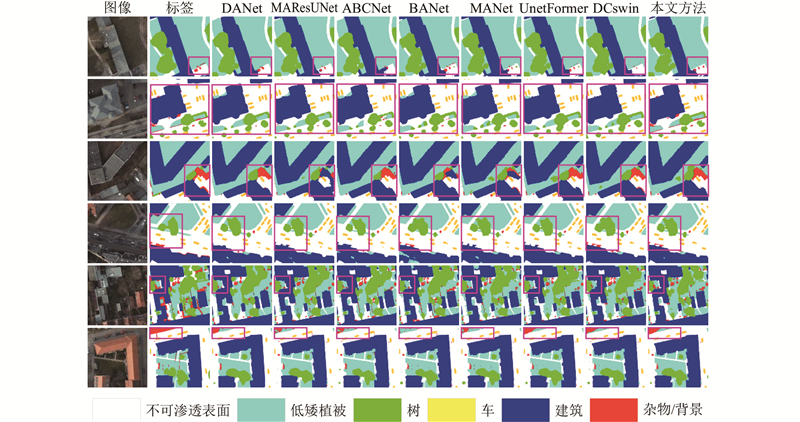
Abstract A network for multi-scale attention extraction and global information reconstruction was proposed in order to enhance the segmentation of remote sensing scene images for downstream tasks. A multi-scale convolutional attention backbone was introduced into the remote sensing deep learning semantic segmentation model in the encoder. Multi-scale convolutional attention can capture multi-scale information and provide richer global deep and shallow information to the decoder. A global multi-branch local Transformer block was designed in the decoder. Multi-scale channel-wise striped convolution reconstructed multi-scale spatial context information, compensating for the spatial information fragmentation in the global branch. The global information segmentation map was reconstructed together with global semantic context information. A polarized feature refinement head was designed at the end of the decoder. A combination of softmax and sigmoid was used to construct a probability distribution function on the channel, which fitted a better output distribution, repaired potential high-resolution information loss in shallow layers, guided and integrated deep information. Then fine spatial texture was obtained. The experimental results showed that high accuracy was achieved by the network, with a mean intersection over union (MIoU) of 82.9% on the ISPRS Vaihingen dataset and 87.1% on the ISPRS Potsdam dataset.
|
|
Received: 29 August 2023
Published: 23 October 2024
|
|
|
| Fund: 国家重点研发计划资助项目(2022YFB3903604);甘肃省自然科学基金资助项目(21JR7RA310);兰州交通大学青年科学基金资助项目(2021029). |
|
Corresponding Authors:
Xiaosuo WU
E-mail: 1367194087@qq.com;wuxs_laser@lzjtu.edu.cn
|
全局信息提取与重建的遥感图像语义分割网络
为了将遥感场景图像更好地进行分割,供给下游任务使用,提出多尺度注意力提取与全局信息重建网络. 编码器引入多尺度卷积注意力骨干到遥感深度学习语义分割模型中. 多尺度卷积注意力能够捕获多尺度信息,给解码器提供更丰富的全局深浅层信息. 在解码器,设计了全局多分支局部Transformer块. 多尺度逐通道条带卷积重建多尺度空间上下文信息,弥补全局分支存在的空间信息割裂,与全局语义上下文信息共同重建全局信息分割图. 解码器末端设计极化特征精炼头. 通道上利用softmax和sigmoid组合,构建概率分布函数,拟合更好的输出分布,修复浅层中潜在的高分辨率信息损失,指导和融合深层信息,获得精细的空间纹理. 实验结果表明,网络实现了很高的精确度,在ISPRS Vaihingen数据集上达到82.9%的平均交并比,在ISPRS Potsdam数据集上达到87.1%的平均交并比.
关键词:
语义分割,
Transformer,
多尺度卷积注意力,
全局多分支局部注意力,
全局信息重建
|
|
| [1] |
LONG J, SHELHAMER E, DARRELL T, et al. Fully convolutional networks for semantic segmentation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Santiago: IEEE, 2015: 3431-3440.
|
|
|
| [2] |
RONNEBERGER O, FISCHER P, BROX T, et al. U-net: convolutional networks for biomedical image segmentation [C]// Proceedings of the Medical Image Computing and Computer-Assisted Intervention . Munich: Springer, 2015: 234-241.
|
|
|
| [3] |
CHEN L C, PAPANDREOU G, KOKKINOS I, et al Deeplab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFS[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 40 (4): 834- 848
|
|
|
| [4] |
CHEN L C, ZHU Y, PAPANDREOU G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation [C]// Proceedings of the European Conference on Computer Vision . Munich: [s. n. ], 2018: 801-818.
|
|
|
| [5] |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [J]. Advances in Neural Information Processing Systems, 2017, 30.
|
|
|
| [6] |
DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: Transformers for image recognition at scale [EB/OL]. [2023-08-01]. https://arxiv.org/abs/2010.11929.
|
|
|
| [7] |
WANG L, LI R, DUAN C, et al. A novel transformer based semantic segmentation scheme for fine-resolution remote sensing images [J]. IEEE Geoscience and Remote Sensing Letters, 2022, 19: 1-5.
|
|
|
| [8] |
GUO M H, LU C Z, HOU Q, et al. Segnext: rethinking convolutional attention design for semantic segmentation [EB/OL]. [2023-08-01]. https://arxiv.org/abs/2209.08575.
|
|
|
| [9] |
WANG L, LI R, ZHANG C, et al UNetFormer: a UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2022, 190: 196- 214
doi: 10.1016/j.isprsjprs.2022.06.008
|
|
|
| [10] |
DIAKOGIANNIS F I, WALDNER F, CACCETTA P, et al ResUNet-a: a deep learning framework for semantic segmentation of remotely sensed data[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2020, 162: 94- 114
doi: 10.1016/j.isprsjprs.2020.01.013
|
|
|
| [11] |
SUN Y, TIAN Y, XU Y Problems of encoder-decoder frameworks for high-resolution remote sensing image segmentation: Structural stereotype and insufficient learning[J]. Neurocomputing, 2019, 330: 297- 304
doi: 10.1016/j.neucom.2018.11.051
|
|
|
| [12] |
吴泽康, 赵姗, 李宏伟, 等 遥感图像语义分割空间全局上下文信息网络[J]. 浙江大学学报: 工学版, 2022, 56 (4): 795- 802
WU Zekang, ZHAO Shan, LI Hongwei, et al Remote sensing image semantic segmentation space global context information network[J]. Journal of Zhejiang University: Engineering Science, 2022, 56 (4): 795- 802
|
|
|
| [13] |
LIU Z, LIN Y, CAO Y, et al. Swin transformer: hierarchical vision transformer using shifted windows [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision. Long Beach: IEEE, 2021: 10012-10022.
|
|
|
| [14] |
FU J, LIU J, TIAN H, et al. Dual attention network for scene segmentation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 3146-3154.
|
|
|
| [15] |
HUANG Z, WANG X, HUANG L, et al. Ccnet: criss-cross attention for semantic segmentation [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Long Beach: IEEE, 2019: 603-612.
|
|
|
| [16] |
LI R, ZHENG S, ZHANG C, et al ABCNet: attentive bilateral contextual network for efficient semantic segmentation of fine-resolution remotely sensed imagery[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2021, 181: 84- 98
doi: 10.1016/j.isprsjprs.2021.09.005
|
|
|
| [17] |
JADERBERG M, SIMONYAN K, ZISSERMAN A. Spatial transformer networks [J]. Advances in Neural Information Processing Systems, 2015, 28: 1–19.
|
|
|
| [18] |
HU J, SHEN L, SUN G. Squeeze-and-excitation networks [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Santiago: IEEE, 2018: 7132-7141.
|
|
|
| [19] |
WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module [C]// Proceedings of the European Conference on Computer Vision. Munich: [s. n. ], 2018: 3-19.
|
|
|
| [20] |
HOU Q, ZHOU D, FENG J. Coordinate attention for efficient mobile network design [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2021: 13713-13722.
|
|
|
| [21] |
LIU H, LIU F, FAN X, et al Polarized self-attention: towards high-quality pixel-wise mapping[J]. Neurocomputing, 2022, 506: 158- 167
doi: 10.1016/j.neucom.2022.07.054
|
|
|
| [22] |
WANG L, LI R, WANG D, et al Transformer meets convolution: a bilateral awareness network for semantic segmentation of very fine resolution urban scene images[J]. Remote Sensing, 2021, 13 (16): 3065
doi: 10.3390/rs13163065
|
|
|
| [23] |
LI R, ZHENG S, ZHANG C, et al Multiattention network for semantic segmentation of fine-resolution remote sensing images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2021, 60: 1- 13
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|