|
|
|
| Image cartoonization incorporating attention mechanism and structural line extraction |
Canlin LI1( ),Xinyue WANG1,Lizhuang MA2,Zhiwen SHAO2,3,Wenjiao ZHANG1 ),Xinyue WANG1,Lizhuang MA2,Zhiwen SHAO2,3,Wenjiao ZHANG1 |
1. School of Computer and Communication Engineering, Zhengzhou University of Light Industry, Zhengzhou 450000, China
2. Department of Computer Science and Engineering, Shanghai Jiao Tong University, Shanghai 200240, China
3. School of Computer Science and Technology, China University of Mining and Technology, Xuzhou 221116, China |
|
|
|
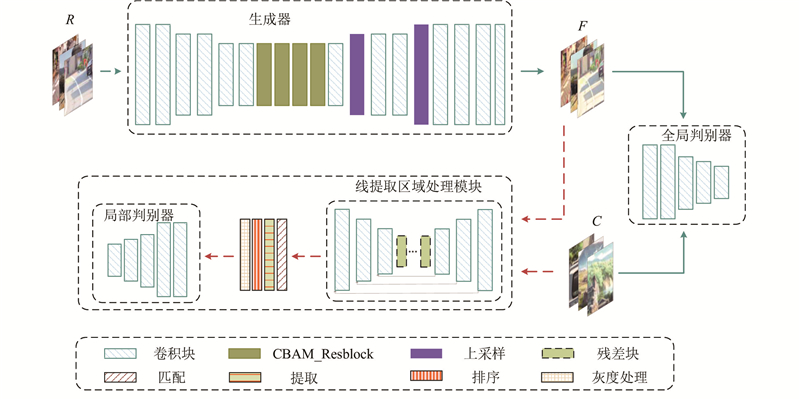
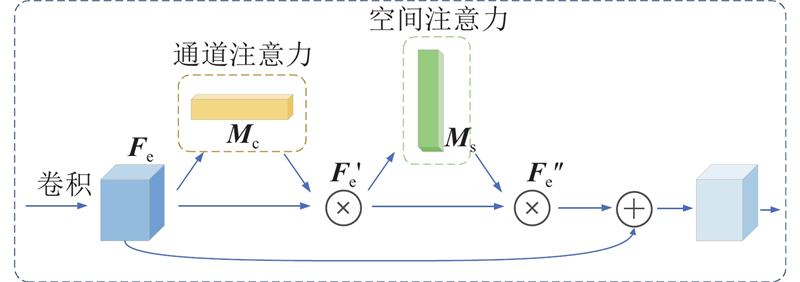
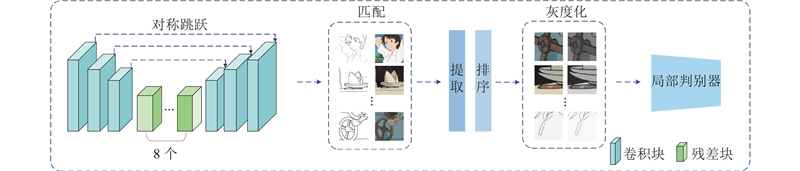
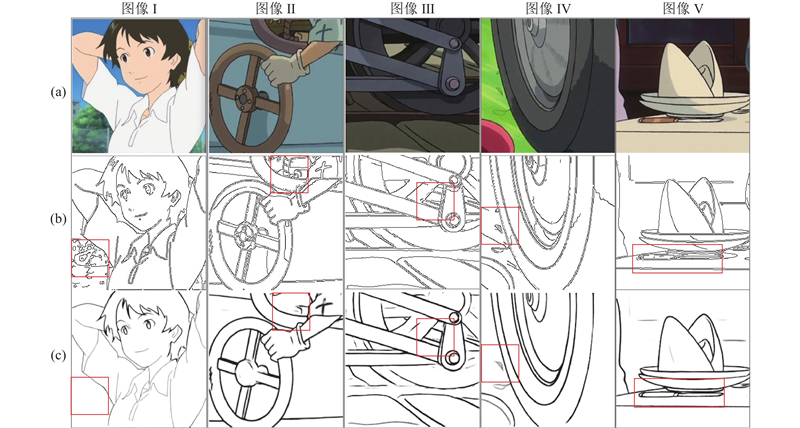
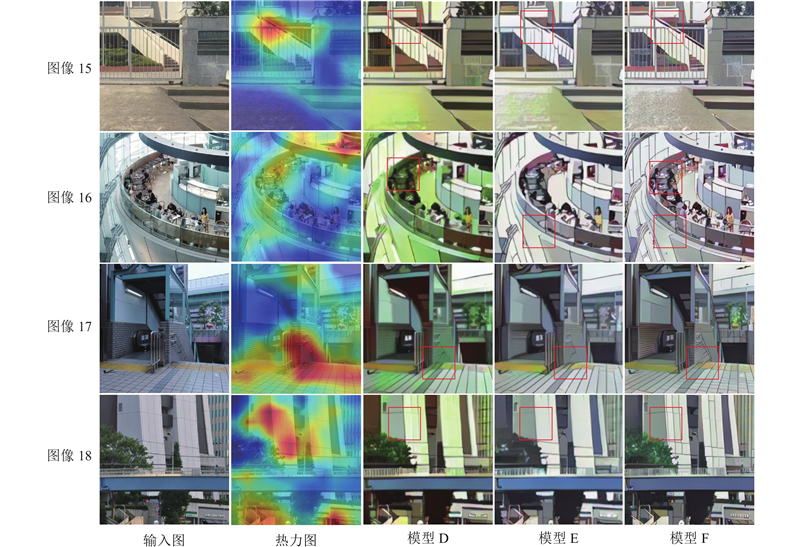
Abstract An image cartoonization method that incorporated attention mechanism and structural line extraction was proposed in order to address the problem that image cartoonization does not highlight important feature information in the image and insufficient edge processing. The generator network with fused attention mechanism was constructed, which extracted more important and richer image information from different features by fusing the connections between features in space and channels. A line extraction region processing module (LERM) in parallel with the global one was designed to perform adversarial training on the edge regions of cartoon textures in order to better learn cartoon textures. This method not only generates cartoonish images with high perceptual quality in terms of important areas and details, but also avoids the loss of content and color. The extensive experimental results showed that the proposed method achieved better cartoonization, which validated the effectiveness of the method.
|
|
Received: 01 July 2023
Published: 23 July 2024
|
|
|
| Fund: 国家自然科学基金资助项目(61972157,62106268);河南省科技攻关项目(242102211003);上海市科技创新行动计划人工智能科技支撑项目(21511101200);江苏省“双创博士”人才资助项目(JSSCBS20211220). |
融合注意力机制和结构线提取的图像卡通化
为了解决图像卡通化没有突出表达图像中的重要特征信息及边缘处理不足的问题,提出融合注意力机制和结构线提取的图像卡通化方法. 构建融合注意力机制的生成器网络,通过空间和通道融合特征间的联系,从不同的特征中提取更加重要和丰富的图像信息. 为了更好地实现对卡通纹理的学习,设计与全局并行的线提取区域处理模块(LERM),以便对卡通纹理的边缘区域进行对抗性训练. 该方法不仅在重要区域和细节方面生成了高感知质量的卡通化图像,而且避免了内容和颜色的损失. 大量的实验结果表明,利用该方法取得了更好的卡通风格化效果,验证了该方法的有效性,.
关键词:
生成式对抗网络,
图像卡通化,
注意力机制,
结构线提取,
边缘检测
|
|
| [1] |
梅洪, 陈昭炯 基于Mean Shift和FDoG的图像卡通化渲染[J]. 计算机工程与应用, 2016, 52 (10): 213- 217
MEI Hong, CHEN Zhaojiong Cartoonish rendering of images based on Mean Shift and FDoG[J]. Computer Engineering and Applications, 2016, 52 (10): 213- 217
doi: 10.3778/j.issn.1002-8331.1407-0015
|
|
|
| [2] |
刘侠 基于OpencCV中Mean Shift的图像卡通化处理[J]. 信息与电脑: 理论版, 2020, 32 (20): 54- 57
LIU Xia Image cartoon processing based on Mean Shift in OpencCV[J]. Information and Computer: Theory Edition, 2020, 32 (20): 54- 57
|
|
|
| [3] |
CANNY J A computational approach to edge detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1986, PAMI-8 (6): 679- 698
doi: 10.1109/TPAMI.1986.4767851
|
|
|
| [4] |
WU Z, ZHU Z, DU J, et al. CCPL: contrastive coherence preserving loss for versatile style transfer [C]// 17th European Conference on Computer Vision . Cham: Springer, 2022: 189-206.
|
|
|
| [5] |
ZHANG Y, TANG F, DONG W, et al. Domain enhanced arbitrary image style transfer via contrastive learning [C]// ACM SIGGRAPH 2022 Conference Proceedings . Vancouver: ACM, 2022: 1-8.
|
|
|
| [6] |
ZHU J Y, PARK T, ISOLA P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks [C]// IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 2223-2232.
|
|
|
| [7] |
CHEN Y, LAI Y K, LIU Y J. Cartoongan: generative adversarial networks for photo cartoonization [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 9465-9474.
|
|
|
| [8] |
PĘŚKO M, SVYSTUN A, ANDRUSZKIEWICZ P, et al Comixify: transform video into comics[J]. Fundamenta Informaticae, 2019, 168 (2-4): 311- 333
doi: 10.3233/FI-2019-1834
|
|
|
| [9] |
WANG X, YU J. Learning to cartoonize using white-box cartoon representations [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 8090-8099.
|
|
|
| [10] |
LI R, WU C H, LIU S, et al SDP-GAN: saliency detail preservation generative adversarial networks for high perceptual quality style transfer[J]. IEEE Transactions on Image Processing, 2020, 30: 374- 385
|
|
|
| [11] |
CHEN J, LIU G, CHEN X. Animegan: a novel lightweight GAN for photo animation [C]// International Symposium on Intelligence Computation and Applications . Singapore: Springer, 2020: 242-256.
|
|
|
| [12] |
GATYS L A, ECKER A S, BETHGE M. Image style transfer using convolutional neural networks [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 2414-2423.
|
|
|
| [13] |
SHU Y, YI R, XIA M, et al GAN-based multi-style photo cartoonization[J]. IEEE Transactions on Visualization and Computer Graphics, 2021, 28 (10): 3376- 3390
|
|
|
| [14] |
DONG Y, TAN W, TAO D, et al cartoonLossGAN: learning surface and coloring of images for cartoonization[J]. IEEE Transactions on Image Processing, 2021, 31: 485- 498
|
|
|
| [15] |
GAO X, ZHANG Y, TIAN Y. Learning to incorporate texture saliency adaptive attention to image cartoonization [EB/OL]. (2022-08-02)[2023-06-01]. https://arxiv.org/abs/2208.01587.
|
|
|
| [16] |
KANG H, LEE S, CHUI C K Flow-based image abstraction[J]. IEEE Transactions on Visualization and Computer Graphics, 2008, 15 (1): 62- 76
|
|
|
| [17] |
WINNEMOELLER H, KYPRIANIDIS J E, OLSEN S C XDoG: an extended difference-of-Gaussians compendium including advanced image stylization[J]. Computers and Graphics, 2012, 36 (6): 740- 753
doi: 10.1016/j.cag.2012.03.004
|
|
|
| [18] |
SÝKORA D, BURIÁNEK J, ŽÁRA J Segmentation of black and white cartoons[J]. Image and Vision Computing, 2005, 23 (9): 767- 782
doi: 10.1016/j.imavis.2005.05.010
|
|
|
| [19] |
SÝKORA D, BURIÁNEK J, ŽÁRA J. Sketching cartoons by example [C]// Proceedings of Eurographics Workshop on Sketch Based Interfaces and Modeling . Schoten: Eurographics Association, 2005: 27-33.
|
|
|
| [20] |
ZHANG S H, CHEN T, ZHANG Y F, et al Vectorizing cartoon animations[J]. IEEE Transactions on Visualization and Computer Graphics, 2009, 15 (4): 618- 629
doi: 10.1109/TVCG.2009.9
|
|
|
| [21] |
LIU X, MAO X, YANG X, et al Stereoscopizing cel animations[J]. ACM Transactions on Graphics, 2013, 32 (6): 1- 10
|
|
|
| [22] |
LI C, LIU X, WONG T T Deep extraction of manga structural lines[J]. ACM Transactions on Graphics, 2017, 36 (4): 1- 12
|
|
|
| [23] |
WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module [C]// Proceedings of the European Conference on Computer Vision . Munich: Elsevier, 2018: 3-19.
|
|
|
| [24] |
RUSSAKOVSKY O, DENG J, SU H, et al Imagenet large scale visual recognition challenge[J]. International Journal of Computer Vision, 2015, 115 (3): 211- 252
doi: 10.1007/s11263-015-0816-y
|
|
|
| [25] |
SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [EB/OL]. (2014-09-04)[2023-06-01]. https://arxiv.org/abs/1409.1556.
|
|
|
| [26] |
MAO X, LI Q, XIE H, et al. Least squares generative adversarial networks [C]// Proceedings of the IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 2794-2802.
|
|
|
| [27] |
HEUSEL M, RAMSAUER H, UNTERTHINER T, et al. GANs trained by a two time-scale update rule converge to a local Nash equilibrium [C]// Advances in Neural Information Processing Systems . Long Beach: MIT Press, 2017: 30.
|
|
|
| [28] |
SZEGEDY C, VANHOUCKE V, IOFFE S, et al. Rethinking the inception architecture for computer vision [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 2818-2826.
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|