|
|
|
| Fusing generative adversarial network and temporal convolutional network for Mandarin emotion recognition |
Hai-feng LI1( ),Xue-ying ZHANG1,*(),Shu-fei DUAN1,Hai-rong JIA1,Hui-zhi LIANG2 ),Xue-ying ZHANG1,*(),Shu-fei DUAN1,Hai-rong JIA1,Hui-zhi LIANG2 |
1. College of Electronic Information and Optical Engineering, Taiyuan University of Technology, Taiyuan 030024, China
2. School of Computing, Newcastle University, Newcastle upon Tyne NE1 7RU, United Kingdom |
|
|
|
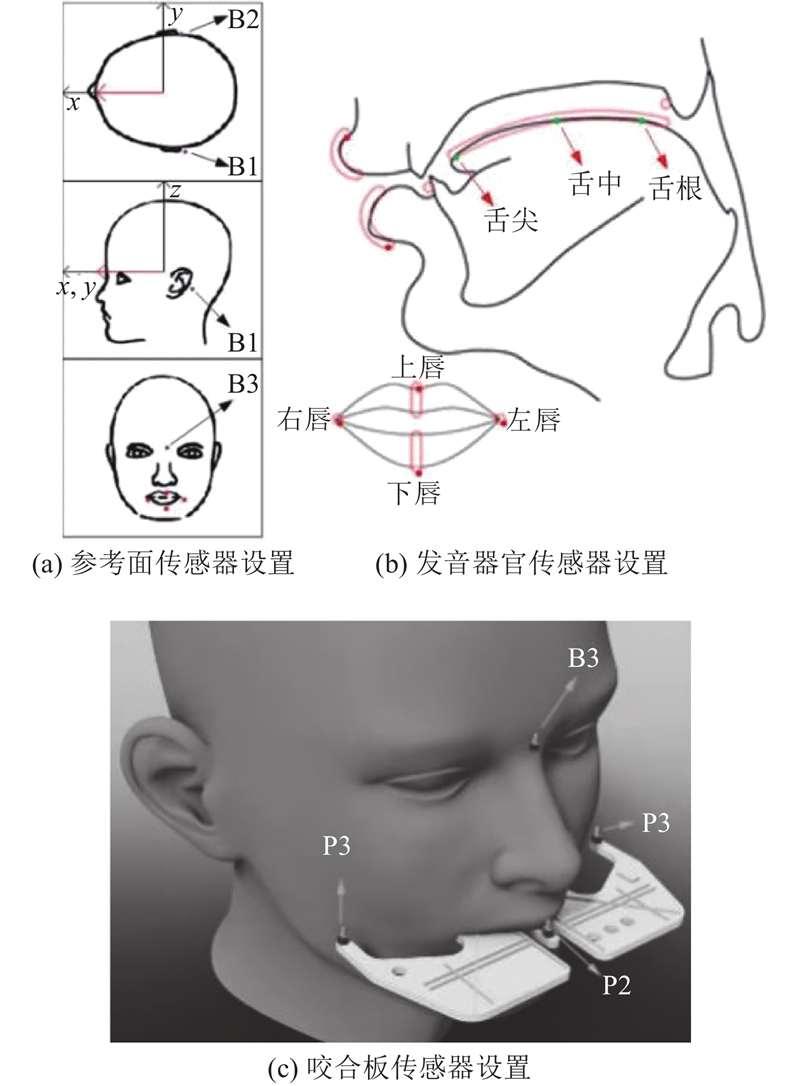
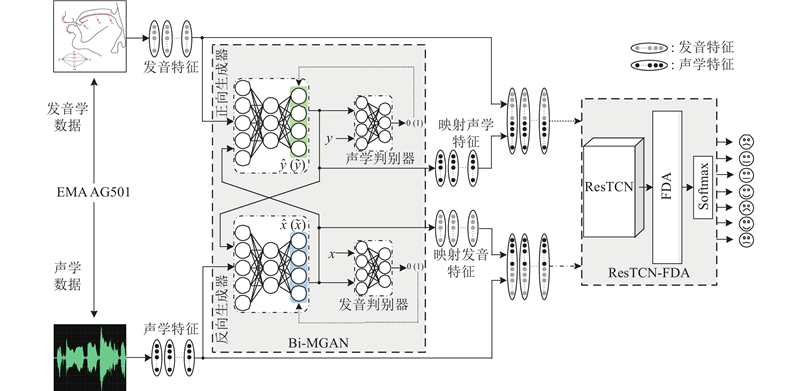
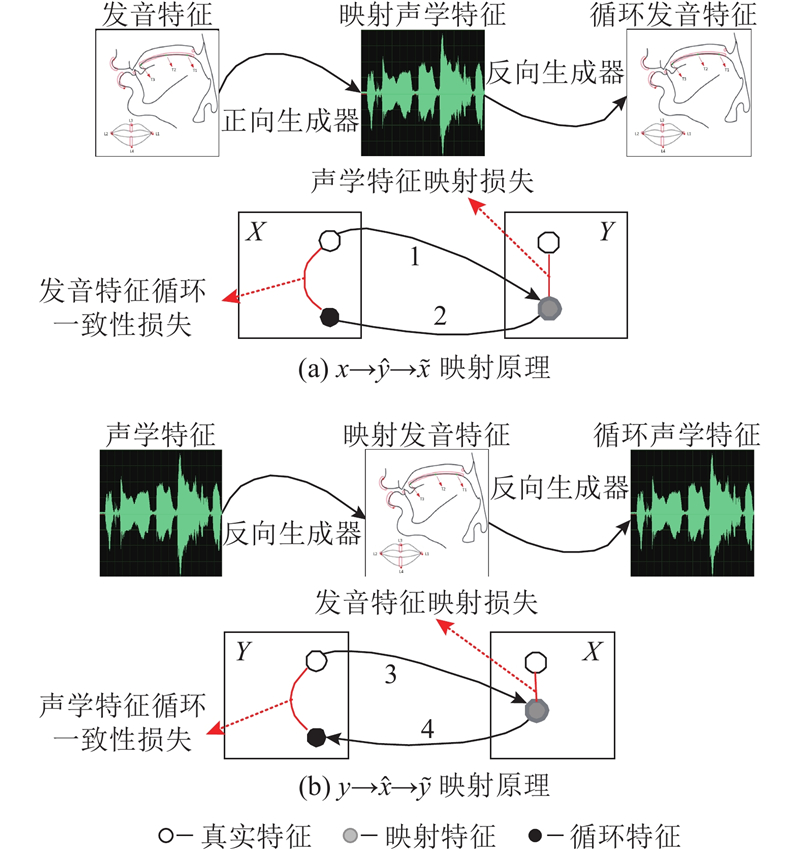
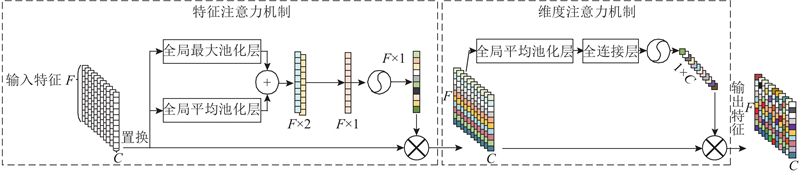
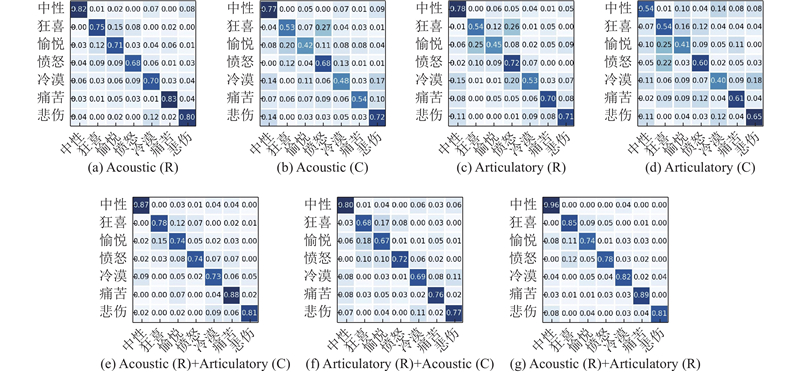
Abstract An emotion recognition system that integrates acoustic and articulatory feature conversions was proposed in order to investigate the influence of acoustic and articulatory conversions on Mandarin emotion recognition. Firstly, a multimodal emotional Mandarin database was recorded based on the human articulation mechanism. Then, a bi-directional mapping generative adversarial network (Bi-MGAN) was designed to solve the feature conversion problem with bimodality, and the generator loss functions and the mapping loss functions were proposed to optimise the network. Finally, a residual temporal convolutional network based on the feature-dimension attention (ResTCN-FDA) was constructed to use attention mechanisms to adaptively assign different weights to different variety features and different dimension channels. Experimental results show that the conversion accuracy of Bi-MGAN outperforms the current optimal algorithms for conversion network in both the forward and the reverse mapping tasks. The evaluation metrics of ResTCN-FDA on a given emotion dataset is much higher than traditional emotion recognition algorithms. The real features fused with the mapped features resulted in a significant increase in the accuracy of the emotions being recognized correctly, and the positive effect of mapping on Mandarin emotion recognition was demonstrated.
|
|
Received: 23 June 2022
Published: 16 October 2023
|
|
|
| Fund: 国家自然科学基金资助项目(12004275);山西省研究生创新项目(2022Y235);山西省留学人员科技活动择优资助项目(20200017);山西省回国留学人员科研资助项目(2019025,2020042);太原理工大学引进人才科研启动基金资助项目(tyut-rc201405b);山西省应用基础研究计划面上自然基金资助项目(20210302123186) |
|
Corresponding Authors:
Xue-ying ZHANG
E-mail: 2244812211@qq.com;tyzhangxy@163.com
|
融合生成对抗网络与时间卷积网络的普通话情感识别
为了探究声学与发音学转换对普通话情感识别的影响,提出融合声学与发音特征转换的情感识别系统. 根据人体发音机制,录制普通话多模态音视频情感数据库. 设计双向映射生成对抗网络(Bi-MGAN)来解决双模态间的特征转换问题,定义生成器损失函数和映射损失函数来优化网络. 搭建基于特征-维度注意力机制的残差时间卷积网络(ResTCN-FDA),利用注意力机制自适应地为不同种类特征和不同维度通道赋予不同的权重. 实验结果表明,Bi-MGAN在正向和反向映射任务中的转换精度均优于主流的转换网络算法;ResTCN-FDA在给定情感数据集上的评价指标远高于传统的情感识别算法;真实特征融合映射特征使得情感被正确识别的准确率显著提升,证明了映射对普通话情感识别的积极作用.
关键词:
循环生成对抗网络,
情感识别,
声学与发音学转换,
时间卷积网络,
注意力机制
|
|
| [1] |
LEI J J, ZHU X W, WANG Y BAT: block and token self-attention for speech emotion recognition[J]. Neural Networks, 2022, 156: 67- 80
doi: 10.1016/j.neunet.2022.09.022
|
|
|
| [2] |
LI Y, TAO J, CHAO L, et al CHEAVD: a Chinese natural emotional audio visual database[J]. Journal of Ambient Intelligence and Humanized Computing, 2017, 8 (6): 913- 924
doi: 10.1007/s12652-016-0406-z
|
|
|
| [3] |
CHOU H C, LIN W C, CHANG L C, et al. NNIME: the NTHU-NTUA Chinese interactive multimodal emotion corpus [C]// 2017 Seventh International Conference on Affective Computing and Intelligent Interaction. San Antonio: IEEE, 2017: 292-298.
|
|
|
| [4] |
BUSSO C, BULUT M, LEE C, et al IEMOCAP: interactive emotional dyadic motion capture database[J]. Language Resources and Evaluation, 2008, 42 (4): 335- 359
doi: 10.1007/s10579-008-9076-6
|
|
|
| [5] |
QIN C, CARREIRA M A. An empirical investigation of the nonuniqueness in the acoustic-to-articulatory mapping [C]// Eighth Annual Conference of the International Speech Communication Association. Antwerp: [s.n.], 2007: 27-31.
|
|
|
| [6] |
REN G, FU J, SHAO G, et al Articulatory to acoustic conversion of Mandarin emotional speech based on PSO-LSSVM[J]. Complexity, 2021, 29 (3): 696- 706
|
|
|
| [7] |
HOGDEN J, LOFQVIST A, GRACCO V, et al Accurate recovery of articulator positions from acoustics: new conclusions based on human data[J]. The Journal of the Acoustical Society of America, 1996, 100 (3): 1819- 1834
doi: 10.1121/1.416001
|
|
|
| [8] |
LING Z H, RICHMOND K, YAMAGISHI J, et al Integrating articulatory features into HMM based parametric speech synthesis[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2009, 17 (6): 1171- 1185
doi: 10.1109/TASL.2009.2014796
|
|
|
| [9] |
LI M, KIM J, LAMMERT A, et al Speaker verification based on the fusion of speech acoustics and inverted articulatory signals[J]. Computer Speech and Language, 2016, 36: 196- 211
doi: 10.1016/j.csl.2015.05.003
|
|
|
| [10] |
GUO L, WANG L, DANG J, et al Learning affective representations based on magnitude and dynamic relative phase information for speech emotion recognition[J]. Speech Communication, 2022, 136 (4): 118- 127
|
|
|
| [11] |
CHEN Q, HUANG G A novel dual attention based BLSTM with hybrid features in speech emotion recognition[J]. Engineering Applications of Artificial Intelligence, 2021, 102 (5): 104277
|
|
|
| [12] |
张静, 张雪英, 陈桂军, 等 结合3D-CNN和频-空注意力机制的EEG情感识别[J]. 西安电子科技大学学报, 2022, 49 (3): 191- 198
ZHANG Jing, ZHANG Xue-ying, CHEN Gui-jun, et al EEG emotion recognition based on the 3D-CNN and spatial-frequency attention mechanism[J]. Journal of Xidian University, 2022, 49 (3): 191- 198
doi: 10.19665/j.issn1001-2400.2022.03.021
|
|
|
| [13] |
KUMARAN U, RADHA R S, NAGARAJAN S M, et al Fusion of mel and gammatone frequency cepstral coefficients for speech emotion recognition using deep C-RNN[J]. International Journal of Speech Technology, 2021, 24 (2): 303- 314
doi: 10.1007/s10772-020-09792-x
|
|
|
| [14] |
LIESKOVSKA E, JAKUBEC M, JARINA R, et al A review on speech emotion recognition using deep learning and attention mechanism[J]. Electronics, 2021, 10 (10): 1163
doi: 10.3390/electronics10101163
|
|
|
| [15] |
ZHU J Y, PARK T, ISOLA P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks [C]// Proceedings of the IEEE International Conference on Computer Vision. Venice: ICCV, 2017: 2223-2232.
|
|
|
| [16] |
YUAN J, BAO C. CycleGAN based speech enhancement for the unpaired training data [C]// 2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference. Lanzhou: APSIPA, 2019: 878-883.
|
|
|
| [17] |
SU B H, LEE C Unsupervised cross-corpus speech emotion recognition using a multi-source CycleGAN[J]. IEEE Transactions on Affective Computing, 2022, 48 (8): 650- 715
|
|
|
| [18] |
LIN J, WIJNGAARDEN A J L, WANG K C, et al Speech enhancement using multi-stage self-attentive temporal convolutional networks[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2021, 29: 3440- 3450
doi: 10.1109/TASLP.2021.3125143
|
|
|
| [19] |
PANDEY A, WANG D L. TCNN: temporal convolutional neural network for real-time speech enhancement in the time domain [C]// 2019 IEEE International Conference on Acoustics, Speech and Signal Processing. Brighton: ICASSP, 2019: 6875-6879.
|
|
|
| [20] |
ZHANG L, SHI Z, HAN J, et al. Furcanext: end-to-end monaural speech separation with dynamic gated dilated temporal convolutional networks [C]// International Conference on Multimedia Modeling. Daejeon: ICMM, 2020: 653-665.
|
|
|
| [21] |
JIANG Z, ZHANG R, GUO Y, et al Noise interference reduction in vision module of intelligent plant cultivation robot using better Cycle GAN[J]. IEEE Sensors Journal, 2022, 22 (11): 11045- 11055
doi: 10.1109/JSEN.2022.3164915
|
|
|
| [22] |
GOODFELLOW I, POUGET A J, MIRZA M, et al Generative adversarial nets[J]. Advances in Neural Information Processing Systems, 2014, 27: 42- 51
|
|
|
| [23] |
LIU P, YU Q, WU Z, et al. A deep recurrent approach for acoustic-to-articulatory inversion [C]// 2015 IEEE International Conference on Acoustics, Speech and Signal Processing. Brisbane: ICASSP, 2015: 4450-4454.
|
|
|
| [24] |
CHENG Y, XU Y, ZHONG H, et al Leveraging semisupervised hierarchical stacking temporal convolutional network for anomaly detection in IoT communication[J]. IEEE Internet of Things Journal, 2020, 8 (1): 144- 155
|
|
|
| [25] |
ZHAO Z P, LI Q F, ZHANG Z X, et al Combining a parallel 2D CNN with a self-attention dilated residual network for CTC-based discrete speech emotion recognition[J]. Neural Networks, 2021, 141: 52- 60
doi: 10.1016/j.neunet.2021.03.013
|
|
|
| [26] |
CHANG, XUAN K. An exploration of self-supervised pretrained representations for end-to-end speech recognition [C]// 2021 IEEE Automatic Speech Recognition and Understanding Workshop. Cartagena: ASRU, 2021, 228-235.
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|