|
|
|
| Multimodal image retrieval model based on semantic-enhanced feature fusion |
Fan YANG( ),Bo NING*(),Huai-qing LI,Xin ZHOU,Guan-yu LI ),Bo NING*(),Huai-qing LI,Xin ZHOU,Guan-yu LI |
| School of Information Science and Technology, Dalian Maritime University, Dalian 116026, China |
|
|
|
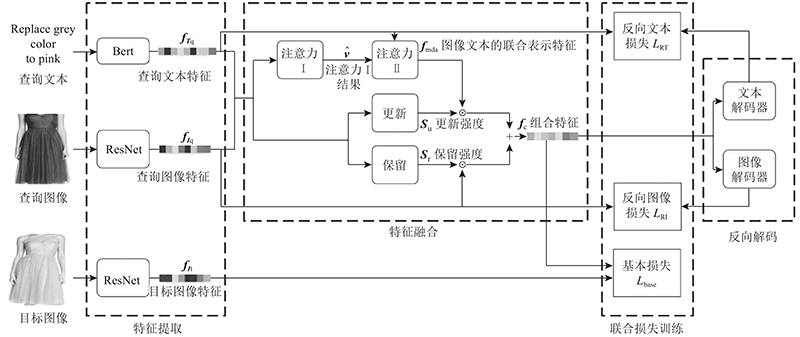
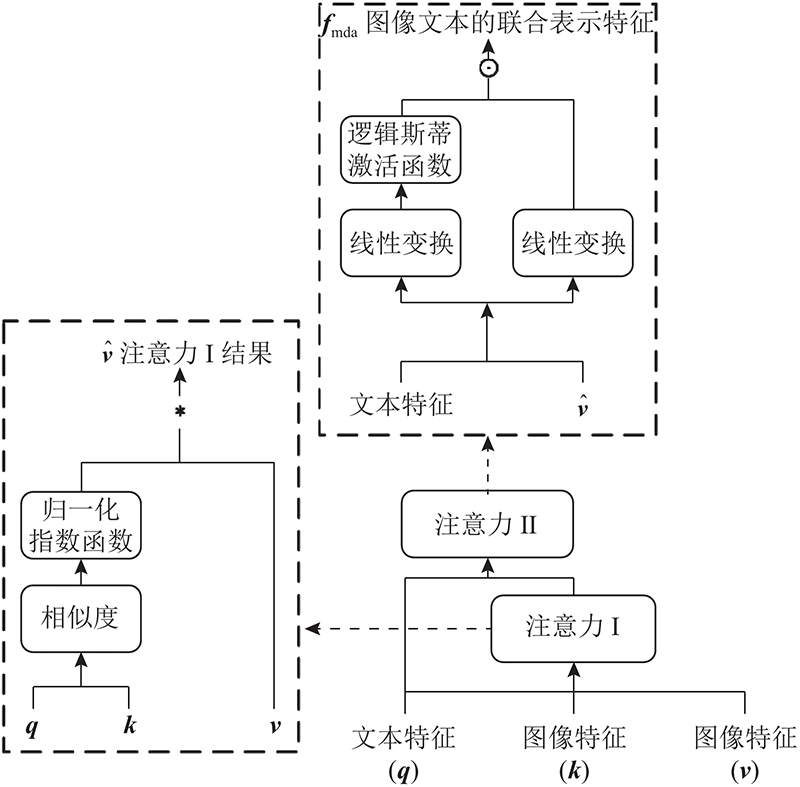
Abstract A multimodal image retrieval model based on semantic-enhanced feature fusion (SEFM) was proposed to establish the correlation between text features and image features in multimodal image retrieval tasks. Semantic enhancement was conducted on the combined features during feature fusion by two proposed modules including the text semantic enhancement module and the image semantic enhancement module. Firstly, to enhance the text semantics, a multimodal dual attention mechanism was established in the text semantic enhancement module, which associated the multimodal correlation between text and image. Secondly, to enhance the image semantics, the retain intensity and update intensity were introduced in the image semantic enhancement module, which controlled the retaining and updating degrees of the query image features in combined features. Based on the above two modules, the combined features can be optimized, and be closer to the target image features. In the experiment part, the SEFM model was evaluated on MIT-States and Fashion IQ datasets, and experimental results show that the proposed model performs better than the existing works on recall and precision metrics.
|
|
Received: 29 July 2022
Published: 28 February 2023
|
|
|
| Fund: 国家自然科学基金资助项目 (61976032, 62002039);辽宁省教育厅科学研究面上资助项目(LJKZ0063) |
|
Corresponding Authors:
Bo NING
E-mail: yangfany116@163.com;ningbo@dlmu.edu.cn
|
基于语义增强特征融合的多模态图像检索模型
为了在多模态图像检索任务中建立文本特征与图像特征的相关性,提出基于语义增强特征融合的多模态图像检索模型(SEFM). 该模型通过文本语义增强模块、图像语义增强模块2部分在特征融合时对组合特征进行语义增强. 在文本语义增强模块建立多模态双重注意力机制,利用双重注意力建立文本与图像之间的关联以增强文本语义;在图像语义增强模块引入保留强度和更新强度,控制组合特征中查询图像特征的保留和更新程度. 基于以上2个模块可以优化组合特征使其更接近目标图像特征. 在MIT-States和Fashion IQ这2个数据集上对该模型进行评估,实验结果表明在多模态图像检索任务上该模型与现有方法相比在召回率和准确率上都有所提升.
关键词:
多模态,
语义增强,
特征融合,
图像检索,
注意力机制
|
|
| [1] |
DUBEY S R A decade survey of content based image retrieval using deep learning[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2022, 32 (5): 2687- 2704
doi: 10.1109/TCSVT.2021.3080920
|
|
|
| [2] |
PANG K T, LI K, YANG Y X , et al. Generalising fine-grained sketch-based image retrieval [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 677-686.
|
|
|
| [3] |
LIN T Y, CUI Y, BELONGIE S, et al. Learning deep representations for ground-to-aerial geolocalization [C]// 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 5007-5015.
|
|
|
| [4] |
ZHANG M, MAIDMENT T, DIAB A, et al. Domain-robust VQA with diverse datasets and methods but no target labels [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. [s.l.]: IEEE, 2021: 7046-7056.
|
|
|
| [5] |
CHEN L, JIANG Z, XIAO J, et al. Human-like controllable image captioning with verb-specific semantic roles [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. [s.l.]: IEEE, 2021: 16846-16856.
|
|
|
| [6] |
SANTORO A, RAPOSO D, BARRETT D G T, et al. A simple neural network module for relational reasoning [C]// Advances in Neural Information Processing Systems 30. Long Beach: Curran Associates, 2017: 4967-4976.
|
|
|
| [7] |
PEREZ E, STRUB F, VRIES H D, et al. FiLM: visual reasoning with a general conditioning layer [C]// 32nd AAAI Conference on Artificial Intelligence. New Orleans: AAAI, 2018: 3942-3951.
|
|
|
| [8] |
NAGARAJAN T, GRAUMAN K. Attributes as operators: factorizing unseen attribute-object compositions [C]// European Conference on Computer Vision. Munich: Springer, 2018: 172-190.
|
|
|
| [9] |
VO N , LU J, CHEN S, et al. Composing text and image for image retrieval: an Empirical Odyssey[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019 : 6439-6448.
|
|
|
| [10] |
ANWAAR M U, LABINTCEV E, KLEINSTEUBER M. Compositional learning of image-text query for image retrieval [C]// 2021 IEEE Winter Conference on Applications of Computer Vision. Waikoloa: IEEE, 2021: 1139-1148.
|
|
|
| [11] |
HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition [C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770-778.
|
|
|
| [12] |
DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Minneapolis: Association for Computational Linguistics, 2019: 4171–4186.
|
|
|
| [13] |
HUANG L, WANG W M, CHEN J, et al. Attention on attention for image captioning[C]// 2019 IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 4633-4642.
|
|
|
| [14] |
ISOLA P, LIM J J, ADELSON E H. Discovering states and transformations in image collections [C]// 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 1383-1391.
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|